

雖然通用語音識別模型在大多數場景下表現不錯,但有些時候,面對專業術語、特定口音或私有詞彙時,難免“聽錯”甚至“幻聽”,比如把內部產品代號識別為常見詞,或在方言會議中漏掉關鍵信息。
如果你希望模型更貼合自己的業務場景,微調是一個高效且實用的選擇。通過使用領域內標註數據微調模型(幾百到幾千小時不等),可以提升模型在特定場景、特定領域、特定用户羣體下的識別準確率,讓通用的模型更好地適應具體應用需求。微調後的模型在保持通用能力的同時,在目標場景下表現更優。
為了讓你更輕鬆地定製語音識別能力,我們支持了模型微調的代碼。現在,你可以基於自己的業務數據,一鍵啓動微調流程,快速打造屬於你的“專屬語音識別引擎”。
本文將帶你通過微調 Fun-ASR-Nano,低成本打造貼合業務的專屬語音識別能力。
Fun-ASR-Nano 1分鐘帶你快速回憶
Fun-ASR-Nano-2512 是通義百聆發佈的一款輕量級語音識別模型,總參數量僅0.8B,推理成本低,支持完全本地部署。模型採用端到端架構,開箱即用即可滿足多數通用場景的語音轉寫需求。此外,它支持全參數微調(無需 LoRA),可基於自有語音數據快速適配醫療、金融、客服等垂直領域,打造更貼合業務的識別能力。
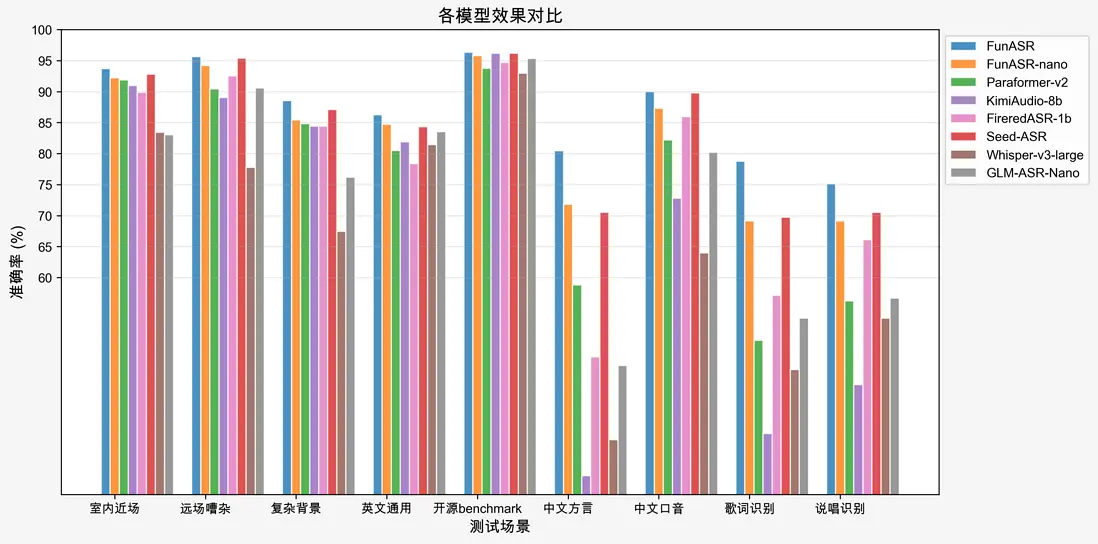
在通用不同場景的測試集中,Fun-ASR-Nano-2512均取得了不錯的準確率指標,達到了商業可用的水平。
訓練環境安裝
Fun-ASR-Nano 模型基於 ModelScope/FunASR `框架進行模型的訓練與微調,在微調模型之前需要安裝該模型訓練框架:
git clone https://github.com/FunAudioLLM/Fun-ASR.git
cd Fun-ASR
pip install -r requirements.txt數據準備
Fun-ASR-Nano 包含了一個參數量為 0.6B 的大語言模型 Qwen/Qwen3-0.6B,其訓練數據遵循 ChatML` (Chat Markup Language) 對話標記語言。
ChatML 是一種結構化的格式,由一系列消息組成,每條消息都包含一個 role和 content,我們模型訓練、微調和測試數據的每一個樣本都包含三條消息,對應三個 role:system,user 和 assistant。
其展開如下所示:
head -n1 data/train_example.jsonl | jq{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "語音轉寫:<|startofspeech|>!https://modelscope.cn/datasets/FunAudioLLM/funasr-demo/resolve/master/audios/IT0011W0002.wav<|endofspeech|>"
},
{
"role": "assistant",
"content": "幾點了?"
}
],
"speech_length": 145,
"text_length": 3
}其中
- system 的 content 固定為 You are a helpful assistant.
-
user 的 content 包含了 prompt 和音頻文件的路徑(位於 <|startofspeech|>!和 <|endofspeech|>之間)。
- prompt 默認為語音轉寫:或Speech transcription:
- 可以結合對應的語種為語音轉寫成英文:或Transcribe speech into Chinese:
- 當音頻文件對應的文本標註不含阿拉伯數字或者標點符號時,可以使用語音轉寫,不進行文本規整:或 Speech transcription without text normalization:
- assistant 的 content 對應音頻文件對應的文本標註
- speech_length:音頻文件的 fbank 幀數(一幀 10ms)
- text_length:音頻文件標註文本的 token 數 (用 Qwen/Qwen3-0.6B編碼)
我們提供了數據格式轉換工具 scp2jsonl.py,可以將常見的語音識別訓練數據格式 wav scp 和 transcription 轉成 ChatML 格式。
👉data/train\_wav.scp
head -n1 data/train_wav.scp
IT0011W0002 https://modelscope.cn/datasets/FunAudioLLM/funasr-demo/resolve/master/audios/IT0011W0002.wav👉data/train\_text.txt
head -n1 data/train_text.txt
IT0011W0002 幾點了?python tools/scp2jsonl.py \
++scp_file=data/train_wav.scp \
++transcript_file=data/train_text.txt \
++jsonl_file=data/train_example.jsonlwav scp 和 transcription 文件都是由兩列組成,兩個文件根據第一列 (Utterance ID) 一一對應,第二列分別是音頻文件的路徑和音頻文件的文本標註。
啓動訓練
截止目前,我們開源的模型主要包含 audio_encoder,audio_adaptor 和 llm 模塊。因此需要確認待微調的模塊有哪些,進而修改 finetune.sh腳本中的對應參數:
- audio_encoder_conf.freeze:false表示微調 audio_encoder
- audio_adaptor_conf.freeze:false表示微調 audio_adaptor
- llm_conf.freeze:false表示微調 llm
推薦配置
- 訓練數據少於 1000 小時,建議微調 audio_adaptor
- 訓練數據少於 5000 小時,建議微調 audio_encoder和audio_adaptor
- 訓練數據大於 10000 小時,建議全量參數微調
接下來即可運行微調腳本:
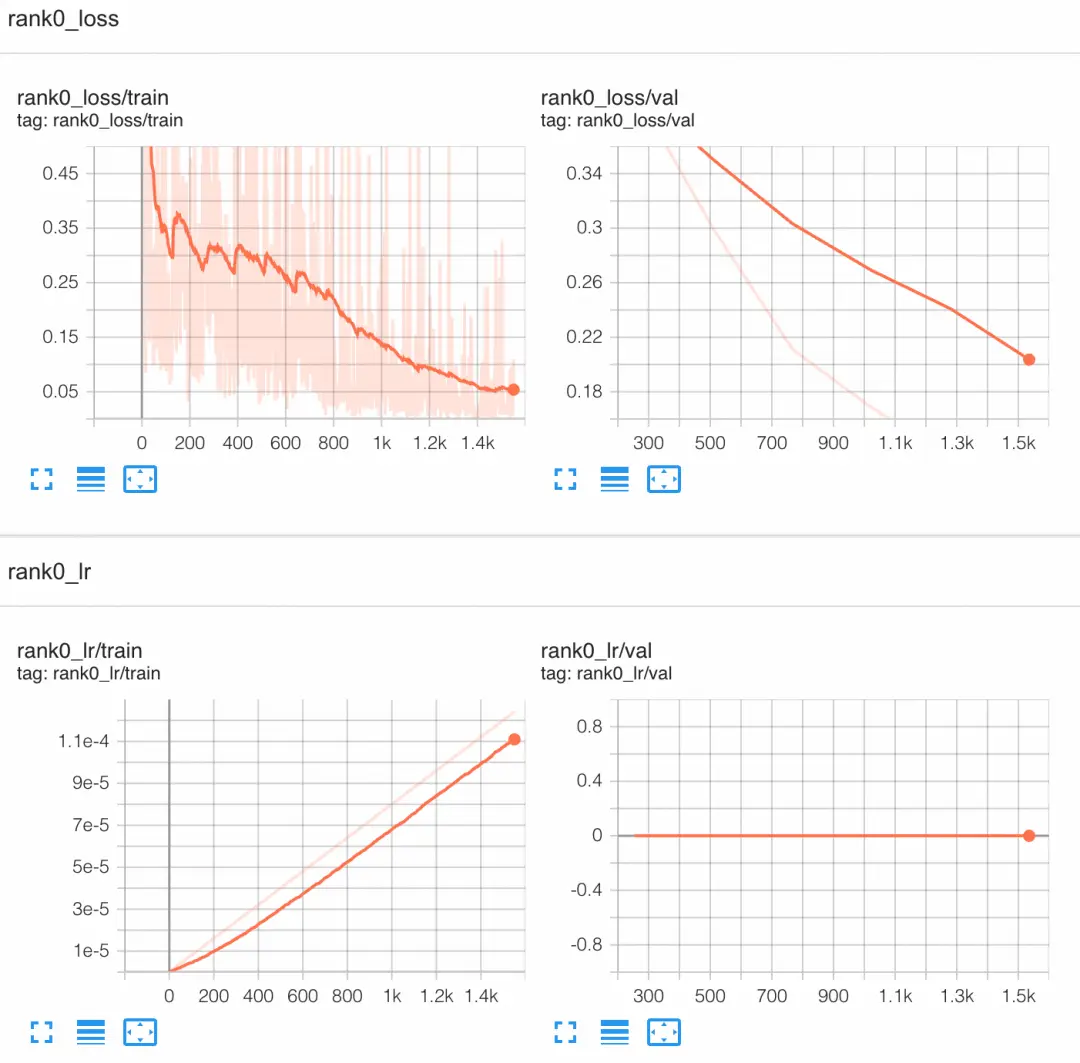
bash finetune.shTensorboard 可視化
tensorboard --logdir outputs/tensorboard瀏覽器中打開:http://localhost:6006/
模型測評
當模型微調結束後,可以使用 decode.py 腳本對模型進行解碼:
python decode.py \
++model_dir=/path/to/finetuned \
++scp_file=data/val_wav.scp \
++output_file=output.txt解碼結束後,需要對標註和識別結果做文本逆歸一化,然後計算 WER:
python tools/whisper_mix_normalize.py data/val_text.txt data/val_norm.txt
python tools/whisper_mix_normalize.py output.txt output_norm.txt
compute-wer data/val_norm.txt output_norm.txt cer.txt
tail -n8 cer.txt相信通過本文的指引,你已經瞭解瞭如何通過微調 Fun-ASR-Nano 來打造專屬的語音識別能力。無論是醫療術語、法律條文,還是企業內部的專業詞彙,都可以通過簡單的數據準備和訓練流程,讓模型真正"聽懂"你的業務語言。
現在就動手試試吧!從 GitHub 克隆代碼開始,體驗打造專屬語音識別引擎的完整流程。
開源地址魔搭、HuggingFace、GitHub
https://github.com/FunAudioLLM/Fun-ASR(GitHub)
https://funaudiollm.github.io/funasr/(GitHub.io)
https://modelscope.cn/studios/FunAudioLLM/Fun-ASR-Nano/(國內...
https://huggingface.co/spaces/FunAudioLLM/Fun-ASR-Nano(海外...
https://modelscope.cn/models/FunAudioLLM/fun-asr-nano-2512(...
https://huggingface.co/FunAudioLLM/Fun-ASR-Nano-2512(海外模...


閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
