









圖片來自:https://bz.zzzmh.cn/
本文作者: cgt
背景: 如何解耦大前端與服務端的適配層依賴
談到 BFF,相信大家都不會太陌生,過去在雲音樂,前後端的協作架構一直維持比較傳統的前後端協作模式。各個端所需要的接口完全依賴服務端提供,服務端同學除了需要完成微服務的業務邏輯外,還需要針對前端頁面調度各個領域的微服務,根據前端的數據訴求進行一定程度的組裝和適配。
在年初,我們計劃針對雲音樂的P0頁面,個人主頁進行改版,雲音樂的個人主頁聚合了來自各個頁面領域的數據,比如用户個人信息,Mlog,雲圈,K歌等等,這些數據來自於各個不同的服務端團隊。對大前端同學來説,我們期望能通過儘量少的接口調用獲取到這些數據,以保證頁面性能,同時,我們期望獲取的數據接口能和頁面 UI 高度適配,不需要在端上進行太多的數據轉換。因此,服務端同學為我們抽離了一層獨立的中間服務,負責聚合各個業務的接口數據,同時,我們需要各個業務服務端將業務領域的 DTO 轉換為 VO,保證能和 UI 進行適配。
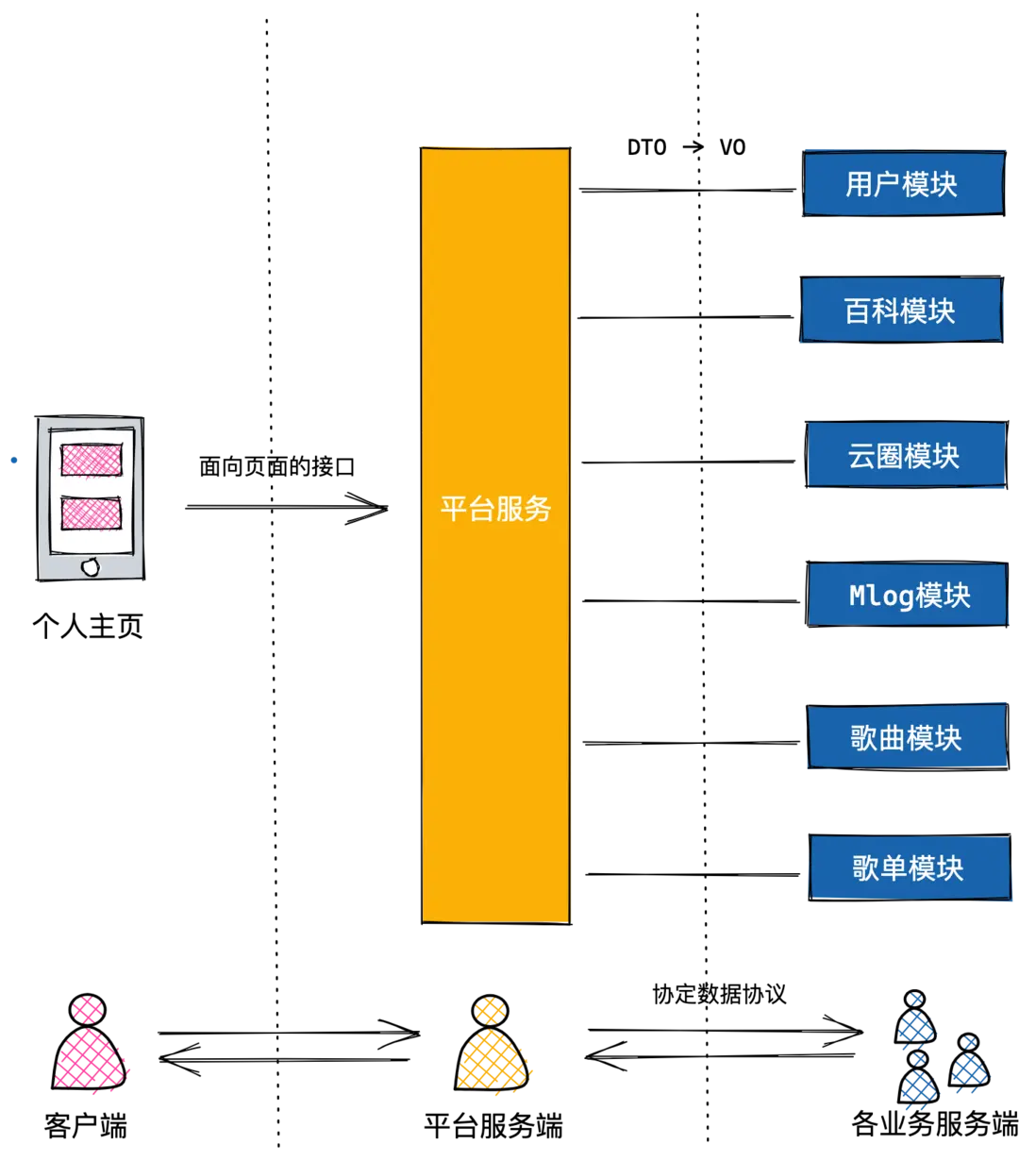
在改版過程中,我們發現了這個模式的一些問題:
- 大前端所需接口的契約定義,對服務端有深度依賴,很多時候一個頁面字段的變更就需要平台服務端以及業務服務端進行評估和排期,由於職能差異,中間會產生大量的溝通成本。
- 由於前端UI的多變性,各個業務服務端針對該場景提供的接口,很難具備複用性,一旦更換了其他場景,服務端同學又不得不封裝新的接口。
而針對這些問題,我們發現業界其實已經給出了比較成熟的解決方案,就是通過在架構上引入 BFF 層。
BFF 的全稱是「Backend For Frontend」,顧名思義就是面向前端的後端。它的主要職責就是針對頁面的數據訴求,進行微服務的調度以及數據的組裝和適配,這一部分原先我們通過微服務去完成,但現在它從微服務拆解出來得到了獨立。
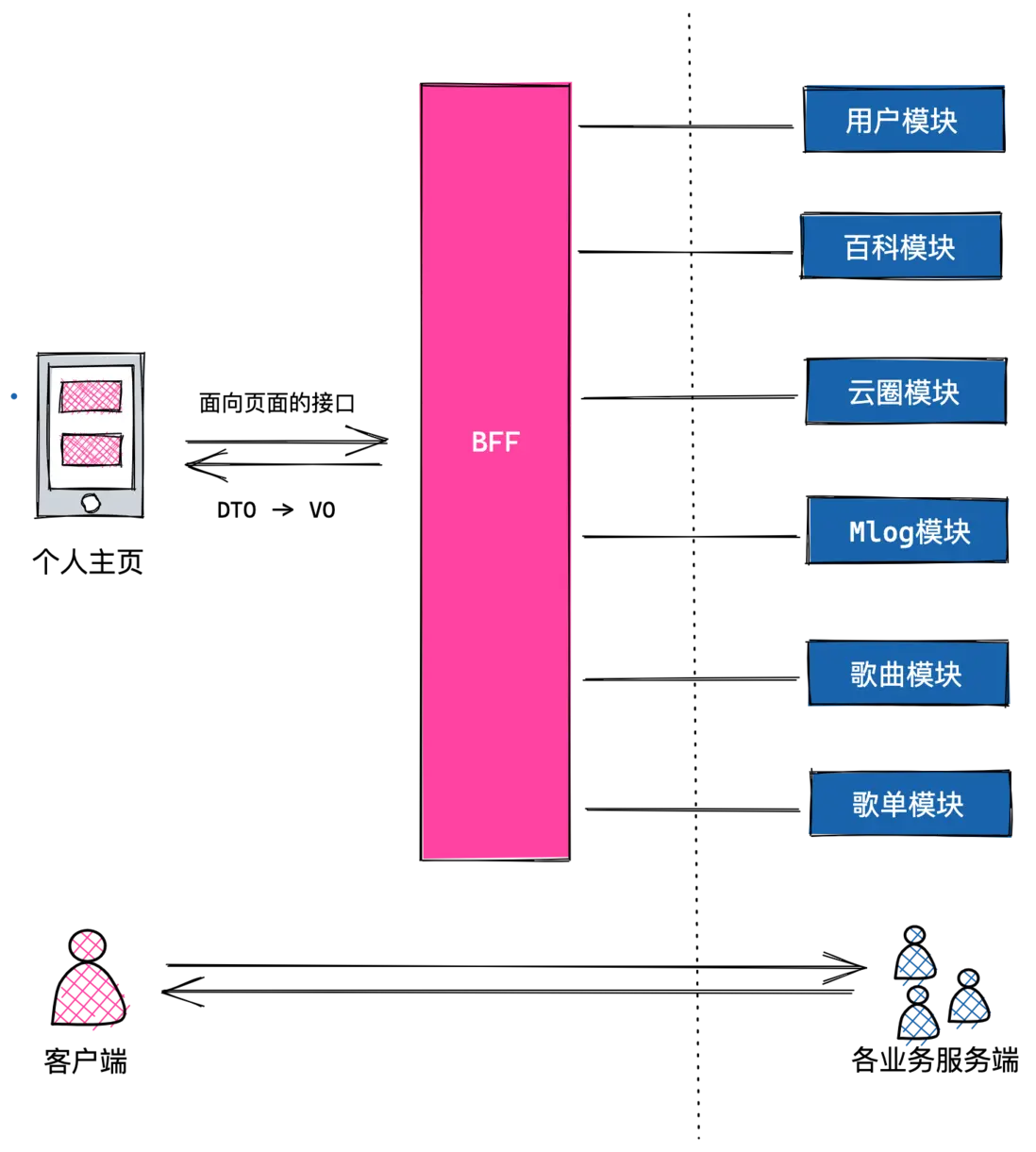
在 BFF 的架構裏,我們不再需要平台服務端為我們提供數據聚合,這解決了我們之前提到的問題:
- 大前端同學可以開始自行完成這一層的數據組裝工作,從而與服務端在適配層完成解耦,大部分字段的變更都可以由前端同學閉環完成,再沒有大量的溝通成本。
- 服務端同學無須再進行從 DTO 到 VO 的數據轉換,從而可以提供複用性更強的接口,微服務的職責也會更加明確。
在雲音樂,存在大量類似的場景,我們期望在這些場景下都能落地 BFF 架構,最終,隨着可複用接口的沉澱,以及溝通成本的降低,可以幫助我們提升整體的業務吞吐量。
那麼,問題來了,如何在大量類似的場景中,讓大前端同學來承接 BFF 層呢?
為什麼我們選擇GraphQL?
Faas VS GraphQL
目前業界比較主流的兩種 BFF 實現方案。
首先是基於 NodeJS + Faas 的形式,這種模式是基於大部分 Web 前端同學對 NodeJS 有一定基礎,可以快速上手,同時它的編排非常靈活,基本能滿足所有 BFF 訴求,甚至能超出 BFF 的邊界,最初,我們也期望依靠這種模式落地 BFF ,但很快,我們就發現這種模式面臨的一些挑戰:
- 基礎建設要求高:這種模式對團隊的 Node 基礎設施和雲原生基礎設施有一定要求,畢竟掌握 NodeJS 開發是一方面,針對服務的監控,運維,部署,線上問題調試都需要有對應的解決方案,並且我們需要保證這些保障能覆蓋到所有 NodeJS 服務
- 存在一定學習成本:除去 Web 前端的同學,對原生客户端的同學來説,儘管 NodeJS 比較輕量,也是一門全新的語言。
第二種方式就是我們今天要聊的基於 GraphQL 的模式,GraphQL 定義來一套用於 API 的查詢語言,開發者甚於可以通過一些低代碼的編排快速完成查詢語言的定義,這給我們帶來了以下優勢:
- 與技術棧解耦:開發者只需要認知 GraphQL 的 DSL,而不用再多學習一門語言,而 GraphQL 的 DSL 相對來説要好上手得多。
- 複雜度更加可控:我們可以統一實現 GraphQL 的執行引擎,開發者全部基於我們的引擎服務執行查詢,能夠自定義的僅僅是數據圖以及查詢語句,從而我們可以將服務開發的一些最佳實踐附着到引擎上面。
什麼是GraphQL?
好,那到底什麼是 GraphQL 呢?
GraphQL 總體分成兩部分:
- 一套用於 API 的查詢 DSL:也可以稱為 GraphQL 語句,你可以在這套 DSL 中描述你的查詢所需要的字段,以及需要調用的接口,所需傳遞的參數等等。
- 一個基於圖狀數據的服務端運行時:來執行這套查詢 DSL,它的執行邏輯就是從一張完整的數據圖上,根據 GraphQL 語句的描述找到需要的節點,調度涉及的接口,最後返回符合查詢語句的數據。

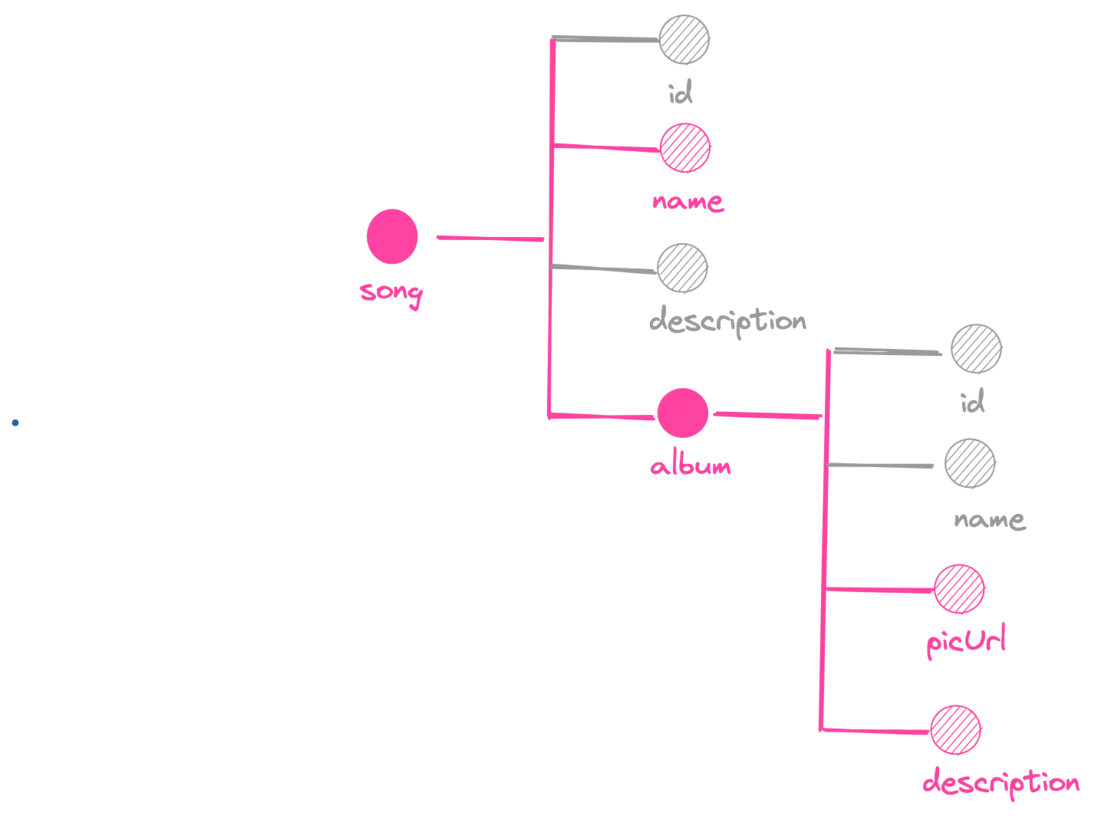
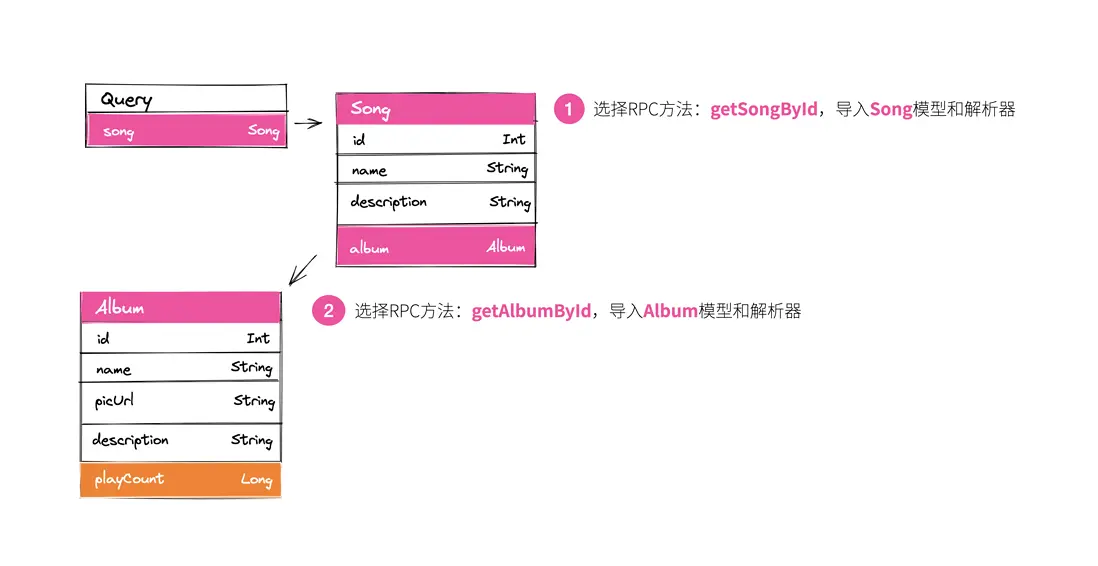
比如:在上圖展示的案例中,我們在(圖左)編寫了查詢語句,(圖右)則是引擎執行該查詢語句後,在數據圖上命中的節點。
可以看出,落地 GraphQL 的關鍵就在於實現它的服務端運行時,而 GraphQL 的運行時整體也可以拆解為三個部分:
- GraphQL 引擎:解析 GraphQL 語句,目前社區已經提供了各個開源版本的 GraphQL 引擎,包括 NodeJS,Java,Python 等等,我們選定適合自己的版本即可。
- 類型定義:GraphQL 的類型系統其實和其他類型系統大同小異,GraphQL 提供了一些基礎標量,你可以在這些基礎標量的基礎上不斷擴展自己的業務模型,最終生成圖狀數據結構。
- 解析器:我們需要描述這些類型節點所需要執行的查詢,當然,並不是所有的節點都需要執行查詢,我們只需要保證查詢的結果和節點的類型定義一致即可。比如在上圖的節點中,我們分別給 song 節點和 album 節點執行了一次查詢,他們會調獲取歌曲詳情以及獲取專輯詳情的 RPC 接口返回相應的數據。
如何在雲音樂落地?
在瞭解 GraphQL 的運行機制後,我們開始考慮如何在雲音樂進行落地,在進行方案設計的階段,我們提出了一些問題:
- 我們如何讓大前端同學能夠搭建穩定可靠的 GraphQL 運行時?大部分大前端同學並不具備服務端開發經驗,對服務的開發,部署,運維基本一無所知,從零開始搭建 GraphQL 運行時會帶來巨大的操作成本
- 如何快速上手 GraphQL 語句?儘管 GraphQL 語句上手並不複雜,但它本身不在前端同學的知識體系內,上手依然存在一定的學習成本。
- 如何與雲音樂現有研發體系的對接?
- 如何儘可能擴大 GraphQL 的邊界?
針對前兩個問題,我們想到可以通過低代碼的方式進行 GraphQL 的應用研發,低代碼可以説是當前業界非常流行的,一種可以打破職能邊界的手段,很多團隊通過低代碼讓服務端同學具備了搭建前端頁面的能力。那麼反過來思考,前端同學同樣可以通過低代碼從而具備編排服務端邏輯的能力。考慮到這個方向後,我們發現 GraphQL 天然就非常適合採用低代碼的形式進行搭建,其 DSL 的設計可以方便地轉換成結構化的數據,從而映射成界面的操作。
針對第三個問題,GraphQL 應用應該具備和雲音樂常規應用一致的發佈流程管控,避免無序發佈導致的線上事故,我們通過 Git 倉庫對 GraphQL 應用的語句,類型定義,解析器進行管理,並融入雲音樂前端研發平台 Febase 進行發佈流程的管控。
最後一個問題,我們希望 GraphQL 能解決至少 70% 的 BFF 編排場景,如果僅僅依賴其自身的能力,會導致落地場景受限而意義不大,因此我們基於 GraphQL 的指令機制,對 GraphQL 的能力進行了擴展,從而能應對更多的場景。
分佈式的架構設計
我們整體採用了分佈式的架構設計:
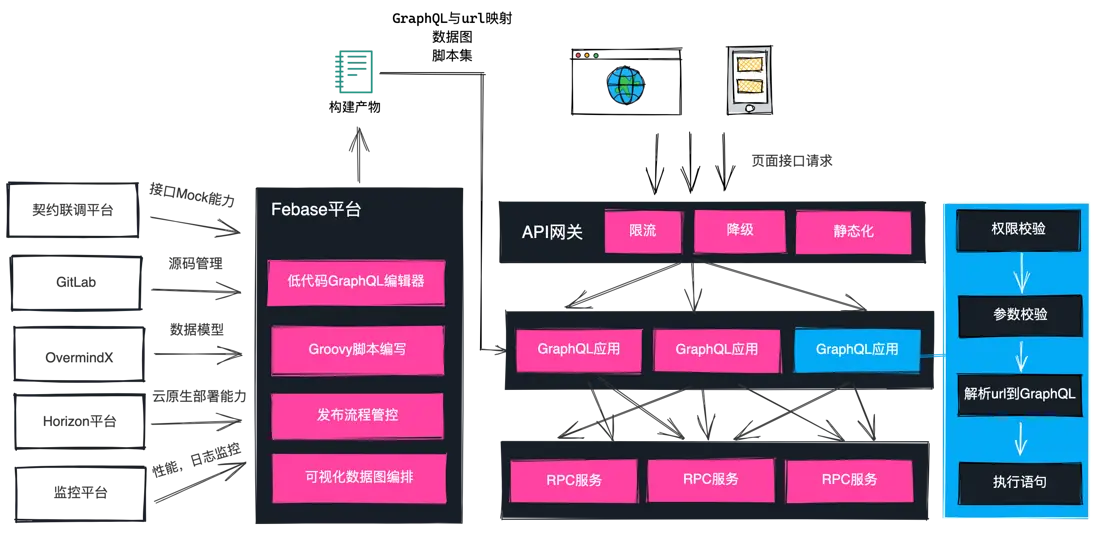
從流量走向上看,前端依然通過 Restful 請求獲取頁面所需要的數據,這樣做的目的是我們的所有請求依然可以依賴雲音樂的通用 API 網關,具備流量控制,異常降級,靜態化的能力,從而極大地提升了接口穩定性。
而當請求通過 API 網關後,會轉發到 GraphQL 應用所在的集羣,GraphQL 應用的內置引擎會將接口 URL 轉換成 GraphQL 語句,從而執行 GraphQL 語句,調度服務端 RPC 接口進行數據組裝,最終返回頁面需要的數據。
我們會為每一個 GraphQL 應用分配獨立的雲原生容器,依託於雲音樂雲原生的基礎建設,我們可以靈活安排每一個 GraphQL 應用所需要的 Pod 數量,甚至能根據 CPU 進行容量的擴縮,從而減輕前端同學的運維負擔。
在 Febase 平台,我們提供了低代碼的 GraphQL 編輯器,Groovy 腳本的編寫能力,發佈流程的管控,可視化的數據圖編排能力,最終基於這些能力,平台能夠輸出一份 GraphQL 應用配置,這份配置的內容包括:
- 從 URL 到 GraphQL 語句的映射關係
- 執行查詢語句所需要的數據圖
- 查詢節點的解析器配置
引擎通過監聽 zookeeper 拿到這份配置,並進行更新,這個過程就是 GraphQL 應用的部署過程,由於整個部署過程不會涉及到服務的重啓,僅僅是一次配置文件的熱更新,所以它的日常發佈也會非常快捷,幾秒就能完成,進一步提升我們的研發效率。
在這些基礎能力之外,我們也和雲音樂的一些基礎設施平台進行了打通。比如:
- 通過 Mock 平台,我們允許開發者自由配置接口的 Mock 數據,只需要在請求頭中加入一個標誌位,就可以讓請求走 Mock 鏈路。
- 所有 GraphQL 語句,數據圖,腳本都會保存在 Gitlab 進行管理,通過分支進行編輯。
- 雲音樂的契約管理平台為我們提供了 Java 服務端 RPC 的數據模型,使得我們可以以近乎零成本的方式來構建數據圖。
- 基於 Serverless 進行應用容器的部署,保證我們的服務可以靈活地擴容縮容。
- 打通了性能,日誌等各類服務監控平台,具備完備的服務運維能力。
基於契約快速構建GraphQL Schema
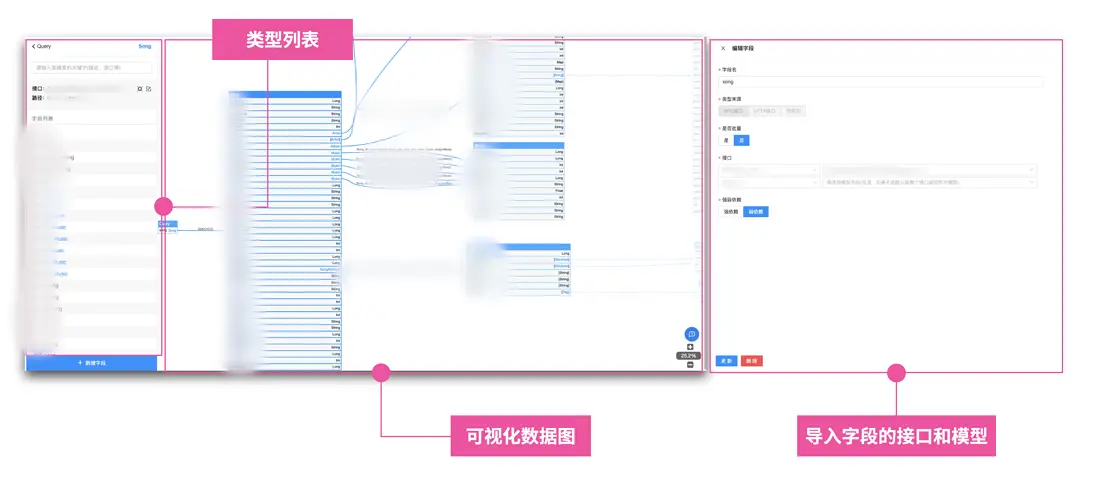
在瞭解我們的整體架構後,我們繼續來看看 Febase 是如何以近乎零成本的方式構建 GraphQL 的數據圖的。下面是一張非常簡單數據圖的構建過程,GraphQL 構建數據圖的方式就是從根節點出發,錄入字段以及字段對應的模型,並且我們可以在任意模型下插入新的字段,並定義該字段的模型。在插入字段的時候,我們需要定義字段對應的解析器,也就是該如何獲取到字段對應的數據。
我們發現,在傳統的 GraphQL 數據圖編排中,開發者需要自行定義模型和解析器,而事實上大部分時候,這個過程只是在搬運服務端的模型定義。因此在這裏我們約定了解析器做的事情僅僅只是調用服務端的 RPC 接口,那麼只要開發者選定 RPC 接口,我們就可以根據其響應的元信息拉取到服務端的數據模型,從而建立數據圖。
比如在上面的例子裏,當我們要導入 song 這個字段時,系統實際上是在倉庫的約定路徑下建立了兩份文件:
resolver.json:描述引擎該如何調用接口,比如 RPC 接口的類名,方法名等等type.schema:保存根據接口響應生成的 GraphQL 模型信息
下面是一份最簡易的 resolver.json 示例:
{
"type": "rpc", // 調用的協議類型
"clzName": "com.netease.music.api.SongService", // RPC 類名
"methodName": "getSongById", // RPC方法
"params": [] // RPC參數類型列表
}type.schema 其實就是 GraphQL 的模型定義:
type Query {
song: Song
}
type Song {
id: ID
name: String
}那麼,我們是如何生成這份模型信息的呢?
通過研究 GraphQL 的引擎源碼,我們發現,GraphQL 的模型定義,其實可以通過官方引擎提供的內置方法,等價轉換稱一份標準的 JSON 結構。那麼,相對於生成模型定義的源碼,生成這份 JSON 結構要簡單得多,比如,上文提到的 Song 模型,就可以進行如下轉換:
import { introspectionFromSchema, buildSchema } from 'graphql';
const schema = introspectionFromSchema(buildSchema(schema));轉換後可以生成如下結構:
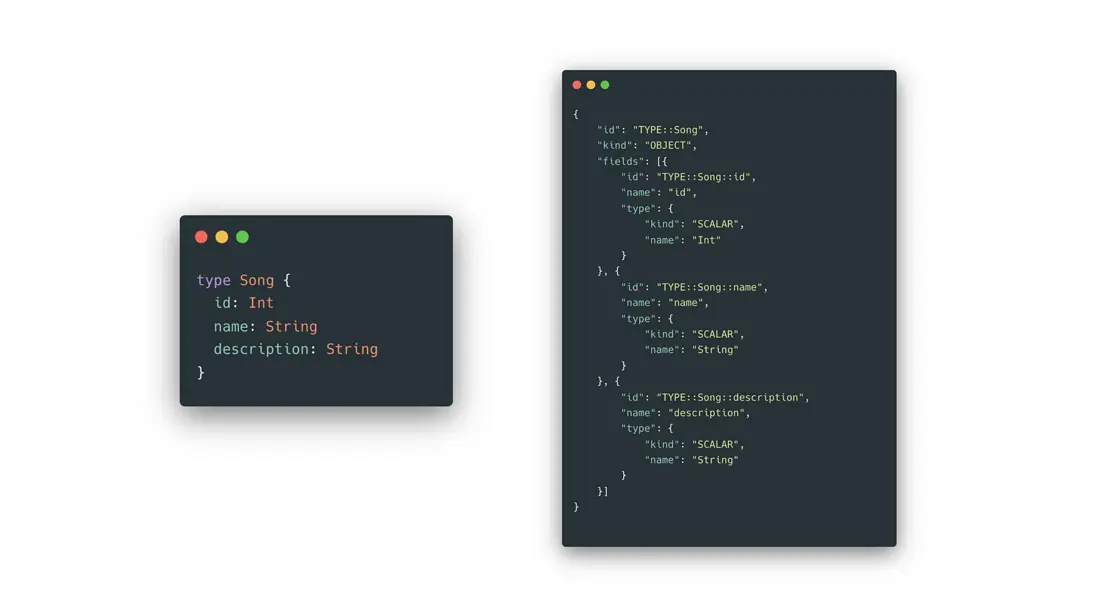
而在雲音樂,所有服務端的接口模型定義都會維護在雲音樂的契約管理平台,同樣具備一份 JSON 結構來描述。
<img src="https://p6.music.126.net/obj/wonDlsKUwrLClGjCm8Kx/23211534140/88f9/7d3c/9211/bb2d1ec275ba645f82ad16211e802b9b.png" width="40%"/>
這兩份數據在邏輯上幾乎完全等價,我們編寫了一個轉換器,定義一些從 Java 類型到 GraphQL 類型的映射關係,即可完成轉換,最終生成 GraphQL 需要的類型定義,並保存在我們的 Git 倉庫中。
在數據圖的展示上,我們直接採用了 graphql-voyager 這個開源庫,通過一些擴展讓其具備了字段編輯能力,字段搜索等開發過程中經常要用到的一些能力。
基於AST打造LowCode GraphQL編輯模式
有了類型定義之後,接下來,我們就開始考慮如何編寫 GraphQL 語句了,下圖是我們的編輯界面。
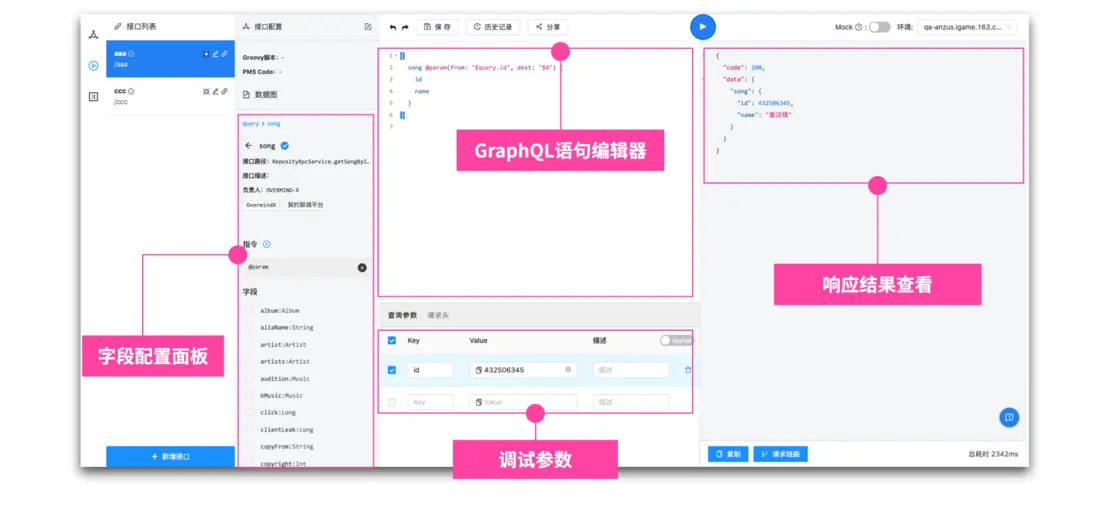
編輯器採用的實際是 LowCode 和 ProCode 雙重模式,大部分時候,開發者只需要進行字段的篩選,以及一些指令表單的配置,即可完成 GraphQL 語句的編輯。
那麼,我們是如何實現這一效果的呢?
GraphQL 官方提供了語句編輯器 graphiql 已經非常強大,提供了語法提示,錯誤校驗,語句調試等基本能力。但為了在團隊內部大規模推廣,這樣的使用方式還是相對來説比較原始,我們需要進一步降低開發者的使用成本,提供 LowCode 的編輯模式。
這裏我們就會提到為什麼説 GraphQL 天然適合 LowCode 的編輯模式,我們知道,所有低代碼編輯模式都需要定義一套標準協議,而界面的大部分操作都可以映射成對該協議的操作變更。
而針對一段 GraphQL 語句,通過官方引擎提供的內置方法,我們可以輕鬆獲取到它的 AST 結構,並且這段 AST 結構非常容易閲讀和理解:
{
song @param(from: "$query.id") {
name
}
}通過調用轉換方法,可以得到如下結構:
import { parse } from 'graphql';
const ast = parse(query); 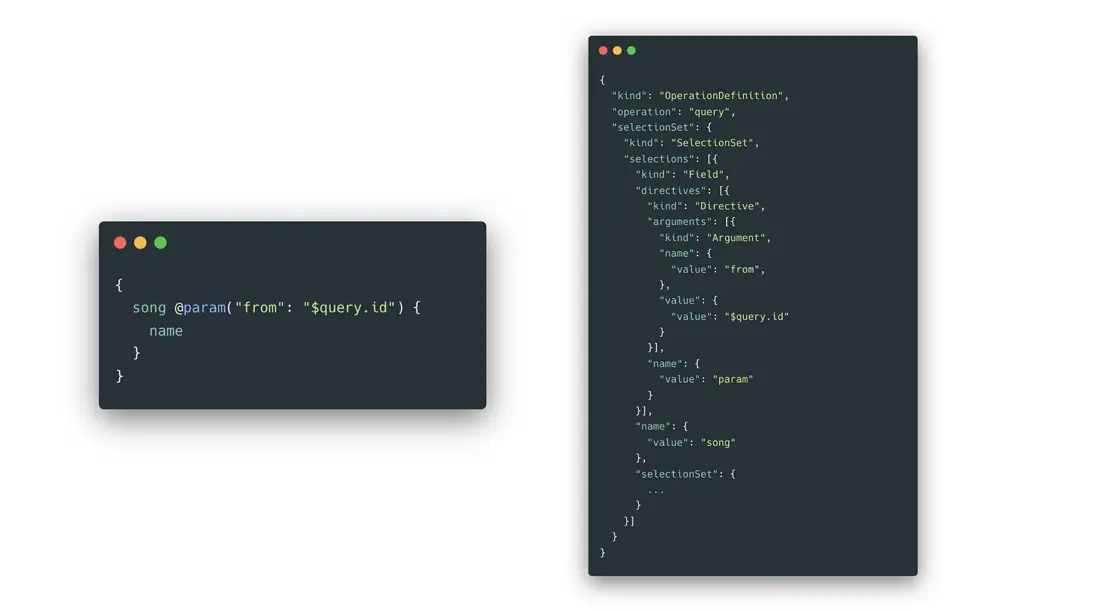
針對這部分結構,我們可以和界面建立映射關係,比如當我們通過對數據圖文檔進行字段勾選時,實際是生成相應的 selection 結構,並將其插入到指定路徑的 selections 中。而當我們通過表單配置指令時,修改的就是相應路徑的 directives 結構。
並且由於我們操作的是 AST 本身,所以開發者同樣可以自行進行 GraphQL 語句的編寫,語句的變更同樣能夠在操作面板體現出來。
除去低代碼編輯能力外,編輯器還提供了一些輔助功能,這些功能可以讓 GraphQL 接口的開發更加流暢便利,比如:
- 自動生成接口文檔 :GraphQL 的查詢結果屬於數據圖的子集,這樣我們完全可以根據開發者的 GraphQL 語句生成響應結構,並分析出依賴的參數,從而自動生成接口文檔,讓 GraphQL 接口也能擁有清晰的定義。
- 追溯請求鏈路:在線開發最大的難點就在於問題的定位和調試,為了幫助開發者更輕鬆的定位問題,我們針對線下環境 GraphQL 語句的每一步操作都進行了打點,包括每一次 RPC 調用,腳本執行,並且記錄了每一次操作的輸入和輸出,這樣,開發者在進行了一次查詢後,就可以查看完整的請求鏈路,在請求出錯時進行問題的定位。
基於指令和腳本強化原生GraphQL能力
剛剛我們提到,要用 GraphQL 滿足至少 70% 的 BFF 編排場景,如果只是用開源引擎,我們很快就發現了下面的問題。
第一個問題是,我們如何傳遞複雜的 RPC 參數?在實際的業務場景裏,由於 RPC 和 HTTP 接口已經解耦,我們往往需要通過一些邏輯構造才能構造出 RPC 需要的參數,比如在下面的 RPC 接口:
Class SearchDto {
Integer pageSize;
Integer cursor;
Integer userId; // 需要獲取登陸用户的 uesrId
String search;
}
...
SongService.searchSongByUser(SearchDto params) { ... }這個接口的入參是一個結構化對象,其中其他 3 個參數來源於 HTTP 接口的查詢參數透傳,而 userId 則需要我們從請求的 cookie 中解析出來。
GraphQL 提供了 變量 的機制,用來進行一些參數的透傳,但如果要完成上述的參數構造,它的靈活度是不夠的。
第二個問題是,我們如何對響應結果做更靈活的數據轉換?GraphQL 的響應結果和必須和 Schema 結構保持嚴格一致,雖然我們可以進行一定的字段裁剪和重命名,但針對多樣的頁面,我們需要更加靈活的數據轉換,以便可以複用同一套 Schema 去面對更多場景。
上面兩個問題的共性是, GraphQL 默認的 DSL 表達難以滿足複雜場景的訴求。幸運的是,GraphQL 提供了一種名為指令的擴展機制。指令可以附着在字段或者片段包含的字段上,然後以任何服務端期待的方式來改變查詢的執行,下面是 GraphQL 引擎內置的 @skip 指令的使用示例。
{
song {
name @skip(if: true)
}
}上述指令的含義是,在判斷條件為 true 時,跳過此字段的查詢。
GraphQL 允許我們自定義指令,我們可以在 GraphQL 的解析器中拿到查詢語句附着的指令描述,從而修改執行邏輯來完成指令的實現。
我們針對上面提到的問題提供了兩種自定義指令。
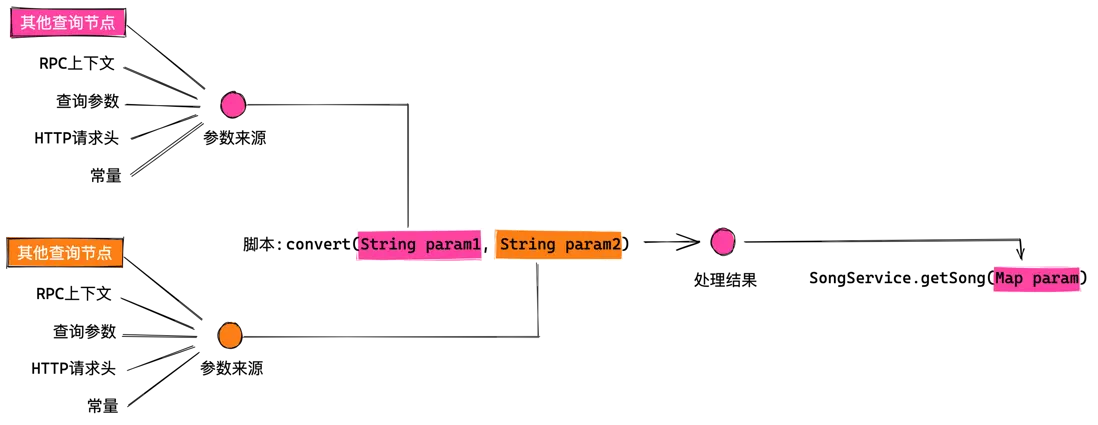
@param指令:傳遞複雜的 RPC 參數
directive @param(
from: String
dest: String
scriptName: String
scriptMethod: String
)@param 指令主要在執行查詢操作之前運行,負責收集參數來源,並將多個參數來源傳入腳本進行處理,最終將處理結果傳遞到 RPC 參數中,它的執行流程如下圖所示:
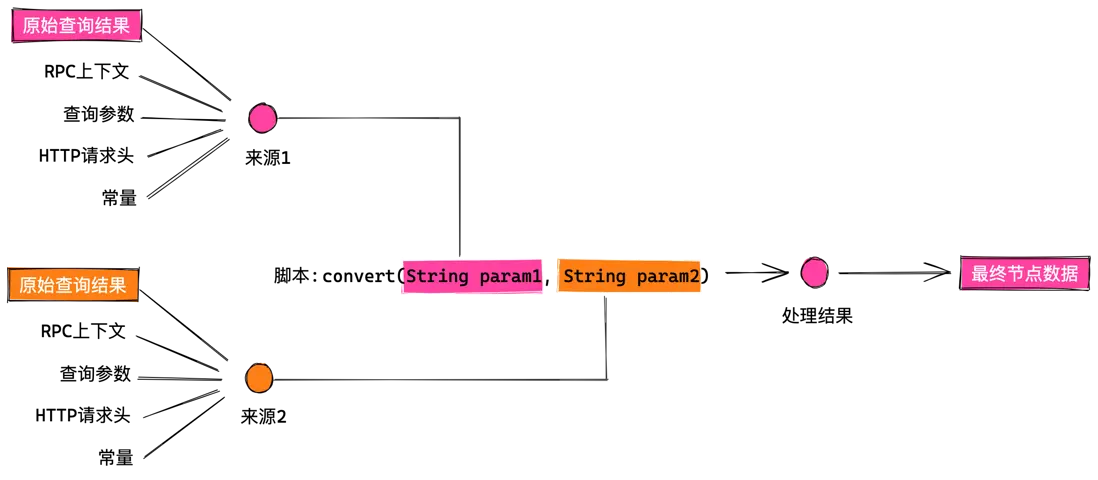
@convert指令:對響應結果做更靈活的數據轉換
directive @convert(
from: String
scriptName: String
scriptMethod: String
)@convert 指令主要在執行查詢操作之後運行,負責收集響應結果,同樣其輸入到腳本進行處理,最終返回通過腳本處理好的結果,它的執行流程如下圖所示:
在擴展了這兩種指令後,開發者可以在查詢操作的前後插入自定義腳本進行參數的構造和響應結果的處理。
我們目前是基於 Java 實現的 GraphQL 引擎,因此腳本語言上採用了 Groovy 語法,儘管不是前端同學熟悉的語言,但處理一些常規的數據轉換邏輯已經綽綽有餘。而在完成這一部分後,我們真正做到了幾乎能覆蓋大部分 BFF 場景。
標準的研發流程管控
我們期望 GraphQL 應用的研發流程應該和普通應用的研發流程一樣,當開發者接到需求時,他需要在平台創建迭代,我們會為它分配分支和環境,當他測試迴歸完成後,需要進行一些卡點,我們會在卡點環節提供一些語法校驗以及變更的 Review,經過卡點流程後,開發者就會進入獨佔的上線通道,完成線上發佈和驗證後,開發者可以一鍵將開發分支合併到 master。
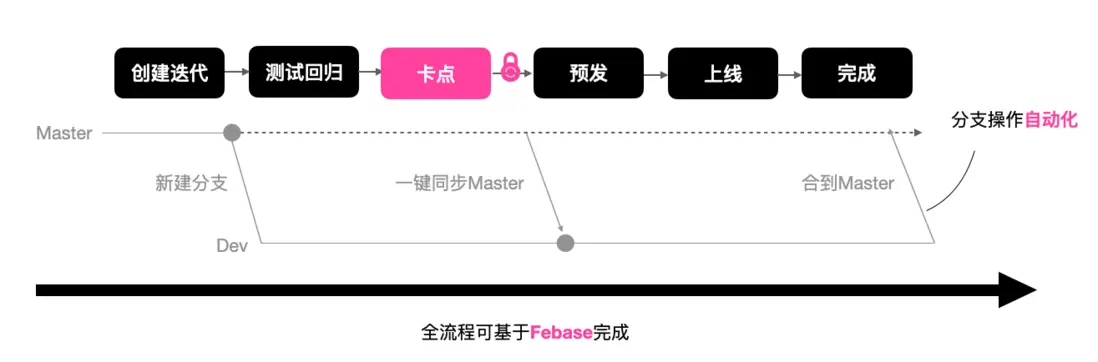
目前在雲音樂,所有前端側的應用研發都遵循這樣一套流程,這套流程極大保證了我們研發過程中的安全性和規範性。針對 GraphQL,我們在應用卡點環節提供了語法校驗,基於 graphql-language-service-interface 提供的 getDiagnostics,可以幫助我們快速定位到錯誤的位置。
const errList = getDiagnostics(query, schema);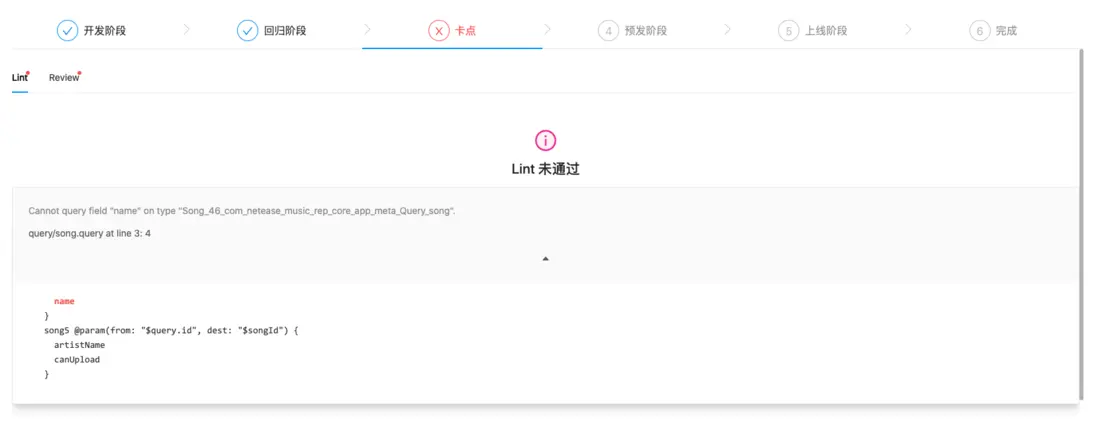
小結
最後,總結一下,在本文中,我們簡單介紹了 GraphQL 以及在雲音樂落地的背景,並且介紹了雲音樂 Febase 平台 GraphQL 研發能力的整體架構設計,一些關鍵模塊(數據圖構造,低代碼 GraphQL 編輯器)的實現思路,以及針對 GraphQL 引擎的擴展設計,GraphQL 應用的研發流程管控。後面我們也會考慮分享更多 GraphQL 引擎的實現細節以及 GraphQL 的應用案例。
目前,基於 GraphQL 的 BFF 研發模式已經在雲音樂實現了半年左右,期間也由大前端同學自主產出了 160+ 的數據接口,其中不乏一些高流量的核心場景。當然,針對 BFF 研發模式,我們確實也還處在起步的探索階段。未來,隨着 GraphQL 接口在雲音樂業務中的覆蓋度越來越高,我們期望能夠從中總結出一些數據圖模型的設計經驗,幫助前後端同學建立更高效的協作關係。
本文發佈自網易雲音樂技術團隊,文章未經授權禁止任何形式的轉載。我們常年招收各類技術崗位,如果你準備換工作,又恰好喜歡雲音樂,那就加入我們 grp.music-fe(at)corp.netease.com!












