

過去三十年,OLAP 引擎的發展核心始終圍繞結構化數據的處理與分析,當然也取得了顯著的進步,比如分佈式架構、存算分離及 cloud native、查詢性能大幅提升等。然而,隨着大模型(LLM)技術的爆發,數據分析的範式正在發生根本性重構。行業預測顯示,未來五年內,非結構化數據(文本、圖像、音視頻等)在企業數據資產中的佔比將達到 80%。
未來的數據形態將趨於多模態,分析需求將更加複雜,查詢方式也將從單一的 SQL 轉向自然語言與多模態混合檢索。因此,我們需要在現代大數據分析平台基礎上,全面擁抱 AI,構建下一代 AI-First Lakehouse。
一、基礎設施演進:異構融合的存儲與計算層
1. 存儲層統一:管理多模態數據
目前大數據體系與 AI 體系存在嚴重的物理與邏輯割裂。
大數據團隊習慣維護基於 Hive、OLAP、Lakehouse 等大數據平台來處理分析結構化數據,也誕生出業界主流的存儲格式如 Parquet、ORC 等,能很好的支持結構化數據分析需求。
而 AI 團隊習慣在單機服務器或配備獨立顯卡的個人電腦(Laptop)上開發調試,數據以本地文件形式散落。
這種割裂導致數據無法統一存儲,治理困難,且跨系統調用的性能極低,需先查數據庫再調 AI 模型。
但大數據時代的存儲格式如 Parquet 的 Row Group 設計專為結構化數據優化,不再適配 AI 場景,AI 場景非結構化數據異構特性明顯,同一批數據裏,部分字段內容小,部分 embedding 後的字段會很大。
為此,可以考慮引入如 Lance 等專為 AI 設計的存儲引擎,支持對文本、圖像、視頻等多模態數據的高效索引與存取。以實現統一管理分散在各處的非結構化數據,使得 Lakehouse 不僅是數據存儲庫,更是 AI 資產的統一底座。
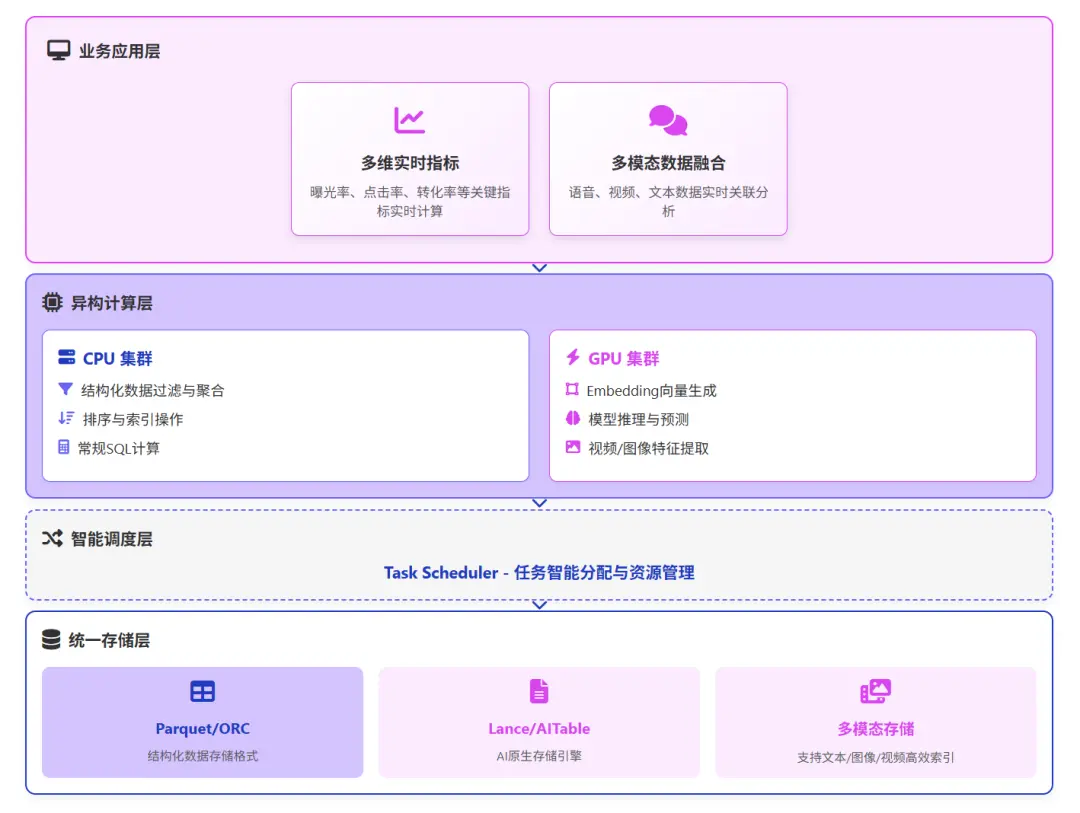
2. CPU/GPU 異構計算統一調度
傳統 OLAP 依賴 CPU 進行聚合、排序與過濾,而 AI 負載(如 Embedding 生成、非結構化數據解析、模型推理)高度依賴 GPU 資源。
計算引擎需從單一的 CPU 架構向 CPU/GPU 異構架構演進。系統應具備智能調度能力,根據任務類型自動分配計算資源,實現結構化查詢與非結構化推理的混合執行。
典型場景:直播電商實時分析
單場直播會上架數十至上百個商品,每個商品展示時長僅 1-2 分鐘。系統需同時處理兩類數據:
- 結構化計算(CPU):五維四率數據(曝光進房率、商品曝光率、商品點擊率、成交轉化率)等實時指標;
- 非結構化計算(GPU):主播語音講解分析、主播商品展示視頻分析、助播互動表現、用户彈幕評論分析
業務方需要將“點擊率”與“主播當時説了什麼/做了什麼”進行關聯分析,以判斷推薦是否精準,以及多種因素對成單的影響。
這要求計算引擎具備異構資源管理能力,能夠靈活調度 CPU 處理統計指標,調度 GPU 處理特徵提取與推理,實現多模態數據的實時融合計算。實時融合計算。
二、內核能力構建:AI 原生的查詢與 In-Database 推理
1. 原生向量檢索,從外掛到內核的能力下沉
簡單的語義檢索已無法滿足高精度的業務需求,且外掛式的向量庫方案會導致數據冗餘與延遲,向量能力已經是多模態處理的必備項(Must-have)。
同時引擎內核需要原生支持混合檢索,並具備混合召回能力,結合關鍵詞匹配(通過倒排索引實現)與語義檢索(通過向量檢索實現),通過粗排與精排的組合策略,滿足如“搜合同關鍵條款”、“電商以圖搜圖”、“在線教育以圖搜題”等高精度業務需求。
更進一步,隨着越來越多不同類型、不同領域、不同維度的數據攝入 Lakehouse,內嵌知識圖譜搜索能力也變得越來越重要,以便高效快捷的挖掘數據之間的關係。
2. In-Database AI ,寫入即處理,查詢即分析
(1)寫入時處理
傳統架構中,非結構化數據的 ETL 依賴外部腳本或獨立工具鏈,維護成本高且容易形成數據孤島。
下一代系統應將 AI 能力內置於寫入路徑,系統自動調用內核級的解析(Parse)、分塊(Chunking)、向量化(Embedding),實現從原始非結構化文件到可查詢數據資產的自動化轉換,無需人工深度介入即可完成打標與關聯。
(2)查詢時推理
將 LLM 能力內嵌至數據庫內核,實現“查詢即分析”。用户無需將數據導出至外部模型處理,而是直接在 SQL 中調用 AI 函數。
還是以直播評論分析為例,系統應能直接通過 SQL 調用內置 AI 能力,對海量彈幕進行情感分析,如:
- 自動過濾“扣 1”、“扣 2”等無意義評論;
- 識別具有購買意向的負面/正面反饋,甚至觸發內置 Chatbot 進行自動回覆;
相比調用外部 API,內置推理可利用本地數據過濾機制,僅對篩選後的高價值數據進行推理,大幅降低延遲與成本,並提升吞吐量。
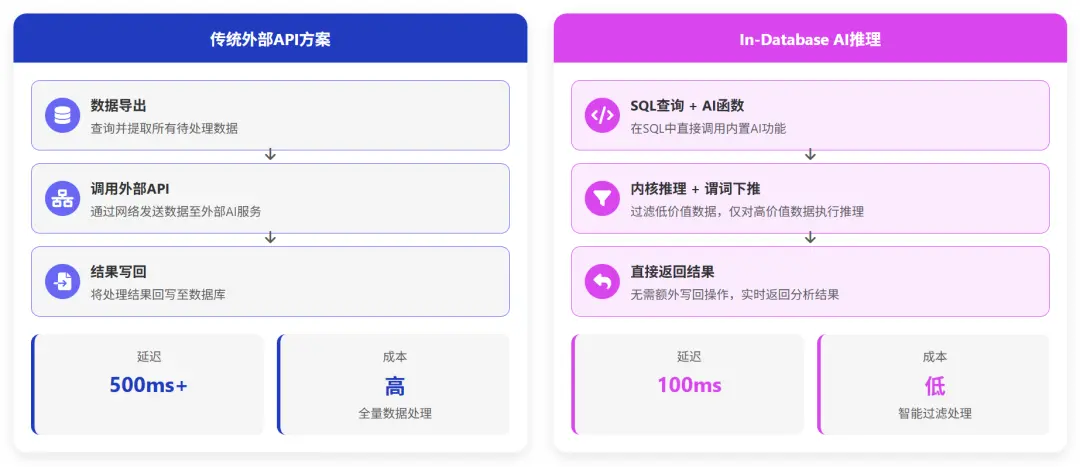
將 AI 能力貫穿寫入和查詢全流程,讓數據處理成為數據庫的內置本能。這種架構下,數據從接入到分析的每個環節都被 AI 增強,消解了傳統“先存儲、後處理”模式的滯後性,使數據在落盤時即具備智能檢索和分析能力。
三、面向 Agent 架構適配:從確定性查詢到探索式執行
隨着 AI Agent 應用的普及,數據交互模式將從“確定性查詢”轉向“探索式執行”。Agent 具有多輪推理、自我修正及高併發的特點,這對底層系統提出了新要求:
1. 極致彈性與高併發
Agent 通過多輪推理、自我修正來完成任務,且存在 Multi-Agent 場景,這將導致會產生海量、突發性的查詢請求。系統需要具備毫秒級的彈性伸縮能力,支持多路 Agent 併發協作,來實現計算資源的即用即取與成本隔離。
2. 高效智能元數據管理
Agent 會頻繁探索數據的 Schema 信息以理解數據結構,系統需提供高性能元數據管理服務,快速響應 Schema 查詢。同時在查詢元數據時除了常規的庫表結構信息外,還應包含豐富的語義數據。
另外,不同於精確的 SQL,Agent 生成的查詢往往很模糊。執行引擎需要支持描述性約束信息(例如,Agent 指令包含“精度要求>80%”或“查詢超時<2 秒”),可以根據約束動態調整策略,允許在精度與資源消耗之間做權衡,而非僵硬地執行全量掃描。
四、平台自治:AI 反哺系統的自我進化
在基礎層、內核層、以及架構層升級後,還可以思考進一步利用 AI 技術反哺 Lakehouse 自身的魯棒性與性能。
- 學習最佳實踐: 系統應自動學習內部海量日誌中的 Best Practice,將其內化為引擎的管理能力。
- 智能故障排查: 利用 AI 自動定位數據庫運行中的隱性問題,替代人工排查。
智能物化視圖(Auto-MV)加速洞察
目前的物化視圖依賴業務方手動創建,門檻較高。未來系統將結合慢查詢分析與數據量特徵,自動識別性能瓶頸,同時,學習用户的查詢行為,自動創建並維護物化視圖,從底層透明地加速查詢響應,無需用户感知。
流暢開發:避免複雜的 UDF 依賴
對於複雜的業務邏輯與非結構化數據處理,不應強行依賴傳統的 UDF,而應通過上述的內核級 AI 能力與開放接口來解決,提供更流暢的開發體驗。
結語
下一代 AI-first Lakehouse 的構建是一個系統性工程,需要從數據處理、存儲引擎、計算架構、Agent 支持以及平台生態進行全方位升級。核心目標是打破結構化與非結構化數據的壁壘,將 AI 能力從應用層下沉至內核層,構建真正面向 AI 時代的新一代數據平台。