









MySQL有兩個kill命令:
-
kill query+線程id,表示終止該線程正在執行的語句;
-
kill (connection)+線程id,表示斷開這個線程的連接,如果線程有語句正在執行,會先停止正在執行的語句。
有時候可能會遇到:使用了kill,卻沒能斷開該連接,再執行show processlist時,看到這條語句的command列顯示的是killed。
那這是什麼意思呢?不是應該直接在show processlist結果裏看不到這個線程了嗎?本文就來討論該問題。
收到kill後,線程做什麼?
比如有一個場景:
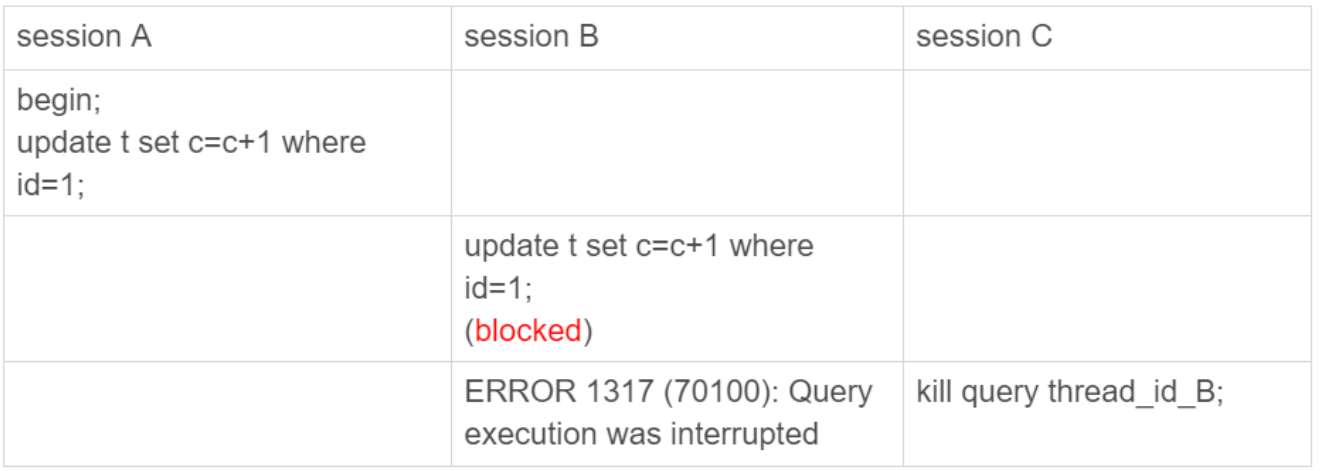
session C執行kill query後,session B幾乎同時提示了語句被中斷,這是預期結果。那麼session B是直接終止掉線程,什麼都不管直接退出嗎?
不是的,session在處於blocked狀態時,還是拿着一個MDL讀鎖的,如果kill時直接終止,該讀鎖就沒機會釋放。這樣看的話,kill並不是馬上停止的意思,而是告訴執行線程該語句已經不需要繼續執行,可以開始“執行停止邏輯”了。
當session C執行kill語句,MySQL裏處理kill命令的線程會做兩件事:
-
將session B的運行狀態改成THD::KILL_QUERY(將變量killed賦值為THD::KILL_QUERY);
-
給session B的執行線程發一個信號,目的是讓session B退出鎖等待,來處理THD::KILL_QUERY狀態。
上面的分析隱含了一些意思:
-
一個語句執行過程中有多處埋點,在這些埋點地方判斷線程狀態,如果發現狀態時THD::KILL_QUERY,才開始進入語句終止邏輯;
-
如果處於等待狀態,必須是一個可以被喚醒的等待,否則不會執行到埋點處;
-
語句從開始進入終止邏輯,到終止邏輯完全完成,是有一個過程的。
接下來看一個kill不掉的例子。首先執行set global innodb_thread_concurrency=2,將InnoDB併發線程上限數設置為2,然後執行下面的序列:

-
session C執行時blocked;
-
session D的kill query C沒產生效果;
-
session E執行kill connection,才斷開session C的連接;
-
但若此時在session E執行show processlist,結果如下:

此時id=12的command列顯示killed,説明客户端雖然斷開了連接,但實際服務端上這條語句還在執行過程中。
這裏為什麼和第一個例子不同呢?
在實現上,等待行鎖使用的是pthread_cond_timedwait函數,該等待狀態可以被喚醒。但這裏12號線程的等待邏輯是每10毫秒判斷是否可以進入InnoDB執行,如果不行就調用nanosleep函數進入sleep狀態。也就是説,雖然12號線程狀態已被設置為KILL_QUERY,但在等待進入InnoDB循環的過程中,並未判斷線程的狀態,因此不會進入終止邏輯階段。
當session E執行kill connection時:
-
將12號線程狀態設置為KILL_CONNECTION;
-
關掉12號線程的網絡連接,因此session C會收到斷開連接的提示。
那為什麼show processlist時能看到command顯示killed呢?是因為執行show processlist時有一個特別的邏輯:如果一個線程的狀態是KILL_CONNECTION,就把command列顯示為killed。所以即使客户端退出,該線程的狀態仍然是在等待中。
只有等到滿足進入InnoDB的條件後,session C的查詢語句繼續執行,然後才有可能判斷到線程狀態已經變成KILL_QUERY或KILL_CONNECTION,再進入終止邏輯階段,線程才會退出。
該例子是kill無效的第一類情況,即線程沒有執行到判斷線程狀態的邏輯。相同情況的還有因為IO壓力過大,讀寫IO的函數一直無法返回,導致不能及時判斷線程狀態。
另一類情況是終止邏輯耗時較長,這時從show processlist結果上看也是command=killed,需要等到終止邏輯完成,語句才算真正完成,這類情況常見場景有以下幾種:
-
超大事務執行期間被kill,此時回滾需要對事務執行期間所有新數據版本做回收,耗時很長;
-
大查詢回滾,刪除查詢過程生成的大臨時文件,加上此時文件系統壓力大,該過程可能需要等待IO資源,導致耗時很長;
-
DDL命令執行到最後階段被kill,需要刪除中間過程的臨時文件,也可能受IO資源影響耗時較久。
關於客户端的誤解
第一個誤解是,如果直接在客户端Ctrl+C,是否可以直接終止線程呢?
答案是不可以的,在客户端的操作只能操作到客户端的線程,而客户端和服務端只能通過網絡交互,是不可能直接操作服務端線程的。實際執行Ctrl+C時,是MySQL客户端另外啓動一個連接,然後發送一個kill query命令。
第二個誤解是,如果庫裏面的表特別多,連接就會很慢。
很多人會認為是表的數目影響了連接性能,但從第一篇文章就知道,客户端和服務端建立連接的時候,需要做的就是TCP握手、用户校驗、獲取權限,這些操作跟表的個數無關。實際上,當使用默認參數連接時,MySQL客户端會提供本地庫名和表名補全的功能,為實現這個功能,客户端連接成功後,需要多做一些操作:
-
執行show databases;
-
切到庫執行show tables;
-
將這兩個命令的結果用於構建一個本地的哈希表。
當一個庫中表個數非常多,第三步就會花很長時間。因此,感知到的連接過程慢,不是連接慢和服務端慢,而是客户端慢。
這裏自動補全效果是在輸入庫名或表名時,輸入前綴,可以使用Tab補全。在連接命令中加上-A,可以關掉這個自動補全功能,因此如果自動補全用得不多,建議關掉。
另外,除了加-A,加-quick(簡寫-q),也可以跳過這個階段。
第三個誤解,就是關於-quick這個參數。
從字面上看,會覺得這是一個讓服務端加速的參數,但實際上設置這個參數可能會降低服務端的性能。
MySQL客户端發送請求後,接收服務端返回結果方式有兩種:
-
一種是本地緩存,即在本地開一片內存,先存結果;
-
另一種是不緩存,讀一個處理一個。
MySQL客户端默認採用第一種,加上-quick後就會使用第二種。此時如果本地處理得慢,就會導致服務端發送結果被阻塞,因此會讓服務端變慢。
因此,-quick是讓客户端變得更快,而不是讓服務端變得更快。


