


開發者朋友們大家好:
這裏是 「RTE 開發者日報」 ,每天和大家一起看新聞、聊八卦。我們的社區編輯團隊會整理分享 RTE(Real-Time Engagement) 領域內「有話題的技術」、「有亮點的產品」、「有思考的文章」、「有態度的觀點」、「有看點的活動」,但內容僅代表編輯的個人觀點,歡迎大家留言、跟帖、討論。
本期編輯:@瓚an、@鮑勃
01 有話題的技術
1、Meta 斥資數十億美元收購 Manus,創始人肖弘出任 Meta 副總裁

今天,Meta 以數十億美元收購中國 AI 初創公司、AI Agent Manus 開發商蝴蝶效應,雙方均發文官宣。這是 Meta 成立以來的第三大收購,僅次於 WhatsApp 和 Scale AI。
交易完成後,蝴蝶效應將保持獨立運營,創始人肖弘將出任 Meta 副總裁。
另據《晚點 LatePost》報道,收購談判在十餘天內迅速完成。在 Meta 提出收購前,蝴蝶效應正以 20 億美元估值進行新一輪融資。真格基金合夥人、蝴蝶效應天使投資人劉元表示,談判速度之快令人一度懷疑「是不是一個假的 offer」。
最終,Meta 創始人兼 CEO 馬克·扎克伯格提出的條件與願景打動了創始團隊,扎克伯格本人及多位高管也是 Manus 的忠實用户。
此次收購是 Meta 推進其「超級智能」戰略的重要一步。今年 7 月,扎克伯格在公開信中表示,Meta 擁有龐大的基礎設施和專業能力,有意願也有能力將新技術推向數十億用户。
同期,Meta 向頂尖 AI 研究者開出上億美元年薪,並重組 AI 團隊。
蝴蝶效應成立於 2022 年,創始人肖弘畢業於華中科技大學,曾開發微信公眾號排版工具壹伴和企業微信插件微伴。
公司首款產品為瀏覽器 AI 插件 Monica,提供聊天、搜索、寫作等大模型功能,成為中國少數實現盈利的 AI 產品之一。
2024 年初,字節跳動曾出價 3000 萬美元試圖收購蝴蝶效應。2024 年,90 後連續創業者季逸超與產品經理張濤加入蝴蝶效應,共同開發出 Manus。該產品於今年 3 月上線,具備調度多工具解決複雜問題的能力,迅速引發中外關注。12 月中旬,Manus 宣佈其年度經常性收入(ARR)突破 1 億美元。
收購前,蝴蝶效應共完成 4 輪融資,投資方包括真格基金、紅杉中國、騰訊、Benchmark Capital 及多位中美科技創業者。
真格基金管理合夥人戴雨森表示,Manus 已成為中國新一代創業精神的象徵,「不靠關係,不比資歷,在全球舞台上光明正大同台競技」。
(@APPSO)
2、Resemble AI 開源 Chatterbox Turbo:支持副語言情感標籤,推理速度提升 6 倍
初創公司 Resemble AI 在 MIT 協議下開源了名為 「Chatterbox Turbo」 的文本轉語音模型。這款模型在性能上實現了顯著突破,僅需五秒鐘的參考音頻即可精準克隆目標語音,並在短短 150 毫秒內輸出首個音頻片段。
這種極致的低延遲表現,使其成為構建實時 AI 代理、自動化客户支持、動態遊戲角色、虛擬形象以及社交平台交互的理想選擇。Resemble AI 聲稱,該模型在語音質量上已超越現有閉源競品,能為開發者提供更自然的合成體驗。
在安全合規方面,Chatterbox Turbo 針對受監管行業內置了名為 「PerTh」 的神經水印功能,可用於驗證語音的 AI 生成身份,有效應對深度偽造風險。
目前,Resemble AI 已同步提供託管服務,並計劃在近期推出進一步優化延遲的版本,旨在通過開源生態重塑語音合成市場的競爭格局。
Huggingface :
https://huggingface.co/spaces/ResembleAI/chatterbox-turbo-demo
GitHub:
http://github.com/resemble-ai/chatterbox
(@Resemble AI @X、@AIBase)
3、alexkroman 開源 「Tiny Audio」:支持 24 小時內完成 ASR 訓練,單卡成本僅約 12 美元
「Tiny Audio」是一個極簡、可定製的 ASR 模型訓練框架,旨在打破高門檻的語音模型構建流程。它通過「凍結端到端,僅訓練連接層」的方案,允許開發者在單張 A40 GPU 上、24 小時內訓練出具備專業性能的語音識別系統。
- 混合模型架構: 採用「OpenAI」的 Whisper-large-v3-turbo 作為音頻編碼器(負責語義提取),配搭 Hugging Face 的 SmolLM3-3B 作為文本生成後端。
- 高效投影層訓練: 系統僅對中間的 MLP(多層感知機)投影層進行參數更新。該層利用 1D 卷積進行 4 倍下采樣壓縮,將 1280 維的音頻嵌入高效映射至 2048 維的 LLM 空間。
- 25,000 小時訓練數據集: 默認基於 LoquaciousSet 語料庫,涵蓋 CommonVoice、VoxPopuli 等多源數據,支持多語調、多環境的語音識別場景,實測詞錯率(WER)可達 12.14。
- 多架構實驗支持: 代碼庫僅約 1000 行,但原生支持 MLP、MoE(混合專家模型)、SwiGLU 和 Residual 等多種投影層架構的快速切換與實驗。
目前該項目已在 GitHub 以 MIT 協議完全開源。開發者可通過 Poetry 環境快速部署,模型權重與在線 Demo 已同步至 Hugging Face。
GitHub: https://github.com/alexkroman/tiny-audio
(@GitHub)
4、上海交大 X-Lance 實驗室開源 X-Talk:基於純 Python 的全雙工語音交互框架,實現亞秒級可中斷對話
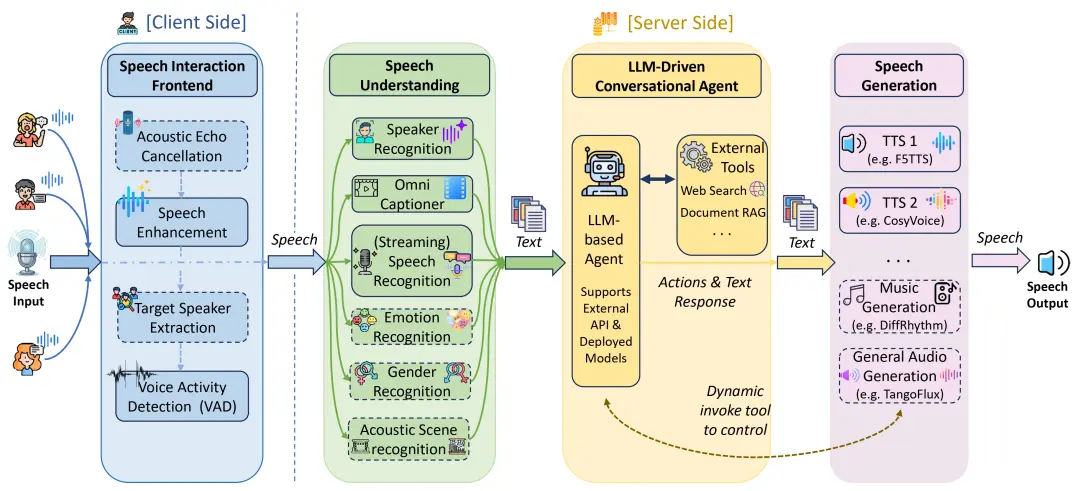
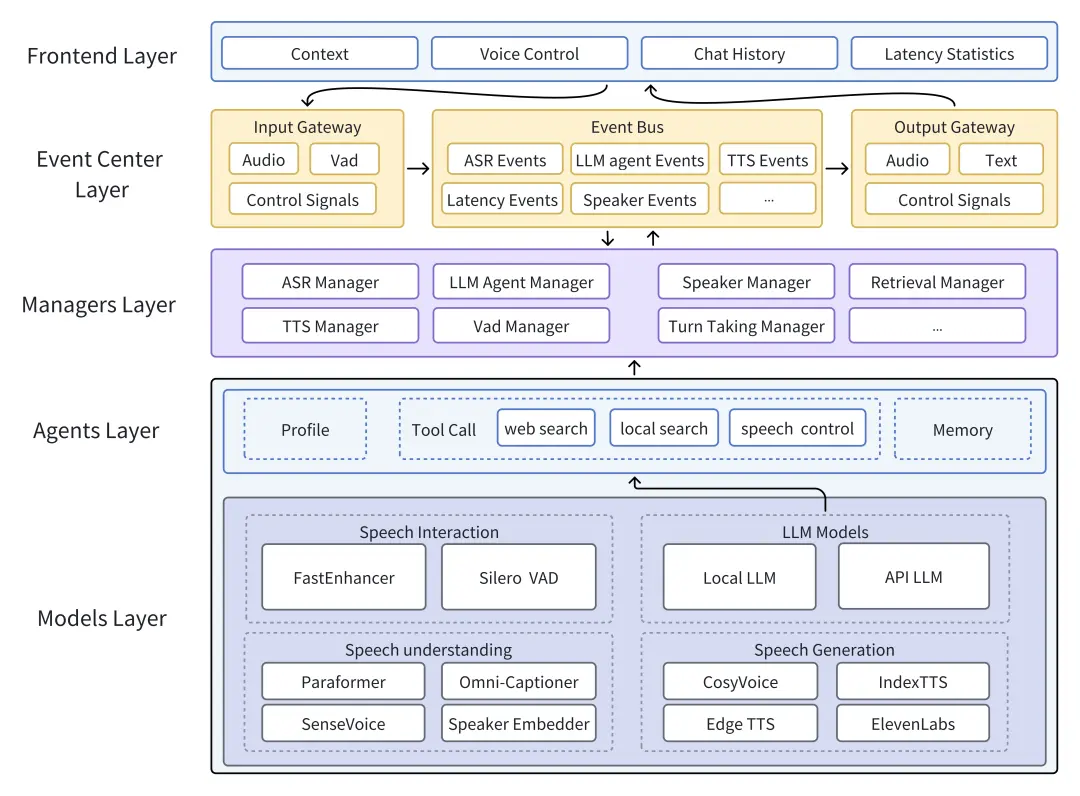
X-Talk 是一款開源的全雙工級聯口語對話系統(Spoken Dialogue System)框架,採用純 Python 編寫的生產級架構。它通過事件驅動機制解決了實時語音交互中的高延遲與不可中斷問題,支持開發者快速構建類似「GPT-4o」體驗的交互式智能體。
- 異步事件總線架構: 核心基於 Event Bus 實現 ASR、LLM、TTS 及 VAD 模塊的鬆耦合通信,所有圖層通過異步發佈/訂閲模式交互,支持複雜的對話狀態管理與流式數據併發處理。
- 全雙工可中斷機制: 系統原生支持用户在機器人説話時隨時打斷(Interruptible),通過前端 VAD 監測與後端信號處理,確保語音流的即時響應與上下文同步,提升交互的自然度。
- 多模型插槽化集成: 框架預設 ASR、TTS、Captioner、Speaker Encoder 等多種接口 Slot。目前已適配 SenseVoice、IndexTTS、CosyVoice、GPT-SoVITS 等模型,並支持通過 4-bit 量化的 Qwen3 系列模型在單張 4090 顯卡上實現低延遲推理。
- 生產級 API 與部署: 採用後端純 Python + 前端 WebSocket 的通信方案,兼容從 Web 瀏覽器到邊緣設備的部署場景。深度集成 LangChain 框架,支持「智能體」在對話中調用網頁搜索、本地檢索及情感/音色控制工具。
- 文檔理解與 RAG 支持: 內置 langchain\_openai 嵌入接口,支持通過 OpenAIEmbeddings 對上傳的文檔進行實時索引與向量搜索,增強對話系統的專業領域知識。
項目採用 Apache 2.0 協議開源,支持 pip install 快速安裝。開發者可通過官方提供的 configurable\_server.py 結合阿里雲 API 或本地模型(如 SenseVoiceSmallLocal)進行快速部署。
API:
https://bailian.console.aliyun.com/?tab=model#/api-key
GitHub:
https://github.com/xcc-zach/xtalk.git
(@GitHub)
02 有亮點的產品
1、Traini 獲超 5000 萬元融資:解析寵物叫聲與行為,實現人犬雙向的實時擬人化對話

硅谷寵物情感智能公司「Traini」完成超 5000 萬元人民幣融資,由 Banyan Tree、Silver Capital 等領投,Nvidia 及 Anthropic 技術高管參投。公司同步發佈了全球首款認知型寵物穿戴設備,利用自研多模態模型解析寵物叫聲與行為,實現人犬雙向的實時擬人化對話。
- PEBI 多模態交互引擎:核心接口支持文本、圖像、視頻、音頻的併發處理,通過解析近 120 個犬種的叫聲聲譜與肢體動作,將寵物意圖轉化為人類語言,情緒識別準確率最高達 94%。
- Valence–Arousal 三維情感向量系統:基於 900 餘項動物行為研究及 200 萬隻犬類數據,該系統融合了叫聲、心率、體温及肢體活動等生命體徵,構建出實時的瞬時情緒畫像,支持早期健康徵兆預警。
- 基於 Transformer 的 PPI 架構:自研的寵物感知交互(Pet Perception Interaction)系統具備實時感知、自適應推理與反饋生成能力,並引入「即用即訓」機制,通過匿名化交互數據構建動態演進的行為數據集。
- T-Agent 自主決策系統:基於其 PetGPT 自然語言行為分析模型,T-Agent 可根據犬隻的真實生理與情緒需求自主觸發服務推薦,使寵物從被動受眾轉變為消費決策者。
- 開放 API 與生態集成:Traini 已向獸醫診所及硬件 OEM 開放接口,並與主流智能手機、電動汽車品牌建立合作,支持將「翻譯結果」接入手機 OS 操作系統或車載娛樂系統。
認知智能項圈已通過 「Traini」 應用及官網開放預訂;API 接口已面向醫療機構及硬件開發者開放。
(@AING 硬跡、@36 氪)
2、3999 元!閃極 loomos AI 眼鏡 S1 發佈:整機 29 克全球最輕

12 月 30 日消息,在昨晚的閃極與中國航母聯名發佈會中,閃極 loomos AI 顯示眼鏡 S1 正式發佈,定價為 3999 元,將於 2026 年第三季度開售。
這款眼鏡將「輕量化」做到極致:官方稱該產品「可能是全球最輕的 AI 眼鏡」,整體重量 29g,體感重量僅 15 克。
發聲系統採用 0.02cc 超小體積硅基芯片揚聲器,實現眼鏡專用的輕量化音頻方案。結合柔性弧形前框的 0°-15°可調面彎,兼顧佩戴舒適度與適配性。
功能層面,S1 搭載「蜻蜓光擎」技術,通過單光機雙目異顯實現真 3D 顯示;AI 能力支持全天音頻感知、主動意圖識別,可對關鍵事項實時提醒。
鏡腿採用可拆卸換電設計,進一步解決智能眼鏡的續航痛點。官方還為其推出了閃極增程環頸環移動電源,號稱充滿一次夠用一個月。
(@快科技)
3、Jetty Health 發佈 AI 慢性病管理智能體:主動電話用户詢問健康狀態
Jetty Health 推出針對慢性病管理的 AI 智能體,通過主動語音外呼技術解決患者記錄依從性低的問題。該產品利用 LLM 將非結構化對話轉化為結構化健康洞察,旨在替代傳統的手動日誌錄入。
- 主動式語音交互(Proactive Voice Engagement):系統可每日定時向用户發起語音通話,通過主動詢問獲取健康狀態,消除用户手動開啓 App 記錄的認知負荷與操作阻礙。
- 非結構化數據捕獲(Unstructured Data Capture):基於 NLP 技術,將用户的自然語言敍述自動解析為症狀嚴重程度、持續時間及潛在觸發因素等結構化數據。
- 自動化模式識別(Pattern Recognition):算法層實時聚合多維度對話數據,自動識別症狀波動的週期性規律及與生活環境的關聯性。
- 臨牀共享接口:支持將 AI 整理的長期病程摘要導出,在診療現場為醫生提供具備時序邏輯的臨牀參考證據。
已上線 iOS App Store,處於 Beta 測試階段,採取小規模邀請制開放。
(@omooretweets @X、@Jetty Health)
4、Zoom 發佈 Realtime Media Streams (RTMS):原生 WebSocket 接入音視頻流,實現無 Bot 化實時 AI
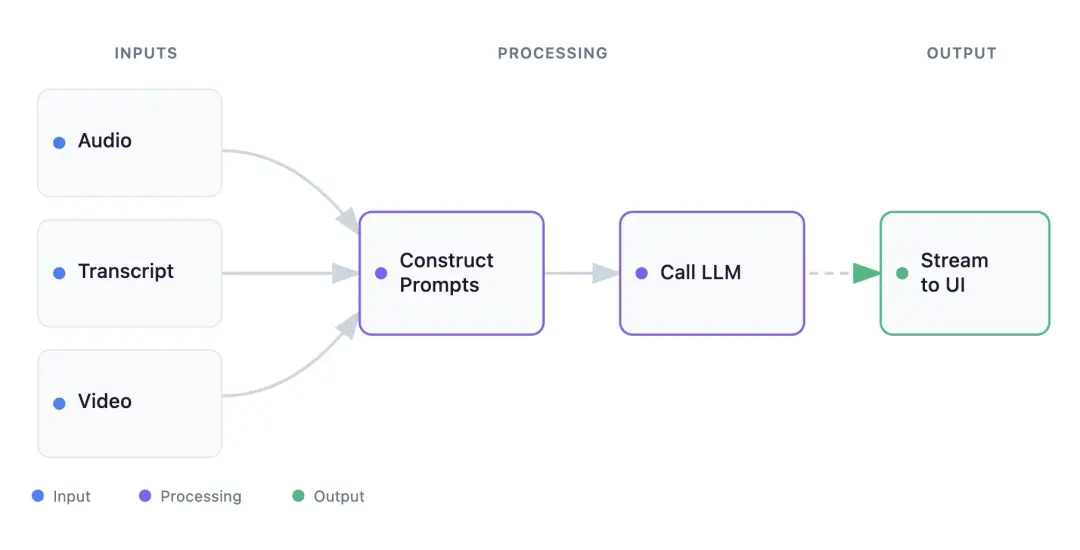
Zoom 推出 「Realtime Media Streams」(RTMS) 功能,允許開發者通過原生 WebSocket 直接獲取會議的音頻、視頻及轉錄數據流。該方案無需部署模擬機器人(Bots),配合 「Inworld Runtime」 等 AI 編排引擎,可在會議期間實現低延遲的實時分析與反饋。
- 無 Bot 化的原生流接入:棄用傳統的「虛擬客户端」入會模式,改用 WebSockets 協議直接推送加密媒體流,大幅降低了服務器計算開銷和部署複雜度。
- 多模態並行處理架構:支持同步運行 Guidance(LLM 實時輔導)、Evaluation(專業度評分)及 Visual Evaluation(基於視頻幀的視覺分析)三大獨立工作流。
- 低延遲 AI 編排集成:深度集成 「Inworld Runtime」,支持將 AI 管道轉化為可組合的圖(Graphs),示例配置採用 \`Groq gpt-oss-120b\` 模型以優化推理響應速度。
- 細粒度權限管控:通過 \`meeting:read:meeting\_transcripts\` 和 \`meeting:read:video\_streams\` 等 Scopes 進行權限隔離,確保數據調用的合規性。
應用案例:
- 實時銷售教練:基於轉錄流進行 LLM 語義分析,在側邊欄實時推送針對客户異議的應對策略。
- 合規性實時審計:通過音頻流實時檢測受限術語,觸發即時告警以規避法律風險。
- 視覺呈現優化:通過定時抓取視頻幀(Frame Capture)分析構圖與光照,為演講者提供實時環境反饋。
- 增量式會議紀要:改變「會後總結」模式,在會議進行中通過增量數據實時生成並修正待辦事項。
(@Zoom Developer Blog)
03 有態度的觀點
1、路透社:2026 年將迎來「智能體」原生語音交互爆發
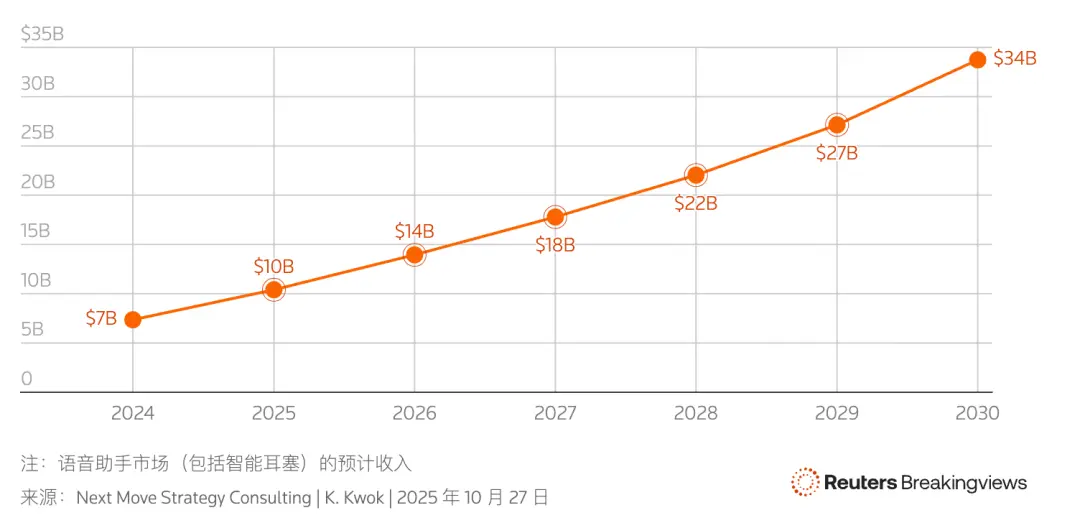
語音交互正從基於規則(Rule-based)的陳舊架構向基於大語言模型(LLM)的生成式架構轉型。隨着 Amazon 和 Apple 等巨頭完成底層技術更替,語音「智能體」將擺脱機械式反饋,實現具備語境感知能力的長文本對話,預計 2026 年將成為個人 AI 助理的真正普及元年。
- 交互架構重構:從「關鍵詞觸發」轉向「端到端語義理解」:傳統的語音助手(如舊版 Alexa、Siri)依賴預設的邏輯樹和規則匹配,導致處理複雜指令時極為僵化;新一代系統由 OpenAI 的 ChatGPT 或 Anthropic 的 Claude 等模型提供推理支持,可實時處理非結構化信息並理解上下文。
- 硬件存量激活:6 億台 Alexa 設備作為潛在入口:截至 2025 年初,全球已有 6 億台支持 Alexa 的設備,這一龐大的分佈式硬件網絡將成為 LLM 落地物理世界的最直接載體。
- 自然語言合成性能突破:徹底告別「機械音」:借鑑「OpenAI」GPT-4o 等多模態模型的語音生成能力,語音「智能體」的延遲將大幅降低,並具備情感表達與語調起伏,向電影《Her》中的 Samantha 式體驗靠近。
- 交互界面轉移:從屏幕向可穿戴設備和可聽設備(Hearables)遷移:隨着語音交互體驗的成熟,用户的交互中心將從智能手機屏幕轉向以 AirPods 為代表的耳塞類硬件,實現全天候、低侵入式的 AI 陪伴。
相關技術正在從實驗階段轉向大規模部署,預計 Apple 與 Amazon 將在 2025-2026 年間的年度發佈會上推出基於自研/合作 LLM 的重構版系統。
(@Reuters Breakingviews)


閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
寫在最後:
我們歡迎更多的小夥伴參與 「RTE 開發者日報」 內容的共創,感興趣的朋友請通過開發者社區或公眾號留言聯繫,記得報暗號「共創」。
對於任何反饋(包括但不限於內容上、形式上)我們不勝感激、並有小驚喜回饋,例如你希望從日報中看到哪些內容;自己推薦的信源、項目、話題、活動等;或者列舉幾個你喜歡看、平時常看的內容渠道;內容排版或呈現形式上有哪些可以改進的地方等。

作者提示:個人觀點,僅供參考