
從通用部署到極致性能:DeepSeek-V3.2 的推理優化突破
在 AI 應用快速落地的今天,大語言模型的推理性能成為制約其廣泛使用的關鍵因素。DeepSeek-V3.2 作為能力領先的開源模型,在實際部署中面臨着性能調優的複雜挑戰。許多團隊發現,直接使用默認配置往往無法充分利用昂貴的 H200 硬件資源。
我們通過系統的優化實驗發現:相比於未優化的 vLLM 基線配置,經過針對性調優的 DeepSeek-V3.2 在 NVIDIA H200 集羣上實現了 57.8% 至 153.6% 的吞吐量提升,這意味着用同樣的硬件資源,可以服務幾乎兩倍的併發用户。
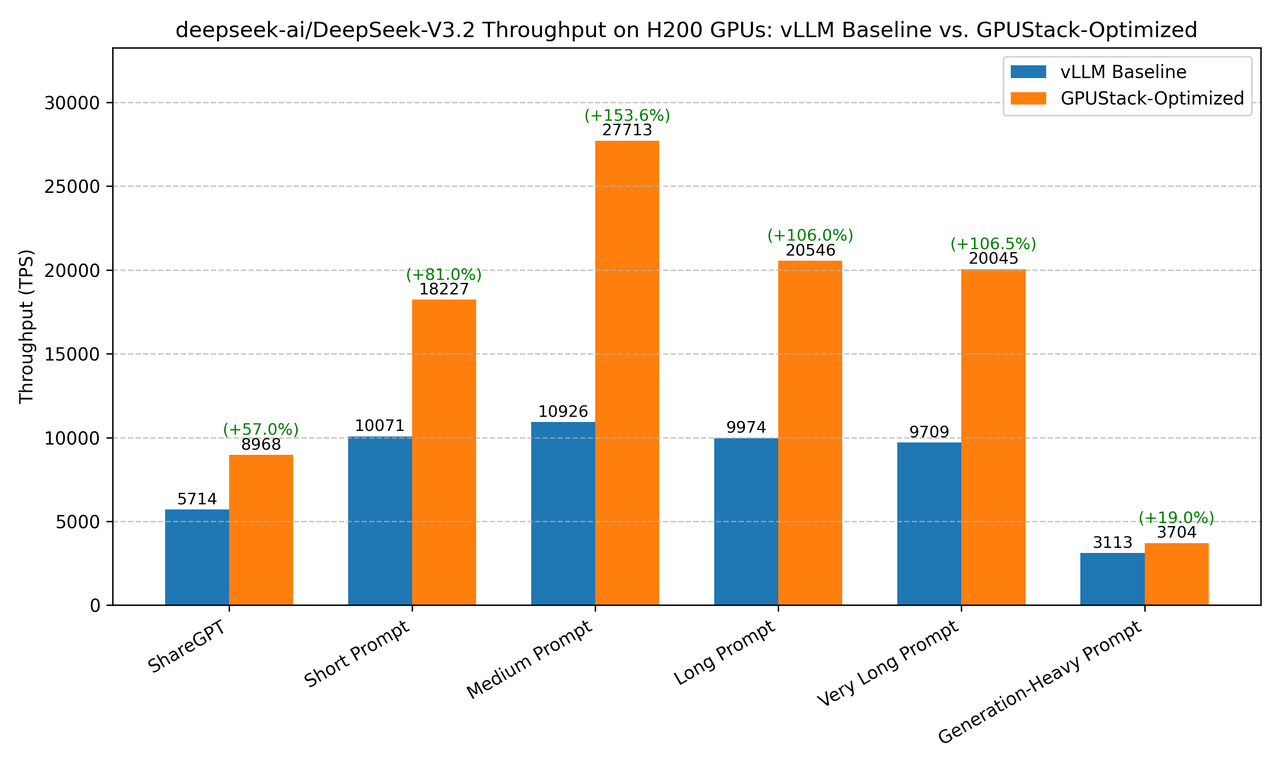
圖 1:優化前後吞吐量對比,最高提升 153.6%(中等長度上下文,高併發)
優化成果:數字見證性能飛躍
我們的基準測試覆蓋了從簡短對話到超長文檔處理的各種真實場景。以下是關鍵數據對比:
| 測試場景 | vLLM 基線 | 優化配置 | 性能提升 |
|---|---|---|---|
| ShareGPT 對話 | 5713.95 tok/s | 8968.32 tok/s | +56.95% |
| 中等長度文本(2K 輸入) | 10925.59 tok/s | 27712.54 tok/s | +153.65% |
| 長文本(4K 輸入) | 9974.26 tok/s | 20545.67 tok/s | +105.99% |
| 超長文本(32K 輸入) | 9709.27 tok/s | 20045.18 tok/s | +106.45% |
| 長文本生成(1K 輸入,2K 輸出) | 3112.52 tok/s | 3703.98 tok/s | +19.0% |
表 1:關鍵場景性能提升對比,優化配置全面超越基線表現
優化策略解密
優化第一步:選擇合適的推理引擎
在開始任何參數調優前,選擇適合的推理引擎至關重要。我們首先測試了三種主流推理引擎在默認配置下的表現:
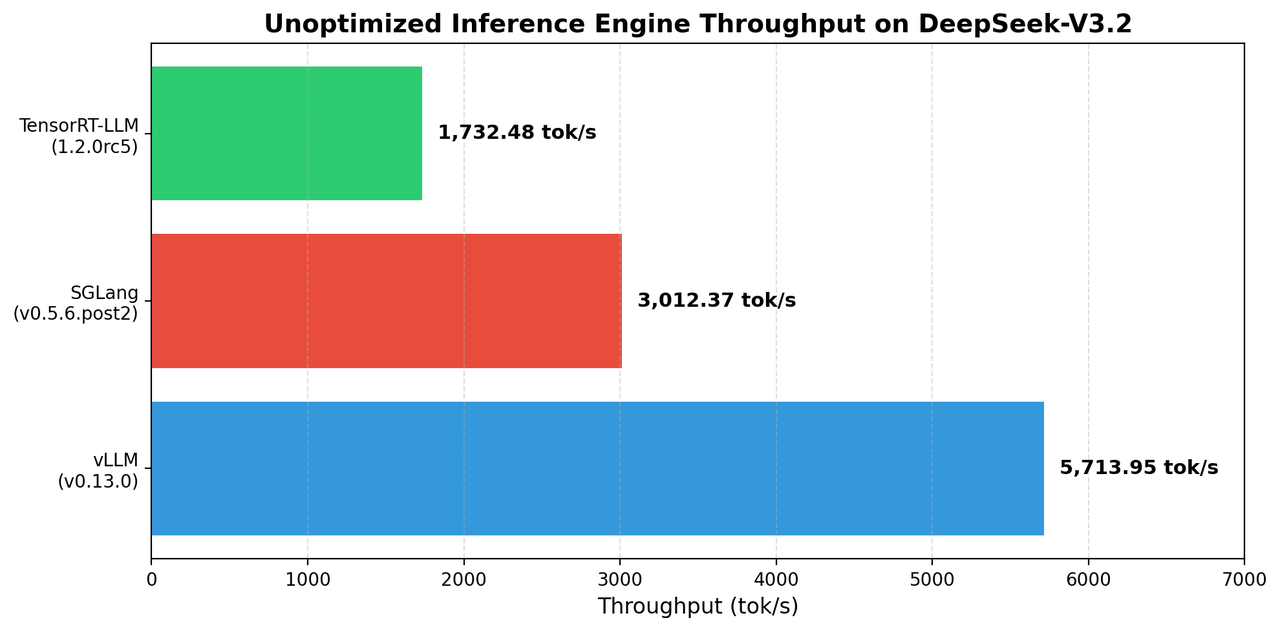
圖 2:三大推理引擎在 DeepSeek-V3.2 上的默認配置吞吐量對比
實驗結果明確:
- vLLM (v0.13.0):5713.95 tok/s - 較強的默認表現
- SGLang (v0.5.6.post2):3012.37 tok/s - 中等表現但優化潛力大
- TensorRT-LLM (1.2.0rc5):1,732.48 tok/s - 當前版本適配有待完善
雖然 vLLM 在默認配置下領先,但我們通過後續實驗發現 SGLang 在特定優化配置下能夠實現更大的性能突破。
第二步:精調並行策略,釋放硬件潛力
基於推理引擎的默認表現,我們深入探索了 vLLM 和 SGLang 各種並行策略的組合效果。基於 SGLang 得到了最好的策略組合,核心突破在於三重並行機制的協同:
# 最終確定的優化配置
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2 \
--chat-template ./tool_chat_template_deepseekv32.jinja \
--tp-size 8 --dp-size 8 --enable-dp-attention
為什麼這個組合如此有效?
--tp-size 8:張量並行,將模型參數分散到 8 個GPU,減少單卡內存壓力--dp-size 8:數據並行,同時處理多個請求,提高吞吐量--enable-dp-attention:注意力機制數據並行,特別優化長序列處理
這一組合策略充分發揮了 H200 集羣的大顯存和高帶寬優勢,特別是在處理超長上下文和高併發請求時效果顯著。
第三步:Tool Call 配置是“隱藏加速器”
實驗結果
在 SGLang 中啓用 Tool Call Parser 後:
- 吞吐從 7351.59 → 8376.43 tok/s
- 額外提升:+13.94%
結論
在真實對話 / Agent 場景中,解析與調度本身就是重要性能瓶頸。
第四步:上下文長度裁剪
實驗結果
在 SGLang 中將最大上下文從默認值裁剪至 32K 後:
- 吞吐從 8376.43 → 8750.49 tok/s
- 額外提升:≈ +4.47%
- TTFT 和 TPOT 均有穩定下降
原因分析
- KV Cache 的分配與最大上下文長度強相關
- 過大的 max context 會:
- 增加顯存佔用
- 降低 batch packing 效率
- 拉低 attention kernel 的 cache locality
結論
有收益,上下文長度裁剪有一定優化,但是上下文長度與業務上下文強相關,不作為默認推薦。
第五步:KV Cache DType
實驗結果(FP8 e4m3)
- 吞吐:8750.49 → 8494.23 tok/s
- 性能略有下降
原因分析
- FP8 KV Cache 減少顯存佔用
- 但在 H200 上:
- 顯存並非主要瓶頸
- 額外的 dtype 轉換帶來調度與訪存開銷
結論
吞吐收益不穩定,非默認推薦,在顯存緊張的環境中可以考慮。
第六步:Attention Backend 切換
實驗結果
| Backend 組合 | 吞吐 | 性能提升 |
|---|---|---|
| 默認 | 8750.49 tok/s | |
| fa3 + fa3 | 8968.32 tok/s | +2.29% |
| flashmla_sparse + flashmla_kv | 5362.16 tok/s | -38.72% |
原因分析
- DeepSeek-V3.2 使用 稀疏 MLA Attention
- 多數 backend 尚未完全針對 sparse pattern 做深度優化
結論
有收益,backend 組合與 GPU 架構、驅動、CUDA 版本高度耦合,不作為默認推薦。
從實驗到生產:一鍵部署優化配置
技術優化雖然複雜,但使用體驗可以極其簡單。我們將所有優化成果封裝為一鍵部署配置:
部署只需三步:
- 安裝平台:安裝 GPUStack,並添加一個 8×H200 的節點。
- 選擇模型:在模型庫中選擇 DeepSeek-V3.2 或 DeepSeek-V3.2-Speciale 模型。
- 啓動服務:系統自動應用所有優化參數,點擊保存即完成部署。
立即體驗優化性能
無需深入研究並行策略,也不必手動調參數。我們的優化方案已經過全面驗證,您可以:
- 快速上手:參考官方快速上手指南,立即體驗一鍵部署優化版 DeepSeek-V3.2
- 技術諮詢:聯繫我們的專家團隊,獲取定製化優化建議
優化不應是少數專家的專利。我們將複雜的技術調優封裝為簡單可用的服務,讓每家企業都能享受頂尖的推理性能。
所有性能數據基於 NVIDIA H200 8-GPU 集羣實測,採用公開可復現的基準測試方法。實際效果可能因具體硬件配置和負載特徵有所差異。
瞭解技術細節或獲取優化支持,請訪問我們的:
推理性能實驗室
https://docs.gpustack.ai/latest/performance-lab/overview/
GitHub 倉庫
https://github.com/gpustack/gpustack