

Java集合框架位於java.util包下,主要包含List、Set、Map、Iterator和Arrays、Collections集合工具類,涉及的數據結構有數組、鏈表、隊列、鍵值映射等,Collection是一個抽象接口,對應List、Set兩類子接口,Map是key-value形式的鍵值映射接口,Iterator是集合遍歷的迭代器,下面是整體框架圖
集合框架整體框架圖
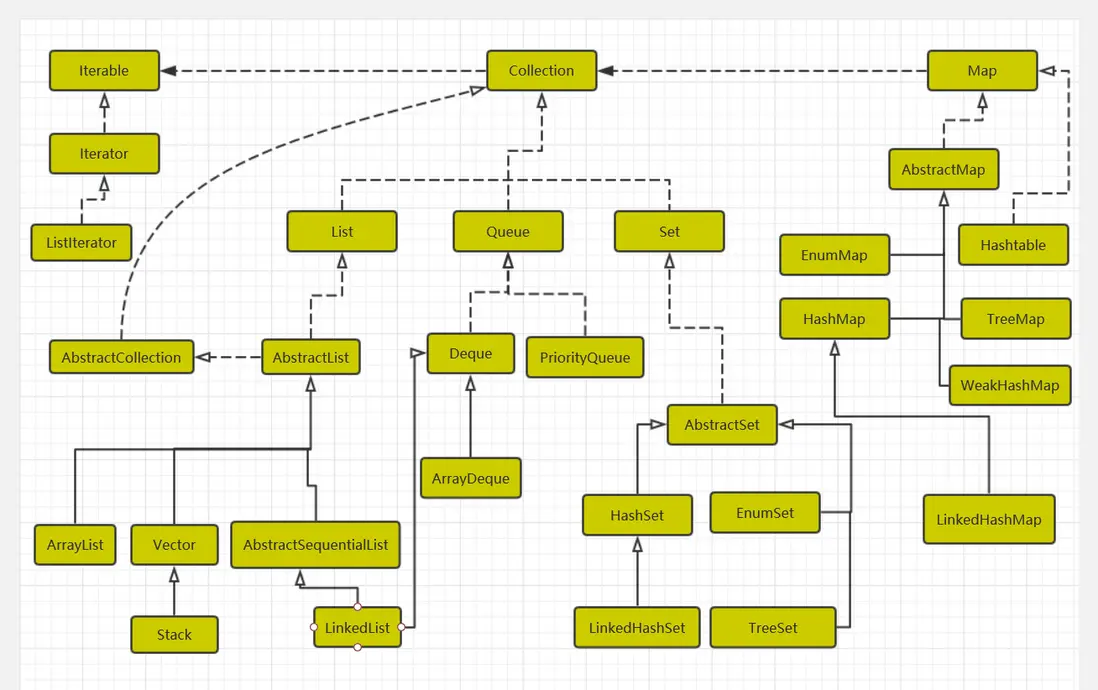
在util包下還涉及SortedMap、SortedSet接口,分別對應Map、Set接口,在concurrent包下有常見的
ArrayBlockingQueue、ConcurrentHashMap、CopyOnWriteArrayList等實現類對Queue、Map、List接口的擴展實現,下面分別從List\Queue\Set\Map接口常用實現類一探究竟
ArrayList實現
我們先來看看初始化方式,
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}從源碼中定義的兩個Object數組可知ArrayList採用數組作為基本存儲方式,在String字節碼中也有定義數組,不過是private final char[] value,transient關鍵字主要是序列化時忽略當前定義的變量;在ArrayList無參函數中給定默認數組長度為10,在實際開發中,一般如果能預知數組長度則會調用帶有長度閾值的構造函數,
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);
}
}源碼方法中會直接按照指定長度創建Object數組並賦值給this.elementData,接下來繼續看看沒有指定數組長度時,數組是如何擴容從而滿足可變長度?此時ArrayList中的add方法登場
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}size為ArrayList中定義的int類型變量,默認為0,當調用ensureCapacityInternal(1),繼續往下看
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}該方法會判斷底層數組elementData與臨時數組DEFAULTCAPACITY_EMPTY_ELEMENTDATA是否相等,如果是就取兩個閾值中的最大值,minCapacity為1,DEFAULT_CAPACITY為10(默認值),然後繼續走ensureExplicitCapacity(10),
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}modCount用於記錄操作次數,如果minCapacity大於底層數組長度,開始調用擴容方法grow
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}oldCapacity為默認底層數組長度,newCapacity = oldCapacity + (oldCapacity >> 1)等價於
newCapacity = oldCapacity + (oldCapacity / 2);在Java位運算中,oldCapacity << 1 相當於oldCapacity乘以2;oldCapacity >> 1 相當於oldCapacity除以2 , 此時新的長度為原始長度的1.5倍,如果擴容後的長度小於minCapacity,則直接賦值為minCapacity,再往下的if判斷中是對int最大值的邊界判定,可以看到最後通過Arrays.copyOf進行數組的copy操作,這是Arrays工具類中的方法,該方法最終調用如下
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));
return copy;
}通過System.arraycopy進行數組複製並return this,System.arraycopy方法為native方法,對應方法如下
//原始數組 //位置 //目標數組 //位置
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos,
int length);//copy長度調用一連串方法最終也只是copy一個默認長度為10的空數組,我們繼續看add方法中的
elementData[size++] = e;//把當前對象放置在elementData[0]上,在ArrayList中size()方法是直接返回定義的size值,即為返回數組元素長度,而非底層數組長度(默認10),所以ArrayList在初始時就佔用一定空間,下面我們看下ArrayList中的查詢方法
public E get(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
return (E) elementData[index];
}如果要查找List中某個對象,假如已知對象在數組中的位置,則直接return (E) elementData[index]返回,在計算算法效率中以O表示時間,此時可以以O(1)表示查詢到指定對象的時間複雜度,因為通過下標查找我們只需要執行一次,如果我們無法得知具體下標,通常是for循環查找位置直到返回對象,假設數組長度為n,此時的時間複雜度為O(n),這種方式實則取的是查找到該對象所消耗的時間的最大值,有可能在for循環中第一個或是中間一個位置就已經查找到了,則可記為O(1)或者O(n/2)
LinkedList實現
LinkedList基於雙向鏈表+內部類Node<>泛型集合實現,初始化沒有默認空間大小,根據頭尾節點查找元素,下面先看下雙向鏈表的數據結構圖
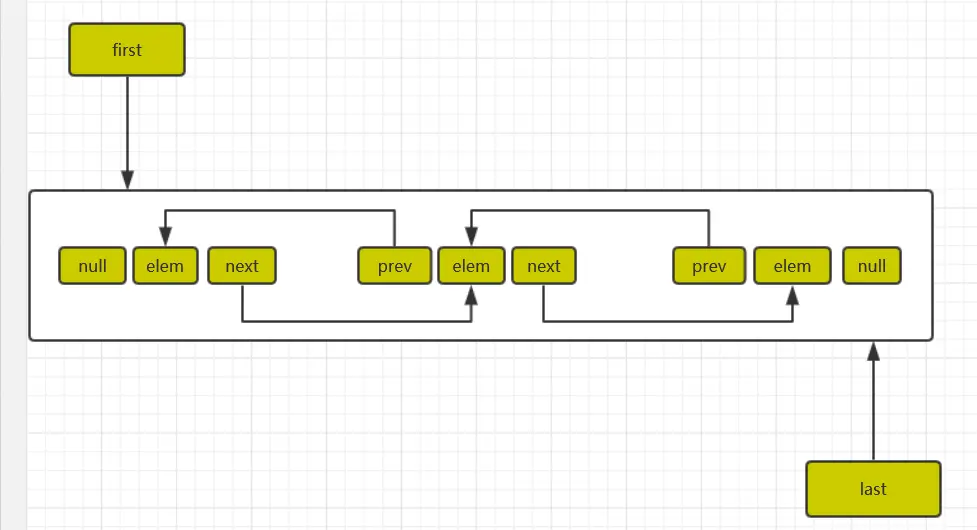
鏈表中elem為當前元素,prev為當前元素的上一個節點,next為下一個節點,LinkedList初始化時鏈表是空的,所以firs頭節點、last尾節點都是null,下面看下初始化源碼,
transient int size = 0; //transient標記序列化時忽略
transient Node<E> first; //頭節點
transient Node<E> last; //尾節點
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}有參函數對應加入整個集合,下面先看下內部類Node的定義,
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}E表示泛型元素類型,prev記錄當前元素的上一個節點,next記錄下一個節點,當我們往LinkedList中add一個元素時,看下源碼是怎麼處理Node節點,
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}在進行添加操作時默認是追加至last節點,linkLast方法中首先將當前數組中last節點賦值臨時變量,然後調用Node<>構造函數將當前添加元素與last關聯,此時l賦值給Node<>中的perv節點,接着判斷l是否為null,如果是表示數組中沒有元素,就直接賦值給first作為第一個,否則就追加至原數組最後一個元素的next節點,從而完成add操作,下面我們看下指定插入位置add方法,
public void add(int index, E element) {
checkPositionIndex(index); //校驗index邊界>=0 && <=size
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}linkBefore方法中首先會調用node(int index)節點生成方法,該方法中首先通過二分法的方式判定元素插入位置,然後分別對first、last節點中的next、prev節點進行賦值操作,最後返回插入的節點元素,傳遞給linkBefore方法,該方法會判斷傳入的節點元素的上一個節點是否為null,對節點進行相應賦值操作,從而完成指定下標插入元素,下面繼續看下LinkedList刪除元素方法remove(int index),
public E remove(int index) {
checkElementIndex(index); //index邊界判定>=0 && <size
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}刪除元素方法基本都會調用unlink(Node<E> x),原理就是把x元素的前後節點指向關係進行替換,然後將當前x元素所有屬性置空,達到刪除元素目的同時等待GC回收,順帶看下LinkedList查詢方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}核心是通過類似二分法定位下標對應的元素並返回該對象的element值,可以看到LinkedList在增刪元素時,只是修改當前下標所在元素的前後節點指向關係,相對於ArrayList的copy數組效率要高,而查詢元素時雖採用二分法提高查詢效率,但其時間複雜度還是O(logN),二分法找一次就排除一半的可能,log是以2作為底數,相對於ArrayList直接索引查詢要慢得多
Queue、Deque的實現
PriorityQueue是基於優先堆的一個無界隊列,該優先隊列中的元素默認以自然排序方式或者通過傳入可比較的Comparator比較器進行排序,下面看下PriorityQueue的add方法源碼
private static final int DEFAULT_INITIAL_CAPACITY = 11; //隊列默認大小
transient Object[] queue; //隊列底層數組存儲結構
int size;
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}在offer方法中如果插入的元素為null則會直接拋出異常,當隊列長度大於等於容量值時開始自動擴容,grow方法與ArrayList的擴容方法類似,最後都調用了Arrays.copyOf方法,唯一區別在於擴容長度不一樣,可自行查看此處源碼,offer方法中i=0時標記為隊列第一個元素,直接賦值queue[0],如果不是第一個,則開始調用siftUp()上浮方法,
private void siftUp(int k, E x) { // k != 0
if (comparator != null)
siftUpUsingComparator(k, x); //指定排序比較器
else
siftUpComparable(k, x); //使用默認自然順序比較器
}
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable,<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}在siftUpComparable方法中,將傳入的可比較的對象轉換為Comparable,如果k下標大於0,計算父節點的下標int parent = (k - 1) >>> 1 等價於int parent = (k - 1)/2;然後取出父一級的節點對象,通過compareTo方法對插入的對象於當前對象比較是否>=0,如果不大於則把當前對象賦值給k位置,再把parent位置賦值給k做替換,最後通過queue[k] = key實現元素上浮排序,繼續看下remove方法
public boolean remove(Object o) {
int i = indexOf(o); //遍歷數組找到第一個滿足o.equals(queue[i])元素的下標
if (i == -1)
return false;
else {
removeAt(i);
return true;
}
}
E removeAt(int i) {
// assert i >= 0 && i < size;
modCount++;
int s = --size;
if (s == i) // removed last element
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved); //調整順序
if (queue[i] == moved) {
siftUp(i, moved);
if (queue[i] != moved)
return moved;
}
}
return null;
}刪除元素時下標是從後往前,當i = s是最後一個元素下標時直接置空,否則從隊列數組中取出要刪除的元素,調用一次siftDown下沉方法對最小堆節點位置進行調整,以不指定比較器的方法源碼分析
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size && //對比左右節點大小
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c; //將子節點c上移
k = child;
}
queue[k] = key; //key向下移動到k位置
}根據int half = size/2 找到非葉子節點的最後一個節點下標並與當前k的位置作比較,從k的位置開始,將x逐層向下與當前節點的左右節點中較小的那個交換,直到x小於或等於左右節點中的任何一個為止,從而達到刪除非最後一個元素的節點排序,相應的時間複雜度也是O(logN),通過此處的方法也可以得知在數組下標從0開始情況下,節點下標計算方式為
left = k 2 + 1 ,right = k 2 + 2, parent = (k -1) / 2, 當然PriorityQueue還有一些其它Queue接口的實現方法,如poll、peek方法,包括在concurrent包下的PriorityBlockingQueue,DelayQueue,ConcurrentLinkedDeque等實現Queue、Deque接口的擴展類,可自行去看下jdk 1.8源碼實現,加深二叉隊列排序原理的理解
HashSet、HashMap、ConcurrentHashMap的實現
HashSet底層是基於HashMap實現,限於本文篇幅過長,剩餘源碼分析參見下篇
《Java深入研究HashMap實現原理》



