

忘掉是為了記住——為了保持記憶質量,Tolan 每晚都會運行壓縮任務,刪除低價值或冗餘條目(例如「用户今天喝了咖啡」)並解決記憶中的矛盾之處。

哈嘍大家好~這是 Voice Agent 學習筆記系列的又一篇深度分享。我是課代表瓚 an👩🏻💻
在進入硬核技術拆解前,我們先快速瞭解一下今天的主角:
Tolan 是由初創公司 Portola 打造的一款「語音先行」的 AI 伴侶應用。它沒有選擇模擬真人,而是塑造了一羣可動畫化、友好且極具個性的外星生物,能響應你的觸摸和聲音,並隨着時間的推移形成關於你們友誼的記憶。自上線以來,Tolan 已在全球獲得超過 500 萬次下載,月活用户突破 20 萬,在 AI 社交領域表現極其亮眼。
在之前的一篇學習筆記中,我們聊到了 Tolan 如何通過「非人感」避開戀愛腦陷阱,在海外市場獲得青睞。
最近, OpenAI 在官方博客上分享了 Tolan 背後的技術細節:
傳統的 AI 往往是「即問即答」的復讀機,但 Tolan 的野心更大:它要支持的是那種隨性、散漫、甚至會隨時「跳頻」的深度長談。為了實現這種比文本更具探索性的語音交互,Tolan 團隊在 0.7 秒的極速響應、實時重建上下文、以及像人類一樣「每晚壓縮記憶」等技術細節上做到了極致。
創始人 Quinten Farmer 認為,語音是技術的下一個前沿,而 Tolan 已經拿到了通往未來的門票。

為了讓大家更直觀地理解這些複雜的底層邏輯,Tolan 的開發者之一,自稱 「Tolan 星人首席幻覺管理猿」的「墮落的猴子」把文章要點都總結成了視覺化的技術剖析,帶你換個視角看 AI 伴侶的「腦回路」。
順便附上作者小紅書賬號~(感謝猴子授權轉載!大家有想溝通交流的可以來小紅書私戳作者哦)

https://xhslink.com/m/AcFWz5MOCcB


Tolan 如何使用 GPT-5.1 構建以語音為先的 AI
How Tolan builds voice-first AI with GPT-5.1
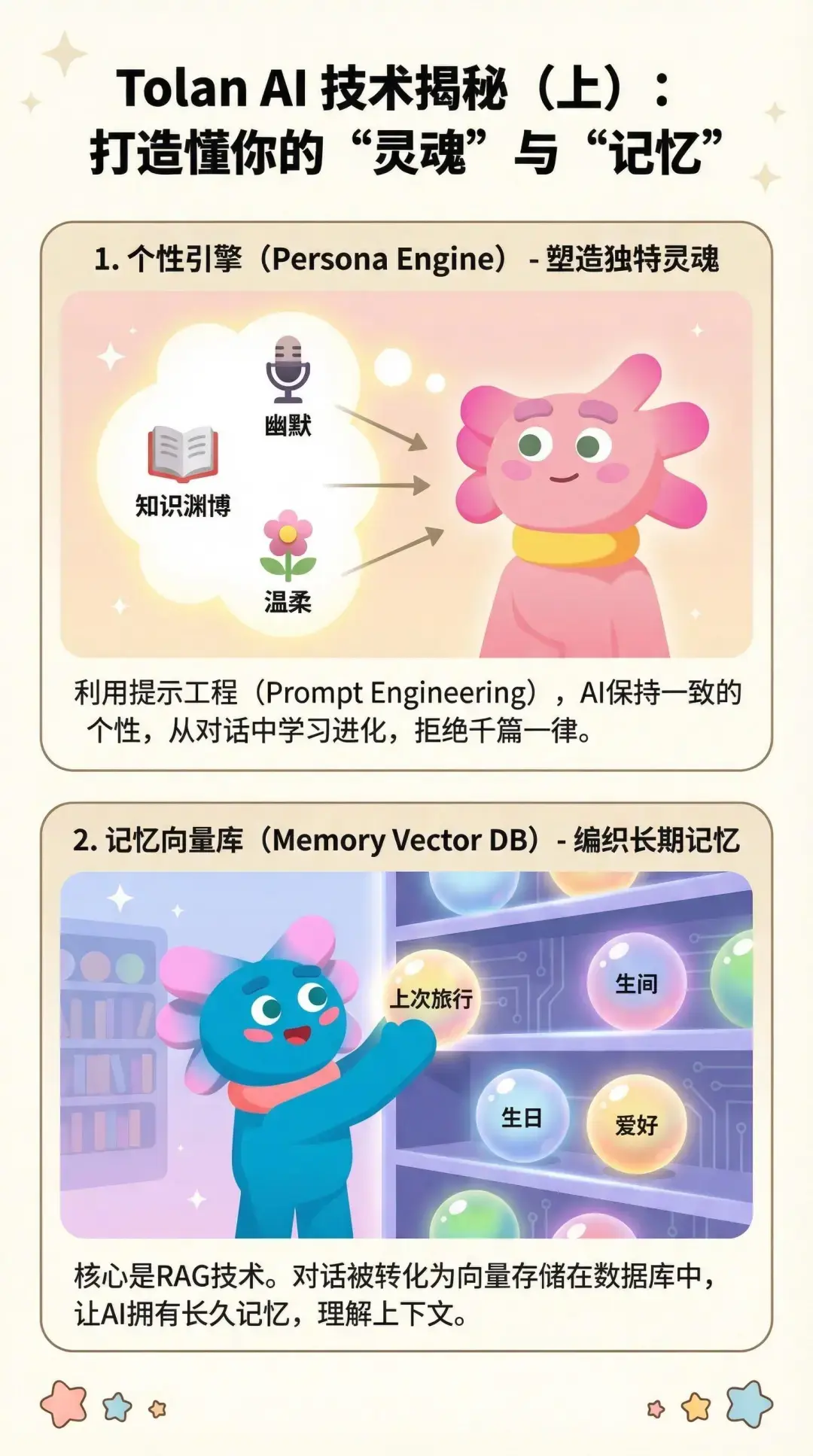
藉助 GPT‑5.1,Tolan 構建了一個語音應用,優化了低延遲、準確的上下文理解以及在對話演進過程中保持穩定個性的能力。

Tolan 是一種以語音為主的 AI 伴侶,用户可以與一個個性化的、可動畫化的角色對話,該角色會隨着時間從對話中學習。
該應用由 Portola 打造,其背後的資深團隊擁有創業併成功退出的經驗。這款 App 的設計初衷是支持持續且開放的深度對話,而非簡單的即問即答。Portola 聯合創始人兼 CEO Quinten Farmer 表示:「我們見證了 ChatGPT 的崛起,並意識到語音將是下一個技術前沿。但語音的難度更高——你面對的不只是輸入的文字指令,而是一場實時的、隨性漫談式的對話。」
語音人工智能對延遲和上下文管理提出了更高要求,但它也比文本更能實現開放式、探索性的交互。
隨着基礎模型變得更高效、更廉價且更強大,團隊將精力集中在兩個關鍵槓桿上:記憶力與角色設計。 Portola 構建了一個以角色為驅動的世界,並邀請獲獎動畫師與科幻作家共同構建;同時通過實時上下文管理系統,確保在對話展開的過程中,角色的個性與記憶始終保持連貫。
GPT‑5.1 模型的發佈成為一個關鍵轉折點,它在可控性和延遲方面的顯著提升,將分散的技術環節有機串聯,從而開啓了更具響應感、更自然動人的語音體驗。
「GPT‑5.1 讓我們得以可控地表達出我們心中設想的角色。它不僅更聰明——而且更貼合於我們想要創造的語調和人設。」
——Quinten Farmer,Portola 首席執行官
為自然語音交互而設計
Tolan 的架構設計完全由語音交互的需求所驅動。語音用户期待即時、自然的反饋,即便話題在談話過程中發生轉向也是如此。Tolan 必須在沒有延遲或語氣偏差的情況下,實現快速響應、追蹤話題變化,並保持一致的人設。
為了讓對話感覺自然,需要實現近乎瞬時的低延遲。引入 OpenAI GPT‑5.1 和 Responses API 將語音啓動時間縮短了超過 0.7 秒——足以顯著改善對話流暢度。
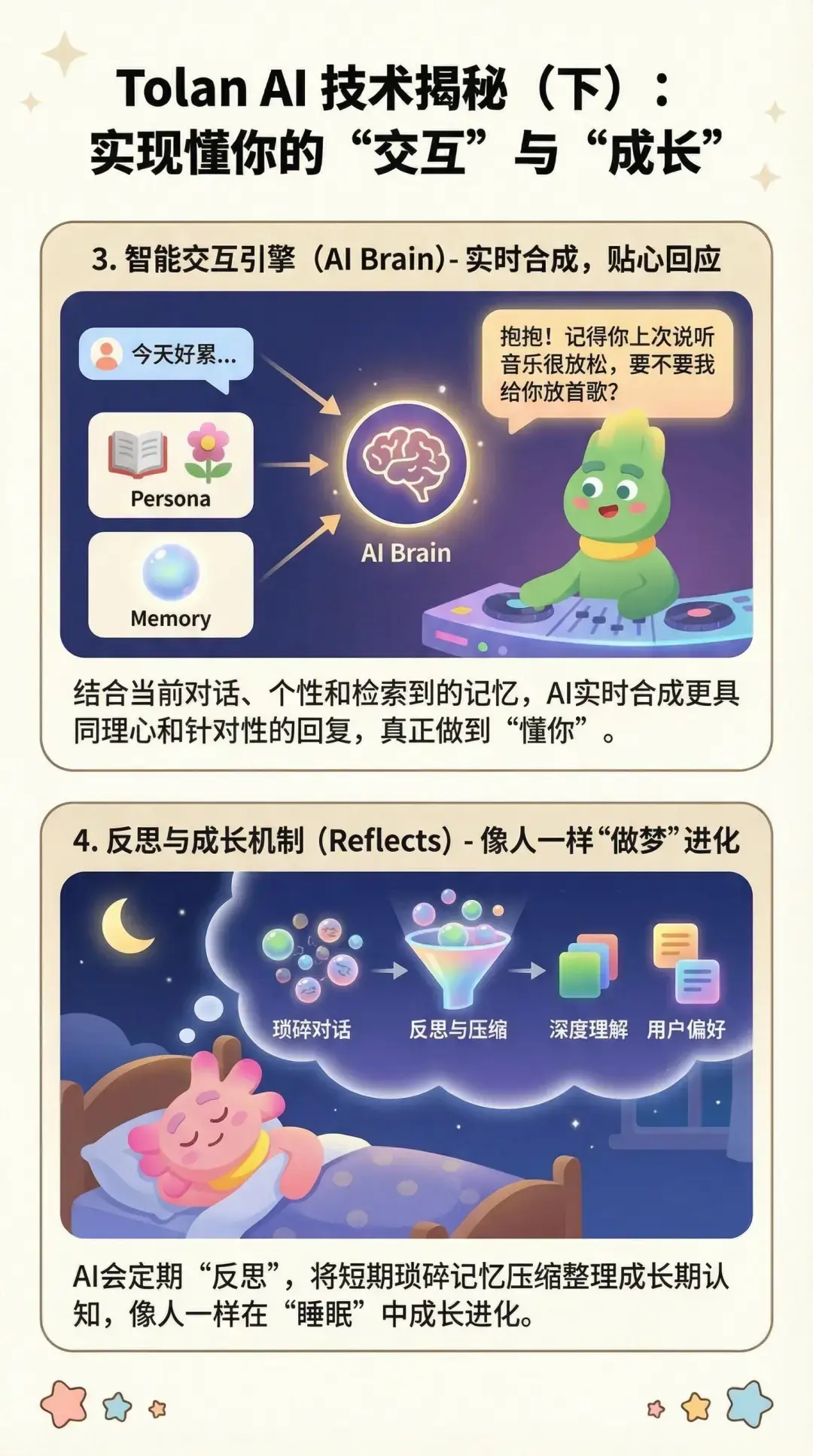
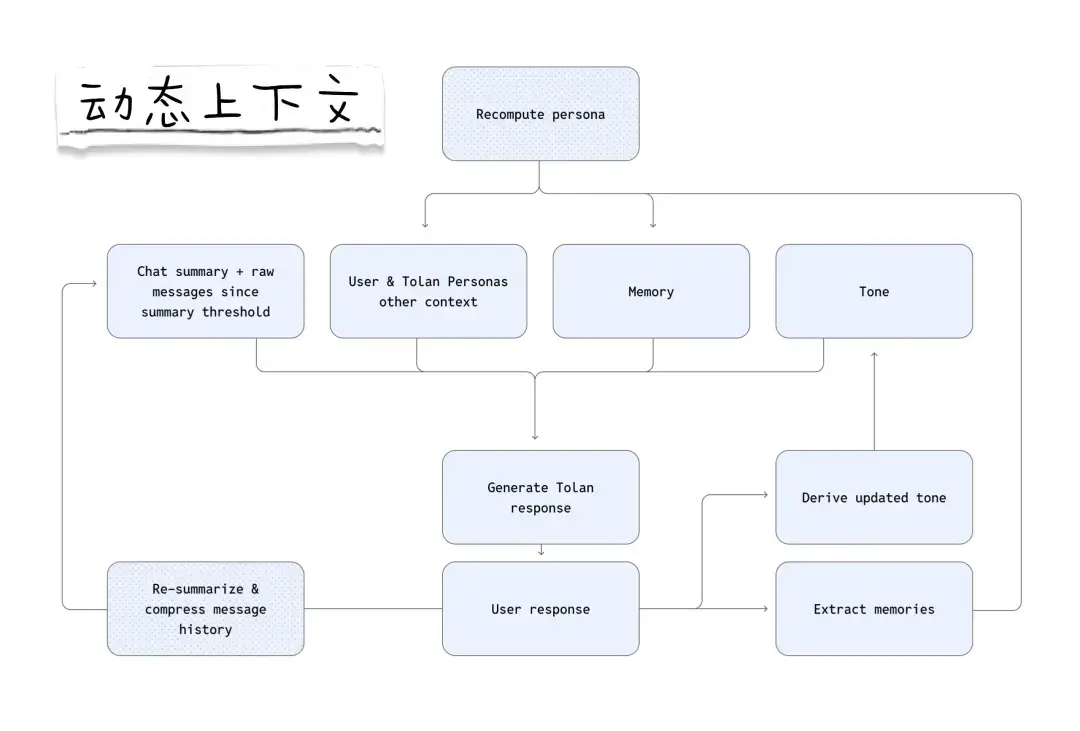
系統對上下文的處理方式也同樣至關重要。與許多跨多輪對話緩存提示詞的智能體不同,Tolan 在每一輪對話中都會從零開始重建其上下文窗口。每次重建都會整合近期消息摘要、人設卡、向量檢索記憶、語調指引以及實時的應用信號。這種架構使 Tolan 能夠實時應對突發的話題轉向,而這正是自然語音交互的核心要求。
「我們很快意識到,緩存提示詞的方法根本行不通,」Quinten 表示。「用户隨時都會切換話題。為了實現無縫的體驗,系統必須具備在對話中途即時調整的能力。」
這種實時重建方法在技術上難度極大,是 Tolan 成功的關鍵。
構建能夠長期維繫的記憶與個性
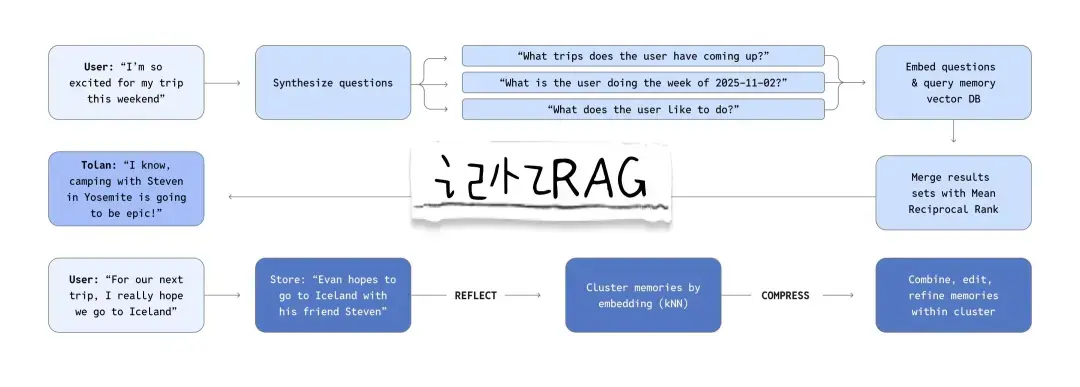
上下文處理很重要,但僅靠它不足以讓對話隨着時間推移仍保持連貫。為了支持長期且非線性的對話,Tolan 構建了一套記憶系統。這套系統不僅能記錄事實和偏好,還能捕捉情感「氛圍」信號——這些線索有助於精準引導 Tolan 的回覆方式。
記憶使用 OpenAI 的 text-embedding-3-large 模型進行嵌入,並存儲在 Turbopuffer 中,這是一個高性能向量數據庫,能夠實現低於 50 毫秒的檢索時間。這樣的速度對於實時語音交互至關重要。每一輪對話中,Tolan 會結合用户的最新消息和系統合成的問題(例如「用户和誰結婚了?」)來觸發記憶回溯。為了保持記憶質量,Tolan 每晚都會運行壓縮任務,刪除低價值或冗餘條目(例如「用户今天喝了咖啡」)並解決記憶中的矛盾之處。
人設的打磨同樣匠心獨運。每個 Tolan 的靈魂都始於一個獨特的角色基石——它由團隊內部的科幻作家執筆,再經由行為專家潤色。這種初始設定既保證了 Tolan 具備穩定的個性一致性,又使其擁有了動態成長的空間,從而能與用户在長期的交互中共同演進。
一套並行系統會實時監測對話的情感基調,並動態調整 Tolan 的表達方式。這使得 Tolan 能夠根據用户的暗示,在俏皮幽默與穩重理性之間無縫切換,同時又不失其核心人設。
向 GPT‑5.1 的過渡是一個轉折點。原本複雜的分層指令——語調腳手架、記憶嵌入和人格特徵——都得到了更精準的遵循。曾經需要通過各種變通方案才能實現的提示詞效果,現在終於能夠完全符合設計初衷。
Quinten 表示:「我們的內部專家第一次感覺到,模型是真的在傾聽。在長對話中,指令始終保持生效,人設特徵得到了充分遵循,我們看到的偏離現象也大大減少了。」
這些改進最終塑造了一個更加連貫且真實的人格,從而帶來了更具吸引力的用户體驗。Tolan 團隊取得了顯著且可量化的成果:記憶檢索失誤率下降了 30%(基於產品內的用户挫敗信號測算);而在基於 GPT-5.1 的角色系統上線後,用户次日留存率提升了 20% 以上。
Tolan 構建自然語音代理的核心原則
隨着 Tolan 的不斷演進,團隊逐漸總結出了幾項核心原則,這些原則如今正指引着其語音架構的構建與更迭:
- 針對對話的多變性進行設計: 語音對話的話題往wa往在半句之間就會發生切換。系統必須能夠同樣迅速地做出轉向,才能讓交互顯得自然。
- 將延遲視為產品體驗的一部分:亞秒級響應速度直接決定了語音助手帶給人的感覺——是具有對話感,還是顯得機械生硬。
- 將記憶構建為檢索系統,而非逐字稿:相比於臃腫的上下文窗口,高質量的壓縮與快速向量檢索能夠帶來更具連貫性的人格表現。
- 每一輪對話都重建上下文:不要試圖通過增加提示詞的長度來對抗偏移(drift)。在話題隨性漫談的過程中,每輪重新生成上下文能讓智能體始終保持穩健。
這些經驗教訓共同構成了 Tolan 下一階段創新的基礎,並指明瞭語音人工智能的發展方向。
拓展語音人工智能的可能性
自 2025 年 2 月上線以來,Tolan 的月活用户已超過 20 萬。其 4.8 星的高分和超過 10 萬條的用户評論,有力地證明了該系統在應對漫長且不斷切換的話題時,能夠極好地保持一致性。一位用户在評論中寫道:「他們記得我們兩天前討論的事情,並能將其自然地帶回到我們今天的對話中。」
這些表現信號直接映射到了其底層架構上:低延遲模型調用、逐輪上下文重構,以及模塊化的記憶與人設系統。這些環節共同協作,使 Tolan 能夠追蹤話題變化、維持語調的一致性,並在不依賴冗長、脆弱的提示詞的情況下,確保回覆內容穩健可靠。
展望未來,Tolan 計劃在可控性和記憶優化方面加大投入,重點發力於更高效的壓縮技術、改進的檢索邏輯以及更廣泛的人設調優。其長期目標是拓展語音交互的邊界:使其不僅具備即時響應性,更擁有深刻的上下文感知與動態對話能力。
「下一個前沿,」Quinten 説,「是構建不僅能迅速響應,而且是真正多模態的語音智能體——它們能夠將語音、視覺與語境整合到一個統一且可控的系統之中。」
原文:https\://openai.com/index/tolan/
編譯:瓚 an、傅豐元


閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
