
核心思路
我們將利用:
• GitLab:作為代碼倉庫、CI/CD 流水線的編排者和觸發器。它負責監控代碼變更、運行自動化測試、構建鏡像並與 Kubeflow 交互。
• Kubeflow:作為運行在 Kubernetes 上的機器學習專用平台。它負責執行復雜的模型訓練(通過 Pipelines)和模型部署(通過 Serving)任務。
整個 MLOps 流程將如下運作:
1. 開發者提交代碼:數據科學家或工程師將模型代碼、訓練腳本等提交到 GitLab 倉庫。
2. GitLab CI/CD 觸發:GitLab 檢測到代碼變更,自動觸發預定義的 CI/CD 流水線(.gitlab-ci.yml)。
3. 流水線執行:
◦ 構建階段:在 GitLab Runner 中,代碼被拉取,依賴被安裝,然後訓練代碼和模型服務代碼被分別打包成 Docker 鏡像。
◦ 推送階段:構建好的 Docker 鏡像被推送到一個容器鏡像倉庫(如 GitLab Container Registry、Docker Hub 或 Harbor)。
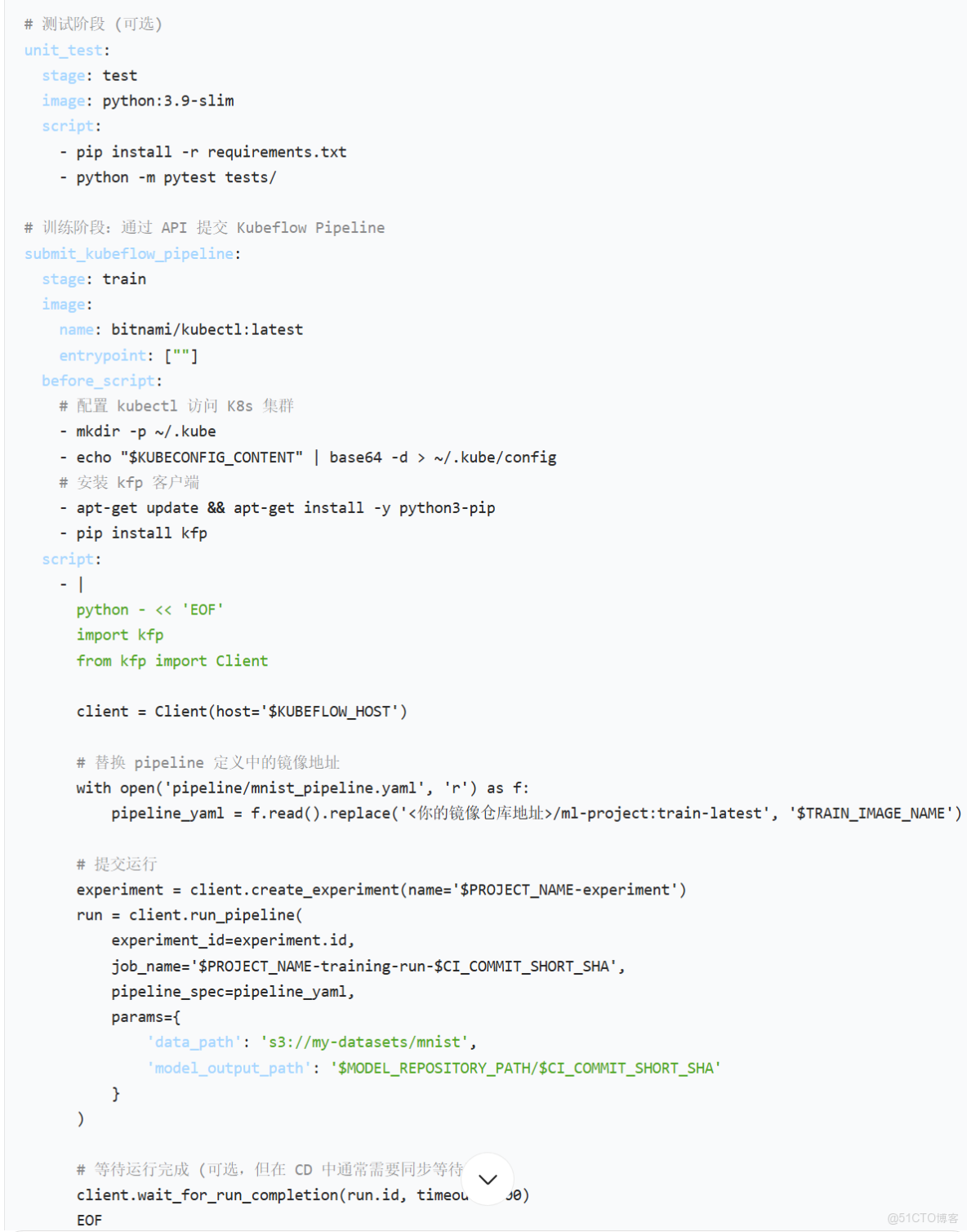
◦ 觸發訓練階段:GitLab CI/CD 調用 Kubeflow Pipelines 的 API,提交一個訓練任務。這個任務會在 Kubernetes 集羣中啓動一個或多個 Pod 來執行訓練。
◦ 模型註冊:訓練完成後,模型工件(Model Artifact)被保存到模型倉庫(如 MinIO、GCS 或 S3),並在 Kubeflow Model Registry 中註冊版本。
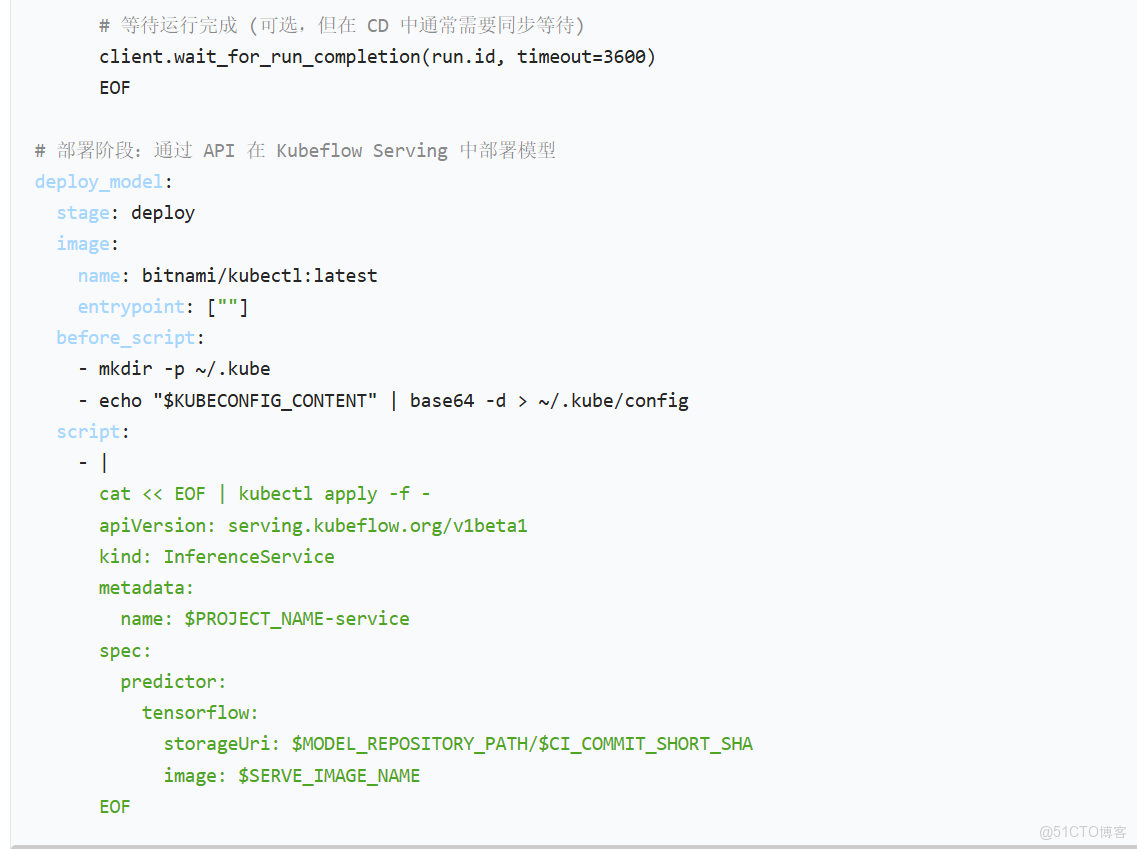
◦ 部署階段:GitLab CI/CD 再次調用 Kubeflow Serving 的 API,使用新訓練好的模型版本來更新或創建一個在線推理服務。
4. 監控與迭代:部署後,通過 Prometheus、Grafana 等工具監控模型性能和服務健康狀況。當需要迭代時,只需重複上述流程。

第一步:環境準備
1. 一個 Kubernetes 集羣:這是 Kubeflow 的運行基礎。你可以使用 EKS (AWS)、GKE (GCP)、AKS (Azure) 或自建的 K8s 集羣。
2. 安裝 Kubeflow:
◦ 參考 Kubeflow 官方文檔 進行安裝。對於初學者,推薦使用 kfctl 工具或更簡化的 distributions 如 Kubeflow on AWS 或 Google Cloud AI Platform Pipelines。
◦ 確保安裝了 Kubeflow Pipelines、Kubeflow Serving (KFServing/KServe) 和 Model Registry 這幾個核心組件。
3. 一個 GitLab 賬號和項目:創建一個新的 GitLab 項目來存放你的 ML 代碼和 CI/CD 配置。
4. 配置 GitLab Runner:
◦ 你需要一個 GitLab Runner 來執行 CI/CD 任務。Runner 可以是一個獨立的 VM,也可以部署在你的 K8s 集羣中(推薦,因為可以共享集羣資源)。
◦ 安裝並註冊 Runner,確保它有足夠的權限(例如,能夠執行 docker 命令來構建鏡像)。
5. 配置訪問憑證:
◦ Kubernetes 訪問:為了讓 GitLab CI/CD 能夠調用 Kubeflow 的 API,你需要在 GitLab 項目的 Settings > CI/CD > Variables 中存儲一個具有相應權限的 Kubernetes kubeconfig 文件(可以 base64 編碼後存儲)。
◦ 鏡像倉庫訪問:存儲一個能訪問容器鏡像倉庫的 DOCKER_AUTH_CONFIG 變量。
◦ 模型倉庫訪問:如果使用 MinIO 等,存儲 AWS_ACCESS_KEY_ID 和 AWS_SECRET_ACCESS_KEY 等變量。

第二步:編寫你的機器學習代碼
在你的 GitLab 項目中,創建典型的目錄結構:
/
├── .gitlab-ci.yml # GitLab CI/CD 配置文件
├── Dockerfile.train # 用於訓練任務的 Dockerfile
├── Dockerfile.serve # 用於模型服務的 Dockerfile
├── pipeline/
│ └── train_pipeline.py # Kubeflow Pipeline 定義
├── src/
│ ├── train.py # 核心訓練邏輯
│ └── model.py # 模型定義和服務代碼
└── requirements.txt # Python 依賴
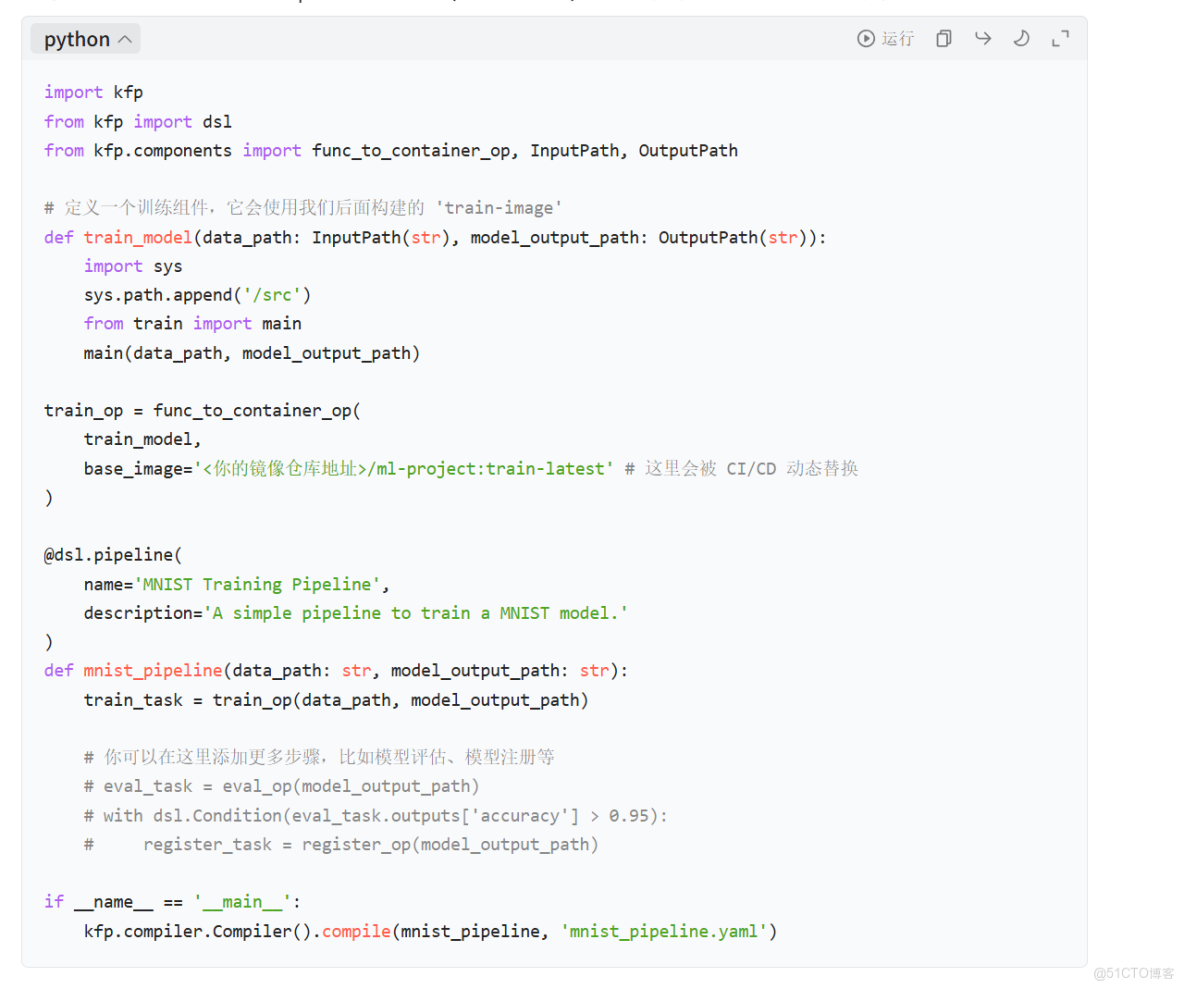
關鍵文件示例:
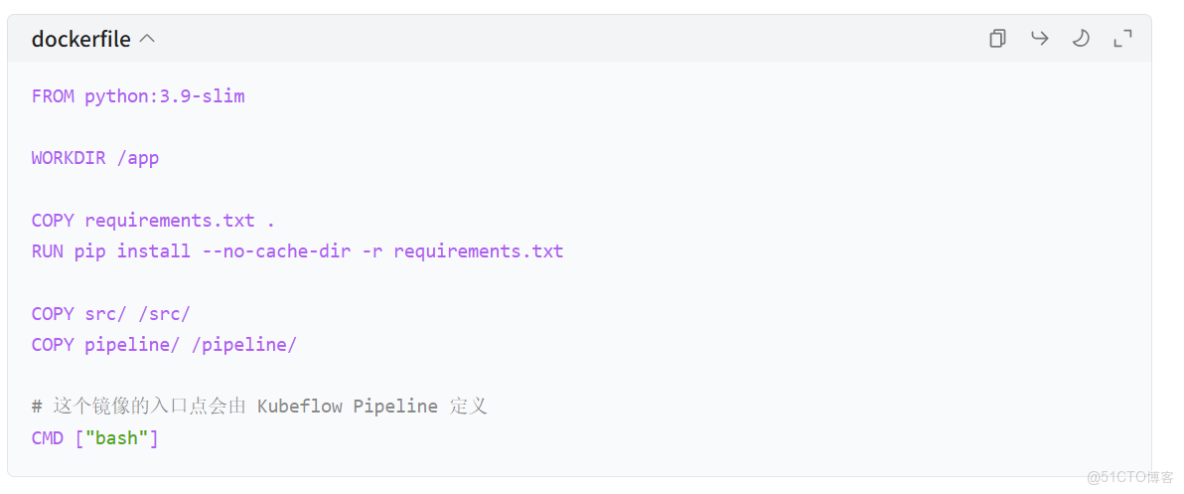
Dockerfile.train:
Dockerfile.serve (使用 KServe 的 ModelServer 作為基礎):
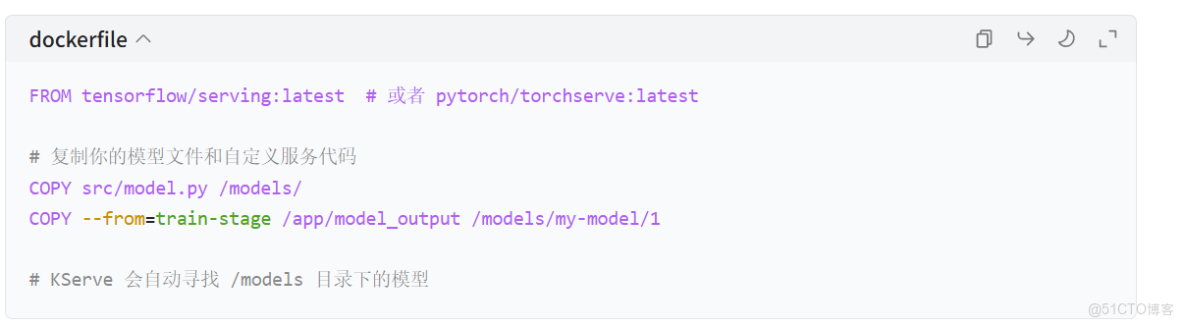
注意:這裏的 --from=train-stage 是一個多階段構建的示例,在實際 CI/CD 中,模型文件通常是從模型倉庫下載的。
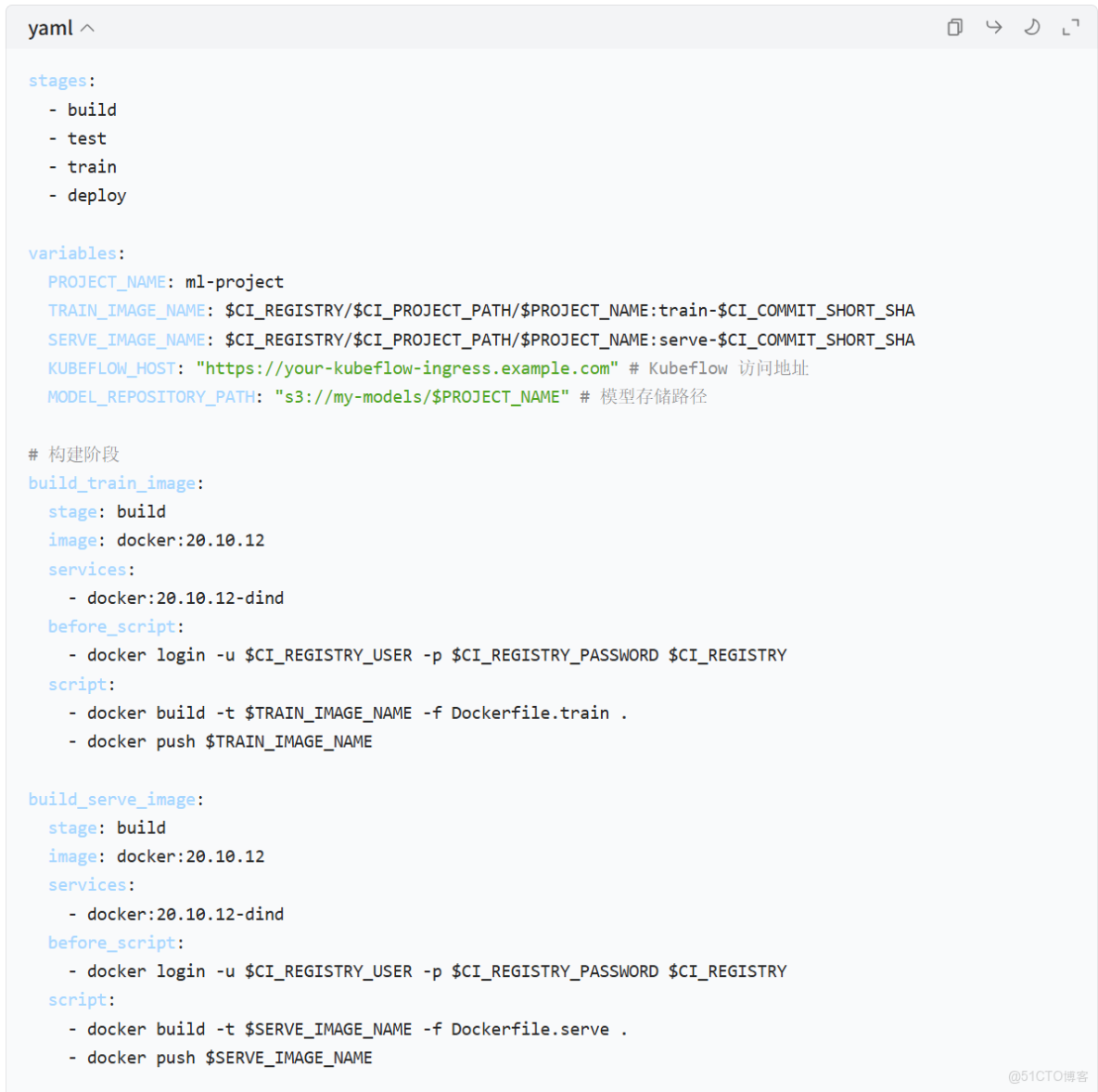
第三步:編寫 .gitlab-ci.yml
這是實現自動化的核心。它定義了流水線的各個階段和任務。
總結與進階
通過以上步驟,你就搭建起了一個基本的 GitLab + Kubeflow MLOps 流水線。
進階方向:
1. 模型版本管理:在 train 階段後,增加一個步驟將模型版本信息註冊到 Kubeflow Model Registry 或 MLflow。
2. 模型評估與驗證:在 Pipeline 中加入模型評估步驟,如果指標不達標,則自動終止後續的部署流程。
3. 藍綠部署 / 金絲雀發佈:在 deploy 階段,利用 K8s 的特性實現更安全的部署策略。
4. 監控集成:將 Prometheus 指標集成到 GitLab CI/CD 中,或在模型部署後自動配置 Grafana 面板。
5. 元數據管理:集成 MLflow 或 Kubeflow Metadata 來追蹤每一次實驗的輸入、參數、指標和輸出。
6. Secret 管理:在生產環境中,避免在 .gitlab-ci.yml 或 GitLab Variables 中明文存儲敏感信息,應使用 K8s Secrets 或外部 Vault 服務。
這套組合非常強大,但也有一定的學習曲線。建議從一個簡單的項目開始,逐步引入更多組件和自動化步驟。