

低代碼並不僅僅意味着“可視化拖拽”或“快速交付”,而是在深層次上重構軟件開發的 知識體系與勞動分工。它通過模型驅動(model-driven)與規則引擎,將底層代碼抽象化,使非專業開發者能夠基於業務邏輯完成系統構建。這一過程顯著降低了入門門檻,但同時帶來了 技術治理與專業價值的再平衡。
- 開發門檻的轉移:低代碼降低了語法和編碼層面的要求,但並未消解對 邏輯建模、數據管理與流程設計的依賴。開發能力正在從“編寫代碼”轉向對 抽象規則與系統約束的理解與操控。
- 協作模式的重構:傳統模式下,開發人員與業務人員各自承擔明確職責。低代碼打破了這種分工,推動“業務即開發”的趨勢。然而,角色邊界的弱化也可能導致 知識碎片化、責任模糊化,需要新的治理機制與協作規範。
- 專業知識的再層級化:低代碼並未消除專業開發者的作用,而是推動其價值向 系統架構、複雜邏輯編排、安全與合規治理等高階層面集中。低層級的編碼勞動被平台封裝,但 複雜性管理與不可自動化的知識仍是專業人員不可替代的核心。
- 效率與風險的並存:低代碼提升了開發效率與業務響應速度,但也帶來 技術債務積累、平台依賴、可維護性下降等隱憂。這些挑戰需要在工具層之外,建立起 質量控制、生命週期治理與安全框架。
因此,低代碼不應被單純理解為一場“效率革命”,而更是一次 社會—技術秩序的再生產。它使軟件開發呈現出更強的民主化趨勢,但同時重塑了職業分工和價值層級。在這一過程中,關鍵問題並非“程序員是否被取代”,而是 如何在新的協作與治理結構中,確保專業開發者的獨特能力得到延展與再定位。
可視化工作流
流程功能
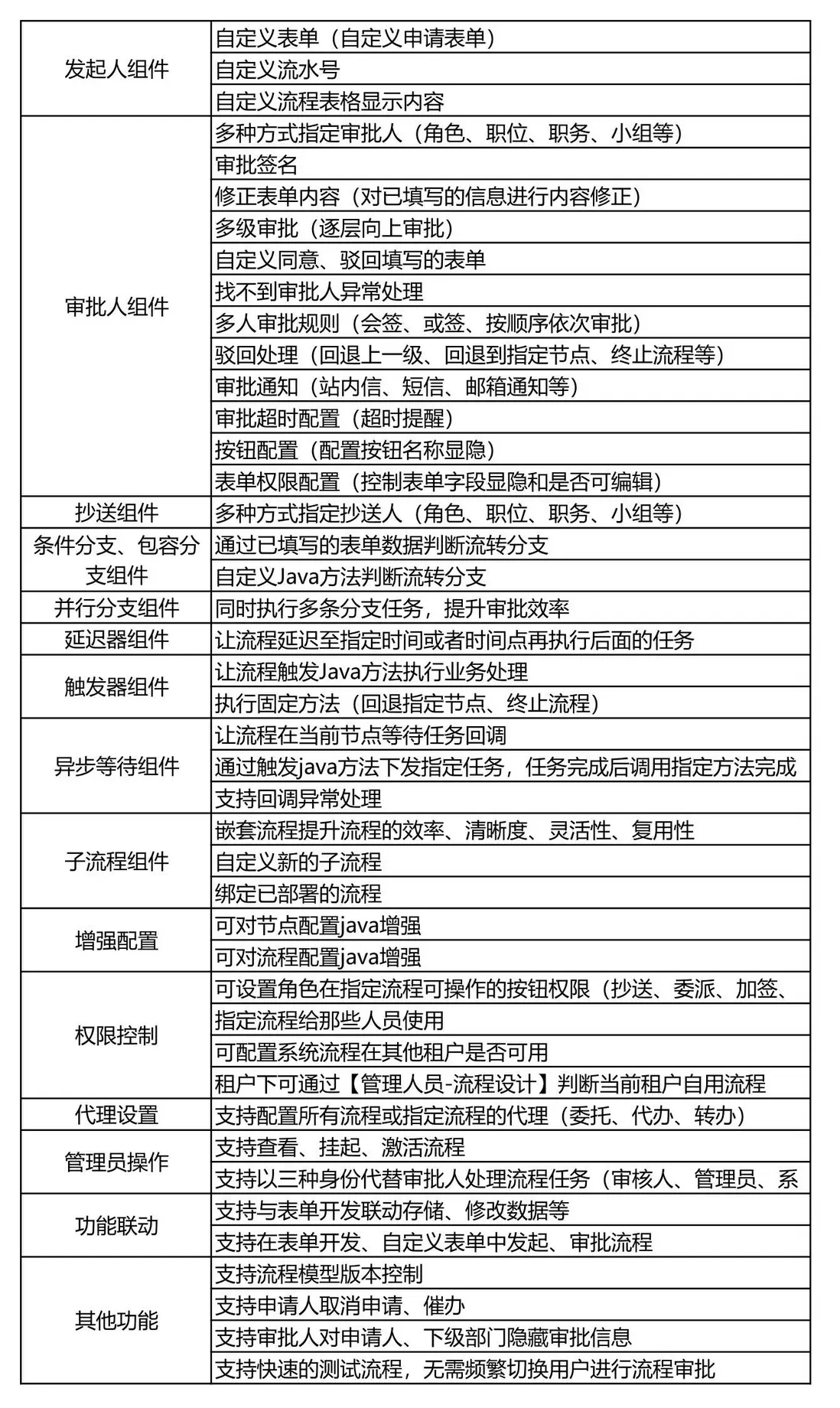
流程功能清單

流程使用示例
系統界面

流程參數設置
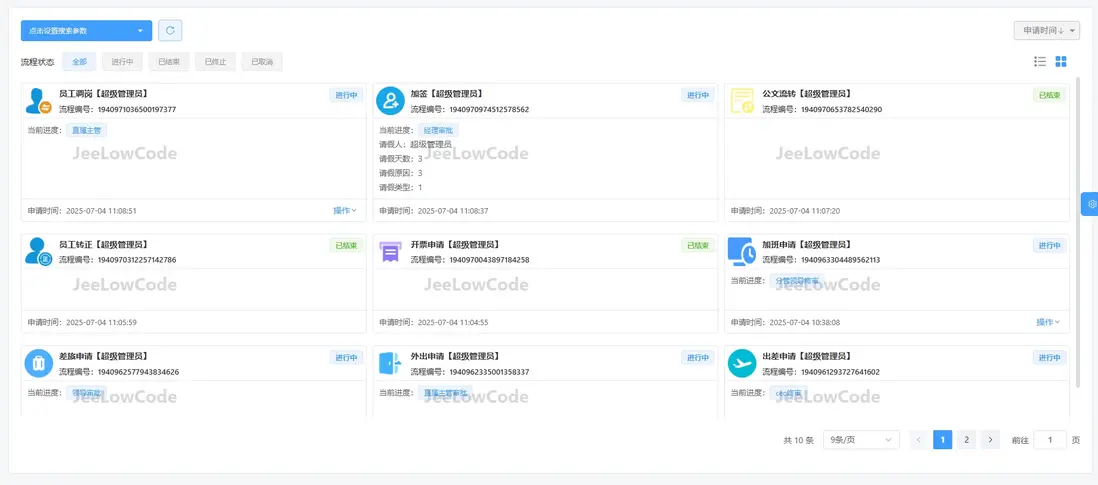
流程示例
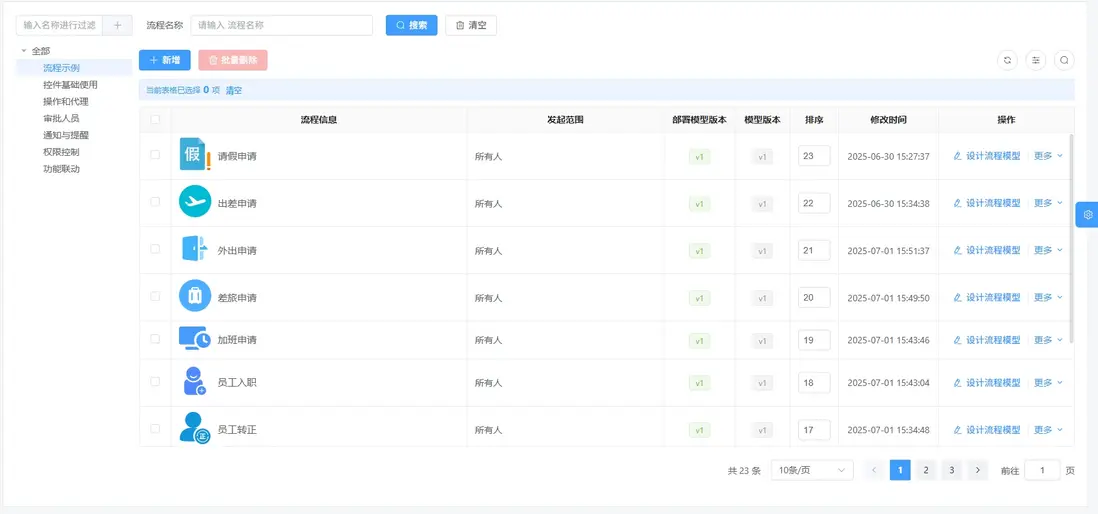
流程設計(請假申請)
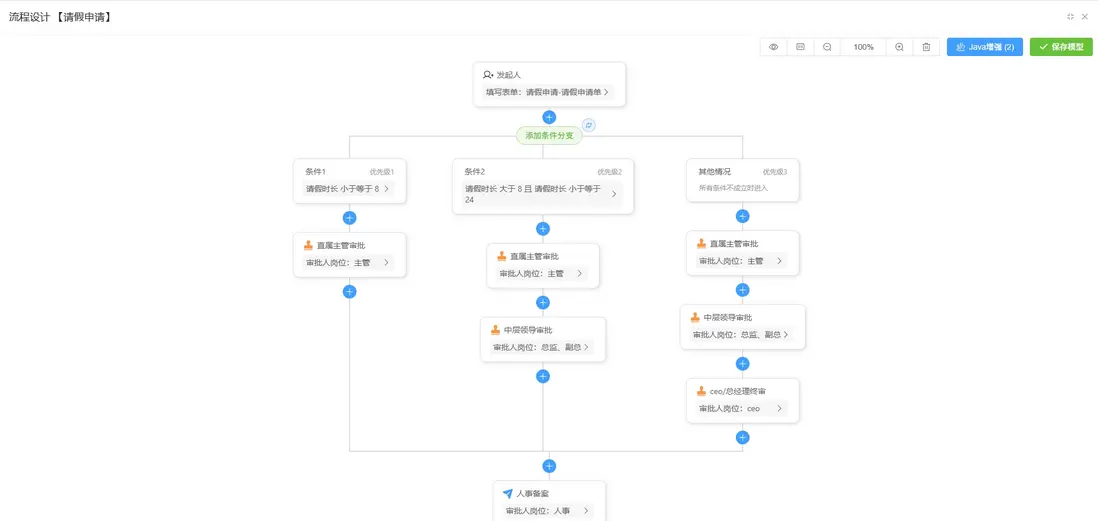
流程設計(主管審批)
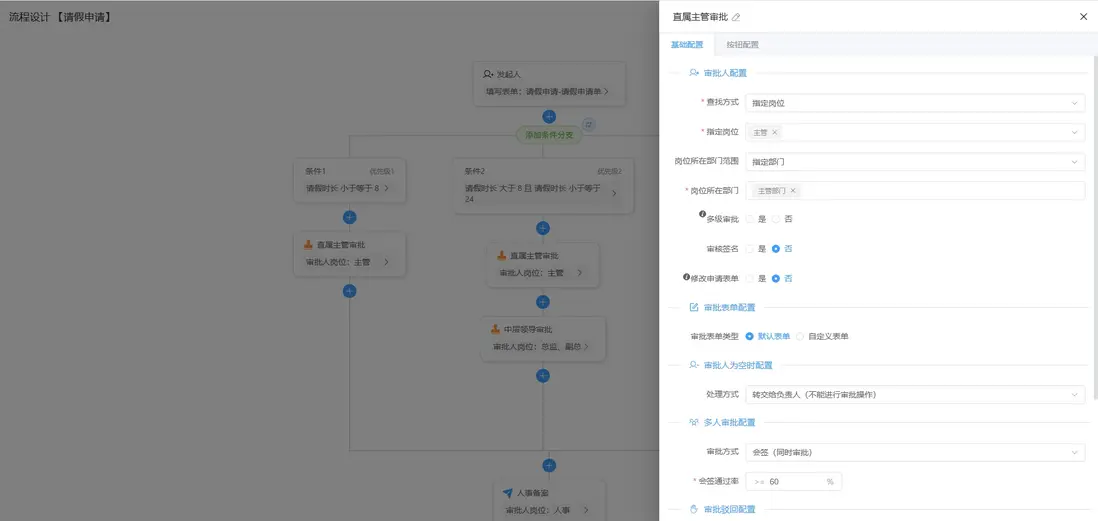
流程設計(完整請假流程)
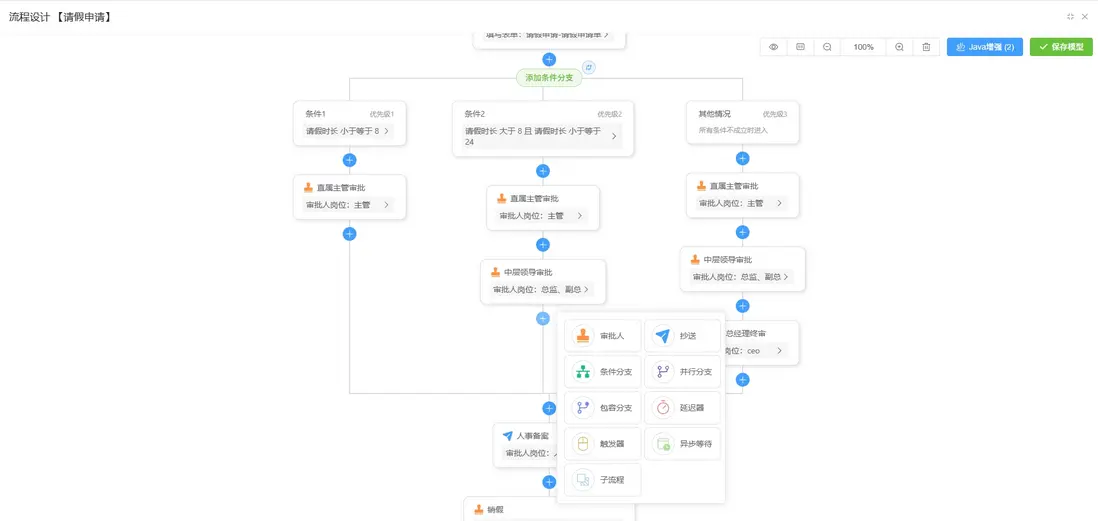
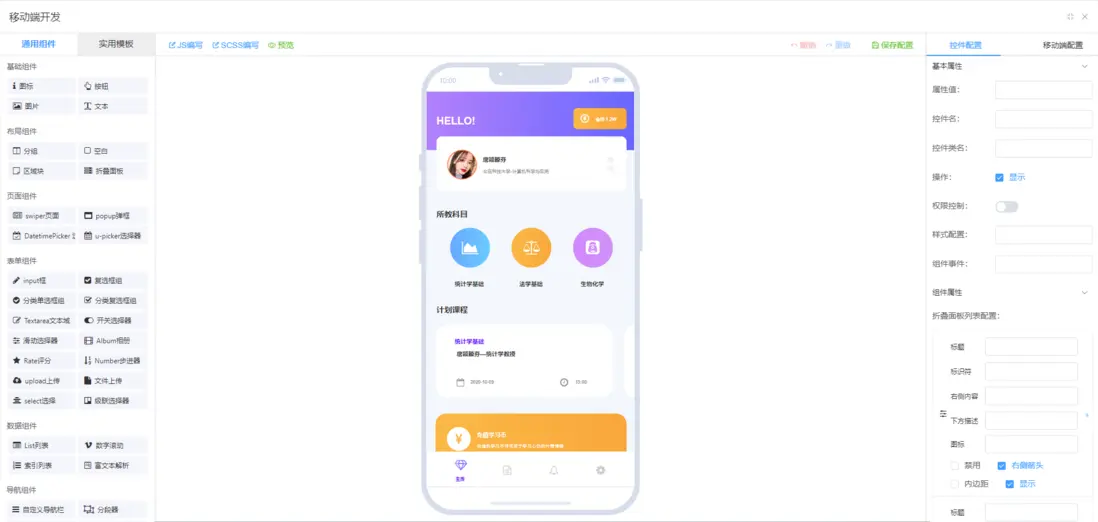
可視化開發:低代碼平台中的結構化構建機制
低代碼平台中的可視化開發,本質上是一種基於 圖形化建模與配置驅動的系統構建方式。通過將用户界面(UI)與邏輯流程抽象為參數化組件,平台實現了對業務需求的更高層次表達。此類機制在降低編碼複雜度的同時,保留了對核心邏輯的控制力,適用於中等複雜度的業務系統快速迭代與交付。
1. 組件化設計:抽象複用與邏輯分離
平台通常內置標準化的 UI 組件與邏輯單元,支持通過參數化配置實現功能定製。組件以模塊化方式封裝,具備良好的複用性與組合性。表單、表格、流程節點等均可作為可拖拽調用的獨立單元,邏輯事件與數據綁定通過配置驅動完成。
這一模式實現了界面構建與邏輯實現的有效分離,使非專業開發者能夠參與開發流程。組件參數結構常基於 JSON Schema或 領域專用語言(DSL)實現,支持運行時動態加載與渲染。但在複雜業務場景中,組件封裝過度可能帶來 靈活性下降與維護成本上升的問題。
2. 實時渲染:增量更新與數據綁定
基於 MVVM 模式的渲染引擎支持雙向數據綁定,實現 UI 與數據狀態的實時同步。多數平台採用虛擬 DOM 與 diff 算法,通過最小化更新減少渲染開銷。
該架構顯著提升了前端響應性能,並允許開發者在可視化界面中即時驗證交互效果。跨平台響應式渲染機制進一步增強了多端一致性,降低了調試與適配成本。然而,雙向綁定與頻繁的狀態更新在高併發場景下可能導致 性能瓶頸與狀態管理複雜化。
3. 分佈式協作:結構化版本控制與變更跟蹤
低代碼平台通常實現類似 Git的版本控制機制,但採用 結構化差異比對而非傳統文本比較。平台對組件與邏輯的變更進行語義層級追蹤,並結合衝突檢測與自動合併,提升多人並行協作的效率。
同時,平台常集成分支管理、變更審批與操作日誌,適配中型以上項目的多人開發需求。該機制雖提高了協作效率,但也對 平台的數據模型一致性與權限治理提出了更高要求。
4. 一鍵部署與分佈式事務處理
平台往往內置容器化工具鏈(如 Docker、Kubernetes)與 CI/CD 流程,支持自動化構建與部署。構建流程通常涵蓋靜態資源打包、後端服務編譯、依賴注入與配置渲染,最終生成可部署的鏡像。
在分佈式系統場景中,平台通過嵌入 Saga或 兩階段提交(2PC)協議實現事務一致性。Saga 模式基於補償機制,適用於鬆耦合服務環境;2PC 則滿足強一致性需求,但存在阻塞與性能風險。如何在不同業務語境下 權衡一致性與可用性,成為低代碼平台落地過程中的核心議題。
核心引擎機制:低代碼平台的技術運行基礎
低代碼平台的運行並非依賴單一工具鏈,而是通過多核心引擎的協同工作,形成具備高性能、可擴展性與工程化特徵的技術體系。這些引擎分別承擔數據處理、業務功能封裝、模板渲染、可視化展示與系統治理等任務,共同構建出一個自洽的工程閉環。
1. SQL 引擎:查詢優化與並行執行
SQL 引擎是數據訪問與處理的核心,其性能直接影響平台整體響應能力。典型特徵包括:
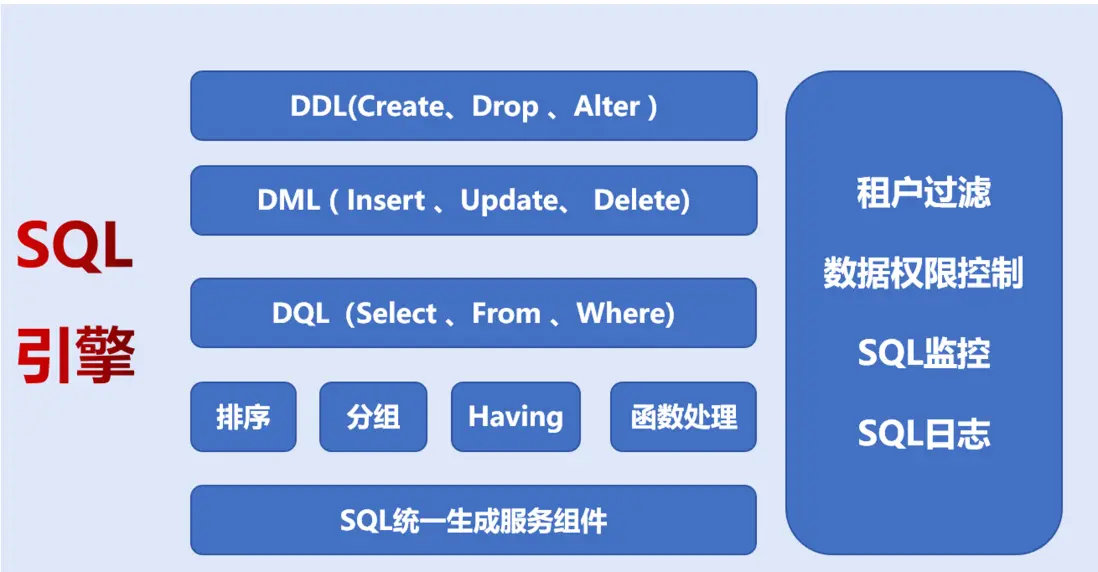
- 查詢優化器:通過基於代價模型的執行計劃生成機制,結合統計信息、索引選擇、謂詞下推與連接重排序等手段,實現複雜查詢的高效執行,尤其適用於多表關聯與大規模數據集分析。
- 並行執行框架:支持多線程併發、數據分區與緩存調度策略。在高併發場景(如訂單處理系統)中,可通過分區鍵設計提升吞吐量,降低鎖衝突與等待開銷。
2. 功能引擎:模塊化與運行時擴展
功能引擎主要負責業務功能的封裝與動態擴展,強調鬆耦合與靈活性:

- 插件化架構:常見的權限控制、工作流管理等模塊以插件形式提供,支持運行時加載與卸載,降低系統核心的複雜性。
- 動態服務註冊:依託控制反轉(IoC)機制與按需加載策略,控制服務實例的初始化時機,避免冗餘資源佔用。
- 規則引擎集成:提供可配置的規則解析與運行時執行能力,用於支撐審批流程、條件判斷等動態業務邏輯。
3. 模板引擎:結構生成與渲染優化
模板引擎在視圖層實現數據與結構的解耦,注重性能與可維護性:

- 動態綁定機制:基於虛擬 DOM 與數據驅動框架,實現數據狀態與 UI 界面的雙向同步,適合高動態表單或數據展示場景。
- 編譯優化:通過模板預編譯、靜態節點提取與批量 DOM 操作合併,減少運行時渲染的性能開銷。
- 繼承與複用結構:支持多層級模板繼承與複用,增強應用在多業務線下的結構一致性與可維護性。
4. 圖表引擎:可視化渲染與交互優化
圖表引擎面向大數據可視化場景,強調高性能與交互能力:

- GPU 加速渲染:基於 WebGL 的圖形處理方案可提升複雜圖表與實時動畫的渲染效率,適用於高併發數據可視化任務。
- 增量更新機制:採用數據差異化檢測,僅重繪發生變化的部分,提升幀率並減少全量刷新帶來的性能損耗。
- 擴展接口:提供 3D 圖表、地理信息可視化、層級圖等多樣化組件,並預留二次開發能力,滿足特定業務場景的定製需求。
5. 切面引擎:橫向關注點治理
切面引擎承擔非業務邏輯的橫切關注點處理,有助於提升平台的可維護性與治理能力:

- AOP 框架:通過靜態或動態代理機制,將日誌、安全審計、性能監測等功能與業務邏輯解耦,典型應用包括全鏈路追蹤與統一異常管理。
- 代理策略選擇:根據系統需求選擇靜態代理(高性能路徑)或動態代理(擴展性優先)實現。
- 自動化維護機制:結合測試框架與日誌追蹤工具,實現切面邏輯異常的快速定位與修復,從而降低長期運維成本。
模型驅動開發:抽象重構與自動化執行框架
模型驅動開發(MDD)通過將業務邏輯與系統結構抽象為形式化模型,實現從需求分析到系統實現的深度自動化。這一方法的理論基礎源於領域驅動設計(Domain-Driven Design, DDD)與模型驅動架構(Model-Driven Architecture, MDA),其核心目標在於消解傳統軟件開發過程中“需求—設計—實現”的斷層,藉助模型作為統一表達媒介,推動開發過程的標準化、自動化與跨平台適配。MDD 的價值不僅體現在開發效率的提升,更體現在其對複雜系統的一致性維護、可移植性擴展與生命週期治理能力。
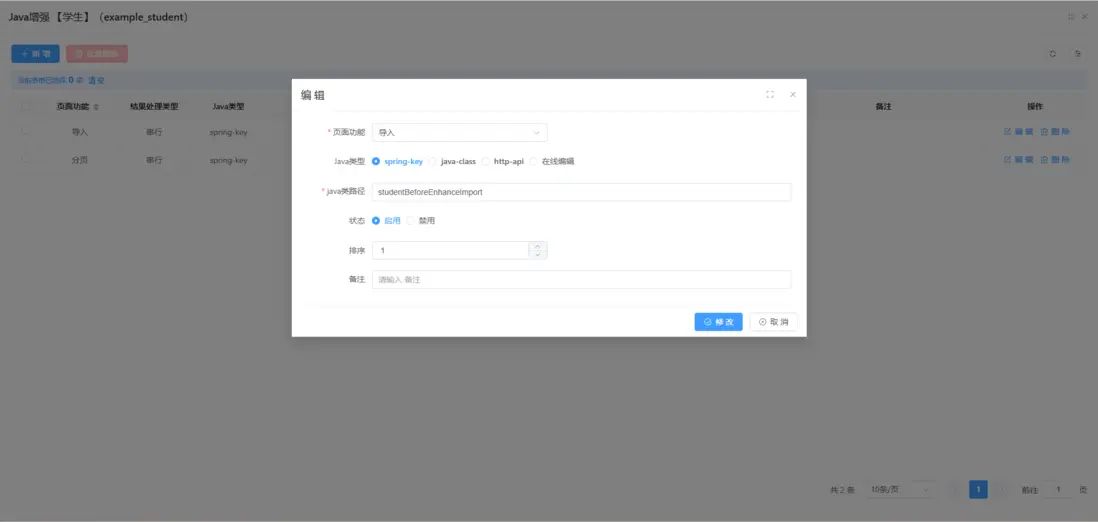
1. 自動化代碼生成:多語言支持與模板定製
自動化代碼生成是 MDD 的基礎能力,其核心在於將高層次的業務模型直接轉譯為應用代碼。
- 跨語言生成機制:MDD 框架支持主流編程語言(如 Java、Python、Go),通過語言映射器將模型元素映射為不同語言中的等效實現。此機制既保障了多樣化技術棧的可兼容性,也減少了開發團隊因語言差異導致的溝通成本。
- 模板驅動定製:代碼生成依賴於可配置的模板機制,開發者可根據特定業務邏輯進行擴展。例如,在金融系統中,模板可嵌入領域特定規則,確保交易流程的合規性與高效性。
- 工程一致性保障:自動生成的代碼不僅具備清晰的層次結構和邏輯邊界,還能通過集成測試與靜態校驗工具保證代碼質量,減少“人為差錯”對系統穩定性的影響。
該機制的實際意義在於開發者能夠將精力集中於核心業務創新,而將大量重複性、結構化的編碼工作交由框架自動完成,從而在降低人力成本的同時提升系統整體的可靠性。
- 智能優化引擎:靜態與動態分析結合
MDD 平台通常內置智能優化引擎,以保障自動生成代碼在可維護性與性能上的平衡。

- 靜態分析:通過語義解析與代碼流檢查,識別冗餘方法、不可達邏輯與潛在的內存泄漏點,進而提升代碼的整潔度與運行效率。靜態分析不僅減少了後期維護難度,也在早期階段降低了安全漏洞產生的可能性。
- 動態分析:運行時的監測機制通過收集性能指標(如響應延遲、內存佔用、併發請求數),實時調整線程調度策略與資源分配方式。例如,在高併發交易場景中,系統可動態擴展處理線程池以緩解瞬時流量高峯。
- 自適應優化:部分 MDD 框架已引入機器學習方法,通過歷史運行數據訓練模型,對性能瓶頸進行預測與提前規避,形成閉環優化體系。
這種靜態與動態結合的優化機制在複雜業務環境(如實時金融交易、工業物聯網監控)中尤為關鍵,可顯著降低調試與運維成本,提升系統的長期可演化性。
3. 跨平台兼容性:容器化與環境抽象
跨平台部署是 MDD 的關鍵價值之一,其通過容器化技術與環境抽象機制,打破了開發環境與運行環境之間的耦合。
**
- 容器化封裝:**基於 Docker 與 Kubernetes,MDD 將應用及其依賴環境打包為可移植的鏡像,確保開發、測試與生產環境之間的一致性,降低了“環境不一致”帶來的部署失敗風險。
- 多環境適配器:MDD 框架通常內置適配層,可根據目標環境(公有云、私有云、混合雲或邊緣計算)自動調整資源參數與配置文件,實現一鍵化遷移與彈性擴展。
- 分佈式彈性支持:在跨平台部署過程中,MDD 框架結合服務網格(Service Mesh)與 API 網關機制,保障服務在不同節點間的高可用性與流量治理能力。
該機制顯著降低了跨環境遷移與運維成本,使 MDD 構建的應用具備更強的可移植性與高可用性,從而在多樣化的 IT 架構中保持持續的運行穩定性。
深度優化數據處理:複雜業務下的數據驅動架構
系統通過構建智能化、高性能的數據處理架構,應對多樣化業務需求,涵蓋跨數據庫兼容、實時流處理、自動化數據轉換、動態數據建模及底層高性能組件支持。該架構強調數據驅動決策能力、可擴展性與系統整體性能優化。
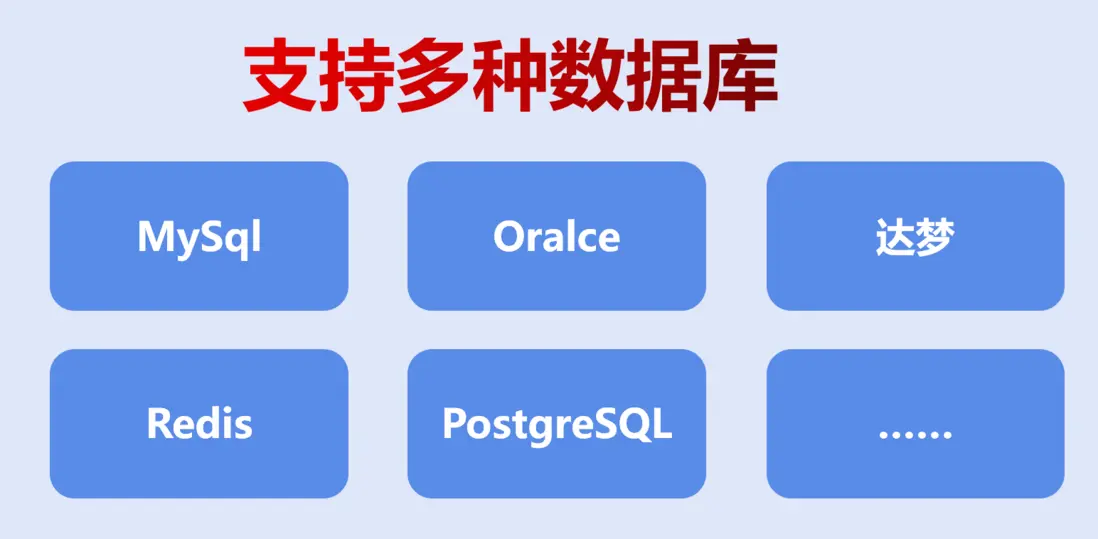
1. 跨數據庫兼容性
採用智能數據連接器,實現關係型(MySQL、Oracle、PostgreSQL)與非關係型(MongoDB、Redis、Cassandra)數據庫的無縫接入與切換。
- 負載均衡與分區策略:基於實時請求負載自動調度讀寫操作,結合水平分區和垂直分區策略提升吞吐量,並避免單點瓶頸與鎖競爭。
- 自適應查詢優化:通過成本模型(Cost-Based Optimizer)動態選擇執行計劃,結合查詢緩存、索引優化和事務併發控制,確保高併發場景下的性能穩定性。
- 跨數據庫事務協調:採用分佈式事務或最終一致性策略(如 Saga、TCC)保證跨數據庫操作的數據完整性,適應微服務化場景的數據一致性需求。
2. 實時流處理
基於分佈式流處理框架(如 Apache Flink、Apache Kafka Streams),實現毫秒級數據計算與事件處理能力。
- 事件驅動架構(EDA):通過解耦數據生產者與消費者,實現異步消息隊列和事件總線支持高吞吐流數據處理。
- 彈性資源調度:結合容器編排(Kubernetes)與自動擴縮容策略,應對流量峯值與突發事件,實現低延遲處理。
- 複雜事件處理(CEP):支持多維度事件聚合、模式匹配及狀態管理,可在金融交易監控、工業 IoT 或智能製造中實現實時異常檢測與決策支持。
- 流批一體化能力:平台可實現批處理和流處理統一執行模型(如 Lambda 或 Kappa 架構),在保證歷史數據分析能力的同時,滿足實時決策需求。
3. 自動化數據清洗與轉換
結合規則引擎、機器學習與元數據管理,實現數據標準化、異常檢測及智能轉換。
- 智能 ETL 流程:自動識別缺失值、異常值及格式衝突,生成可審計的數據處理日誌,確保數據質量可追溯。
- AI 輔助異常預測:通過基於歷史數據的模型預測潛在異常,實現主動修正,降低後續數據錯誤傳播風險。
- 跨源一致性校驗:利用數據映射、主鍵約束及標準化規則,實現多源數據的規範化整合,為上層分析提供高可信度數據基礎。
4. 動態數據建模與多維分析支持
通過虛擬字段、可配置指標和多維分析引擎,滿足複雜業務的自定義分析需求。
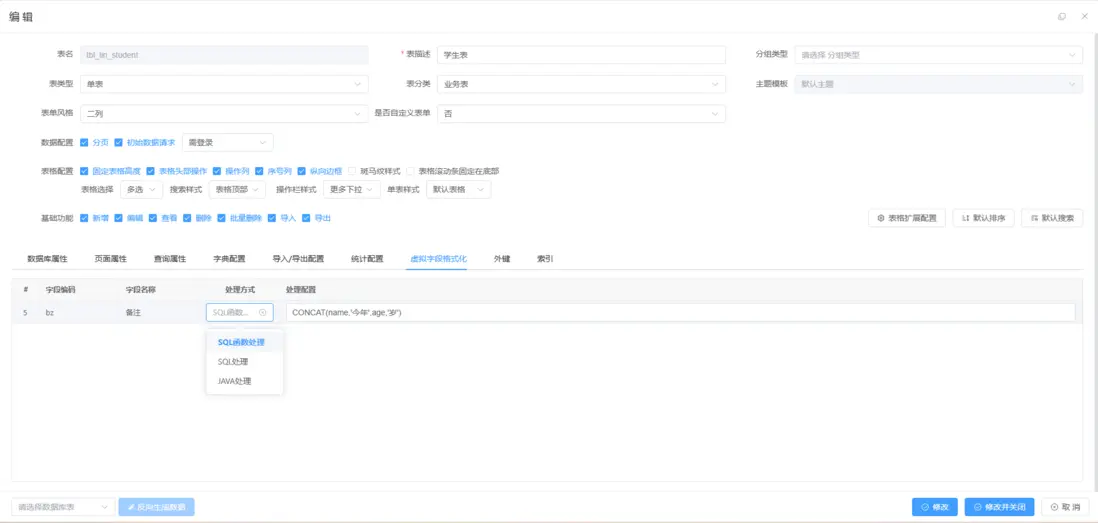
- 虛擬字段與衍生指標:業務人員可在業務層定義計算字段或邏輯關係,無需修改底層數據庫結構,支持靈活報表與多維分析。
- 多維分析引擎:結合 OLAP 核心算法(如 ROLAP/MOLAP)與列式存儲優化,實現大數據量下的多維查詢與交互式儀表盤分析。
- 交互式可視化支持:與 BI 平台或前端可視化組件集成,提供實時鑽取、過濾和關聯分析能力,為決策提供直觀的數據洞察。
5. 高性能底層組件庫支持
模塊化組件庫與事件驅動架構保障系統的高效性、可維護性和可擴展性。

- 事件總線(EventBus):實現模塊間的異步發佈/訂閲,支持分佈式事件路由與優先級調度,減少模塊耦合度。
- 數據庫方言與執行優化:根據不同數據庫特性生成優化 SQL,結合批處理和緩存策略提升執行效率。
- 事件驅動架構(EDA):將業務邏輯處理與數據流處理解耦,通過異步事件處理和消息隊列實現系統擴展性與穩定性。
- 組件監控與自動調優:集成監控指標採集與日誌分析,實現對關鍵組件性能和吞吐量的動態調整,保障系統在高負載下穩定運行。
AI 深度融合重構開發體驗
人工智能技術與軟件開發流程的深度集成,推動開發效率、質量及系統智能化管理的系統性提升。通過智能代碼生成、主動故障排查、場景化推薦、自然語言交互、自動化測試與自適應學習六大模塊,AI 構建了覆蓋編碼、測試、部署及運維的全鏈路智能支持體系,為開發流程提供動態優化與決策輔助能力。
1. 智能代碼生成與實時優化
基於 Transformer 架構(如 CodeBERT、GPT 系列)和大規模預訓練模型,AI 代碼助手能夠解析自然語言指令,實現代碼片段自動生成。
- 跨語言與多範式生成:支持主流語言(Java、Python、Go 等)及函數式/面向對象等多種編程範式,生成可直接集成到現有系統的高質量代碼。
- 實時靜態分析:結合語義解析、抽象語法樹(AST)分析和代碼模式檢測,識別冗餘邏輯、潛在漏洞和不規範結構。
- 動態運行時優化:通過運行時監控性能指標(如 CPU/內存佔用、執行延遲),提供代碼重構與並行執行優化建議。
- 應用場景:適合快速構建基礎模塊或原型,也可為資深開發者節省重複性編碼工作,提升整體開發效率。
2. 主動故障排查與預測維護
AI 系統結合時序數據分析和深度學習模型(如 LSTM、Temporal Convolution Networks),實現故障異常檢測與預測維護。
- 實時異常監控:分析系統日誌、性能指標及調用鏈數據,快速識別潛在異常。
- 根因定位:通過事件相關性分析和因果建模自動定位故障源。
- 預測性維護:基於歷史故障數據預測潛在風險,支持預防性擴容、配置優化與系統調優。
- 應用場景:高可用性系統、金融交易平台及大規模分佈式服務的穩定性保障。
3. 場景化推薦與智能決策支持
AI 引擎基於上下文感知與歷史項目數據,為不同開發場景提供智能決策輔助。
- 組件與架構推薦:根據業務規模、性能需求和技術約束選擇最佳實踐組件與架構模式。
- 算法優化建議:針對數據量與業務複雜度,推薦適合的算法實現方案,降低試錯成本。
- 跨團隊協作支持:為項目經理、架構師提供決策參考,提高整體開發效率和系統可擴展性。
4. 自然語言交互開發接口
通過對話式 AI,實現開發者與系統之間的自然語言交互,支持文本、語音及可視化多模態操作。
- 低代碼/無代碼融合:開發者可通過自然語言描述完成代碼生成與系統配置操作,降低編碼門檻。
- 跨職能協作:設計師、產品經理和非編碼人員能夠直接參與開發過程,縮短需求到實現週期。
- 智能上下文理解:系統通過語義解析與項目上下文建模,精確理解指令意圖並生成可執行操作。
5. AI 驅動的自動化測試與質量保障
結合機器學習與規則引擎,實現測試用例自動生成、執行與優化。
- 測試覆蓋優化:基於代碼邏輯和業務規則生成覆蓋率最大化的測試腳本。
- 動態調整策略:根據歷史缺陷分佈、性能趨勢和風險評估調整測試優先級。
- 持續質量保障:與 CI/CD 流程集成,實現自動迴歸測試、性能驗證與缺陷預警。
6. 自適應學習與持續優化
AI 系統持續採集開發者行為和項目運行數據,通過自適應學習不斷優化輔助策略。
- 個性化推薦:根據開發者習慣和編碼風格提供定製化代碼片段、模塊調用及最佳實踐建議。
- 迭代趨勢預測:通過歷史迭代數據預測系統瓶頸、潛在風險及技術需求變化。
- 長期演進支持:動態調整開發流程與資源配置,保障系統長期穩定演進與競爭力。
豐富插件生態:驅動多場景應用與技術擴展
低代碼平台通過模塊化、插件化架構,構建了多樣且開放的插件生態,極大地提升了系統的可擴展性和適應性,滿足不同行業與業務場景的複雜需求。以下為關鍵插件類別及其技術特點:
- 實時數據流處理插件:利用Apache Kafka、Apache Flink等流式計算框架,支持低延遲的數據採集、處理與分析,適應金融交易監控、用户行為追蹤等場景。
- AI模型訓練與推理插件:集成TensorFlow、PyTorch等深度學習框架,支持模型開發、訓練和在線部署,適用於智能推薦、圖像識別等應用。
- 智能圖像處理插件:基於卷積神經網絡(CNN)技術,實現OCR文字識別、目標檢測和視頻分析,廣泛應用於安防監控和醫療影像分析。
- 數據集成與ETL插件:支持多源異構數據的採集、清洗、轉換和加載,助力數據倉庫與數據湖的建設,提升數據治理能力。
- 自然語言處理插件:集成GPT等大型預訓練語言模型,支持語義理解、多語言翻譯和文本生成,適合智能客服與輿情分析。
- 智能客服插件:結合對話管理和意圖識別技術,實現自動應答、工單生成與客户交互優化,提升服務效率。
- 智能推薦系統插件:基於協同過濾與深度學習算法,提供個性化推薦功能,適用於電商、內容分發等平台。
- 容器化部署插件:支持Docker和Kubernetes,實現雲原生應用的彈性部署與高可用保障。
- 低代碼RPA插件:通過流程自動化技術實現數據錄入、報表生成等重複任務自動化,提升業務效率。
- API網關插件:集成API聚合、負載均衡、認證授權和版本管理,優化微服務架構中的接口性能與安全性。
- 邊緣計算插件:支持物聯網設備的本地數據處理與分析,降低中心服務器負載,適用於工業自動化等場景。
- 智能運維插件(AIOps):融合故障診斷、性能監控和異常檢測技術,提高IT運維效率與系統穩定性。
- 數據安全與隱私保護插件:提供數據加密、訪問控制及隱私合規功能,滿足金融、醫療等行業的安全需求。
- 身份認證與訪問管理插件:支持多因素認證(MFA)、單點登錄(SSO)等安全機制,強化身份管理。
- 安全審計與日誌分析插件:實現日誌採集、異常行為檢測與合規性報告,助力網絡安全與合規審計。
- 業務流程建模插件:基於BPMN標準,支持快速流程設計與優化,提高企業級流程透明度與管理能力。
- 數據可視化插件:提供多樣化交互圖表和儀表盤,支持實時數據分析與業務洞察。
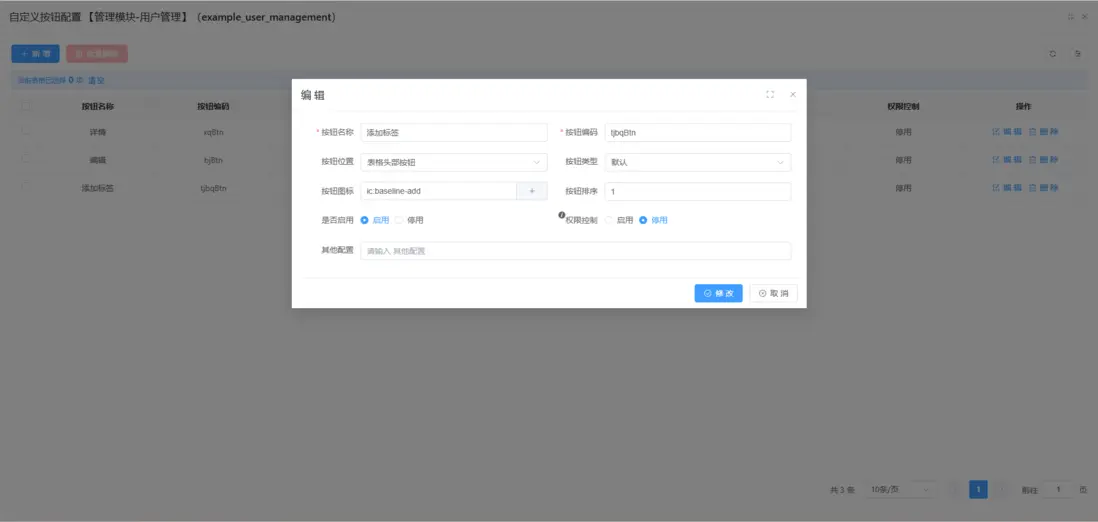
- 表單生成插件:通過拖拽組件快速搭建複雜表單,支持動態字段和權限控制,適用於行政審批及問卷調查等場景。
開放架構:高性能技術棧與開源生態融合
低代碼平台通過開放架構結合高性能技術棧、靈活擴展能力及開源資源,構建可持續演進的技術平台,支持多樣化業務需求和複雜系統長期發展。開放架構不僅保障平台的技術可擴展性,還形成可持續創新的生態閉環。
1. 微服務架構:解耦、高併發與數據一致性保障
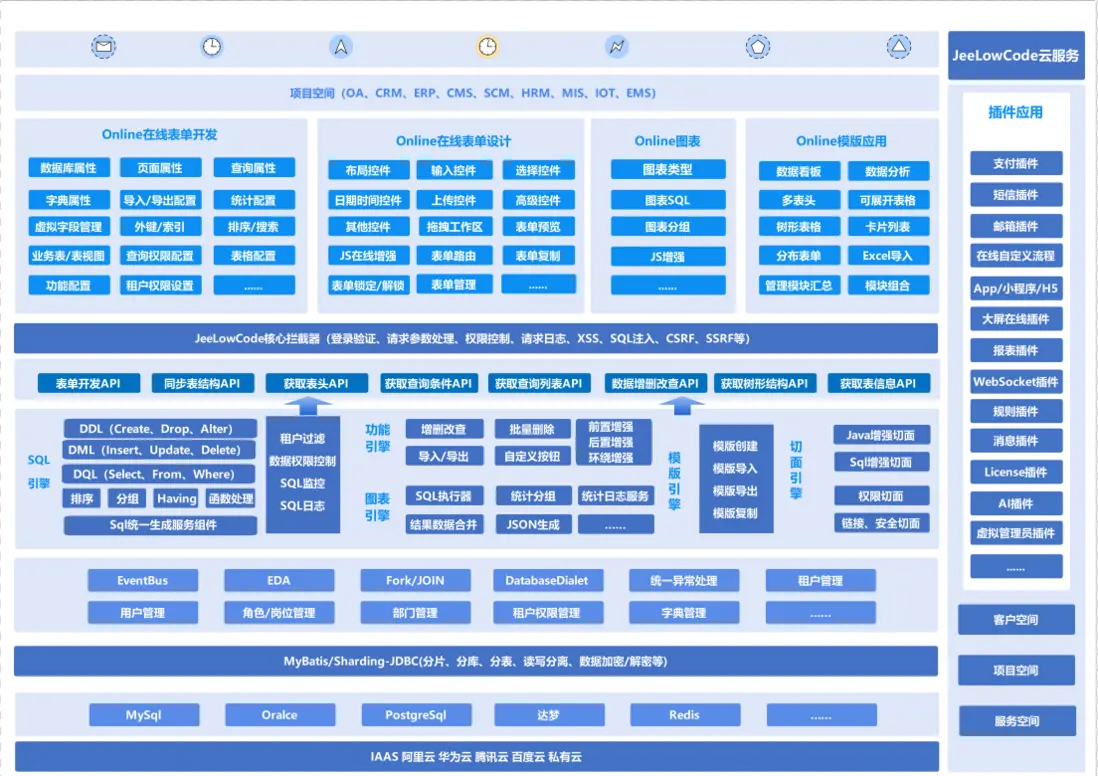
- 事件驅動與異步通信:採用事件驅動架構(EDA)與分佈式任務調度機制,實現服務間異步通信與解耦。事件總線提供異步事件傳遞機制,降低服務間耦合度,提升系統彈性和橫向擴展能力。
- 分佈式任務調度:結合 Celery、Quartz 等分佈式調度器,實現高併發任務動態分配與負載均衡,保障複雜業務場景下的任務可靠性。
- 事務一致性機制:引入 Saga、TCC 等分佈式事務控制方案,確保跨服務調用中的數據一致性與事務完整性,有效支撐複雜業務流程和高可用要求。
2. 開源框架支持:降低門檻與促進創新
開源框架不僅為系統提供了高性能和可擴展的技術基礎,也為開發者提供了透明、可定製的工具鏈。
- 技術棧與工具鏈:平台基於 Spring Boot、Node.js 等主流開源框架構建核心後端服務,提供透明源碼與完善文檔,降低開發門檻。內置 JUnit、Jest 等測試工具鏈,保障代碼質量與系統可維護性,同時支持持續集成(CI)和持續交付(CD),提升開發效率與一致性。
- 全球協作與社區生態:依託 GitHub 等開源社區,開發者可通過提交 Pull Request、參與 Issue 討論等方式推動框架迭代與功能創新。開源社區機制不僅支持跨團隊協作與經驗共享,還形成了平台持續更新和優化的技術生態閉環,為低代碼平台的長期演進提供可靠保障。
3. 多樣化組件庫:標準化與靈活定製結合
組件庫是低代碼平台高效開發和業務適配的基礎,既提供標準化模塊,也支持個性化二次開發。
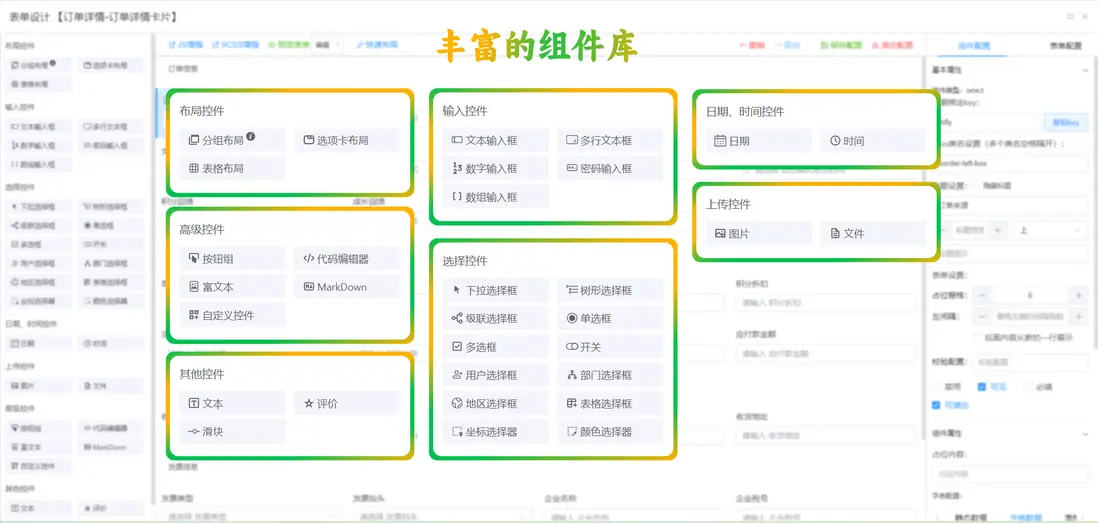
- 行業組件覆蓋:組件庫涵蓋金融、零售、醫療等行業,提供表單生成器、動態圖表、流程節點等標準化組件。
- 前端框架兼容:兼容 React、Vue、Angular 等主流框架,通過接口適配器實現無縫集成。
- 模塊化與二次開發:插件化設計支持組件二次開發與個性化定製,簡化複雜業務邏輯實現,提升開發效率與系統擴展能力。
4. 高性能支撐:內存計算與雲原生技術
在大規模數據與高併發場景下,低代碼平台需通過內存計算、列式存儲和分佈式計算結合雲原生技術,實現高效數據處理、彈性部署及系統高可用性。
- 內存數據庫與列式存儲:整合 Redis、Memcached、ClickHouse、Apache Druid 等高性能數據庫,提升讀寫速度並優化複雜查詢響應。
- 雲原生與彈性部署:結合 Docker、Kubernetes,實現快速部署和彈性伸縮,確保高併發與大規模數據處理環境下的穩定性。
- 多技術協同保障:通過內存緩存、列式存儲和分佈式計算協同,優化系統吞吐量和響應時延,確保大規模業務場景下的高可用性。
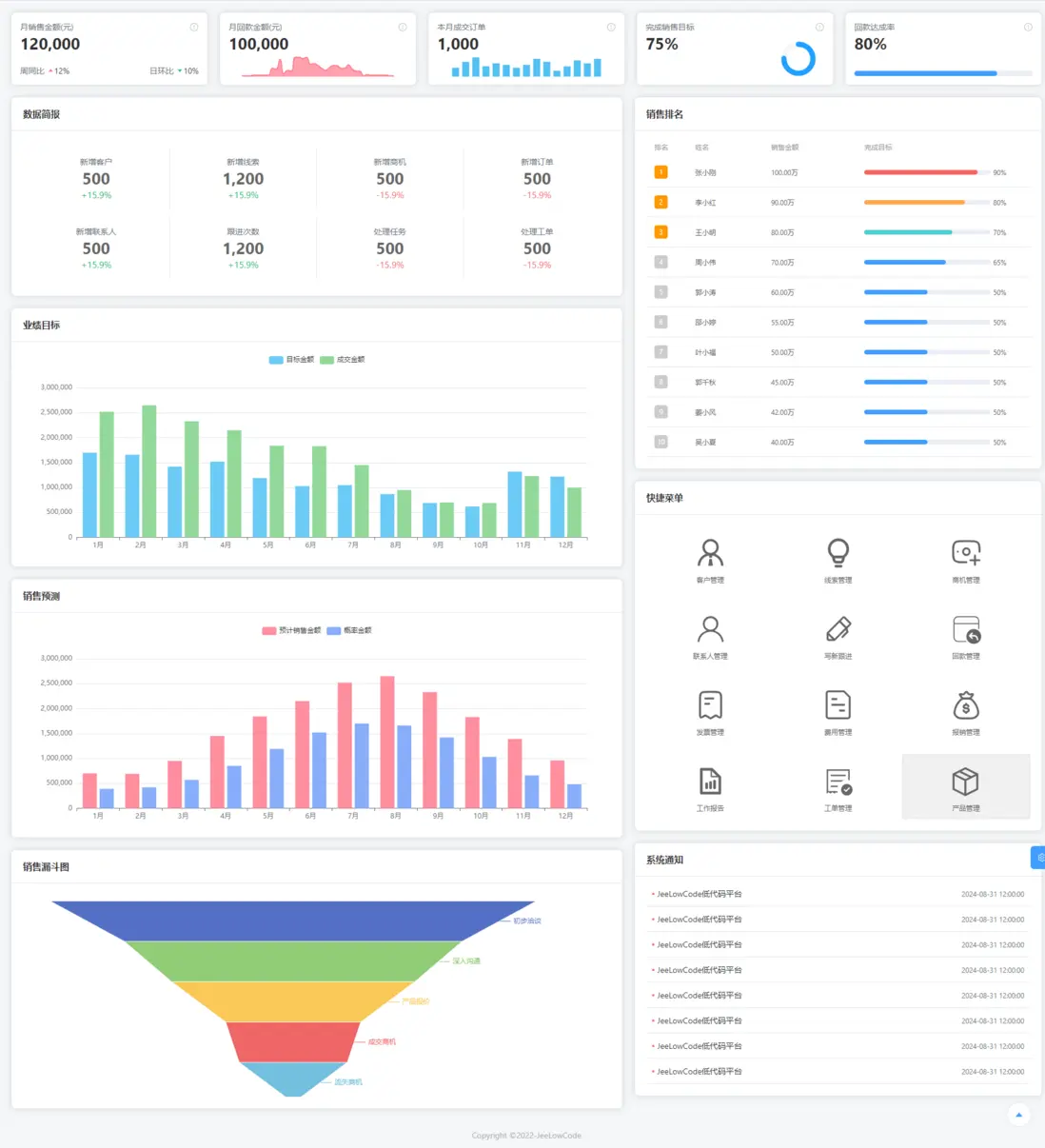
企業功能增強:從開發工具到智能決策支持
隨着企業數字化轉型的深入,現代企業開發環境逐步演變為集數據管理、業務處理與智能決策支持於一體的綜合技術架構。這一架構不僅提升企業在複雜業務場景下的處理效率和適應力,也為快速迭代、創新研發和系統可持續演進提供技術支撐。
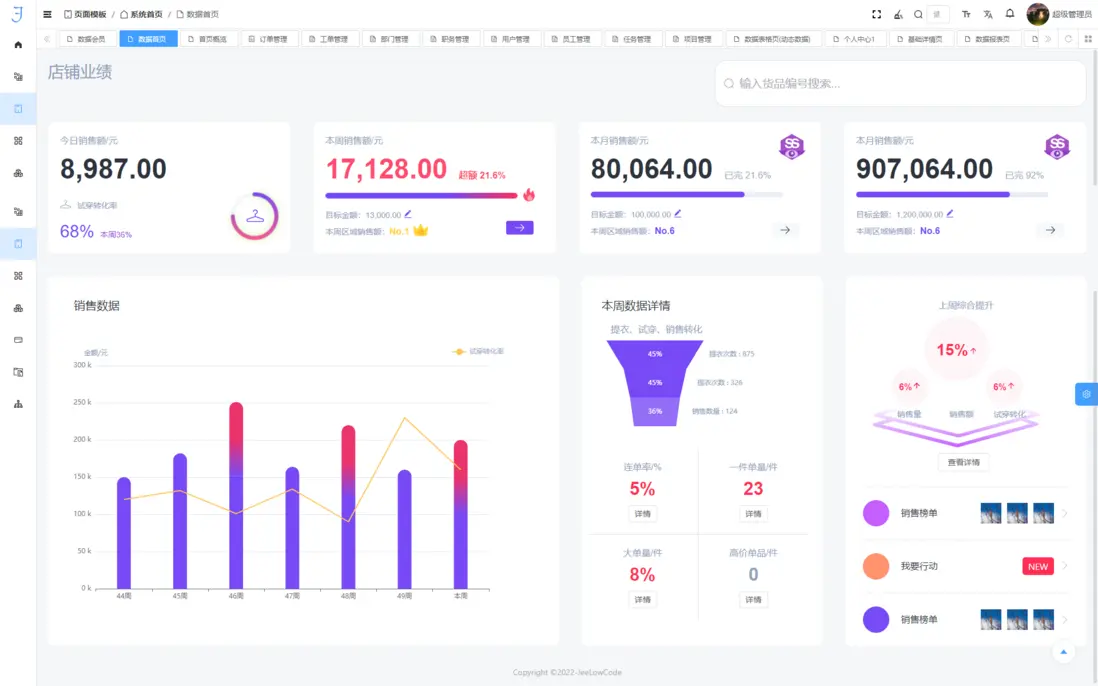
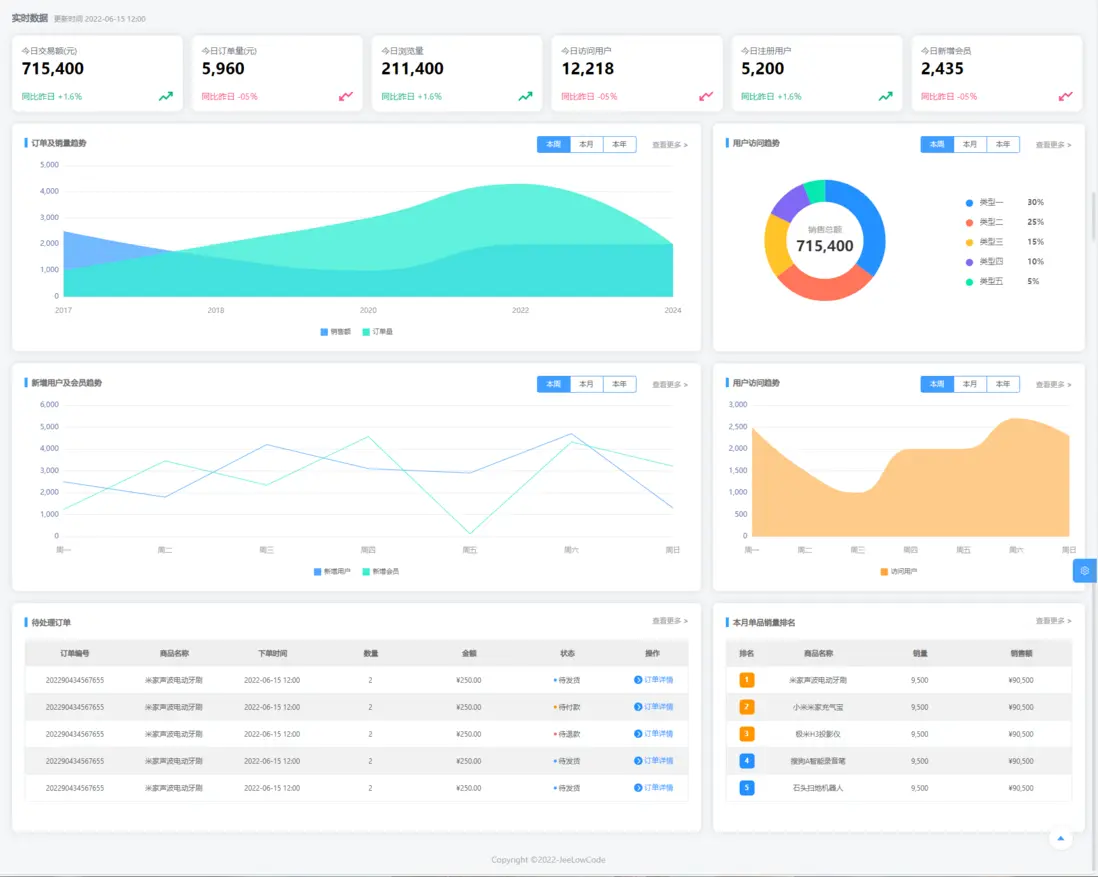
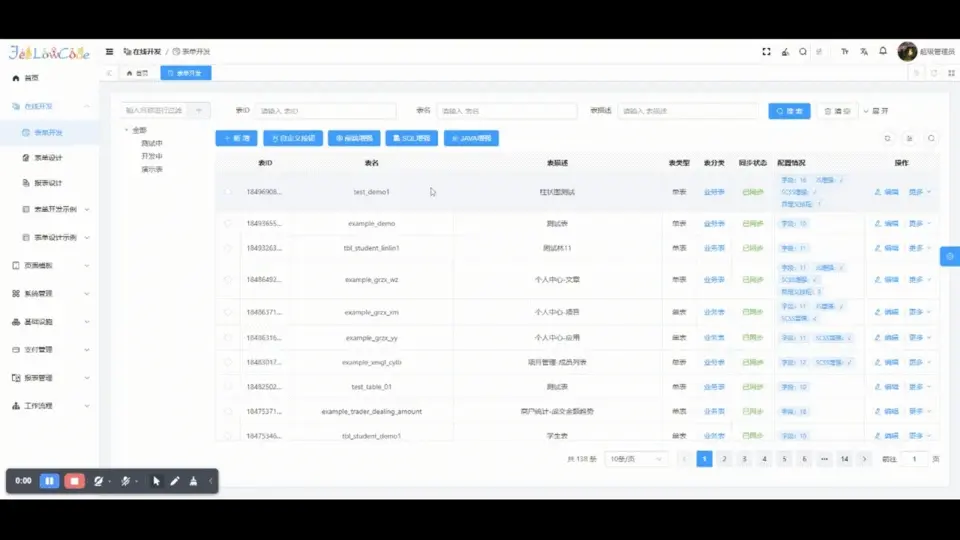
1. 數據增刪查改(CRUD):高效靈活的數據操作
低代碼平台通過可視化開發、動態數據綁定與後台智能調度,實現高效、可擴展的數據操作。
- 實時同步與雙向綁定:前端 UI 與後端數據源實時聯動,確保數據狀態與展示一致,減少數據延遲與一致性錯誤。
- 高併發優化:通過批量操作、事務合併、異步隊列和任務調度機制,在高訪問壓力場景下保持系統穩定性,降低數據庫鎖競爭和前端響應延遲。
- 智能負載均衡:結合數據分區策略與分佈式緩存(如 Redis、Memcached),動態調節讀寫負載,實現海量數據訪問的高可用性。
- 典型應用:電商促銷、金融交易、IoT 設備數據管理中,通過高效批量操作和事務優化,保證業務連續性與性能可靠性。
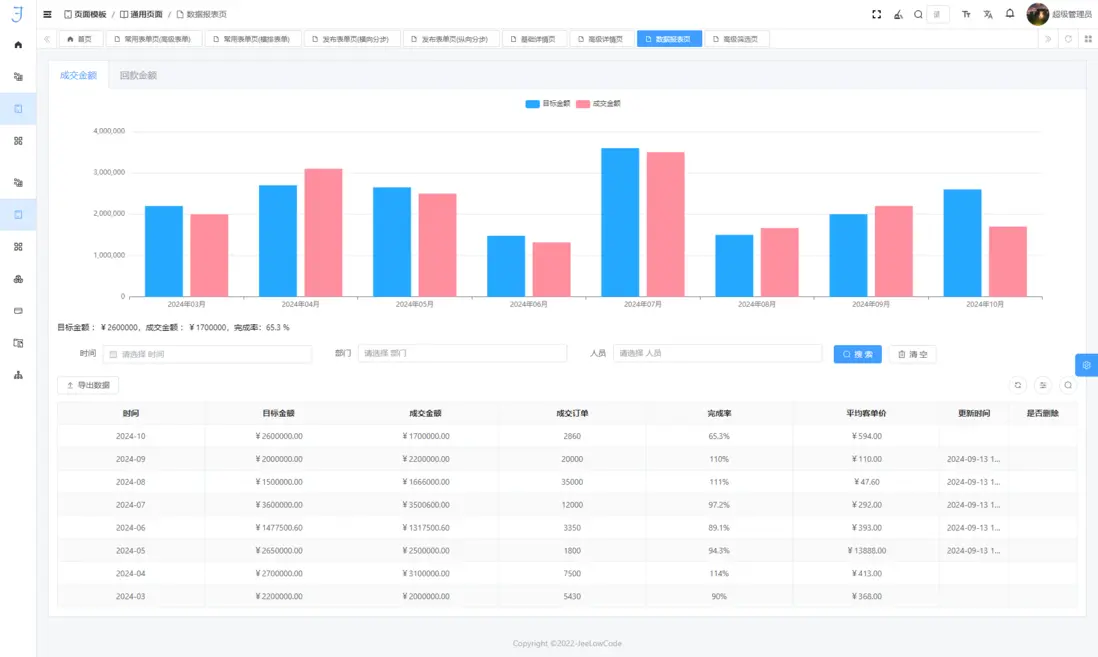
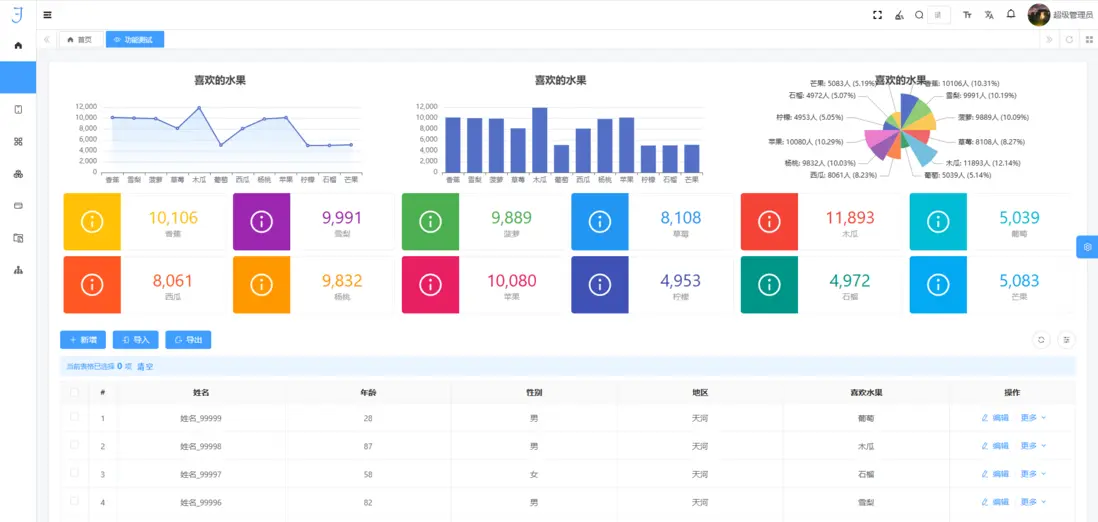
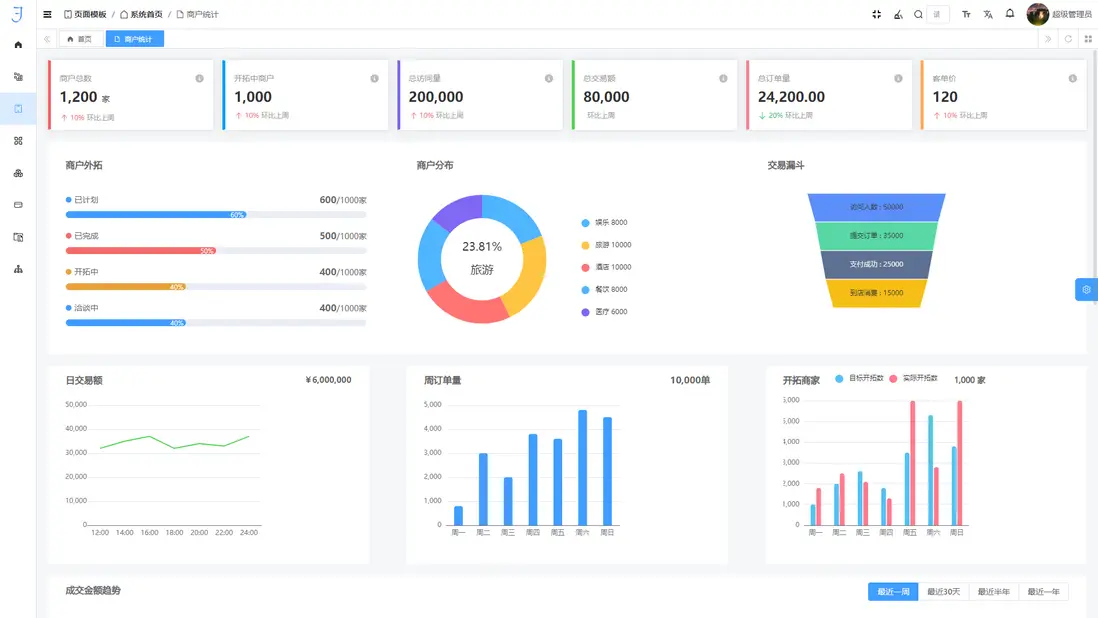
2. 圖表創建與交互分析:高性能可視化渲染
低代碼平台通過標準化組件庫和高性能渲染引擎,實現複雜數據的動態可視化。
- 硬件加速與分層渲染:利用 WebGL 與 Canvas 技術實現 GPU 加速和分層渲染,保障百萬級數據點的流暢展示。
- 增量更新與差異渲染:僅重繪數據變化部分,減少瀏覽器渲染負載,提高交互響應速度,滿足實時分析和監控場景需求。
- 多維交互分析:支持篩選、聯動、高亮、鑽取等功能,實現數據的深度探索和可視化決策支持。
- 典型應用:金融風控監控儀表盤、零售運營分析和工業 IoT 可視化分析,實現大規模實時數據的快速洞察。
3. 業務邏輯配置:響應式編程與事件驅動設計
平台通過響應式編程模式和事件驅動機制,實現數據流與業務邏輯的高效耦合與動態響應。
- 條件邏輯與規則鏈:支持複雜條件判斷、動態字段計算、流程觸發等業務規則鏈的快速配置。
- 事件驅動架構:用户操作或系統狀態變化觸發事件處理,實現流程自動化、異步任務處理和業務規則即時執行。
- 彈窗與交互優化:提供上下文感知的界面元素,如審批歷史展示、關聯信息提示,提升用户操作體驗和流程透明度。
- 典型應用:訂單審批、庫存調度、客户關係管理等場景,通過事件驅動提高業務流程的靈活性和響應速度。
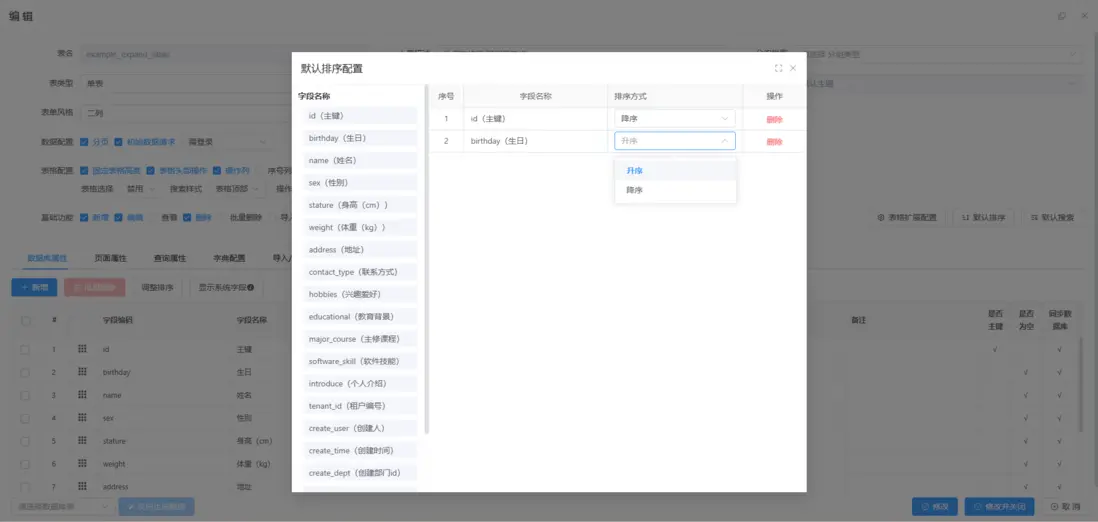
4. 公式計算與規則執行:自動化與實時驗證
在低代碼平台中,公式計算與規則執行機制不僅支撐業務邏輯的自動化,還保障系統在複雜業務場景下的高效性與可靠性。通過公式庫、實時驗證與規則引擎的結合,平台能夠實現業務流程的智能化管理和動態優化。
- 公式庫與自定義擴展:平台內置覆蓋數學運算、邏輯判斷與文本處理的公式庫,同時支持用户根據業務需求進行自定義擴展,以滿足特定業務計算需求。
- 實時驗證與錯誤反饋:公式執行即時返回計算結果,並自動提示潛在錯誤或不一致數據,減少人工校驗和修正時間,提高業務操作準確性。
- 規則引擎執行:支持庫存預警、風險評分、動態折扣策略等複雜業務規則的自動化執行,確保流程的高效性、精確性與一致性。
- 優化策略:結合緩存機制、批處理和異步執行方式,提升規則引擎在高併發環境下的計算性能與系統響應速度,從而保障平台在大規模業務場景中的穩定運行。
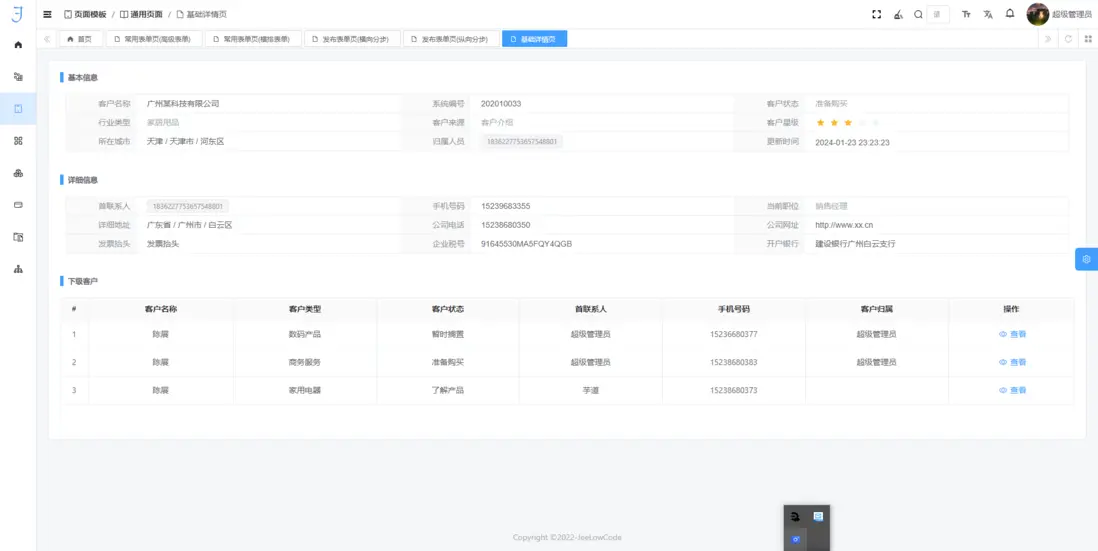
5. 虛擬字段與權限管理:靈活性與安全性並重
業務模型的快速迭代與數據安全性同等重要。虛擬字段與權限管理機制通過靈活的數據定義和細粒度訪問控制,實現業務敏捷性與系統安全性的平衡。
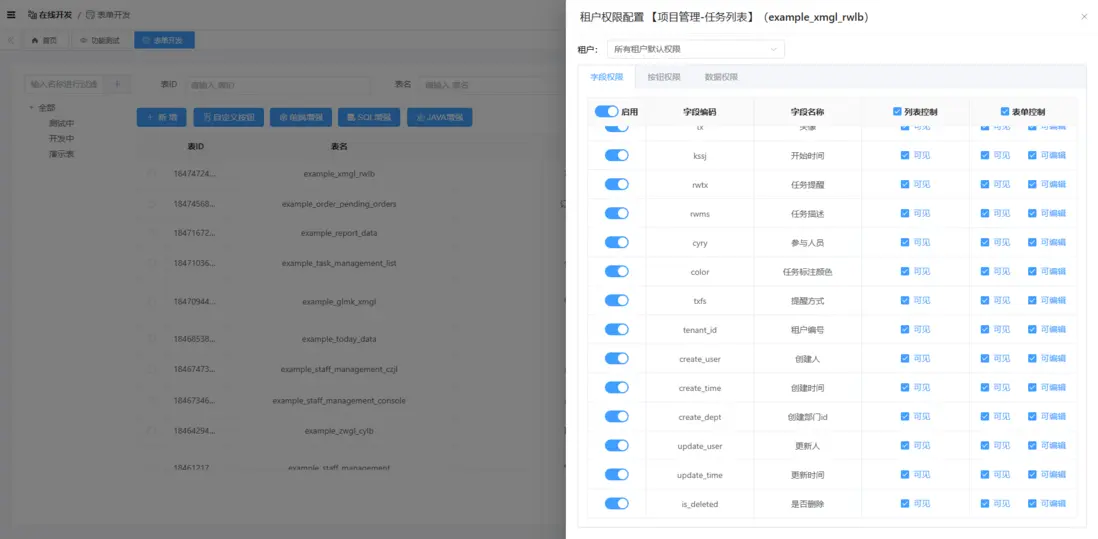
- 虛擬字段機制:允許在業務層動態定義計算字段、聚合字段和關聯字段,無需修改底層數據庫架構,實現業務模型快速迭代。
- 角色與權限控制(RBAC):實現細粒度訪問管理,保障數據安全性和操作合規性。
- 多租户隔離策略:通過數據庫分片、命名空間隔離和行級安全控制,確保不同租户數據隔離,滿足企業級多租户安全要求。
- 典型應用:CRM 系統、企業內部管理平台,通過靈活字段定義和安全策略支持業務多樣性和敏捷迭代。
6. 高併發與系統性能保障
低代碼平台通過多層優化機制,從事務處理、緩存策略到資源調度,實現高併發下的穩定運行和業務連續性保障。
- 事務優化與並行處理:結合異步隊列、批量事務、數據庫分區和索引優化,提高系統在高併發場景下的數據處理能力。
- 緩存與內存計算:Redis、Memcached、內存數據庫等技術減少對後端數據庫訪問壓力,提升數據響應速度。
- 動態資源調度:通過容器化與雲原生技術(Docker、Kubernetes)實現彈性伸縮,保障高峯業務負載下的服務可用性。
- 典型應用:大促電商、金融交易系統、IoT 實時監控平台,實現業務連續性和高可用性保障。
