

一、由一張圖引入
首先論文中指明瞭當前Agent memory領域主要有什麼研究方向,從下圖可以看出,這個領域中研究方向很多,我們逐一拆解
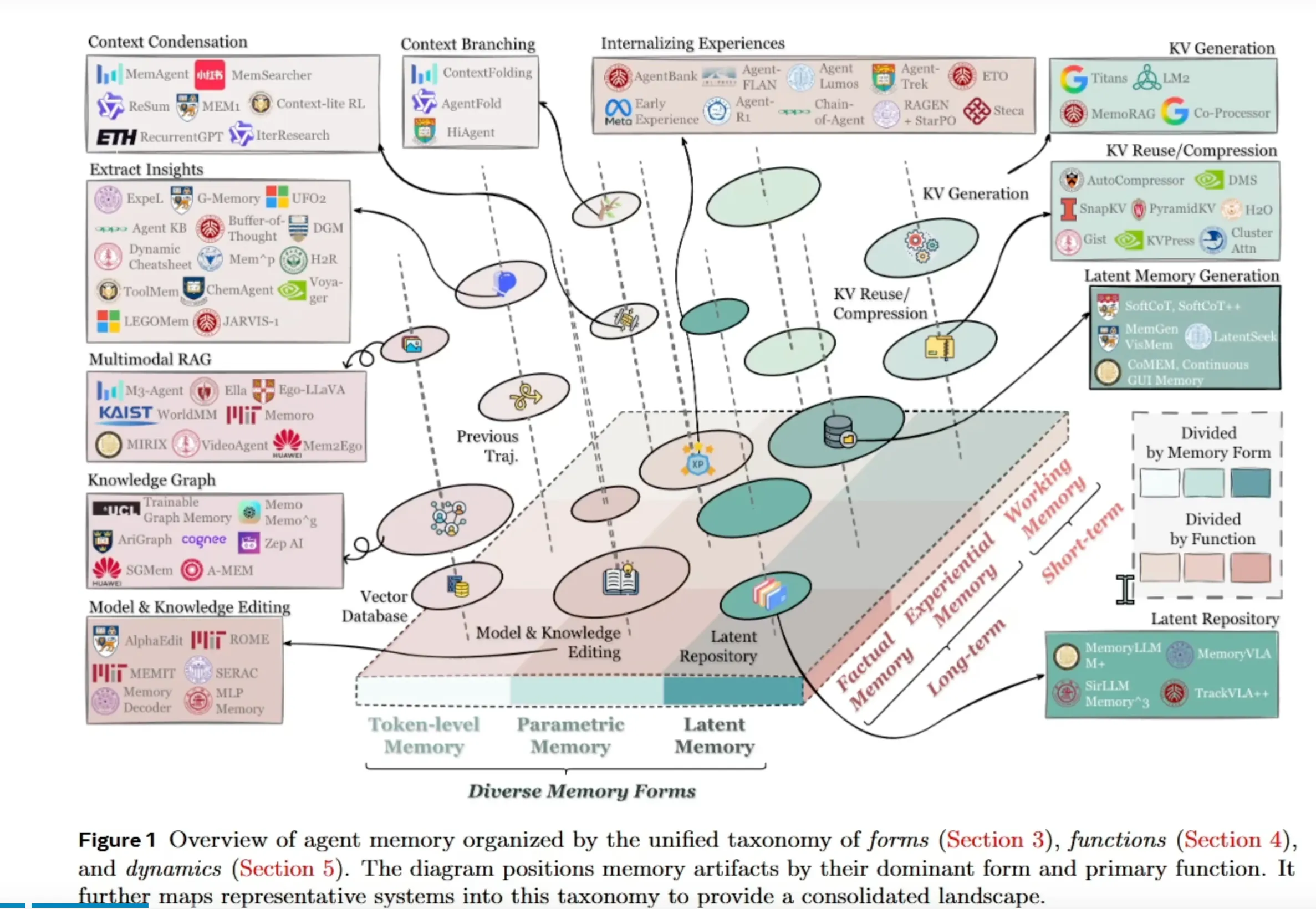
一、 圖的核心目的與價值
標題已點明核心:這是一張基於統一分類法繪製的智能體記憶概覽圖,該分類法包含:
- 形式(Forms):記憶以何種技術形式存在?(第3節)
- 功能(Functions):記憶在智能體中扮演什麼角色?(第4節)
- 動態(Dynamics):記憶如何被操作、更新和演化?(第5節)
圖的價值在於:它將數十個看似獨立的AI智能體系統和記憶模塊(如 G-Memory , Buffer-of-Thought , JARVIS-1 等)整合到一個統一的框架中,讓研究者一眼就能看出某個系統“用哪種形式的記憶,主要解決什麼問題”。
| --- | --- |
| 令牌級/明文記憶 | 原始文本或令牌序列,未經深度編碼。 | Context Condensation , REsum , Gist |
| 參數記憶 | 知識被編碼在神經網絡模型的權重參數中。 | Model & Knowledge Editing (如 ROME , SERAC ) |
| 潛在記憶 | 信息被編碼在低維稠密向量(嵌入)或隱狀態中。 | Vector Database , Latent Repository , AutoCompressor |
| 體驗記憶 | 對事件、交互序列的連貫記錄,常具時空上下文。 | Experience , Memoro , Mem2Ego , Ego-LLaVA |
| 工作記憶 | 當前任務相關的、被激活的短期信息。 | Working Memory , Short-term , Redis |
| 長期記憶 | 持久化存儲的海量知識庫。 | Long-term , Agent KB , Knowledge Graph |
| 加密記憶 | 基於區塊鏈或分佈式賬本,實現不可篡改、可驗證的記憶。 | Distributed ledger , Blockchain , Token-level Cryptographic Memory |
演進邏輯:從易失、具體的工作記憶,到持久、抽象的參數/長期記憶,形成了一個完整的記憶層次結構。
維度2:記憶的功能(Functions)—— “記憶用來做什麼?”
這是圖的縱向次要分類軸,描述了記憶在智能體中的應用場景和目標:
| 功能類別 | 核心目標 | 代表模塊 |
|---|---|---|
| 上下文管理 | 壓縮、篩選、組織當前對話或任務的上下文,以突破模型長度限制。 | Context Condensation , ContextFolding , SnapKV , PyramidKV |
| 經驗內化 | 從過往的交互(成功或失敗)中學習,形成可複用的策略或知識。 | Internalizing Experiences , Chain-of-Agent , RAGEN |
| 知識提取與洞察 | 從海量信息中主動發現模式、規律和新知識。 | Extract Insights , IterResearch |
| 工具使用記憶 | 記住如何調用API、使用工具,並記錄其結果。 | ToolMem , ChemAgent , GUI Memory |
| 世界模型構建 | 形成對環境和物理/社會規律的內部表徵。 | WorldM , KΛIST , VideoAgent |
| 持續學習與適應 | 在不遺忘舊知識的前提下,不斷整合新信息。 | CoMEM , Continuous , Trainable |
維度3:系統的映射(Systems Mapping)—— “誰用了哪種記憶?”
圖的核心區域佈滿了具體的AI智能體系統或模塊名稱,它們被放置在其主要採用的記憶形式和主要實現的記憶功能的交叉區域。
例如:
- G-Memory **, ** Mem^p 被放在 潛在記憶(Latent Memory) 區域,並靠近 知識提取 功能。説明它們擅長用向量表徵來存儲和提取知識。
- JARVIS-1 **, ** VideoAgent 被放在 體驗記憶(Experiential Memory) 區域,並靠近 世界模型 功能。説明它們通過記憶事件序列來理解動態環境。
- Buffer-of-Thought **, ** Dynamic Cheatsheet 被放在 工作記憶(Working Memory) 區域,功能是 上下文管理。説明它們專注於管理和優化當前任務的思考暫存區。
四、 總結:圖揭示了什麼趨勢?
- 記憶是智能體的核心瓶頸與突破點:圖表的複雜性直接反映了業界正在投入巨大精力解決“記憶”問題——如何讓AI記得更多、更準、更智能。
- 從“單一記憶”到“混合記憶體系”:現代智能體不再依賴一種記憶形式,而是組合多種形式(如用向量數據庫做快速檢索 + 用知識圖譜做深度推理 + 用參數編輯做知識更新),形成類似人類的記憶系統。
- 從“被動存儲”到“主動管理”:記憶不再是簡單的存和取,而是包含了動態壓縮、總結、洞察、遺忘(Expel)和持續學習的主動過程。智能體正在學會“如何記住”以及“記住什麼”。
- 跨模態與具身化: Ego-LLaVA , Mem2Ego , VideoAgent 等系統表明,記憶正從純文本擴展到視覺、聽覺、行動序列,為具身智能(如機器人、虛擬人)打下基礎。
總而言之,這張圖是AI智能體記憶技術的“地圖”和“指南”。它告訴研究者:
- 橫軸(形式):你有哪些技術武器?(令牌、向量、參數、圖...)
- 縱軸(功能):你要解決什麼問題?(管理上下文、積累經驗、提取知識...)
- 圖中的點(系統):前人是怎麼做的?我的工作可以填補哪個空白?
這為設計和評估新一代具有更強記憶能力的AI智能體提供了一個非常清晰、實用的理論框架。
二、主要的工作問題

三、 預備知識:形式化代理和記憶
3.1 Agent Memory Systems
當基於LLM的智能體與環境交互時,其瞬時觀測值往往不足以進行有效決策。因此,Agent依賴從先前的交互中獲得的額外信息,無論是當前任務內部還是在以前完成的任務之間。我們通過一個統一的代理記憶系統將這種能力形式化,表示為一個不斷演化的記憶狀態。
這種記憶系統沒有施加特定的內部結構;它可以採用文本緩衝區、鍵值存儲、向量數據庫、圖結構或任何混合表示的形式。在任務開始時,Mt可能已經包含了從先前軌跡中提取的信息(跨試次記憶)。在任務執行過程中,新的信息積累並作為短期的、任務特定的記憶發揮作用。這兩種角色都在單一的記憶容器中得到支持,時間上的區別來自於使用模式,而不是架構上的分離。
3.2 記憶形成 - 演化 - 檢索
智能體記憶不是一個靜態倉庫,而是一個“形成-演化-檢索” 的動態循環系統。其核心要點如下:
1. 記憶形成(Formation)
- 輸入:智能體在每一步交互中產生的原始“信息工件”,如工具調用的結果、內部推理的步驟、計劃的片段、自我評價或環境反饋。
- 過程:通過一個 “形成操作符 F” 進行篩選和提煉。
- 核心原則:不是全盤記錄歷史,而是像一名經驗豐富的編輯,主動提取那些對未來決策可能有用的精華信息,將其轉化為“記憶候選”。
2. 記憶演化(Evolution)
- 輸入:上一步篩選出的“記憶候選”。
- 過程:通過一個 “演化操作符 E” 將其整合到長期記憶中。
- 關鍵操作:這是一個主動管理的過程,包括:合併相似或重複的記憶。解決新舊記憶間的矛盾。遺忘(丟棄) 價值不高的信息。重組結構以便未來能快速、準確地查找。
- 結果:形成一個持續更新、結構清晰、去蕪存菁的 “記憶基”。
3. 記憶檢索(Retrieval)
- 時機:當智能體需要做出決策時。
- 過程:根據當前的觀察和任務,通過 “檢索操作符 R” 構建查詢,從龐大的記憶庫中動態提取最相關的片段。
- 輸出:生成一個格式化的 “記憶信號” ,直接作為提示的一部分輸入給語言模型,從而用過去的經驗指導當下的行動。
四、 將agent內存與其他關鍵概念進行比較
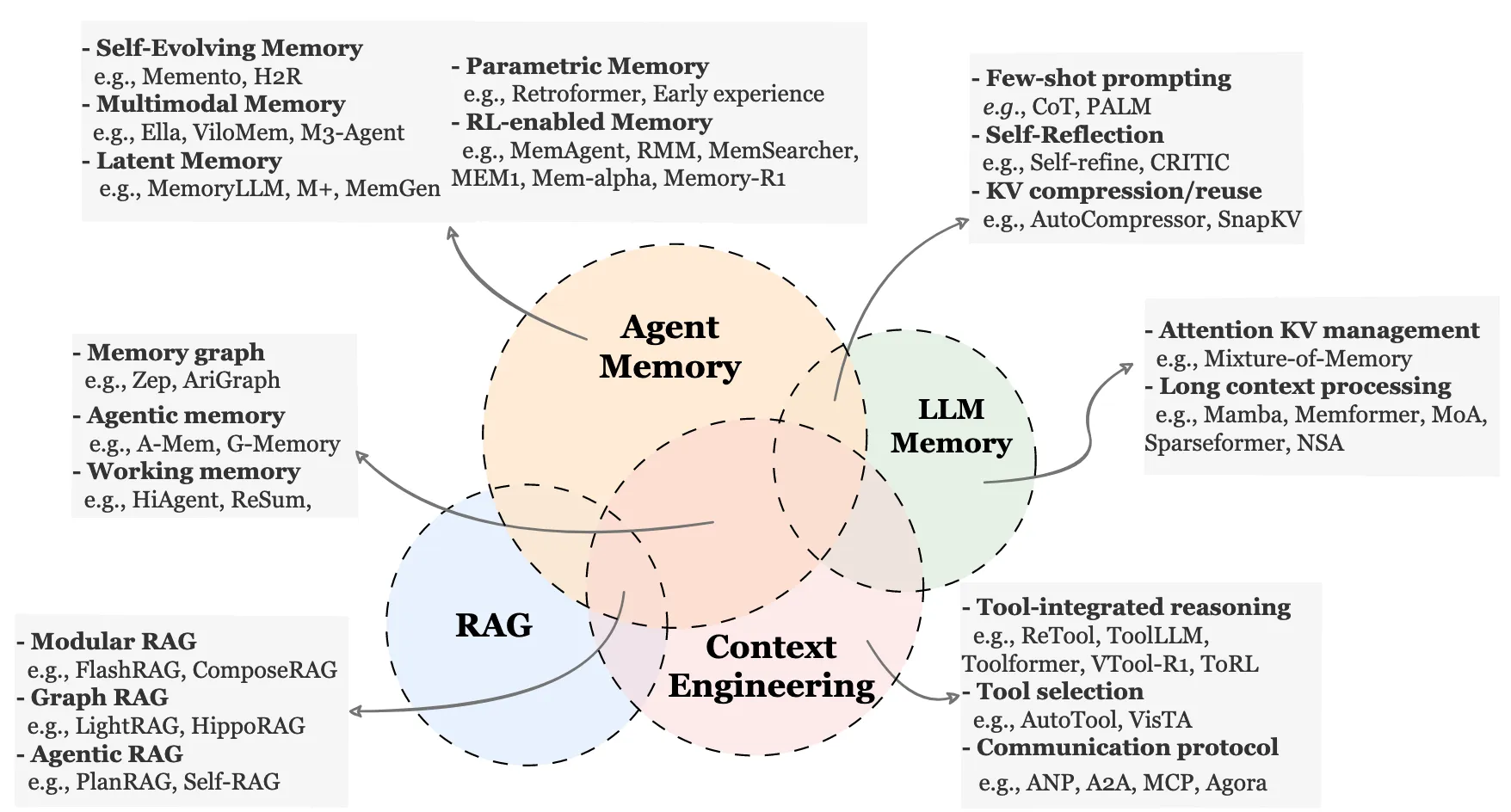
4.1 Agent Memory (代理記憶)
- 是什麼:智能體專屬的記憶系統,負責記錄、存儲和利用自身的交互經驗和內部狀態。
- 怎麼實現:圖中展示了多種技術路徑:
- 自我演化記憶:如 Memento ,讓記憶能根據新經驗自動優化和成長。
- 多模態記憶:如 Ella ,能存儲和處理圖像、視頻等多感官信息。
- 潛在/參數記憶:將經驗編碼為模型內部的向量或直接調整模型參數。
- 強化學習賦能記憶:如 MemAgent ,用RL策略來優化記憶的存儲和檢索。
- 關鍵模塊: Memory Graph (記憶圖譜,如 Zep )、 Agentic Memory (代理記憶,如 G-Memory )、 Working Memory (工作記憶,如 HiAgent )。
4.2 LLM Memory (大語言模型記憶)
- 是什麼:挖掘和優化大模型自身固有的記憶與推理能力,不依賴外部工具。
- 怎麼實現:
- 提示工程:如 CoT (思維鏈),引導模型展示推理過程。
- 自我反思:如 CRITIC ,讓模型自我檢查、發現並修正錯誤。
- 技術優化:如 KV壓縮 、 長上下文模型 (如 Mamba ),直接擴展模型“記得住”的內容量。
4.3 RAG (檢索增強生成)
- 是什麼:通過從外部知識庫(如文檔、數據庫)中實時檢索相關信息,來增強大模型的回答,保證事實準確性。
- 怎麼實現:
- 模塊化RAG:將檢索、生成等步驟拆分成可替換的模塊。
- 圖RAG:利用知識圖譜進行更復雜的語義檢索。
- 智能體RAG:如 Self-RAG ,讓模型自己判斷何時需要檢索、檢索結果是否相關。
4.4 Context Engineering (上下文工程)
- 是什麼:管理與外部世界的交互接口和協議,讓智能體能有效地使用工具、進行通信。
- 怎麼實現:
- 工具集成推理:如 ToolLLM ,學習如何規劃和調用各種API工具。
- 工具選擇:面對多個工具時,能智能選擇最合適的一個。
- 通信協議:如 Agora ,定義智能體之間如何交換信息和協作。
五、 記憶存在形式
在不同的Agent系統中,記憶並不是通過單一的、統一的結構來實現的。相反,不同的任務設置需要不同的存儲形式,每種存儲形式都有自己的結構屬性。這些架構賦予了記憶不同的能力,塑造了智能體如何通過交互積累信息並保持行為一致性。它們最終使記憶能夠在不同的任務場景中完成其預定的角色。

5.1 Token-level Memory
Token級記憶:以離散、外部可訪問的單元(如文本塊、向量、圖節點)存儲信息。這是最常見的形式,可進一步按組織結構分為:
- 扁平記憶:無顯式結構(如序列、集合)。
- 平面記憶:單層結構(如圖、樹、表)。
平面記憶( Planar Memory )引入了記憶單元之間的顯式組織拓撲,但僅限於單個結構層內,簡稱為2D。拓撲可能是圖、樹、表、隱式連接結構等,其中鄰接、父子序或語義分組等關係編碼在一個平面內,沒有層次或跨層引用。
- 分層記憶:多層互連的複雜結構。
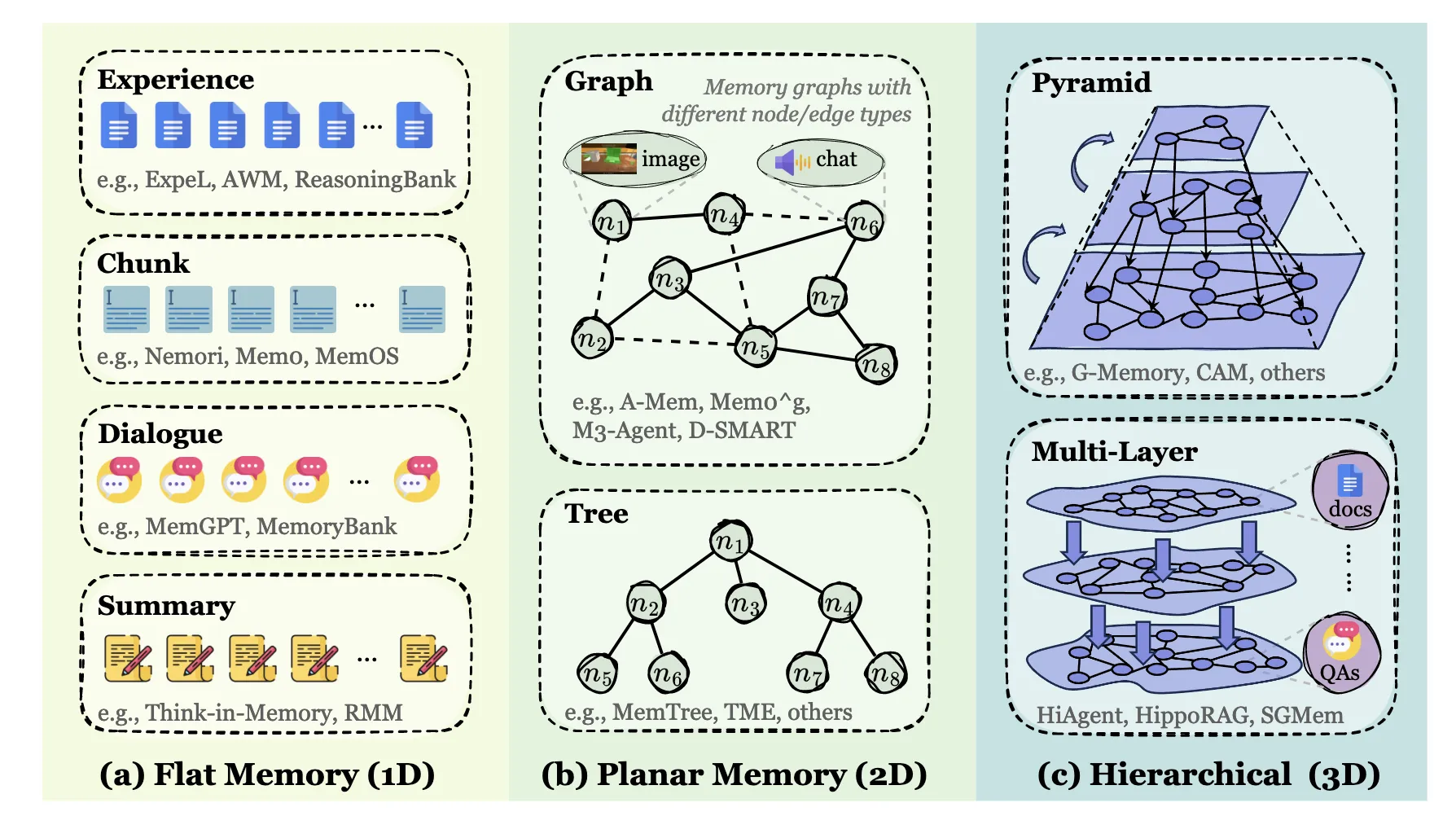
5.2 Parametric Memory
參數記憶:信息編碼在模型參數內部,通過前向計算隱式訪問。
參數記憶的兩種主要類型
1 .內部參數記憶:在模型( e.g. ,權重,偏差)的原始參數內編碼的記憶。這些方法直接對基模型進行調整,以納入新的知識或行為。
2 .外部參數存儲器:存儲在額外或輔助參數集合中的存儲器,如適配器、LoRA模塊或輕量級代理模型。這些方法在不修改原有模型權重的前提下,引入新的參數進行記憶。
5.3 Latent Memory
潛在記憶:信息存在於模型的內部隱藏狀態或連續的潛在表示中,在推理過程中持續和演化。
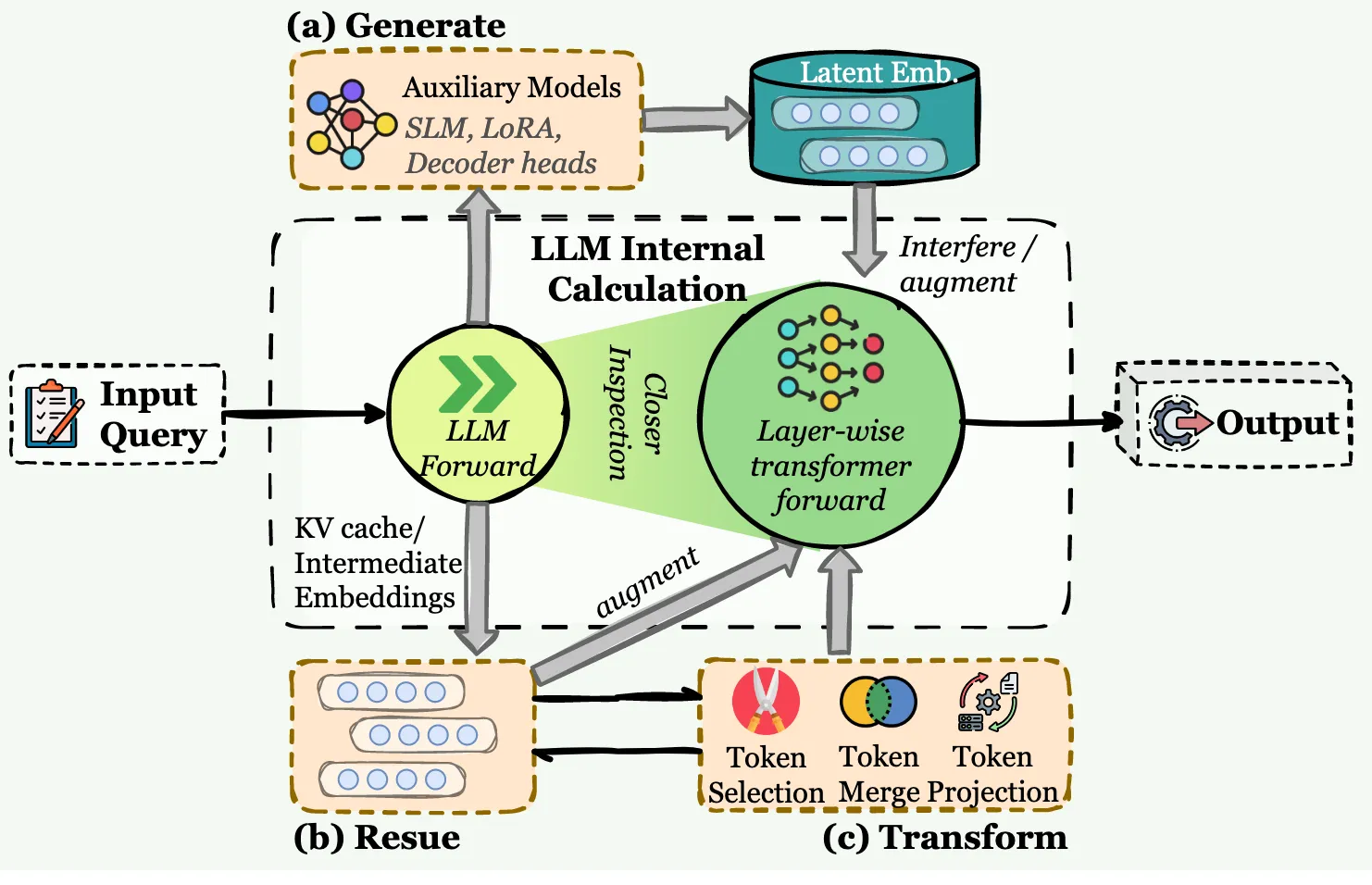
LLM代理中的潛在內存集成概述。與顯式文本存儲不同,潛在記憶在模型的內部表徵空間進行操作。該框架根據隱狀態的來源進行分類:
( a )生成,其中輔助模型合成嵌入,以干擾或增強LLM的前向傳遞;
( b )重複使用,它直接傳播先驗計算狀態,如KV緩存或中間嵌入;
( c ) Transform,它通過令牌選擇、合併或投影來壓縮內部狀態,以保持有效的上下文。
六、Why Agent Need Memory?
根據定義,智能體必須隨着時間的推移而持續、適應和一致地交互。實現這一點不僅依賴於一個大的語境窗口,而且從根本上取決於記憶的容量。
三個主要記憶功能
1 .Factual Memory 事實記憶:智能體的陳述性知識基礎,通過回憶明確的事實、用户偏好和環境狀態來確保一致性、連貫性和適應性。這個系統回答了"智能體知道什麼"的問題。
2 .Exp Memory 經驗記憶:行動者的程序性和策略性知識,通過從過去的軌跡、失敗和成功中抽象出來而積累起來,以使其能夠持續學習和自我進化。這個系統回答:"智能體如何改進"
3 .Working Memory 工作記憶:智能體的容量限制,動態控制的畫板,用於在單個任務或會話期間進行主動的上下文管理。這個系統回答:'智能體現在在想什麼'
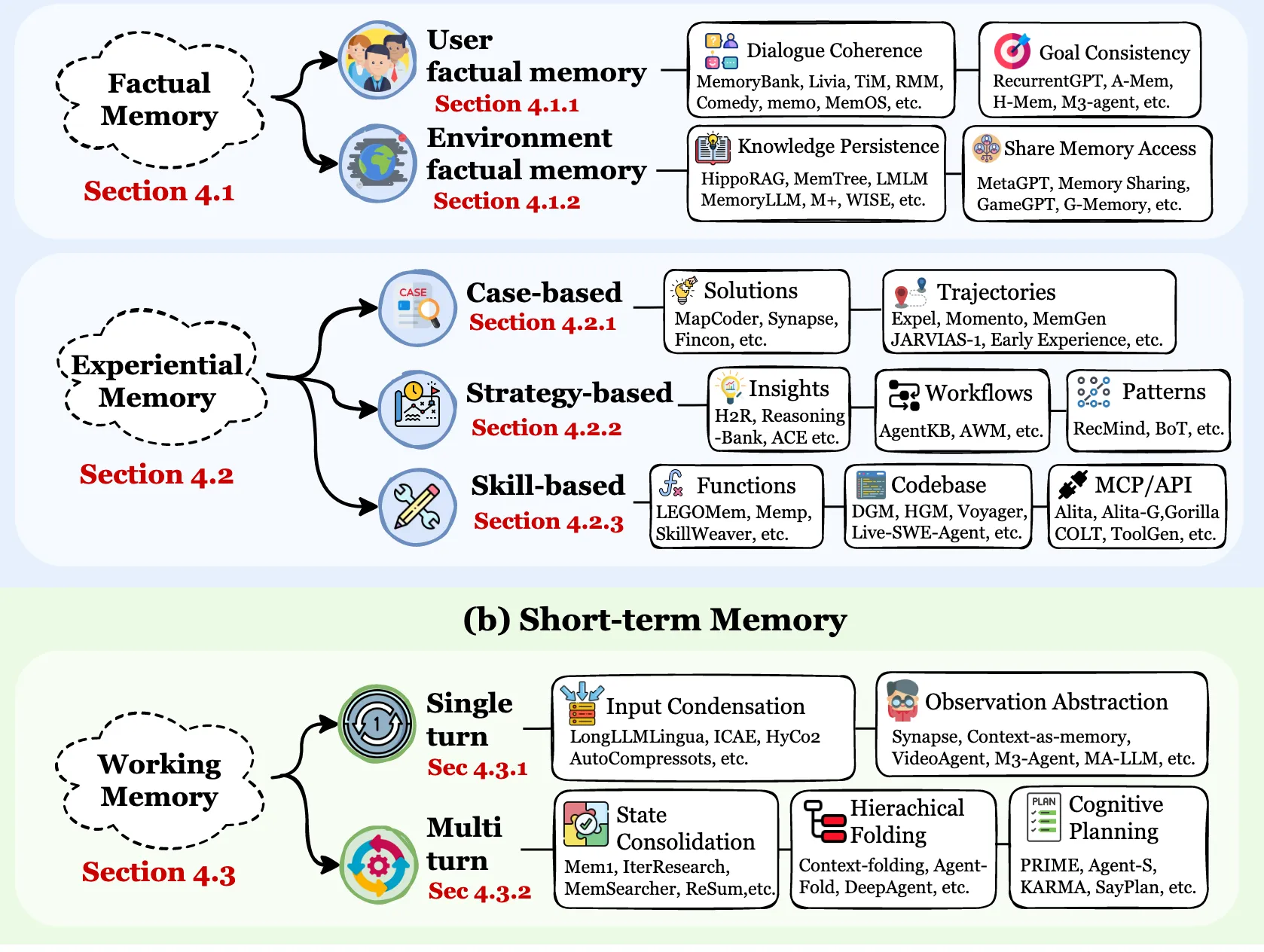
6.1 第一部分:長期記憶 Long-term Memory
這部分是智能體持久化的“大腦皮層”,存儲着長期、穩定的信息。它被分為兩大類:
- 事實記憶
存儲關於世界和用户的客觀事實。
- 用户事實記憶:記住用户的個人信息、偏好等(如用户説“我對花生過敏”)。
- 對話一致性:確保在長對話中,智能體對之前説過的話、用户提過的要求保持一致,不自相矛盾。代表工具:MemoryBank, TiM。
- 目標一致性:記住用户的終極目標,在執行多步驟任務時不跑偏。代表工具:A-Mem, H-Mem。
- 知識持久化與共享:將學到的通用知識(如常識、專業知識)固化下來,並能在不同任務或智能體間共享。代表工具:HippoRAG, G-Memory。
- 經驗記憶
存儲智能體親身實踐過的行動和思考過程,類似於人類的“閲歷”。
- 基於案例的:記住過去成功或失敗的完整任務實例。
- 解決方案:存儲具體問題的解決方法和答案。代表工具:MapCoder。
- 行動軌跡:記錄完成任務的一系列具體步驟(思考→行動→結果)。代表工具:Momento, JARVIS-1。
- 基於策略的:從大量案例中提煉出的通用規律和方法論。
- 洞察與推理:抽象出的推理模式和深度洞察。代表工具:Reasoning-Bank。
- 工作流程:完成某類任務的標準操作程序。代表工具:AgentKB。
- 模式:可複用的解決方案模板。代表工具:Buffer-of-Thought。
- 基於技能的:掌握的具體操作能力,尤其是使用外部工具的能力。
- 函數工具:封裝好的可調用函數。代表工具:SkillWeaver。
- 代碼庫:編寫和執行代碼的能力。代表工具:Voyager。
- API協議:理解和調用各種應用程序接口的規則。代表工具:Gorilla。
6.2 第二部分:工作記憶 Short-term memory
這部分相當於智能體的“桌面”或“思維緩存”,處理當前任務相關的即時信息。它容量有限,但高度活躍和動態。
- 單輪交互處理:處理當前這一步的輸入。
- 輸入濃縮:在信息過長時,智能地壓縮或提取關鍵信息,以節省有限的上下文窗口。代表工具:LongLLMLingua。
- 觀察抽象化:將看到的原始數據(如一段視頻描述)轉化為高層次的理解。代表工具:VideoAgent。
- 多輪交互處理:管理與整合跨越多個步驟的思維狀態。
- 狀態合併:將分散在多輪對話中的信息整合成一個連貫的上下文。代表工具:Mem1, ReSum。
- 層級摺疊:將複雜的、長篇的思維過程分層摺疊,保持主幹清晰。代表工具:Agent-Fold。
- 認知規劃:在行動前進行內部推演和步驟規劃。代表工具:PRIME, SayPlan
七、動態:記憶是如何運作和演化的
前幾節介紹了記憶的架構形式(第3節)和功能角色(第4節),勾勒出一個相對靜態的主體記憶概念框架。然而,這種靜態的觀點忽略了根本上表徵施事記憶的內在動態性。與靜態編碼在模型參數或固定數據庫中的知識不同,代理記憶系統可以動態地構建和更新其記憶庫,並根據不同的查詢執行定製的檢索。
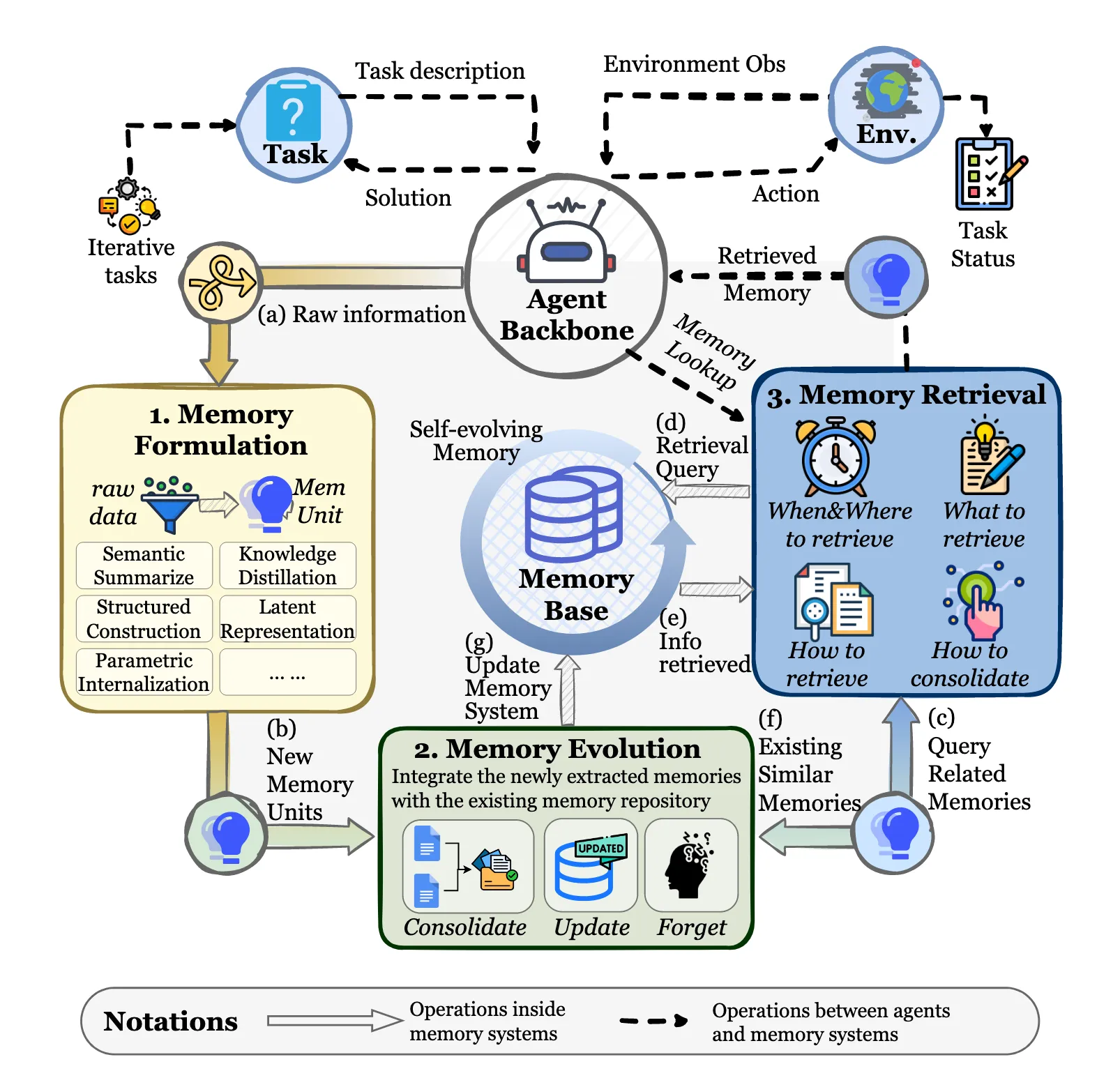
記憶系統中的三個基本過程
1 . MemoryForformation:這個過程着重於將原始經驗轉化為信息密集的知識。記憶系統不是被動地記錄所有的交互歷史,而是有選擇地識別具有長期效用的信息,如成功的推理模式或環境約束。這一部分回答了"如何提取記憶"的問題。
2 . Memory Evolution:這個過程代表了記憶系統的動態演化。它注重將新形成的記憶與已有的記憶基礎進行整合。 該系統通過相關詞條的合併、衝突解決、自適應剪枝等機制,保證了記憶在不斷變化的環境中保持可泛化、連貫和高效。這一部分回答了"如何提煉記憶"的問題。
3 .內存檢索:這個過程決定了檢索到的內存的質量。在上下文的條件下,系統構建了一個任務感知的查詢,並使用精心設計的檢索策略來訪問相應的內存庫。因此,提取的記憶對推理既是語義相關的,也是功能關鍵的。這一部分回答了"如何利用記憶"的問題。
7.1 三大核心模塊:記憶系統的完整生命週期
智能體的“智能”主要體現在它能利用過去、指導現在、優化未來。這三個模塊共同構成了一個完整的“學習-記憶”閉環。
- 模塊1:記憶構建——從經驗中提煉智慧
目的:不是簡單地記錄所有聊天記錄,而是像人類做筆記一樣,從原始交互數據中提煉出有價值、可複用的“知識單元”。
輸入(a):原始對話、工具輸出、任務結果等。
處理過程:
- 語義總結:將冗長的文本濃縮為要點。
- 結構化構建:將信息整理成清晰的格式(如誰、何時、做了什麼、結果如何)。
- 知識蒸餾:從具體案例中提取通用規律。
- 潛在表徵 / 參數內化:將知識編碼為向量或調整模型自身的參數。
輸出(b):結構化的、語義清晰的 “新記憶單元”。
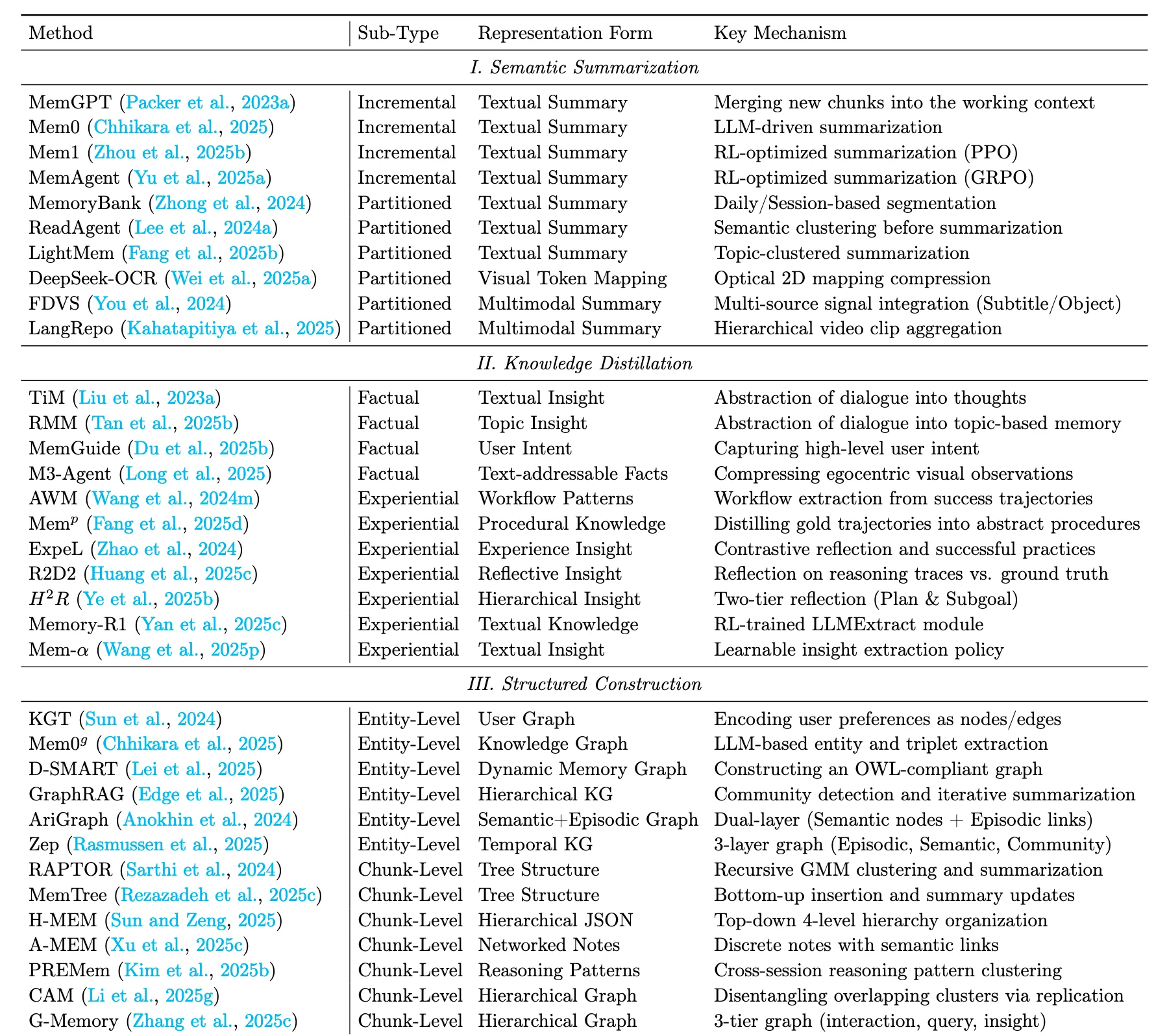
Summary Semantic summarization operates as a lossy compression mechanism, aiming to distill the gist from lengthy interaction logs. Unlike verbatim storage, it prioritizes global semantic coherence over local factual precision, transforming linear streams into compact narrative blocks. The primary strength of semantic summarization is efficiency: it drastically reduces context length, making it ideal for long-term dialogue. However, the trade-off is resolution loss: specific details or subtle cues may be smoothed out, limiting their utility in evidence-critical tasks.
7.1.1 增量式摘要
該範式採用時間整合機制,不斷將新觀察到的信息與已有的摘要進行融合,產生了一種不斷演化的全局語義表示。
7.1.2 分區摘要
該範式採用空間分解機制,將信息劃分為不同的語義分區,併為每個分區生成單獨的摘要。早期的研究通常採用啓發式的劃分策略來處理長語境。
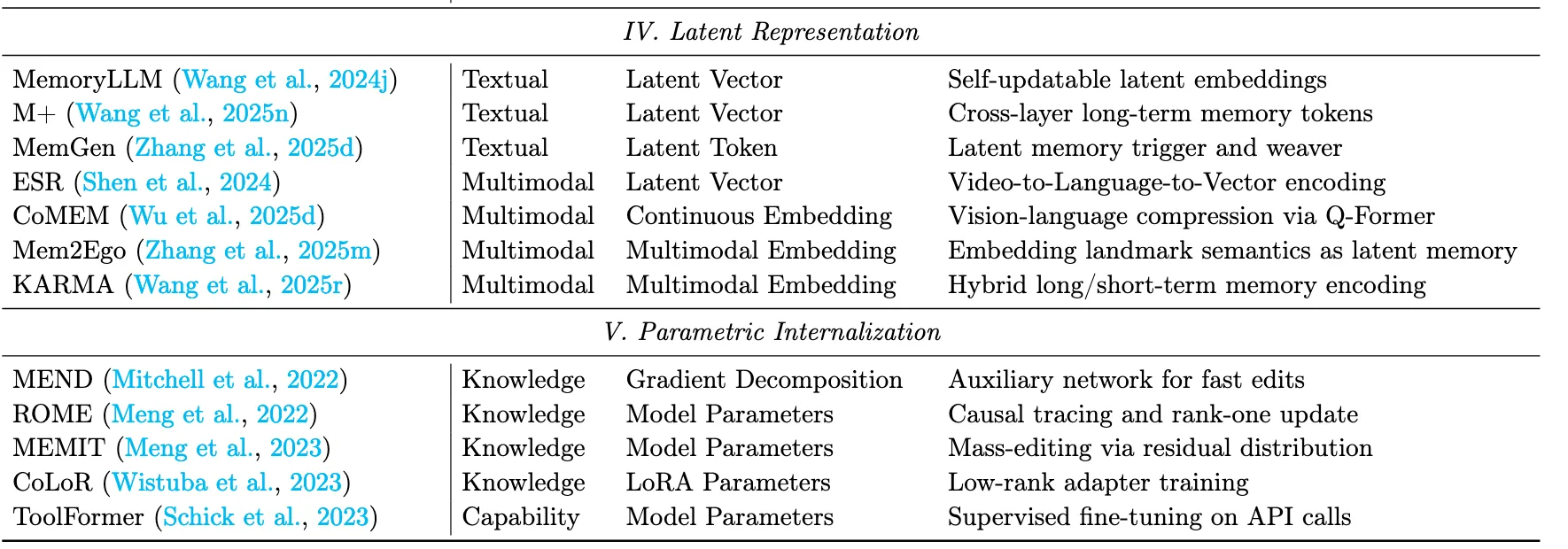
Summary:The main advantage of structured construction is explainability and the ability to handle complex relational queries. Such methods capture intricate semantic and hierarchical relationships between memory elements, support reasoning over multi-step dependencies, and facilitate integration with symbolic or graph-based reasoning frameworks. However, the downside is schema rigidity: pre-defined structures may fail to represent nuanced or ambiguous information, and the extraction and maintenance costs are typically high.
7.1.5 實體層次的結構化
該範式的基礎結構來源於關係三元組抽取,它將原始上下文分解為其最細粒度的語義原子實體和關係。傳統方法將記憶建模為平面知識圖譜。
7.1.6 分塊層次的結構化
該範式將連續的文本跨度或離散的記憶項作為節點,在保持局部語義完整性的同時將其組織成拓撲結構。該領域的發展經歷了從靜態的、平面的( 2D )從固定語料中提取,到動態地適應新的軌跡,最終發展到分層的( 3D )架構。
Summary:Parametric internalization represents the ultimate consolidation of memory, where external knowledge is fused into the model’s weights via gradients. This shifts the paradigm from retrieving information 54 to possessing capability, mimicking biological long-term potentiation. As knowledge becomes effectively instinctive, access is zero-latency, enabling the model to respond immediately without querying external memory. However, this approach faces several challenges, including catastrophic forgetting and high update costs. Unlike external memory, parameterized internalization is difficult to modify or remove precisely without unintended side effects, limiting flexibility and adaptability.
7.1.10 知識內化
這一策略需要將外部存儲的事實記憶,如概念定義或領域知識,轉換到模型的參數空間中。通過這個過程,模型可以直接回憶和利用這些事實,而不需要依賴顯式檢索或外部記憶模塊。
7.1.11
能力內化這一策略旨在將經驗知識,如程序性專業知識或戰略啓發式知識,嵌入到模型的參數空間中。該範式代表了一種廣義上的記憶形成操作,從事實性知識的獲得轉向經驗能力的內化。具體來説,這些能力包括特定領域的解決方案模式、戰略規劃以及Agent技能的有效部署等。從技術上講,能力內化是通過從推理軌跡中學習,通過有監督的微調( Wei et al , 2022 ; Zelikman et al , 2022 ; Schick et al , 2023 ;慕克吉et al , 2023)或偏好引導的優化方法,如DPO (拉斐洛夫等)來實現的 2023年;滕斯托爾et al,2023;Yuan et al .,2024c;Grattafiori et al,2024 )和GRPO (邵敏等, 2024 ; DeepSeek-AI et al , 2025)。作為將外部RAG與參數化訓練相融合的嘗試,Memory Decoder ( Cao et al , 2025a)是一種即插即用的方法,它不像外部RAG那樣修改基模型,同時通過消除外部檢索開銷來實現參數內化的推理速度。這種即插即用的參數化記憶可能具有廣泛的潛力。
- 模塊2:記憶進化——知識庫的自我優化
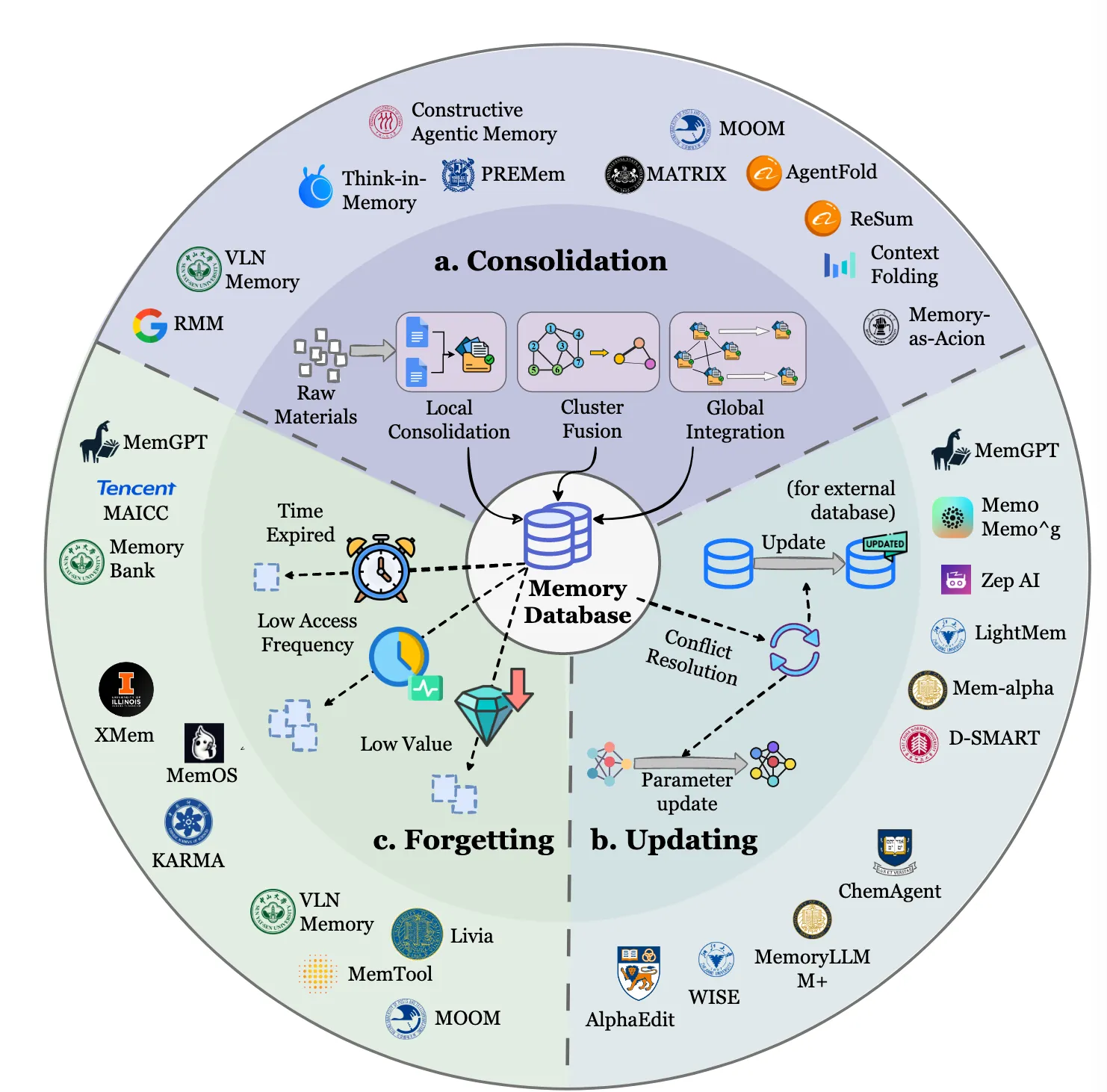
目的:管理記憶庫,使其像一個不斷成長的智庫,而不是一個雜亂無章的倉庫。通過整合、去重、更新,確保知識的質量和可用性。
輸入(g):從模塊1來的新記憶單元。
處理過程:
- 整合:將新知識與庫中已有的相關知識聯繫起來。
- 鞏固:合併重複或高度相似的知識點,形成更強大的記憶痕跡。
- 更新:用更準確、更新的信息覆蓋舊有或錯誤的知識。
- 輸出:更新後的、結構更優的 “記憶庫”。
記憶進化的三種機制
7.2.1 記憶整合
Consolidation is the cognitive process of reorganizing fragmented short-term traces into coherent long-term schemas. It moves beyond simple storage to synthesize connections between isolated entries, forming a structured worldview. It enhances generalization and reduces storage redundancy. However, it risks information smoothing, where outlier events or unique exceptions are lost during the abstraction process, potentially reducing the agent’s sensitivity to anomalies and specific events.
將新的和已有的記憶進行融合,進行反思性整合,形成更一般化的洞見。這確保了學習是累積的而不是孤立的。
- 局部合併: 這項操作側重於涉及高度相似的內存片段的細粒度更新。在RMM ( Tan et al , 2025c)中,每一個新的主題存儲器檢索它的前K個最相似的候選,LLM決定合併是否合適,從而減少錯誤泛化的風險。
- 簇級融合: 採用簇級融合對於捕捉隨着內存增長的跨實例規律是必不可少的。在跨集羣中,PREMem ( Kim et al . , 2025b)將新的記憶集羣與相似的現有記憶集羣對齊,並採用泛化、精化等融合模式形成高階推理單元,顯著提高了可解釋性和推理深度。
- 全局整合:這項操作進行整體整合,以保持全球一致性,並從積累的經驗中提取系統級的見解。語義摘要側重於從現有的上下文中推導出一個全局的摘要,可以看作是摘要的初始構建。In contrast, this paragraph emphasizes how new information is integrated into an existing summary as additional data arrives.
7.2.2 內存更新
Summary:From an implementation standpoint, memory updating focuses on resolving conflicts and revising knowledge triggered by the arrival of new memories, whereas memory consolidation emphasizes the integration and abstraction of new and existing knowledge. The two memory updating strategies discussed above establish a dual-pathway mechanism involving conflict resolution in external databases and parameter editing within the model, enabling agents to perform continuous self-correction and support long-term evolution. The key challenge is the stability–plasticity dilemma: determining when to overwrite existing knowledge versus when to treat new information as noise. Incorrect updates can overwrite critical information, leading to knowledge degradation and faulty reasoning.
解決了新的和現有內存之間的衝突,糾正和補充了存儲庫,以保持準確性和相關性。它允許代理適應環境或任務需求的變化。
- 外部記憶更新:當出現矛盾或新的事實時,對向量數據庫或知識圖譜中的條目進行修改。該方法不改變模型權重,而是通過外部存儲的動態修改來保持事實一致性。靜態記憶不可避免地會積累過時或衝突的條目,導致邏輯不一致和推理錯誤。更新外部存儲器可以實現輕量級的修正,同時避免了完全重新訓練或重新索引的成本。
- 模型編輯:模型編輯在模型的參數空間內進行直接修改,以修正或注入知識,而不需要進行充分的再訓練,代表隱式的知識更新。再訓練代價高昂且容易發生災難性遺忘。模型編輯可以實現精確的、低成本的校正,從而增強適應性和內部知識保留。
7.2.3 內存遺忘
Summary Time-based decay reflects the natural temporal fading of memory, frequency-based forgetting ensures efficient access to frequently used memories, and importance-driven forgetting introduces semantic discernment. These three forgetting mechanisms jointly govern how agentic memory remains timely, efficiently accessible, and semantically relevant. However, heuristic forgetting mechanisms like LRU may eliminate long-tail knowledge, which is seldom accessed but essential for correct decision-making. Therefore, when storage cost is not a critical constraint, many memory systems avoid directly deleting certain memories.
刪除過時或冗餘的信息,釋放容量,提高效率。這樣可以防止由於知識過載而導致的性能下降,並確保內存存儲庫仍然專注於可操作的和當前的知識。
- 基於時間的遺忘:時間驅動的遺忘只考慮記憶的產生時間,隨着時間的推移逐漸衰減記憶的強度,以模擬人類記憶的衰退。
- 基於頻率的遺忘:頻率驅動的遺忘根據提取行為對記憶進行優先排序,保留頻繁訪問的條目,而丟棄不活躍的條目。
- 重要性驅動的遺忘:重要性驅動的遺忘整合了時間、頻率和語義信號,在修剪冗餘的同時保留高價值知識。
基於時間的衰減反映了記憶的自然時間衰減,基於頻率的遺忘保證了對經常使用的記憶的有效訪問,而重要性驅動的遺忘引入了語義辨別。這三種遺忘機制共同決定了施事記憶如何保持及時、有效和語義相關。然而,LRU等啓發式遺忘機制可能會消除長尾知識,而這些知識很少被訪問,但對於正確決策至關重要。因此,當存儲開銷不是一個關鍵的限制條件時,許多存儲系統避免直接刪除某些內存。
- 模塊3:記憶檢索——在正確的時間獲取正確的知識
目的:當智能體面對新任務時,它能主動、精準地從龐大的記憶庫中召回最相關的經驗來輔助決策。
- 輸入(c):由Agent Backbone根據當前任務和環境生成的檢索查詢。
- 處理過程:
- 判斷時機與位置:決定何時、從記憶庫的哪個部分進行檢索。
- 生成檢索策略:決定“如何檢索”,比如是基於語義相似度、任務類型還是時間順序。
- 輸出(d):一組與當前問題高度相關的記憶片段,這些片段會被送給Agent Backbone作為思考的上下文。
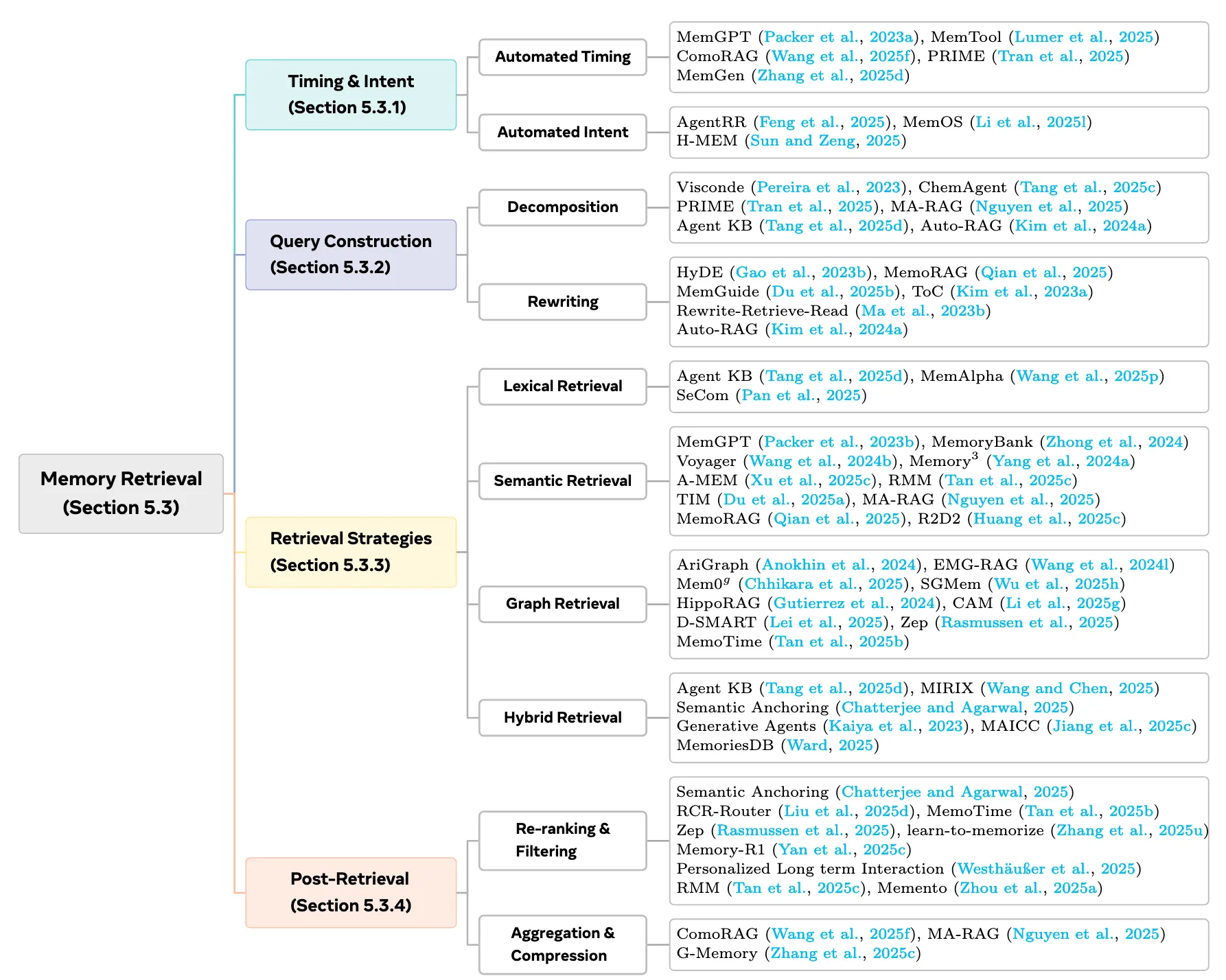
7.3.1 檢索時機和檢索意圖
Summary: Autonomous timing and intent help reduce computational overhead and suppress unnecessary noise, but they also create a potential vulnerability. When an agent overestimates its internal knowledge and fails to initiate retrieval when needed, the system can fall into a silent failure mode in which knowledge gaps may lead to hallucinated outputs. Therefore, a balance needs to be achieved: providing the agent with essential information at the right moments while avoiding excessive retrieval that introduces noise.
自動檢索時機這一術語是指模型在推理過程中自主決定何時觸發記憶檢索操作的能力。最簡單的策略是將決策委託給LLM或外部控制器,允許其僅從查詢中確定是否需要檢索。自動檢索意圖這一方面涉及模型自主決定在一個層次的存儲形式中訪問哪個內存源的能力。
7.3.2 查詢信號
These two paradigms, decomposition and rewriting, are not mutually exclusive. Auto-RAG (Kim et al., 2024a) integrates both by evaluating HyDE and Visconde under identical retrieval conditions and then selecting the strategy that performs best for the given task. The findings of this work demonstrate that the quality of the memory-retrieval query has a substantial impact on reasoning performance. In contrast to earlier research, which primarily focused on designing sophisticated memory architectures, recent studies (Yan et al., 2025b) place increasing emphasis on the retrieval construction process, shifting the role of memory toward serving retrieval. The choice of what to retrieve with is, unsurprisingly, a critical component of this process.
- 查詢分解:這種方法將複雜的查詢分解成更簡單的子查詢,使得系統能夠檢索到更細粒度和更相關的信息。這種分解通過對中間結果進行模塊化檢索和推理,緩解了一次性檢索的瓶頸。
- 查詢重寫策略:不是分解,而是在檢索之前重寫原始查詢或生成假設文檔以細化其語義。這樣的重寫減輕了用户意圖和內存索引之間的不匹配。
7.3.3 檢索策略
- 詞彙檢索:該策略依靠關鍵詞匹配來定位相關文檔,具有代表性的方法包括TF - IDF ( SPARCK JONES , 1972)和BM25 (羅伯特森和扎拉戈薩, 2009)。
- 語義檢索:該策略將查詢和記憶條目編碼到一個共享的嵌入空間中,並基於語義相似性而不是詞彙重疊進行匹配。
- 圖檢索:這種策略不僅利用了語義信號,還利用了圖的顯式拓撲結構,從而實現了本質上更精確和結構感知的檢索。通過直接訪問結構路徑,這些方法表現出更強的多跳推理能力,能夠更有效地探索長程依賴關係。此外,將關係結構作為推理路徑的約束,自然支持由精確規則和符號約束控制的檢索。
- 生成式檢索:該策略用直接生成相關文檔標識符( Tay et al , 2022 ; Wang et al , 2022b)的模型來代替詞彙或語義檢索。通過將檢索作為條件生成任務,模型將候選文檔隱式地存儲在其參數中,並在解碼( Li et al , 2025k)的過程中執行深度查詢-文檔交互。
- 混合檢索:這種策略綜合了多種檢索範式的長處。Agent KB ( Tang et al , 2025d)和MIRIX (王永進、陳曉, 2025)等系統將詞彙和語義檢索相結合,以平衡精確的術語或工具匹配和更廣泛的語義對齊。通過融合異構檢索信號,混合方法在保留關鍵詞匹配精度的同時融入語義方法的上下文理解,最終得到更加全面和相關的結果。
7.3.4 檢索後處理
初始檢索通常返回冗餘的、有噪聲的或語義不一致的片段。直接將這些結果注入提示中,會導致上下文過長、信息衝突、推理被無關內容干擾等問題。因此,檢索後的處理對於確保及時的質量至關重要。它的目標是將檢索到的結果提取到一個簡潔、準確、語義連貫的上下文中。在實際應用中,有兩個組成部分是核心的:
( 1 )重排序和過濾:執行細粒度的相關性估計,以刪除不相關或過時的記憶,並對剩餘的片段進行重新排序,從而減少噪聲和冗餘。
( 2 )聚合與壓縮:將檢索到的內存與原始查詢進行整合,消除重複,合併語義相似的信息,重建緊湊連貫的最終上下文。
八、附錄
大家感興趣可以去看看原論文噢:https://arxiv.org/pdf/2512.13564
這篇綜述的代碼倉庫鏈接:https://github.com/Shichun-Liu/Agent-Memory-Paper-List