

本文介紹了美團技術團隊在國際頂會ICCV 2025中發表的5篇論文。同時,在ICCV 2025 舉辦的多模態推理競賽中,美團基礎研發平台/計算和智能平台組建的ActiveAlphaAgent團隊,斬獲賽題1真實場景視覺定位(VG-RS)冠軍,賽題2空間感知視覺問答(VQA-SA)季軍和賽題3創意廣告視頻視覺推理(VR-Ads)季軍。本文也分享了這三道賽題的解題思路,希望相關研究能給同學們帶來一些幫助或啓發。
計算機視覺國際大會(ICCV, International Conference on Computer Vision),是由IEEE主辦的頂級會議之一,與計算機視覺模式識別會議(CVPR)和歐洲計算機視覺會議(ECCV)並列為計算機視覺領域的三大頂級會議,中國計算機學會CCF推薦的A類會議。 ICCV每兩年舉辦一次,被公認為三大會議中級別最高的會議。
01 DisTime: Distribution-based Time Representation for Video Large Language Models
論文類型:ICCV Main Conference
論文下載:PDF
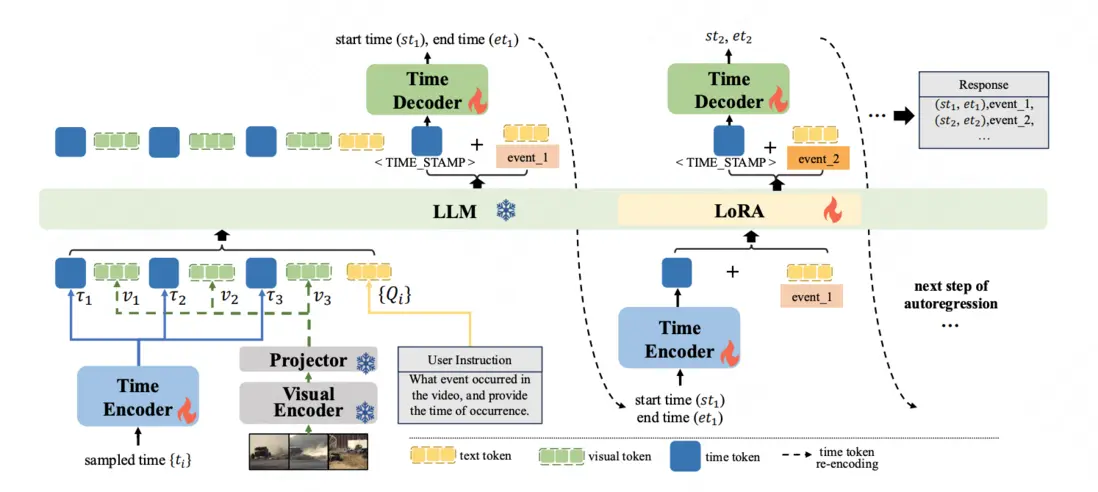
論文簡介:儘管視頻大型語言模型(Video-LLMs)在通用視頻理解方面取得了進展,但是在精確的時間定位上仍面臨挑戰,這主要是由於離散的時間表示和有限的時序感知數據集。現有的時間表達方法要麼將時間與基於文本的數值混淆,要麼添加一系列專用的時間標記,或者通過專門的時間定位頭回歸時間。
為了解決這些問題,我們引入了DisTime,這是一種輕量級框架,旨在增強視頻大型語言模型的時間理解能力。DisTime使用單個可學習的時間標記來創建一個連續的時間嵌入空間,並結合基於分佈的時間解碼器,生成時間概率分佈,有效緩解邊界模糊性並保持時間連續性。此外,基於分佈的時間編碼器重新編碼成時間戳,為視頻大型語言模型提供時間標記。為了克服現有無監督數據集中的時間粗粒度,我們提出了一種自動化標註模式,將視頻大型語言模型的描述能力與專用時間模型的時序定位相結合。這促進了InternVidTG的創建,這是一個包含17.9萬個視頻和125萬個時間定位事件的大型數據集,是ActivityNet-Caption的55倍。大量實驗表明,DisTime在三個不同的時間敏感任務的基準測試中達到了最先進的性能,同時在視頻問答任務中保持了競爭力。
02 ARIG: Autoregressive Interactive Head Generation for Real-time Conversations
論文主頁:ARIG
論文下載:PDF
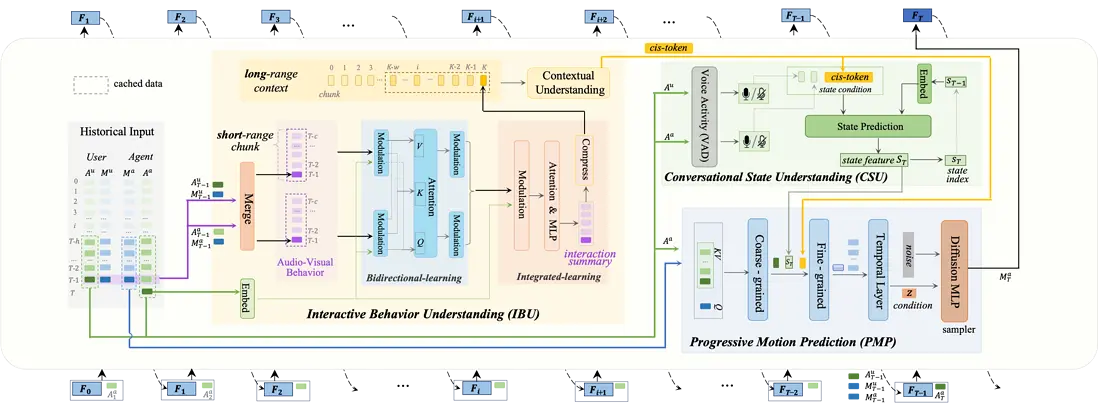
論文簡介:在2D可交互數字人生成任務中,之前研究採用了clip-wise的diffusion生成範式或顯式的聽者/説者切換方法,它們在未來信號獲取、上下文行為理解和狀態切換平滑度方面存在侷限性,難以實現實時性和真實感。本文提出了一種基於自迴歸 (AR) 的逐幀生成框架 ARIG,採用AR+diffusion框架以實現流式實時生成,並充分利用上下文語境和複雜對話狀態理解實現了更高的交互真實感。
為了實現實時生成,論文將運動預測建模為非向量量化的 AR 過程。與離散碼本索引預測不同,論文使用擴散過程表徵運動分佈,從而在連續空間中實現更準確的預測。為了提高交互真實感,論文注重交互式行為理解 (IBU) 和複雜對話狀態理解 (CSU)。在IBU中,基於雙路雙模態信號,通過雙向集成學習總結短距離行為,並在長距離範圍進一步實現上下文理解。在CSU中,利用語音活動信號和上下文特徵來理解實際對話中存在的各種複雜狀態(打斷、反饋、停頓等),並以此作為最終漸進式動作預測的條件,最終通過擴散過程實現動作生成。
03 Advancing Visual Large Language Model for Multi-granular Versatile Perception
論文類型:ICCV Main Conference
論文下載:PDF
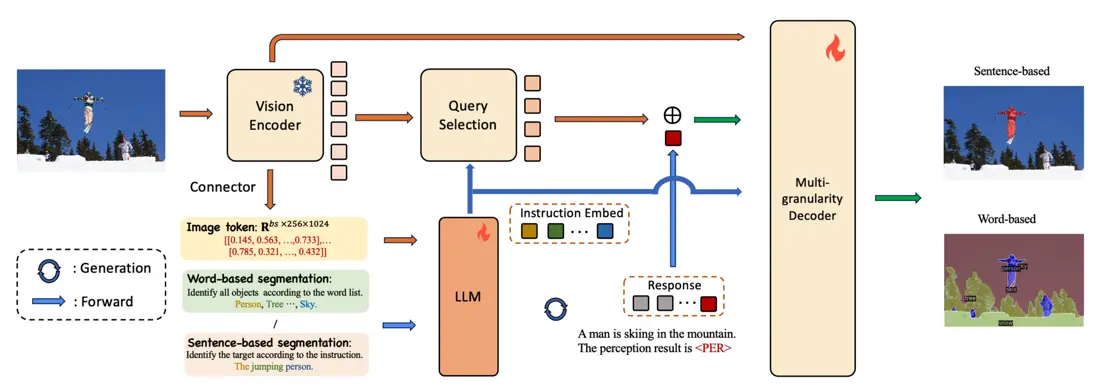
論文簡介:感知是計算機視覺領域中的一項基礎任務,涵蓋了多種不同的子任務。這些子任務可以根據預測類型和指令類型兩個維度,系統地劃分為四個不同的類別。值得注意的是,現有研究往往只專注於這些潛在組合中的一小部分,這限制了它們在不同場景下的適用性和多樣性。
針對這一挑戰,我們提出了MVP-LM——一種融合了視覺大語言模型的多粒度、多功能感知框架。我們的框架旨在於單一架構中整合基於詞語和基於句子的感知任務,支持框及掩碼的預測。MVP-LM配備了創新的多粒度解碼器,並結合了受鏈式思維啓發的數據集統一策略,使其能夠在包括全景分割、檢測、定位和指代表達分割等在內的廣泛任務上實現無縫的有監督微調。此外,我們還提出了一種查詢混合增強策略,旨在充分利用視覺大語言模型固有的解碼與生成能力。在基於詞語和基於句子的感知任務的多個基準測試中,我們進行了大量實驗,結果驗證了我們框架的有效性。
04 A Token-level Text Image Foundation Model for Document Understanding
論文類型:International Conference on Computer Vision
論文下載:PDF
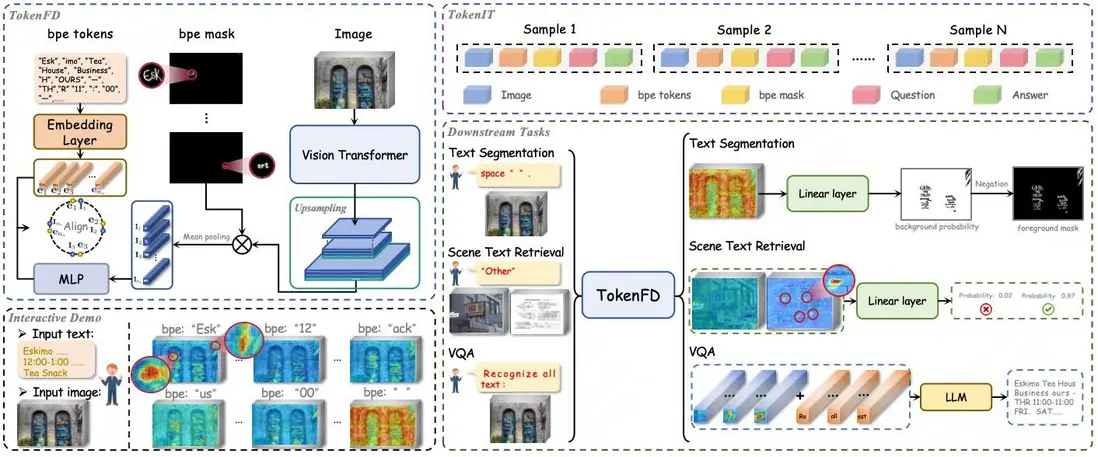
論文簡介:百億Token級掩碼數據構建圖文領域首個細粒度大一統基座,模態GAP不再存在 CLIP、DINO、SAM基座的重磅問世,推動了各個領域的任務大一統,也促進了多模態大模型的蓬勃發展。然而,這些經過圖像級監督或弱語義訓練的基座,並不是處理細粒度密集預測任務的最佳選擇,尤其在理解包含密集文字的文檔圖像上。
為解決這一限制,我們實現了圖文對齊粒度的新突破,其具備三大核心優勢:
- 構建業內首個token級圖文數據集TokenIT:該數據集包含 2000 萬條公開圖像以及 18 億高質量的Token-Mask對。圖像中的每個BPE子詞均對應一個像素級掩碼。數據體量是CLIP的5倍,且比SAM多出7億數據對。
- 構建圖文領域首個細粒度大一統基座TokenFD:僅需通過簡單的一層語言編碼,依託億級的 BPE-Mask 對打造出細粒度基座 TokenFD。真正實現了圖像Token與語言Token在同一特徵空間中的共享,從而支持Token級的圖文交互和各種下游任務。
- TokenVL打通模態GAP:進一步開放圖像即文本的語義潛力,首次實現在大語言模型中進行token級的模態對齊,賦能密集型的多模態文檔理解任務。
05 InstructSeg: Unifying Instructed Visual Segmentation with Multi-modal Large Language Models
論文類型:ICCV Main Conference
論文下載:PDF
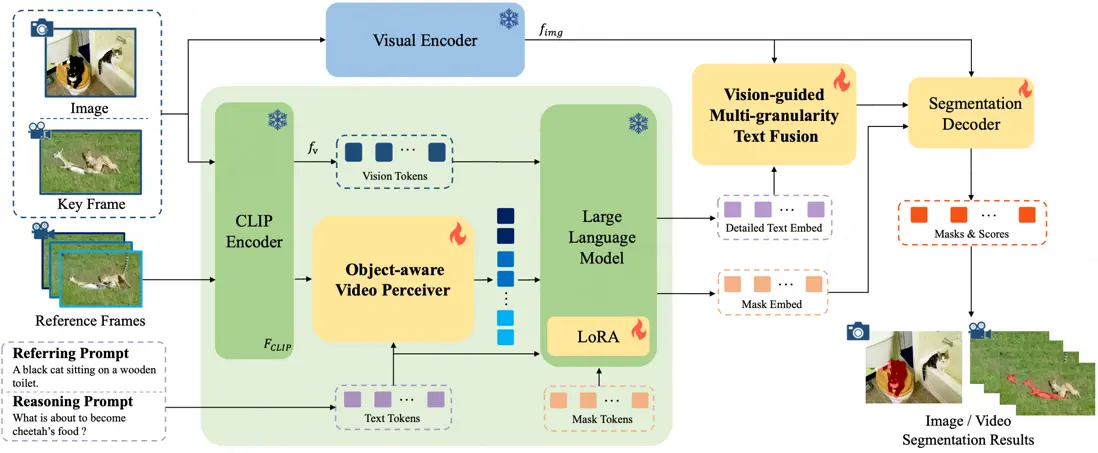
論文簡介:受多模態大型語言模型 (MLLM) 推動,用於圖像和視頻領域的文本引導通用分割模型近年來取得了快速發展。然而,這些方法通常是針對特定領域單獨開發的,而忽略了這兩個領域在任務設置和解決方案上的相似性。本文首先把圖像和視頻級的參考分割和推理分割的統一歸到指導視覺分割 (IVS)框架下,並提出了 InstructSeg,一種專用於 IVS任務 的 基於MLLM 的端到端分割模型。InstructSeg利用目標感知的視頻感知器從參考幀中提取時間和目標雙重信息,從而提升模型的視頻理解能力。此外,我們引入了視覺引導的多粒度文本融合,更好地將全局和細節的文本信息與細粒度的視覺引導相結合。通過利用多任務和端到端訓練,InstructSeg 在各類圖像和視頻任務中表現出色,僅通過單一模型超越了以往的分割專家模型和基於 MLLM 的方法。
ICCV 2025 多模態推理競賽解題方案
大推理模型(LRM)時代已經來臨,這為計算機視覺領域帶來了新的機遇與挑戰。大語言模型(LLM)強大的語義智能與大推理模型(LRM)的鏈式推理能力,為視覺理解和解釋開闢了新的前沿領域。
為了彌合計算機視覺與大語言/推理模型之間的鴻溝,本次會議將探討多模態大模型如何通過思維鏈(Chain-of-Thought)、多步推理(Multi-step Reasoning)等慢思考方法理解複雜關係,深入理解複雜場景中的對象交互。在此背景下,本次舉辦的Challenge on Multimodal Reasoning,重點關注需要高級推理能力的多模態複雜任務,具體包括:
- 賽題1:真實場景視覺定位(VG-RS),評估模型在複雜多模態場景中的場景感知、物體定位與空間推理能力。
- 賽題2:空間感知視覺問答(VQA-SA),評估模型基於具體物理規律,遵循用户指令進行空間推理、常識推理與反事實推理的能力。
- 賽題3:創意廣告視頻視覺推理(VR-Ads),評估模型在廣告視頻中理解非物理性及抽象視覺概念的認知推理能力。
三道賽題均未提供官方訓練數據,最終需要提交模型和推理方案由組委會進行復現。
美團/基礎研發平台/計算和智能平台部組建的ActiveAlphaAgent團隊參加了ICCV 2025舉辦的Challenge on Multimodal Reasoning,斬獲賽題1真實場景視覺定位(VG-RS)冠軍,賽題2空間感知視覺問答(VQA-SA)季軍和賽題3創意廣告視頻視覺推理(VR-Ads)季軍。
賽題1:真實場景視覺定位(VG-RS)
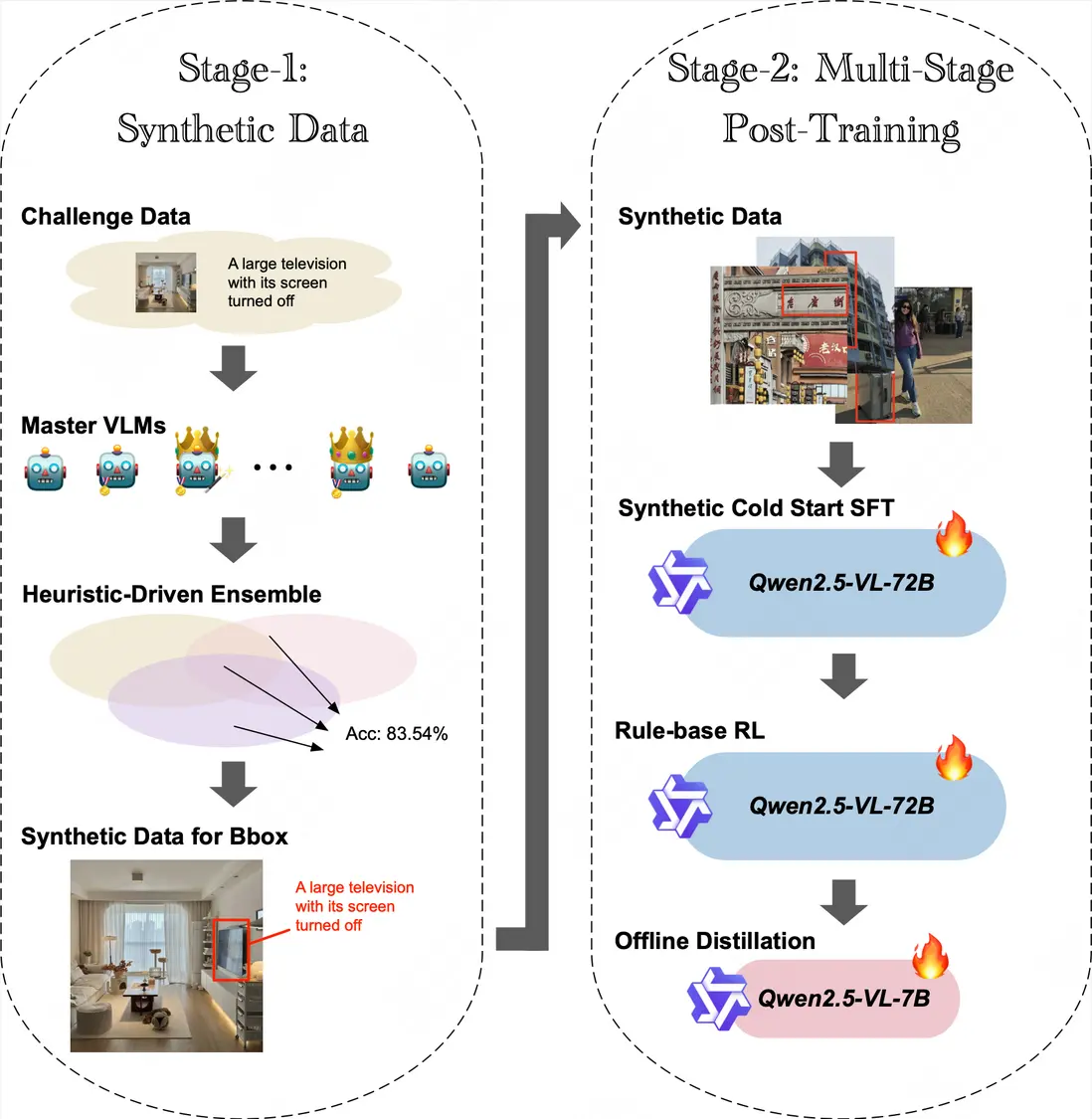
解決方案簡介 | 我們提出了一種結合信噪比驅動數據合成、多階段對齊與強化訓練的視覺定位框架VG-SMART。具體而言:
- 首先通過精心調優prompt提升SOTA模型在該任務上的表現, 並集成多個SOTA模型結果合成初始數據集;
- 隨後在初始數據集上為每條數據採樣計算pass rate,並基於自定義信噪比(SNR)指標對數據進行嚴格篩選構建有難度的高質量合成數據集;
- 然後基於高質量的合成數據集進行Qwen2.5-VL-72B-Instruct的多階段訓練,包含監督微調(SFT)階段和採用IoU中心獎勵函數的強化學習(RL)階段;
- 最終我們將訓練好的Qwen2.5-VL-72B-Instruct蒸餾至Qwen2.5-VL-7B,在保持性能的同時優化了推理速度,在排行榜上以0.6671分獲得第一名。
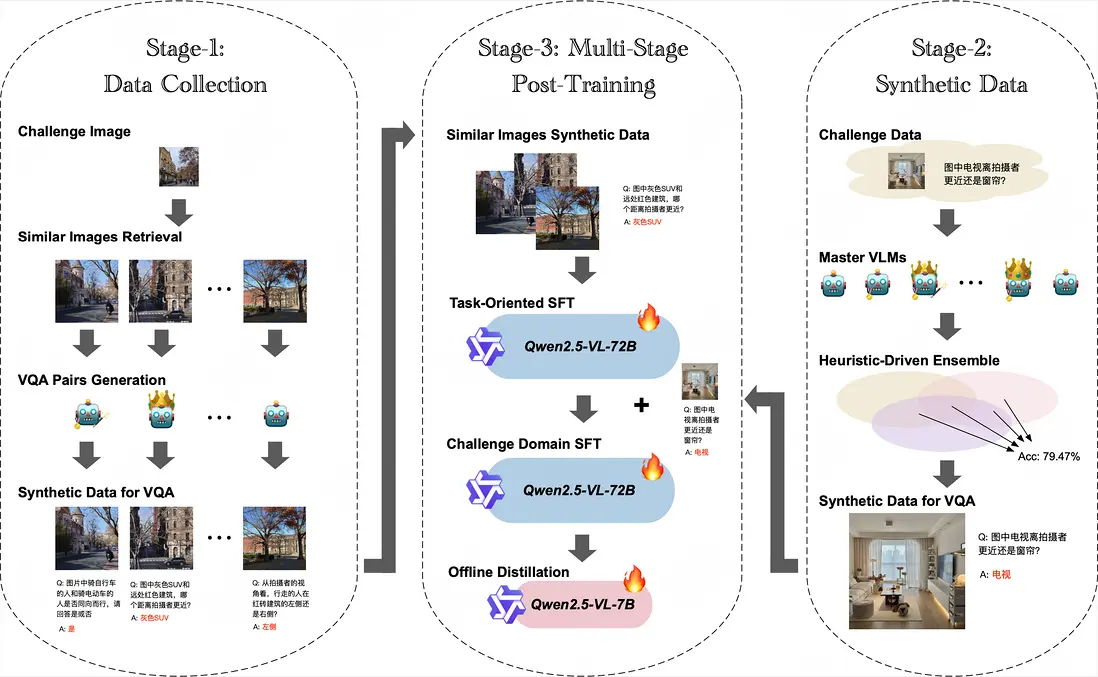
賽題2:空間感知視覺問答(VQA-SA)
解決方案簡介 | 我們提出了一種適合多模態VQA任務的多階段數據合成與訓練框架STAGES,具體包括:
- 首先以無答案的比賽圖片為種子利用圖搜工具檢索與比賽數據相似的圖片,並參考比賽數據集形式,精心調優prompt,利用LLM和LVLMs合成80萬類似VQA數據;
- 然後在這80萬合成數據上對Qwen2.5-VL-72B-Instruct進行第一階段SFT,顯著提升了模型在該類任務的表現;
- 接着在無答案比賽數據集上,我們進一步精調多個SOTA模型prompt,並以集成方式合成出少量高置信的比賽數據樣本,之後使用這批合成數據對Qwen2.5-VL-72B-Instruct進行第二階段SFT,進一步提升了模型在比賽數據上的表現;
- 最終我們將訓練好的Qwen2.5-VL-72B-Instruct蒸餾至Qwen2.5-VL-7B,在保持性能的同時優化了推理速度,在排行榜上以0.6972分獲得第三名。
賽題3:創意廣告視頻視覺推理(VR-Ads)
解決方案簡介 | 我們提出了面向創意廣告視頻的測試時策略調優與自適應推理方法T-STAR,該方案聚焦於優化Qwen2.5-VL-72B-Instruct的推理策略,通過精細調節關鍵推理參數來最大化模型在該複雜任務中的固有推理能力。具體方法:
- 首先對視頻採樣幀率和圖像分辨率進行了系統實驗,探索視覺信息密度與處理效率之間的權衡;
- 在此基礎上,我們疊加了約束性拒絕採樣策略,確保輸出簡潔且符合任務要求;
- 最終,我們以Test-time scaling方式,使用Qwen2.5-VL-72B-Instruct以0.53分在最終排行榜上位列第三。
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明“內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。

