

開發者朋友們大家好:
這裏是 「RTE 開發者日報」,每天和大家一起看新聞、聊八卦。我們的社區編輯團隊會整理分享 RTE(Real-Time Engagement) 領域內「有話題的技術」、「有亮點的產品」、「有思考的文章」、「有態度的觀點」、「有看點的活動」,但內容僅代表編輯的個人觀點,歡迎大家留言、跟帖、討論。
本期編輯:@瓚an、@鮑勃
01 有話題的技術
1、樂鑫攜手 Bosch Sensortec(博世傳感器)推出 AI 智能交互方案
樂鑫科技 (688018.SH) 宣佈與 Bosch Sensortec(博世傳感器)達成合作,共同推出基於動作感知與大模型能力的人機交互創新方案。
該方案旨在推動多模態感知與智能交互技術的深度融合,覆蓋 AI 玩具、智能家居、運動健康、智慧辦公等典型應用場景,實現從環境感知、行為理解到智能反饋的完整鏈路升級,為新一代智能終端提供更自然、更實時的交互體驗。
在此次聯合方案中,博世提供多類型高性能 MEMS 傳感器及算法優化能力,用於精準獲取微動作、姿態與環境變化等多維數據;樂鑫以雙頻 Wi-Fi 6 物聯網芯片 ESP32-C5 作為核心主控,通過穩定的無線連接、實時的數據處理能力以及對 MCP 協議的原生支持,實現感知數據的本地解析與大模型聯動,使系統在端側具備即時理解與響應能力。
這一方案不僅融合了雙方的核心技術能力,也在系統架構、數據鏈路與交互體驗層面進行了深度協同。無論是動作識別、場景感知,還是智能響應,均經過體系化整合,使設備能夠更準確地理解用户意圖。同時,該方案提供標準化的軟硬件基礎能力,大幅降低開發與驗證的複雜度,縮短創新產品的落地週期,助力開發者更高效地構建下一代智能應用。
(@樂鑫董辦)
2、塗鴉智能發佈 Hey Tuya:基於多設備協同的 AI 智能管家,全球響應延遲低於 86 毫秒
塗鴉智能推出「超級 AI 助手」——Hey Tuya。它不再侷限於手機 App,而是作為「物理 AI」的調度核心,通過接入各類智能硬件(智能體),實現跨設備、跨空間的自動服務與習慣學習。
- 毫秒級實時交互: 依託全球邊緣加速網絡,Hey Tuya 實現了全球平均低於 86 毫秒的響應速度。支持「極速打斷」,用户在 AI 説話時可隨時插入新指令,交互體驗接近真人。
- 具備長期記憶能力: 區別於「聊完即忘」的普通 AI,該助手能學習用户的作息規律與環境偏好(如週五晚間自動調暗燈光)。通過長記憶技術,它能隨使用時長增加而更精準地預測用户需求。
- 從「對話」轉向「執行」: 深度集成視覺與感知引擎。例如,通過攝像頭自動識別食物熱量、根據室內光線自動調整照明方案,或在監測到能耗異常時主動開關電器。
- 全場景硬件覆蓋: 智能體邏輯可原生運行於智能音箱、AI 玩具、中控屏、智能手錶等硬件入口,打破了「必須打開 App」的操作限制。
- 開發者快速接入: 提供模塊化編排工具,廠商可以將語音、視覺、控制等功能像「搭積木」一樣組合。最快可在 1 天內完成傳統硬件到 AI 智能裝備的升級。
該系統現已面向全球開發者與硬件廠商開放。廠商可根據自身產品形態(如家電、穿戴、騎行設備)集成對應的 AI 功能,現已支持 60 多種語言。
(@新智元)
3、騰訊混元開源 HY-MT1.5 翻譯模型:1.8B 版僅需 1GB 內存,性能對標 Gemini-3.0-Pro
昨天下午,騰訊混元正式開源翻譯模型 1.5 版本,發佈 Tencent-HY-MT1.5-1.8B 和 7B 兩個參數規模,涵蓋 33 個語種及 5 種民漢/方言互譯。該系列模型通過架構優化實現端雲協同,其中 1.8B 版本在端側表現出超越主流商用 API 的推理效率與翻譯質量。
- 端側超低資源佔用: 1.8B 模型支持量化部署,僅需 1GB 內存即可在手機等消費級設備實現離線實時翻譯,適配 ARM、高通、Intel、沐曦等多種硬件平台。
- 推理速度提升 2.2 倍: 在處理 50 tokens 的標準任務中,1.8B 模型平均耗時僅 0.18 秒,而主流商用翻譯模型平均耗時約為 0.4 秒,顯著降低了高吞吐場景的響應延遲。
- On-Policy Distillation 蒸餾技術: 採用 7B 模型作為 Teacher 指導 1.8B Student 模型,通過糾正預測序列分佈的偏移,使小模型能夠從預測錯誤中學習,而非傳統的「死記硬背」標準答案,大幅提升了小參數模型的泛化能力。
- Flores-200 評分達閉源模型 90%: 在 WMT25 及中外互譯測試中,1.8B 模型性能達到 Gemini-3.0-Pro 的 90 分位水平,並在質量評估中獲得約 78% 的分數。
- 原生支持複雜格式與術語控制: 模型具備自定義術語庫(Terminology)導入能力,支持長對話上下文理解及帶格式文本(如 HTML)翻譯,有效解決了小模型常見的語種混雜及譯文註釋夾帶問題。
模型已在 GitHub 及 HuggingFace 正式開源,支持 1.8B 與 7B 版本下載,騰訊混元官網已同步上線相關功能。
混元官網:
https\://hunyuan.tencent.com/modelSquare/home/list
Github:
https\://github.com/Tencent-Hunyuan/HY-MT
HuggingFace:
https\://huggingface.co/collections/tencent/hy-mt15
(@騰訊混元)
4、阿里通義開源 MAI-UI 系列智能體:涵蓋 2B-235B 四種規格,端雲協同實現 33% 成功率增益
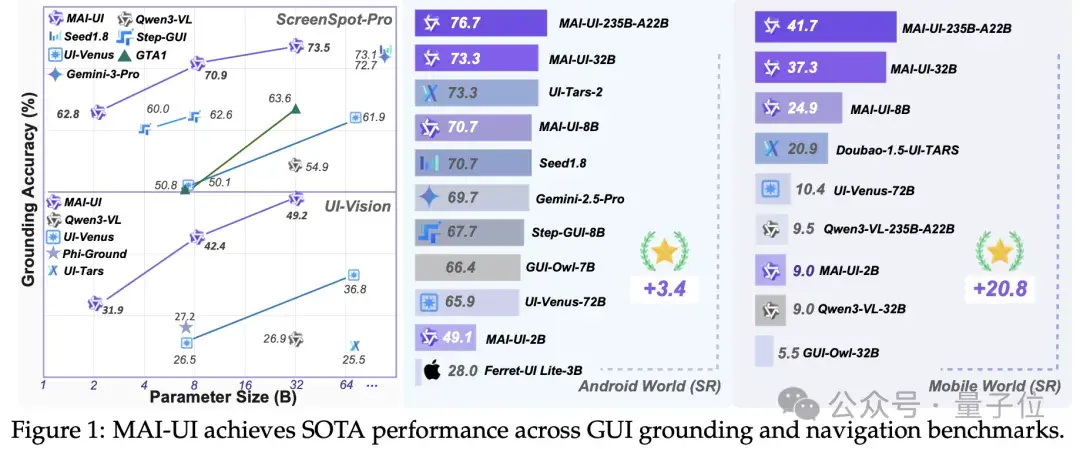
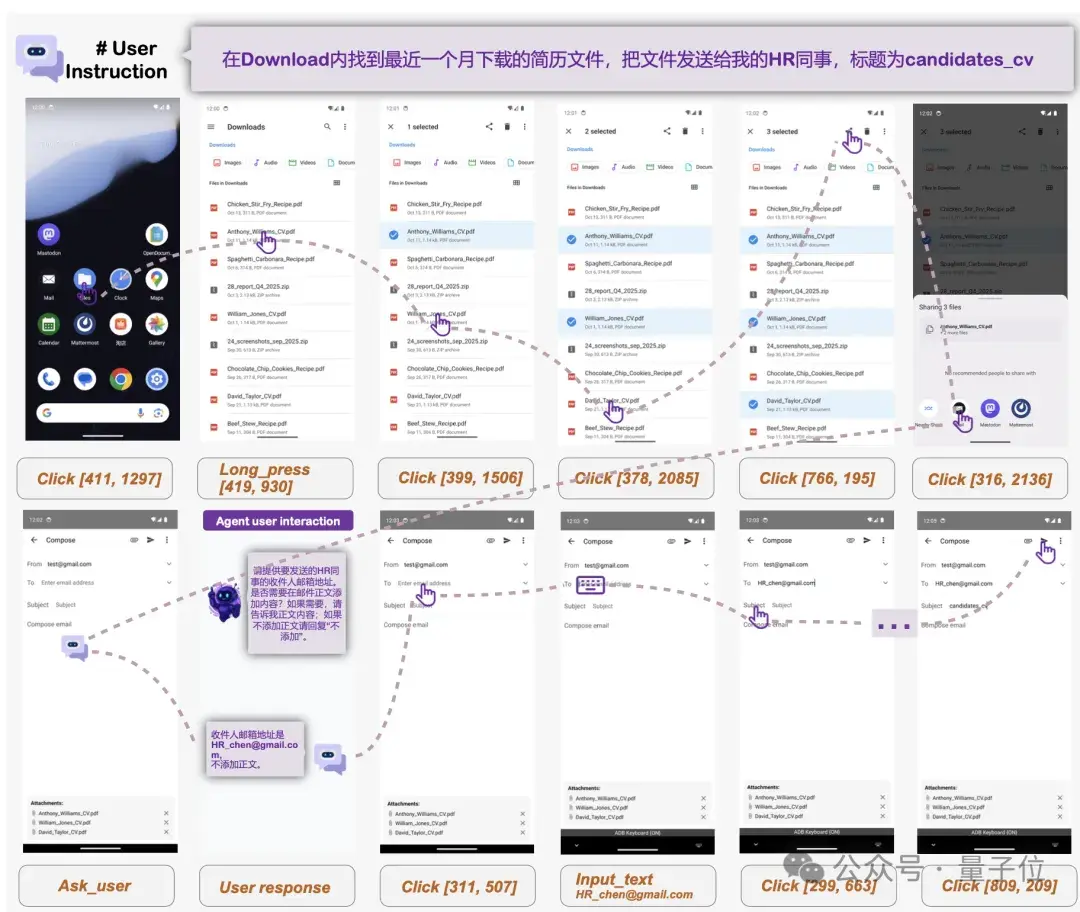
阿里通義實驗室開源「MAI-UI」全套 GUI 智能體方案,包含從 2B 端側小模型到 235B MoE 架構雲端模型在內的四個版本。該系統通過引入 MCP(Model Context Protocol)工具調用和主動追問機制,解決了移動端 GUI 操作步驟冗餘及指令模糊等痛點,並在多項行業 Benchmark 中刷新 SOTA 紀錄。
- 多尺度模型覆蓋與 MoE 架構:發佈 2B、32B、72B 及 235B(MAI-UI-235B-A22B)四個尺寸,滿足從手機端側部署到高性能雲端推理的全場景需求。
- 端雲協同任務切換機制:系統內置監控模塊,根據任務軌跡是否偏離意圖及數據敏感度動態分配算力。實驗數據顯示,協同機制使 2B 模型的任務成功率提升 33%,並減少了 40% 以上的雲端調用。
- 原生集成 MCP 工具調用與主動交互:支持通過 MCP 協議直接調用外部 API(如高德、GitHub),繞過繁瑣的 UI 界面操作;具備缺失信息檢測能力,可在關鍵參數缺失時暫停並向用户索取反饋。
- 強化學習與自演化管線:採用支持 500+ 並行環境、最長 50 步交互的在線強化學習框架,配合自演化數據管線生成交互與工具調用數據,提升了模型在動態、複雜 UI 環境下的魯棒性。
- 刷新多項 SOTA 指標:MAI-UI-235B 在 AndroidWorld 任務成功率達到 76.7%,超越 Gemini-1.5-Pro;MAI-UI-32B 在 ScreenSpot-Pro 上的元素定位準確率達 73.5%,優於 Gemini-1.0-Pro。
論文、代碼及全系列模型權重已在 GitHub 開源,並提供詳細的端雲協作部署參考方案。
論文地址:
https\://arxiv.org/abs/2512.22047
GitHub:
https\://github.com/Tongyi-MAI/MAI-UI
(@量子位)
02 有亮點的產品
1、2025 AI 聽寫工具技術盤點:本地化 LLM 推理、自定義 API 接入與開發流深度集成
2025 年 AI 聽寫領域完成從單純「語音轉文字 (STT)」向「LLM 語義重構」的技術轉型。新一代工具通過本地部署、自定義 Prompt 引導以及對 IDE 的原生支持,解決了傳統聽寫工具在專業術語識別及上下文格式化方面的瓶頸。
- 本地化推理與隱私工程:以「Monologue」和「VoiceTypr」為代表的工具支持全本地模型運行,通過下載模型至客户端實現離線轉錄,從物理層面隔離敏感數據;「Willow」則通過 LLM 語義補全能力,支持從少量關鍵詞生成長段落文本。
- 模型異構支持與 API 接入:工具如「Superwhisper」允許用户根據精度需求切換模型,包括 Nvidia 的「Parakeet」語音識別模型;同時支持接入第三方雲端或本地 AI API 密鑰,解除 Token 使用上限。
- 開發者工作流與「Vibe-coding」集成:針對編程場景,「Wispr Flow」實現了與「Cursor」等 IDE 的深度集成,支持語音識別代碼變量、自動打標文件,並針對不同寫作風格(正式/隨意)提供預設的 Context 引導。
- 低延遲與宏指令擴展:YC 孵化的「Aqua」重點優化了端到端延遲,並引入了基於短語觸發的自動填充功能(如通過語音指令觸發地址、代碼片段填充),同時提供獨立的「STT API」供開發者二次開發。
- 開源生態與多平台兼容:開源項目「Handy」和「VoiceTypr」(提供 GitHub 倉庫)補齊了跨平台短板,支持 Linux 系統及 99+ 種語言,採用一次性買斷或完全免費模式挑戰訂閲制主流。
( @TechCrunch)
2、字節版 NotebookLM 悄悄上線,實測 AnyGen,不僅要終結對話框依賴,它甚至推倒了某些數據孤島
字節跳動在海外上線 AI 生產力平台「AnyGen」,定位為集文檔、智能體、演示文稿與數據分析於一體的協作空間。該產品通過前移輸入入口至多模態記錄,並強化輸出端的「原生可編輯性」,旨在解決 AI 生成內容在辦公場景中因格式崩壞、邏輯漂移導致的「高返工率」問題。
- 多模態上下文聚合輸入:支持長按錄音實時轉寫,並允許同步投喂照片、網頁鏈接、截圖等碎片化素材,將非結構化信息統一轉化為可加工的上下文環境。
- 結構鎖定與段落級局部迭代:採用「引導式提綱」生成邏輯,用户需先確認骨架再填充內容;支持段落與句子級別的局部重寫(Local Rewrite),避免因全篇重生成導致的上下文邏輯衝突。
- 原生 Slides 編輯器架構:輸出結果非靜態圖片或 HTML 卡片,而是支持拖拽、對齊、網格調整的原生元素;支持上傳 PPTX 模板並遵循主版式規範,圖表對象支持直接修改數值。
- 異步 Deep Research 與數據清洗:集成實時檢索與 Agent 處理能力,可執行批量頻道篩選、訂閲數核對等複雜調研任務;生成的分析報告支持模塊化拆解,規避了表格亂碼及導出兼容性問題。
目前已在海外市場上線(anygen.io),提供文檔、智能體、Slides、數據分析四大模塊;支持 Google、Apple 及 Lark 賬號登錄。
( @Z Finance)
03 有態度的觀點
1、夸克揭曉 2025 十大搜索熱詞

昨天,夸克發佈了「2025 年度十大搜索熱詞」,通過對全年用户搜索關鍵詞的脱敏加密數據進行統計分析,揭示了年輕用户在學習、生活、消費等多個維度的關注焦點。
入圍的熱詞有「黃金」「救救」「入坑神作」「這道題」「熱量」「小眾旅行」「新年旺」「高清」「PPT」「一句話」,反映出用户在信息過載時代下的實用需求與情緒表達。
具體來看,「黃金」相關搜索頻繁出現「黃金多少錢一克」「金價預測」等,體現出年輕人對資產保值的關注日益增強,傾向於「不求暴富,只求別跌」的穩健理財觀。
「救救」則成為學習壓力下的情緒出口,涵蓋「四六級救命高頻詞」「期末急救題庫」「開題方向救急」等高頻場景。
內容消費方面,「入坑神作」「這道題」等熱詞顯示出用户對優質內容與學習工具的強烈需求,搜索中頻繁出現「爆款短劇」「深度解題」「英語真題範文」等關鍵詞,夸克的懸浮窗搜題功能也因此受到青睞。
生活方式層面,「熱量」「小眾旅行」「高清」等熱詞揭示了用户對健康飲食、個性化出行與影像質量的關注。
「熱量」相關搜索如「低脂食品」「這道菜多少卡」反映出用户對飲食控制的精細化管理;「小眾旅行」則聚焦於「跨年煙花」「雙人行程規劃」等關鍵詞,展現出逃離喧囂、追求獨特體驗的趨勢。
此外,「新年旺」「旺」等詞彙則體現出用户對好運、財運、桃花等傳統文化意象的持續熱衷;而「PPT」「一句話」則折射出職場與學習場景中對效率工具與信息提煉能力的高度依賴。
夸克表示,通過年度熱詞的發佈,夸克希望與用户共同回顧這一年在搜索中留下的痕跡,洞察時代情緒與趨勢。
( @APPSO)


閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
寫在最後:
我們歡迎更多的小夥伴參與 「RTE 開發者日報」 內容的共創,感興趣的朋友請通過開發者社區或公眾號留言聯繫,記得報暗號「共創」。
對於任何反饋(包括但不限於內容上、形式上)我們不勝感激、並有小驚喜回饋,例如你希望從日報中看到哪些內容;自己推薦的信源、項目、話題、活動等;或者列舉幾個你喜歡看、平時常看的內容渠道;內容排版或呈現形式上有哪些可以改進的地方等。

作者提示:個人觀點,僅供參考