

1. 前言
之前總結了一篇基於現有業務線在停機重啓時會產生RPC和MQ調用強殺導致業務數據不一致文章,文中通過優雅停機改造對RPC服務進行反註冊和MQ進行暫停消費,進而可以解決在停機時強制kill掉RPC線程或者MQ線程導致數據不一致現象,具體的原文大家感興趣可以去看一下。Ok前情提要結束,最近在一些核心應用上線重啓的時候又出現了業務訂單數據不一致的情況,通過排查定位發現還是因為停機不夠優雅,罪魁禍首是定時任務執行時間過長,在上線重啓的過程中定時任務沒有執行完成而被強行kill,詳細分析及處理方案如下。

2. 問題簡述
為了便於快速理解上線停機時導致業務數據不一致的的具體環節,簡要的繪製一個業務流程圖如下,其中以資金前置應用為例,定時任務運行在資金前置應用上,當涉及到資金前置應用的重啓或者停機時,之前的優雅停機改造是會先把RPC反註冊和MQ暫停消費,然後在預留60s的時間以供存活的線程執行完畢。其實這麼做確實還是有缺陷的,就比如60s也不能確保所有的存活線程執行完畢,文中前言中所提到的問題就是這個,由於定時任務執行時間大於60s,所以就會存在在定時任務尚未執行完成的情況下,強行把該定時任務給銷毀掉了,恰巧兩個數據表的更新還不在一個位置,導致停機完成的第60s正好在其中的一個表更新完成和發送MQ去更新另一個數據表之間,這樣就會存在兩個表的數據不一致。
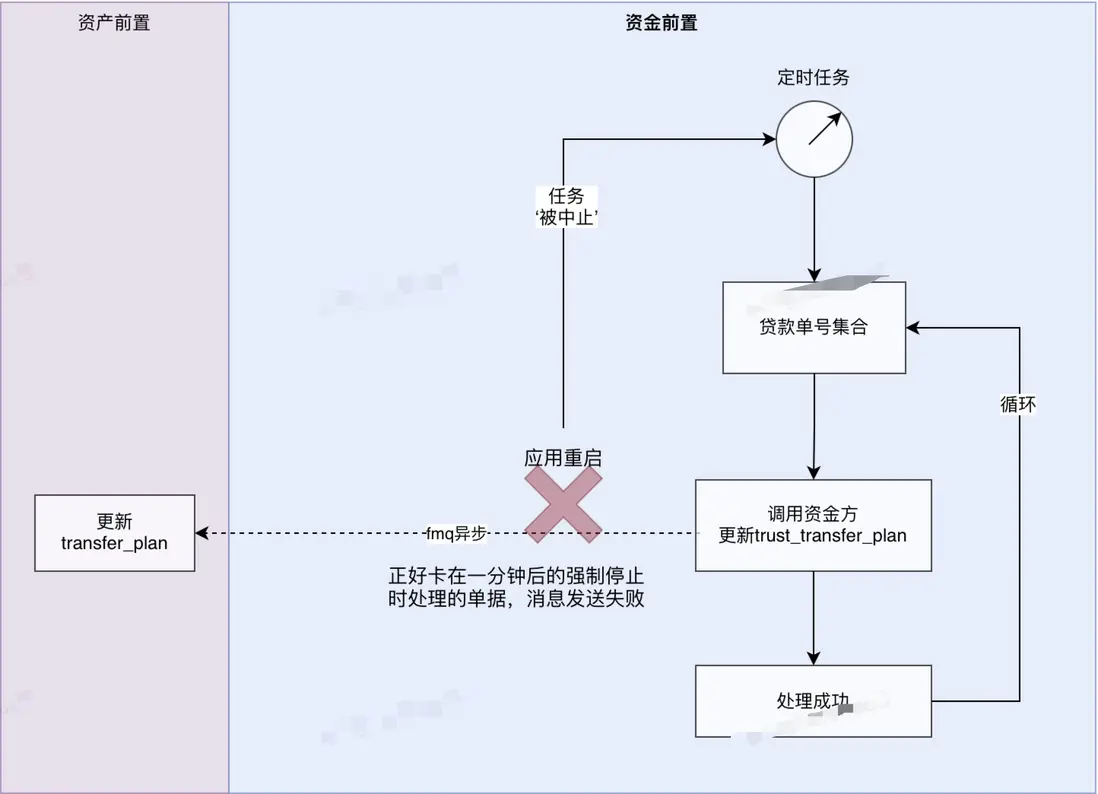
現有中斷問題流程圖
3. 解決方案
通過對上述問題的調研及分析,目前有以下幾種解決方案。
3.1 拆分子任務
當然這個方案治標不治本,降低定時任務的執行時間只能説會降低數據不一致產生的頻次,即使將定時任務優化到執行完成進需要2s,上線的時候只要不刻意避開定時任務的執行的話,還是會存在在倒計時結束的第60s時正好撞上定時任務正在執行的場景。不過還是藉此機會排查了一下定時任務耗時的原因,其主要原因如下。其中以目前耗時比較長的定時任務(還款結果查回)為例。

定時任務1
通過梳理還款結果查詢定時任務發現,主要的耗時點有兩個:數據量大和併發量小。其中數據量大這個只能通過優化索引結構來降低耗時,併發量小可以通過拆分子任務或者修改代碼批量發送數據到業務方來提速。
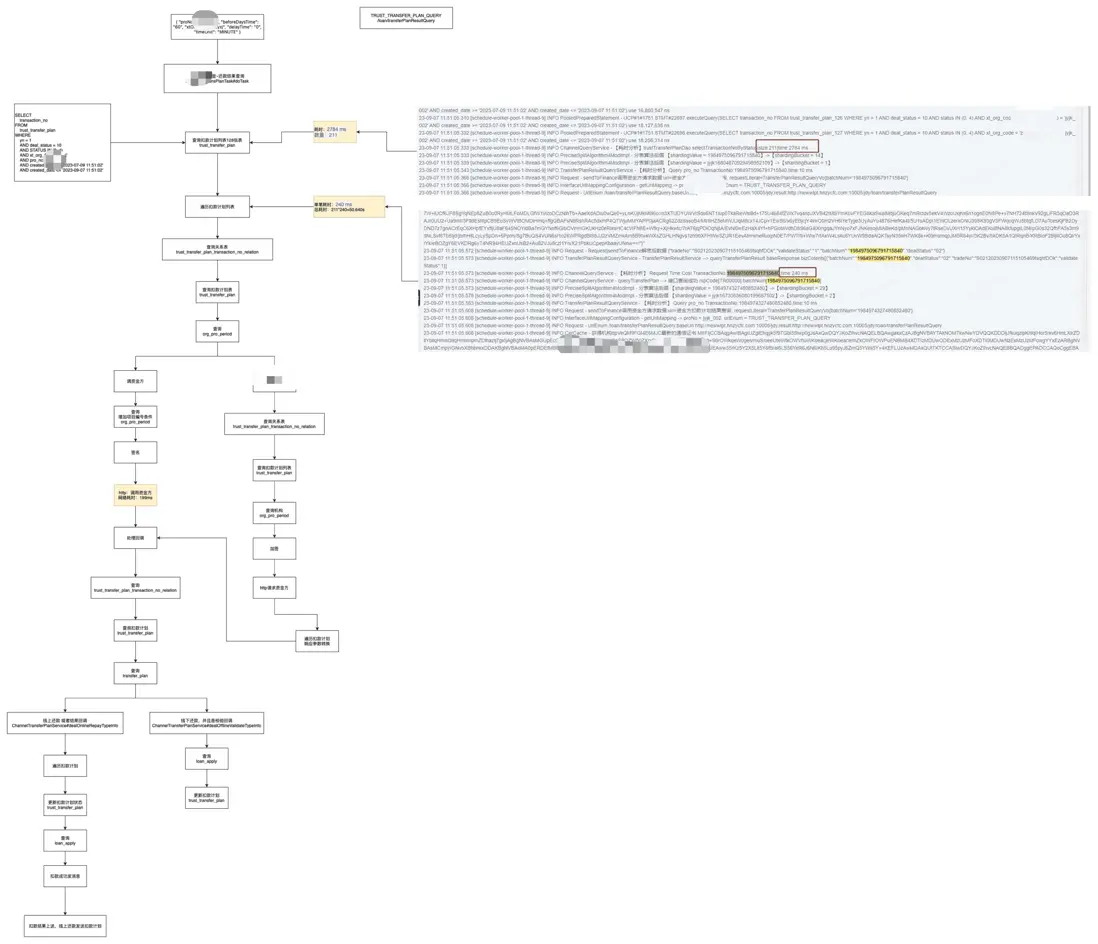
定時任務2
同理,該定時任務制約因素同上。通過調研EasyJob平台發現提供了拆分子任務功能,可以通過平台拆分來降低耗時,並且不對現有的業務代碼進行修改。emm,然而通過跟下游業務方溝通發現,受業務方併發tps制約,不建議通過此方式來提速。那降低耗時方案不是最佳的,可不可以通過設置一個全局變量呢?通過共享該變量的值,這樣可以在停機的時候判斷是否還有定時任務在處理。因此,方案二應運而生。
3.2 共享信號量機制
既然定時任務無論執行多少時間都可能會出現這個停機不優雅的問題,那麼我們可以嘗試增加一個全局變量,其主要作用是在定時任務中和優雅停機任務中共享達到優雅停機的目的。
@Component
@Slf4j
public class ShutDownHook {
/**
* 定時任務停止執行標識
*/
public static volatile int interrupt = 0;
@PreDestroy
public void destroyHook() {
try {
JobService jobService = schedulerFactoryBean.getObject();
if (null != jobService) {
boolean stop = jobService.stop();
if (stop) {
log.info("停止EasyJob完成。");
} else {
log.info("停止EasyJob失敗");
}
} else {
log.info("停止EasyJob沒執行");
}
} catch (Exception e) {
log.error("停止EasyJob異常", e);
}
interrupt = 1; //Easyjob停止後修改標識
}
}
@Component
public class xxxTask implements ScheduleFlowTask {
@Override
public TaskResult doTask(ScheduleContext scheduleContext) throws Exception {
transactionNoList.forEach(transactionNo ->{
if (0 != ShutDownHook.interrupt) {
throw new RuntimeException("停機中斷");
}
// 業務邏輯
...
});
return TaskResult.SUCCESS_BLANK;
}
}
通過interrupt標識作為共享變量,這塊就涉及到一個問題,如果多個線程同時修改這個變量會不會導致數據錯誤呢?為了避免出現和這個問題,在優雅停機腳本中我們使用volatile關鍵字來修飾該變量,通過先初始化停機標識interrupt,利用volatile關鍵字中的可見性(即:一個線程對其修改立即對其餘線程可見)可以在停機腳本反註冊掉定時任務服務後,修改該停機標識為1,然後在定時任務執行業務邏輯數據更新時,每次執行前判斷停機標識是否為1(即是否已開始進行EasyJob服務反註冊),假如停機腳本已經開始EasyJob服務反註冊,則不繼續進行後續業務邏輯操作,直接拋出運行時異常RuntimeException。
那麼此時還有一個問題,定時任務在上線期間中斷後,能不能在我們無感知的情況下進行重做呢?難不成我們每次都需要去根據異常來確認在上線期間是否存在定時任務中斷,如果有的話難不成我們還要手動再次執行麼?亦或者是等到定時任務的下一次自動執行的時間點執行?那麼有沒有一種方案可以自動立即重做呢?
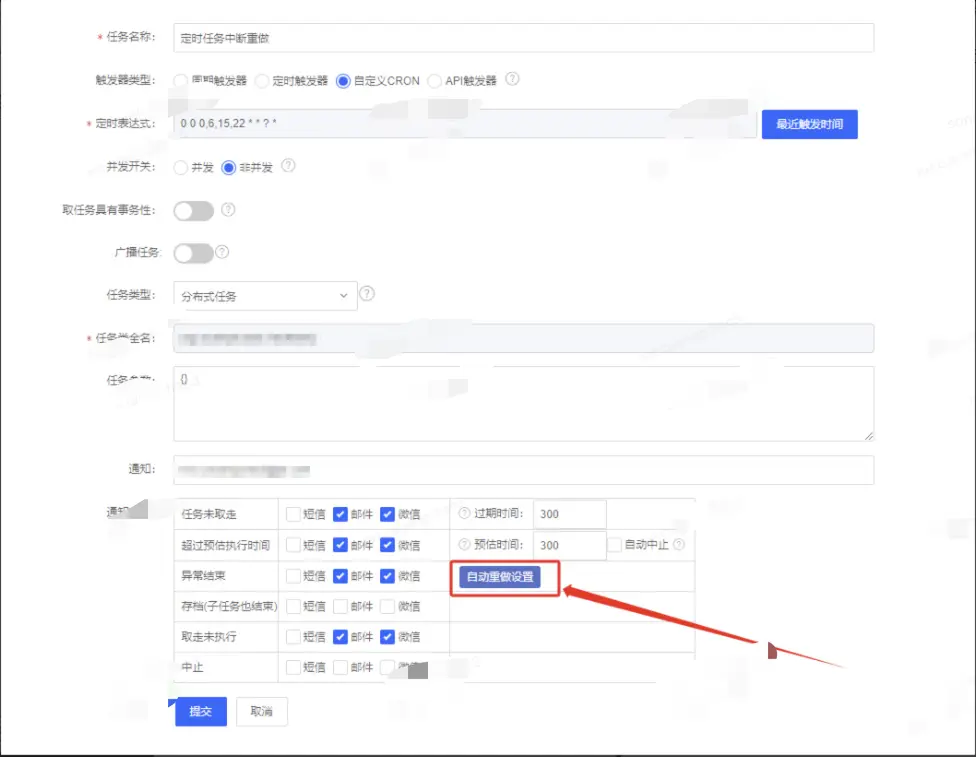
自動失敗重做機制
通過調研EasyJob定時任務平台發現提供了自動重做機制,通常我們一般部署的服務都是多台機器,即當我們上線的這台機器上面的定時任務執行中斷後,可以通過配置自動重做機制來自動選擇現有的存活的機器執行,其中自動重做裏面中設置的參數如下:可以通過調整參數來控制第一次重做延遲時間、後續的重做時間間隔、以及最多重做次數。為什麼要配置重做次數呢?一般機器上線是陸續進行的,極端情況下,定時任務執行時間完全覆蓋了所有機器的上線時間,那麼定時任務就會分別在每台機器上面中斷一次,最終還是迴歸到最開始的那台機器上面繼續執行(此刻該機器已上線完成)。所以針對定時任務時間執行比較長的,需要根據實際機器設置合理的重做次數。
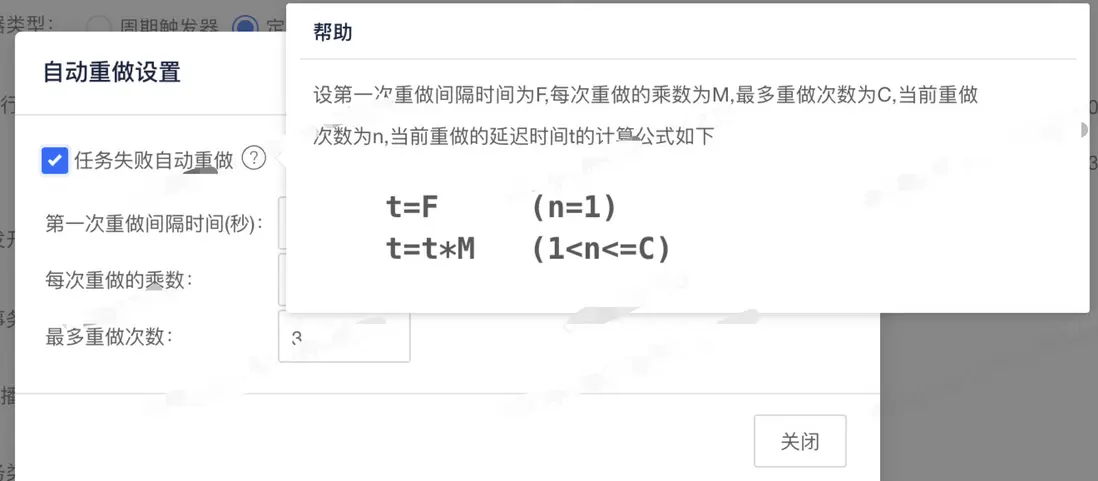
參數詳情
3.3 拆分子任務&共享信號量
另一個方案其實就是融合了方案一(拆分子任務)和方案二(共享信號量),這樣的好處就是能夠解決在3.2節末尾提到的上線期間極端情況下,定時任務執行時間過長而在沒台機器上都中斷重做場景。但是受限場景和方案一也是一致的,目前受下游業務方能夠接受的最大併發限制而暫緩實施。
3.4 包裝成事務
因為涉及到更新兩個數據表操作,要想避免兩個數據表數據不一致,最常用的做法就是把更新兩個數據表的操作封裝成一個事務操作,這樣的話就無需考慮定時任務的執行時間,由於事物的原子性,肯定不會出現兩個數據表的數據不一致情況。當然這個方案的缺點就是需要重構現有的業務邏輯,需要把MQ的下游重構,把兩個數據表的更新位置重構一下。這塊對現有的業務邏輯代碼有侵入,並且需要重構現有的業務流程,目前不太建議這麼修改。
4. 總結
ok,通過這次優化應該能夠使得現有的應用在重啓或者是上線停機時,能夠避免定時任務中斷而導致的數據更新不一致場景。以上是優雅停機第二彈內容。以上。
作者:京東科技 宋慧超
來源:京東雲開發者社區 轉載請註明來源