

作者:曠視 MegEngine 架構師 張孝斌
快速瞭解 mperf
在移動/嵌入式平台,為了最大程度發揮硬件算力,對算子極致性能的追求變成必然,不同於桌面/服務器平台,移動/嵌入式平台在算子性能調優方面可選擇的工具很少。
MegEngine 團隊一直在探索什麼樣的工具能夠在算子調優流程中帶來助益,來幫助達成如下的算子性能調優反饋迴路,這也是 mperf 誕生的背景。
<p align=center><img src="https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/db65dd714a724afd943a3860cc041974~tplv-k3u1fbpfcp-zoom-1.image" alt="圖1 算子性能調優反饋迴路" /></p>
<p align=center>圖1 算子性能調優反饋迴路</p>
mperf 是一個微架構層次的算子性能調優工具箱,主要面向移動/嵌入式平台的 CPU/GPU 核心,目標是“為構建一個更接近閉環的算子調優反饋迴路”提供系列基礎工具。
核心功能:
- [基礎能力] 測試微架構層次的各類常用性能分析參數(GFLOPS/Multi-level Bandwidth/Latency...)
- [基礎能力] 提供 PMU(Performance Monitoring Unit) 數據獲取能力
- [性能分析] 繪製 Hierarchical Roofline
- [問題定位] 加工 PMU 數據得到各種指標(如 IPC, Instructions per cycle)、TMA(Top-Down Microarchitecture Analysis Method)分析能力,可以作為部分 vendor 提供的 GUI 分析工具的平替
- [優化指引] 提供 OpenCL Linter 方案(後續版本提供)
- ...
作為一個 C++ API 級別的工程,mperf 外部依賴少,可以簡單方便(侵入式)集成到目標工程中,目前已經開源到 GitHub,歡迎大家試用交流。
使用方法參考 README 文檔;快速上手指南見 Tutorial 文檔
對 mperf 的實現原理感興趣的同學,可以繼續往下看~~
展開説説 mperf 的工程實現
緣起
算子調優目前還是一個難以閉環的工作,需要開發者對目標硬件架構特性、算子優化水平評估、性能瓶頸定位、豐富的優化技巧等都有很深的瞭解之後才能變得遊刃有餘。同時隨着 CPU/GPU 架構越來越多,越來越複雜,普通的開發者很少有精力去深入理解各個架構的特性,問題變得更加棘手。
理想中的調優過程是能夠形成如上圖所示的閉環,甚至可以走向編譯器全自動化調優方案,過程中往往需要依賴工具完成,在桌面/服務器平台的工具較為完備,如 linux perf, lmbench/stream,NVIDIA NSight Compute,Intel vtune/Advisor/pmu-tools 等開閉源工具等都提供了一部分能力,通過人為組合還是能得到比較全的能力;與此同時,在移動/嵌入式平台,也有 simpleperf、Arm mali streamline、snapdragon profiler、MegPeak、ArchProbe、HWCPipe 等優秀的開閉源工具,但是完備性和易用性方面都存在很多問題:
- GUI 工具不支持函數級/代碼片段分析(如基於 PMU 的指標分析等,詳見下方“PMU 數據蒐集、加工和分析”),還不容易擴展新的分析指標
- 不支持 ARM CPU 的 TMA 分析(詳見下方“PMU 數據蒐集、加工和分析”)
- 繪製 Roofline 等所依賴的基礎數據的獲取能力散落在多個工具中,普通同學很難入手
- 很少的優化指導能力
因此我們啓動了 mperf 項目,希望提供系列工具來完整獲得這些基礎能力:
- 常見 CPU/GPU 微架構參數,目前已經支持 ARM CPU/Mali GPU/ Adreno GPU 的部分型號
- 通過 Hierarchical Roofline 模型評估算子優化水平
- 通過豐富的指標和 TMA 分析模型來定位性能瓶頸/提示性能問題
- 通過 OpenCL Linter 等工具能固化專家優化經驗,掃描用户代碼後給出性能優化建議
- ...
常見 CPU/GPU 微架構參數
為 Roofline 繪製/Metrics (指標)計算等模塊提供架構相關的基礎參數,如多級存儲 bandwidth/latency,指令 throughput/latency,各種基礎 micro-kernel的bandwidth,GPU 特有的參數(warp size 等)等,這部分是常規功能,測試原理很多都參考了 MegPeak/lmbench/ArchProbe 等工程的實現,此處不再展開,僅舉一個小例子方便大家看到它的價值。
例1. 在移動端 GPU 上在做向量計算的時候,我們會關心 int8:int16:int32 算力是否一定存在 4:2:1 的關係?mperf 實測數據顯示在 Adreno A640 呈現難以解釋的 int16>int8>int32,在 Mali G78 上則滿足比例關係,實測的詳實數據會告知開發者 float->int16 定點化是否能帶來性能收益。
Hierarchical Roofline 繪製
原生 Roofline Model 建模了“算子計算模式、目標硬件架構、性能”三者之間的關係,可以為算子調優提供大方向的指引,比如:
- 確認瓶頸:位於 Machine Balance Point 左側是訪存 bound,右側是計算 bound
- 指導優化方向: 如果是訪存 bound,可以考慮結合各種已知的專家經驗如 tiling/prefetch/aligned allocator 等進行優化嘗試,也就是知道了努力的方向
- 提示停止優化的時機:如果是計算 bound 且已經接近屋頂(峯值性能上限),可以考慮停止優化
- 預測性能:如果已知架構峯值性能數據、算子本身的計算訪存比、計算規模這三個數據就能算估算出執行時間
但因為原生 Roofline Model 存在一些問題:
- 未區分多級存儲的情況,一般只考慮 DRAM Bandwidth,如果輸入 Tensor 小到可以塞入 L1 Cache,採用 L1 Cache Bandwidth 更加準確
- 未區分執行環境的複雜性,比如是否啓動多線程,處於 Turbo Mode 等,這些都影響實際理論峯值
- 未區分指令類型(instruction mixes),一般默認採用單一指令如 FMA 進行測試,實際理論峯值可以是不同指令性能的加權求和
- 未區分 read/write/access,比如 sum(Tensor),採用 read Bandwidth 更加準確
之後發展出了 Hierarchical Roofline,實際中為了方便繪製,mperf 提供了不同的手段來獲取上述基礎數據。
繪製Roofline需要兩組數據:
-
架構理論峯值性能(GFLOPS)和帶寬(Bandwidth)
- 理論峯值性能:單指令測試原理參考此文;分析不同指令佔比的方案還在驗證中;
- 理論帶寬: 提供的方案可以測試多級存儲帶寬,並提供各種基礎 micro-kernel (如純 read 函數)來測試貼近實際訪存模式的帶寬上限
- 算子實測性能/帶寬: 通過 PMU 的方式獲取
PMU 數據蒐集、加工和分析
PMU 數據蒐集
CPU/GPU 架構大多都包含 PMU 硬件,用於計數一些底層硬件事件,如 CPU Core 所屬的執行指令數和時鐘週期,Cache 所屬的 L1 Cache Miss 等;mperf 提供了 CPU/GPU 的 PMU 數據獲取能力,特別是 Adreno GPU 這種缺乏官方開源支持的平台。
加工指標(又名 Metrics)
以 ARM A55 Core 為例,有超過 100 種硬件事件,Adreno A6xx 系列 GPU 則有約 125 種硬件事件,這些事件的數值可以用來加工計算各種指標,如 IPC=INST_RETIRED 計數(指令數)/ CPU_CYCLES 計數(Cycle 數),也可以用來計算 DRAM Bandwidth、算子 GFLOPS、L1 MISS Ratio 等等,具體的指標支持列表及其計算方式可閲讀文檔及源碼。
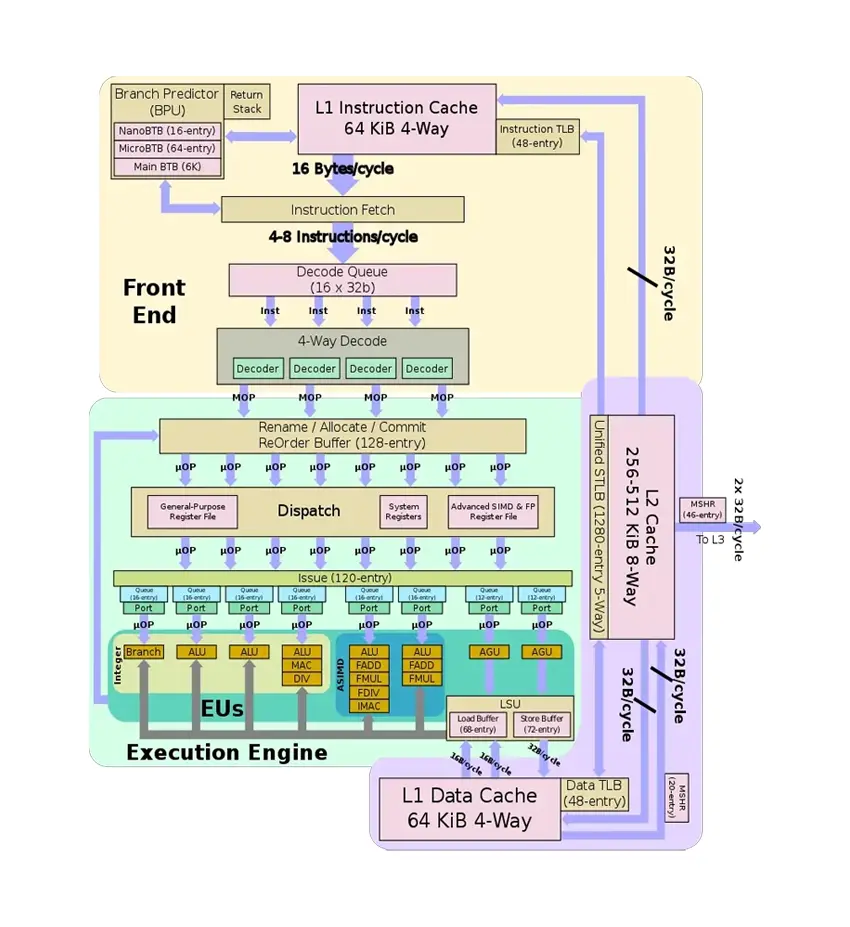
圖2 Arm A76 Core 微架構圖(來源)
TMA 分析
TMA 是一套自頂向下的 Intel CPU 算子性能瓶頸分析方法,這套思想可以擴展到其它架構。上圖描述了 A76 Core 指令的生命週期,過程中涉及到的硬件資源(如可執行 FMA 的端口數量)都可能成為指令執行過程中的瓶頸,TMA 用於分析瓶頸所在,從而指引優化方向,詳細思想大家可以閲讀官方文檔。
mperf 計算得到的所有指標中一部分可以歸類進 TMA 範式,另一部分作為單獨的指標存在用於輔助性能分析。不管是 TMA 還是獨立指標都可以提供細粒度的優化方向指引。
在 mperf 裏面我們將 TMA 擴展到了 ARM CPU 上,過程中我們得到了一些經驗:
- 因為 ARM CPU 提供的硬件事件的類別/定義與 Intel CPU 有很多差異,完美復刻 TMA 各類別的定義很困難也不現實,但是 ARM CPU 本身提供的硬件事件的類別也很豐富,可以摸索和總結出適合自身的 TMA 方案和獨立指標,實踐中我們證明了這條路行的通。
- ARM 不同系列 CPU 微架構之間有明顯差異,比如 A55(in-order)與 A76(out-of-order)在 TMA 各類別/定義上有很多不同,每個架構都需要單獨處理。
- 由於 vendor 相關資料開放程度不同,部分指標的定義可能會在長期實踐驗證中被修正。
本模塊 GPU 部分的長期目標是成長為移動端 GPU 類似 NVIDIA Nsight Compute 的等價物。目前已經總結了很多有優化指導意義的 GPU 指標,但 TMA 在 GPU 上可行性和必要性我們還在探索中。在通用計算相關指標方面(不涉及渲染相關),目前已經具備替代 ARM 官方 GUI 工具 streamline 和高通官方 GUI 工具 snapdragon profiler 的能力,使用這兩個 GUI 工具的同學可以嘗試替換為 mperf,一方面 API 級別更加靈活,另一方面可以享受到不斷增補指標(Metrics)帶來的好處。
這裏同樣舉一個實際例子來展示 mperf 的工作邏輯:
例2:GPU 支持不同向量寬度的浮點數據加載,如 vload4/8/16 等等,不同的架構有不同的限制,並不是向量寬度越寬越好,我們觀察到 Mali G78 GPU 上 vload4 比 vload16 快很多,在 mperf 中的分析邏輯如下:
首先蒐集一系列 event 的數值(下圖 3 展示了其中一部分),如 ExternalMemoryReadBytes 含義是 DDR→Unified L2 Cache 的 read 數據量,可以看出 vload16 相對 vload4 增加了 4 倍還多, LoadStoreReadFull(LS_MEM_READ_FULL) 含義是 full-width read 的次數,LoadStorePartial(LS_MEM_READ_SHORT)代表了 partial-width read 的次數,發現在 vload16 的時候 partial-width read 的次數增大了很多,額外發射了更多的 read 指令,解釋了速度變慢的原因。為了方便快速發現此類問題,mperf 也專門整理了一個 PartialReadRatio 的指標,其計算公式見下方。

圖3 Mali G78 vload4/vload8
// PartialReadRatio 計算公式
GpuCounter::PartialReadRatio, [this] {
return get_counter_value(MALI_NAME_BLOCK_SHADER, "LS_MEM_READ_SHORT") /
(float)(get_counter_value(MALI_NAME_BLOCK_SHADER,"LS_MEM_READ_FULL") + get_counter_value(MALI_NAME_BLOCK_SHADER, "LS_MEM_READ_SHORT"));}
更多關於 PMU 數據蒐集、加工和分析的細節,歡迎大家閲讀源碼。
OpenCL Linter
MegEngine 團隊在做 OpenCL 算子開發的過程中積累了一系列優化經驗,希望能通過工具化的方式將這部分經驗固化下來。
目前初步計劃參考 Linter 思路,大體有兩個部分:
- 靜態代碼分析掃描 OpenCL Kernel,檢查規則是預置的 OpenCL 專家優化經驗,如使用 select 指令而非三目運算符,對齊檢查等,給出優化建議。
- 在動態執行過程中監測各種預置的指標,結合專家經驗對一些異常數據給出提示,如寄存器使用量分析等,引導用户調優。
這部分工作目前正在做 POC 驗證,敬請期待。
總結
mperf 為移動/嵌入式平台性能調優提供了系列工具,其中在 PMU 獲取/ARM TMA/分層 Roofline 繪製/OpenCL Linter 等方面都有不同程度的創新,希望這個工具箱能為開發人員提供更多的分析手段和調優建議。
當前階段 mperf 開發方向會以優先豐富基礎工具為主,部分工具暫時還需要一些體系結構的知識才能用好,更長遠來看,我們會做更多的工作來降低使用門檻,朝着更易用更自動化的方向努力。與此同時,大家都希望有一套閉環的方法論來告訴我們算子調優的時候每一步先分析什麼指標,然後建議嘗試 N 種優化方法,不斷迭代到最優,但是目前業內距離這個願景還有點遠,mperf 也是如此,它的主要能力此刻還停留在為開發者提供更多決策信息的階段。
為了能更近一步,下一階段我們會先從積累豐富的實操案例入手,和 mperf 的使用者一起探索在不同的案例下什麼樣的指標能發現問題,什麼樣的優化方法可以嘗試;之後在發現特定指標異常的時候可以將積累的優化方法展示給用户。因此,mperf 是一個具有成長性的工程,歡迎大家一起參與共建,聚沙成塔,打造好用的調優工具!
mperf 開發過程中受到了上面提到的各種優秀開源工程的啓發和指引,方法論上參考了大量包括 Intel/ARM 官方文檔在內的諸多資料,在此一併致謝!
附:
更多 MegEngine 信息獲取,您可以:查看文檔和 GitHub 項目,或加入 MegEngine 用户交流 QQ 羣:1029741705。歡迎參與 MegEngine 社區貢獻,成為 Awesome MegEngineer,榮譽證書、定製禮品享不停。