

1. 引言:Java 意外的機器學習復興
儘管 Python 主導了機器學習的研究與實驗,但生產部署講述着不同的故事。截至 2025 年,68% 的應用程序運行在 Java 或 JVM 上,那些已在 Java 生態系統投入巨資的企業面臨一個關鍵問題:是重新培訓團隊並重寫系統,還是將機器學習能力引入 Java?答案正日益傾向於後者。

Netflix 使用 Deep Java Library 進行分佈式深度學習實時推理,通過字符級 CNN 和通用句子編碼器模型處理日誌數據,每個事件的延遲為 7 毫秒。這代表了一個更廣泛的趨勢——儘管 Python 在訓練方面占主導地位,但 Java 在生產系統、多線程、穩定性和企業集成方面的優勢,使其在機器學習部署上極具吸引力。
本文探討 Java 在機器學習生命週期中的角色,比較各種框架,探索與 Python 生態系統的集成模式,並識別 Java 提供明顯優勢的場景。
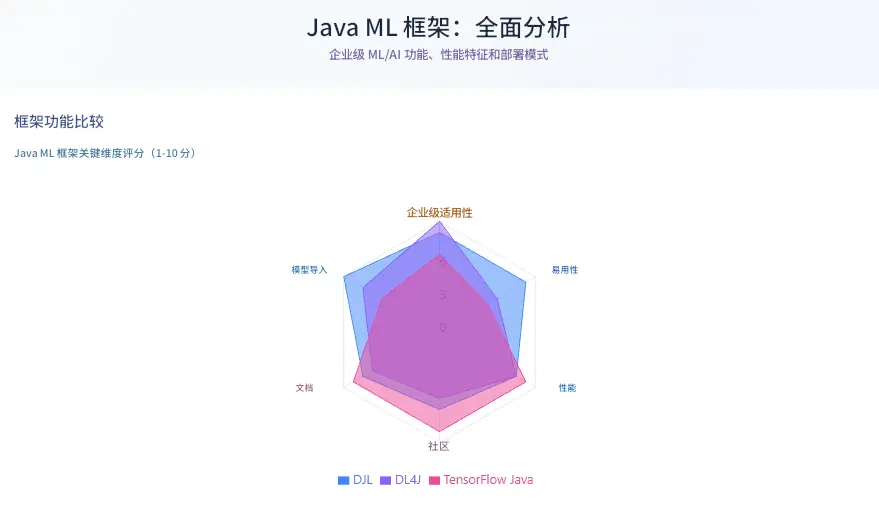
2. Java ML 框架對比
2.1 Deep Java Library:引擎無關的方案
Deep Java Library 是一個開源的、高層次的、引擎無關的 Java 深度學習框架,它提供原生 Java 開發體驗,功能如同任何其他常規 Java 庫。由 AWS 創建的 DJL,其架構理念以抽象為核心——開發者編寫一次代碼,即可在 PyTorch、TensorFlow、MXNet 或 ONNX Runtime 之間切換而無需修改。
該框架由五層架構組成。高層 API 層提供符合 Java 習慣的接口,供開發者直接交互。引擎抽象層與底層框架通信,隱藏實現差異。NDManager 管理表示張量的 NDArray 的生命週期,在處理後自動釋放張量內存以防止泄漏或崩潰。數據處理層提供為模型準備數據的實用工具。最後,原生引擎層通過對 C++ 實現的 JNA 調用執行實際計算。
DJL 與 TensorFlow、PyTorch、MXNet 等各種深度學習框架無縫集成,提供一個高層次 API 以便於在 Java 環境中輕鬆構建、訓練和部署模型,並且與 AWS 服務緊密集成。其 Model Zoo 提供了來自 GluonCV、HuggingFace、TorchHub 和 Keras 的 70 多個預訓練模型,支持單行命令加載模型。
優勢:
- 引擎靈活性:允許根據部署需求切換後端(研究模型用 PyTorch,生產用 MXNet,跨平台用 ONNX)。
- 原生多線程支持:與 Akka、Akka Streams 及併發 Java 應用程序自然集成。
- 自動 CPU/GPU 檢測:無需配置即可確保最佳硬件利用率。
- 通過 DJL Spring starters 集成 Spring Boot:簡化企業採用。
侷限:
- 訓練功能存在,但不如推理功能成熟。
- 文檔側重於推理而非訓練工作流。
- 社區規模小於 Python 優先的框架。
2.2 Deeplearning4j:JVM 原生解決方案
Eclipse Deeplearning4j 是為 Java 虛擬機編寫的編程庫,是一個廣泛支持深度學習算法的框架,包括受限玻爾茲曼機、深度信念網絡、深度自動編碼器、堆疊降噪自動編碼器、遞歸神經張量網絡、word2vec、doc2vec 和 GloVe 的實現。
DL4J 於 2014 年問世,目標客户是已投入 Java 基礎設施的企業。Eclipse Deeplearning4j 項目包括 Samediff(一個類似 TensorFlow/PyTorch 的框架,用於執行復雜計算圖)、Python4j(一個 Python 腳本執行框架,用於將 Python 腳本部署到生產環境)、Apache Spark 集成以及 Datavec(一個將原始輸入數據轉換為張量的數據轉換庫)。
該框架的分佈式計算能力使其區別於其他方案。Deeplearning4j 包含與 Apache Hadoop 和 Spark 集成的分佈式並行版本。對於處理大規模數據的組織,DL4J 提供了無需 Python 依賴的原生 JVM 解決方案。
優勢:
- 完整的 ML 生命週期支持——訓練、推理和部署完全在 Java 中完成。
- 分佈式訓練:使用 Spark 或 Hadoop 在集羣中擴展。
- ND4J 提供支持 GPU 加速的、類似 NumPy 的 n 維數組。
- SameDiff 提供類似 TensorFlow 的“先定義後運行”圖執行方式。
- Keras 模型導入:支持 h5 文件,包括 tf.keras 模型。
侷限:
- 文檔和社區資源落後於 TensorFlow 和 PyTorch。
- 與高層次框架相比學習曲線更陡峭。
- 採用範圍較窄,主要集中在重度使用 Java 的企業。
2.3 TensorFlow Java:官方但功能有限
TensorFlow Java 可在任何 JVM 上運行以構建、訓練和部署機器學習模型,支持 CPU 和 GPU 在圖模式或即時執行模式下的運行,並提供了在 JVM 環境中使用 TensorFlow 的豐富 API。作為 TensorFlow 的官方 Java 綁定,它提供了對 TensorFlow 計算圖執行的直接訪問。
TensorFlow 的 Java 語言綁定已移至其獨立的代碼庫,以便獨立於官方 TensorFlow 版本進行演進和發佈,大多數構建任務已從 Bazel 遷移到 Maven。這種分離允許在不等待 TensorFlow 核心發佈的情況下進行 Java 特定的改進。
優勢:
- 與 TensorFlow 生態系統和工具直接集成。
- SavedModel 格式兼容性支持從 Python 到 Java 的無縫模型移交。
- TensorFlow Lite 支持面向移動和邊緣部署。
- 通過原生 TensorFlow 運行時支持 GPU 和 TPU 加速。
侷限:
- TensorFlow Java API 不在 TensorFlow API 穩定性保證範圍內。
- 對 Keras on Java 幾乎無官方支持,迫使開發者必須在 Python 中定義和訓練複雜模型以供後續導入 Java。
- 與 DJL 甚至 DL4J 相比,較低級別的 API 需要編寫更多代碼。
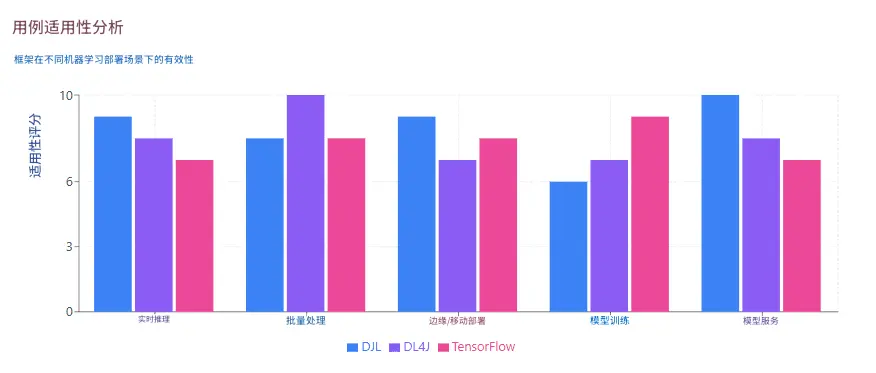
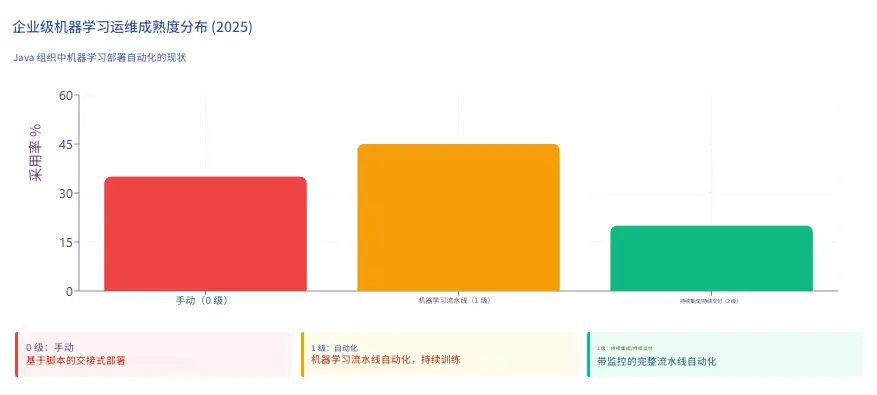
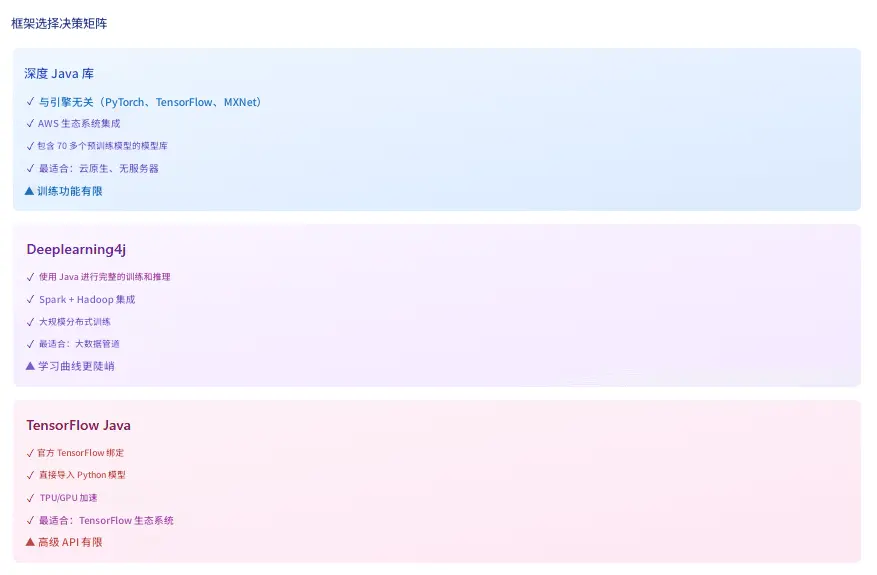
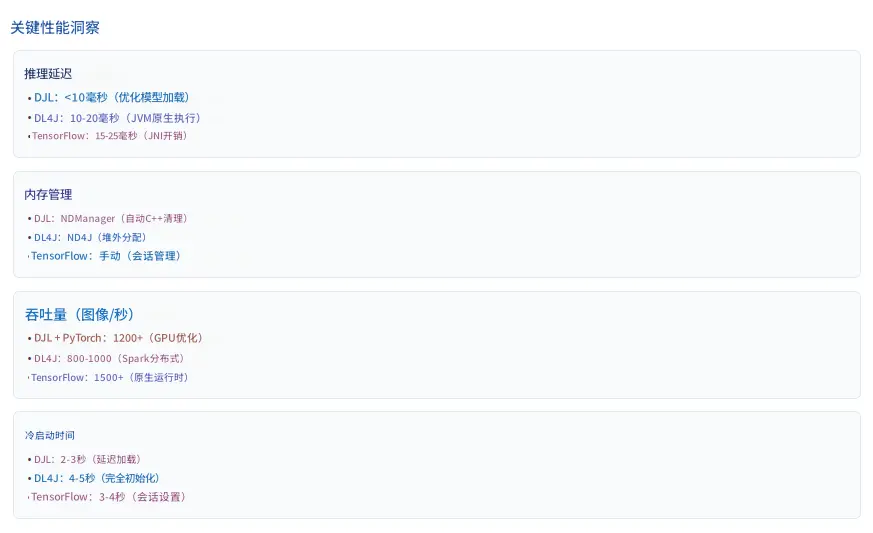
3. 框架對比表
| 標準 | Deep Java Library | Deeplearning4j | TensorFlow Java |
|---|---|---|---|
| 主要用例 | 推理與模型服務 | 完整 ML 生命週期 | 模型服務 |
| 引擎支持 | PyTorch, TensorFlow, MXNet, ONNX | 原生 JVM | 僅 TensorFlow |
| 訓練能力 | 有限 | 完全支持 | 有限 |
| 分佈式計算 | 通過引擎(如 MXNet 上的 Spark) | 原生 Spark/Hadoop | 通過 TensorFlow |
| 模型導入 | PyTorch, TensorFlow, Keras, ONNX | Keras, TensorFlow, ONNX | 僅 TensorFlow |
| 預訓練模型 | Model Zoo 中 70+ | 社區模型 | TensorFlow Hub |
| Spring Boot 集成 | 原生 starters | 手動 | 手動 |
| 學習曲線 | 低 | 中-高 | 中 |
| 內存管理 | NDManager(自動) | ND4J(堆外) | 手動會話 |
| 企業就緒度 | 高 | 非常高 | 中 |
| 社區規模 | 增長中 | 小眾 | 大(Python) |
| 最適合 | 雲原生推理 | 大數據 ML 流水線 | TensorFlow 生態系統 |
決策矩陣:
- 選擇 DJL 用於:微服務、無服務器函數、Spring Boot 應用、引擎靈活性、AWS 生態系統。
- 選擇 DL4J 用於:分佈式訓練、Spark/Hadoop 集成、完整的純 Java 技術棧、企業數據流水線。
- 選擇 TensorFlow Java 用於:現有的 TensorFlow 投資、TPU 部署、直接的 Python 模型兼容性。
4. 與 Python ML 生態系統的集成
4.1 多語言生產模式
最優的企業 ML 工作流通常結合 Python 的研究能力和 Java 的生產優勢。數據科學家在熟悉的 Python 環境中使用 TensorFlow、PyTorch 或 scikit-learn 訓練模型。工程師隨後將這些模型部署在每天處理數百萬請求的 Java 應用程序中。
模型導出格式:
- ONNX:這個通用的交換格式支持大多數框架。在 PyTorch 中訓練,導出到 ONNX,通過 DJL 或 DL4J 導入。這種方法支持與框架無關的部署流水線。
- TensorFlow SavedModel:對於長期生產服務,導出到中立格式(如 ONNX)或針對服務優化的框架特定生產格式(SavedModel、TorchScript)。SavedModel 將計算圖、變量值和元數據打包到單個目錄結構中。
- TorchScript:PyTorch 模型通過腳本或追蹤序列化為 TorchScript。DJL 的 PyTorch 引擎直接加載這些模型,保持完整的計算圖。
- Keras H5:DL4J 導入 Keras 模型(包括 tf.keras 變體),保留層配置和訓練好的權重。
4.2 Python4j:在 Java 中嵌入 Python
DL4J 的 Python4j 模塊解決了需要 Java 中不可用的 Python 庫的場景。Python4j 是一個 Python 腳本執行框架,簡化了將 Python 腳本部署到生產環境的過程。該方法將 CPython 解釋器嵌入到 JVM 進程中,實現雙向調用。
用例包括:
- 在 Java 推理前使用 scikit-learn 流水線進行預處理。
- 從 Java 數據流水線調用專門的 Python 庫(NumPy, SciPy)。
- 在 Java 模型服務旁邊運行基於 Python 的特徵工程。
權衡之處在於需要管理 Python 運行時依賴項和潛在的 GIL 限制。對於高吞吐量場景,模型導出仍然優於運行時 Python 執行。
5. 模型服務與部署模式
5.1 實時推理架構
面向用户的應用,其生產 ML 系統需要低於 100 毫秒的延遲。Java 的線程模型和 JVM 優化在此背景下表現出色。在生產中無需 Python 即可提供 TensorFlow 模型服務,每次預測延遲低於 10 毫秒,並像任何 Spring Boot 服務一樣水平擴展。
同步 REST API:
@RestController
public class PredictionController {
private final Predictor<Image, Classifications> predictor;
@PostMapping("/predict")
public Classifications predict(@RequestBody Image image) {
return predictor.predict(image); // <10ms 典型延遲
}
}Spring Boot 的自動配置、健康檢查和指標與 DJL 或 DL4J 的預測器實例無縫集成。水平擴展遵循標準的微服務模式——在負載均衡器後部署多個實例。
異步處理:
對於非關鍵預測,異步處理可提高吞吐量。Java 的 CompletableFuture、Reactor 或 Kotlin 協程支持併發預測批處理:
// 異步批量預測
List<CompletableFuture<Result>> futures = images.stream()
.map(img -> CompletableFuture.supplyAsync(
() -> predictor.predict(img), executor))
.collect(Collectors.toList());5.2 批量推理模式
批量作業可以容器化並部署到作業調度器或流水線(如 Airflow/Prefect、Kubeflow Pipelines、雲數據管道服務),而在線模型則部署到服務基礎設施(Web 服務器、Kubernetes)。
DL4J 的 Spark 集成處理海量數據集:
// Spark 上的分佈式批量評分
JavaRDD<DataSet> testData = loadTestData();
JavaRDD<INDArray> predictions = SparkDl4jMultiLayer
.predict(model, testData);該模式將推理分佈在集羣節點上,高效處理數百萬條記錄。對於擁有 Hadoop 或 Spark 基礎設施的組織,這種原生集成消除了 Python 橋接開銷。
5.3 邊緣與移動端部署
DJL 支持部署到邊緣設備和移動平台。對於 Android,DJL 提供了針對 ARM 處理器優化的 TensorFlow Lite 和 ONNX Runtime 引擎。自動 CPU/GPU 檢測可適應可用硬件。
用例包括:
- 移動應用中的設備端圖像分類。
- 無需雲連接的 IoT 傳感器異常檢測。
- 需要本地推理的邊緣計算場景。
該方法降低了延遲,提高了隱私性(數據保留在本地),並消除了網絡依賴。
6. 可擴展性考量
6.1 容器化與編排
使用 Docker 進行容器化,允許將模型及其代碼連同所有必需的庫和依賴項打包到一個自包含的單元中,該單元可以在任何地方運行(您的筆記本電腦、雲虛擬機、Kubernetes 集羣中)。
Java ML 服務與傳統 Spring Boot 應用的容器化方式相同:
Dockerfile 模式:
FROM eclipse-temurin:21-jre-alpine
COPY target/ml-service.jar app.jar
ENTRYPOINT ["java", "-jar", "app.jar"]Kubernetes 編排處理擴展、健康檢查和滾動更新。這種統一性意味着現有的 DevOps 流水線無需特殊處理即可擴展到 ML 服務。
6.2 性能優化策略
- 模型量化:通過將 float32 權重轉換為 int8 來減少模型大小和推理時間。TensorFlow Lite 和 ONNX Runtime 支持量化,且精度損失最小。典型收益:模型縮小 4 倍,推理速度加快 2-3 倍。
- 批處理:將預測分組以分攤開銷。DJL 和 DL4J 支持批處理輸入,利用 SIMD 指令,並將每項預測的延遲從 10 毫秒降低到批量 32 條時的每條 2-3 毫秒。
- 模型編譯:ONNX Runtime 和 TensorFlow XLA 將模型編譯為優化的執行圖。在容器構建期間進行預編譯可消除運行時編譯開銷。
- 內存管理:DJL 通過其特殊的內存收集器 NDManager 解決了內存泄漏問題,該管理器及時收集 C++ 應用程序內部的陳舊對象,在測試 100 小時連續推理不崩潰後,在生產環境中提供穩定性。
- 連接池:對於調用外部模型服務器(TensorFlow Serving、Triton)的服務,維護連接池以減少 TCP 握手開銷。
6.3 水平擴展模式
Java ML 服務的擴展方式與無狀態 Web 服務相同:
- 在負載均衡器後部署多個實例。
- 基於 CPU、內存或自定義指標(推理隊列深度)使用 Kubernetes HorizontalPodAutoscaler。
- 實施熔斷器以優雅地處理下游故障。
- 使用 Redis 或 Caffeine 緩存頻繁的預測結果。
推理的無狀態特性(給定模型版本)使得無需協調開銷即可實現彈性擴展。
7. Java 應用的 MLOps
7.1 持續訓練與部署
MLOps 團隊的目標是自動將 ML 模型部署到核心軟件系統中或作為服務組件,自動化整個 ML 工作流步驟,無需任何人工干預。
- Level 0(手動):許多團隊擁有能夠構建先進模型的數據科學家和 ML 研究人員,但他們構建和部署 ML 模型的過程完全是手動的,每個步驟都需要手動執行和手動過渡。這代表了 2025 年 35% 的 Java ML 部署。
- Level 1(ML 流水線自動化):自動化訓練流水線根據新數據重新訓練模型。Jenkins、GitHub Actions 或 GitLab CI 觸發訓練作業,將模型導出到工件倉庫(Nexus、Artifactory),並通知部署系統。版本化的模型自動部署到預發佈環境。
- Level 2(ML 的 CI/CD):持續集成通過添加測試和驗證數據和模型來擴展對代碼和組件的測試和驗證;持續交付關注自動部署另一個 ML 模型預測服務的 ML 訓練流水線的交付;持續訓練自動重新訓練 ML 模型以重新部署。
在 Java 上下文中,這意味着:
- 數據流水線和預處理的自動化單元測試。
- 確保模型預測符合預期輸出的集成測試。
- 金絲雀部署(5% 流量導向新模型版本)。
- 性能下降時的自動化回滾。
7.2 模型版本控制與註冊
將模型視為一等工件:
models/
fraud-detection/
v1.0.0/
model.onnx
metadata.json
v1.1.0/
model.onnx
metadata.json元數據包括訓練日期、數據集版本、性能指標(準確率、F1 分數)和依賴版本。可以使用 Maven 座標引用模型版本:
<dependency>
<groupId>com.company.ml</groupId>
<artifactId>fraud-detection-model</artifactId>
<version>1.1.0</version>
<classifier>onnx</classifier>
</dependency>這種方法將標準的依賴管理實踐應用於 ML 模型,從而實現可重複的構建和可審計的部署。
7.3 監控與可觀察性
ML 模型部署後,需要進行監控以確保其按預期執行。Java 的可觀察性生態系統自然地擴展到 ML 服務:
要跟蹤的指標:
- 推理延遲:通過 Micrometer 統計 p50、p95、p99 百分位數。
- 吞吐量:每秒預測數、每秒請求數。
- 錯誤率:失敗的預測、模型加載失敗。
- 數據漂移:通過統計測試檢測到的輸入分佈變化。
- 模型性能:生產數據上的準確率、精確率、召回率(當標籤可用時)。
與現有工具的集成:
Spring Boot Actuator 暴露 ML 特定指標:
@Component
public class PredictionMetrics {
private final MeterRegistry registry;
public void recordPrediction(long latencyMs, String modelVersion) {
registry.timer("prediction.latency",
"model", modelVersion)
.record(Duration.ofMillis(latencyMs));
}
}Prometheus 抓取這些指標,Grafana 可視化趨勢,並在出現異常(延遲峯值、準確率下降)時觸發告警。
7.4 測試 ML 系統
- 單元測試:驗證數據預處理、特徵工程和後處理邏輯。標準的 JUnit 測試即可滿足。
- 集成測試:測試 ML 模型是否成功加載到生產服務中,並且對真實數據的預測符合預期;測試訓練環境中的模型與服務環境中的模型給出相同的分數。
- 性能測試:使用 JMeter 或 Gatling 模擬負載,在真實流量模式下測量吞吐量和延遲。建立基線並檢測迴歸。
- 影子部署:將新模型版本與現有版本並行運行,記錄預測而不影響用户。在全面部署前比較結果以識別意外行為。
8. Java 在機器學習中表現出色的用例
8.1 企業集成場景
- 金融服務中的欺詐檢測:擁有成熟 Java 生態系統的企業越來越尋求將 ML/AI 模型直接集成到其後端系統的方法,而無需啓動單獨的基於 Python 的微服務。銀行每天通過 Java 系統處理數百萬筆交易。將 DJL 預測器直接嵌入交易處理流水線中,無需外部服務調用即可實現低於 10 毫秒的欺詐評分。
- 實時推薦:基於 Spring Boot 構建的電子商務平台集成 DJL 進行產品推薦。會話數據流經現有的 Java 服務,預測在進程內進行,結果無需網絡延遲即可呈現。
- 日誌分析與聚類:Netflix 的可觀察性團隊使用 DJL 在生產中部署遷移學習模型,以對應用程序日誌數據進行實時聚類和分析,通過字符級 CNN 和通用句子編碼器模型處理日誌行,每條約 7 毫秒。基於 DJL 的流水線分配保留相似性的聚類 ID,從而實現告警量減少和存儲效率提高。
8.2 大數據 ML 工作流
使用 Spark 或 Hadoop 每天處理 TB 級數據的組織受益於 DL4J 的原生集成。在歷史數據上訓練模型、對新記錄進行評分以及更新模型——所有這些都在 Spark 流水線內完成,無需 Python 橋接。
示例工作流:
- 從 HDFS 或 S3 將數據讀入 Spark DataFrames。
- 使用 Spark SQL 進行特徵工程。
- 在集羣上分佈式訓練 DL4J 模型。
- 使用訓練好的模型對新數據評分。
- 將結果寫回數據倉庫。
整個端到端流程保持在 JVM 中,避免了序列化開銷和 Python 互操作的複雜性。
8.3 微服務與雲原生應用
Spring Boot 應用程序主導着企業微服務架構。通過 DJL starters 添加 ML 能力可無縫集成:
- 熔斷器:Resilience4j 模式保護 ML 服務免受級聯故障影響。
- 服務發現:Eureka 或 Consul 註冊 ML 預測服務。
- 配置:Spring Cloud Config 管理模型端點和參數。
- 追蹤:Zipkin 或 Jaeger 追蹤通過 ML 流水線的請求。
這種統一性簡化了運維——ML 服務與業務邏輯服務以相同的方式部署、擴展和監控。
8.4 邊緣計算與物聯網
Java 的“一次編寫,隨處運行”理念擴展到邊緣設備。為 ARM 處理器編譯的 DJL 模型可以在 Raspberry Pi、NVIDIA Jetson 和工業 IoT 網關上運行。用例包括:
- 預測性維護:本地分析傳感器數據,異常時觸發警報。
- 視頻分析:在邊緣處理安防攝像頭視頻流,減少帶寬。
- 智能家居設備:設備端語音識別和自然語言理解。
GraalVM 原生鏡像編譯生成獨立的可執行文件,內存佔用小(< 50MB),啓動速度快(< 100ms),非常適合資源受限的環境。
8.5 法規與合規要求
隨着歐盟《人工智能法案》等法規的收緊,集成重點轉向模型的左移安全性——在流水線中掃描偏見、可解釋性和合規性。Java 的強類型、顯式異常處理和成熟的日誌記錄框架便於審計追蹤和滿足可解釋性要求。
金融和醫療保健行業通常要求所有代碼(包括 ML 模型)通過經過驗證的、帶有審批工作流的流水線進行部署。與引入 Python 運行時依賴相比,Java ML 服務能更自然地與現有的治理流程集成。
9. 結論:我們的收穫
Java 在機器學習中的作用代表了務實的生產工程,而非研究創新。我們分析得出的主要見解:
- 框架選擇取決於上下文:DJL 在推理和模型服務方面表現出色,具有引擎靈活性,是雲原生微服務的理想選擇。DL4J 提供了與大數據框架集成的完整 ML 生命週期功能,適用於需要分佈式培訓的組織。TensorFlow Java 服務於深度投入 TensorFlow 生態系統、需要直接模型兼容性的團隊。
- 多語言模式行之有效:在 Python 中訓練並在 Java 中部署,利用了每種語言的優勢。ONNX 和 SavedModel 格式支持無縫交接。Python4j 在必要時彌合差距,但出於性能考慮,模型導出仍是首選。
- 生產性能至關重要:Netflix 7 毫秒的推理延遲證明 Java ML 服務能夠滿足實時性能要求。適當的內存管理(NDManager、ND4J)、模型優化(量化、編譯)和水平擴展提供了生產級系統。
- MLOps 成熟度參差不齊:只有 20% 的 Java ML 部署達到了 Level 2 CI/CD 成熟度,具備自動重新訓練和監控。機會在於將已建立的 DevOps 實踐——容器、編排、可觀察性——應用於 ML 工作流。
- Java 在特定場景中表現出色:企業集成(欺詐檢測、推薦)、大數據 ML 流水線(Spark/Hadoop)、微服務架構、邊緣計算和法規合規代表了 Java 的特性——穩定性、線程處理、生態系統成熟度——相比以 Python 為中心的方法提供優勢的領域。
- 內存管理區分了框架:DJL 的 NDManager 解決了管理 JVM 應用程序中本機內存的關鍵挑戰,實現了 100 小時以上的生產運行而無內存泄漏。這種生產就緒性將企業可行的框架與實驗性綁定區分開來。
- 差距正在縮小:雖然 Java 不會取代 Python 在 ML 研究中的地位,但像 DJL 和 DL4J 這樣的框架已經足夠成熟,可用於生產部署。生態系統現在支持完整的推理生命週期,性能可與 Python 解決方案相媲美。
未來可能涉及更深層次的集成——Spring AI 為 Java 帶來 LLM 能力,GraalVM 原生鏡像為無服務器 ML 實現即時啓動,以及 MLOps 和 DevOps 實踐之間持續的融合。對於擁有大量 Java 投資的組織,問題從“我們能用 Java 做 ML 嗎?”轉變為“我們如何優化 Java ML 部署?”。
隨着 ML 在企業系統中變得無處不在,Java 的生產優勢——穩定性、性能、工具成熟度和操作熟悉度——使其成為推理層的務實選擇,即使 Python 在訓練和實驗中仍占主導地位。多語言方法——在 Python 中訓練,在 Java 中部署——代表的不是妥協,而是對每個平台獨特優勢的優化。
【注】本文譯自:AI and Machine Learning in Java: TensorFlow, DJL, and Enterprise AI