









@[toc]
我們在項目的具體實踐中,有時候會遇到一些比較特殊的字段,例如身份證號碼。
鬆哥之前有一個小夥伴做黑龍江省的政務服務網,裏邊有一些涉及到用户身份證存儲的場景,由於存儲的數據大部分都是當地的,此時如果想給身份證號碼建立索引的話,小夥伴們知道,身份證前六位是地址碼,在這樣的場景下,給身份證字段建立索引的話,前六位的區分度是很低的,甚至前十位的區分度都很低(因為出生年份畢竟有限,一個省份上千萬人口,出生年份重複率是很高的),不僅浪費存儲空間,查詢性能還低。
那麼有沒有辦法解決這個問題呢?我們今天就來聊一聊前綴索引,聊完之後相信大家自己就有答案了。
1.什麼是前綴索引
有時候為了提升索引的性能,我們只對字段的前幾個字符建立索引,這樣做既可以節約空間,還能減少字符串的比較時間,B+Tree 上需要存儲的索引字符串更短,也能在一定程度上降低索引樹的高度,提高查詢效率。
MySQL 中的前綴索引有點類似於 Oracle 中對字段使用 Left 函數來建立函數索引,只不過 MySQL 的這個前綴索引在查詢時是內部自動完成匹配的,並不需要使用 Left 函數。
不過前綴索引有一個缺陷,就是有可能會降低索引的選擇性。
2.什麼是索引選擇性
關於索引的選擇性(Index Selectivity),它是指不重複的索引值(也稱為基數 cardinality)和數據表的記錄總數的比值,取值範圍在 (0,1] 之間。索引的選擇性越高則查詢效率越高,因為選擇性高的索引可以讓 MySQL 在查找時過濾掉更多的行。
那有小夥伴要問了,是不是選擇性越高的索引越好呢?當然不是!索引選擇性最高為 1,如果索引選擇性為 1,就是唯一索引了,搜索的時候就能直接通過搜索條件定位到具體一行記錄!這個時候雖然性能最好,但是也是最費空間的,這不符合我們創建前綴索引的初衷。
我們一開始之所以要創建前綴索引而不是唯一索引,就是希望能夠在索引的性能和空間之間找到一個平衡,我們希望能夠選擇足夠長的前綴以保證較高的選擇性(這樣在查詢的過程中就不需要掃描很多行),但是又希望索引不要太過於佔用存儲空間。
那麼我們該如何選擇一個合適的索引選擇性呢?索引前綴應該足夠長,以便前綴索引的選擇性接近於索引的整個列,即前綴的基數應該接近於完整列的基數。
首先我們可以通過如下 SQL 得到全列選擇性:
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name;然後再通過如下 SQL 得到某一長度前綴的選擇性:
SELECT COUNT(DISTINCT LEFT(column_name, prefix_length)) / COUNT(*) FROM table_name;在上面這條 SQL 執行的時候,我們要注意選擇合適的 prefix_length,直至計算結果約等於全列選擇性的時候,就是最佳結果了。
3.創建前綴索引
3.1 一個小案例
舉個例子,我們來創建一個前綴索引看看。
鬆哥這裏使用的數據樣例是網上找的一個測試腳本,有 300W+ 條數據,做 SQL 測試優化是夠用了,小夥伴們在公眾號後台回覆 mysql-data-samples 獲取腳本下載鏈接。
我們來大致上看下這個表結構:

這個表有一個 user_uuid 字段,我們就在這個字段上做文章。
Git 小夥伴們應該都會用吧?不同於 Svn,Git 上的版本號不是數字而是一個 Hash 字符串,但是我們在具體應用的時候,比如你要做版本回退,此時並不需要輸入完整的的版本號,只需要輸入版本號前幾個字符就行了,因為根據前面這一部分就能確定出版本號了。
那麼這張表裏邊的 user_uuid 字段也是這意思,如果我們想給 user_uuid 字段建立索引,就沒有必要給完整的字符串建立索引,我們只需要給一部分字符串建立索引。
可能有小夥伴還是不太明白,我舉一個例子,比如説我現在想按照 user_uuid 字段來查詢,但是查詢條件我沒有必要寫完整的 user_uuid,我只需要寫前面一部分就可以區分出我想要的記錄了,我們來看如下一條 SQL:

大家看到,user_uuid 我只需要給出一部分就能唯一鎖定一條記錄。
當然,上面這個 SQL 是鬆哥測試過的,給定的 '39352f%' 條件不能再短了,再短就會查出來兩條甚至多條記錄。
通過上面這個例子我們就可以看出來,如果給 user_uuid 字段建立索引,可能並不需要給完整的字符串建立索引,只需要給一部分前綴字符串建立索引。
那麼給前面幾個字符串建立索引呢?這個可不是拍腦門,需要科學計算,我們繼續往下看。
3.2 前綴索引
首先我們通過如下 SQL 來看一下 user_uuid 全列索引選擇性是多少:
SELECT COUNT(DISTINCT user_uuid) / COUNT(*) FROM system_user;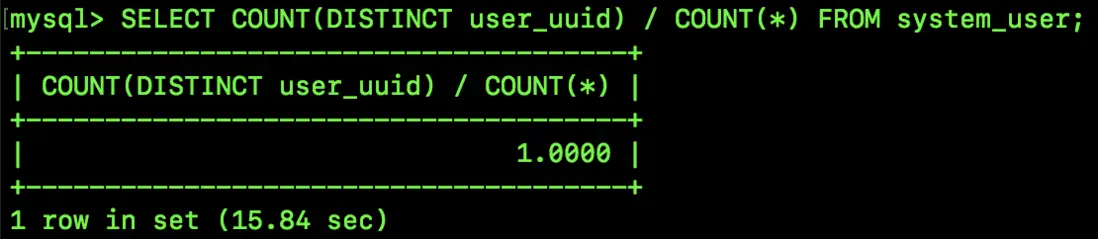
可以看到,結果為 1。全列選擇性為 1 説明這一列的值都是唯一不重複的。
接下來我們先來試幾個不同的 prefix_length,看看選擇性如何。
鬆哥這裏一共測試了 5 個不同的 prefix_length,大家來看看各自的選擇性:
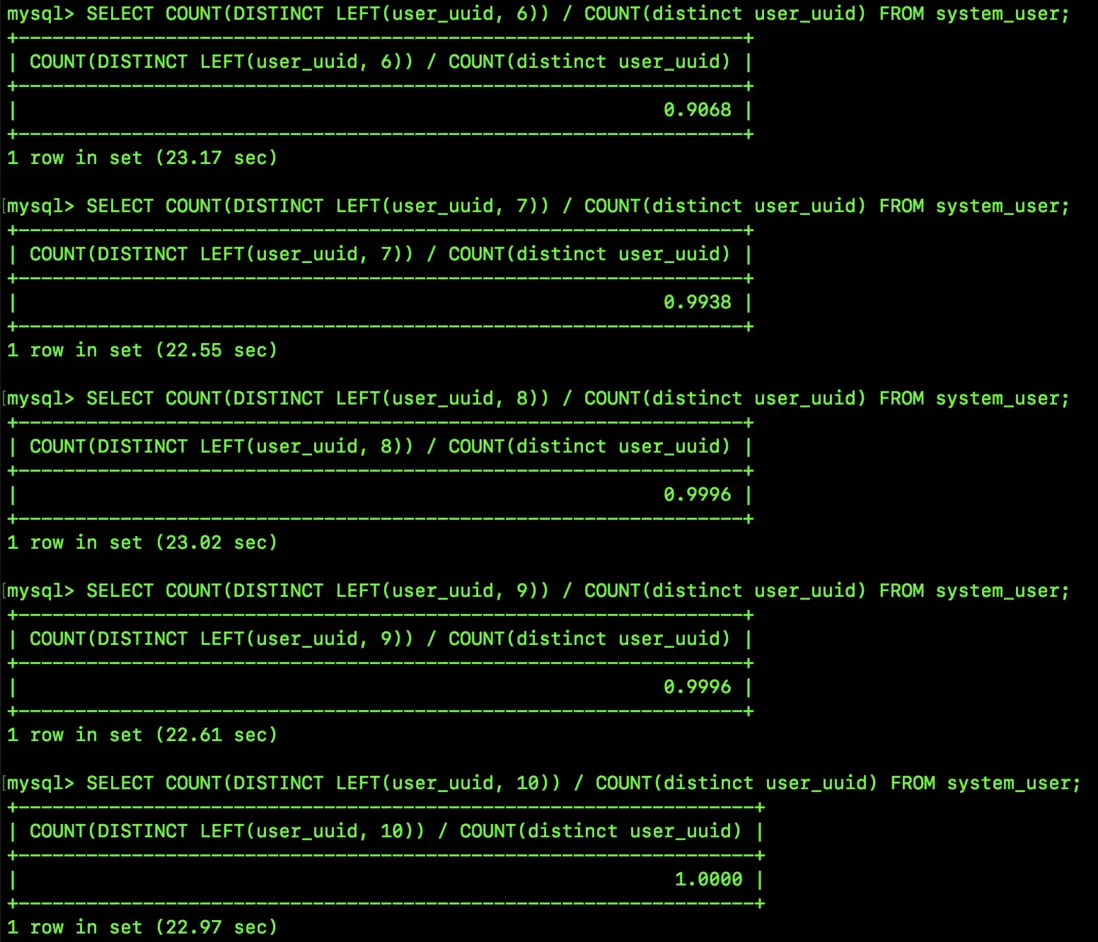
8 和 9 的選擇性是一樣的,因為在 uuid 字符串中,第 9 個字符串是 -,所有的 uuid 第九個字符串都一樣,所以 8 個字符和 9 個字符串的區分度就一樣。
當 prefix_length 為 10 的時候,選擇性就已經是 1 了,意思是,在這 300W+ 條數據中,如果我用 user_uuid 這個字段去查詢的話,只需要輸入前十個字符,就能唯一定位到一條具體的記錄了。
那還等啥,趕緊創建前綴索引唄:
alter table system_user add index user_uuid_index(user_uuid(10));查看剛剛創建的前綴索引:
show index from system_user;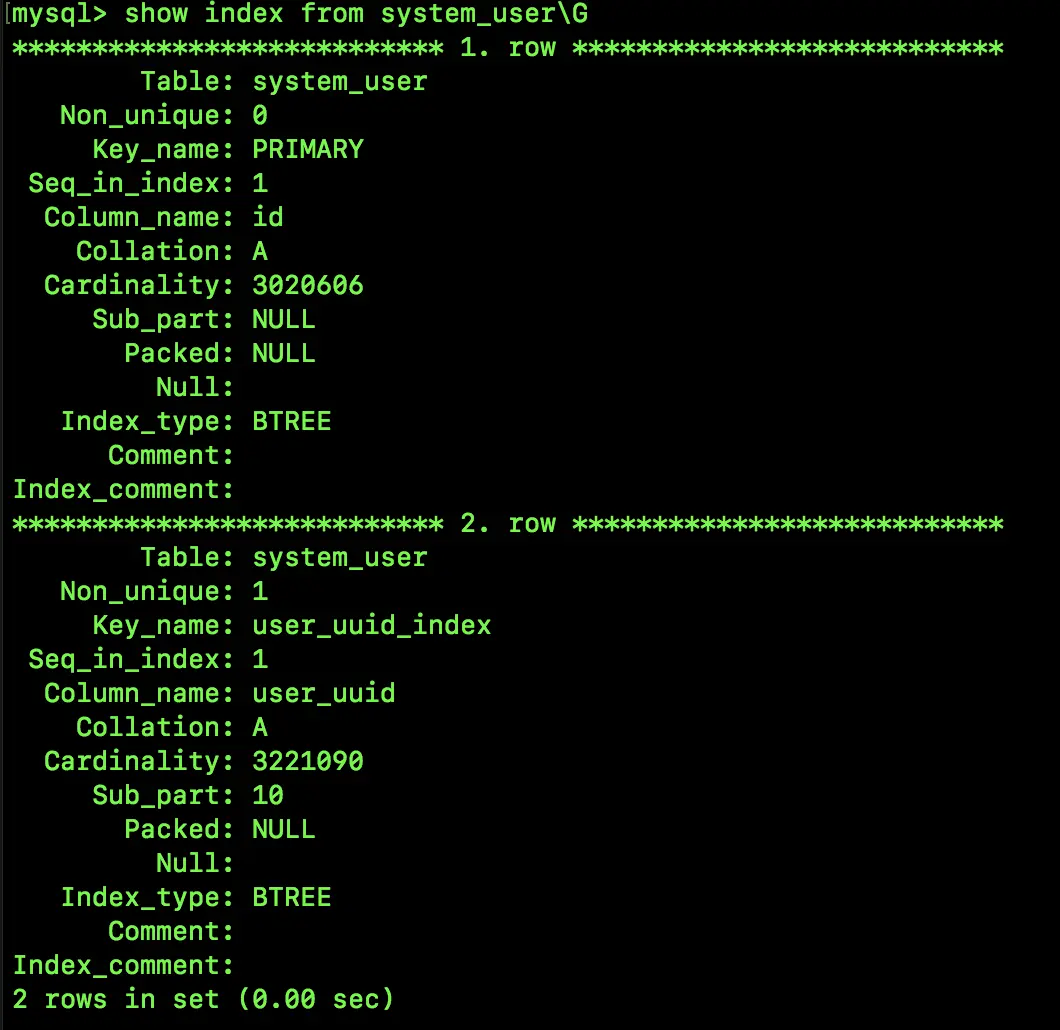
可以看到,第二行就是我們剛剛創建的前綴索引。
接下來我們分析查詢語句中是否用到該索引:
select * from system_user where user_uuid='39352f81-165e-4405-9715-75fcdf7f7068';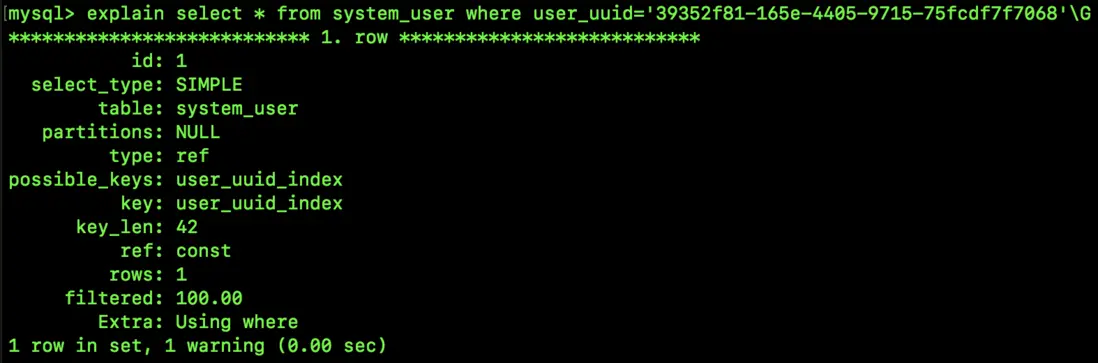
可以看到,這個前綴索引已經用上了。
具體搜索流程是這樣:
- 從
user_uuid_index索引中找到第一個值為39352f81-1的記錄(user_uuid 的前十個字符)。 - 由於 user_uuid 是二級索引,葉子結點保存的是主鍵值,所以此時拿到了主鍵 id 為 1。
- 拿着主鍵 id 去回表,在主鍵索引上找到 id 為 1 的行的完整記錄,返回給 server 層。
-
server 層判斷其 user_uuid 是不是
39352f81-165e-4405-9715-75fcdf7f7068(所以執行計劃的 Extra 為 Using where)。- 如果不是,這行記錄丟棄。
- 如果是,將該記錄加入結果集。
- 索引葉子結點上數據之間是有單向鏈表維繫的,所以接着第一步查找的結果,繼續向後讀取下一條記錄,然後重複 2、3、4 步,直到在 user_uuid_index 上取到的值不為
39352f81-1時,循環結束。
如果我們建立了前綴索引並且前綴索引的選擇性為 1,那麼就不需要第 5 步了,如果前綴索引選擇性小於 1,就需要第五步。
從上面的案例中,小夥伴們看到,我們既節省了空間,又提高了搜索效率。
3.3 一個問題
使用了前綴索引後,我們來看一個問題,大家來看如下一條查詢 SQL:
select user_uuid from system_user where user_uuid='39352f81-165e-4405-9715-75fcdf7f7068';這次不是 select *,而是 select user_uuid,小夥伴們知道,這裏應該是要用到覆蓋索引,我們來看看執行計劃:
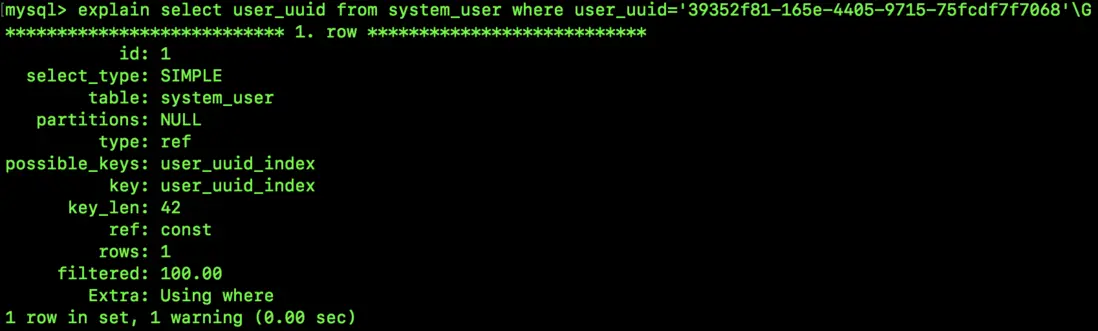
咦,説好的索引覆蓋呢?(注意看 Extra 是 Using where 不是 Using index)。
大家想想,前綴索引中,B+Tree 裏保存的就不是完整的 user_uuid 字段的值,必須要回表才能拿到需要的數據。所以,用了前綴索引,就用不了覆蓋索引了。
4. 回到開始的問題
在本文一開始,鬆哥拋出了一個問題,如何給身份證建立索引更高效?
由於身份證前六位區分度太低,所以我們可以考慮將身份證倒序存儲,倒序存儲之後,為前六位或者前八位(可以自行計算選擇性)建立前綴索引,這樣的建立的索引選擇性就會比較高,同時對空間的佔用也會比較小。在查詢的時候使用 reverse 反轉身份證號碼即可,像下面這樣:
explain select * from user where id_card=reverse('正序的身份證號碼');5.小結
好啦,這就是前綴索引,感興趣的小夥伴趕緊體驗一把吧~












