我們通過在操作系統裏進行一些簡單的聯繫,可以加深對 Unicode 編碼這些基礎知識的理解和記憶。
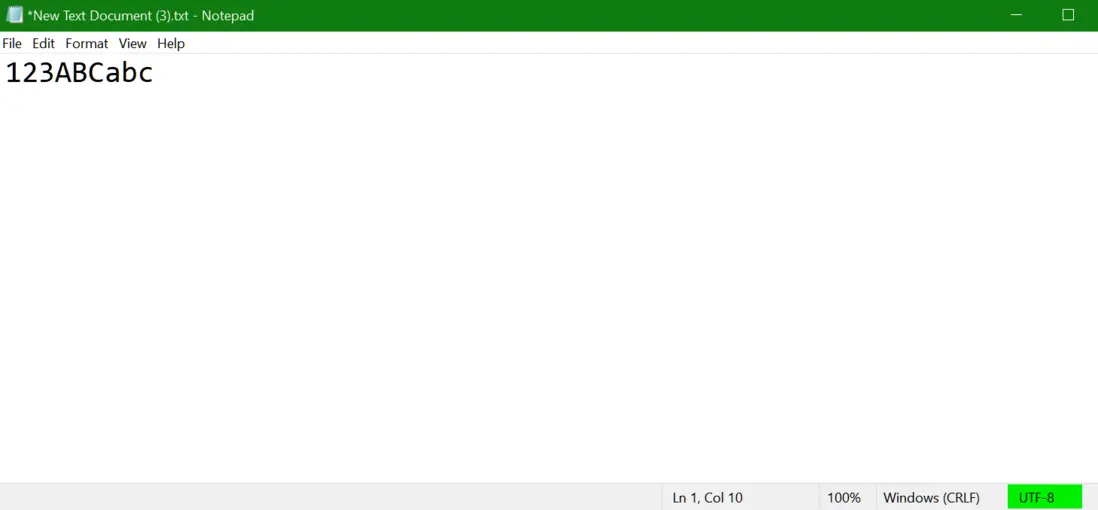
Windows10 操作系統下,新建一個記事本文件,輸入 123ABCabc
默認的 encoding 格式為 UTF8:
使用 winhex 這款 16進制文件編輯器打開該記事本文件:

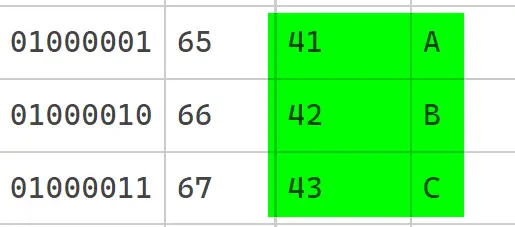
看到正文區域的 31 32 33 41 42 43 61 62 63。這些數字代表什麼含義?
UTF8 (Universal Character Set/Unicode Transformation Format) 是針對 Unicode 的一種可變長度字符編碼。它可以用來表示 Unicode 標準中的任何字符,而且其編碼中的第一個字節仍與 ASCII 相容,使得原來處理 ASCII 字符的軟件無須或只進行少部分修改後,便可繼續使用。
ASCII 是美國標準信息交換代碼(American Standard Code for Information Interchange)的縮寫, 為美國英語通信所設計。它由 128 個字符組成,包括大小寫字母、數字0-9、標點符號、非打印字符(換行符、製表符等4個)以及控制字符(退格、響鈴等)組成。
ascii 對照表可以從這個鏈接獲得。
其中數字 1,2,3 的 UTF8(ASCII) 編碼分別為 31,32和33:
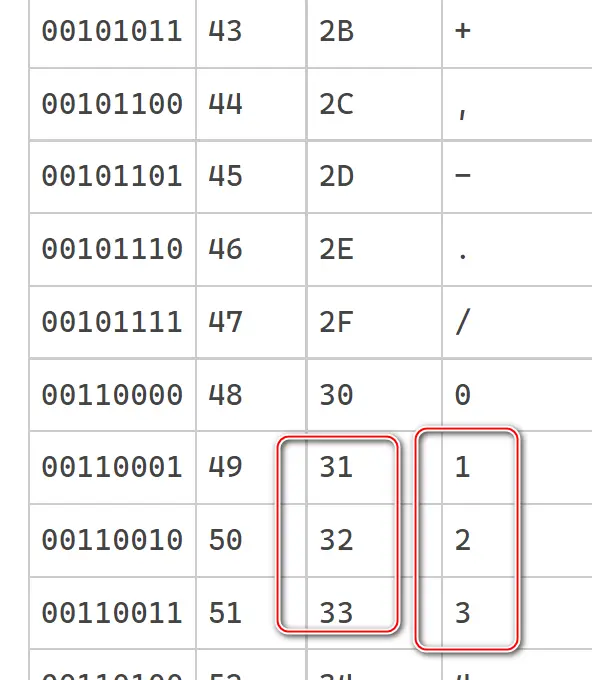
大寫的 A B C 的 UTF8(ANSI) 編碼為 41 42 43,小寫字母為 61 62 63:
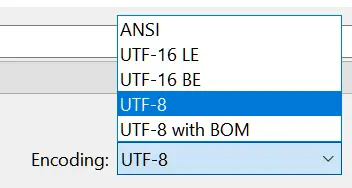
ENCODING 改成 ANSI:

winhex 中的內容不變。
記事本的 Encoding 改成 UTF8 with bom 之後:
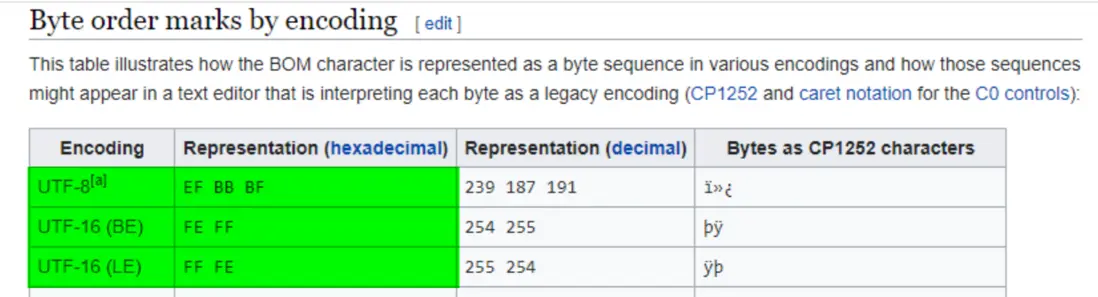
winhex 文件內容的前部,多了三個EF BB BF

首先,BOM 的含義是 byte order mark,BOM(byte order mark)是為 UTF-16 和 UTF-32 準備的,用於標記字節序(byte order)。微軟在 UTF-8 中使用 BOM 是因為這樣可以把 UTF-8 和 ASCII 等編碼明確區分開。
可以把這個 EF BB BF 理解成一種特殊的標記符,用於顯式表明該文件的編碼為 UTF-8:
https://en.wikipedia.org/wiki...
相應的,在記事本里將 encoding 改成 UTF-16(BE) 之後,文件頭就變成了 FE FF,並且以前的 31 32 33 變成了雙字節 00 31 00 32 00 33:

下面再試試中文。
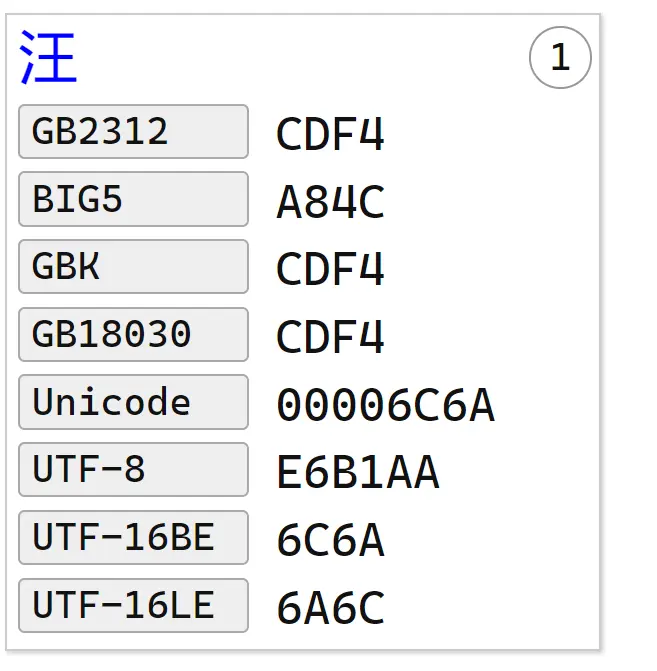
在記事本里輸入一箇中文“汪”:
汪 UTF8

E6 B1 AA 這是漢字 汪 的三字節 Unicode 編碼,來自網站。
AA 佔一個字節,8位:1010 1010

UTF16-LE 6A6C

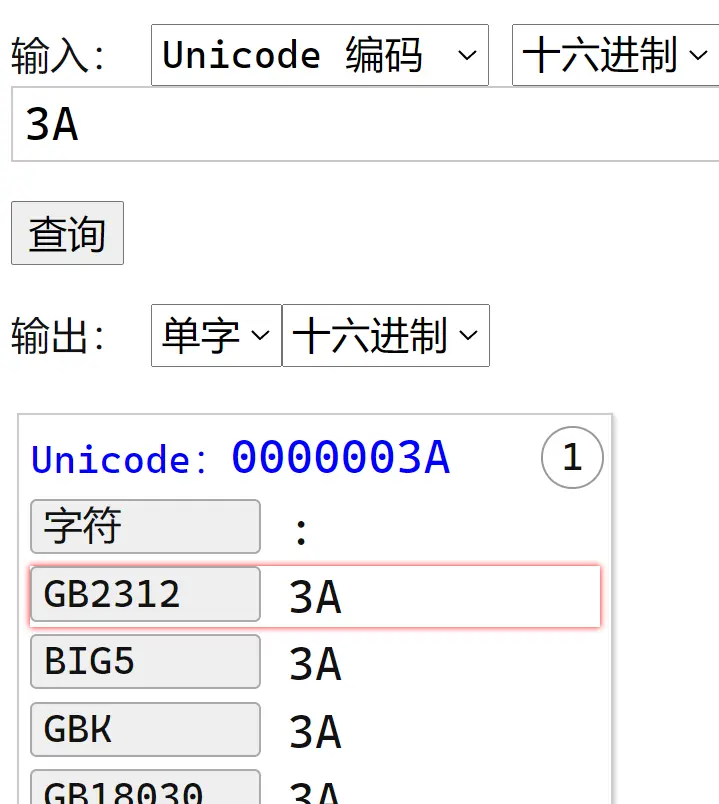
3A 代表冒號:
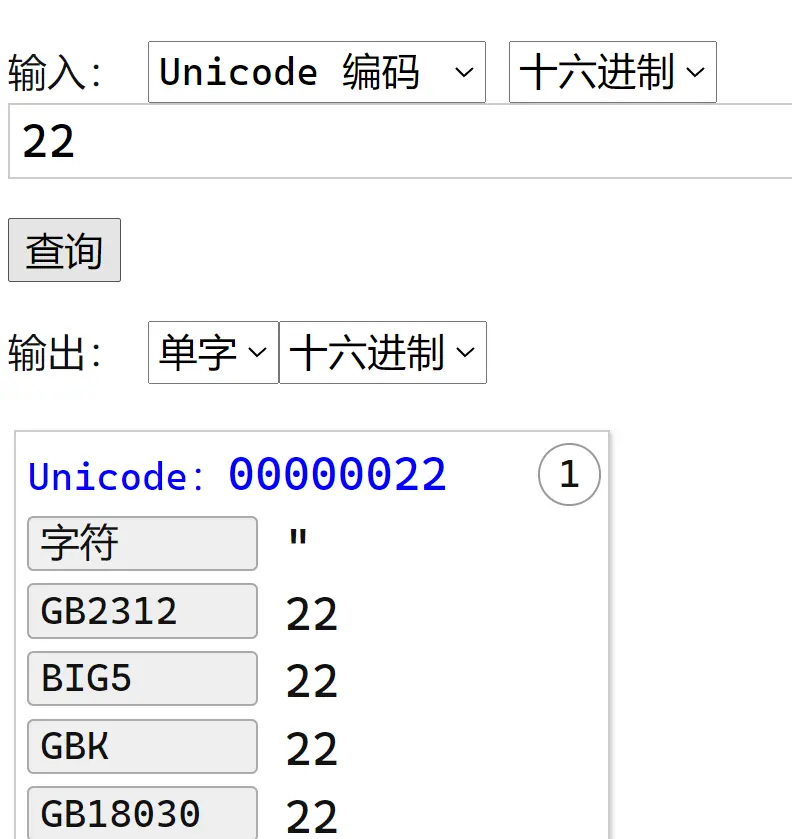
22 代表引號:
更多Jerry的原創文章,盡在:"汪子熙":