

從2022年優化智能客服開始,我就開始嘗試優化人機語音對話中的 “語義完整度” 模塊。當時大部分人的精力都集中在優化識別率,在語音對話系統中,這不是一個核心模塊,似乎是可有可無的,但語義上的完整度對於用户體驗、信息收集的效率都有很大的影響。 特別是在今天人們對於智能和體驗的極致追求下,語音對話類各種應用,比如陪伴、玩具、客服等場景的大模型升級,越來越多的工作開始瞄準這個方向,業界需求也在增加,這也印證了我們之前的文章中提到的語音應用的趨勢之一,即從功能實現到體驗提升。本文將重點分享幾個語義完整度的優化思路、方案和實際挑戰。
一個完整的級聯對話系統的方案
本文就不再過多解釋,有興趣的朋友可以參考下面的視頻:
什麼是語義完整度?
語義完整度,或者叫做Turn Detection,輪次檢測,其實屬於用户意圖判定的一種,主要用來判定用户是否已經完整地表達了自己的想法。一個真正的智能系統,應該可以做到有“眼力見”:
該響應的時候及時回覆,不該響應的時候保持沉默。
但在真實的語音交互場景中,經常有以下這幾種情況出現:
- 機器過早回覆: 用户使用“嗯、啊”等詞彙過渡,用户的不流利發音,或者用户在面對複雜問題的思考間隙過長,從語音信號能量上看,物理上用户是停止了説話,但信息並不完整,或者噪聲導致識別出文字,誤以為用户響應;
- 機器等待過長: 一般是由於噪聲存在,機器誤以為用户正在響應,沒有及時做出迴應。
看似一個簡單的分類任務,做起來可不簡單。同樣一個“嗯”字,不同的上下文、不同的語調語氣説出來,意義就完全不一樣。
其實語義完整度的預測並不是新方向。下面,就按照時間順序,梳理一下幾個不同的方案,包括一些開源的工作,不同的方案適應不同的場景,有些看似過時的方案,也許是適合現在業務的。特別是方案5,聯合文本+音頻的方案,我認為是最合理的。
方案1:VAD和完整度的聯合預測
可以參考Google 2019年左右的文章[1],雖然比較老了,但優點是相對獨立,輕量級。適合有一定語音背景,訓練過VAD模型的朋友。

這篇文章中,他們把語義上的完整度叫做End-of-Query (EOQ),主要是針對語音搜索場景,同樣適用於語音對話。
相比於VAD模型只進行語音、非語音的預測,他們的方案採用多任務學習框架,額外增加了EOQ的預測:
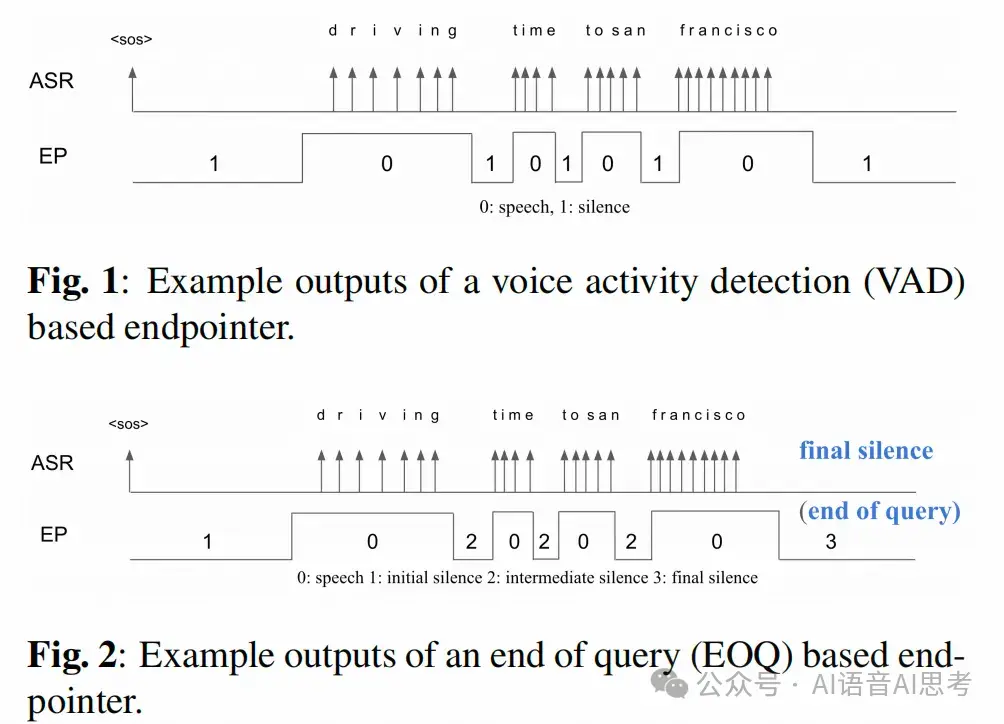
並且考慮到不同領域的應用,比如近場和遠場交互,將domain ID作為一個特徵。後面,我還會講到,Domain或者數據覆蓋,其實是語義完整度檢測的一個比較大的挑戰。
方案2:ASR和Turn Detection的聯合優化
同樣是Google在2022年的文章[2],由此可見,Google對於這個問題還是很重視的。這個方法適用於有自己的語音識別系統,能夠自己訓練模型。 如果採用了別人的API,就不適合這個方法了。簡單來説,就是在語音識別的標籤中增加一個特殊的標記符號 <pause>來標識短暫的暫停。
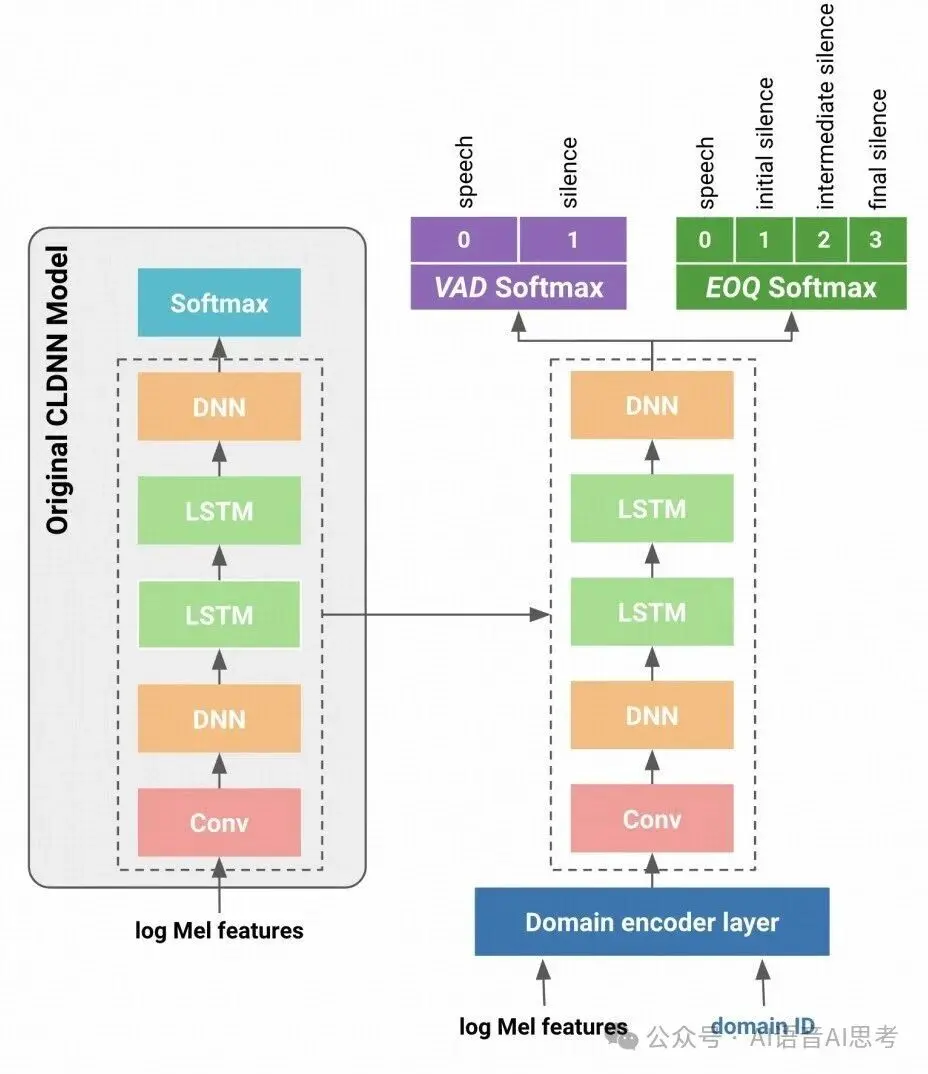
當然了論文還是基於RNNT的框架,有一些探索也不具有很大的意義。但這種聯合訓練方式優點有:
- 本質上是一種多模態的方式,因為ASR模型天然就是文本+語音的。
- 可以降低由於數據不匹配造成的性能下降。
- 不增加額外的模塊和系統複雜度。
方案3:純文本大模型方案
比如Agora開源的TEN Turn Detection[3],支持三個狀態的預測:
Finished:用户完整表達了自己的意圖
Wait:用户明確要求AI停止輸出
Unfinished:用户表達不完整,還沒有完成本輪輸入
支持多輪對話管理,可以將長上下文作為條件,支持多語言。
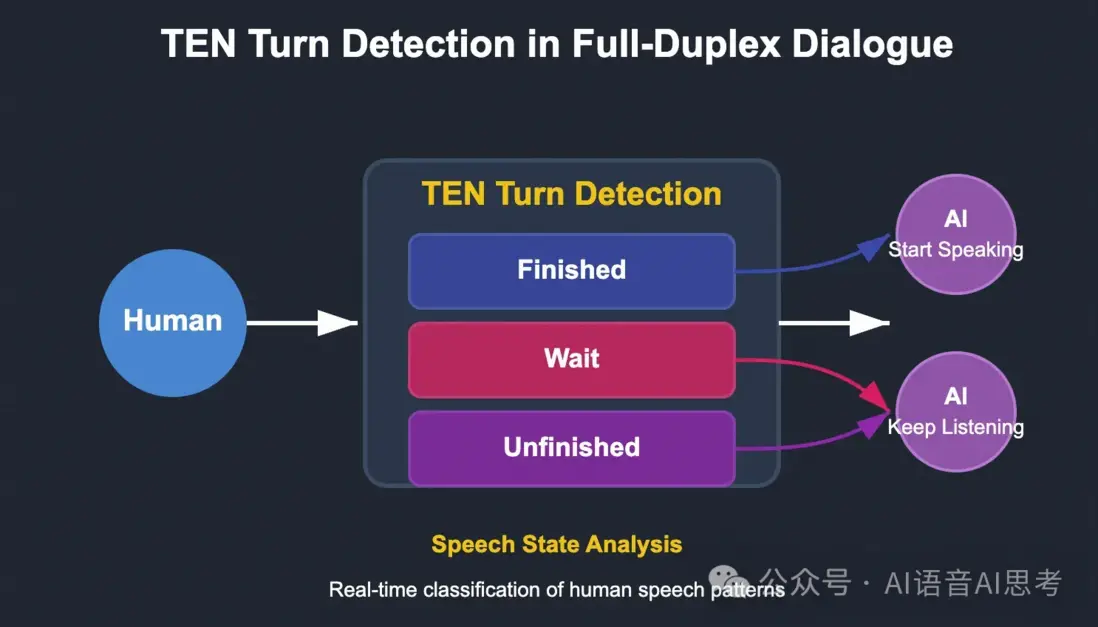
純文本的方案缺點明顯,會丟失語音中能量、語調、情感、頻率等信息;TEN Turn Detection採用了文本大模型作為Base模型,需要GPU推理。
優點就是非常容易級聯到現有系統。 具體實現的時候,將聲學VAD的靜音判斷時間調短,在短暫暫停時,將當前的識別結果送給TEN Turn Detection,根據結果來調整下一步的狀態。
方案4:純音頻方案Smart Turn
其實Smart Turn的方案[4]比方案1還要簡單,官方也是建議配合VAD使用,VAD檢測到靜音之後,將整段音頻送入Smart Turn進行判斷,它並不適合流式的推理。
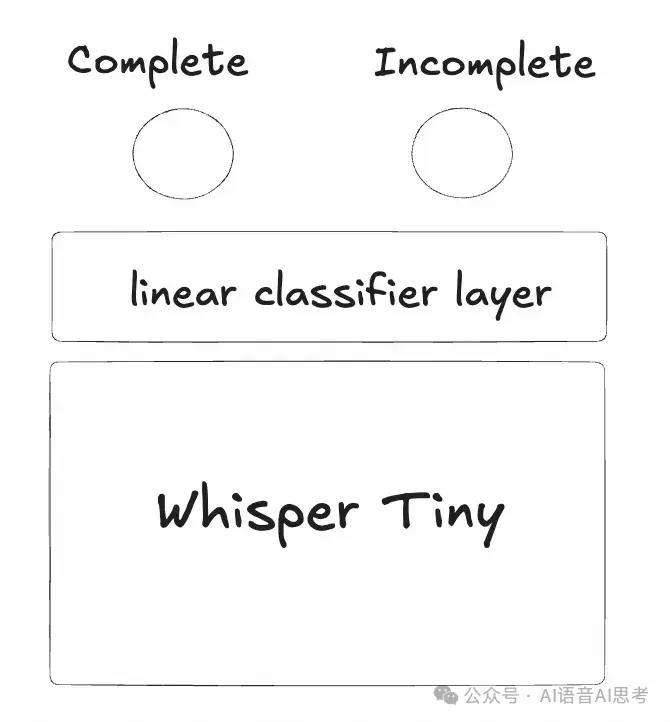
Smart Turn的優點是部署相對容易,因為底層是Whisper,支持多語言。
但是在真實的、垂直的業務場景中的效果如何,需要實際去驗證。
方案5:文本+語音多模態大模型方案
Easy Turn[5],西工大ASLP開源的一個基於多模態的大模型方案。我個人認為文本+語音多模態的方式,是最好的解決方案,其訓練流程融合語音識別的預訓練和Turn Detection的後訓練。
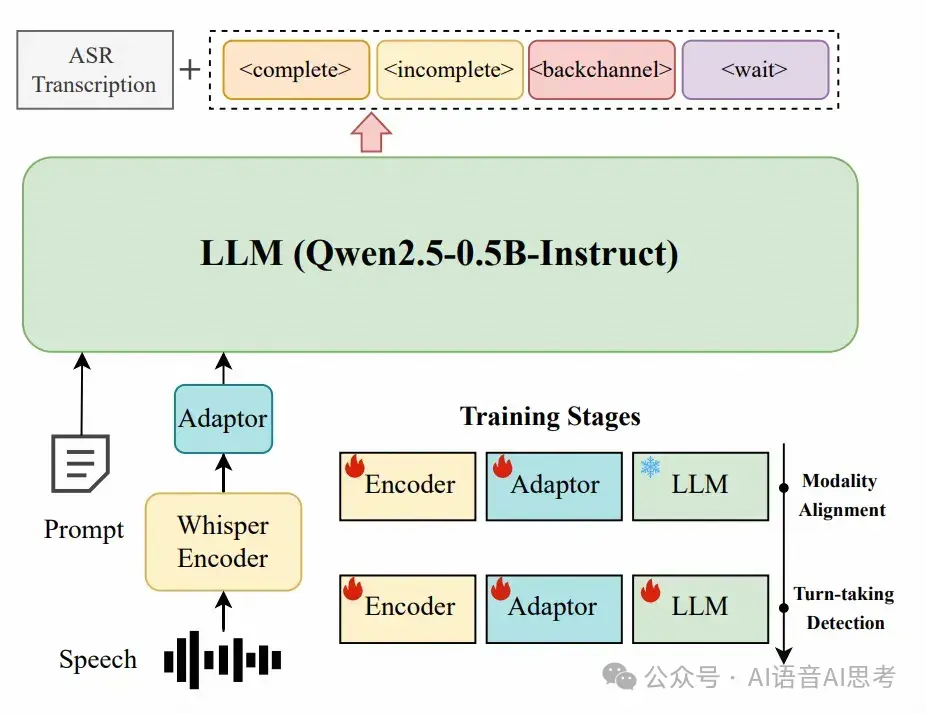
但是由於這個工作是學術工作,如果想要在工程上進行應用,其實需要做一些工程化的工作,比如流式推理的時候,需要做好語音流隊列管理,ASR結果和語音數據的對應等工作。
基於這個架構,在自己的垂直領域上進行微調,可以進一步解決數據不匹配的問題。
文章對方案3-5做了系統的對比:

其他方案
如果是相對封閉的場景,比如問題有限的信息採集、確認,還可以採用Embedding+完整度計算的方式。這個方式和大模型方案整體比較相近,不過多解釋。
挑戰和總結
所有的方案,其實都面臨一個domain mismatch的問題,他們使用的數據往往和真實業務數據有很大的分佈差異,並且會採用大量的合成數據進行模型訓練,這些都是影響效果的重要因素。看似簡單的問題,其實一點都不簡單,它需要模型能力足夠強,需要產品設計來兜底。上面的5種方案和思路,也只是一個參考和基線。具體的問題還有具體分析。在大家都用API的時代,細節決定了產品體驗,而語義完整度就是這樣的重要細節。總結來説:
- 純文本的方案無法充分利用音頻特徵,但是容易集成。
- 純音頻方案會缺失語言語義信息。
- 音頻+文本方案是一個理論上比較完善的方案,但是需要匹配的訓練數據,工程化相對複雜。
參考文獻
[1] https\://ieeexplore.ieee.org/abstract/document/9003787/
[2] https\://arxiv.org/pdf/2208.13321
[3] https\://github.com/TEN-framework/ten-turn-detection
[4] https\://github.com/pipecat-ai/smart-turn
[5] https\://arxiv.org/pdf/2509.23938


閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
