

一、前言
近期在學習 Qwen3 的模型結構時,看到了 Qwen 使用了 GPTQ 與 AWQ 量化方案,於是便萌生了介紹 LLM 量化技術的想法,筆者將用 2-3 篇文章,給讀者們介紹大模型量化的技術。
量化是指將高精度計算的浮點型數據近似為低比特位數據(如 int16、int8、int4 等)的過程,此過程需在不顯著損耗精度的同時,提升模型推理效率並降低內存佔用。特別是在當前主流大語言模型(LLM)的參數量輕鬆突破萬億規模的情況下,量化技術對於高效低成本部署 LLM 尤為重要。而且由於 LLM 的參數量巨大,當前主流的模型都採用 PTQ 後量化技術,從而降低量化過程帶來的成本。
在正式開始這篇文章之前,我們首先來了解一下 LLM 量化的相關概念。
二、LLM 量化相關概念
2.1 LLM 量化常用的數值格式

2.2 LLM 量化對象
在部署推理時,LLM 的量化對象與傳統的 CNN 有所不同,除了權重與激活以外,還增加了 LLM 特有的 KV Cache。所以,LLM 的量化對象主要是權重、激活和 KV Cache。
- 權重量化:僅對 LLM 中的權重進行量化,常見的方法有 GPTQ (W4A16,權重量化為 INT4,激活保持 FP16/BF16)、AWQ(W4A16/W8A16)等;
- 激活量化:對 LLM 中的激活進行量化,常見的方法有 SmoothQuant (W8A8)、LLM.int8()等,由於激活分佈範圍大且動態變化,相比權重量化更具挑戰;
- KV Cache 量化:在 LLM 推理中,為避免重複計算,會緩存 Attention 中的 Key/Value 向量(KV Cache)。 KV Cache 的大小與 上下文長度線性相關,是長文本推理時的主要顯存瓶頸。常見的方法有 KV Cache INT8/INT4 量化。
LLM 的實際部署過程中,常見的量化方案包括:
- W4A16(GPTQ、AWQ) :權重量化為 INT4,激活保持 FP16/BF16。
- W8A16 : 權重量化為 INT8,激活保持 FP16/BF16。
- W8A8(SmoothQuant): 權重和激活均量化為 INT8。
- KV Cache INT8 :緩解長上下文顯存開銷。
下面,我們將對具體的量化方法進行介紹。
三、主流 LLM 量化方法介紹
Qwen 系列模型使用了 AWQ、GPTQ 和 llama.cpp 中的量化技術,且推薦使用 <u>AWQ</u> 結合 <u>AutoAWQ</u><u>,</u>所以本節我們先介紹此方法。
3.1<u> </u><u>AWQ</u> 結合 <u>AutoAWQ </u>量化方法介紹及使用示例
<u>AWQ</u> 全稱為 ACTIVATION-AWARE WEIGHT QUANTIZATION,即激活感知的權重量化,是一種針對 LLM 的低比特權重量化的硬件友好方法。AWQ 在業界廣泛應用,除了官方的支持<u> llm-awq </u>外,<u>AutoAWQ</u>、<u>vLLM</u>、 <u>HuggingFace </u>NVIDIA <u>TensorRT-LLM</u>、<u>FastChat</u> 等主流模型或框架也提供了對 AWQ 的支持。
3.1.1<u> </u><u>AWQ</u> 量化技術原理
<u>AWQ</u> 作者認為:
- 權重對於大語言模型的性能並不同樣重要, 有一小部分(0.1%-1%)對模型精度影響較大的關鍵權重;跳過這些關鍵權重的量化將顯著減少量化精度損失。
- 而且,關鍵權重對應於較大激活幅度的權重通道更加顯着,因為它們處理更重要的特徵,從而根據這個現象尋找關鍵權重。儘管將 0.1% 的權重保留為 FP16 可以在不明顯增加模型大小的情況下提高量化性能,但這種混合精度數據類型會給系統實現帶來困難(硬件效率低下)。
- 設計了一種 per-channel 縮放方法來自動搜索最佳縮放,從而減少顯著權重的量化誤差,這種方法不存在硬件效率低下的問題。

PPL:即困惑度 Perplexity,是語言模型預測序列的平均不確定性度量。PPL 越小,表示模型越“自信”且預測越接近真實分佈;PPL 越大,説明預測分佈和真實分佈偏差更大。
上圖是作者的實驗,可以看出:
- 左圖:所有的權重都從 FP16 量化到 INT3,PPL 為 43.2;
- 中圖:基於激活分佈找到了 1% 的關鍵權重,將關鍵權重保持 FP16 精度,其餘權重量化到 INT3,PPL 由 43.2 大幅下降至 13.0,但這種混合精度格式在硬件上運行並不高效;
- 右圖: AWQ 執行 per-channel 縮放以保護關鍵權重從而減少量化誤差,這裏可以看到縮放 weight 後再做量化的 PPL 為 13.0,縮放本身未對精度產生影響。
權重的縮放因子 s 為超參數,作者在 OPT-6.7B 模型上做了對比實驗,發現當 s 比較大比如等於 4 時,非關鍵通道的相對誤差將會增加(非顯著通道的誤差將被放大)。
為了同時考慮關鍵權重和非關鍵權重,AWQ 選擇自動搜索最佳(每個輸入通道)縮放因子,使某一層量化後的輸出差最小。這就把量化問題建模為如下的最優化問題:
為提升該過程的穩定性,我們通過分析影響縮放因子(scaling factor)選擇的相關因素,為最優縮放比例(optimal scale)定義了一個搜索空間(search space)。如前一部分所述,權重通道(weight channels)的顯著性實際上由激活值縮放比例(activation scale)決定(即 “激活感知性”,activation-awareness)。因此,AWQ 採用了一個極為簡潔的搜索空間,具體如下:
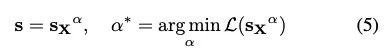
其中 α 是用於平衡對關鍵 channel 與非關鍵 channel 的保護力度。通過在區間 [0, 1] 內執行快速網格搜索(grid search),可確定最優的 α 值(其中 α=0 代表不進行縮放;α=1 代表在我們的搜索空間內採用最激進的縮放策略)。此外,論文中還引入了權重裁剪(weight clipping)操作,以最小化量化過程中的均方誤差(MSE)。
3.1.2 <u>AWQ</u> 量化模型示例
<u>AWQ</u> 與 HuggingFace Transformers 無縫兼容,加載模型後可以直接 .quantize() 做量化,相關使用流程如下。
安裝依賴
pip3 install transformers accelerate autoawq量化模型
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
from transformers import AwqConfig
model_path = "facebook/opt-125m"
quant_path = "opt-125m-awq"
#量化參數配置
quant_config = {
"zero_point": True,
"q_group_size": 128,
"w_bit": 4,
"version": "GEMM"
}
# 加載模型
model = AutoAWQForCausalLM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
#準備校準數據
data = []
for msg in dataset:
text = tokenizer.apply_chat_template(msg, tokenize=False, add_generation_prompt=False)
data.append(text.strip())
# 量化
model.quantize(tokenizer, quant_config=quant_config,calib_data=data)
# 修改配置,保證和 Transformers 兼容
quantization_config = AwqConfig(
bits=quant_config["w_bit"],
group_size=quant_config["q_group_size"],
zero_point=quant_config["zero_point"],
version=quant_config["version"].lower(),
).to_dict()
model.model.config.quantization_config = quantization_config
# 保存模型
model.save_quantized(quant_path, safetensors=True, shard_size="4GB")
tokenizer.save_pretrained(quant_path)quant_config 參數解析:
"w_bit": 權重量化的位寬"q_group_size":量化不是對整個權重張量做一次縮放,而是分組處理,上述示例選擇每組 128 個權重會共享一組縮放因子(scale)和零點(zero point),128是一個常用折中值(Meta 在 LLaMA-2/3 的 INT4 AWQ 中也常用 128)。"zero_point":是否使用零點(zero point)補償,如果設成False,就是對稱量化(中心對齊 0),如果設成True,就是非對稱量化,可以更好覆蓋權重分佈,提高精度。"version":GEMM:通用矩陣乘法(General Matrix Multiplication),適合大模型的權重矩陣乘法。GEMV:矩陣-向量乘法(適合批次小、延遲敏感的場景)。一般推薦用GEMM,因為推理框架(Transformers, vLLM 等)大部分優化都是基於 GEMM 內核。
加載量化後的模型進行推理
from transformers import AutoTokenizer, AutoModelForCausalLM
quant_path = "opt-125m-awq"
tokenizer = AutoTokenizer.from_pretrained(quant_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(quant_path, device_map="auto")
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt").to(0)
out = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(out[0], skip_special_tokens=True))3.2 GPTQ
<u>GPTQ</u>(Gradient Post-Training Quantization)是一種針對類 GPT 大型語言模型的量化方法,它基於近似二階信息進行一次性權重量化。本節將會介紹 GPTQ 量化的基本原理,同時也會展示如何通過<u> AutoGPTQ </u>來對您自己的模型進行量化處理。GPTQ 量化具有以下特點:
GPTQ 量化的優點:
- 無須重新訓練(僅需少量校準數據)。
- 量化精度接近全精度,4bit GPTQ 能維持 LLaMA、OPT 等模型接近 FP16 的性能。
- 速度快,實用性強,已成為主流 LLM 低比特推理方法。
GPTQ 量化的缺點:
- 量化過程涉及 Hessian 矩陣近似和逐元素優化,計算複雜度較高。
- 一般只量化權重,激活量化效果不佳(通常保持 FP16)。
3.2.1 GPTQ 量化技術原理
GPTQ 是一種高精度、高效率的量化方法,它可以在大約四個 GPU 小時內量化具有 1750 億個參數的 GPT 模型,將位寬降低到每個權重 3 位或 4 位,與未壓縮基線相比,精度下降可以忽略不計。GPTQ 源於 OBQ(Optimal Brain Quantization),而 OBQ 改進自剪枝方法 OBS(Optimal Brain Surgeon),OBS 又源自 Yann LeCun 1990 年提出的 OBD(Optimal Brain Damage)。OBD 通過泰勒展開簡化目標函數並計算海森矩陣確定參數影響;OBS 考慮參數交叉項,求海森矩陣逆確定剪枝順序並更新其他參數減少誤差。OBQ 將剪枝思路推廣到量化,視剪枝為近似 0 的特殊量化,但速度慢,大模型量化需數天。GPTQ 作為 OBQ 加速版,優化算法性能,降低複雜度並保證精度,176B Bloom 模型量化不到 4 小時,且有嚴謹數學理論推導。
GPTQ 在執行量化操作時,會先對權重實施分組處理(比如,每 128 列劃分為一個組),進而構成若干個數據塊。對於每個數據塊裏的全部參數,會逐一開展量化工作。在完成某一個參數的量化後,藉助校準數據集,對該數據塊中其餘還未進行量化的參數進行合理調節,通過這種方式來補償量化過程中產生的精度損耗。GPTQ 的量化過程如下所示:
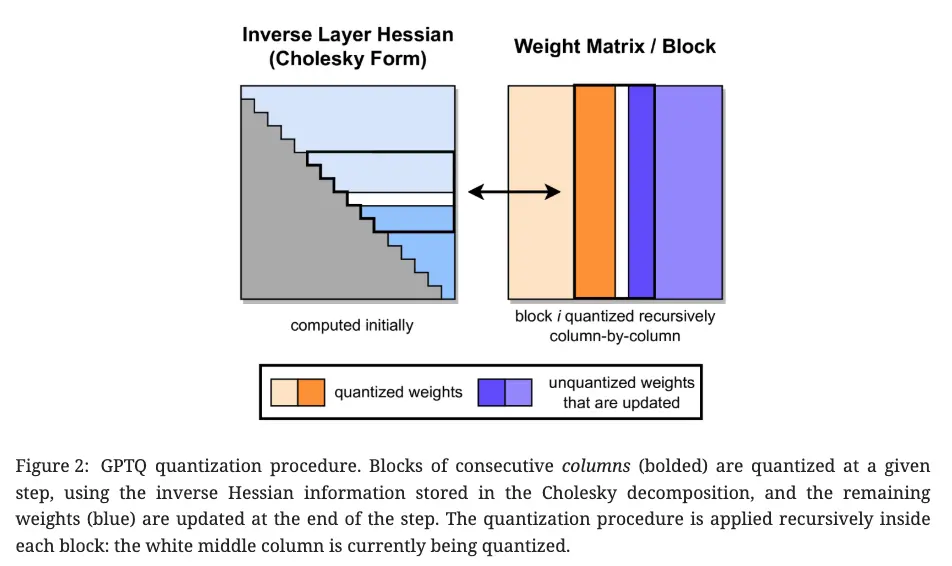
-
前向採樣數據
先用一小部分校準數據(calibration data,通常只需幾百到幾千條樣本,比如來自模型訓練語料的子集),將校準數據喂入原始全精度模型,收集每一層的 激活值(輸入向量 X)。
-
構造量化優化問題
GPTQ 的目標是 最小化量化後輸出誤差的二次形式:

其中 WX 為量化前的權重和激活輸入,另外一項為量化後的權重和激活。
-
Hessian 近似
GPTQ 使用輸入激活的協方差來近似 Hessian,這樣就轉化為公式(2)中的問題:
-
逐元素優化(帶校正)
GPTQ 不一次性量化整個權重矩陣,而是 逐元素(或逐塊)地量化權重。對每個權重,在量化時會根據 Hessian 的對角線項(近似二階導信息)進行 誤差校正,首先量化一個權重,然後更新剩餘權重的“殘差誤差”,這相當於執行一次 逐步的高斯消元式校正,避免量化誤差累積。

重複上述步驟,依次處理完一層的全部權重。然後繼續到下一層,直到整個模型量化完成。
3.2.2 GPTQ 量化使用示例
transformers 已經正式支持了 AutoGPTQ,這意味着您能夠直接在 transformers 中使用量化後的模型。
安裝依賴
推薦通過安裝源代碼的方式獲取並安裝 AutoGPTQ 工具包:
git clone https://github.com/AutoGPTQ/AutoGPTQ
cd AutoGPTQ
pip install -e .量化模型
import os
import logging
import torch
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from transformers import AutoTokenizer
# =============================
# 配置路徑和量化超參數
# =============================
model_path = "your_model_path" # 原始模型路徑(本地或HF Hub)
quant_path = "your_quantized_model_path" # 保存量化後模型的路徑
# 量化配置
quantize_config = BaseQuantizeConfig(
bits=4, # 量化比特數,可選 4 或 8
group_size=128, # 分組大小,推薦 128
damp_percent=0.01, # Hessian 阻尼因子,提升數值穩定性
desc_act=False, # 是否對激活值量化,一般 False 以提升推理速度
static_groups=False, # 是否使用靜態分組,通常 False
sym=True, # 是否對稱量化,True 更穩定
true_sequential=True, # 是否順序量化,提升精度但更慢
model_name_or_path=None, # 保持 None(除非做特殊兼容)
model_file_base_name="model" # 保存的模型文件前綴
)
max_len = 8192 # 輸入最大長度(根據模型上下文窗口設置)
# =============================
# 加載分詞器和模型
# =============================
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
# 確保 pad_token 存在(某些 LLM 沒有定義 pad_token)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = AutoGPTQForCausalLM.from_pretrained(model_path, quantize_config)
# =============================
# 準備校準數據(calibration data)
# dataset 需要你自己定義,比如一小部分語料
# dataset = ["hello world", "some calibration sentence", ...]
# =============================
data = []
for msg in dataset:
# 轉換成文本(可根據是否使用 chat 模板決定)
text = tokenizer.apply_chat_template(
msg,
tokenize=False,
add_generation_prompt=False
)
# 編碼輸入
model_inputs = tokenizer(
text,
truncation=True,
max_length=max_len,
padding="max_length", # 保證對齊
return_tensors="pt"
)
# 收集數據(dict 格式)
data.append(dict(
input_ids=model_inputs["input_ids"].squeeze(0),
attention_mask=model_inputs["attention_mask"].squeeze(0)
))
# =============================
# 配置日誌輸出
# =============================
logging.basicConfig(
format="%(asctime)s %(levelname)s [%(name)s] %(message)s",
level=logging.INFO,
datefmt="%Y-%m-%d %H:%M:%S"
)
# =============================
# 執行量化
# =============================
model.quantize(data, cache_examples_on_gpu=False)
# =============================
# 保存量化後的模型和分詞器
# =============================
os.makedirs(quant_path, exist_ok=True)
model.save_quantized(quant_path, use_safetensors=True)
tokenizer.save_pretrained(quant_path)
print(f"量化模型已保存到: {quant_path}")四、參考資料
<u>Qwen 官方文檔</u>
https://zhuanlan.zhihu.com/p/681578090
https://zhuanlan.zhihu.com/p/680212402
http://cnblogs.com/xwher/p/18788021
<u>AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration</u>
<u>GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers</u>