


楓清科技(Fabarta)合作人
ChatGPT 2022年底出現以來,大模型熱度持續不減,尤其是今年年初DeepSeek的爆火,更讓大模型走入更多人的視野。大模型除了在C端(個人用户)廣泛應用,在B端(企業)也有越來越多的企業在做落地。2025年8月26號, 國務院發佈《關於深入實施“人工智能+”行動的意見》,更將以大模型為主的人工智能技術放到更加突出的位置。“人工智能+” 行動堪比十年前國家推出的互聯網+ 政策。人工智能+行業將重塑各行各業,助力數智化轉型和產業重構。在此大背景下,以大模型為主的人工智能應用和落地已成為各大企業的必答題,而非選做題。
通過筆者與上百家企業客户的交流進而觀察到:中國企業客户IT基礎差異大、數據儲備和質量不同、智能化進展參差不齊、AI落地驅動力差異大,可謂是一企業一世界。我們可將AI在企業落地按四個階段進行劃分:
第一階段:企業關注大模型,但還未進行落地。有用户覺得大模型是萬能的,什麼都能做;有用户覺得大模型在企業中無法真正應用,純娛樂用途。在此階段,需要跟客户對齊理解,瞭解大模型能力邊界,為AI在企業應用打好認知基礎。
第二階段:企業已認可大模型價值,也在探索階段。在此階段,不少客户也會自己拿開源軟件進行各種嘗試。這類客户經常會發現大模型實際落地效果不好。此時需要跟客户對齊正確的大模型落地路線,並通過場景驗證技術路線的效果。
第三階段:通過探索,認可技術路線,並且開始落地。在落地時,有兩種思路,一種是直接落地場景,另一種是構建平台,基於平台落地場景。如果場景相對較少,可以直接從場景出發進行落地。但如果場景多,或有統一規劃,需要統一技術路線和技術棧,降低後續運維複雜度,此情況下建議基於統一的平台構建各類場景,這與大模型出現之前的AI平台落地類似。
第四個階段:在前三個階段都完成的基礎之上,開始深入將AI賦能各項業務,助力企業的智能決策。
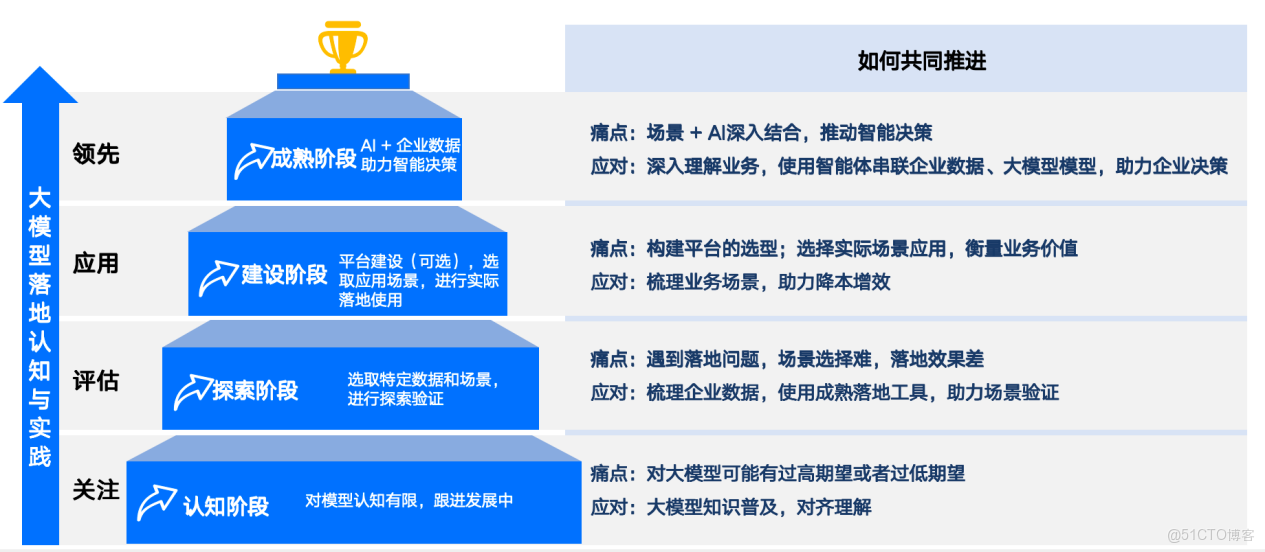
圖1:大模型落地的不同階段
通常企業落地過程中會經歷規劃準備、實施落地、持續運營三個關鍵里程碑,在這期間有哪些要點是客户關心的?本文將其歸類,簡稱為六問大模型落地。
01規劃準備
【定方向】第一問:大模型落地都包含哪些部分,只用大模型是否足夠?
不少客户會認為,有大模型,就可以直接進行場景落地,在企業直接應用。
大模型是基於世界通識數據訓練而來,作為企業級應用存在明顯侷限。一方面,很多企業私有化知識並沒有被內化到大模型中;另一方面,大模型由於其按照概率進行“單字接龍”預測輸出的技術特點,導致其必然存在幻覺,所以並不適合將大模型直接用於企業的應用。僅當在回答通用知識時,原生大模型輸出結果方可作為結果參考,而專業化應用必須結合領域內知識及上下文工程進行適配和效果提升。
那大模型落地都包含哪些主要部分?下圖是我們根據實踐給出的企業落地參考架構。
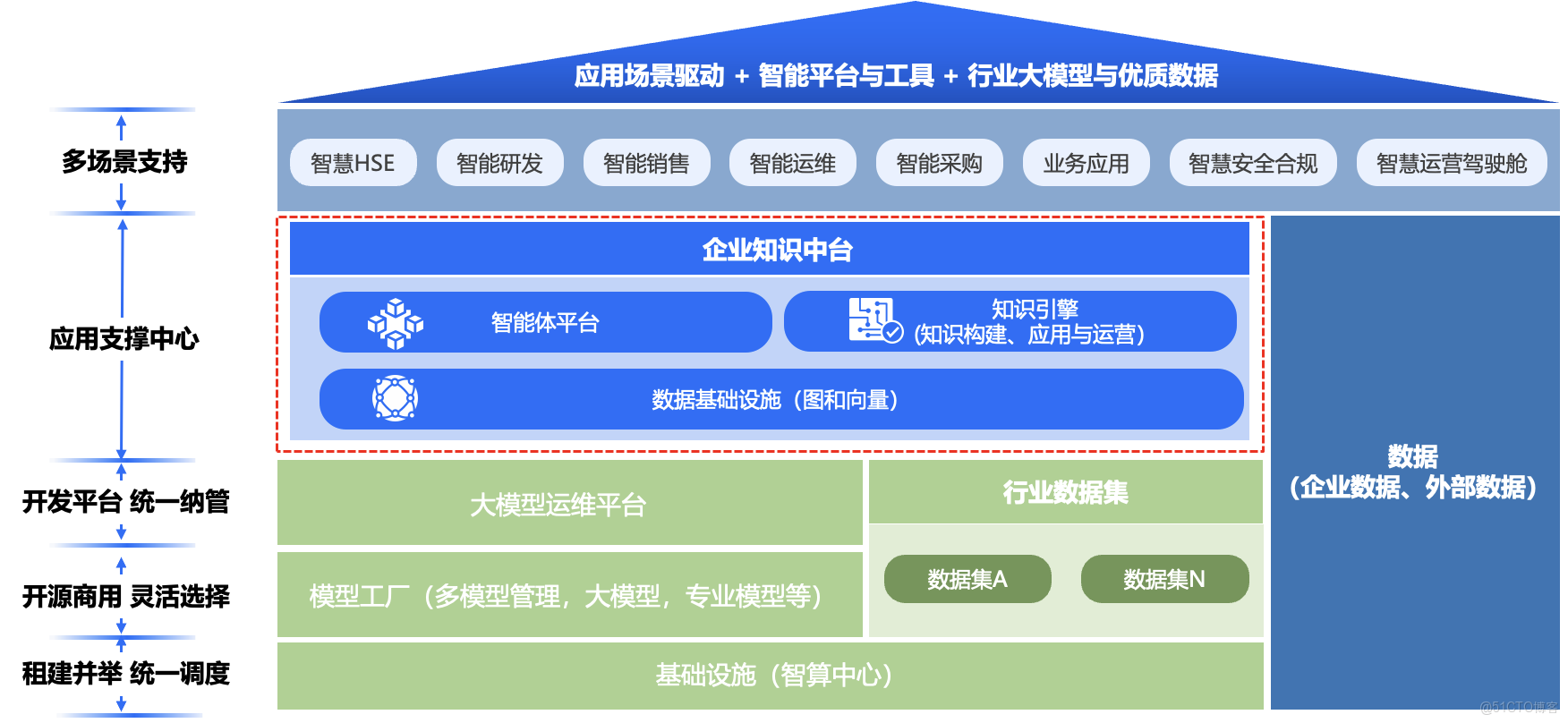
圖2:大模型落地整體參考架構
首先大模型落地所需要的算力基礎設施層通常使用主流的Nvidia GPU 與國產NPU(比如華為昇騰系列等)。 在硬件之上,可以統稱為模型服務層,包括可運行各類大模型和專業領域模型,支持大模型訓練、管理和推理服務,對模型進行全生命週期管理,同時覆蓋用於模型訓練或蒸餾的行業高質量數據集構建。
在模型之上,要結合企業數據進行大模型落地,我們將其稱之為應用支撐中心。楓清科技的企業知識中台正是提供鏈接大模型和應用場景的中間層,包含知識引擎(將數據轉換為知識,並且提供知識應用和運營),提供圖+向量融合的多模態引擎助力知識的記憶和推理,以及智能體平台可以將知識和業務流程串聯用於支撐場景應用,助力大模型對於業務價值的提升。
【選路徑】第二問:是否用開源軟件做落地就可以?
這是很多用户常問的問題,“我已經用開源軟件進行了一些驗證,並且已經運行了一些demo結果, 我是否可以直接使用開源工具進行實際場景落地?”
這個問題的答案依不同企業的自身訴求而異。如果客户的實際情況是做一些非常簡單的驗證,或者對業務垂域效果要求、數據的安全管控要求相對寬鬆,那用開源軟件其實可以滿足訴求,比如非常簡單的文檔問答或者工作流,使用RAGFlow或者Dify開源框架都是常見的做法。但在企業級應用中,開源軟件存在如下問題:
1.如何進行復雜的企業級權限管控?
2.如何進行系統的可擴展設計?
3.如何與企業已有系統進行對接?
4.如何根據企業需求進行定製化?
5.如何兼容更多平台的不同能力?
這些問題會在自建企業級知識中台的過程中遇到,需要考慮支持從複雜的權限控制到安全體系設計、從系統可開放性設計到系統對接,從原型驗證到持續運營,需要以企業級產品支撐場景落地。
以集團級規章制度問答為例,規章制度查詢需要進行嚴格的管控公司內及跨公司權限控制,對本職能部門與上下級及其他職能部門的交互權限進行精準界定,構建清晰的權限邊界。該管控模式通過限制非授權交互,從源頭防範越權的操作風險,保障規章制度問答在合規範圍內進行。當前開源軟件無法滿足此類複雜的權限管控需求,而這些需求又是大型企業落地時的常見需求。楓清科技的知識中台可以實現文檔、知識庫、應用等不同類型的資源在用户、組織等層級的進行精細粒度權限管控,並且可以實現不同層級的權限分享,以滿足企業複雜的權限管控要求。
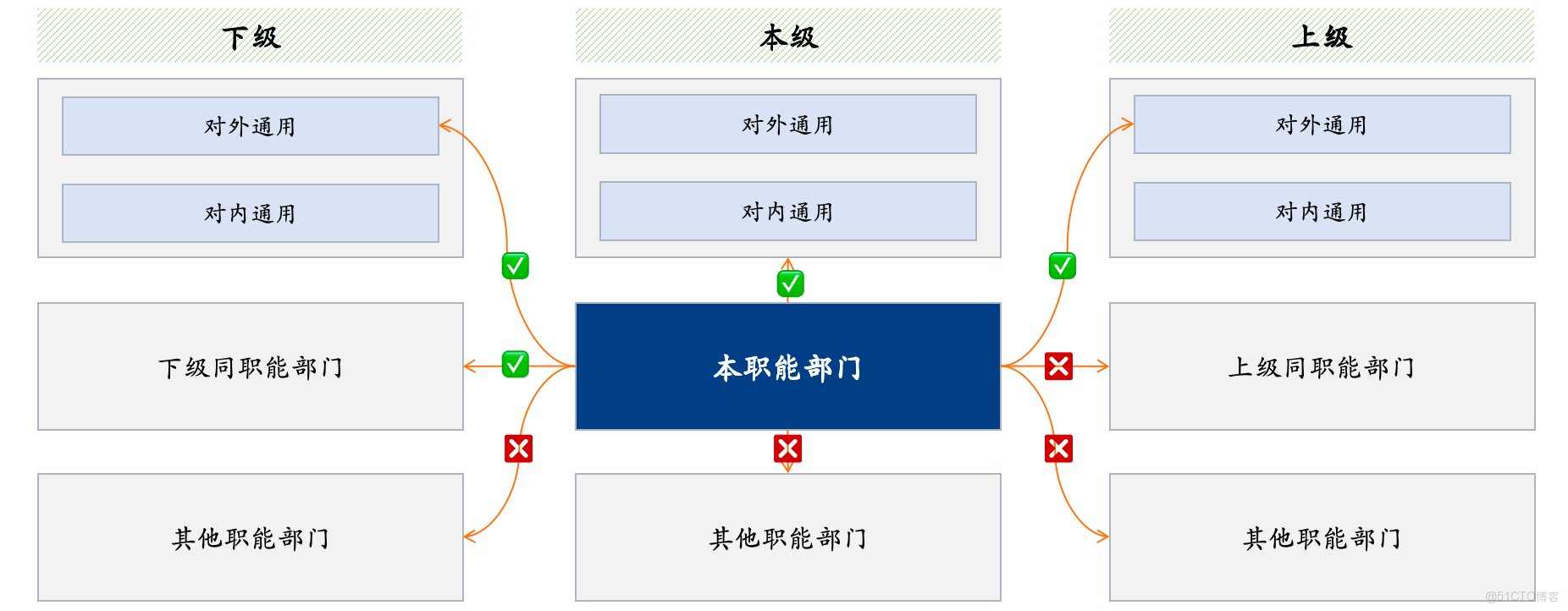
圖3:企業級權限需求實例 -- 開源軟件無法處理此類需求
02實施落地
【找場景】第三問:場景挖掘這件事重要嗎,如何找高價值場景?
傳統軟件開發一般需求相對可明確定義,而AI,尤其是大模型企業落地是新生事物,其落地效果與具體業務場景和數據情況密切相關,包括大模型在內的AI技術都有其能力邊界。因此選取高價值場景成為大模型和AI落地的重要環節。
楓清科技在實際落地過程中,沉澱了一系列的方法論來發掘高價值場景,包括明確用户、梳理流程、瞭解數據情況,從已有流程中尋找痛點,挖掘出AI能夠賦能的場景,最終從技術可行性和業務價值度兩個維度進行評估,來確定實際落地應用,進而助力流程的智能化實現。
通常場景挖掘挖掘過程中,需要業務人員深度參與,人工智能技術一定是為業務服務的,應當先與業務人員進行訪談作為輸入,探索用户旅程,獲取實際工作中的痛點,再看如何用AI進行賦能。
梳理體系會隨着不同行業、不同業務訴求而變化。比如在已有客户落地過程中,我們與業務人員共創,對研產供銷服完整的業務鏈,與通用的管理協同整體場景進行梳理,結合企業現狀確定優先級列表,作為落地場景候選,進而供客户基於場景進行選擇,共同進行落地。楓清科技也構建了包括AI4S、智能經營分析等多個垂類場景方案,可以在這些業務領域為客户賦能。
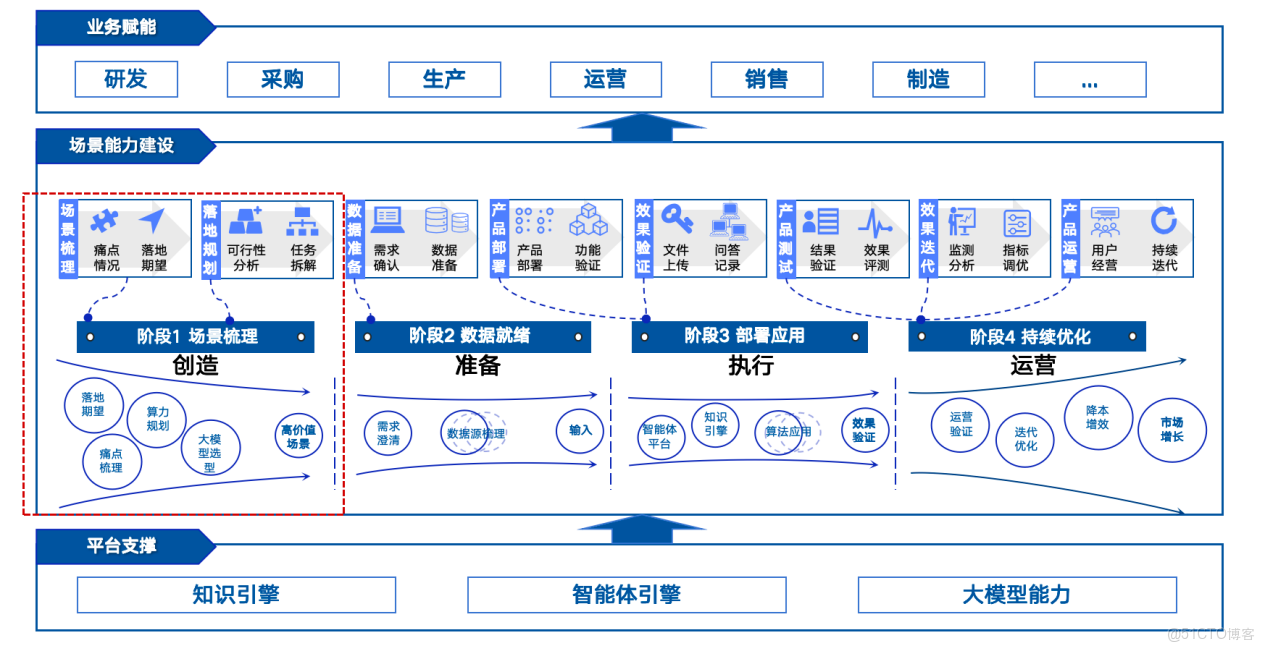
圖4:場景挖掘是大模型落地的重要步驟
【理流程】第四問:大模型落地流程是怎樣的?
場景選定後,我們來看實際落地的技術方案是怎樣的,根據落地實踐,推薦流程如下圖所示。
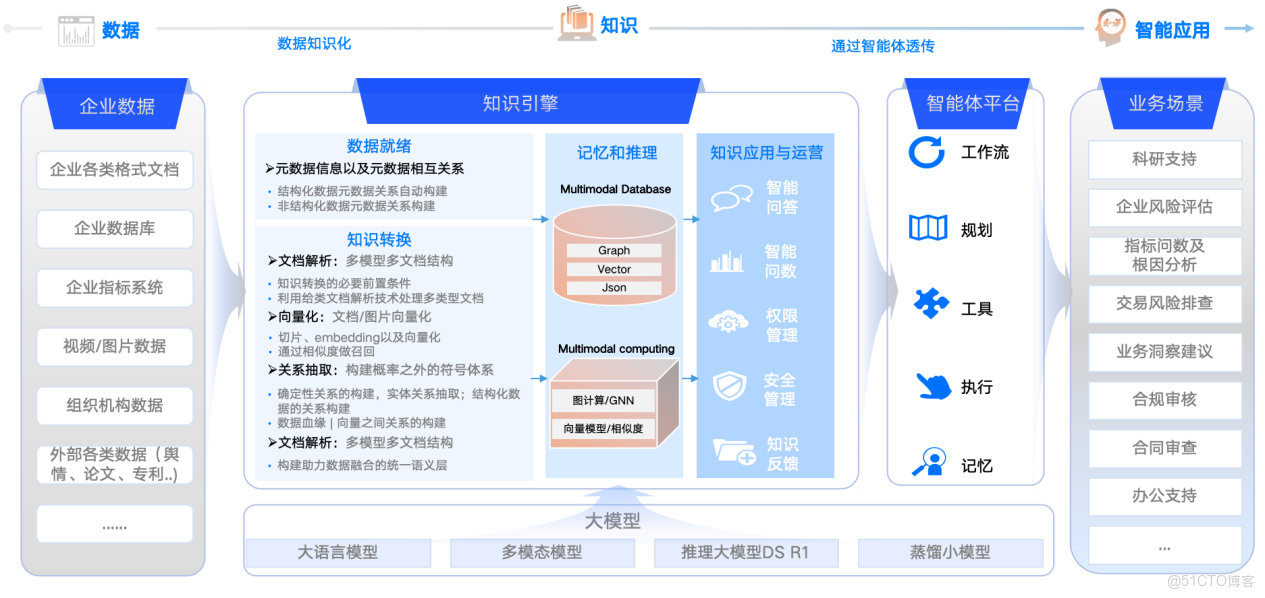
圖5:大模型落地流程
整個流程本質上是從數據到知識再到智能應用的轉化過程。輸入是企業內部的多模態源數據,包括企業內部存儲在關係型數據庫、指標系統裏的各類結構化數據、文檔/圖片/音頻/視頻等各類非結構化數據,以及外部的各類輿情/新聞報道/論文/專利等各類數據。而輸出則是賦能企業業務的場景應用。中間是核心處理流程,通過知識引擎對源數據的預處理、數據解析向量化、實體及關係抽取等技術將各種多模態數據轉換為知識,再存儲到圖和向量融合的多模態引擎中作為構建應用的知識儲備,包括以實現文檔問答、智能問數、圖譜應用等基礎知識應用。最終再結合具體業務流程,通過智能體平台串聯,結合知識應用,進而實現對於各個場景的支持。在整個落地流程中,結合客户的多模態數據,基於知識引擎和智能體平台進行落地,我們稱之為以數據為中心的大模型落地範式。
【看微調】第五問:需不需要微調大模型?
很多客户會關心,在上面的架構中都要調用大模型能力,那是否需要微調或者蒸餾大模型?
根據我們的經驗,大模型微調並非普適性選擇,而是有明確的適用邊界。如果企業在特定垂直領域不存在明確的專業訴求,並且自身尚未具備高質量、成體系的領域數據積累,盲目微調往往事倍功半。如果有垂直場景需求,數據為特定領域數據(通用大模型未將此領域知識內化為模型能力),在具有高質量數據集的同時也有領域大模型構建訴求,則可以嘗試領域垂類大模型。為清晰展示不同技術路線的差異與選型邏輯,我們通過下圖進行對比分析來描述各種技術路線的區別。從我們的實踐來講,以數據為中心的思路進行大模型落地,可以結合具體場景進行大模型微調,無需為了微調而微調,微調的基礎需要懂數據、有高質量數據。與此同時,微調是一項資源密集型的投入,它通常涉及高昂的計算成本和專業的技術實施,性價比也是重要決策依據。
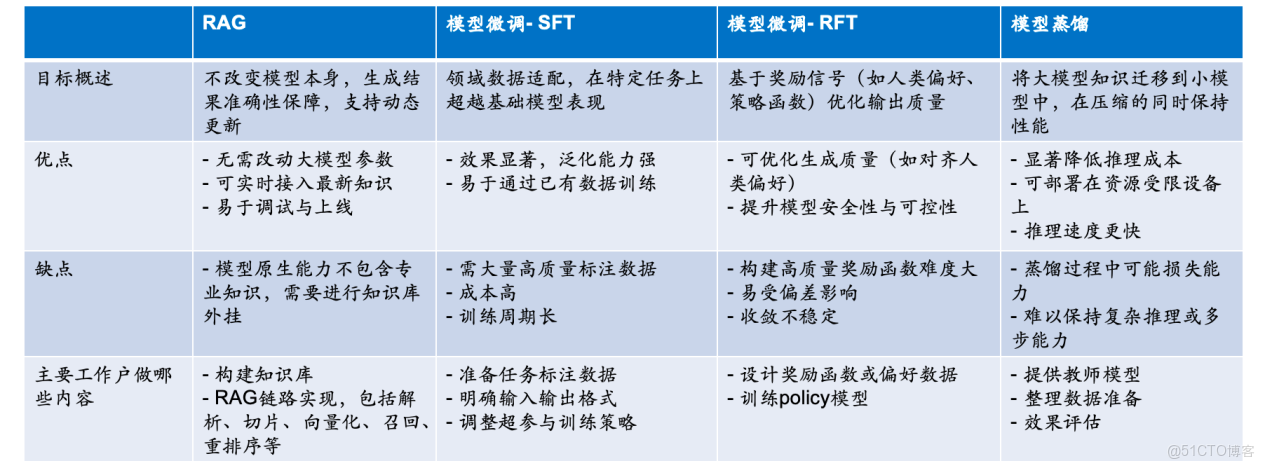
圖6:RAG與模型微調、模型蒸餾的比較
03運營迭代
【促優化】第六問:大模型項目是不是可以像傳統軟件項目一樣,先設定一個最終目標,僅依賴技術人員一次性調優就可交付?
從“找場景”到“理流程”便可看到,大模型落地從來不是一個僅依賴技術部門實現的項目,它需要業務部門和技術部門的共同參與,各司其職:
業務部門負責明確業務目標,對輸入進行明確整理,在項目實施過程中進行深度參與,例如,及時提供問題與答案列表、測試用例、在測試過程中反饋實現與業務訴求不相符的內容,輔助大模型落地效果評估與持續迭代。
數據部門是以數據為中心的落地應用效果的第一道防線,在楓清的指標問數實施過程中,數據質量、數據加工邏輯會嚴重影響AI問數應用的準確性,在優化的過程中排查到大量數據不一致的問題對實現效果構成阻礙。
技術部門則作為技術落地的執行人員,解決AI應用實施的技術問題,並提供應用使用的培訓以及持續運營的技術支持,包括但不限於對用户遇到的問題提供支持,甚至包括文件上傳、權限管理等操作問題。
綜合來看,在實際落地時,有三個重要影響因素:
1.業務價值是目標,所有的落地都是為業務服務的;在高價值場景挖掘中,就要挖掘和發現高價值的場景,進而讓大模型在高價值場景下發揮作用,具備高的業務價值;
2.數據是基礎,企業只有在數據質量滿足要求的情況下,才能有好的落地效果。比如在指標問答落地項目中,客户的指標體系以及指標內容就是好的落地效果的基礎,在實際落地過程中,可以反推數據質量,進而促進指標體系的標準化,從而保證落地效果。對於文檔落地也是類似情況,需要保證文檔的正確性。
3.技術是保障,需要了解大模型的技術邊界,也瞭解人工智能技術中其他技術點的技術邊界。在實際項目落地中,很難都用大模型來解決,有可能需要視覺模型、數據分析模型、多模態大模型等來解決,在這其中,需要了解清楚各個模型的邊界和上限,進而保證落地效果。
另外,從落地場景來説,會先從外圍逐步過渡到核心業務。會遵從敏捷迭代,先小步快跑快速驗證,再逐步推廣;需要從最開始就引入業務人員,確保共同定義目標,且及時同步進展,確保交付內容是業務想要的結果。
在場景落地後,也需要通過持續優化的方式來進行迭代和完善,不同部門協作,通過收集人工反饋,針對反饋進行場景調優、新增功能、功能解耦升級以及模型定製微調方式實現閉環反饋;同時隨着經驗的積累和能力提升,進而轉向智能自適應反饋機制,在運營中持續提升效果。
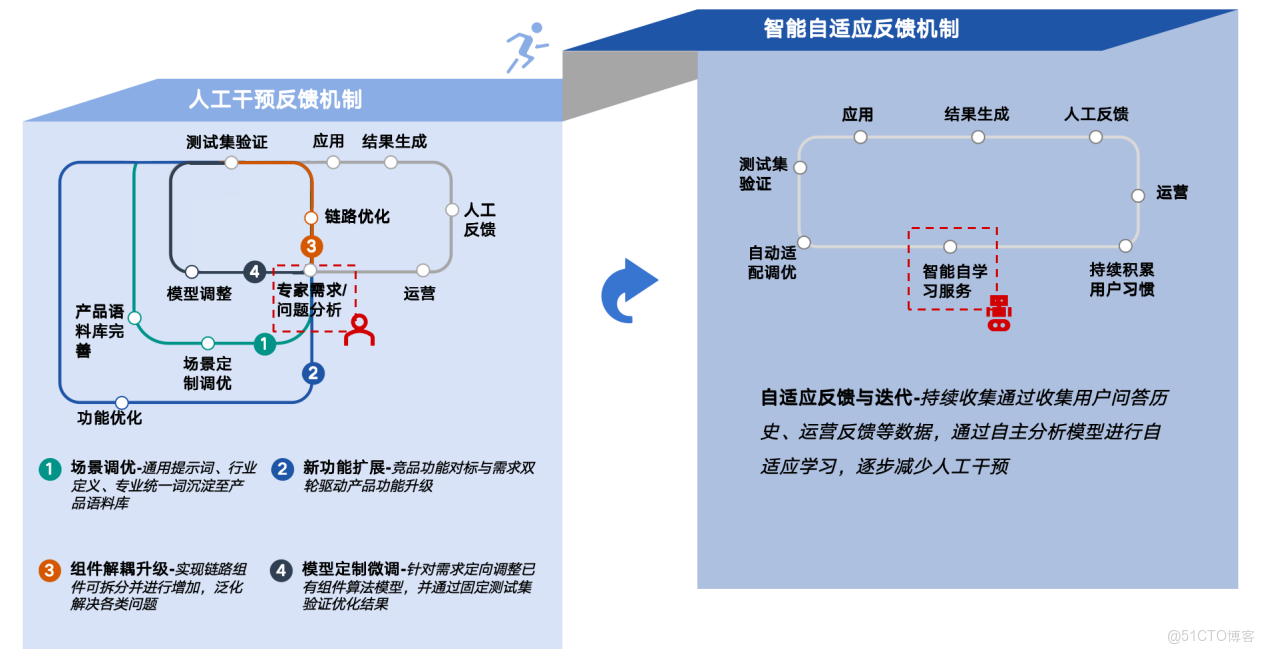
圖7:大模型持續迭代優化流程
以上是結合我們的實踐經驗,針對大模型落地過程中用户常見6類問題給出的回答。在後續系列中,我們將針對各個部分展開詳細介紹,涵蓋從場景挖掘、平台建設到各個場景落地提供最佳實踐分享,敬請期待。







