

近期,以 OpenAI o 系列模型、Claude 3.5 Sonnet 和 DeepSeek-R1 等各類大模型為代表的 AI 技術快速發展,其知識與推理能力得到了廣泛認可。然而,許多用户在實際使用中也注意到一個普遍現象:模型有時未能嚴格遵循輸入指令的具體格式要求、字數限制或內容約束,導致輸出結果雖內容尚可,卻不完全符合輸入指令。
針對大模型知識推理能力與指令遵循能力存在表現差異的現象,為推進指令遵循能力的系統化研究與精準評估,美團 M17 團隊推出全新評測基準 Meeseeks。
基於 Meeseeks 基準的評測結果顯示(以輪次 3 為準),推理模型 o3-mini (high)憑藉絕對優勢強勢登頂,與另一版本 o3-mini(medium)包攬冠亞軍;Claude 3.7 Sonnet 的“思考版”則穩居第三,共同構成本次評測的第一梯隊,而 DeepSeek-R1 在所有模型中排名僅第七,GPT-4o 排名第八。此外 DeepSeek-V3 在非推理大模型中處於領先位置,而 Qwen2.5 則展現出參數規模與指令遵循能力並非絕對相關的有趣現象。(備註:評測結果來源於 Meeseeks 中文數據)

Meeseeks 支持 中文/英文,已在魔搭社區、GitHub、Huggingface 上線。
- 魔搭社區:https://www.modelscope.cn/datasets/ADoubLEN/Meeseeks
- GitHub: https://github.com/ADoublLEN/Meeseeks
- Huggingface:https://huggingface.co/datasets/meituan/Meeseeks
下面,讓我們一同深入瞭解 Meeseeks 評測體系及其具體發現。
1. Meeseeks:重新定義大模型“聽話”能力評測
Meeseeks 是一個完全基於真實業務數據構建的,專注於評測大模型指令遵循(Instruction-Following)能力的基準測試。它引入了一種創新的評測視角:只關注模型是否嚴格按照用户指令(Prompt)的要求生成回答,而不評估回答內容本身的知識正確性。為了全面、深入地衡量模型的指令遵循能力,研究人員設計了一套覆蓋不同粒度和層面的精細化評測框架。
1.1 精細入微的三級評測框架
你可能遇到過這種情況:讓模型 “用 50 字介紹北京,別提故宮”,結果它寫了 80 字,還順口誇了句 “故宮雄偉”。這就是典型的 “指令遵循翻車”——不看對錯,只看是否按要求來。
Meeseeks 的評測框架從宏觀到微觀,把這種 “要求” 拆成了三層,像剝洋葱一樣細,確保評估的深度與廣度。

- 一級能力:任務核心意圖與結構的把握。這是最基礎的層面,主要評估模型是否正確理解了用户的核心任務意圖(Intent Recognition)、回答的整體結構是否滿足指令(Output Structure Validation),以及回答中的每一個獨立單元是否都符合指令細節(Granular Content Validation)。例如,在“以 JSON 格式生成 10 個以‘天’開頭的花名”指令中,一級能力會分別檢查模型是否理解了“生成花名”的意圖、是否輸出了 10 個條目並採用了 JSON 格式、以及每個花名是否都以“天”字開頭。
- 二級能力:具體約束類型的實現。 在理解任務的基礎上,此層級關注模型對各類具體約束的執行情況,主要分為內容約束與格式約束。內容約束包括主題(如改編歌詞需提及特定內容)、文體(如生成劇本)、語言(如繁體)、字數(如精確值、範圍)等;格式約束則涵蓋模版合規(如 JSON、Markdown)、單元數量(如生成指定數量的評論)等。
- 三級能力:細粒度規則的遵循。 這是最精細的評測層面,關注那些極易被模型忽略的細節規則。這包括通用的細則,如押韻、關鍵詞規避、禁止重複、符號使用、特定寫作手法等;也包括中文特有的規則,如平仄、成語接龍等,全面考驗模型的細緻程度。
2. Meeseeks 評測結果
本次 Meeseeks 基準評測清晰地揭示了不同模型在指令遵循與自我糾錯能力上的顯著差異。評測結果顯示,RLLMs(推理語言模型)在所有輪次中均展現出壓倒性優勢,而一些知名大模型的表現則引發了深入思考。

在經過三輪評測後,各模型的最終排名與表現分析如下:
- OpenAI o-series 絕對優勢:o3-mini(high)與 o3-mini(medium)在本次評測中位列第一與第二名。作為推理語言模型(RLLMs),它們在指令遵循任務上表現突出。
- GPT-4o 跌出第一梯隊:與 o-series 模型的強勢表現相比, GPT 系列的模型表現意外不佳:GPT-4o 最終排名為第八(準確率 0.531)。分析顯示,其排名受初始準確率(0.312)較低的影響,且在多輪糾錯環節中的準確率提升幅度(總計提升 0.219),小於部分其他參評模型。
- Claude 系列表現強勁:Claude 系列模型在此次評測中表現出顯著的自我糾錯能力。其中,具備推理能力的 Claude-3.7-Sonnet-thinking 排名第三。其標準版 Claude-3.7-Sonnet 則在所有參評的通用大模型(LLMs)中位列第一,總排名為第四。
- DeepSeek 系列位居評測中游:DeepSeek 系列模型在中游排名中呈現出性能趨同與反轉的現象。評測發現,DeepSeek-V3 的兩個版本在多輪評測後性能趨於一致。同時,DeepSeek-R1 在初始輪次領先的情況下,其最終排名被 DeepSeek-V3-Chat-20241226 超越。
- Qwen2.5 系列觀察:Qwen2.5 系列的兩個模型排名相對靠後。其中一個值得關注的現象是,參數量較小的 32B 版本在三輪評測後的最終表現,優於參數量更大的 72B 版本。
3. Meeseeks 的獨特優勢
3.1 橫向對比:更廣、更細、更客觀、更高難度
相較於 IF-Eval、Complexbench 等知名的開源指令遵循評測集,Meeseeks 在多個維度上實現了突破,展現出其獨特的評測價值。
Meeseeks 通過四個關鍵特性,構建了其在橫向對比中的核心競爭力。
首先是 覆蓋面更廣,其數據源於豐富的真實業務場景,確保了評測的全面性與實用價值。
其次是 評測粒度更細,它將單一約束拆解得更為精細,如將“字數遵循”細分為精確值、範圍、倍數等多種情況,實現了對模型能力的精準畫像。

再者是 杜絕主觀評測,摒棄瞭如“以媽媽的口吻”這類模糊指令,所有評測項均為客觀可判定標準,保證了結果的一致性。

最後是 數據難度更高,其測試用例設計更具挑戰性,能有效拉開不同模型間的差距。
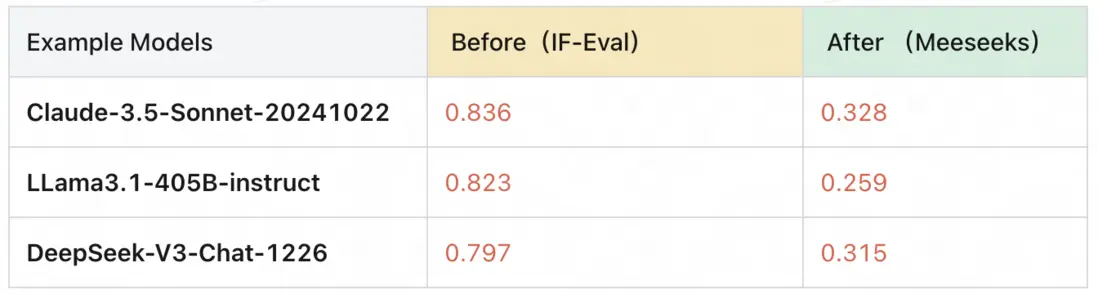
3.2 縱向創新:革命性的“多輪糾錯”模式
Meeseeks 最具突破性的特點:
- 其一評測 更靈活:受模型回答風格/格式影響小,無需限定模型回答特定格式,對不同模型的兼容性更強;
- 其二 全新的“多輪模式”。在該模式下,如果模型的第一輪迴答未能完全滿足所有指令,評測框架會自動生成明確的反饋,指出具體哪個指令項未被滿足,並要求模型根據該反饋修正答案。這種模式首次將模型的“自我糾錯”能力納入指令遵循的評測範疇。
為了驗證該模式的有效性,研究團隊選擇了一批具有代表性的推理語言模型(RLLMs)和大型語言模型(LLMs)進行了評測。如前文圖 1 所示,結果清晰地展示了各模型在不同糾錯輪次下的表現。
4. 核心評測洞察
通過對多輪評測數據的深入分析,研究團隊得出以下幾點關鍵發現:
- 強大的自我糾錯潛力:所有模型在接收到反饋後,其指令遵循準確率均有顯著提升。例如 Claude-3.7-Sonnet 在第二輪的準確率從 0.359 躍升至 0.573,我們得出結論:不管是 RLLMs 還是 LLMs 在指令遵循場景,都存在強大的自我糾正的能力。
- 首輪表現與最終表現的相關性: 模型的第一輪表現(Round 1)與其最終表現(Round 3)並非完全相關。部分模型存在第一輪劣勢,但是第三輪優勢的情況,這説明了模型自我糾錯至正確答案的能力和能一次遵循所有用户指令的能力並非完全相關。
- 與部分指令遵循 Benchmark 相悖的是:RLLMs 的指令遵循能力相比 LLMs 更加優異,特別是 o3-mini 這樣的 RLLMs 不僅初始表現優異,其後續提升同樣顯著,最終以絕對優勢領跑。我們發現,在大量文案生成任務中,我們發現了一些模型會反覆確認當前輸出的內容是否與之前重複;在存在字數要求的場景下,RLLMs 甚至會出現 1 你 2 好這樣的輔助 index 方法來確認字數,這些給 RLLMs 在指令遵循任務上帶來了非常大的優勢。
- 多輪場景下長思維效益縮減?具備更強推理能力的模型(如 Claude-3.7-Sonnet-thinking)與其對應的標準版本(Claude-3.7-Sonnet)在指令遵循能力上的差距,會隨着糾錯輪次的增加而逐漸縮小,這表明反饋機制可以在一定程度上代替了 RLLMs 的長思維鏈帶來的效益,有效地讓模型逐漸達到自身指令遵循能力的上限。
5. 總結與展望
綜上所述,面對當前大模型普遍存在的“不聽話”痛點,Meeseeks 基準通過其精細化的三級評測框架、對客觀性的嚴格堅守以及革命性的“多輪糾錯”模式,把評測結果不僅揭示了頂尖模型在複雜指令面前的真實短板,也驗證了模型強大的自我修正潛力,將指令遵循評測帶到了全新的維度。這為模型開發者指明瞭優化方向:除了提升基礎能力,更要強化模型理解並執行修正指令的能力。
目前,對於共計 11 種語言的 Meeseeks 多語言版本已經在開發末期,多語言 Meeseeks 不僅在保證準確率的基礎上適配了不同語言,並基於不同語言的特色內容構建了全新的指令遵循內容,會在不遠的將來和大家見面!
未來我們將持續專注於高質量評估研究,推動大模型在指令遵循能力上的提升與發展。歡迎關注美團 M17 團隊,瞭解更多關於評測集的內容!
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明“內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。
