









併發控制機制大揭秘:解析SQL Server與PostgreSQL的併發控制策略
前言
理解SQL Server和PostgreSQL中的併發控制:比較分析 併發控制是數據庫管理系統的基石,確保在多個用户同時訪問或修改數據時,數據的一致性和完整性。SQL Server和PostgreSQL在併發控制的實現上有所不同,這反映了它們各自獨特的架構理念。
本文將探討這兩種數據庫系統使用的併發控制方法,重點介紹SQL Server中的悲觀併發和樂觀併發,以及PostgreSQL中的多版本併發控制(MVCC)。
SQL Server中的併發控制
SQL Server默認使用悲觀併發控制,但它也提供了樂觀併發控制。這兩種方法根據工作負載和衝突的可能性提供了靈活性。
悲觀併發控制
悲觀併發控制依賴於鎖來防止衝突,確保在任何時候只有一個事務可以修改或訪問資源。這種方法假設衝突是可能發生的,並旨在主動避免衝突。當一個事務讀取或修改一行數據時,它會在該行上加鎖(讀取時使用共享鎖,寫入時使用排他鎖),直到鎖被釋放,其他事務才能訪問該行數據。SQL Server在多個級別上使用鎖,例如行鎖、頁鎖或表鎖。這些鎖的作用範圍和持續時間由事務隔離級別決定,例如未提交讀取(Read Uncommitted)、已提交讀取(Read Committed)、可重複讀取(Repeatable Read)和串行化(Serializable)。
這種方法通過防止髒讀、不可重複讀和幻讀等問題,確保了數據的一致性,具體取決於所選擇的事務隔離級別。 然而,使用鎖可能導致阻塞,事務必須等待鎖被釋放,從而降低數據庫吞吐量。此外,還存在死鎖的風險,即兩個或多個事務持有其他事務所需的鎖,導致相互等待,形成僵局。這些因素可能會在高併發環境中由於鎖競爭而降低性能。
樂觀併發控制
與此相反,樂觀併發控制假設衝突是存在的,允許事務在不加鎖資源的情況下繼續進行。這種方法在數據修改時檢測衝突,而不是在修改前就加鎖。SQL Server通過行版本檢查實現這一點,每行數據都有時間戳或版本號來跟蹤變化。在提交之前,系統會檢查自讀取數據以來,數據是否已經被修改。 樂觀併發控制通常基於行版本的事務隔離級別來實現,例如已提交讀取快照隔離(RCSI) 或 快照隔離(SI)。 基於行版本的事務隔離級別減少了鎖競爭和阻塞,因為在事務過程中不會持有鎖。在大量讀取操作的環境中,它的表現良好。然而,衝突僅在事務結束時被檢測到,如果衝突頻繁發生,可能會導致工作浪費。此外,維護版本信息需要額外的數據行存儲開銷和TempDB數據庫中的開銷。
PostgreSQL中的併發控制
PostgreSQL採用多版本併發控制(MVCC)作為其主要的併發控制機制。MVCC是一種樂觀的方法,它避免了鎖的使用,通過數據的多個版本來管理併發訪問。
MVCC的工作原理
在PostgreSQL中,記錄從不被直接修改。相反,當一個事務更新一條記錄時,PostgreSQL會創建該行的新版本,同時保持舊版本不變。每個行版本都會存儲帶有元數據的字段:xmin和xmax,這些字段用於跟蹤與行版本的創建和過期相關的事務ID。
- xmin字段包含創建該行版本的事務ID。這確保其他事務可以根據自己的快照來確定該行版本是否可見。
- xmax字段包含將該行版本標記為過時的事務ID,例如在更新或刪除操作中。
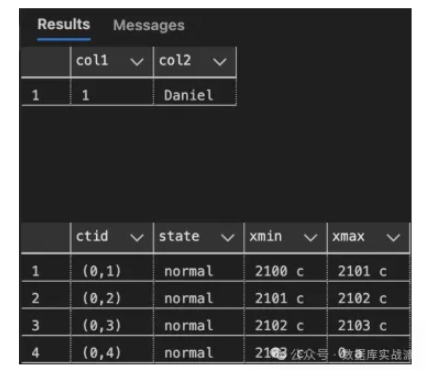
這種版本控制機制確保每個事務都能擁有數據庫的一致性視圖,因為它可以根據事務的快照來確定哪些行版本是可見的。 下圖展示了一個包含單個邏輯行的表,每個物理行版本由同一邏輯行記錄的連續UPDATE語句所創建。
索引條目和行版本
當表中存在索引時,每個行版本都會有一個相應的索引條目。這意味着,如果一行數據被多次更新,表中將存在多個行版本,每個版本都會有自己的索引條目。這確保了使用索引的查詢能夠根據事務的快照找到適當的行版本。 儘管這種方法提高了讀取一致性,但它也引入了額外的存儲開銷,因為行版本及其相關的索引條目都佔用了存儲空間。PostgreSQL依賴其自動清理(Auto Vacuum)進程來清理那些已過時的、不再對任何活動事務可見的行版本及其索引條目。
MVCC的優點
MVCC的一個重要優勢是其非阻塞行為。讀取操作從不阻塞寫入操作,寫入操作也從不阻塞讀取操作,這增強了併發性和性能。 這使得MVCC在高讀取併發的系統中尤其有效。此外,MVCC通過允許事務獨立操作,並且只對重疊的數據修改進行衝突解決,提供了精細的衝突解決機制。
MVCC的缺點
維護多個行版本會增加存儲需求,尤其是在寫入密集型工作負載的情況下。PostgreSQL的自動清理(Auto Vacuum)進程會移除過時的行版本,增加了操作的開銷,如果沒有正確調優,可能會影響性能。另一個挑戰是,寫衝突只在提交時被檢測到,這可能導致在頻繁更新相同數據的場景中出現競爭問題。例如“更新丟失”的問題。
SQL Server和PostgreSQL的關鍵差異
SQL Server和PostgreSQL在併發控制方面採取了截然不同的方法。SQL Server的樂觀併發提供了一個折衷,避免了鎖,從而減少了競爭。PostgreSQL依賴於MVCC,它提供非阻塞的讀取,特別適合高讀取併發的環境,但由於行版本控制和索引維護,存儲開銷會更大。
在性能方面,SQL Server在讀取密集型工作負載中如果不把默認的悲觀併發修改為樂觀併發可能會遭遇鎖競爭問題,而PostgreSQL的MVCC在這種場景中表現優越,因為它確保讀取操作永遠不會阻塞寫入操作。然而,PostgreSQL的方法需要更多的資源來管理數據的多個版本,並且由於清理過程的開銷,在寫密集型工作負載中可能會帶來挑戰。
總結
併發控制是數據庫性能和一致性的重要方面。SQL Server和PostgreSQL採取了不同的策略,這些策略與它們的架構理念相一致。SQL Server同時提供了悲觀併發和樂觀併發方法為不同的工作負載提供了靈活性,而PostgreSQL的默認MVCC機制則確保了併發操作的無縫高效處理。理解這些機制及其權衡,可以幫助你選擇合適的數據庫系統,並根據具體需求進行最佳配置。

本文版權歸作者所有,未經作者同意不得轉載。
