

Transformer 的核心範式一直是“Next Token Prediction”——像接龍一樣,一個詞一個詞地往後蹦。雖然 OpenAI o1 和 DeepSeek-R1 通過 Chain of Thought (CoT) 開啓了“慢思考”時代,但其本質依然是通過生成更多的顯性 Token 來換取計算時間。
這就帶來了一個巨大的效率悖論:為了想得深,必須説得多。這一章我們看四篇極具代表性的論文(Huginn, COCONUT, TRM, TiDAR),它們不約而同地試圖打破這一侷限:能否在不輸出廢話的情況下,讓模型在內部“空轉”思考? 甚至打破自迴歸的束縛,進行全局規劃?
Hugin:內生循環思考提升深度
- Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
這篇論文的核心在於打破大模型推理時計算量恆定的限制,提出了一種在“深度”上進行循環的架構,從而實現了在隱空間(Latent Space)進行遞歸推理。
🚨 核心痛點:固定計算圖與動態難度的矛盾
傳統的 LLM 一旦訓練完成,其層數(Depth)是固定的。這意味着無論輸入是簡單的“1+1”還是複雜的數學證明,模型在生成每一個 Token 時消耗的 FLOPs是一樣的 。這顯然不符合直覺——難題應該需要更多的“思考時間”。因此我們有了COT和現在的Reasoning模式。
- 現狀:為了處理難題,現在的 CoT 策略不得不強迫模型“自言自語”生成大量 Token,這導致了顯存(KV Cache)的爆炸式增長和推理速度的線性下降。
- 目標:能否讓模型在內部“停下來想一會兒”,但不佔用輸出帶寬?
🛠️解決方案:循環深度架構
Huginn 提出了一種特殊的架構設計,試圖在 Transformer 中原生實現“慢思考”。

如上圖,模型包括三個部分
- (P)Prelude: 相當於Encoder層,負責將 Input Token 映射為隱狀態。
- (R)recurrent block: 這是一個多層Transformer Layer,所有的思考都發生在這裏,但是和傳統Transformer不同的點在於,這個模塊可以循環運行任意次。
- (C)Coda:相當於輸出頭,對思考完成的隱狀態進行token解碼生成。
這本質上是“層參數共享”的極致應用。 模型通過動態決定 R 模塊循環的次數,實現了在參數量不變的情況下,動態調整推理時的計算深度。為了防止深層循環導致的梯度消失或遺忘,模型在每一步循環都會注入原始輸入的 Embedding,起到錨點(Anchor)的作用。
💡 深度洞察
-
高效推理:遞歸模塊不產生線性增長的KV-Cache,只是不斷更新遞歸參數
-
難度自適應:可以通過控制遞歸的輪數來對不同難度的問題實現自適應計算,不需要對所有難度的問題進行統一的思考或者不思考
-
Test Time Scaling:論文發現遞歸的模式同樣存在Test-time scaling,更多的遞歸次數會帶來持續的表現提升。
COCONUT:拋棄語言,用“直覺”思考
- Meta: Training Large Language Models to Reason in a
Continuous Latent Space
如果説 Huginn 是在架構層面“摺疊”了深度,那麼 COCONUT則是在思維載體上進行了一次革命。它質疑了大模型推理的一個基本假設:為什麼思考的過程必須用人類語言(Tokens)來表達?
🚨核心痛點:語言空間的侷限性
由OpenAI-O1拉開序幕的Reasoning時代,當前的推理過程一般是
:Hidden State \(\rightarrow\) Logits \(\rightarrow\) Sampling (Token) \(\rightarrow\) Embedding \(\rightarrow\) Next Input。
這就引入了一些侷限性
- 信息丟失:將高維連續的 Hidden State 坍縮為離散的 Token,會丟失大量非結構化的“直覺”信息。就像你腦海裏有大量信息,卻必須用一句話説出來。
- 效率低下:當CoT 中充斥着 "Let's think step by step", "Therefore" 等無意義的連接詞。
- 線性約束:語言是線性的,但思維往往是發散的、網狀的。之前很多parrallel思考的方案都是為了打破這個約束。
🛠️解決方案:連續思維鏈
COCONUT 提出了一種Latent Mode。雖然架構仍基於 Transformer,但它改變了數據流轉方式:
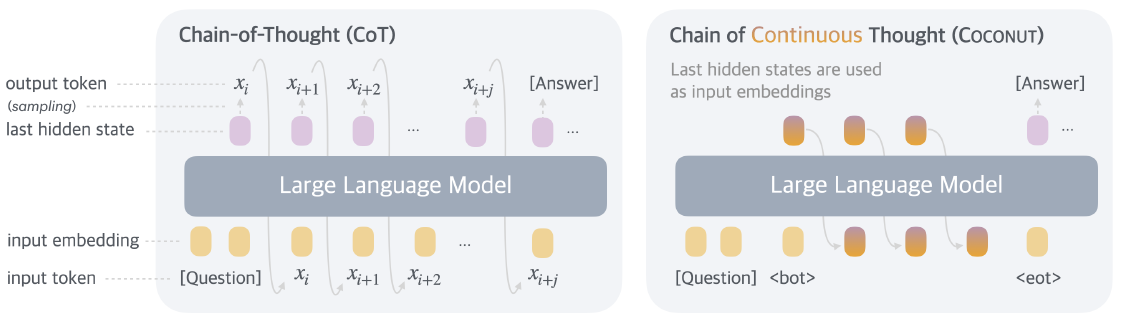
- 推理模式:Latent Mode (隱模式)
Coconut 引入了一種新的推理模式。模型可以在Language Mode和Latent Mode之間切換。
機制:當模型進入Latent Mode後(輸出<bot>特殊字符),它不再將 Last Hidden State 解碼為 Token。而是直接將這個 Hidden State 作為下一步的 Input Embedding 餵給模型。
這就像是模型在“自言自語”,但是用只有它自己聽得懂的“腦電波”(向量)在交流,而不是用人類語言。這種“連續思維”一直持續到模型輸出<eot>特殊字符,然後再切回語言模式輸出最終答案。
- 訓練策略:多階段課程學習
為了讓模型學會使用上述的思考向量信息,論文使用了漸進式的訓練方案,如下圖

- Stage 0:先用標準的 CoT 數據訓練模型,讓它學會邏輯。
- Stage 1 ~ k:逐步“擦除”CoT 中的文本。
- 例如,在 Stage 1,把 CoT 的第 1 步推理文本去掉,替換為 \(c\) 個 Continuous Thoughts(隱向量)。模型必須學會用這 \(c\) 個向量來承載原本那句話的邏輯信息
- 隨着訓練進行,逐步把更多的文本推理步驟替換為隱向量。
- 最終形態:所有的中間推理文本都被“內化”成了連續的隱向量,模型只輸出最終答案。
💡 深度洞察
- 核心能力涌現:隱式 BFS (Implicit Breadth-First Search)
這是最精彩的發現。相比原有COT是線性的,同一時刻只能推理一個思路。但COconut因為Hidden State是高維連續向量,所以它可以處於“疊加態”,可以同時編碼多個可能的推理路徑。隱式進行了廣度搜索。
- 推理效率提升
雖然和Hugin相比依舊需要使用KV-cache,但因為連續向量的數量往往顯著小於token數,所以推理效率會有提升,同時也因為省略了推理token採樣的步驟,而進一步提升吞吐。
- 超越人了語言思維密度
尤其對於一些複雜多路徑規劃任務,以及部分需要look ahead推理的任務,因為隱向量比token包含廣度更大的思考信息,因此效果有所提升。
看到這裏我也有個想法,邏輯上hidden thought一定會比token攜帶更多的信息量,但最大的問題就是無法可視化,那能否想一會,説兩句,想一會説兩句,也就是把hidden thought和token reasoning通過interleave串聯起來?
TRM: 像改代碼一樣迭代推理
- Less is More: Recursive Reasoning with Tiny Networks
TRM和前面的Hugin是非常相似的,幾乎都是走的“循環思維載體”的思路。但是TRM多了雙流遞歸的設計,把循環過程中的草稿和打磨這兩個不同信息拆分開處理。
和COCONUT也有相似之處,只不過COCONUT更像是潛意識在時間軸上(自迴歸推理)的延伸,而TRM是在質量軸上的不斷迭代修正。
🚨 核心痛點:自迴歸的“落子無悔”
Reasoning最大的問題,就是前面COCONUT提到的“落子無悔”問題,想要進一步反思或者修正,就需要繼續顯性延伸你的思考鏈路進行反思。
論文的目標:能否構建一個模型,它的推理過程不是“生成下一個詞”,而是不斷修正當前的答案?這需要模型具備迭代修正的能力。
🛠️ 解決方案:TRM (Tiny Recursive Model)
TRM 的架構設計非常精簡,它直接回到了最本質的遞歸結構,如下圖
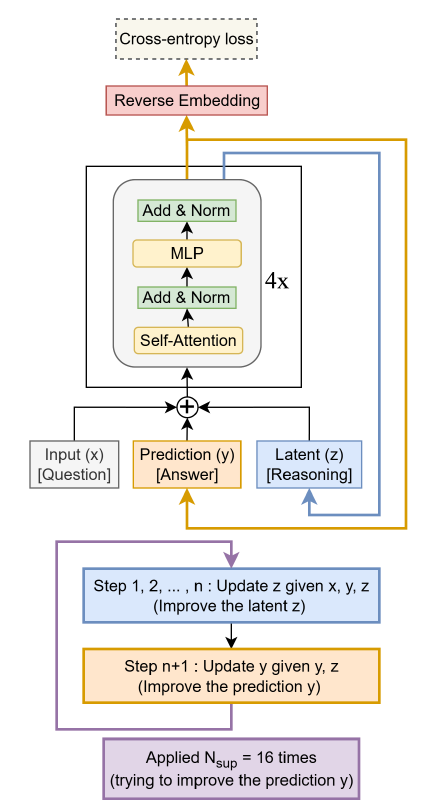
- 雙流遞歸狀態
TRM 維護兩個核心狀態,並在循環中不斷更新它們 :
- Latent (Z):推理狀態。這和Huginn多步遞歸循環的R Block類似,都是思維的載體,存儲不斷更新的思維上下文。
- Prediction (Y):當前答案的草稿。這是 TRM 最獨特的地方。它把“當前的預測結果”Embedding 之後,作為下一輪的輸入餵給自己。(對比Hugin所有信息都在R,TRM把已經形成的預測結果解耦出來了)
推理循環邏輯 (The Loop):
這就像我們寫代碼:先寫個大概 (\(y_0\)) -> 腦子轉一下 (\(z_1\)) -> 改一行代碼 (\(y_1\)) -> 發現有個 Bug (\(z_2\)) -> 再改一行 (\(y_2\))。
- 架構極簡主義
- Tiny Network:模型只有 2 層 Transformer Layer,參數量僅 5M - 7M
- 參數共享:同一個網絡(Net)在每一次循環中被反覆使用
- 全量推理模式:並非自迴歸模型token by token的推理,而是每一步循環都生成全量的Y,並且每一步都對全量的Y進行修正
💡 深度洞察
- 全量生成的思維轉換:TRM 的生成方式更像 Diffusion Model(擴散模型),是從模糊到清晰的過程,而不是從左到右的過程。但這同樣也約束了當前TRM只能用於固定長度內容的輸出。
- Deep Supervision:訓練時,TRM 並不只在最後一步計算 Loss,而是對每一步生成的草稿都計算 Loss。這強迫模型在第一步就給出一個“大致正確”的解,然後在後續步驟中精細化。
TiDAR
- TiDAR: Think in Diffusion, Talk in Autoregression
英偉達的這篇論文,則是和TRM思路非常相像,都是在生成階段拋棄自迴歸“蹦字”的方案,採用全局生成並不斷打磨的思路。只不過TIDAR引入了擴散模型,並切讓模型在同一個 Forward Pass(前向傳播)裏,既作為“起草者”並行地想,又作為“驗證者”自迴歸地確認。
🚨 核心痛點:既要還要的困境
在大模型推理中,我們一直面臨一個trade-off
- AR:自迴歸模型由於符合語言的因果律,質量最高,但推理速度慢
- Diffusion:非自迴歸模型可以並行生成,吞吐量極高但往往質量不佳,並且質量會隨着生成的token個數而持續下降。
現在已有的一些解決方案例如DeepSeek提出的MTP,同時預測多個token,也是在嘗試解決以上的問題,但MTP的本質還是自迴歸的。
還有Speculative decoding,使用一個輕量級的AR模型去生成多個token的草稿,再用大模型並行對草稿的每個token進行驗證,但這樣就需要同時部署多個模型進行推理。
🛠️ 解決方案: Think + Talk的雙流協同
TiDAR 的模型結構則是在speculative Decoding的基礎上,把草稿模型和驗證模型合併在了一個模型結構裏,通過特殊掩碼實現同時推理。
- Think in Diffusion
在推理時,TiDAR 並不像 GPT 那樣一次只預測一個詞。它使用 Diffusion的方案,在當前位置之後的K個槽位上,同時生成所有候選Token。這 \(K\) 個 Token 是並行生成的。它利用了擴散模型的全局視野。
- Talk in Autoregression"
生成的這K個候選詞並不能直接作為答案,因為 Diffusion 的邏輯一致性不如 AR。TiDAR 在同一個前向傳播中,利用 AR 的邏輯對這K個候選詞進行拒絕採樣。
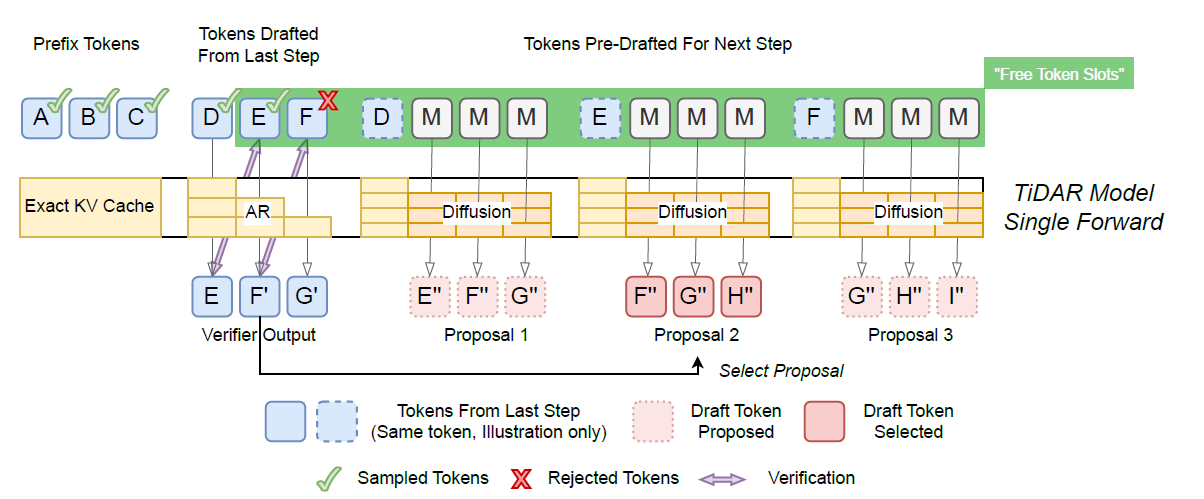
- 雙流的核心實現:結構化注意力掩碼
為了在一次向前推理時,同時實現以上兩種推理,TIDAR設計了一個特殊的二維MASK,將序列分成了兩個部分
- Diffusion MASK:這個區域的token直接是全連接的,為了讓模型能夠根據上文同時猜出後面K個詞
- AR MASK:這個區域是causal MASK,它負責根據上下文和前面猜出的草稿進行遞歸生成。
這樣在一次向前推理中,Inp亡的KV Cache會參與兩次計算
- Input —> Think Mask -> Diffusion Drafts
- Input + Diffusion Drafts -> AR Mask -> Final verified Token
- 多任務聯合優化訓練
為了同時訓練Diffusion和AR,TIDAR在傳統的NSP訓練的基礎上進行了改良,同時訓練兩個loss
- Diffusion Loss:訓練模型在給定上下文和部分噪聲的情況下,並行重構出後續 \(K\) 個詞的能力。
- AR Loss:標準的交叉熵損失,確保模型的最終輸出符合語言概率分佈
總結:推理的未來是“向內生長”?
從以上四篇論文,我們不妨猜測下後Reasoning時代的技術演進方向
- 從Explicit到Implicit?
- 從Linear到Recurrent?
- 從AR到Hybrid?
未來的大模型,或許會變得更像人類的大腦: 表面上沉默寡言,但內心戲極其豐富,並且能夠反覆推敲,最終給出一個深思熟慮的答案。
想看更全的大模型論文·微調預訓練數據·開源框架·AIGC應用 >> DecryPrompt