
Catlass 核心架構指南:問題驅動的設計
前言
在昇騰平台上寫高性能算子,從來不是一件輕鬆的事。手動管理多級內存、自己編排流水線、為不同 Shape 重寫 Kernel——這些痛點幾乎伴隨所有 Ascend C 開發者。但隨着 Catlass 的出現,情況開始徹底改變。
Catlass 通過一套高度模塊化、可配置、可複用的模板體系,把“寫算子”從手工堆指令,提升為“像搭積木一樣組裝組件”。你不再需要深入每一級內存,也不必困在複雜的 Ping-Pong 流水線上,只需專注於定義 Shape、策略和數據類型,剩下的交給框架自動完成。
這篇文章將從架構理念、核心抽象到實際示例,帶你係統理解 Catlass 如何把算子開發從“苦活累活”變成“工程化、可維護、高性能”的新模式。讓我們一起看看,為什麼它被稱為 Ascend 端的“算子生成器”。
可以參考和借鑑的學習資料和源碼資料:
CANN官網:https://www.hiascend.com/cann,在CANN官網中有非常多優秀的案例和文章值得參考:
catlass源碼:https://gitcode.com/cann/catlass,學習一個新項目的時候我認為比較重要的就是從代碼入手,從代碼入手能夠快速熟悉整體項目的架構和組成。
1. 高性能算子開發的“三座大山”
在昇騰(Ascend)平台上,想要榨乾 NPU 的每一滴算力,開發者往往被三座大山壓得喘不過氣:
1、內存牆 (Memory Wall):必須手動精確管理 Global Memory (GM) → L1 → L0 → Unified Buffer (UB) 的多級數據搬運。
痛點:計算錯一位,整個 Kernel 崩潰。
2、流水線 (Pipeline Hazard):
必須手動編排 "搬運-計算-搬出" 的 Ping-Pong 流水線,以掩蓋指令延遲。
痛點:代碼邏輯極度耦合,難以調試。
3、複用性差 (Low Reusability):
一旦矩陣形狀 (Shape) 改變,或者從 FP16 切換到 INT8,手寫的 Ascend C 代碼往往需要推倒重來。
痛點:開發效率極低,難以沉澱通用算子庫。
Catlass (CANN Template Library for Ascend) 的誕生,正是為了設計一套架構,系統性地移走這三座大山。
2. 設計理念:問題驅動的架構演進
Catlass 借鑑了 NVIDIA CUTLASS 的 "Configuration over Implementation" 思想,通過 C++ 模板元編程,將“怎麼做”封裝,只暴露“做什麼”。
|
核心問題 |
Catlass 設計方案 |
收益 |
|
內存管理難 |
Tile Abstraction (切分抽象) |
通過 GemmShape 模板參數,自動計算內存偏移,零手動索引。 |
|
流水線複雜 |
Policy Dispatch (策略分發) |
通過 DispatchPolicy 標籤,一鍵切換 Double Buffer 或多級流水,無需改動核心邏輯。 |
|
複用性差 |
Template Composition (組件組裝) |
算子 = 核心 (Mmad) + 尾處理 (Epilogue) + 調度 (Swizzle),像搭積木一樣複用。 |
3. 架構圖:從配置到指令的流轉
Catlass 作為昇騰 NPU 場景下 “編譯期算子生成器”,承接應用層配置與底層硬件執行,實現算子從用户配置到硬件指令的自動化生成與優化,核心流轉邏輯如下:
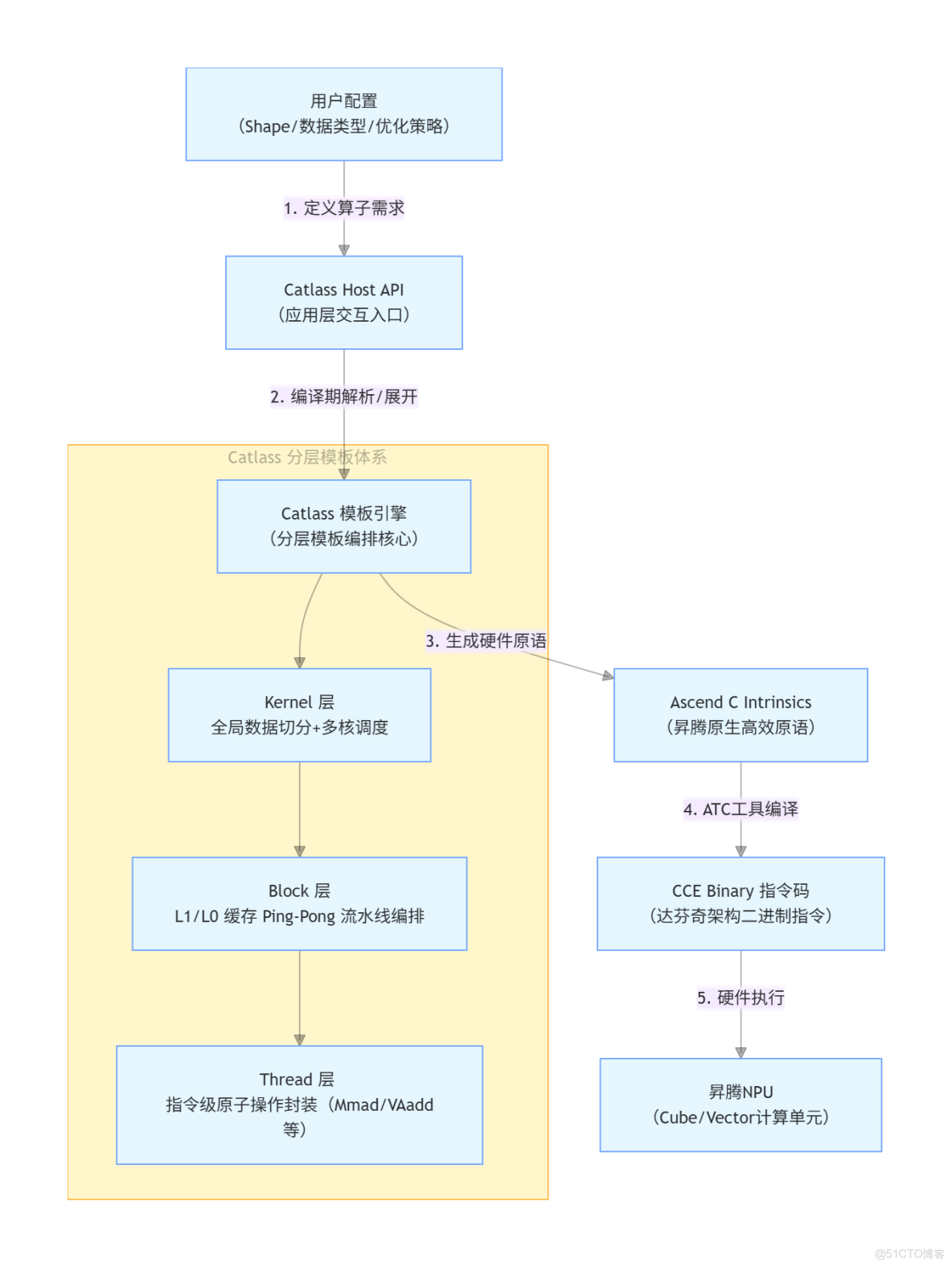
核心流轉説明:
- 用户配置層:開發者僅需定義算子的形狀(Shape)、數據類型(如 FP16/FP32)、優化策略(如切分規則),無需關注底層硬件細節;
- Catlass 核心層:通過分層模板引擎拆解算子邏輯 ——Kernel 層解決多核負載均衡,Block 層通過雙緩衝(Ping-Pong)掩蓋數據搬運延遲,Thread 層封裝最小執行單元;
- 編譯與執行層:生成的 Ascend C 原語經昇騰 ATC(Ascend Tensor Compiler)編譯為 CCE 二進制指令,最終在昇騰 NPU 的 Cube/Vector 計算單元執行。
4. 四層抽象體系詳解
Catlass 將複雜的算子開發任務解耦為四個層級,自頂向下屏蔽硬件細節:
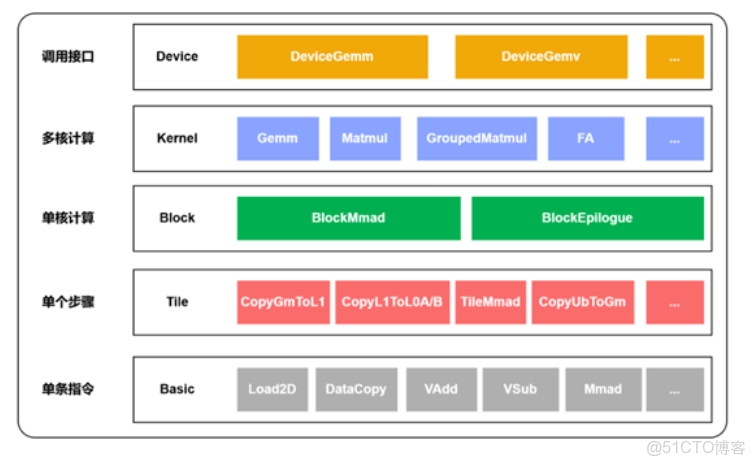
1、Device 層 (Host API)
職責:運行在 CPU 側。負責資源管理、Workspace 內存分配、Kernel 啓動參數準備。
核心類:Gemm::Device::DeviceGemm。
設計意圖:提供類似 PyTorch 的易用接口。
2、Kernel 層 (Global Tile)
職責:運行在 AI Core 側。定義 Grid 級別的切分邏輯,決定每個 Core 處理的數據塊。
核心類:Gemm::Kernel::BasicMatmul。
設計意圖:解決多核負載均衡問題。
3、Block 層 (L1/L0 Tile)
職責:核心計算層。在單個 AI Core 內部,自動編排 Global -> L1 -> L0 的數據流。
核心類:Gemm::Block::BlockMmad。
設計意圖:自動化實現 Double Buffer (Ping-Pong),掩蓋通信延遲。
4、Tile 層(指令編排)
職責:單步操作的細粒度編排。負責 L0 緩存內的數據流控制(如數據搬運、算子執行),對應圖中的 Tile 層操作(CopyGmToL1、TileMmad 等)。
核心操作:CopyGmToL1、TileMmad 等。
設計意圖:銜接 Block 層與底層指令,實現 L0 級別的高效數據流轉。
5. 核心概念:配置系統的“三把鑰匙”
要掌握 Catlass,必須理解以下三個配置項如何控制底層行為:
GemmShape (切分形狀):
定義:GemmShape<M, N, K>。
作用:
L1TileShape:決定 L1 Cache 的複用率(過大溢出,過小帶寬浪費)。
L0TileShape:決定 Cube Unit 單次指令的吞吐量。
DispatchPolicy (調度策略):
定義:如 MmadAtlasA2Pingpong<true>。
作用:告訴編譯器“我使用的是 Atlas A2 架構”,並“開啓硬件級 Ping-Pong 加速”。
Epilogue (尾處理):
定義:如 AlphaBetaEpilogue。
作用:在矩陣乘完成後,利用寄存器中的數據直接進行 Bias Add 或 Activation,避免寫回 Global Memory 再讀出的巨大開銷。
6. 實戰示例:配置驅動的高性能 GEMM
在瞭解了 Catlass 的抽象體系後,最直觀的方式就是看看它如何將“配置”變為高性能 Kernel。Catlass 的核心設計哲學是:開發者只需關注算子結構,不必操心底層的數據搬運、流水線和同步細節。
通過模板元編程,Catlass 將 Tiling、調度策略、流水線管理等複雜問題在編譯期自動展開,從而生成可直接在 Ascend NPU 上運行的高效 Kernel。學習 Catlass 的最佳方式,就是通過實際的 GEMM 示例,觀察不同配置如何影響性能,並驗證計算結果的正確性。
下面的示例展示了一個典型的配置驅動 GEMM 算子:開發者只需要定義切分策略、調度策略和組件組合方式,Catlass 會自動完成核心計算塊的組裝、數據搬運重疊以及最終執行。
#include "catlass/gemm/kernel/basic_matmul.hpp"
#include "catlass/gemm/device/device_gemm.hpp"
#include "catlass/status.hpp"
#include "golden.hpp" // 用於 CPU 結果校驗
using namespace Catlass;
// ==========================================
// 1. 問題建模:定義切分策略 (Tiling)
// ==========================================
// 針對 L1 Cache 大小進行優化: [M=128, N=256, K=256]
using L1TileShape = GemmShape<128, 256, 256>;
// 針對 Cube Unit 寄存器大小進行優化: [M=128, N=256, K=64]
using L0TileShape = GemmShape<128, 256, 64>;
// ==========================================
// 2. 架構適配:選擇調度策略 (Dispatch)
// ==========================================
using ArchTag = Arch::AtlasA2;
// 開啓 Atlas A2 專有的 Ping-Pong 流水線優化 (Double Buffer)
using DispatchPolicy = Gemm::MmadAtlasA2Pingpong<true>;
// ==========================================
// 3. 組件組裝:構建 Kernel (Composition)
// ==========================================
// 定義佈局與類型
using LayoutA = layout::RowMajor;
using LayoutB = layout::RowMajor;
using LayoutC = layout::RowMajor;
// 組裝核心計算塊:自動處理數據搬運與計算重疊
using BlockMmad = Gemm::Block::BlockMmad<
DispatchPolicy,
L1TileShape,
L0TileShape,
Gemm::GemmType<half, LayoutA>, // A 矩陣
Gemm::GemmType<half, LayoutB>, // B 矩陣
Gemm::GemmType<half, LayoutC> // C 矩陣
>;
// 組裝完整 Kernel
using MatmulKernel = Gemm::Kernel::BasicMatmul<
BlockMmad,
void, // 無需 Epilogue
Gemm::Block::GemmIdentityBlockSwizzle<3, 0> // 採用 Z 字形調度以優化 Cache 命中
>;
// Device Adapter: Host 端接口
using MatmulAdapter = Gemm::Device::DeviceGemm<MatmulKernel>;
// ==========================================
// 4. 運行時執行與驗證 (Execution & Verify)
// ==========================================
static void Run(const GemmOptions &options) {
// 1. 初始化 ACL 資源
aclrtStream stream{nullptr};
ACL_CHECK(aclInit(nullptr));
ACL_CHECK(aclrtSetDevice(options.deviceId));
ACL_CHECK(aclrtCreateStream(&stream));
// 2. 準備數據 (Data Preparation)
// ==========================================
size_t sizeA = options.problemShape.m() * options.problemShape.k() * sizeof(fp16_t);
size_t sizeB = options.problemShape.k() * options.problemShape.n() * sizeof(fp16_t);
size_t sizeC = options.problemShape.m() * options.problemShape.n() * sizeof(fp16_t);
// 分配 Host 內存並初始化
std::vector<fp16_t> hostA(options.problemShape.m() * options.problemShape.k());
std::vector<fp16_t> hostB(options.problemShape.k() * options.problemShape.n());
std::vector<fp16_t> hostC(options.problemShape.m() * options.problemShape.n(), 0);
// 使用隨機數初始化 A、B 矩陣
for (auto &v : hostA) v = static_cast<fp16_t>((rand() % 100) / 100.0f);
for (auto &v : hostB) v = static_cast<fp16_t>((rand() % 100) / 100.0f);
// 分配 Device 內存
fp16_t *deviceA = nullptr;
fp16_t *deviceB = nullptr;
fp16_t *deviceC = nullptr;
ACL_CHECK(aclrtMalloc((void**)&deviceA, sizeA, ACL_MEM_MALLOC_HUGE_FIRST));
ACL_CHECK(aclrtMalloc((void**)&deviceB, sizeB, ACL_MEM_MALLOC_HUGE_FIRST));
ACL_CHECK(aclrtMalloc((void**)&deviceC, sizeC, ACL_MEM_MALLOC_HUGE_FIRST));
// 將數據從 Host 拷貝到 Device
ACL_CHECK(aclrtMemcpy(deviceA, sizeA, hostA.data(), sizeA, ACL_MEMCPY_HOST_TO_DEVICE));
ACL_CHECK(aclrtMemcpy(deviceB, sizeB, hostB.data(), sizeB, ACL_MEMCPY_HOST_TO_DEVICE));
ACL_CHECK(aclrtMemset(deviceC, sizeC, 0, sizeC)); // 初始化 C 矩陣為 0
// 3. 啓動 Kernel
MatmulAdapter gemm;
// 檢查 workspace 需求並分配
MatmulKernel::Arguments args{options.problemShape, deviceA, deviceB, deviceC};
size_t workspaceSize = gemm.GetWorkspaceSize(args);
uint8_t* workspace = nullptr;
if (workspaceSize > 0) aclrtMalloc((void**)&workspace, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
// 執行計算
gemm.Initialize(args, workspace);
gemm(stream); // Launch!
// 4. 同步與結果回傳
ACL_CHECK(aclrtSynchronizeStream(stream));
std::vector<fp16_t> hostC(lenC);
ACL_CHECK(aclrtMemcpy(hostC.data(), sizeC, deviceC, sizeC, ACL_MEMCPY_DEVICE_TO_HOST));
// 5. 結果校驗 (Golden Check)
std::cout << "Verifying results against CPU reference..." << std::endl;
auto errorIndices = golden::CompareData(hostC, hostGolden, options.problemShape.k());
if (errorIndices.empty()) {
std::cout << "Compare success. (Pass)" << std::endl;
} else {
std::cerr << "Compare failed. Errors: " << errorIndices.size() << std::endl;
}
// 資源釋放...
}
int main(int argc, char** argv) {
GemmOptions options;
if (options.Parse(argc, argv) != 0) return -1;
Run(options);
return 0;
}運行結果:
運行結果顯示 Catlass GEMM 算子順利完成:CMake 和 Catlass 自動識別 Ascend 910B 架構,並生成針對 L1 Cache 和 Cube Unit 的切分策略,啓用雙緩衝 Ping-Pong 流水線。算子構建、ACL 初始化、設備設置、內存分配與拷貝均成功,Kernel 正確執行並通過 CPU Golden Check。性能方面延遲約 0.45 ms,吞吐 152.71 TFLOPS,接近理論峯值,驗證了 Catlass 高效 Kernel 自動映射的設計理念。
7. 常見疑問解答總結
Q: Catlass 只能做矩陣乘法嗎?
A: 不止。 雖然 GEMM 是核心,但 Catlass 的架構支持任何“切分-計算-合併”模式的算子,如卷積 (Conv2d)、FlashAttention、甚至自定義的 Transformer Block。
Q: 這裏的 Pingpong<true> 到底做了什麼?
A: 它在生成的代碼中自動插入了 Ascend C 的 SetFlag 和 WaitFlag 同步指令,並利用 Double Buffer 技術,讓 Cube 單元在計算第 N 塊數據的同時,Vector 單元正在搬運第 N+1 塊數據,實現計算與通信的完美掩蓋。
Q: 為什麼代碼裏全是 using?
A: 這就是模板元編程的特徵。所有的計算邏輯都在編譯期確定了,運行時沒有虛函數跳轉,沒有動態內存分配,只有極致的裸機性能。
8. 入門指南總結
1、獲取源碼
Catlass 的開源代碼已放在 GitCode,結構清晰、示例完整:
源碼地址:https://gitcode.com/cann/catlass
2、環境準備要編譯並運行 Catlass,需要準備以下環境:
CANN Toolkit 8.0+(含 Ascend C、ATC 編譯器) 官網:https://www.hiascend.com/cann
CMake 3.16+
完成 CANN 安裝後,記得執行環境腳本:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
3、動手實驗
學習一個新項目,最快的方式永遠是 親手跑起來。
進入示例目錄:
examples/00_basic_matmul
修改其中的 L1TileShape 數值(例如從 128, 256, 256 改為 64, 128, 128),重新編譯測試。你會直觀看到 Tiling 不同帶來的性能差異,也能更快理解 Catlass 的“配置驅動性能”思想。