

榨乾H100算力!GLM-4.6V×vLLM 極致推理實戰:從9B到106B MoE的全鏈路優化
我是大模型實驗室Lab4AI,一個面向高校科研人員、AI開發者、行業用户及AIGC創作者的高性能GPU場景內容社區,持續分享火熱項目實戰。
最近,我完成了一個GLM-4.6V與vLLM的深度整合項目,成功在H100上實現了從輕量版9B到106B MoE模型的全鏈路推理優化。
今天,就帶大家揭秘如何用vLLM榨乾H100的每一滴算力!
01 項目背景
當“原生多模態”遇上“混合專家”.
智譜AI開源的GLM-4.6V系列代表了當前VLM(Vision-Language Model)的架構巔峯,但也給工程部署帶來了前所未有的挑戰:
-
雙極分化的架構挑戰:
- 9B Flash版:參數小,但在高併發場景下,如何避免Vision Encoder成為瓶頸?如何餵飽H100的巨大算力?
- 106B MoE版:1060億參數/120億激活的MoE架構,對顯存帶寬和通信拓撲提出了嚴苛要求。
-
長上下文與多模態的顯存黑洞:
支持128k上下文意味着KV Cache的顯存佔用呈指數級增長;“圖像即參數”的原生工具調用機制,要求推理引擎必須高效處理異構數據流。
而硬件方面,NVIDIA H100 80GB SXM5是AI算力的天花板,但實際部署中,我們常痛心地發現算力被浪費:顯存牆導致併發數上不去,FP8算力閒置,小模型無法極致併發。
面對這些痛點,我們基於vLLM框架,通過一系列工程手段,實現了從“跑通”到“極致”的跨越。而完成這次項目實戰的破局點就在:
-
FP8 KV Cache(Hopper 專屬):
利用 H100 的 Transformer Engine,將 KV Cache 顯存佔用直接砍半,在單卡上實現 128~150 個併發。
-
併發調優:
將長 Prompt 拆解計算,防止顯存峯值瞬間爆炸(OOM),同時顯著降低首字延遲(TTFT)。
-
異構計算調度:
讓 Vision Tower 在數據並行模式下運行,消除多圖輸入時的流水線空轉。
我們先來看看,如何通過兩個實戰項目,帶你體驗vLLM的極致推理與H100算力壓榨。

02 實戰一 馴服巨獸4×H100 扛起 GLM-4.6V-106B(MoE)
大模型實驗室項目體驗
首先進入項目,在 大模型實驗室Lab4AI 中搜索項目榨乾 H100 算力!GLM-4.6V × vLLM 極致推理實戰:從 9B 到 106B MoE 的全鏈路優化,建議開啓4卡進行體驗。
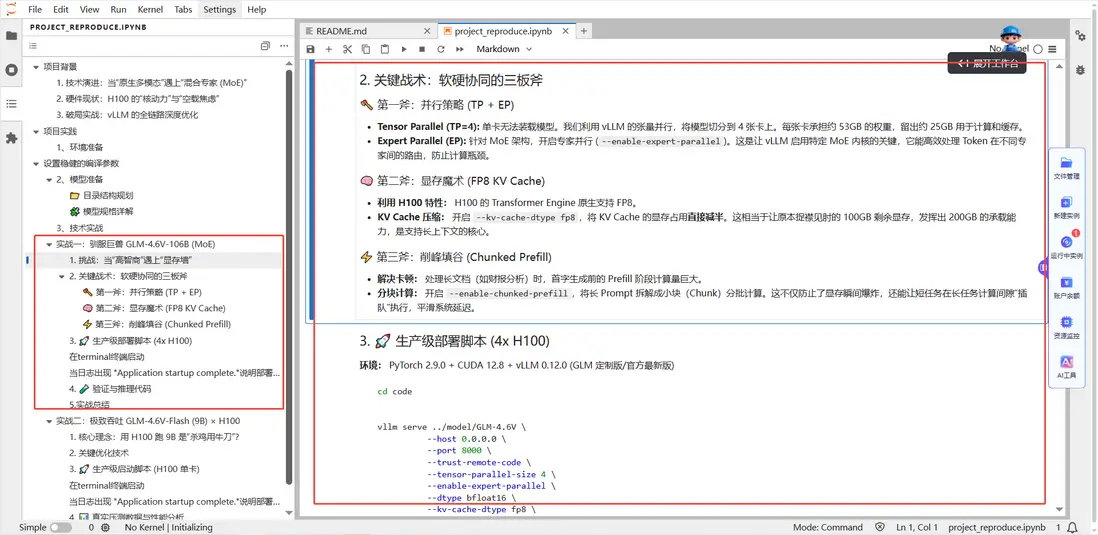
GLM-4.6V-106B 是典型的“高智商、大胃王”:雖然它的激活參數只有 12B(推理快),但靜態權重高達 212GB (FP16),加上 128k 上下文產生的巨大 KV Cache。如何在 H100 上不炸顯存且跑滿算力,是本次實戰的核心。
核心戰術:三位一體優化.
- 並行切分 (TP4 + EP): 利用張量並行 (TP=4) 將模型切分至 4 張卡,並開啓專家並行 (EP) 釋放 MoE 推理性能。
- 顯存魔術 (FP8 KV): H100 的 Transformer Engine 原生支持 FP8,我們利用H100的特性,開啓 --kv-cache-dtype fp8,將KV Cache的顯存佔用減半,讓100GB 剩餘顯存發揮出200GB 的承載力。
- 削峯填谷 (Chunked Prefill): 開啓分塊預填充,防止長文本首字生成時顯存瞬時爆炸 (OOM) 。
配置完成後,在終端進行啓動:

當日志出現 "Application startup complete."説明部署完成
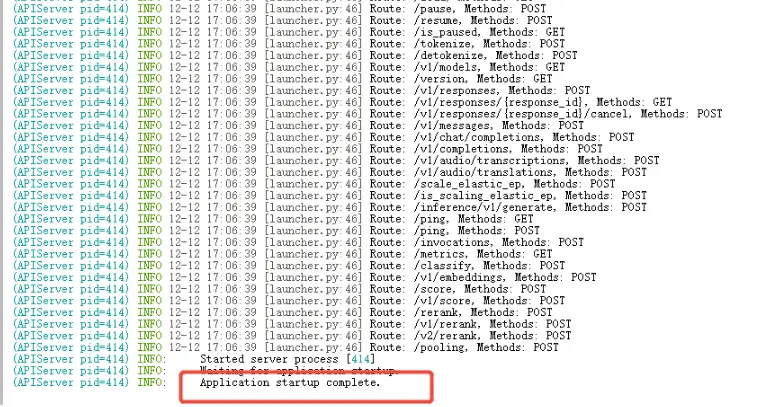
服務啓動後,推薦使用OpenAI SDK 進行調用。該代碼支持本地圖片讀取並在 Jupyter 環境中預覽。直接在ipynb中的代碼塊部分填入url和key即可,運行代碼,可以查看如下:

實戰總結:通過上述配置,我們成功將GLM-4.6V-106B 部署在 4 張 H100 上,利用 FP8 KV Cache 解決了長文本顯存瓶頸,並通過 Expert Parallel 釋放了 MoE 架構的推理性能。這是一個可直接用於生產環境的高性能方案。
03 實戰二
單卡 H100 把 9B Flash 榨到“接近物理上限”.
9B 模型在 H100 上的權重僅佔 20GB,剩餘 60GB 顯存如果閒置就是極大的浪費。普通的部署方式(默認配置)就像開着一輛核動力大巴車,卻只允許坐 20 個人,極其浪費。
我們的目標是通過FP8 KV Cache 和超大併發槽位,把這60GB顯存塞滿,實現單卡9000+ tokens/s 的吞吐奇蹟。
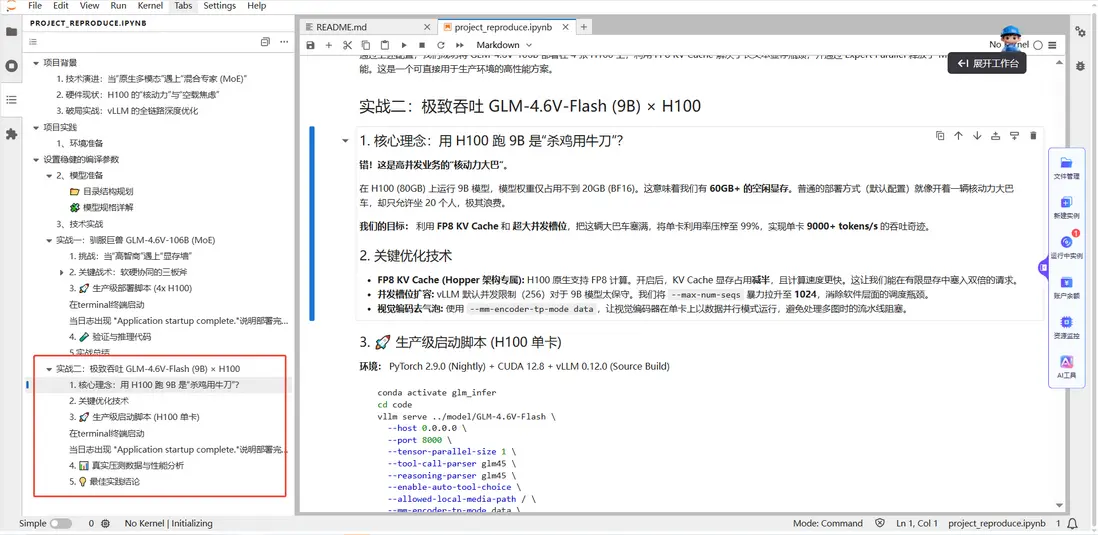
核心戰術:把大巴車塞滿.
- 空間翻倍(FP8 KV): 開啓FP8 KV Cache,顯存佔用直接減半,讓有限空間能塞入雙倍請求 。
- 槽位擴容(Max Seqs): 拒絕默認的256 併發,暴力拉昇至 1024,徹底消除軟件調度瓶頸,餵飽 GPU 核心 。
- 視覺去氣泡(MM Data Parallel): 視覺編碼器開啓數據並行模式,避免多圖處理時的流水線阻塞。
配置完成後,同樣在終端啓動服務器,當日志出現"Application startup complete."説明部署完成。記得關閉之前的服務器。
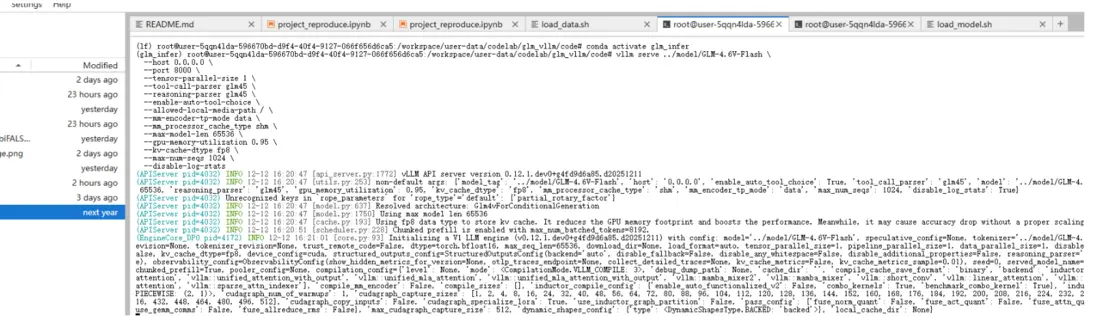
直接在文檔裏面運行代碼,這段代碼的意思是:切到指定conda 環境,然後用 vLLM 自帶的壓測工具,對 GLM-4.6V-Flash(9B)做“隨機數據模式”的高併發吞吐/延遲壓測。
真實壓測與性能分析:
為了排除網絡下載數據集的不穩定性,我們使用vLLM 內置的 random 數據集進行純算力壓測,模擬高負載場景(輸入 1024 tokens / 輸出 512 tokens)。
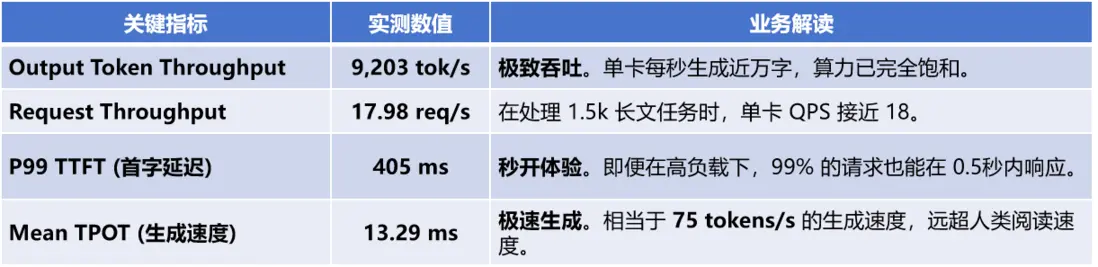
實戰總結:併發數控制在128左右是最佳平衡點。
✅當併發低於64時,延遲極低,但 GPU 沒吃飽,吞吐量浪費。
✅當併發大於256時,吞吐增幅開始變小,但排隊效應爆炸,P99 會從400ms 拉到 7000ms+。
✅當併發等於128時,吞吐拉滿同時延遲可控,9200 tok/s + 405ms 是一個非常適合上線的區間。
這裏,我們給出一些生產建議:
✅網關層(Nginx / API Gateway)建議給單實例加“保險絲”:最大連接數/併發上限設到 ~150,過載時寧可限流,也不要讓 P99 進入秒級排隊區。
✅對GLM-4.6V-Flash,這套參數本身已經非常“接近單卡 H100 的上限區間”,一般不需要再大改;真正影響線上體驗的,更多是輸入輸出長度分佈和限流策略。|
04 總結
不止於“跑通”,更要“極致”.
大模型部署的核心,不是能跑就行,而是把硬件潛力發揮到極致。
這是一套可直接用於生產環境的部署方案:既能承載MoE 權重,也能穩住長文本場景,同時讓 MoE 的推理性能真正跑出來。
這套方案不僅適用於GLM-4.6V,更可遷移到其他 VLM 模型,為高併發多模態服務提供了可直接落地的參考。如果你也在部署大模型時遇到算力浪費、顯存不足等問題,不妨試試這套方案,讓你的H100 真正“物超所值”!
關注“大模型實驗室Lab4AI”,第一時間獲取前沿AI技術解析!