









温馨提示:本文共有
8472個字,平均閲讀時間約為34分鐘
大家可以快速查看自己感興趣的內容點擊下面的目錄:
- 模型簡介
- 整體架構
- Encoder結構
- 輸入階段
- 輸入嵌入(Input Embedding)
- 位置編碼(Position Encoding)
- 輸入向量構建
- Attention結構
- 自注意力機制 Self-Attention 和 縮放點積注意力 Scaled Dot-Product Attention
- 第一步 生成QKV
- 第二步 計算注意力分數
- 第三步 縮放與Softmax
- 第四步 加權得到輸出
- 多頭(自)注意力機制 Multi-Head Attention
- 多的“頭”是什麼
- 多頭的作用
- Encoder結構中的多頭注意力的輸出
- 自注意力機制 Self-Attention 和 縮放點積注意力 Scaled Dot-Product Attention
- 殘差連接與層歸一化 Add&Normalize
- 殘差連接
- 層歸一化
- 前饋神經網絡 Feed Forward
- 這一項的意義
- Encoder的流程與訓練
- 輸入階段
- Decoder結構(訓練)
- 輸入階段
- 目標序列的右移
- 掩碼多頭注意力機制
- 掩碼
- 掩碼類型
- 掩碼多頭注意力的輸出
- Decoder的第二個多頭注意力模塊
- Decoder的流程與訓練
- 輸出
- Decoder結構(推理)
- Encoder結構
最近肝大模型綜述和時序transformer相關的工作太多了,回頭看似乎這個最基礎的結構似乎還是有點忘得差不多了,所以抽出一個下午時間簡單地做了一個簡單的模型結構拆分,用了我最通俗的語言進行一個簡單的解釋吧。
模型簡介
作為機器學習領域必讀的經典模型,Transformer模型首次提出於《Atttention is all you need》這篇論文中。
最早應用於NLP領域,作為文字處理任務的一個解決方法。後來被引申應用於圖像、時序等領域,併為大語言模型的構建提供了基礎。
靈感來自於傳統的“電力變壓器”結構(Transformer),不是變形金剛電影(也叫Transformers)
整體架構
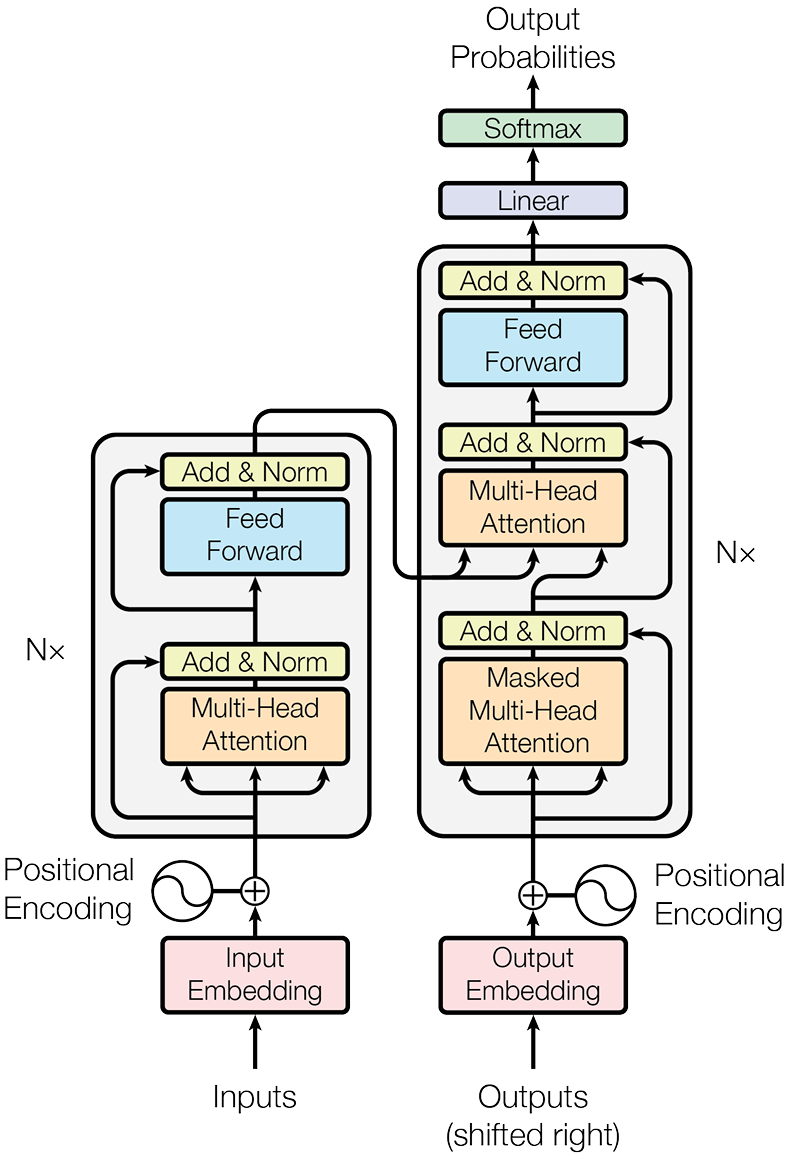
我們首先舉一個例子,我們從整體的流程開始走一遍,從這個過程中瞭解transformer的架構構成。
假如我們的輸入是“我”,“是”, “人”三個漢字,並且想使用它預測我下一個字,我們將這個輸入的一箇中文序列作為輸入X
Encoder結構
Transformer的第一層架構Encoder結構,它的主要任務就是理解我們現在輸入的向量內容,並且將其轉化為一箇中間表示。
輸入階段
輸入嵌入(Input Embedding)
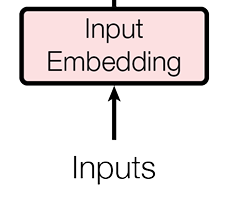
首先第一步,模型無法直接讀取中文,我們首先要將這個中文序列轉換為計算機可以認識的內容,這一步就是輸入嵌入(IE)過程。在這個過程中,模型會使用詞嵌入的方式將序列轉化到一個向量。
通俗理解
transformer翻開詞典,找到你輸入的詞,並且翻譯成自己認識的數學語言
原文理解
在這裏使用了一個可學習的嵌入矩陣,大小為[vacabulary_size * d_model](在原文中d_model尺寸為512)
每個詞被映射為d_model維的向量,這個結果會被乘以\(\sqrt{d\_model}\)進行縮放
位置編碼(Position Encoding)
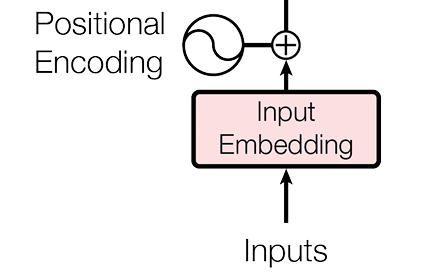
眾所周知我們現在的中文一般是從左往右進行閲讀的,但是對於古人或者外國人(尤其是一些中東國家)來説,他們閲讀和書寫的順序可能是從上到下或者從右到左。
所以對於模型來説,我們也需要對他説明這些輸入的詞語位置,方便他理解上下文信息。所以這裏我們就需要用到位置編碼(PE)了。
通俗理解
我們通過標註的方式,給每個詞標記了相對位置,並且特別標註了“哪個詞與哪個詞意思相近”。比如説我輸入了“男”、“樹”和“女”,可能這裏就把“男”和“女”標註意思相近,方便模型理解。
原文理解
Transformer結構與RNN不同,不能順序讀取序列,所以需要標註清楚每個詞在句子中的位置
Transformer的位置編碼使用了固定相對位置編碼,運用了正弦函數和餘弦函數共同標註詞的位置
\(PE_{ (pos, 2i)} = sin(pos / 10000^{(2i/d\_model)})\)
\(PE_{ (pos, 2i+1)} = cos(pos / 10000^{(2i/d\_model)})\)
其中,pos是表示詞語在句子裏面的位置,i是索引維度(奇偶維度分開),d_model是模型維度
運用正餘弦定理,任意相對位置都可以通過某一位置相加計算得到。
輸入向量構建
經過上述的變化之後,我們的中文序列就轉化為了可以被模型認識的向量表示了。最終的輸入表示 X就由詞嵌入 和位置編碼 相加得到。
Attention結構
作為整個Transformer結構最為重要的部分之一(從論文名字就能看出來吧),看見他的名字我們就可以看出來,它的主要作用就是發掘序列中值得模型重點關注的地方。那麼他是如何工作的,我們接下來看一看吧。
自注意力機制 Self-Attention 和 縮放點積注意力 Scaled Dot-Product Attention
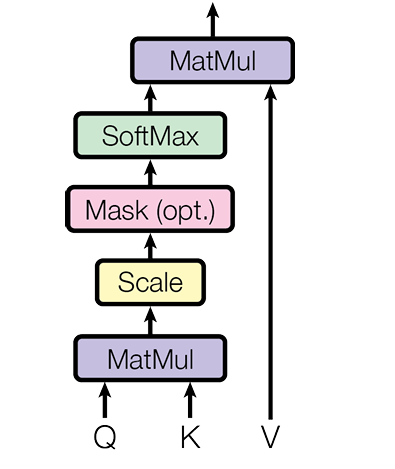
PS:這裏提到的縮放點積注意力是所有注意力機制數學化的基礎計算原理(文中説明的),而自注意力機制則是其最基礎的表現形式。很多人會把它們混用,但在技術嚴謹性上,它們是“機制”與“實現”的關係。
作為最基礎的注意力單元,也是模型中所有注意力結構的最基礎結構,按照縮放點積注意力構建的自注意力單元已經成為Transformer中最為獨特的創新點。要想理解它的工作原理,我們這裏還是拿我們已經經過構建的輸入向量X做一個比喻吧。
我們暫且認為經過變換後的X仍然表示這“我”,“是”,“人”這三個詞吧。
第一步 生成QKV
用到這個結構的時候,我們需要將我們的輸入序列進行拆分,拆分為Q、K、V三個向量。
-
Q(query)查詢:“我在找什麼”。在句子中,當前詞想要了解自己與其他詞與自己的關係。
-
K(Key)鍵值:“我是誰”。在句子中,相當於自己的“標籤”,每個詞向外界展示的特徵,用於匹配查詢。
-
V(value)數值:“我的內容是什麼”。在句子中,每個詞真正要傳達的信息.
通俗理解:
想象注意力機制就是一個人在翻字典,就比如説輸入了“我是人”這個句子,他翻到了“我”這個字:
Q就是在想知道“我”可以組成什麼詞語(或者和哪個詞語關係大);
K就是每個詞的頁碼;
V就是這個每個詞在詞典中對應的解釋。
這樣分開式地處理,讓QK可以更加專注於詞語的匹配,而V只需考慮信息的傳遞,避免了很多問題(自相關等)。
那麼我們如何得到這三個主要的向量呢,在這裏,輸入向量X需要通過3個不同的線性變換矩陣得到Q、K、V,也就是:
Q = X·W_Q,K = X·W_K,V = X·W_V
這些權重矩陣W_Q、W_K、W_V是模型訓練過程中學習得到的
第二步 計算注意力分數
瞭解了通過Q、K、V這樣一個可以快速計算詞與詞之間關係的方法,我們就需要通過這一步計算每個詞與每個詞之間的關係,也就是計算注意力分數。
在這個階段,一般是通過將所有詞向量拼接為一個大的向量統一進行運算,但是這裏方便理解我們就還是將每個詞向量進行拆分計算吧。
所以在這一步我們需要計算每個詞的Query和所有詞Key的相似度:\(Q * K^T\)。相當於衡量"每個詞想了解的內容"(\(Q\))與"其他詞提供的特徵"(\(K^T\))的匹配程度。
通俗理解:
這一步就好理解了。我們將“我是人”的Q * K^T簡化為\([Q_1, Q_2, Q_3] * [K_1,K_2,K_3]^T\)(T為轉置)。
\(Q * K^T\)這個過程就相當於:
注意力機制開始翻字典,當前的“我”字在第22頁。他首先翻到了第33頁,翻到了“是”這個詞,看了看下面的解釋,感覺他們語序之間有關係,那麼這個\(Q_1*K_2\)計算結果就賦予一個0.5的相關性。
接下來它又翻到了55頁,看到了“人”這個詞,感覺他們語序之間有關係但不多,那麼這個\(Q_1*K_3\)計算結果就賦予一個0.3的相關性。
按照這個順序,就可以計算其他不同詞之間的關係,最後統一得到\(Q * K^T\)的結果。也就是每個詞與所有詞只見的相似度。
第三步 縮放與Softmax
為了方式數值過大,這裏使用了一個縮放。使用當前計算分數除以$\sqrt{d_k} $(d_k是Key的維度)防止數值過大。
這裏有的文章説可以使用其他的值作為分母進行縮放,本質上都是為了防止內積過大的操作
然後通過softmax將這個分數轉化為一個概率分佈,所得到的結果就是注意力分佈。
通俗理解:
一個不太恰當但淺顯的例子,比如説得到的最終分數為1,2,3。那麼經過softmax之後就變成了1/6,2/6,3/6,得到了注意力權重就是0.17,0.33,0.5這樣子變成一個概率分佈。
第四步 加權得到輸出
最後使用注意力權重與每個詞的V進行加權求和:\(Output=Attention\_weight * V\),這樣的輸出就可以讓我們的向量本身包含更加豐富的語義信息。
通俗理解:
就拿上面的“我”這個詞來説,比如説它對於“是”和“人”的注意力權重分別是0.5和0.3(現實應該是一個矩陣,這裏方便理解化為一維),那麼“我”這個詞就會根據注意力權重有選擇地學習到“是”和“人”的語義信息,成為了一個與“是”和“人”上下文信息的全新的“我”向量。
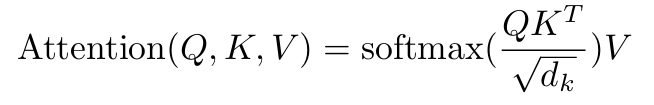
這樣一個self-attention結構,就讓每個詞語可以學習到與自己相關的詞語的上下文信息。回頭我們再看它的整個公式,我們就可以更加清晰地理解其中的意思。
多頭(自)注意力機制 Multi-Head Attention
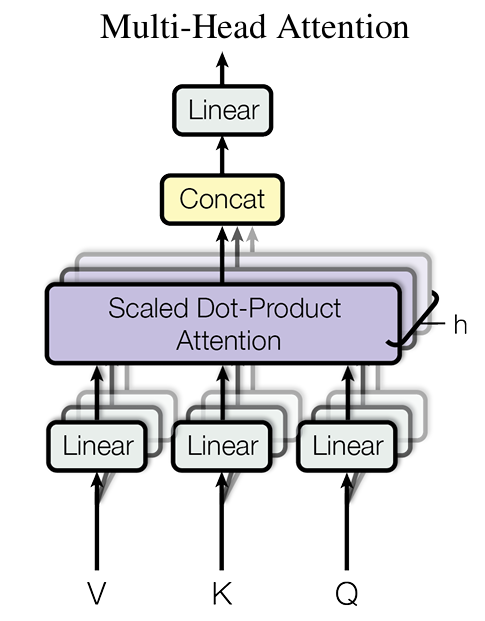
在原文結構中,我們可以看到我們的輸入序列進入的Encoder結構中遇到的第一個處理就是這個多頭注意力,那麼這個多頭注意力和我們上述提到的自注意力機制有什麼區別呢?
正如我們上文所説的那樣,所謂的多頭注意力機制就是由多個自注意力合併而來。
那麼具體它的結構到底是什麼,我們接下來會進行一個更加詳細的解釋。
多的“頭”是什麼
首先相信大家也很好奇這裏面所謂的頭指的是什麼。我們繼續將所謂的自注意力機制看為一個翻字典的人。
有的時候我們在解決問題的時候,每個人都有不同的看法,包括我們翻字典這件事情來説也是一樣的。有的人認為“我”和“是”關係比較密切,有的人認為“我”和“人”的關係比較密切。
所以這個時候,我們就需要不同的人來一起翻字典,來讓結果儘可能地“服眾”(或者説趨於一個一致的結果)。
那麼這個時候我們就構成了一個“多頭”的概念。
通俗解釋:
不同的翻字典的人得到自己對於句子的理解後,彙總起來出一個比較統一的結果。不同的翻字典的人就被視為“頭”,也就是從不同的角度出發。
有的“頭”從語言學的角度看“我是人”這個句子。“我”是主語,應該後面連上“是”才能使句子通暢,所以“我”和“是”注意力分數高;
有的“頭”從生物學的角度看“我是人”這個句子。“我”在生物學標準上屬於動物,所以“我”和“人”注意力分數高。
……
等所有的“頭”處理完之後,將所有的結果彙總起來得到最終我們的輸入句子“我是人”的注意力結果。
原文解釋:
在原文中,一共分為了8個注意力頭,每個頭獨立計算自己的注意力。
不同的是,他們獨立隨機初始化屬於自己的QKV權重,並獨立計算注意力,使得每個注意力頭可以關注不同語義信息。
\(head_i = Attention(Q·W^Q_i, K·W^K_i, V·W^V_i)\)
這裏的i指代的對應的頭
最終將8個頭的64維輸出拼接成512維向量,並通過線性變換調整維度為與輸入X相同的維度。
\(MultiHead = Concat(head_1,...,head_8)·W^O\)
多頭的作用
為什麼要將多個自注意力拼接起來使用呢?我覺得有着以下的原因:
- 使得模型可以對Q、K、V不同的向量進行更加細化深入的構建,每個"頭"專注一種特定關係類型。
- 多個自注意力的隨機初始化可以消除偏差的影響,讓詞與詞之間的學習更加豐富。
原文中對於整個過程的定義為:

和我們分析的一致。
Encoder結構中的多頭注意力的輸出
最終,我們得到了一個和輸入的向量X大小維度相同的輸出變量Z。
這個Z變量和輸入的X相比,它不僅包含了句子“我是人”的所有信息,還包含了每個詞之間的注意力關係等豐富的語義。
殘差連接與層歸一化 Add&Normalize
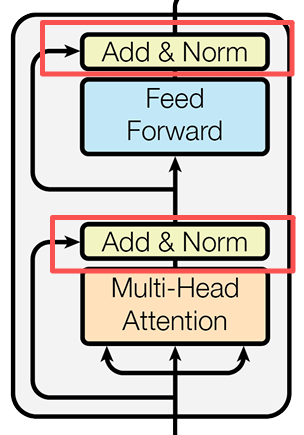
在Encoder的多頭注意力之後,向量進入了一個Add&Normalize層。它由殘差連接和層歸一化兩部分組成。其實在Encoder結構中,在每次大型操作後(多頭注意力操作、前饋神經網絡)都會進行一次這個層。
下面我們用多頭注意力操作後的Add&Normalize舉一個例子,看一看它的具體結構和操作。它的公式也很簡單:
殘差連接
根據公式可得,是一個非常簡單的過程。
簡單來説:把多頭注意力之前的輸入X和經過注意力處理的輸出Z相加。
那麼為什麼要這麼做呢,我們明明都處理好了,給句子加上了注意力,為什麼還要加上沒有經過注意力處理的句子呢?
通俗理解:
給句子加一個存檔,我們可以通過比對存檔讓我們知道目前句子經過了哪些修改,防止經過大型操作之後句子的某些信息丟失。
原文理解:
我們首先要了解:神經網絡退化指的是在達到最優網絡層數之後,神經網絡還在繼續訓練導致Loss增大。
如果沒有殘差鏈接,在訓練時梯度會越來越小直至飽和,訓練也會越來越困難。而有了殘差鏈接後,可以有效解決梯度消失的問題。
殘差連接後,可以讓網絡更加專注於存在差異的部分進行訓練。
同樣的,即使子層學習效果不佳,也能保證至少保留原始輸入信息。
層歸一化
層歸一化是一個比較通用的技術,相當於通過全覽向量信息之後,將所有向量整理到一個相同的水平上,方便後續操作。
層歸一化本身的公式:\(LayerNorm(x) = γ * (x - μ) / √(σ² + ε) + β\)。其中μ是均值,σ²是方差。γ和β是可學習的縮放和平移參數。ε是小常數,防止除零錯誤。
通俗理解:
對當前句子“我是人”這句話的字體統一設成“微軟雅黑”,22字號。
原文理解:
這裏的歸一化,是對於當前樣本的所有特徵進行歸一化。(區別於批歸一化:對同一批次的不同樣本的同一特徵歸一化)
歸一化使優化曲面更平滑,梯度下降更高效。
通過這一層後,所有的詞向量變得更加適合模型操作了。
前饋神經網絡 Feed Forward
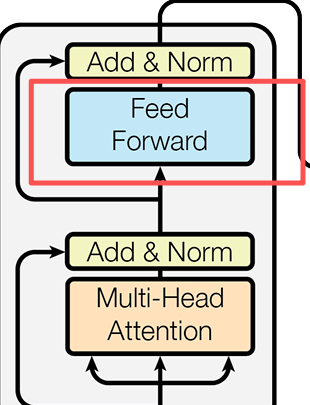
這一層主要是由兩層全連接層構成,它的公式很簡單:
講解一下這個網絡,X就是上述我們經過多頭注意力和Add&Norm的輸入詞”我是人“的向量表示。它的作用就是將我們的向量轉化為一個更高維度的向量進行語義特徵聯繫,然後在恢復到原來維度。
第一層網絡就是一個很簡單的線性函數\(f(x) = (xW_1+b_1)\),其中\(W_1\)是第一層的權重,它的維度為\((d_model×d_ff)\),一般這個d_ff是d_model的4倍,它的作用就是將我們的詞向量映射到更高維度。
通俗解釋:
將句子”我是人“的每個詞拆解成拼音”wo shi ren“,並且將每個詞的筆畫拆解,模型覺得他們之間可能存在更多的關係。
然後通過一個ReLU函數,\(f(x) = max(0,xW_1+b_1)\) 來進行非線性的引入,將強特徵增強,抑制弱特徵,去除雜項。
最後再回復到原有的維度\(f(x)=xW_2+b_2\) ,這裏的W_2就是第二層的權重,它的權重就是$(d_ff×d_model) $ 讓向量迴歸正常維度。
這一項的意義
多頭注意力的本質上只是線性的加權,針對語義來説,可能只學習到了基礎的上下文關聯關係。而前饋網絡項最為重要的升維+ReLU則是給這個向量帶來更多非線性特徵的學習能力。
通俗理解:
通過這一步,我們的模型學習再學習了上下文關係後,還能學到:
情感強度特徵
語義角色特徵
時態特徵
與其他詞的複雜關係
通過ReLU激活,只保留有意義的特徵組合
Encoder的流程與訓練
經過了我們的多頭注意力機制——>Add&Norm——>Feed Forward——>Add&Norm 這樣的一個結構,就構成了我們大名鼎鼎的Encoder結構。
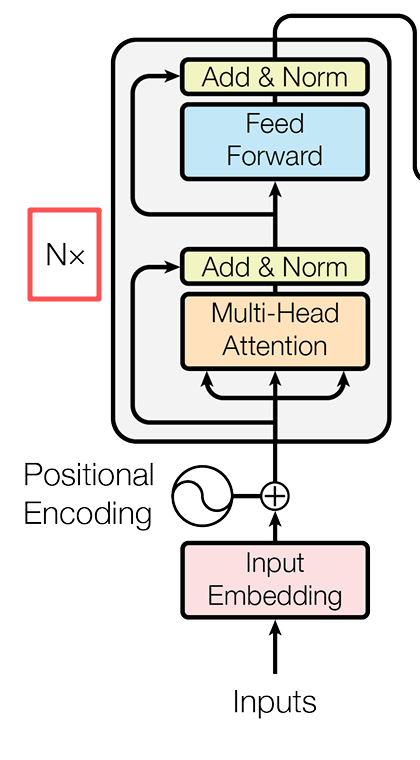
在原文的結構中,我們的模型通過了6層堆疊的Encoder架構進行學習。也就是説,這一層Encoder結構的輸出,會被作為下一層Encoder架構的輸入,循環6次。
通過這個過程,我們的模型對於”我是人“這個句子的理解到達了”空前的高度“,那麼接下來,就需要完成它的預測任務了,根據他的”理解“來生成了。
Decoder結構(訓練)
有了Encoder結構,那肯定也有Decoder結構。在這個結構中,它的組成部分和Encoder有些類似,但是仍有部分不同:
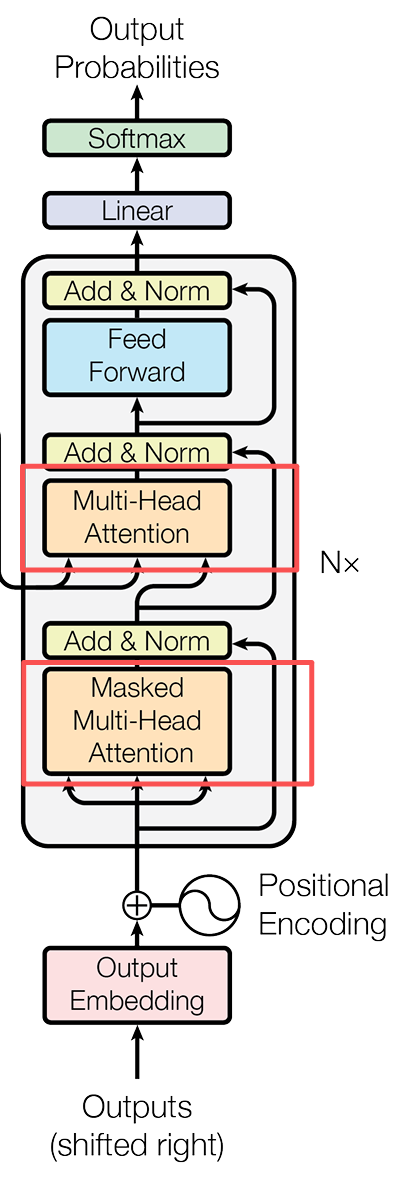
- 包含兩個多頭注意力機制
- 第一個多頭注意力使用了掩碼操作,構成了掩碼多頭注意力機制
- 第二個多頭注意力的Q使用了第一個多頭注意力的輸出,而它的K和V則是使用了Encoder的輸出。
- 最後使用了Softmax來計算可能詞語的概率。
PS:小建議,最好把Encoder和Decoder看作兩個完全獨立的工廠,Encoder看作原材料工廠,Decoder看作加工工廠。
接下來我們繼續按照Encoder的分析方式,從輸入到輸出分析一下Decoder的工作原理。
輸入階段
相較於Encoder的輸入,Decoder有兩個輸入源。
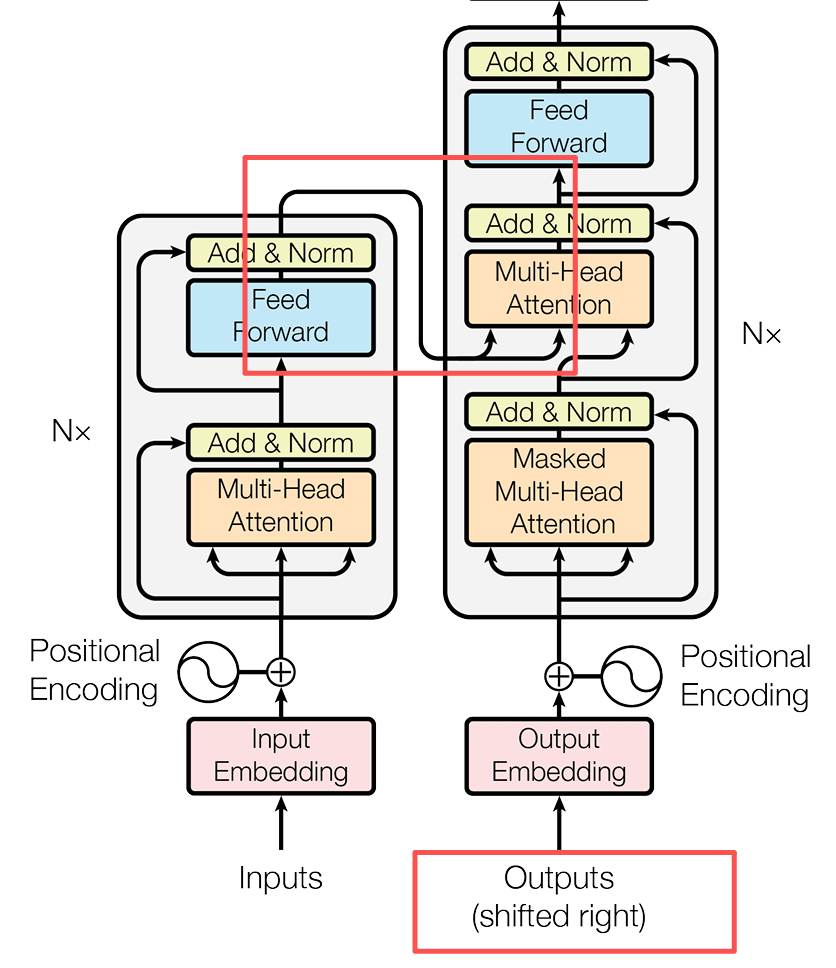
1. 目標序列的右移。
1. Encoder的輸出。
Encoder的輸出好理解,那麼目標序列的右移是什麼玩意兒?
目標序列的右移
我們繼續發揮想象力,先不看Decoder的整體結構,而是直接先看這個流程(Encoder-->Decoder-->輸出)。
通俗理解:
Decoder拿到Encoder處理好的”我是人“的句子,在訓練時,我們希望讓他明白下一個字是”類“字(即”我是人類“這個句子)。
我們不是把完整的答案”我是人類“ 直接給解碼器,而是將最後一個詞給蓋住,讓他去猜。就是給他”我是人“這個句子,讓他去猜下一個詞,直到猜對來訓練他。
原文理解:
Encoder處理完整輸入序列
[“我”, “是”, “人”],並輸出一個包含所有信息的“上下文向量”。 在訓練的時候,我們不是把完整的答案
[“我”, “是”, “人”,“類”]直接給解碼器。而是製作一個“右移”的版本:[<start>, “我”, “是”,“人”]作為解碼器的輸入。 Decoder接收
[<start>, “我”, “是”,“人”]和編碼器的上下文向量。解碼器基於這些信息,一步步地計算輸出。 Decoder嘗試預測下一個詞,我們希望它的第一個輸出是
“我”,第二個輸出是“是”,第三個輸出是“人”,第四個輸出是“類”。 我們將解碼器的預測結果 (
[“我”, “是”, “人”,“X”]) 與真正的答案 ([“我”, “是”, “人”,“類”]) 進行比較,計算損失並更新模型權重。
我們可以對比看到每次Decoder的輸入和輸出,就可以發現一個比較明顯的右移現象。模型故意把解碼器的輸入(目標語句)整體向右移動了一位,目的是為了“欺騙”模型,讓它學會根據“已經生成的詞”來預測“下一個詞”。
掩碼多頭注意力機制
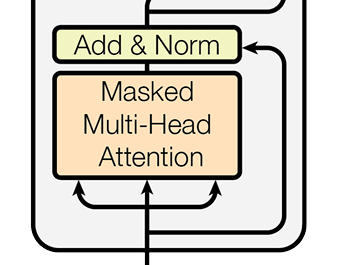
我們首先將上面的右移的目標語句作為輸入記為\(X_1\) ,他經過經典的位置編碼後,傳入到了一個特殊的多頭注意力機制——掩碼多頭注意力機制中。
相較於普通的多頭注意力機制,它多加了一層名為掩碼的操作。
掩碼
掩碼,顧名思義,是要掩蓋一些東西。正如它的名字一樣,掩碼的作用就是在訓練時將一些詞給“蓋住”,不讓注意力機制注意到,或者説模型給訓練到。
它的原理解釋起來也很簡單,就是在預測或者翻譯的過程中,不管是我們人來還是讓模型來,都是要一句一句來順序學習的。所以掩碼的作用就是:掩蓋住當前學習詞後面的詞語,防止模型過早地知道“答案”。
通俗理解:
舉個例子,模型在學習“我是人類”這個句子的時候,當前他的輸入只是“我是人”。
為了防止模型過早學習到這個答案,就會用掩碼將“類”掩蓋起來,讓模型先去猜(推測出下一個詞)
具體的結構上,我們在訓練時,我們需要構造一個大小為k*k的下三角的單位矩陣(下三角為1,其餘為-∞),k為輸入詞序列的長度。這樣就可以實現將當前詞後續的內容給掩蓋掉的效果,讓模型暫時不能學習到。
所以這個掩碼是放在\(Q * K^T\)計算後,與V相乘之前參與運算的。
掩碼類型
為什麼我在説明了掩碼多頭注意力機制後再去講掩碼類型呢,因為其實在注意力機制中,不只一種掩碼存在,其實在之前我們已經使用了掩碼。
在之前的普通多頭注意力中,我們就使用了一種名叫padding mask的掩碼技術。
在我們之前計算所有詞的Q和K的相似度的時候進行了\(Q * K^T\)的計算。在實際的訓練中,我們不可能一條一條的語料讓模型處理,當然是把所有語料都放給模型去訓練,這個時候難免會出現句子長度不一的情況。那麼這個時候,padding mask就起到了一個填充的作用。
它的用法很簡單,打個比方就是給短的句子後面填充0讓其長度變長。這個時候計算\(Q * K^T\)的時候就可以進行運算了。當然在進行學習的時候,填充的內容當然不是我們想讓模型學習到的東西,所以就相當於這部分是一個掩碼信息不讓模型進行學習。
掩碼多頭注意力的輸出
這個時候,我們也是和Encoder的多頭注意力模塊一樣,拼接各個“頭”的掩碼輸出成為一個輸出Z,當然這個輸出和輸入的向量維度相同。
Decoder的第二個多頭注意力模塊
在經過了掩碼多頭注意力的輸出與Add&Norm之後,就到了第二個Decoder的多頭注意力模塊。這個多頭注意力看上去跟Encoder的架構一樣,但是它的輸入卻很奇怪。
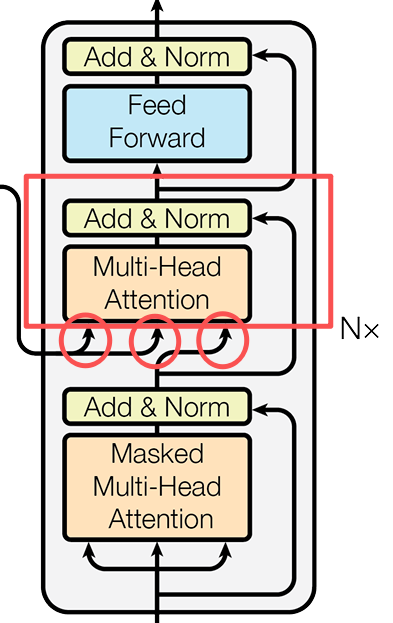
他的Q來自於同Decoder的掩碼多頭注意力機制中的輸出,而他的K和V則是來自於Encoder層的輸出**。
通俗理解:
我們得到了當前的詞語“我是人”和蓋住的答案,要預測下一個詞。它好奇根據語境的話下個詞應該是什麼(Q)
看看Encoder給出的原文,他開始查找一些關鍵信息
Q = [D_我, D_是, D_人] ← 來自Decoder的疑問
K = [E_我, E_是, E_人] ← Encoder提供的"關鍵詞"
V = [E_我, E_是, E_人] ← Encoder提供的"詳細解釋"當處理最後一個字“人”的時候,它的內心OS(D_人)
"在中文'我是人'這個語境中,'人'具體指什麼?"
Encoder通過注意力權重回答:
"主要看'人'本身(70%),其次看'是'(20%),'我'影響較小(10%)"
這樣,模型可能就理解了包含了"人"在判斷句中的特殊含義,識別出這不是單獨的"人",而是"人類"概念。
就是這樣一個過程,讓Decoder可以理解Encoder指示的內容去進行判斷。也是這個第二個多頭注意力機制所關注的內容。
Decoder的流程與訓練
經過了我們的掩碼多頭注意力機制——>Add&Norm——>多頭注意力機制——>Add&Norm——>Feed Forward——>Add&Norm 這樣的一個結構,就構成了Decoder的結構。
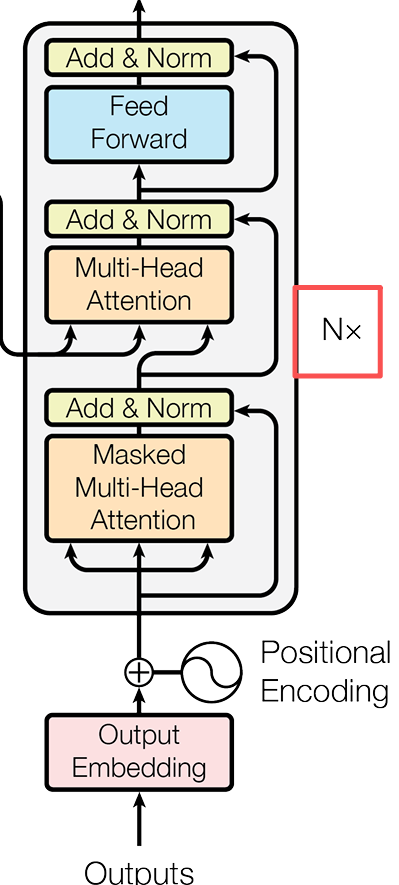
和Encoder一樣,上面的Decoder過程也是反覆進行了6次,Decoder已經對當前的這個詞語已經完全理解了,現在的用處就是讓他學會“説話”——也就是輸出自己的答案。
輸出
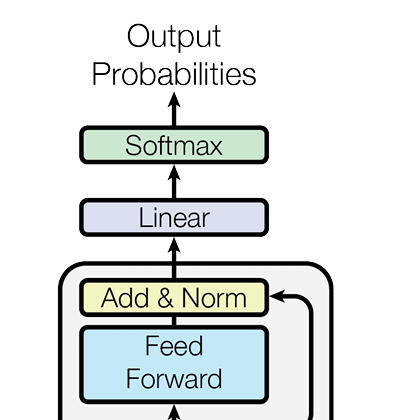
在這個部分,我們首先對上面Decoder的輸出進行一個表示:\(Output Z ∈ ℝ^(batch_size × seq_len × d_model)\) ,每個位置的向量已包含完整上下文信息,而最後一個位置的向量最"富含"預測下一個詞的信息。
首先,我們需要將輸出結果Z的最後一個位置進行預測。經過一次線性變換(全連接神經網絡)和概率分佈變換。通過這一個線性層,我們將這個結果的輸出向量投影到一個詞彙空間。
在這個維度上,模型對每個可能的詞計算一個"匹配分數"(logit),分數越高,表示該詞越可能出現在當前位置。然後,將這個結果通過Softmax將對應的分數轉化為概率。
想象一下,Decoder將自己的輸出去查字典去了。然後比對詞彙表的每一個詞,看哪個詞是概率最高的下一個詞。這個字典是一開始訓練的時候,模型根據學習的預料數據自己學習統計的。
這樣,我們的模型得到了下一個概率最高的字進行輸出。這樣下來,就算模型得到了自己的學習結果。如果實在訓練過程中,我們需要對這個過程進行批改和糾正,就是讓他和原始的訓練數據“我是人類”進行loss計算,從而反覆進行訓練,直到達到最好的loss值。
這樣就是一個完整的Decoder訓練過程。
Decoder結構(推理)
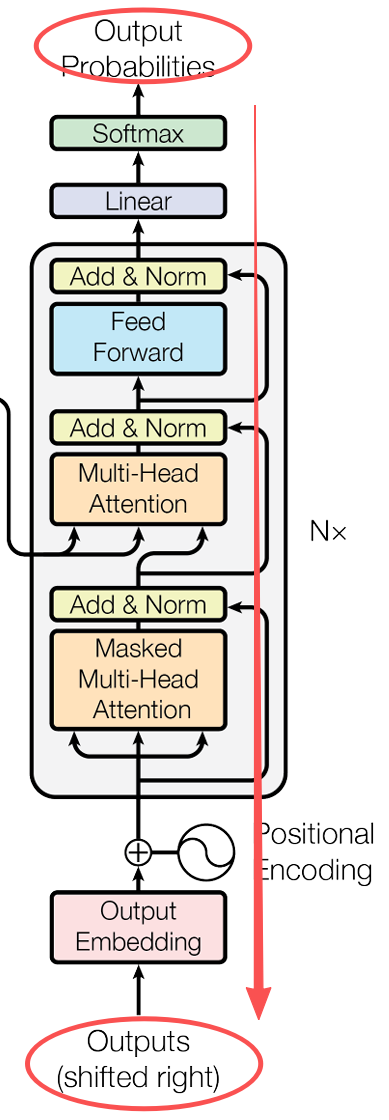
當我們已經訓練好一個Transformer架構了,我們現在想要使用它進行預測。我們的輸入還是“我是人”。這樣,Encoder已經完成了語義的分析與注意力關注,接下來的重點就是Decoder的推理了。那麼它可能是:
通俗理解:
我們的Decoder相當於一個預言家,它開始拿到我們Encoder給他處理好的句子”我是人“。此時Decoder已經學會了預測的方法(參透了符文的力量哈哈)。
它開始一個詞一個詞的預測,先是從”類“開始。然後它再猜下一個詞是什麼,它隱隱約約覺得下一個詞好像是”你“……
最後,Decoder下定決心,它感覺有一股冥冥之中的旨意告訴他,讓他根據自己的訓練數據生成一段完整的話:
“我是人類你是人嗎?”
原文理解:
在原文中,訓練好的Decoder從起止符開始進行預測,它已經通過自迴歸學習讓它從盲猜中找到規律。
開始:給定一個起始符
<start>、“我”、“是” 、”人“(輸入為”<s>,我,是,人“),預測第一個詞 “類”。(輸出為”我是人類“) 迭代:將
<start>、“我”、“是” 、”人“ 和 “類” 一起輸入(輸入為”<s>,我,是,人,類“),預測下一個詞 “你”。(輸出為”我是人類你“) ……
結束:直到預測出結束符
<end>,生成結束。(輸出為“我是人類你是人嗎?”)
