

本篇為《可信實驗白皮書》系列的最後一篇內容,主要分享了AB實驗分析方法庫在美團的實踐。同時,我們也為大家準備了一份系列全集的PDF文檔,希望能夠幫助到更多從事AB實驗工作的同學們。
獲取方式:關注美團技術團隊微信公眾號,在對話框回覆「可信實驗白皮書」即可獲取下載鏈接。
為了幫助任何用户輕鬆擺脱A/B測試中的各種挑戰,讓沒有複雜實驗背景和專家知識的人也能零門檻自主進行可信、高效的實驗。同時實現實驗方法庫與實驗平台各基礎設施(例如流量配置、數據生產)的解耦,以方便各專業團隊能在各自領域內發揮專長,提高平台功能與方法的迭代效率。美團履約技術團隊孵化了AB實驗分析方法庫——實驗分析引擎BETA(Banma Experimentation and Testing Analysis)。該庫涵蓋數十種先進的實驗技術,支持實驗設計、評估、診斷等環節所需的多樣化核心功能以及標準化流程。並在工程層面統一解決了實驗過程中大量統計理論導致的實驗分析複雜化問題、過多統計陷阱引起的實驗不可信難題,使實驗者能夠無門檻地以科學、高效的方式開展實驗,並輕鬆獲得可信的實驗報告。
目前,該實驗分析引擎作為核心方法庫,已經面向美團內部開放,方便實驗者和數據科學家的按需取用以及靈活探索需求。同時可避免重複開發相同解決方案的工作浪費,促進跨團隊的知識共享和能力提升,推動整體實驗能力的提升。關於履約平台實驗分析引擎的更多思考,可參閲美團技術博客《新一代實驗分析引擎:驅動履約平台的數據決策》。
8.1 產品特性
在履約技術團隊,運行着大量實驗,我們希望賦能所有團隊以速度、嚴謹和信心進行改進。為此,秉承着可信、開放、敏捷、易用的原則,打造了新一代實驗引擎。該實驗分析引擎通過良好的封裝以及設計,包括但不限於以下特性。
- 豐富的實驗方法:涵蓋白皮書中提到的所有實驗方法,包括隨機對照實驗、隨機輪轉實驗、準實驗、觀察性研究4大類別,其中提供了11+種實驗方法、7+種分組方法、10+種假設檢驗方法等等。不僅覆蓋單邊、多邊實驗場景多樣實驗用例,還提供了業界領先的小樣本解決方案,如協變量自適應分組來解決小樣本同質性問題,輪轉實驗和雙重差分實驗來應對溢出效應問題,以及合成控制法等觀察性研究技術等。
- 方便易用:標準化實驗分析請求參數,分析引擎會依據實驗方法、指標類型、樣本分佈等上下文自動選擇最為合適的檢驗方法,確保分析過程的魯棒性。同時整個實現流程標準化,可自動執行數據預處理、策略效應估計、方差計算、P值計算(假設檢驗),最終得出分析結論。如果進行的是實驗設計,系統會根據實驗方法選擇與之相匹配的實驗分組方法。
- 性能高效:分析方法執行期間會充分利用向量化運算、並行化技術來提升分析效率,其中隨機對照實驗支持分佈式計算,億級別數據可在分鐘級完成分析。
- 多重比較修正:檢驗結果自動進行多重比較修正,解決了對於多實驗組、多指標檢驗引起的第一類錯誤增大問題,確保實驗結果科學性。
- 功效提升:例如隨機對照實驗場景下支持通過CUPED來進行方差縮減以提升檢驗靈敏度,支持選擇一元同系數CUPED、二元同系數CUPED、新CUPED等多種方差縮減方法。
- 統合分析:突破單次實驗樣本量限制,支持對相同目的、相互獨立的多個實驗進行綜合分析,以提升檢驗的統計功效。有助於在小流量場景下檢測策略效果,且無需單個實驗有大量樣本就能獲得可信結果。支持的統合分析技術包括樣本加權、逆方差加權等。
- 功效測算:提供最小樣本量預估、MDE等計算方法,方便用户在實驗前判斷實驗樣本量是否充足,以避免實驗白做。同時在實驗後幫助用户分析策略不顯著原因,判斷是由於樣本量不足,還是策略無效或未達預期導致,從而支持科學的實驗決策。
8.2 系統設計
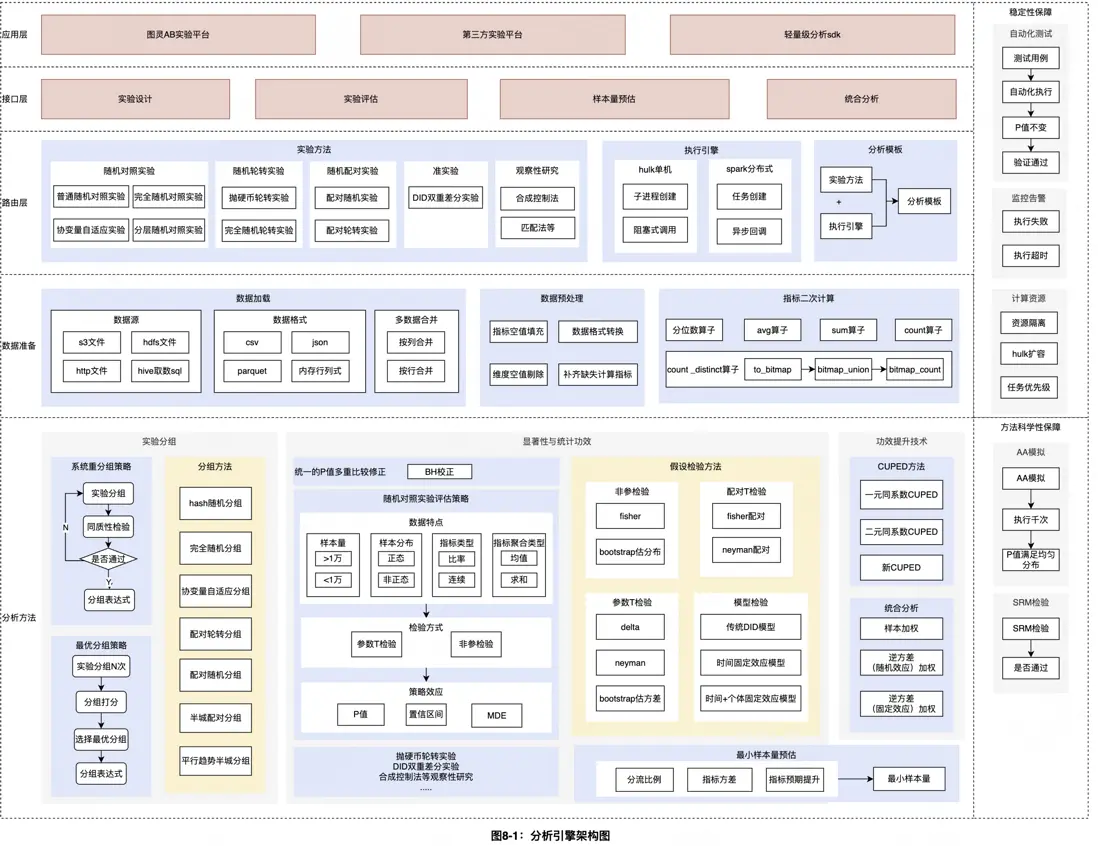
如圖8-1所示,分析引擎提供標準化的分析流程以及多樣化方法,採用模塊化和分層設計原則來提升實驗方法的迭代、拓展效率,以及實現像積木一樣靈活應用,服務不同角色的用户。具體每層作用如下:
- 應用層:上層實驗平台入口,包括到家履約團隊孵化的圖靈實驗平台,通過接口接入分析引擎的第三方實驗平台。此外還可通過Python SDK線下便捷使用實驗分析引擎進行實驗分析。
- 接口層:面向應用層提供的標準化的實驗設計與實驗評估接口。通過抽象出通用的實驗分析參數,如數據集、分析指標、指標元數據、實驗分組信息、擴展參數等信息,進而標準化了整個實驗分析流程。這種方式提升了系統擴展性,方便我們快速集成新的實驗方法,降低運維成本。
- 路由層:實驗分析模板是通過原子分析方法庫編排出的對應實驗方法的確定的分析流程。路由層會根據實驗方法、執行引擎信息,路由至不同的實驗分析模板。特別的對於面向海量數據場景下的普通隨機對照實驗,我們通過抽象出一些關鍵聚合算子(如協方差、方差、均值等)的計算邏輯,適配了一套基於PySpark的分佈式執行引擎。利用到Spark對於批量聚合算子的處理優化技術,做到了分鐘級完成億級以上的海量數據評估。
-
數據準備層:實驗分析流程之前引擎層統一進行數據處理流程來準備實驗數據集,包括:數據加載、數據預處理、指標二次計算等。這裏的數據處理流程同時支持了單機與分佈式兩種方式。
- 數據加載:單機分析方式支持S3(美團內部存儲服務)文件、HTTP文件作為數據源,通過pandas.DataFrame方式表徵數據集。分佈式分析方式支持HDFS文件、Hive取數SQL兩種方式定義數據源,通過pyspark.DataFrame來表徵數據集。實驗數據集定義方式支持多源合併策略,包括按列合併、按行合併。
- 數據預處理:引擎側對異常數據進行統一的預處理,以獲取有效、準確的實驗數據,整個流程包括:① 空值填充,對於指標空值進行補零填充;② 數據格式轉換,指標類型統一轉換為Float32類型;③ 異常值剔除,支持實驗單元為空值時的自動剔除,支持配置3σ 、IQR等統計方法對天級異常數據的剔除,並將剔除信息展示在最終的實驗報告中。④ 補齊缺失計算指標,基於指標計算公式以及對應原子指標,補齊缺失的計算指標。
- 指標二次計算:滿足個性化指標計算訴求,通過將更細粒度的數據按照預定義的指標聚合算子,上卷至實驗單元粒度的數據。如:xx指標90%分位點-10%分位點。
-
分析方法層:實驗分析引擎所集成的核心方法庫,這一層通常由數據科學家負責,涵蓋實驗分組方法、假設檢驗方法、功效提升技術、最小樣本量預估、MDE計算等核心方法。每種實驗方法的實驗分組方法、顯著性檢驗方法均編排至對應的分析模板中。其中顯著性檢驗方法必須經過AA模擬驗證才能上線,以確保實驗方法的科學性。
- 實驗分組:一般情況下,一個分組方法確定了一個實驗方法。整體來看實驗分組方法主要分為兩類,① 隨機實驗分組,支持對於單次分組不同質時的系統重分組(最多5次),以儘可能獲取一個滿足實驗條件的分組。這類實驗方法包括:隨機對照實驗、隨機輪轉實驗。② 最優實驗分組,通過隨機多次產生多個分組,選取Diff最小的一個分組作為最終分組。這類實驗方法包括:隨機配對實驗、DID雙重差分實驗。
- 顯著性檢驗:通過實驗方法、數據特點選擇合適的假設檢驗方法,產出顯著性檢驗結果。這裏檢驗方法主要包括四大類:非參檢驗、參數檢驗、配對檢驗、模型檢驗。對於隨機對照實驗,默認會通過CUPED方法來提升檢驗靈敏度。完成顯著性檢驗後也會通過統一的P值多重比較修正,以解決指標多重比較之後帶來的假陽率升高問題。
8.3 系統接入
作為核心分析方法庫,當前分析引擎已面向美團內部全體成員開放,並提供多種接入途徑,方便實驗者自行根據自身場景選擇最佳實驗接入方式。

8.4 線下分析實戰
案例:履約xx算法計劃開展一次隨機對照實驗以對比驗證策略效果,實驗流量選取若干城市,實驗單元為AOI,實驗指標:訂單量、完單用户數,人均完成單量,其中人均完成訂單量指標為比率型指標,計算公式= [訂單量]/[完單用户數]
預期分三個實驗分組,分組流量配比分別為2:3:5。額外要求採用CUPED方法以提升檢驗靈敏度,通過murmurhash哈希函數來生成隨機分組表達式。
方案:由於實驗或指標暫時並未接入實驗平台,為了快速開展實驗,需採用線下分析的方式來進行實驗設計,以尋找滿足實驗要求的分組劃分方式。通過如下四個步驟即可在線下完成一個完整的隨機對照實驗設計(實驗後的評估流程類似),具體流程如下:
步驟01 :引入分析包
通過pip命令安裝線下分析SDK,引入核心分析客户端AbAnalyzeClient及相關類。
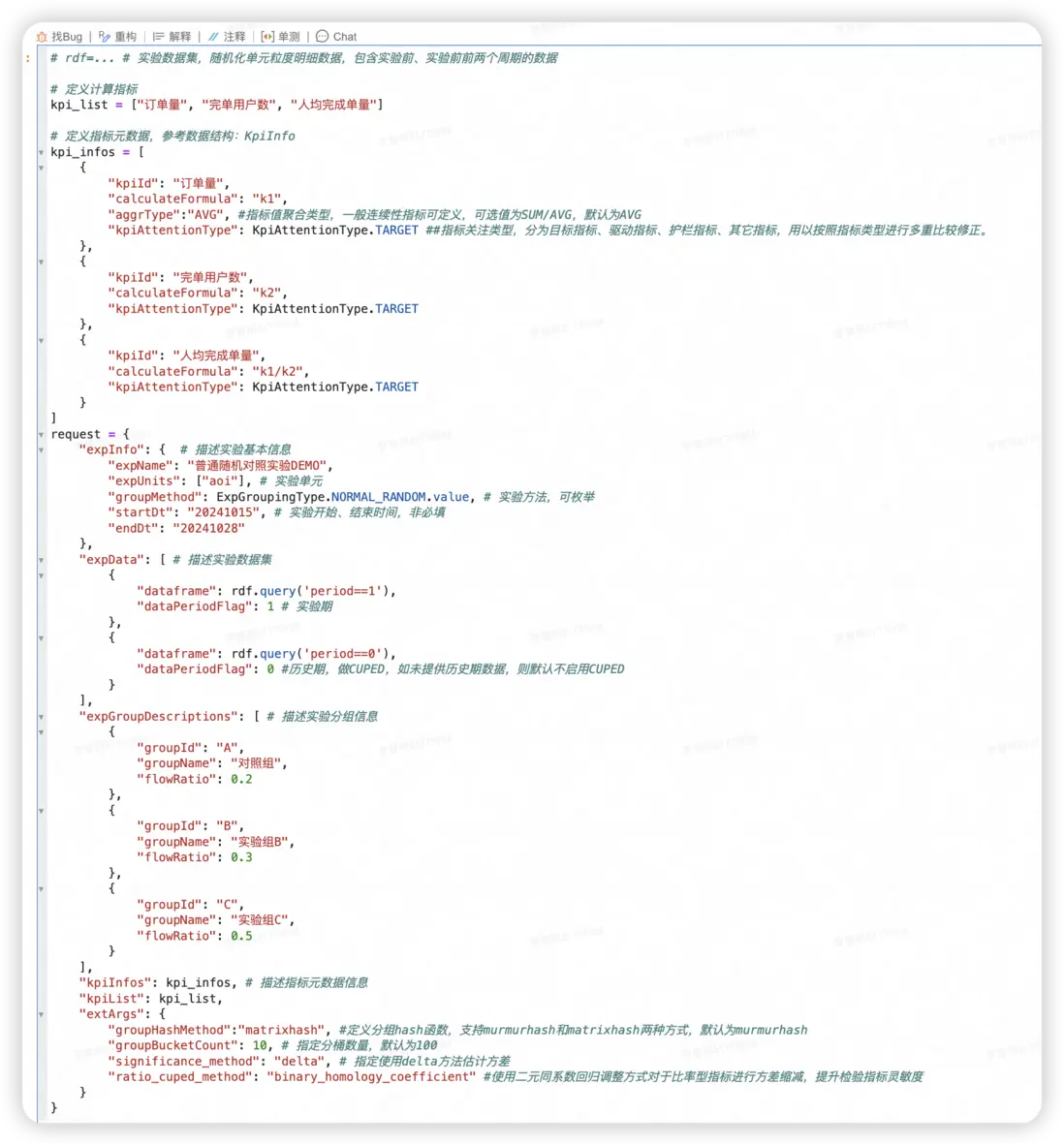
步驟02:定義分析參數
- 通過定義數據集、實驗分組、分析指標等信息來構造分析請求,請求參數對應於數據結構[AnalyzeRequest]。
- 可以通過擴展參數extArgs來控制指定具體的分析行為,本案例中通過設置方差估計方法為delta、CUPED方法為二元同系數迴歸調整來指定隨機對照實驗的分析行為。
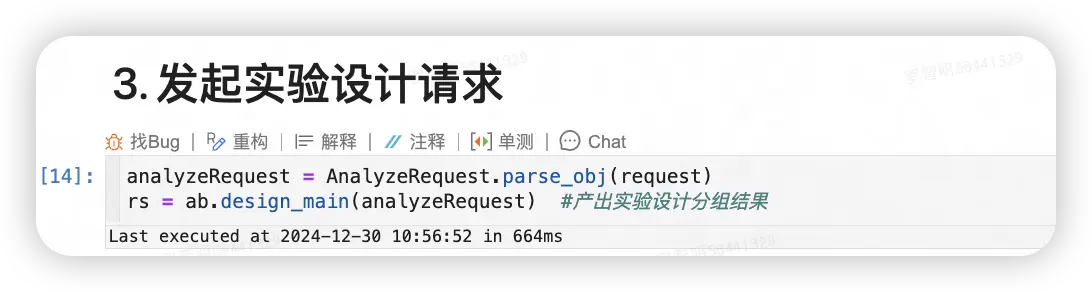
步驟03:發起分析請求
- 通過函數式調用發起分析請求,這裏會自動執行遠程調用操作,直至返回分析響應結果,響應結果對應數據結構[AnalyzeResponse]
- 如果某次分組不同質,後端系統會自動進行重試以獲取一個目標指標滿足同質性的分組結果。
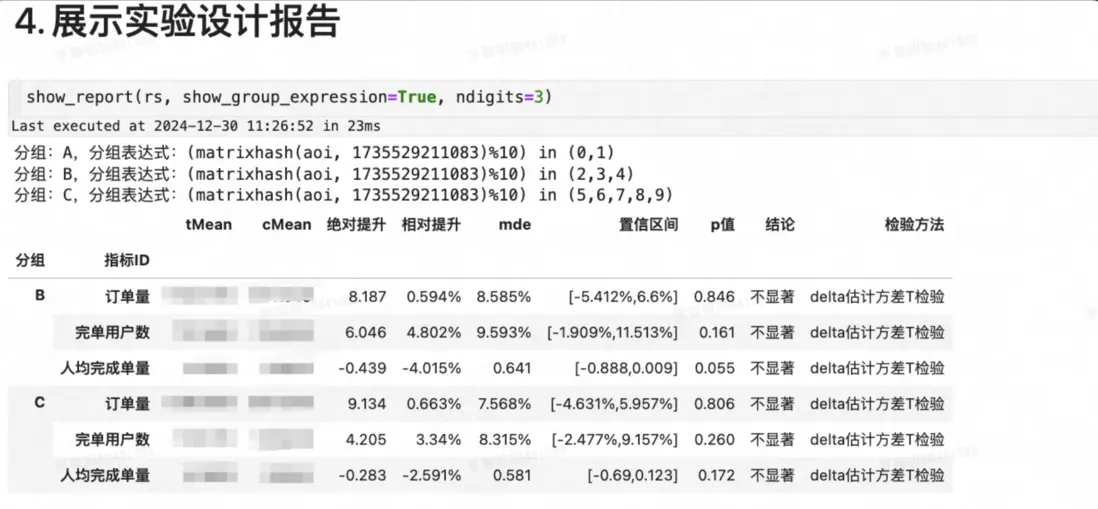
步驟04:實驗設計報告
- 通過show_report函數以表格方式展示同質性檢驗結果信息,該報告支持複製。
- 業務可自行根據MDE、P值來判斷該次分組是否達到實驗開展的前提條件,如果達到滿足實驗條件,即可使用最終分組表達式來開展實驗。
總結與展望
本白皮書基於美團履約與外賣策略的實驗實踐,系統梳理了隨機對照實驗、隨機輪轉實驗、準實驗、觀察性研究四大類方法以及高階實驗工具,涵蓋數十種實驗技術,構建了完整的實驗科學方法體系。為提高實操性,同步提供了配套分析引擎工具的使用指南,可助力用户快速上手。展望未來,我們將持續追蹤實驗方法的前沿進展,分享其在履約等場景的落地經驗與最佳實踐。同時逐步開放可信實驗分流與計算架構等實驗知識,推動實驗能力的規模化賦能。通過共建科學、高效的實驗體系與文化生態,致力於為組織的創新突破與可持續增長提供堅實支撐。
致謝
首先衷心感謝美團履約與外賣數據科學團隊,特別是主要作者以及同事們對本白皮書的辛勤付出。同時感謝履約與外賣算法、數據、業務和產品等團隊的鼎力支持,正是多部門背後的協同實踐探索,以及對實驗科學的信賴與支持,才使得我們不斷深化對實驗方法的理解與應用。最後誠摯感謝每一位讀者的關注與閲讀,希望本文對您有所啓發,也歡迎和期待與您分享交流,共同成長。
閲讀更多
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明“內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。