

原文作者:Elijah Zupancic of F5 和 Jason Schmidt of F5
原文鏈接:現代應用參考架構之 OpenTelemetry 集成進展報告
轉載來源:NGINX 官方網站
去年秋天我們在 Sprint 2.0 上介紹 NGINX 現代應用參考架構 (MARA) 項目時,就曾強調過這不是一個隨隨便便的架構,我們的初衷是打造一款“穩定可靠、經過測試且可以部署到在 Kubernetes 環境中運行的實時生產應用”的解決方案。對於這樣一個項目來説,可觀測性工具可以説是必不可少。MARA 團隊的所有成員都曾親身體驗過,缺乏狀態和性能洞察會讓應用開發和交付變得多麼困難。我們很快就達成了共識,即 MARA 必須添加可以在生產環境中進行調試和跟蹤的工具。
MARA 的另一項指導原則是首選開源解決方案。本文描述了我們對多功能開源可觀測性工具的追求是如何使我們將目光轉向 OpenTelemetry 的,然後詳細介紹了其中的利弊權衡和設計決策,以及採用了哪些技術將 OpenTelemetry 與使用 Python、Java 和 NGINX 構建的微服務應用相集成。
我們希望我們的經驗可以幫助您避開可能的陷阱,並加快您對 OpenTelemetry 的採用。請注意,本文是一份具有時效性的進展報告 —— 我們討論的技術預計將在一年內成熟。此外,儘管我們指出了某些項目當前的不足之處,但我們仍然對所有已經完成的開源工作深表感激,並期待它們未來取得更好的進展。
我們的應用
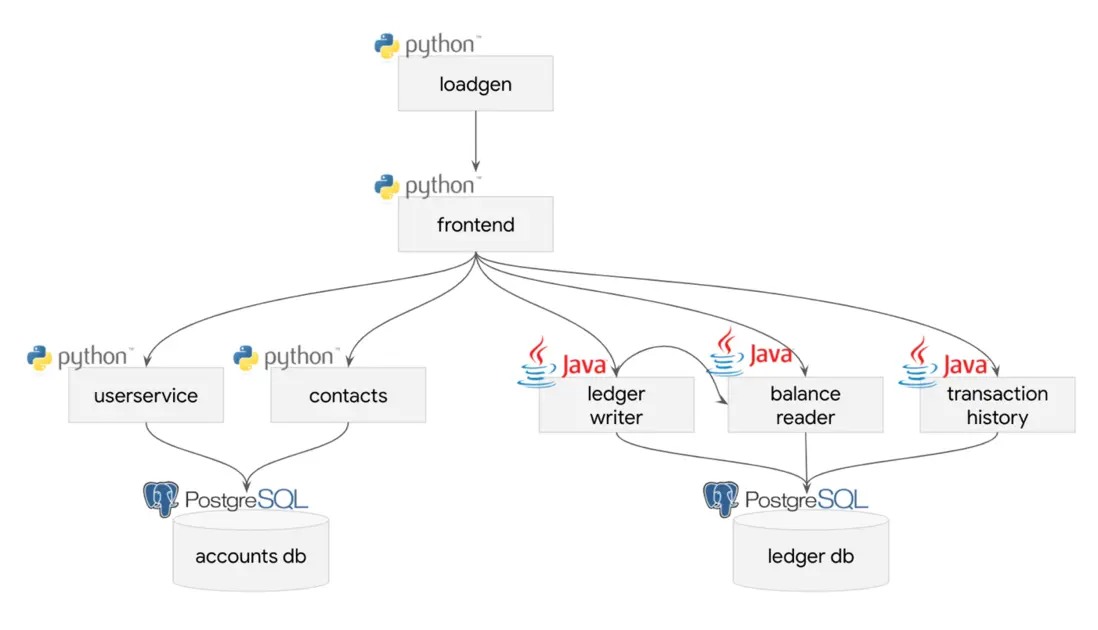
我們選擇了 Bank of Sirius 作為集成可觀測性解決方案的應用。Bank of Sirius 是我們從 Google 提供的 Bank of Anthos 示例應用引出的分支,是一個具有微服務架構的 Web 應用,可以通過基礎架構即代碼進行部署。雖然我們可以通過很多種方式來改進此應用的性能和可靠性,但它已經足夠成熟,可以被合理地認為是一種“棕地”應用。因此,我們認為這是一個展示如何將 OpenTelemetry 集成到應用中的好例子,因為理論上分佈式跟蹤可以生成有關應用架構缺點的寶貴洞察。
如圖所示,支持應用的 service 相對簡單。
我們是怎麼選擇了 OpenTelemetry
我們選擇 OpenTelemetry 的道路相當曲折,經歷了幾個階段。
創建功能清單
在評估可用的開源可觀測性工具之前,我們確定了哪些方面需要關注。根據過去的經驗,我們列出了以下清單。
- 日誌記錄 —— 顧名思義,這意味着從應用中生成經典的、以換行符分隔的消息集;Bank of Sirius 應用會以 Bunyan 格式構建日誌
- 分佈式跟蹤 —— 整個應用中每個組件的Timing和元數據,例如供應商提供的應用性能管理 (APM)
- 指標 —— 在一段時間內捕獲並以時間序列數據的形式繪製的測量值/li>
- 異常/錯誤聚合和通知 —— 一個聚合了最常見的異常和錯誤的集合,該集合必須是可搜索的,以便我們可以確定哪些應用錯誤是最常見的錯誤
- 健康檢查 —— 發送給 service 的定期探針,用於確定它們是否在應用中正常運行
- 運行時狀態自檢 —— 一組僅對管理員可見的 API,可以返回有關應用運行時狀態的信息
- 堆轉儲/核心轉儲 —— service運行時狀態的綜合快照;考慮到我們的目的,很重要的一點就是看在需要時或在 service 崩潰時獲取這些堆轉儲的難易程度
對照功能清單比較工具功能
當然,我們並不指望一個開源工具或一種方法就能搞定所有功能,但至少它為我們提供了一個比較可用工具的理想依據。我們查閲了每個工具的文檔,確定了各個工具可支持七項功能清單中的哪些功能。下表對我們的發現進行了總結。
| 技術 | 日誌記錄 | 分佈式跟蹤 | 指標 | 錯誤聚合 | 健康檢查 | 運行時自檢 | 堆/核心轉儲 |
|---|---|---|---|---|---|---|---|
| ELK + Elastic APM | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| Grafana | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| Graylog | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Jaeger | ❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
| OpenCensus | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| OpenTelemetry | Beta | ✅ | ✅ | ✅ | ✅* | ❌ | ❌ |
| Prometheus | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| StatsD | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| Zipkin | ❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
*作為一項擴展功能
做完這張表格後,我們突然意識到一個問題。各個工具的功能和預期用途差別很大,我們根本不能將它們歸為一類,這樣的比較可以説是驢唇不對馬嘴!
舉例來説,ELK(Elasticsearch-Logstash-Kibana,再加上 Filebeat)和 Zipkin 的作用具有根本性的不同,兩相比較只會讓人摸不着頭腦。遺憾的是,為了響應用户請求,有些工具無疑還會添加一些次要的功能,從而與其他工具產生功能上的重疊,這就是臭名昭著的“任務蔓延”問題。從表面上看,ELK 主攻日誌存儲和可視化,Zipkin 擅長分佈式跟蹤。但如果您稍微深入研究一下 Elastic 產品組合,您很快就會發現其中的 Elastic APM 也支持分佈式跟蹤,甚至兼容 Jaeger。
除了任務蔓延的問題外,許多工具還可以相互集成,從而產生各種不同的收集器、聚合器、儀表板等功能組合。有些技術相互兼容,有些則不兼容。
執行定性調查
綜上所述,這個比較表格無法幫助我們足夠準確地做出選擇。考慮到一個項目的價值觀與我們的價值觀越相似,我們就越有可能在一段時間內保持兼容,我們決定對每個項目的目標、指導原則和可能的未來方向進行定性調查。訪問 OpenCensus 頁面時,我們一眼就發現了這段話。
OpenCensus 和 OpenTracing 合併形成了 OpenTelemetry,以作為 OpenCensus 和 OpenTracing 的下一個主版本。OpenTelemetry 將向後兼容現有的 OpenCensus 集成,我們將在未來兩年內繼續為現有 OpenCensus 庫打安全補丁。
這條信息對我們來説很關鍵。我們知道我們無法保證我們的選擇一定會經得起未來考驗,但我們至少要知道未來它是否有堅實的社區支持。有了這些信息,我們就可以將 OpenCensus 從候選名單中剔除了。使用 Jaeger 可能也不是一個好主意,因為它是現已正式棄用的 OpenTracing 項目的參考實現 — 大部分新貢獻將落在 OpenTelemetry 上。
然後我們查閲了 OpenTelemetry Collector 的網頁。
OpenTelemetry Collector 針對如何接收、處理和導出遙測數據提供了的實現,並且不受供應商的限制。此外,它無需運行、操作和維護多個代理/收集器,即可支持將開源遙測數據格式(例如 Jaeger、Prometheus 等)發送到多個開源或商用後台系統。
OpenTelemetry Collector 充當聚合器,允許我們使用不同的後端來混搭不同的可觀測性收集和檢測方法。簡單來説,我們的應用可以使用 Zipkin 收集跟蹤信息、使用 Prometheus 獲取指標,這些信息都可以被髮送到可配置的後端,然後我們再使用 Grafana 對其進行可視化。這種設計的其他一些排列組合也是可行的,因此我們可以多嘗試幾種方法,看看究竟哪些技術適合我們的用例。
選定 OpenTelemetry 集成作為前進方向
我們最終將目光落在了 OpenTelemetry Collector 上,因為理論上它允許我們切換不同的可觀測性技術。儘管該項目相對不那麼成熟,但我們決定大膽一試,使用僅具有開源集成的 OpenTelemetry——畢竟東西好不好,用了才知道。
但是,OpenTelemetry Collector 還是缺少一些功能,我們必須添加其他技術來填補這些缺口。以下小節總結了我們的選擇及其背後的原因。
- 實施日誌記錄
- 實施分佈式跟蹤
- 實施指標收集
- 實施錯誤聚合
- 實施健康檢查和運行時自檢
- 實施堆轉儲和核心轉儲
實施日誌記錄
在選擇可觀測性工具時,日誌記錄這一要素看似簡單,實則並不好抉擇。説它簡單,是因為您只需從容器中獲取日誌輸出即可;説它複雜,是因為您需要決定將數據存儲在哪裏、如何將其傳輸到該存儲庫、如何進行索引才能使其發揮效用,以及這些數據需要保留多長時間。只有支持根據足夠多的不同標準(以滿足不同搜索者的需求)輕鬆進行搜索,日誌文件才能發揮效用。
我們研究了 OpenTelemetry Collector 的日誌記錄支持,在撰寫本文時它還處於 Beta 測試階段。我們決定短期內使用 ELK 進行日誌記錄,同時繼續調查其他選擇。
在沒有更好的選擇之前,我們默認使用 Elasticsearch 工具,以便將部署分為ingest、coordinating、master 和 data 節點。為了便於部署,我們使用了 Bitnami 圖表。為了傳輸數據,我們將 Filebeat 部署到 Kubernetes DaemonSet 中。通過部署 Kibana 並利用預加載的索引、搜索、可視化和儀表盤,我們輕鬆添加了搜索功能。
很快我們便發現,儘管這個解決方案可行,但其默認配置非常耗費資源,因此很難在 K3S 或 Microk8s 等資源佔用較小的環境中運行。雖然我們通過調整每個組件的副本數量解決了上述問題,但卻出現了一些故障,這些故障可能是由於資源耗盡或數據量過多所致。
我們並未因此氣餒,而是將藉機對採用不同配置的日誌記錄系統進行基準測試,並研究其他選項,如 Grafana Loki 和 Graylog。我們很可能會發現輕量級的日誌記錄解決方案無法提供某些用户需要的全套功能,而這些功能可能為資源密集型工具所提供。鑑於 MARA 的模塊化特性,我們可能會為這些選項構建額外的模塊,從而為用户提供更多的選擇。
實施分佈式跟蹤
除了需要確定哪種工具可提供我們所需的跟蹤功能之外,我們還需考慮解決方案的實施方式以及需要與之集成的技術。
首先,我們希望確保任何工具都不會影響應用本身的服務質量。我們都有過這樣的經歷:在導出日誌時,系統性能每小時就會下降一次,因此我們不想再重蹈覆轍。在這方面,OpenTelemetry Collector 的架構引人注目,因為它支持您在每個主機上運行一個實例。每個收集器從主機上運行的所有不同應用(容器化或其他類型)中的客户端和代理中接收數據。收集器會整合,並(可能)會壓縮這些數據,然後將其發送到存儲後端。這聽起來棒極了。
接下來,我們評估了應用中所用的不同編程語言和框架對 OpenTelemetry 的支持。此時,事情變得有點棘手。儘管我們只使用了兩種編程語言和相關框架(如下表所示),但複雜程度之高令人咂舌。
| 語言 | 框架 | service數量 |
|---|---|---|
| Java | Spring Boot | 3 |
| Python | Flask | 3 |
為了添加語言級跟蹤,我們首先嚐試了 OpenTelemetry 的自動檢測代理,但卻發現其輸出數據混亂不堪。我們相信,隨着自動檢測庫的日趨成熟,這種情況會有所改善。但目前我們不考慮 OpenTelemetry 代理,並決定將跟蹤語句加入我們的代碼。
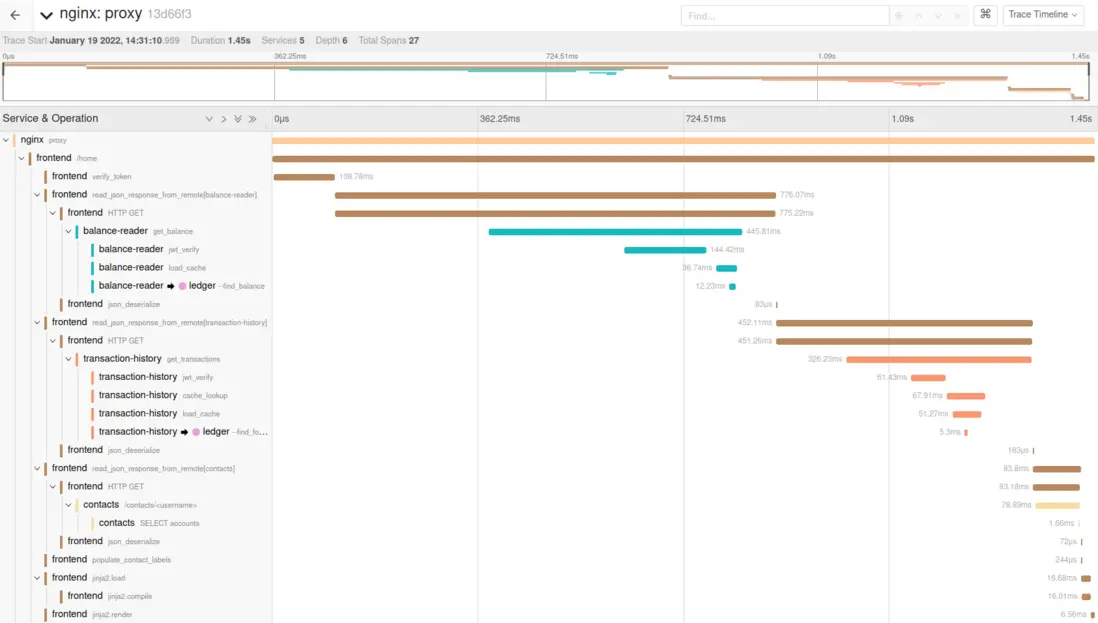
在開始在代碼中直接實現跟蹤之前,我們首先連接了 OpenTelemetry Collector,以便將所有跟蹤數據輸出到本地運行的 Jaeger 實例,從而更輕鬆地從中查看輸出結果。這樣做有很大幫助,因為當我們瞭解如何全面集成 OpenTelemetry 時,便可使用跟蹤數據的可視圖像。例如,如果在調用從屬服務時發現 HTTP 客户端庫不含跟蹤數據,我們可以立即將該問題添加到修復列表中。Jaeger 在單個跟蹤中清晰呈現了所有不同跨度:
Python 分佈式跟蹤
在我們的 Python 代碼中添加跟蹤語句相對來説比較簡單。我們添加了兩個我們所有 service 都引用的 Python 源文件,並更新了各自的 requirements.txt 文件,以添加相關的 opentelemetry-instrumentation-* 依賴項。這意味着我們不僅可以對所有 Python 服務使用相同的跟蹤配置,而且還能夠將每個請求的跟蹤 ID 添加到日誌消息中,並將跟蹤 ID 嵌入從屬 service 的請求。
Java 分佈式跟蹤
接下來,我們將視線轉向 Java 服務。在“綠地”項目中直接使用 OpenTelemetry Java 庫相對簡單 —— 您只需導入必要的庫並直接使用跟蹤 API 即可。但是,如果您也和我們一樣使用 Spring,則需做出其他決定。
Spring 已有一個分佈式跟蹤 API —— Spring Cloud Sleuth。它為底層分佈式跟蹤實現提供了一個 façade,並具有以下功能(如文檔中所述):
- 將跟蹤和跨度 ID 添加到 Slf4J MDC,以便從日誌聚合器中的給定跟蹤或跨度中提取所有日誌。
- 檢測 Spring 應用的通用進出點(servlet filter、rest template、scheduled actions、message channels、feign client)。
- 如果 spring-cloud-sleuth-zipkin 可用,……,則通過 HTTP (生成並報告)兼容 Zipkin 格式的跟蹤數據。默認情況下,它將這些數據發送到 localhost(端口 9411)上的 Zipkin 收集器服務。您可使用 spring.zipkin.baseUrl 配置服務的位置。
此外,該 API 還支持我們將跟蹤數據添加到 @Scheduled 註解的任務。
換句話説,我們只使用 Spring Cloud Sleuth 便可從一開始就獲得 HTTP 服務端點級的跟蹤數據 —— 這堪稱一大優勢。由於我們的項目使用了 Spring,因此我們決定全面擁抱該框架並利用其所提供的功能。但在使用 Maven 將這一切連接在一起時,我們發現了一些問題:
- Spring Cloud Sleuth Autoconfigure 模塊仍然處於里程碑版本。
- Spring Cloud Sleuth Autoconfigure 模塊依賴於過時的內測版opentelemetry-instrumentation-api。該庫目前沒有最新的非內測 1.x 版本。
- 鑑於 Spring Cloud Sleuth 為里程碑版本編碼其依賴項引用的方式,該項目必須從 Spring Snapshot 存儲庫中拉取父項目對象模型 (POM)spring-cloud-build。
我們的 Maven 項目定義因此變得有些複雜,因為我們必須從 Spring 存儲庫和 Maven Central 中拉取 Maven(這充分表明 Spring Cloud 很早便提供了 OpenTelemetry 支持)。儘管如此,我們仍持續推進,創建了一個通用遙測模塊,以使用 Spring Cloud Sleuth 和 OpenTelemetry 配置分佈式跟蹤,並開發了多種遙測相關的輔助功能和擴展功能。
在通用遙測模塊中,我們通過提供以下特性擴展了 Spring Cloud Sleuth 和 OpenTelemetry 庫的跟蹤功能:
- 支持 Spring 的自動配置類,為項目設置跟蹤和擴展功能,並加載其他跟蹤資源屬性。
- NoOp 接口實現,這樣我們可以將 NoOp 實例注入所有 Spring Cloud Sleuth 接口,以便在啓動時禁用跟蹤。
- 跟蹤命名攔截器,用於規範跟蹤名稱。
- 通過 slf4j 和 Spring Cloud Sleuth 跟蹤輸出錯誤的錯誤處理程序。
- 跟蹤屬性的增強實現,它將附加信息編碼到每個發出的跟蹤中,包括 service 的版本、service 實例的 ID、機器 ID、pod 名稱、容器 ID、容器名稱和命名空間名稱。
- 跟蹤語句檢查器,它將跟蹤 ID 注入 Hibernate 發出的 SQL 語句之前的註釋中。顯然,這項工作現在可以使用 SQLCommenter 完成,但我們尚未進行遷移。
此外,依託於 Apache HTTP 客户端,我們還實現了兼容 Spring 的 HTTP 客户端,因為我們希望在 service 之間進行 HTTP 調用時獲得更多的指標和更高的可定製性。在此實現中,當調用從屬服務時,跟蹤和跨度標識符將作為 HTTP 請求頭傳入,以包含在跟蹤輸出中。此外,這一實現提供了由 OpenTelemetry 聚合的 HTTP 連接池指標。
總而言之,使用 Spring Cloud Sleuth 和 OpenTelemetry 進行跟蹤是一段艱難的歷程,但我們相信一切都值得。希望本項目以及本文能夠為做出這一選擇的人們照亮前路。
NGINX 分佈式跟蹤
為了在請求的整個生命週期中獲取連接所有 service 的跟蹤信息,我們需要將 OpenTelemetry 集成到 NGINX 中。為此,我們使用了 OpenTelemetry NGINX 模塊(仍處於beta測試階段)。考慮到可能很難獲得適用於所有 NGINX 版本的模塊的工作二進制文件,因此我們創建了一個容器鏡像的 GitHub 代碼倉庫,其中包含不受支持的 NGINX 模塊。我們運行夜間構建,並通過易於從中導入的 Docker 鏡像分發模塊二進制文件。
我們尚未將此流程整合到 MARA 項目的 NGINX Ingress Controller 的構建流程中,但計劃儘快實施。
實施指標收集
完成 OpenTelemetry 跟蹤集成後,接下來我們將重點放在指標上。當時,我們基於 Python 的應用沒有現成指標,於是我們決定暫時推遲添加相關指標。對於 Java 應用,原始的 Bank of Anthos 源代碼(結合使用 Micrometer與 Google Cloud 的 Stackdriver)為指標提供了支持。但我們從 Bank of Sirius 中刪除了該代碼,原因是它不支持配置指標後端。儘管如此,指標鈎子的存在説明需要進行適當的指標集成。
為了制定一個實用的可配置解決方案,我們首先研究了 OpenTelemetry Java 庫和 Micrometer 中的指標支持。我們搜索了這兩種技術之間的比較,許多搜索結果都列舉了 OpenTelemetry 在 JVM 中用作指標 API 的缺陷,儘管在撰寫本文時 OpenTelemetry 指標仍處於內測階段。Micrometer 是一個成熟的 JVM 指標門面層,類似於 slf4j,提供了一個通用 API 包裝器,對接可配置的指標實現,而非自身指標實現。有趣的是,它是 Spring 的默認指標 API。
這時,我們對以下實際情況進行了權衡:
- OpenTelemetry Collector 可以使用幾乎任何來源的指標,包括 Prometheus、StatsD和原生OpenTelemetry Protocol (OTLP)
- Micrometer 支持大量的指標後端,包括 Prometheus 和 StatsD
- 面向 JVM 的 OpenTelemetry Metrics SDK 支持通過 OTLP 發送指標
經過幾次試驗後,我們確定,最實用的方法是搭配使用 Micrometer Façade 和 Prometheus 支持實現,並配置 OpenTelemetry Collector 從而可以使用 Prometheus API 從應用中提取指標。許多文章都曾介紹過,OpenTelemetry 中缺少指標類型可能會導致一些問題,但我們的用例無需這些指標類型,因此可以在這點上讓步。
我們發現 OpenTelemetry Collector 有趣的一點是:即使我們已將其配置為通過 OTLP 接收跟蹤數據和通過 Prometheus API 接收指標,它仍然可以配置為使用 OTLP 或任何其他支持協議將這兩種類型的數據發送到外部數據接收器。這有助於我們輕鬆地使用 LightStep 來試用我們的應用。
總體而言,使用 Java 編寫指標非常簡單,因為我們按照 Micrometer API 標準進行編寫,後者有大量示例和教程可供參考。對於指標和跟蹤而言,最困難之處可能是恰好在面向 telemetry-common 指標的 pom.xml 文件中獲取 Maven 依賴關係圖。
實施 error 聚合
OpenTelemetry 項目本身的任務中不包含 error 聚合,而且它所提供的 error 標記實現也不像 Sentry 或 Honeybadger.io 等解決方案那樣簡潔。儘管如此,我們還是決定在短期內使用 OpenTelemetry 進行 error 聚合,而非添加其他工具。藉助 Jaeger 之類的工具,我們可以搜索 error=true,以找到所有帶有 error 條件的跟蹤。這至少能夠讓我們瞭解常見問題之所在。未來,我們可能會考慮添加 Sentry 集成。
實施健康檢查和運行時自檢
在我們應用的上下文中,通過健康檢查,Kubernetes 能夠知道 service 是否健康或是否已完成啓動階段。如果 service 不健康,則可將 Kubernetes 配置為終止或重啓實例。因為我們發現文檔資料的欠缺,我們決定不在我們的應用中使用 OpenTelemetry 健康檢查。
而在 JVM 服務中,我們使用了名為 Spring Boot Actuator 的 Spring 項目,它不僅提供健康檢查端點,而且還提供運行時自檢和堆轉儲端點。在 Python 服務中,我們使用 Flask Management Endpoints 模塊,該模塊提供了 Spring Boot Actuator 功能的子集。目前,它只提供可定製的應用信息和健康檢查。
Spring Boot Actuator 可接入 JVM 和 Spring,以提供自檢、監控和健康檢查端點。此外,它還提供了一個框架,用於將自定義信息添加到其端點上呈現的默認數據中。端點可提供對緩存狀態、運行時環境、數據庫遷移、健康檢查、可定製應用信息、指標、週期作業、HTTP 會話狀態和線程轉儲等要素的運行時自檢。
Spring Boot Actuator 實現的健康檢查端點採用了模塊化配置,因此 service 的健康狀況將包括多個單獨的檢查(分成“存活”、“就緒”等類別)。此外,它還提供了顯示所有檢查模塊的完整健康檢查。
信息端點在 JSON 文檔中被定義為單個高級 JSON 對象和一系列分級密鑰和值。通常,文檔會指定 service 名稱和版本、架構、主機名、操作系統信息、進程 ID、可執行文件名稱以及有關主機的詳細信息,例如機器 ID 或唯一 service ID。
實施堆轉儲和核心轉儲
您可能還記得上述“對照功能清單比較工具功能”部分的表格,其中沒有一個工具支持運行時自檢或堆轉儲/核心轉儲。但作為我們的底層框架,Spring 提供了對二者的支持 —— 儘管將可觀測性功能添加到應用中需要花一些功夫。如上一節所述,在運行時自檢中,我們結合使用了 Python 模塊與 Spring Boot Actuator。
同樣,在堆轉儲中,我們使用了 Spring Boot Actuator 提供的線程轉儲端點來實現所需功能的子集。我們無法按需獲得核心轉儲,也無法以理想的細粒度級別獲得 JVM 的堆轉儲,但我們可以輕鬆地獲得一些所需的功能。然而,Python 服務的核心轉儲將需要開展大量額外工作,這有待在後期進行。
總結
在反覆嘗試和比較之後,我們最終選擇使用以下技術來實現 MARA 的可觀測性(在下文中,OTEL 代表 OpenTelemetry):
- 日誌記錄 (適用於所有容器) – Filebeat → Elasticsearch / Kibana
-
分佈式跟蹤
- Java – Spring Cloud Sleuth → 用於 OTEL 的 Spring Cloud Sleuth 導出器 → OTEL Collector → 可插式導出器,如 Jaeger、Lightstep、Splunk 等。
- Python – OTEL Python 庫 → OTEL Collector → 可插式存儲
- NGINX 和 NGINX Plus (尚不支持 NGINX Ingress Controller) – NGINX OTEL 模塊 → OTEL Collector → 可插式導出器
-
指標收集
- Java – Micrometer(通過 Spring) → Prometheus 導出器 → OTEL Collector
- Python – 尚未實現
- Python WSGI – GUnicorn StatsD → Prometheus (通過 StatsD/ServiceMonitor)
- NGINX – Prometheus 端點 → Prometheus (通過 ServiceMonitor)
- 錯誤聚合 – OTEL 分佈式跟蹤 → 可插式導出器 → 導出器的搜索功能,用於查找標明 error 的跟蹤
-
健康檢查
- Java – Spring Boot Actuator → Kubernetes
- Python – Flask Management Endpoints 模塊 → Kubernetes
-
運行時自檢
- Java – Spring Boot Actuator
- Python – Flask Management Endpoints 模塊
-
堆/核心存儲
- Java – Spring Boot Actuator 支持線程轉儲
- Python – 尚不支持
此實現只是當前進展情況,必將隨着技術的發展而演進。不久之後,我們將通過廣泛的負載測試來運行應用。我們希望全面瞭解可觀測性方法的不足之處並添加更多可觀測性功能。
歡迎親自試用現代應用參考架構和示例應用 (Bank of Sirius)。如果您對幫助我們改進服務有任何想法,歡迎您在我們的 GitHub 倉庫中建言獻策!
更多資源
想要更及時全面地獲取 NGINX 相關的技術乾貨、互動問答、系列課程、活動資源?
請前往 NGINX 開源社區:
- 官網:https://www.nginx.org.cn/
- 微信公眾號:https://mp.weixin.qq.com/s/XV...
- 微信羣:https://www.nginx.org.cn/stat...
- B 站:https://space.bilibili.com/62...



