









1. 概述
KWDB 作為一款面向 AIoT 場景的分佈式多模數據庫產品,支持在同一實例同時建立時序庫和關係庫並融合處理多模數據,具備千萬級設備接入、百萬級數據秒級寫入、億級數據秒級讀取等時序數據高效處理能力,具有穩定安全、高可用、易運維等特點。
KWDB 的 SQL 引擎由解析器、優化器和執行器組成,編譯優化部分主要介紹解析器和優化器。
解析器:核心作用是將用户輸入的 SQL 語句轉換為 KWDB 可運行的結構化數據,同時完成必要的規範性校驗,主要包含詞法解析、語法解析和語義解析三個關鍵步驟。
優化器:核心作用是基於規則與成本優化策略,對解析器生成的結構化數據進行等價轉換,在不改變 SQL 語句原意的前提下,提升執行效率、降低運行成本,主要涵蓋 RBO 優化、CBO 優化和多模計算優化等方式。
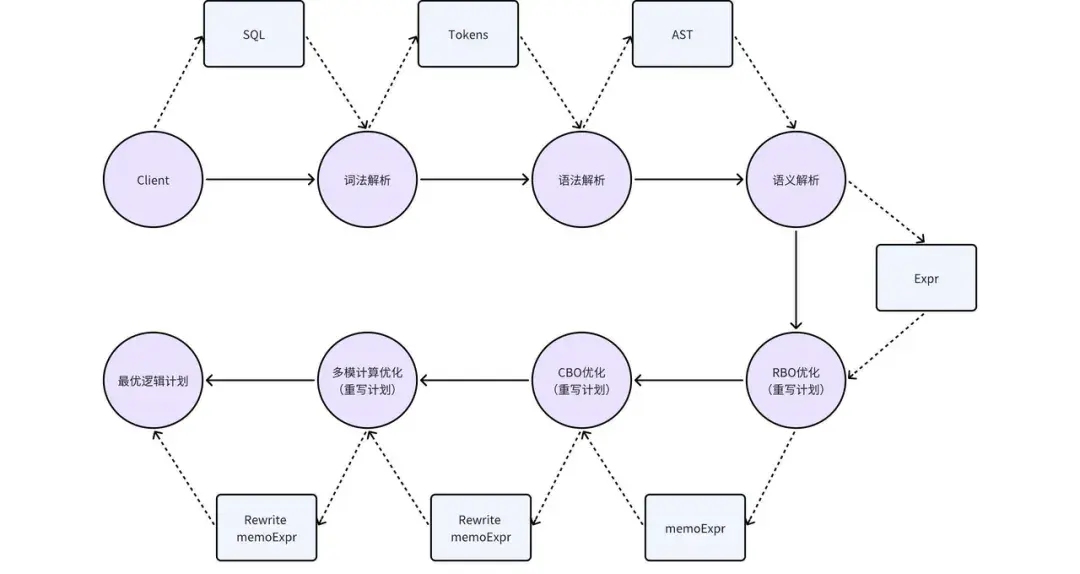
2. KWDB 查詢編譯和優化基礎架構
在 KWDB 的編譯階段,SQL 語句主要經歷詞法解析、語法解析和語義解析三個處理步驟。其中,為進一步優化執行計劃,在語義解析階段還會同步進行 RBO 優化。
2.1 詞法解析
KWDB 的詞法解析會依據 yacc 文件中定義的詞法單元,將 SQL 語句從字符流轉換為具備明確詞法屬性的詞法單元列表(tokens),這些詞法單元包括關鍵字、標識符、常量和運算符等。
具體步驟如下:
預處理:去除 SQL 語句中的註釋與空白字符,簡化後續解析流程。
詞法單元識別:掃描處理後的 SQL 字符流,按照詞法規則分解並識別出各個詞法單元。
構建 tokens 列表:將識別出的詞法單元按照原始 SQL 語句的順序排列,形成 tokens 列表。
例如有以下查詢語句:
SELECT a, b FROM t WHERE c > 30;
詞法分析的結果如下:
SELECT(關鍵字)
a(標識符)
,(分隔符)
b(標識符)
FROM(關鍵字)
t(標識符)
WHERE(關鍵字)
c(標識符)
>(運算符)
30(常量)
;(分隔符)
2.2 語法解析
KWDB 的語法解析會根據 yacc 文件中定義的語法規則,對 tokens 列表進行遍歷識別,主要完成兩項核心任務:一是校驗語法是否存在錯誤,二是判斷是否存在規約衝突。
無法生成語法樹的情況如下:
語法錯誤:在判斷需要進行規約(生成語法)時校驗失敗,如:未定義的語法。
移進-規約衝突:無法決定是移入(繼續讀取token)還是規約(生成語法),通常是因為輸入串中的符號可能會匹配多個產生式的右側。
規約-規約衝突:存在多個規約操作的可能性,無法確定應使用哪一個規約規則,存在歧義。
當每次規約操作均正確完成,且 tokens 列表遍歷結束後,最終會生成抽象語法樹(AST),為後續語義解析提供結構化基礎。
2.3 語義解析
KWDB 的語義解析會對查詢的語法樹AST進行深入的分析,以確保查詢在邏輯和語義上是有效的,並且能夠正確地執行。
具體操作如下:
有效性校驗:檢查查詢語句是否為 SQL 語言中的合法語句,包括表與列的存在性校驗、數據類型兼容性檢查、用户操作權限驗證以及約束條件合規性校驗等。
名稱解析:確定表名、變量名等標識符的具體含義與對應值。
常數摺疊:消除中間運算過程,例如將 0.5+0.5 直接替換為 1.0,減少執行階段的計算量。
數據類型確定:明確中間結果的數據類型,例如當查詢語句包含子查詢時,需確定子查詢返回結果的具體數據類型。
經過語義解析後生成的執行計劃已具備可執行性,但此時的計劃並非最優方案,還需通過後續優化步驟進一步提升性能。
2.4 RBO 優化
RBO(Rule-Based Optimization,基於規則的優化)的核心原理是基於關係代數的等價變換,用執行效率更高的等價表達式替換原始表達式。其典型優化規則包括列裁剪、最大最小值消除、投影消除和謂詞下推等。
具體分析如下:
- 列裁剪
假設表t有 a、b、c、d 四列。
有以下查詢語句:
SELECT a FROM t WHERE b > 5;
① 未優化方案:讀取表 t 的所有列數據,根據 b > 5 的條件過濾後,再投影出 a 列數據。
② 優化後方案:先進行列裁剪,僅讀取 a、b 兩列數據,再根據過濾條件篩選,最終輸出 a 列結果,顯著減少數據讀取量。
- 最大最小值消除
有以下查詢語句:
SELECT min(a) FROM t;
這句話可以轉換成:
SELECT a FROM t ORDER BY a DESC LIMIT 1;
相較於傳統聚合計算,排序 + 限制的方式無需遍歷所有數據後進行聚合操作,執行效率更高。
- 投影消除
假設表t和tt均有a、b、c、d四列。
有以下查詢語句:
SELECT t1.a t2.b FROM t AS t1 JOIN (SELECT a, b, c FROM tt) AS t2 ON t1.a=t2.a;
此查詢語句投影列中只需要表t的a列和表tt的b列,而join的右側子查詢的投影列存在a、b、c三列,c列在外層是不需要的,所以計劃中會消除掉c列。
- 謂詞下推
有以下查詢語句:
SELECT * FROM t, tt WHERE t.a > 3 AND tt.b < 5;
① 未優化方案:先對兩表進行笛卡爾積計算(需處理 100×100=10000 條數據),再根據過濾條件篩選。
② 優化後方案:先將過濾條件下推至表掃描階段,假設符合 t.a > 3 的數據有 10 條,符合 tt.b < 5 的數據有 8 條,再對過濾後的數據進行笛卡爾積計算(僅需處理 10×8=80 條數據),數據處理量大幅降低。
謂詞下推就是將過濾條件儘量靠近葉子節點。
經過 RBO 優化後的執行計劃,在性能效率與資源成本上均優於未優化方案。除 RBO 優化外,KWDB 還會針對 SQL 語句進行更深度的 CBO 優化與多模場景的計算優化,具體內容將在第 3、4 章節展開介紹。
3. 針對多模計算的優化
3.1 KWDB 多模計算本地化
3.1.1 計算本地化概念
計算本地化是指將查詢(query)儘可能部署到時序引擎內部執行,通過減少跨引擎數據傳輸、實現數據本地處理,從而提升查詢效率。其核心目標是找到時序引擎能夠支持的最大計劃樹,確保儘可能多的計算邏輯在時序引擎中完成。
3.1.2 計算本地化的基本思路
計劃樹構建:查詢語句經語法解析後會生成樹狀結構的表達式(稱為 memo tree),樹中每一層表達式後續將轉換為對應的算子,由執行引擎執行。在構建 memo tree 的過程中,需對 filter 等標量表達式進行評估與處理。
最大本地化計劃樹識別:memo tree 基本構建完成後,通過自頂向下的遍歷方式,分析樹中各層算子能否在時序引擎中本地化執行,最終確定可在時序引擎中完整執行的最大計劃樹。
3.1.3 每層針對計算本地化的處理
Scan 層: 時序數據的掃描操作全部在時序引擎中執行,默認支持計算本地化。
Filter 層:
① 需要對 filter 表達式進行拆解,判斷哪些 filter 條件能實現計算本地化和哪些 filter 條件不能實現計算本地化並記錄;
② 對記錄結果進行一系列運算獲取最終需要進行計算本地化的 filter 集合;
③ 將能實現計算本地化的部分作為一個過濾算子放到時序引擎執行;
④ 關係引擎根據不能實現計算本地化的部分重新構建新的 filter 層;
⑤ 關係接收時序 filter 處理後的數據並再做過濾;
這樣就完成了 filter 層的計算本地化處理。
Group 層:涵蓋 GroupBy、ScalarGroupBy、DistinctOnExpr 三種類型,需檢查兩處能否本地化:
① GroupBy:檢查 group by 列與聚合函數(含輸入類型、個數及運算邏輯)能否本地化;
② ScalarGroupBy(僅聚合函數,無 group by):僅需檢查聚合函數能否本地化;
③ DistinctOnExpr(僅 group by,無聚合函數):僅需檢查 group by 列能否本地化;
注:若任一檢查項不滿足,整個 group 層無法本地化。
Projection 層:檢查投影操作能否本地化,例如投影列中若出現int + float 類型運算(時序引擎不支持),則本層不進行本地化處理。
Limit 層:支持在時序引擎中本地化執行;若為多節點部署,需由網關節點對各時序引擎返回的結果進行二次 limit 匯聚,確保最終結果正確。
其他層:目前暫未實現本地化支持(如 join 表達式),將在後續版本中逐步完善。
3.1.4 計算本地化控制
我們希望通過一個靈活的、可調整的機制去控制各個層的計算本地化判斷。下面介紹一個控制計算本地化的機制:本地化計算白名單。
3.1.4.1 本地化計算白名單
本地化計算白名單,一個用於控制表達式能否進行本地化計算的名單,具體形式為一張系統表。他記錄了時序引擎支持的所有表達式,白名單由下列元素構成:可本地化執行操作、參數數量、參數類型、可本地化執行位置、默認是否開啓、支持類型。
下面解釋一下各個元素。
① 可本地化執行操作:表示這個表達式的操作符能否在時序引擎本地化計算;
② 參數數量:表示這個表達式的參數數量;
③ 參數類型:表示這個表達式的參數類型,可以表示多個參數的類型,是一個數組;
④ 可本地化計算位置:表示這個表達式在 query 中出現的位置;
⑤ 默認是否開啓:默認是否可以本地化計算,可手動變更;
⑥ 支持類型:支持表達式的類型,如 const、column、agg、bianary、compare。
下面是一個白名單的例子:

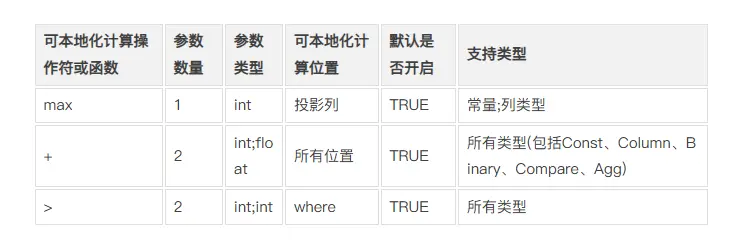
在這個例子中,白名單允許滿足某些條件的 “+” 操作符的表達式進行本地化計算機,“+”操作符滿足以下條件時,可以通過本地化計算實現:
① “+” 操作符的參數數量為2,即左右參數;
② “+” 操作符的參數數類型為:左參數類型為int,右參數類型為int;
③ “+” 操作符出現在where條件中;
④ “+” 操作符的結果為一個常量或列類型。
3.1.4.2 利用白名單控制計算本地化
下面介紹下如何判定這個表達式在白名單中。
① 哈希編碼生成:對每一條白名單記錄,根據 “操作符 / 函數名稱、參數數量、參數類型” 生成唯一的哈希編碼(hash code)。
② 映射表構建:以哈希編碼為 key,“可執行位置、表達式輸出類型” 為 value,構建映射表(map)。
③ 表達式哈希計算:對需判斷的表達式,同樣根據 “操作符 / 函數名稱、參數數量、參數類型” 生成哈希編碼。
④ 映射表匹配與校驗:用表達式的哈希編碼在映射表中查詢,若查詢到對應 value,則進一步校驗 “表達式實際位置是否匹配允許的位置”“輸出類型是否符合要求”。
⑤ 結果判定:若上述校驗均通過,則該表達式可基於白名單規則進行本地化執行;否則不可本地化。
3.1.5 本地化計算判斷舉例説明
下面介紹一個例子判斷計算本地化的過程。
如 select max(e1+e2) from d1.t1 where e1 > 0 group by e1; 其中 e1 列為int類型、e2列為float類型。
假設我們的白名單是這樣的:
首先,這個 query 生成的 memo tree 是這樣的。
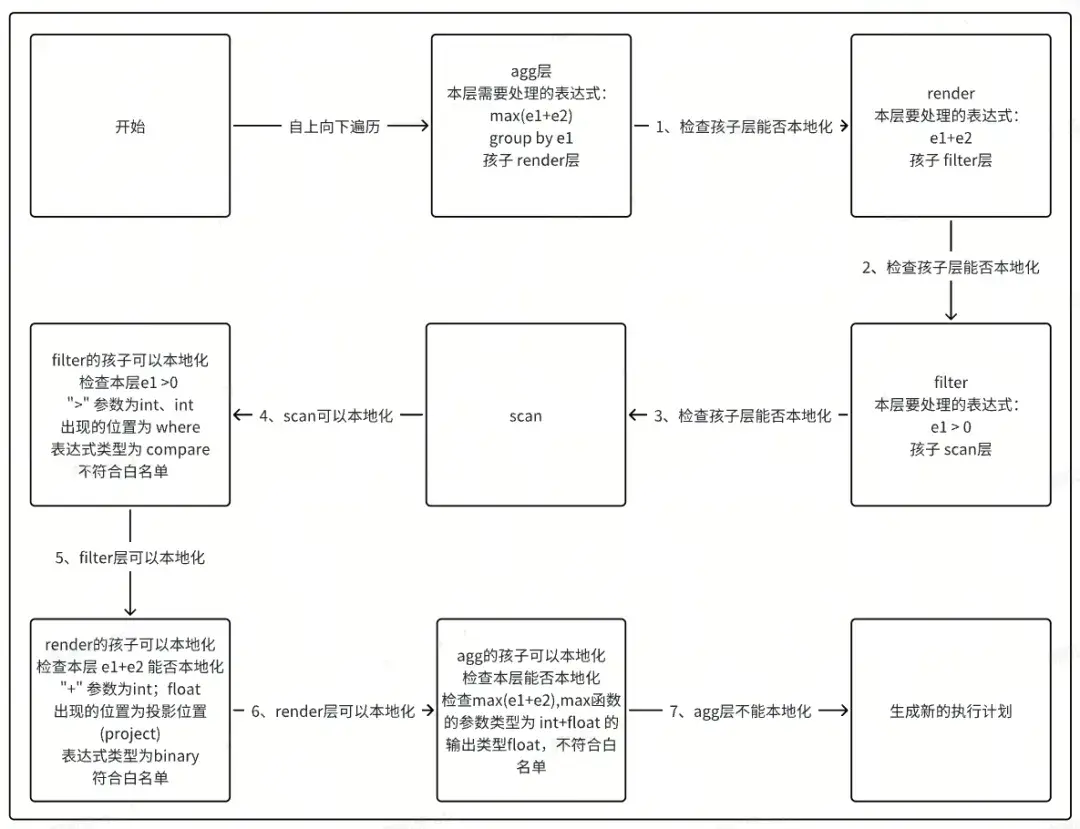
3.1.6 本地化計算主要邏輯入口
① CheckWhiteListAndAddSynchronize 本地化計算邏輯的入口;
② CheckWhiteListAndAddSynchronizeImp 本地化計算邏輯的主體,檢查每一層算子能否本地化計算,其中包含檢查每一層的函數;
③ CheckExprCanExecInTSEngine 判斷本層表達式是否能由時序引擎本地化計算;
④ SetAddSynchronizer 給本層加併發標記。使用時序本地化計算的算子支持併發,所以找到可以本地化計算的最大樹後,會加上可以併發的標記,以供時序引擎執行併發。
3.2 統計信息和 CBO
KWDB 的查詢優化器採用 CBO(Cost-Based Optimization,基於成本的優化)策略,通過統計信息評估不同查詢計劃的預期執行成本,最終選擇成本最低的執行計劃。查詢優化的主要流程如圖所示:
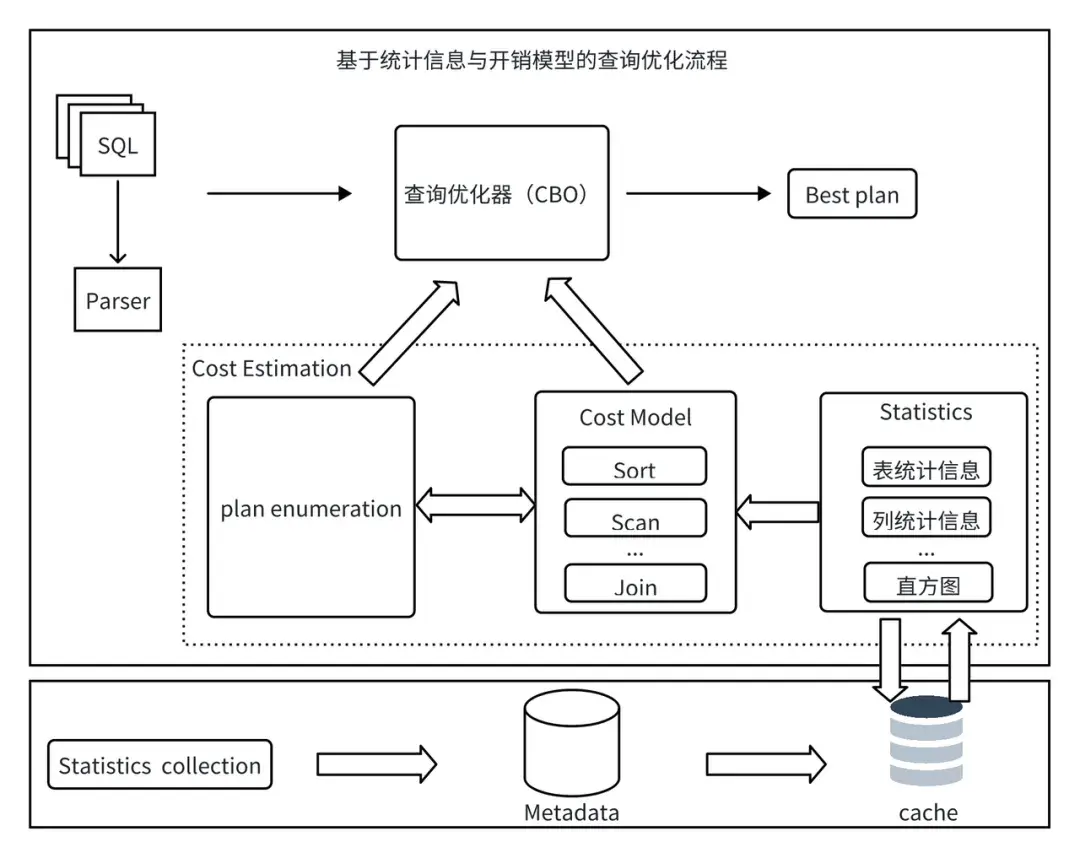
3.2.1 統計信息
統計信息作為查詢優化器的數據源,統計信息的收集過程如圖所示:
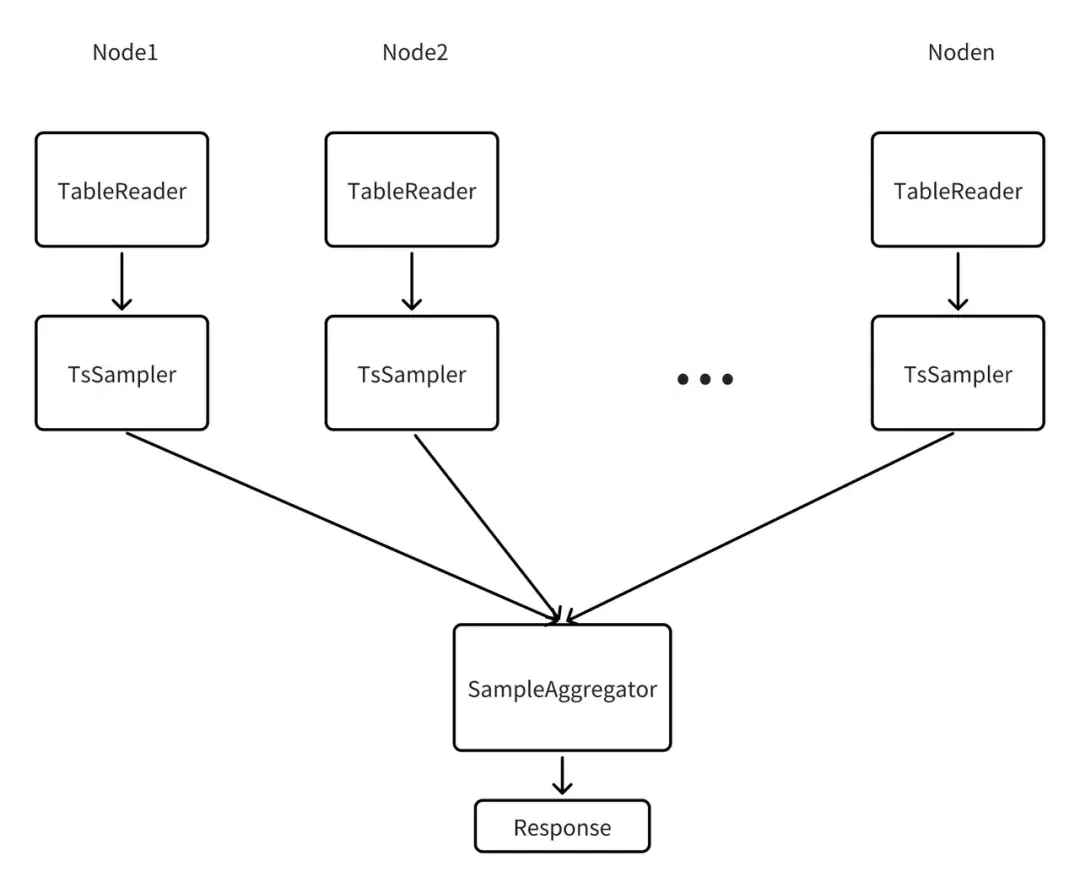
TableReader(表讀取器):在各個數據節點上讀取目標表的數據,為採樣提供原始數據。
TsSampler(樣本採樣器):在每個節點上對 TableReader 讀取的數據進行採樣,統計該節點的表級信息、列的樣本數據與基數。
SampleAggregator(採樣彙總器):接收並聚合所有節點的採樣結果,生成全局統計信息,並將其持久化存儲至系統中,同時更新元數據緩存(Metadata Cache),供後續查詢優化快速調用。
3.2.2 開銷模型
開銷模型由不同種操作類型的開銷計算公式函數組成,在優化器中的主要行為包括:
① 對於傳入的候選表達式,基於邏輯表達式樹中的統計信息,對實際執行代價進行一個估計。
② 將估計代價分配給對應的表達式中,如果候選表達式的成本低於 memo 中的其他任何表達式,則它將成為該組的最佳新表達式。
Costor.go 中以 ComputeCost 為主函數入口展開,調用了相應的對象和其對應的函數來估算出表達式的執行代價。
3.2.3 計劃列舉
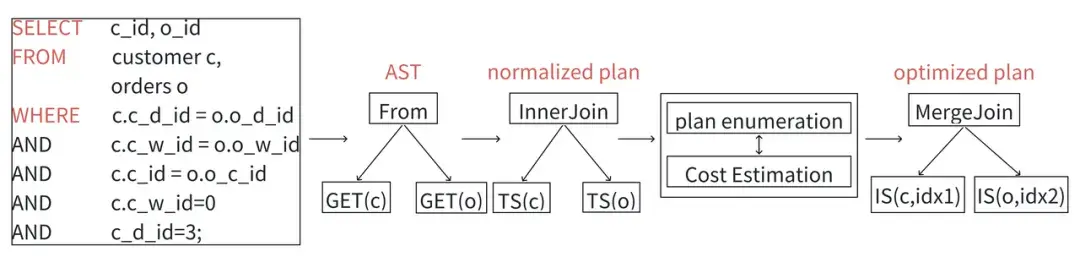
① 查詢優化器採用Cascades框架,自頂向下進行優化;
② 在CBO初始階段,將AST轉化為一個規範化(normalized)計劃;
③ 計劃列舉依次枚舉所有與規範化計劃等價的表達式,並估算每個表達式的代價;
④ 最後輸出估算代價最小的計劃,即最優計劃。
以下舉例説明:
3.3 總結
本文系統梳理了 KWDB 在查詢編譯與優化方面的核心流程,包括 SQL 語句的詞法解析、語法解析、語義解析,以及基於規則的 RBO 優化、基於成本的 CBO 優化,同時詳細介紹了針對多模場景的計算本地化優化策略。KWDB 項目目前仍處於快速迭代階段,更多最新功能與技術創新可通過訪問 KWDB 代碼庫獲取。












