


RowKindExtractor 是 Apache SeaTunnel 的一個轉換插件,它能將 CDC 數據流轉為 Append-Only 模式,並提取原始 RowKind 信息為新字段。本文將介紹 RowKindExtractor 的核心功能,其在 CDC 數據同步場景下的使用方法,以及配置選項、注意事項及多種應用示例。
RowKindExtractor
RowKindExtractor 轉換插件用於將 CDC(Change Data Capture)數據流轉換為 Append-Only(僅追加)模式,同時將原始的 RowKind 信息提取為一個新的字段。
核心功能:
- 將所有數據行的 RowKind 統一改為 +I(INSERT),實現 Append-Only 模式
- 將原始的 RowKind 信息(INSERT、UPDATE_BEFORE、UPDATE_AFTER、DELETE)保存到新增的字段中
- 支持短格式和完整格式兩種輸出方式
為什麼需要這個插件?
在 CDC 數據同步場景中,數據行帶有 RowKind 標記(+I、-U、+U、-D),表示不同的變更類型。但某些下游系統(如數據湖、分析系統)只支持 Append-Only 模式,不支持 UPDATE 和 DELETE 操作。此時需要:
- 將所有數據轉換為 INSERT 類型(Append-Only)
- 將原始的變更類型保存為普通字段,供後續分析使用
轉換示例:
輸入(CDC 數據):
RowKind: -D (DELETE)
數據: id=1, name="test1", age=20
輸出(Append-Only 數據):
RowKind: +I (INSERT)
數據: id=1, name="test1", age=20, row_kind="DELETE"
典型應用場景:
- 將 CDC 數據寫入只支持 Append 的數據湖
- 需要在數據倉庫中保留完整的變更歷史記錄
- 需要對不同類型的變更進行統計分析
配置選項
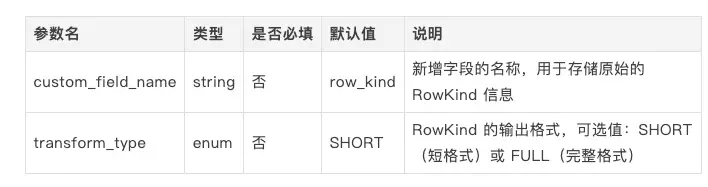
custom_field_name [string]
指定新增字段的名稱,該字段用於存儲原始的 RowKind 信息。
默認值:row_kind
注意事項:
- 字段名不能與原有字段重名,否則會報錯
- 建議使用有意義的名稱,如 operation_type、change_type、cdc_op 等
示例:
custom_field_name = "operation_type" # 使用自定義字段名transform_type [enum]
指定 RowKind 字段值的輸出格式。
可選值:

默認值:SHORT
各值含義:
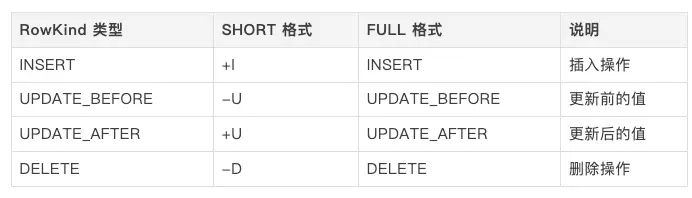
選擇建議:
- SHORT 格式:節省存儲空間,適合對存儲敏感的場景
- FULL 格式:可讀性更好,適合需要人工查看或分析的場景
示例:
transform_type = FULL # 使用完整格式完整示例
- 示例 1:使用默認配置(SHORT 格式)
使用默認配置,將 CDC 數據轉換為 Append-Only 模式,RowKind 以短格式保存。
env {
parallelism = 1
job.mode = "STREAMING"
}
source {
MySQL-CDC {
plugin_output = "cdc_source"
server-id = 5652
username = "root"
password = "your_password"
table-names = ["mydb.users"]
url = "jdbc:mysql://localhost:3306/mydb"
}
}
transform {
RowKindExtractor {
plugin_input = "cdc_source"
plugin_output = "append_only_data"
# 使用默認配置:
# custom_field_name = "row_kind"
# transform_type = SHORT
}
}
sink {
Console {
plugin_input = "append_only_data"
}
}數據轉換過程:
輸入數據(CDC 格式):
1. RowKind=+I, id=1, name="張三", age=25
2. RowKind=-U, id=1, name="張三", age=25
3. RowKind=+U, id=1, name="張三", age=26
4. RowKind=-D, id=1, name="張三", age=26
輸出數據(Append-Only 格式):
1. RowKind=+I, id=1, name="張三", age=25, row_kind="+I"
2. RowKind=+I, id=1, name="張三", age=25, row_kind="-U"
3. RowKind=+I, id=1, name="張三", age=26, row_kind="+U"
4. RowKind=+I, id=1, name="張三", age=26, row_kind="-D"- 示例 2:使用 FULL 格式和自定義字段名
使用完整格式輸出 RowKind,並自定義字段名稱。
env {
parallelism = 1
job.mode = "STREAMING"
}
source {
MySQL-CDC {
plugin_output = "cdc_source"
server-id = 5652
username = "root"
password = "your_password"
table-names = ["mydb.orders"]
url = "jdbc:mysql://localhost:3306/mydb"
}
}
transform {
RowKindExtractor {
plugin_input = "cdc_source"
plugin_output = "append_only_data"
custom_field_name = "operation_type" # 自定義字段名
transform_type = FULL # 使用完整格式
}
}
sink {
Iceberg {
plugin_input = "append_only_data"
catalog_name = "iceberg_catalog"
database = "mydb"
table = "orders_history"
# Iceberg 表會包含 operation_type 字段,記錄每條數據的變更類型
}
}數據轉換過程:
輸入數據(CDC 格式):
1. RowKind=+I, order_id=1001, amount=100.00
2. RowKind=-U, order_id=1001, amount=100.00
3. RowKind=+U, order_id=1001, amount=150.00
4. RowKind=-D, order_id=1001, amount=150.00
輸出數據(Append-Only 格式,FULL 格式):
1. RowKind=+I, order_id=1001, amount=100.00, operation_type="INSERT"
2. RowKind=+I, order_id=1001, amount=100.00, operation_type="UPDATE_BEFORE"
3. RowKind=+I, order_id=1001, amount=150.00, operation_type="UPDATE_AFTER"
4. RowKind=+I, order_id=1001, amount=150.00, operation_type="DELETE"- 示例 3:完整的測試示例(使用 FakeSource)
使用 FakeSource 生成測試數據,演示各種 RowKind 的轉換效果。
env {
parallelism = 1
job.mode = "BATCH"
}
source {
FakeSource {
plugin_output = "fake_cdc_data"
schema = {
fields {
pk_id = bigint
name = string
score = int
}
primaryKey {
name = "pk_id"
columnNames = [pk_id]
}
}
rows = [
{
kind = INSERT
fields = [1, "A", 100]
},
{
kind = INSERT
fields = [2, "B", 100]
},
{
kind = UPDATE_BEFORE
fields = [1, "A", 100]
},
{
kind = UPDATE_AFTER
fields = [1, "A_updated", 95]
},
{
kind = UPDATE_BEFORE
fields = [2, "B", 100]
},
{
kind = UPDATE_AFTER
fields = [2, "B_updated", 98]
},
{
kind = DELETE
fields = [1, "A_updated", 95]
}
]
}
}
transform {
RowKindExtractor {
plugin_input = "fake_cdc_data"
plugin_output = "transformed_data"
custom_field_name = "change_type"
transform_type = FULL
}
}
sink {
Console {
plugin_input = "transformed_data"
}
}預期輸出:
+I, pk_id=1, name="A", score=100, change_type="INSERT"
+I, pk_id=2, name="B", score=100, change_type="INSERT"
+I, pk_id=1, name="A", score=100, change_type="UPDATE_BEFORE"
+I, pk_id=1, name="A_updated", score=95, change_type="UPDATE_AFTER"
+I, pk_id=2, name="B", score=100, change_type="UPDATE_BEFORE"
+I, pk_id=2, name="B_updated", score=98, change_type="UPDATE_AFTER"
+I, pk_id=1, name="A_updated", score=95, change_type="DELETE"