
sjmj 《數據密集型應用系統設計》 - 數據模型和查詢語言
概覽
- 現實世界的API和相關程序作用於某個特定領域解決現實生活的某些問題。
- 存儲數據的模型可以使JSON也可以是XML類型。
- 如何展示以及表示JSON,以及如何操作和處理數據模型使應用開發人員天職工作。
- 越底層的工程師需要考慮的內容越多,需要具備過硬的軟硬件知識。
NOSQL誕生
第一部分講述了NOSQL為什麼會主鍵由關係模型發展而來。以及介紹了歷史長河中曾經被嘗試的一些模型信息。
NOSQL之所以越來越受歡迎,主要是下面幾個特點:
- 相比關係型數據庫更加靈活的存儲形式,支持大的數據集和寫入吞吐量。
- 對於一些特定查詢操作需要NOSQL完成。
- 開源免費的產品更加受到歡迎。
- 關係型數據固有的一些缺點,NOSQL更靈活的表現形式。
對象關係匹配問題
所謂對象和關係的匹配問題指的是在一個看似簡單的現實對象中,如果通過關係型數據庫往往需要較多的表之間形成關聯關係才能完整展示。
而使用NOSQL數據模型,則可以直接通過一個JSON模型,展示一個對象的多種嵌套關係。
雖然ORM框架某些程度上解決了數據庫數據和對象模型的映射問題,但是並不能完全解決靈活性問題,在NOSQL上不存在靈活性限制。
最終一對多的關係模型由於不匹配出現了樹狀結構:
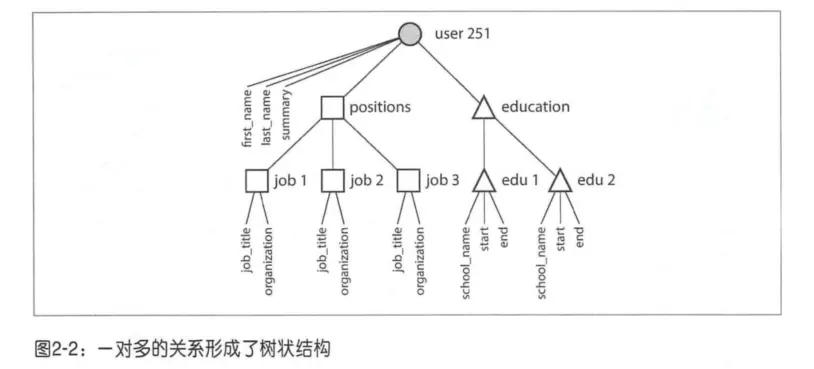
多對一和多對多
多對一需要使用唯一ID進行關聯,使用唯一ID的好處是一旦創建就不需要更改,本身的無意義特點也決定了不會被輕易改變的特點。
如果不使用關聯,則多對一的展示需要的是多次關聯查詢的操作,把一個對象的內容拆分為多個查詢搜索。
所以一個單體對象在最初非常適合使用單一的關係模型,而在後續得擴展之中發現對象的嵌套使用關係型數據庫雖然也能完成,但是帶來是臃腫和業務複雜的加劇。
顯然文檔模型在處理關係的層面上更加靈活。
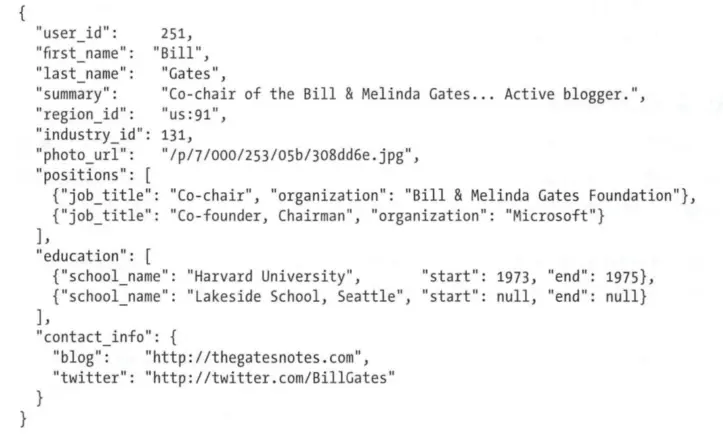
網絡模型
網絡模型是由於 CODASYL 的標準化被提出,最原始的數據庫數據庫可以看做是不同廠商實施的CODASYL模型。
關於網絡模型的歷史,可以看看wiki的相關介紹:
CODASYL - Wikipedia
CODASYL屬於層次模型的推廣,網絡模型的架構之下每個記錄可能多個父節點,通過一個節點服務多個紀錄,實現一對多和多對一的模型。
關係鏈路和關係模型的主鍵以及外鍵不同,使用的是類似鏈表指針串聯的方式連接,多對多的關係模型,需要正確的找到“父節點”,才能再重複的數據中找到匹配結果。
網絡模型僅僅是作為當時歷史背景下解決有限硬件資源搜索慢的問題處理的,最大的缺點和他的特點一樣,就是這個特殊的“父節點”,為了尋找一條關係鏈路,需要準確找到父節點,顯然這種模型是複雜並且難以維護的。
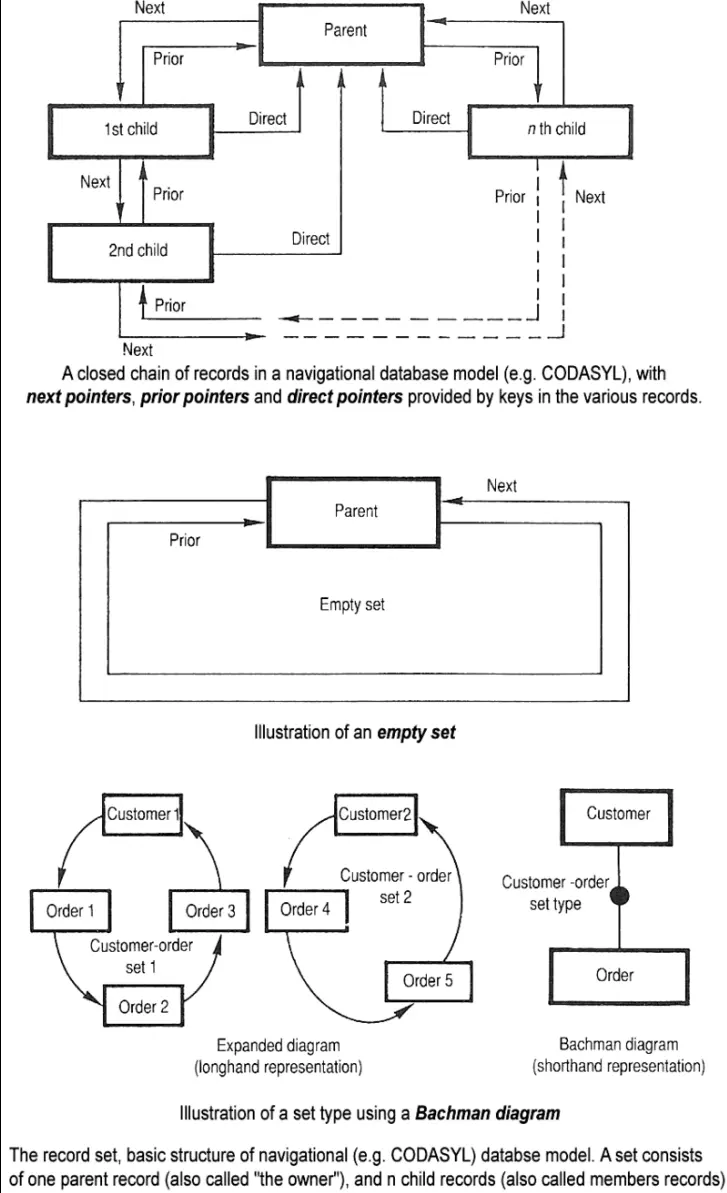
CODASYLwiki解釋:CODASYL - Wikipedia
關係模型
關係模型定義了表和元組(行)的集合,支持任意的條件搜索和表中主外鍵清晰的邏輯結構,迅速取代網絡模型從而得到快速發展。
雖然關係型數據庫的擴展帶來的是越來越複雜的關係模型,但是關係模型的最大特點是隻需要構建一次查詢優化器就可以使得所有的應用程序都可以通用。最終查詢優化器解決了網絡模型鏈路查找的痛點問題。
文檔模型比較
文檔模型為了解決關係模型的複雜化誕生,文檔模型的關係也就是外鍵信息被叫做文檔引用,可以通過直接鏈接查詢和解析嵌套“關係”,所以這種設計並沒有遵循網絡模型單一父節點的特點。
文檔模型和關係模型
現今的數據和網絡結構通常是文檔模型和關係模型的結合,文檔模型可以聚合多個關係表的內容僅限一次展示,但是如果存在多對多的關係,由於文檔模型的自由一定程度上需要應用程序進行限制和防範,在這一層面上關係模型顯然勝任多對多的處理。
針對關係模型的字段擴展通常需要小心謹慎的完成,比如在MYSQL種修改表alter table需要建立
新的BTree樹並且進行拷貝工作,如果表非常大會非常久的停機時間。
一種處理方式是通過建立新表拷貝舊錶的數據導入來完成,可以保證不受影響的情況下完成備份操作。如果需要聚合多個對象的內容,使用文檔模型顯然更加合適,而使用關係模型則需要維護龐大的多表結構。
查詢侷限性
文檔模型的瓶頸出現在本身的數據結構上,尤其是JSON或者XML格式,存儲和更新文檔模型在文檔模型較大的時候磁盤IO的開銷比較大,大文檔模型的查詢效率也會越發效率低下。
關於文檔模型的JSON以及XML優化,將在第一部分的第四章節進行更詳細的講解。
關係模型和文檔模型融合
主流的數據庫在文檔模型的發展之後,逐漸引入了對文檔模型的兼容,比如Postgresql在9.3之後引入了JSON的API以及原生JSON的存儲支持,支持文本以及二進制的存儲。
而在文檔數據庫方面同樣存在反向結合關係數據模型的特點,比如MongoDB可以自動解析數據庫的引用關係轉化為文檔模型。
目前看來最終未來兩者的模型結構是融合而不是一方取代另一方的模式。
數據查詢語言
聲明式查詢
所謂聲明式查詢指的是隻需要數據模型以及制定結果,通過抽象轉化數據以及數據顯示實現這一個目標完成數據模型展示邏輯上的抽象。
換句話説聲明式的查詢只關注整體的規範,不關注具體的實現,但是在SQL中存在諸多限制,所以SQL也存在許多的優化空間,太過自由和不夠自由是聲明式查詢的優點和缺點。
以此為代表的的聲明式查詢有下面幾種結構:
- SQL
- WEB標籤
命令式查詢
命令式查詢的好處是對於業務處理的靈活性十足, 相比於聲明式的抽象和難以排查,命令式的查詢則具備較強的邏輯性和可排查行。
當然命令式查詢最大的問題是隨着邏輯的複雜,命令會越發的難以閲讀,如果不加以重構最終就會造成無法閲讀的代碼。但是不管怎麼説相比較聲明式語言,命令式顯然更容易理解一些。

MapReduce 查詢
MapReduct是一種編程模型,主要作用是在多機器上面晚餐海量數據處理,最初由Google提出。關於這一數據結構的討論在第十章也有更為詳細的討論。
下面是可供參考的原始論文:
[[Mapreduce.pdf]](Obsidian)
[[三大論文中文版.pdf]](Obsidian)
MapReduce 查詢是一種介於聲明式和命令式之間的一種組件,代碼片段可以被處理框架反覆調用。
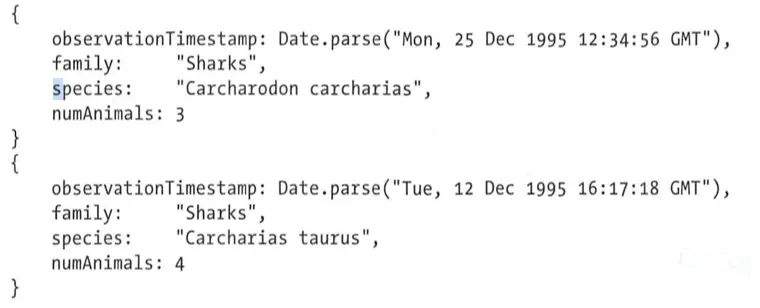
主要的函數分為 map 函數和 reduce 函數。例如,假設 observations 集合包含如下兩個文檔:
將下面的的SQL進行 Map 和 Reduce 函數操作
SELECT date_trunc (’ month ’, observation_timestamp) AS sum(num_animals) AS total_animals
FRO問 observations
WHERE family= 'Sharks ’ GROUP BY observation_month ;對於這個查詢,首先需要編寫相關的 map 和 reduce 函數對於實現上面的相同效果:
db.observations.mapReduce(
function map() { @ var year = this. observation Times tamp . getFull Year(); var month = this .observationTimestamp .getMonth() + 1; emit (year +”-”+ mo『1th, this . numAnimals); €>
},
function reduce(key, values) { e return Array . sum(values); ©
query: { family :” Sharks" } , 0 out :” monthlySharkReport ”@每個文檔都會調用 一次map 函數,從而產生Emit ( '’ 1995 - 12 4 )。隨後, reduce 函數將被調用, reduce ( “ 1995 - 12 ” , 【3 ,4】),最終返回總和 7。
注意 在這個例子中map 以及 reduce 函數需要依賴純JS函數來完成操作,傳遞進去的數據作為輸入操作同時不能完成數據庫查詢的操作。
這些限制保證數據庫查詢可以在任意的位置運行函數,一旦失敗重新運行即可,所以最後發現MapReduce特點是一個相當底層的編程模型,用於在計算集羣上分佈執行。
MapReduce的一個可用性問題是,必須編寫兩個密切協調的JavaScript 函數,這通常比編 寫單個查詢更難,此外MapReduct編寫高級函數執行相關操作這比寫單個查詢要還要難上不少。
如果書中的句子難以理解,我們可以換用IBM官方的介紹,個人認為比較直觀的顯示這兩個函數的意義。
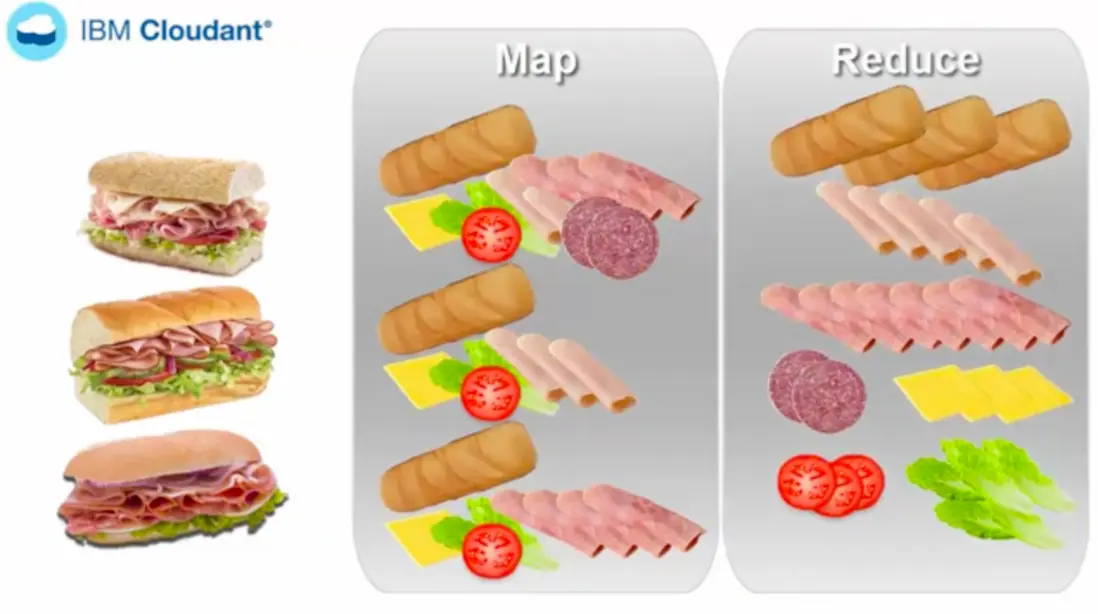
類似下面的情況,如果我們要對漢堡進行分類,抽出裏面的所有內容,首先我們需要用map函數把漢堡分類為一個個部分,然後再通過reduce函數對於相同分類的內容進行合併。
最終結果就像是下面這樣,我們通過漢堡的歸類組合,拼接出多種不一樣的漢堡:
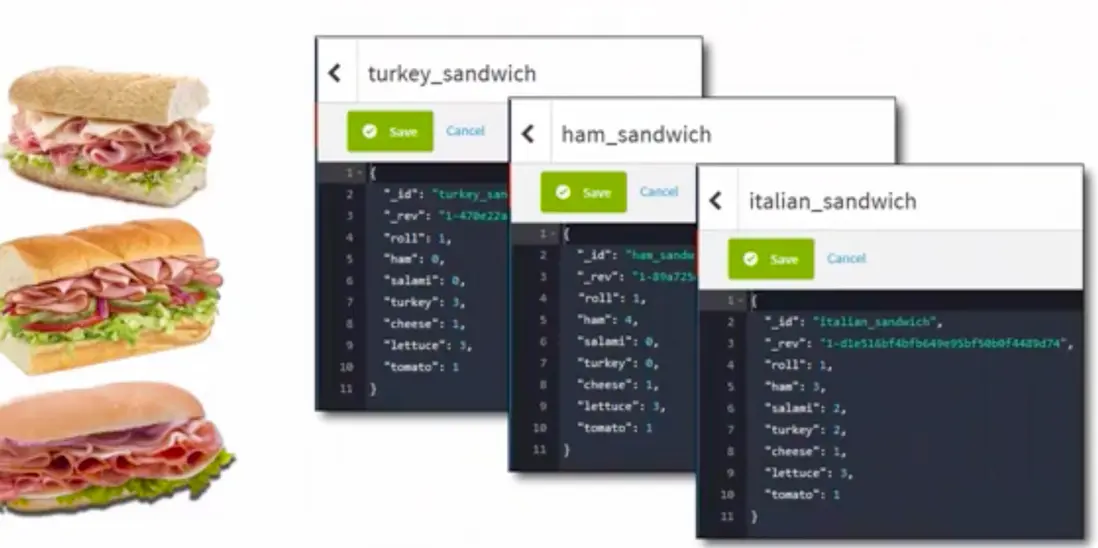
最終通過JSON的方式進行展示

對於不同函數的調用,最終實現不同形式的數據以獲取不同的數據統計信息,這種類似靈活運用SQL函數的結果,運用Reduce的各種變化是非常有意義的。
圖數據模型
圖數據模型相比其他幾個模型來説複雜很多,但是實際使用圖數據庫的廠商通常制定了一套圖數據模型查詢語言幫助開發者降低門檻。
個人始終認為圖模型才是人類思考的最終形式,因為這種模型實際上更像是對於“網絡模型”的變種和拓展,從圖中也可以看到“父節點”本身的界限瞭解的更加清晰。
圖的主要思想是頂點(也叫做節點或者實體)以及 邊(關係和弧)進行建模。
典型的案例可以直接看下面的圖形:
圖模型通常具備下面的特點:
- 強大的靈活性, 頂點和頂點之間的關係不受限制,沒有強制的措施否認事物的關聯。
- 利於演化和擴展,編寫一個關係模型受到數據模型本身的影響比較小,在擴展中複雜化數據結構對於圖模型本身也具備兼容條件。
下面討論的內容涉及了Neo4j為代表的圖數據庫實現,Neo4j也是市面上較為成熟的圖數據庫。
屬性圖
在屬性圖模型中,每個頂點包括:唯一的標識符、 出邊的集合、 人邊的集合、 屬性的集合 (鍵-值對)
每個邊包括 :唯一的標識符、邊開始的頂點(尾部頂點) 邊結束的頂點(頭部頂點) 描述兩個頂點間關係類型的標籤、屬性的集合 (鍵-值對)。
通過關係模型表示,屬性圖類似下面的語句:

屬性圖存在下面的特點:
- 頂點之間的互相連接不存在限制。
- 給定頂點可以快速的找到邊和另一個頂點。
Cypher 查詢語言
Cypher是一種用於屬性圖的聲明式查詢語言, 最早為Neo4j 圖形數據庫而創建,另外Cypher這個單詞出自黑客帝國的一個比較重要的角色,這個單詞的原意叫做“暗號”。
Cypher的語法結構如下,包含一個頂點和一個邊,數據的存儲是使用類似JSON的key/value方式。初看可能覺得奇怪,但是理解概念之後意外的十分好上手。

查詢顯然是根據出生地和居住地這兩條關係線找到位置相關的信息,最終返回用户的名稱,比較符合人的思考習慣。這裏再舉一個更簡單點的例子,比如查找相關的遷出地的人和遷入地的人:

對於上面的查詢寫法並不是唯一的,其實可以直接從Location開始查找歐洲和美國兩個頂點,然後根據關係線找到其他的關係也是一種解法。
Neo4j還是比較意思的東西,書中只是簡單介紹了一下,更多內容可以找一些簡單的項目結合官方問你大概可以快速入門和上手。
當然我不推薦你研究過深,這種東西在國外應用場景也不多見,看起來壯闊的腦圖實際上用起來因人而異,至少OB軟件個人不太喜歡用。
Neo4j相關閲讀參考:
# Neo4瞭解
# 安裝Apoc插件以及JAVA集成
SQL中的圖查詢
如果上面的案例中的關係使用關係型數據庫實現,雖然完成起來可能很複雜但是確實是可以完成,需要大量的關係表配合完成,關係型數據庫另一項難題是這樣的針對“邊”的檢索能力十分羸弱,所以不建議去讓關係型數據庫去幹它不擅長的東西。
SQL在遇到圖數據庫的衝擊之後也開始了關於圖查詢到研究,目前較為成功的案例為PostgreSql的圖查詢(Graph Query)。
小貼士:
注意在SQL:l999標準以後, 查詢過程中這種可變的遍歷路徑可以使用稱為遞歸公用表表達式(即WITH RECURSIVE) 來表示。這裏截取了一部分,但是顯然這個查詢複雜而且顯得臃腫不可理解。

這樣的查詢也更加説明對於不同的場景選擇合適的數據模型非常重要,不要試圖去讓一個不適合的數據模型強行去做另一個模型的專長,不會顯得技術牛逼,只會顯得白費力氣。
三元存儲和SAPRQL
三元存儲的方式幾乎和SPARQL一致。只是不同的名詞采用了相同的思想,三元模型發展出了不同的工具和語言,所以這裏還算要放到“圖”的範疇考慮。
三元的三元分別叫做:主體、謂語、客體。有一丁點兒類似語言中到主謂賓。
在三元模型彙總主體充當圖的頂點,客體分為下面兩種:
- 原始數據類型的值。這種情況可以認為謂語以及客體相當於主體的鍵值對的鍵和值。
- 圖的另一個頂點。相當於主從結構的客體部分類似另一個“頂點”,此時謂語是一條“邊”。
也就是説主體必定是一個抽象的頂點“對象”,而客體可以是另一個“主體”對象,也可以是一個具體的值。
這樣描述依然比較抽象,下面是舉個相關的結構圖例子:

為了簡化書寫減少相同單詞的輸入,可以使用分號對於這樣的寫法進行改良:

吐槽:圖數據的介紹這一段顯然有點翻譯災難,有些個人認為翻譯不是很恰當,建議直接看Neo4j的使用更為直觀。
語義網
語義網本質指的是將發給人類閲讀的文字按照機器本身可以識別的方式解讀?RDF框架實現了這樣的機制,不同網站的數據合併為一個數據網絡,也就是實現數據互聯。
但是因為它在過去被過分的誇大,所以導致與此沾邊的概念會受到牽連,注意RDF是不同的數據模型。
RDF數據模型
Turtle語言參考:
https://www.w3.org/TR/turtle/
國內有博主做了翻譯,很強:
https://www.cnblogs.com/coodr...
一句話Turle語言:Turtle文檔是以緊湊的文本形式來描述一個RDF圖,這種RDF圖是由主語、謂詞、賓語組成的三元組構成的。
通過Turtle語言實現代表了RDF數據的人類可讀格式,目前已經有不少開源組件支持對於這種數據模型格式的轉化,比如使用RDF/XML語法。

這門語言主要的目的是不同網站之間的數據河流,有一個特殊約定是對於三元結構存在主體、謂語、客體三部分通常為URL的設計,採用這樣的設計是防止相同數據的衝突無法區分的問題,這時候通過URI區分是一種比較好的方式,哪怕結果相同也不會影響關係的存在。
從RDF角度看URI不一定是需要解析,也有可能是一個URI佔位符號的存在。
SPARQL查詢語言
定義:採用 RDF數據模型的三元存儲查詢語言。名字是SPARQL Protocol 和RDF Query Language的縮寫 ,發音為“sparkle”。注意這要比Cypher還要早,並且後者借用了前者的模式匹配,所以不少地方比較像。下面是這門語言的相關格式:
形式和Cypher基本類似,但是RDF的區別是不分屬性和邊。
圖數據庫和網絡模型的比較
主要的區別如下:
- 網絡模型需要指定哪一條記錄嵌套在其他的標記當中,圖數據不存在記錄嵌套關係以及記錄限制,可以為需求提供更多的靈活性。
-
圖數據庫可以通過一個頂點索引不同頂點,而網絡模型需要唯一的一個入口找尋關係。
- 圖數據庫頂點和邊不一定是有序的,而網絡模型則在插入新記錄的時候考慮記錄在集合中的位置。
- 網絡模型中所有查詢都是命令式,圖數據庫使用自制語言,可以靈活的組合頂點和邊形成網絡。
Datalog基礎
Datalog要比SPARQL 以及Cypher更為古老,作為查詢語言的鼻祖比較重要。實際案例:
- Datomic系統的查詢語言
- Cascalog 主要是查詢大數據集的Datalog實現。
Datalog 的模型類似SPASQL,其中重要的區別是它並不是使用三元而是二元結構,只是用謂語(主體、客體)的方式表達和處理。
下面為使用Datalog的語法實現上述的查詢功能,注意和SPARQL以及Cypher查詢語言不同的,是因為它需要每次實現一塊功能。

查詢邏輯類似 “樹分叉匹配”的方式處理,通過“包含”關係以及二元結構遞歸整個二三目錄產生所有的匹配結果,最終形成下面的最終結果:
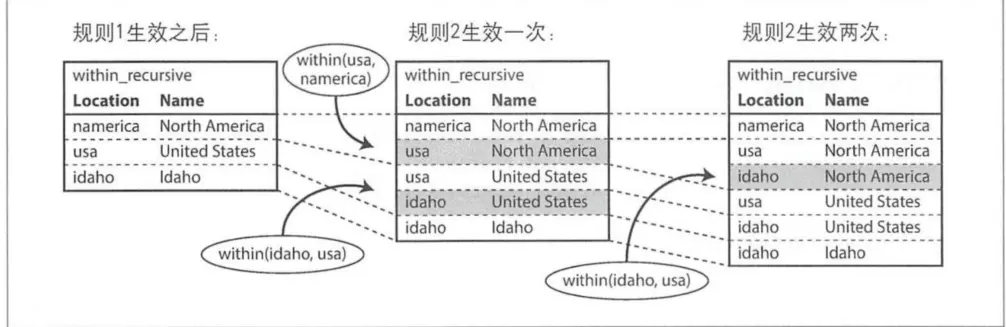
在最後一級也就是第三級當中可以指定who來查找具體的人。Datalog雖然看上去比較繁瑣,但是實際上非常強大,通過規則拆解關係,可以組合一級來重用各種查詢,對於複雜數據的處理十分方便。
總結
數據模型是抽象並且複雜的問題,在本書的第二章重點討論了不同數據模型的優劣,我們可以明顯的看到最初的數據模型實際上是屬於“網狀”的。
最初人們的設想是通過層級結構和單一節點作為入口展示節點,後續則發現這種的單一結構雖然可以解決一對多,但是碰到多對多會十分複雜,這種想法很快被關係模型取代。
關係型數據庫發展之後,開發人員發現對於多關係結構的組合在傳統關係數據庫表述並不合適,所以出現了“NOSQL”,而“NOSQL” 本身又劃分出兩個分歧線路:
- 文檔數據庫設定數據都是文檔,文檔通常是獨立的,和其他文檔之間關係不大。
- 圖數據庫強調節點之間的強關聯,更加貼合最原始的網狀模型,特點是所有數據都能產生聯繫。
文檔數據庫和圖數據庫的共同特點是都不會對於存儲的形式加以限制,可以更快的適應需求,而關係型數據庫則適用於業務邏輯的場景,在目前看來Btree為首的數據結構的關係型數據庫還能活很長時間。
此外還有一些數據模型也比較有意思:
- 基因組數據的研究人員需要智行序列相似的搜索,所以存在關於基因組的數據庫軟件,比如GenBank。
- 粒子物理學家通過大型對撞機(LHC)的項目來實PB級別的數據管理,需要一些定製的解決方案避免硬件成本失控。
- 全文搜索可以説一種警察和數據庫一起使用的數據模型。
寫在最後
個人認為收穫比較大的是從原始到現代瞭解了一些數據庫的不同分支,有的分支還屬於戰未來的階段,而有的分支在逐漸消亡,有的分支個人也從來沒聽過,當然可能一輩子都沒有交集,但是十分感謝作者一一講解,但是從個人看來什麼樣的庫能貼合商業化和產品話,誰更有可能活下來,因為數據庫還是各種存儲媒介,最終只有被用上才有意義和價值。
庫是很複雜的概念,大部分程序員不要妄想去深鑽數據庫,很可能產生整個計算機都要重修失去自信心,瞭解到原理的部分點到為止即可,或者説能用它擰出更好的螺絲都並不是非常容易。