

這是Java19新增的預覽版功能,到Java21正式可以使用
簡介
虛擬線程是一種用户態下的線程,類似go語言中的goroutines 和Erlang中的processes,虛擬線程並非比線程快,而是提高了應用的吞吐量,相比於傳統的線程是由操作系統調度來看,虛擬線程是我們自己程序調度的線程。如果你對之前java提供的線程API比較熟悉了,那麼在學習虛擬線程的時候會比較輕鬆,傳統線程能運行的代碼,虛擬線程也可以運行。虛擬線程的出現,並沒有修改java原有的併發模型,也不會替代原有的線程。虛擬線程主要作用是提升服務器端的吞吐量。
為什麼要有虛擬線程
服務器應用程序的伸縮性受利特爾法則(Little’s Law)的制約,與下面3點有關
-
延遲:請求處理的耗時
-
併發量:同一時刻處理的請求數量
-
吞吐量:單位時間內處理的數據數量
比如一個服務器應用程序的延遲是50ms,處理10個併發請求,則吞吐量是200請求/秒(10 / 0.05),如果吞吐量要達到2000請求/秒,則處理的併發請求數量是100。按照1個請求對應一個線程的比例來看,要想提高吞吐量,線程數量也要增加。
java中的線程是在操作系統線程(OS thread)進行了一層包裝(目前大部分語言實現採用的線程模型,都是用户態的線程一對一映射到內核線程上,好處是實現簡單,統一由操作系統負責調度),OS線程的優點是它足夠通用,不管是什麼語言/什麼應用場景,但OS線程的問題也正是來自於此:
- OS不知道用户態的程序會如何使用線程,它會給每條線程分配一個固定大小的堆棧,通常會比實際使用的要大很多;
- 線程的上下文切換要通過內核調度進行,相對更慢;
- 線程的調度算法需要做兼顧和妥協,很難做特定的優化,像web server中處理請求的線程和視頻編解碼的線程行為有很大的區別;
為了解決該問題,虛擬線程就出現了。也就是多對多的線程模型:經典的就是Erlang的進程和Go的goroutine,M:N 的映射關係,大量(M)虛擬的線程被調度在較少數量(N)的操作系統線程上運行。用户態的運行時負責調度用户態線程,OS則只需要負責OS線程,各司其職。靈活度更高,開發者基本不用擔心線程數爆炸的問題。
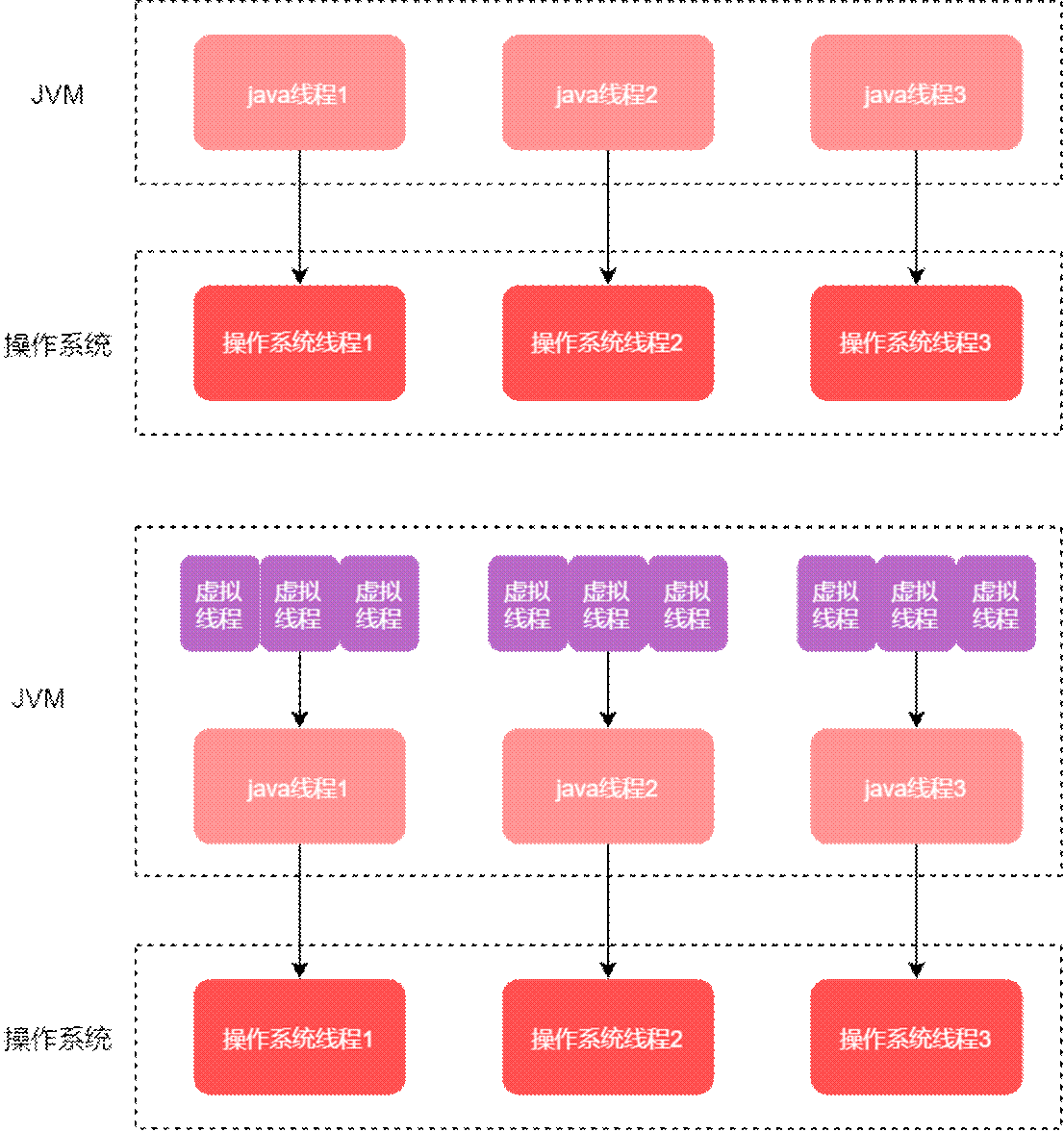
與虛擬地址可以映射到物理內存類似,java是將大量的虛擬線程映射到少量的操作系統線程,帶來了一些好處:
- 線程的切換很快,無需系統調用和系統級別的上下文切換
- 分配線程的開銷很低:一方面是創建和銷燬很快,另一方面內存使用也更少
- 競態條件和線程同步處理起來更簡單
- 且虛擬線程的生命週期短暫,不會有很深的棧的調用
- 一個虛擬線程的生命週期中只運行一個任務,因此可以創建大量的虛擬線程,
- 虛擬線程無需池化
另一方面,虛擬線程不能帶來什麼?
要意識到虛擬線程是更輕量的線程,但並不是"更快"的線程,它每秒執行的CPU指令並不會比普通線程要多。假設有這樣一個場景,需要同時啓動10000個任務做一些事情:
// 創建一個虛擬線程的Executor,該Executor每執行一個任務就會創建一個新的虛擬線程
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10_000).forEach(i -> {
executor.submit(() -> {
doSomething();
return i;
});
});
} // executor.close() is called implicitly, and waits
考慮兩種場景:
-
如果doSomething()裏執行的是某類IO操作,那麼使用虛擬線程是非常合適的,因為虛擬線程創建和切換的代價很低,底層對應的可能只需要幾個OS線程。如果沒有虛擬線程,不考慮ForkJoin之類的工具,使用普通線程的話:
-
- Executors.newVirtualThreadPerTaskExecutor()換成Executors.newCachedThreadPool()。結果是程序會崩潰,因為大多數操作系統和硬件不支持這種規模的線程數。
- 換成Executors.newFixedThreadPool(200)或者其他自定義的線程池,那這10000個任務將會共享200個線程,許多任務將按順序運行而不是同時運行,並且程序需要很長時間才能完成。
-
如果doSomething()裏執行的是某類計算任務,例如給一個大數組排序,那麼虛擬線程反而還可能帶來多餘的開銷。
總結一下,虛擬線程真正擅長的是等待,等待大量阻塞操作完成。它能提供的是 scale(更高的吞吐量),而不是 speed(更低的延遲)。虛擬線程最適合的是原來需要更多線程數來處理計算無關業務的場景,典型的就是像web容器、數據庫、文件操作一類的IO密集型的應用。
虛擬線程的理解
平台線程和虛擬線程
平台線程(platform thread):指Java中的線程,比如通過Executors.newFixedThreadPool()創建出來的線程,我們稱之為平台線程。
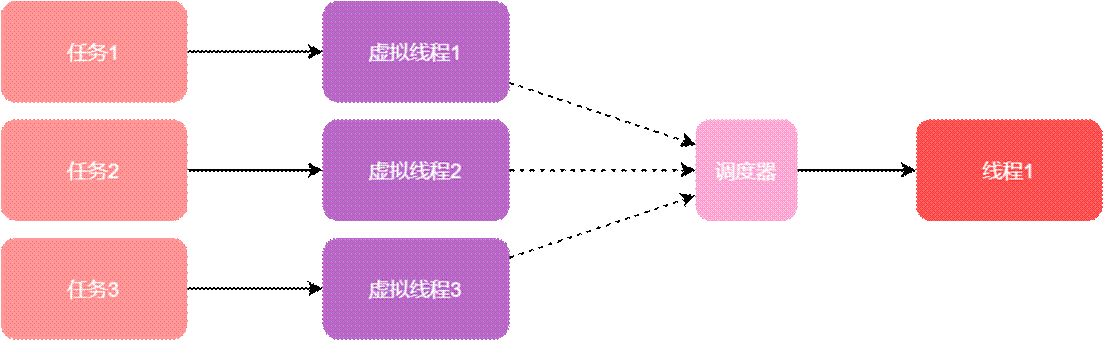
虛擬線程並不會直接分配給cpu去執行,而是通過調度器分配給平台線程,平台線程再被調度器管理。Java中虛擬線程的調度器採用了工作竊取的模式進行FIFO的操作,調度器的並行數默認是Jvm獲取的處理器數量(通過該方法獲取的數量Runtime.getRuntime().availableProcessors()),調度器並非分時(time sharing)的。在使用虛擬線程編寫程序時,不能控制虛擬線程何時分配給平台線程,也不能控制平台線程何時分配給cpu。
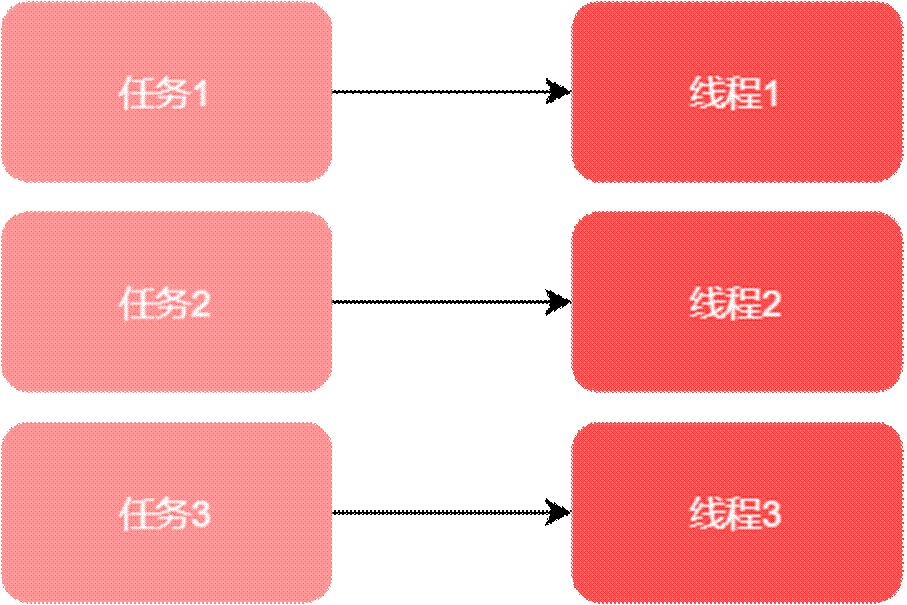
以前任務和平台線程的關係:
使用虛擬線程之後,任務-虛擬線程-調度器-平台線程的關係,1個平台線程可以被調度器分配不同的虛擬線程:
攜帶器
調度器將虛擬線程掛載到平台線程之後,該平台線程叫做虛擬線程的攜帶器(言外之意就是,平台線程攜帶着虛擬線程),調度器並不維護虛擬線程和攜帶器之間的關聯關係,因此在一個虛擬線程的生命週期中可以被分配到不同的攜帶器,即虛擬線程運行了一小段代碼後,可能會脱離攜帶器,此時其他的虛擬線程會被分配到這個攜帶器上。
攜帶器和虛擬線程是相互獨立的,比如:
-
虛擬線程不能使用攜帶器的標識,Thread.current()方法獲取的是虛擬線程本身。
-
兩者有各自的棧空間。
-
兩者不能訪問對方的Thread Local變量。
在程序的執行過程中,虛擬線程遇到阻塞的操作時大部分情況下會被解除掛載,阻塞結束後,虛擬線程會被調度器重新掛載到攜帶器上,因此虛擬線程會頻繁的掛載和解除掛載,這並不會導致操作系統線程的阻塞。下面的代碼在執行兩個get方法和send方法(會有io操作)時會使虛擬線程發生掛載和解除掛載:
response.send(future1.get() + future2.get());
有些阻塞操作並不會導致虛擬線程解除掛載,這樣會同時阻塞攜帶器和操作系統線程,例如:操作系統基本的文件操作,java中的Object.wait()方法。下面兩種情況不會導致虛擬線程的解除掛載:
- 執行synchronized同步代碼(會導致攜帶器阻塞,所以建議使用ReentrantLock替換掉synchronized)
- 執行本地方法或外部函數
虛擬線程和平台線程的區別
從內存空間上來説,虛擬線程的棧空間可以看作是一個大塊的棧對象,它被存儲在了java堆中,相比於單獨存儲對象,堆中存儲虛擬線程的棧會造成一些空間的浪費,這點在後續的java版本中應該會得到改善,當然這樣也是有一些好處的,就是可以重複利用這部分棧空間,不用多次申請開闢新的內存地址。虛擬線程的棧空間最大可以達到平台線程的棧空間容量。
虛擬線程並不是GC root,其中的引用不會出現stop-world,當虛擬線程被阻塞之後比如BlockingQueue.take(),平台線程既不能獲取到虛擬線程,也不能獲取到queue隊列,這樣該平台線程可能會被回收掉,虛擬線程在運行或阻塞時不會被GC
-
通過Thread構造方法創建的線程都是平台線程
-
虛擬線程是守護線程,不能通過setDaemon方法改成非守護線程
-
虛擬線程的優先級是默認的5,不能被修改,將來的版本可能允許修改
-
虛擬線程不支持stop(),suspend(),resume()方法
使用虛擬線程
java中創建的虛擬線程本質都是通過Thread.Builder.OfVirtual對象進行創建的,虛擬線程的API非常非常簡單,在設計上與現有的Thread類完全兼容。虛擬線程創建出來後也是Thread實例,因此很多原先的代碼可以無縫遷移。創建虛擬線程有三種方式:
- 通過Thread.startVirtualThread直接創建一個虛擬線程
//創建任務
Runnable task = () -> {
System.out.println("執行任務");
};
//創建虛擬線程將任務task傳入並啓動
Thread.startVirtualThread(task);
//主線程睡眠,否則可能看不到控制枱的打印
TimeUnit.SECONDS.sleep(1);
- 使用Thread.ofVirtual()方法創建
//創建任務
Runnable task = () -> {
System.out.println(Thread.currentThread().getName());
};
//創建虛擬線程命名為諾手,將任務task傳入
Thread vt1 = Thread.ofVirtual().name("諾手").unstarted(task);
vt1.start();//啓動虛擬線程
//主線程睡眠,否則可能看不到控制枱的打印
TimeUnit.SECONDS.sleep(1);
- 通過ExecutorService創建,為每個任務分配一個虛擬線程,下面代碼中提交了100個任務,對應會有100個虛擬線程進行處理。
/*
通過ExecutorService創建虛擬線程
ExecutorService實現了AutoCloseable接口,可以自動關閉了
*/
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
//向executor中提交100個任務
IntStream.range(0, 100).forEach(i -> {
executor.submit(() -> {
//睡眠1秒
try {
Thread.sleep(Duration.ofSeconds(1));
System.out.println(i);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
});
}
現在平台線程和虛擬線程都是Thread的對象,那該如何區分該對象是平台線程還是虛擬線程?可以利用Thread中的isVirtual()方法進行判斷,返回true表示虛擬線程:
//創建任務
Runnable task = () -> {
System.out.println("執行任務");
};
//創建虛擬線程將任務task傳入並啓動
Thread vt = Thread.startVirtualThread(task);
System.out.println(vt.isVirtual());
性能對比
public void tryCreateInfiniteThreads() {
var adder = new LongAdder();
Runnable job = () -> {
adder.increment();
System.out.println("Thread count = " + adder.longValue());
LockSupport.park();
};
// 啓動普通線程
startThreads(() -> new Thread(job));
// 或是啓動虛擬線程
startThreads(() -> Thread.ofVirtual().unstarted(job));
}
public void startThreads(Supplier<Thread> threadSupplier) {
while (true) {
Thread thread = threadSupplier.get();
thread.start();
}
}
普通線程:創建到4064個線程後程序報OOM錯誤崩潰。
.......
Thread count = 4063
Thread count = 4064
[0.927s][warning][os,thread] Failed to start thread "Unknown thread" - pthread_create failed (EAGAIN) for attributes: stacksize: 1024k, guardsize: 4k, detached.
[0.927s][warning][os,thread] Failed to start the native thread for java.lang.Thread "Thread-4064"
Exception in thread "main" java.lang.OutOfMemoryError: unable to create native thread: possibly out of memory or process/resource limits reached
at java.base/java.lang.Thread.start0(Native Method)
at java.base/java.lang.Thread.start(Thread.java:1535)
at com.rhino.vt.VtExample.startThread(VtExample.java:24)
at com.rhino.vt.VtExample.main(VtExample.java:13)
虛擬線程:創建了超過360萬個虛擬線程後被掛起,但沒有崩潰,虛擬線程的計數一直在緩慢增長,這是因為被 park 的虛擬線程會被垃圾回收,然後 JVM 能夠創建更多的虛擬線程並將其分配給底層的平台線程。
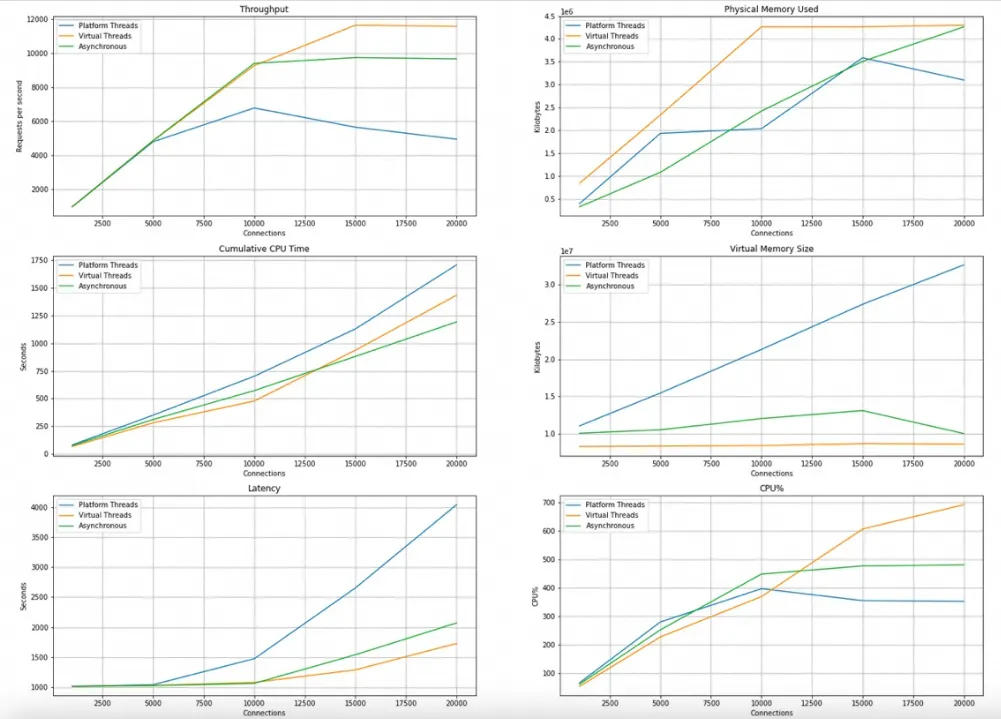
Github上有位老哥做了個更接近真實場景的測試,模擬遠程服務請求數據,比較了使用普通線程阻塞式請求、CompletableFeature異步請求、虛擬線程的三種方式的差異,結果顯示在連接數少的時候三者差別不大,連接數上去後虛擬線程在吞吐量、內存佔用、延遲、CPU佔用率方面都有比較大的優勢,如下圖:
可能這麼對比還是不夠公平,畢竟一般我們不會直接用這麼簡單的異步編程,還是會通過各種框架輪子搞。Oracle 的Helidon Níma 號稱是第一個採用了虛擬線程的微服務框架,主要的賣點也是性能,可以參考其QPS性能測試數據:
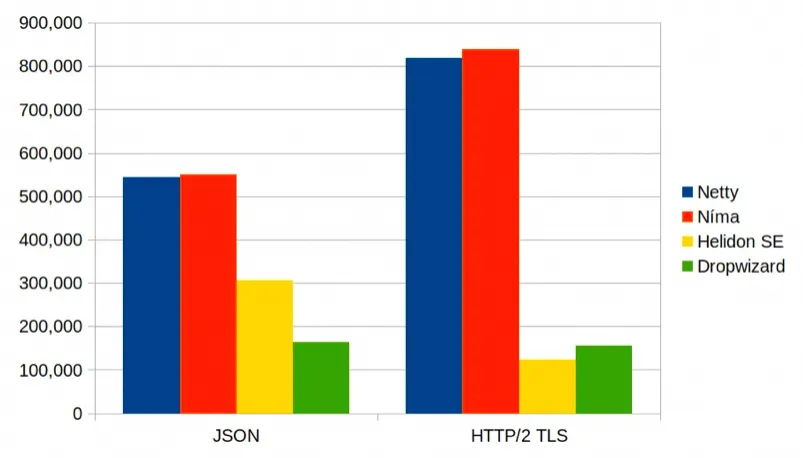
可以看到使用了虛擬線程的web服務器性能很好,與用Netty的差距很小,這也符合預期。相比起來虛擬線程使用起來更簡單。
深入虛擬線程
thread = continuation + scheduler
回過頭來討論下:到底什麼是"線程"?簡單的定義是,"線程"是順序執行的一系列計算機指令。由於我們處理的操作可能不僅涉及計算,還涉及 IO、定時暫停和同步等,線程會有包括運行、阻塞、等待在內的各種狀態,並在狀態之間調度流轉。當一個線程阻塞或等待時,它應該騰出計算資源(CPU內核),並允許另一個線程運行,然後在等待的事件發生時恢復執行。這其中涉及到兩個概念:
- continuation(這個詞實在不知道怎麼翻譯才恰當):一系列順序執行的指令序列,可能會暫停或阻塞,然後恢復執行;
- scheduler:顧名思義,負責協調調度線程的機制;
兩者是獨立的,因此我們可以選擇不同的實現。之前的普通線程,在VM層面僅僅是對OS線程的一層簡單封裝,continuation和scheduler都是交給OS管理,而虛擬線程實現則是在VM裏完成這兩件事情,當然底層還是需要有相應的OS線程作為載體線程(CarrierThread),並且這個對應並不是固定不變的,在虛擬線程恢復後,完全可能被調度到另一個載體線程。
| 組合 | scheduler-OS | scheduler-Runtime |
|---|---|---|
| continuation-OS | Java現在的Thread | 谷歌對Linux內核修改的User-Level Threads |
| continuation-Runtime | 糟糕的選擇? | 虛擬線程 |
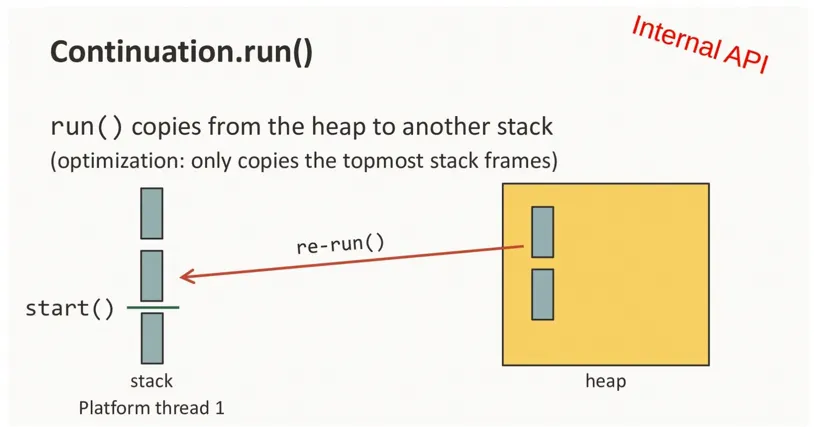
虛擬線程的調用堆棧存在Java堆上,而不是OS分配的棧區內。其內存佔用開始時只有幾百字節,並可以隨着調用堆棧自動伸縮。虛擬線程的運行其實就是兩個操作:
- 掛載(mount):掛載虛擬線程意味着將所需的棧幀從堆中臨時複製到載體線程的堆棧中,並在掛載時借用載體堆棧執行。
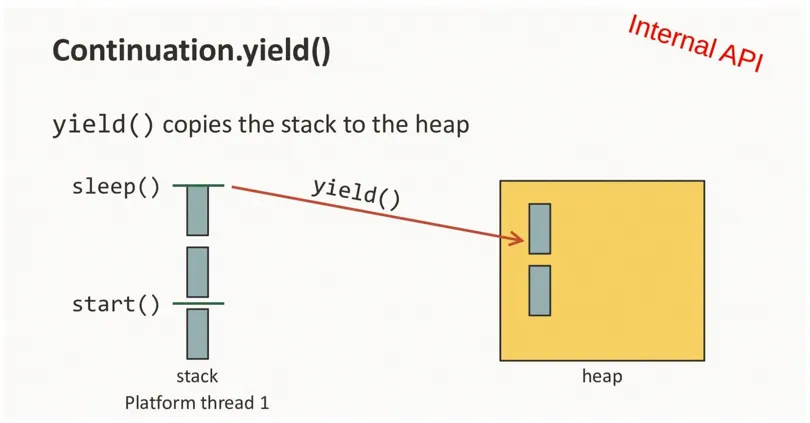
- 卸載(unmount):當在虛擬線程中運行的代碼因為 IO、鎖等原因阻塞後,它可以從載體線程中卸載,然後將修改的棧幀複製回堆中,從而釋放載體線程以進行其他操作(例如運行另一個虛擬線程)。對應的,JDK 中幾乎所有的阻塞點都已經過調整,因此當在虛擬線程上遇到阻塞操作時,虛擬線程會從其載體上卸載而不是阻塞。
關於scheduler就比較簡單了,因為JDK中有現成的ForkJoinPool可以用。work-stealing + FIFO,性能很好。scheduler的並行性是可用於調度虛擬線程的OS線程數。默認情況下,它等於可用CPU核數,也可以使用系統屬性jdk.virtualThreadScheduler.parallelism進行調整。
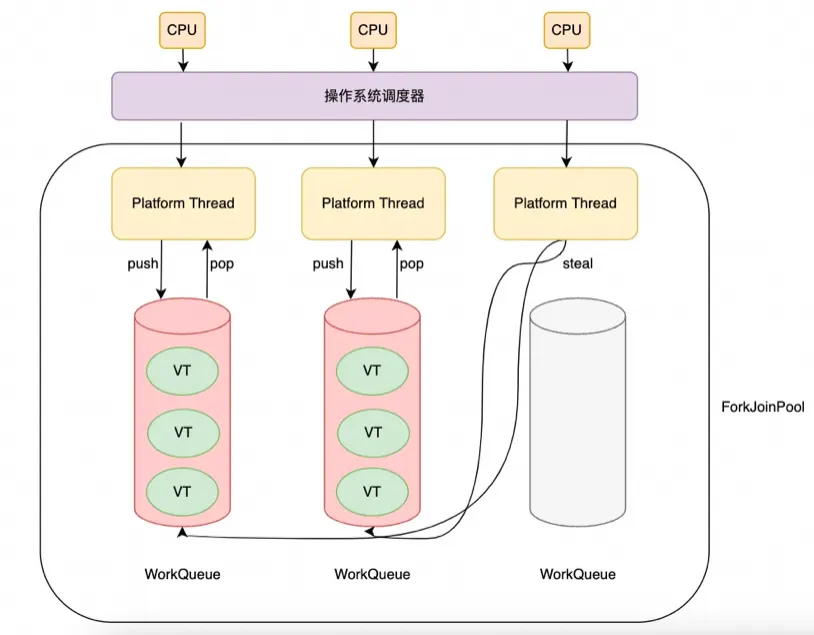
需要注意的是,JDK中的絕大多數阻塞操作將卸載虛擬線程,釋放其載體線程來承擔新的工作。但是,JDK中的一些阻塞操作不會卸載虛擬線程,因此會阻塞其載體線程。這是因為操作系統級別(例如,許多文件系統操作)或JDK級別(例如,Object.wait())的限制。這些阻塞操作的解決方式是,通過臨時擴展scheduler的並行性來補償操作系統線程的捕獲。因此,scheduler的ForkJoinPool中的平台線程數量可能暫時超過CPU核數。scheduler可用的最大平台線程數可以使用系統屬性:jdk.virtualThreadScheduler.maxPoolSize進行調整。
虛擬線程源碼
試着寫一個使用虛擬線程進行網絡IO的例子,來窺視下虛擬線程底層的魔法。
下面代碼使用了基於虛擬線程的ExecutorService來獲取一組URL的響應。每個URL任務會啓動一個虛擬線程進行處理。
// record是JDK 14中引入的,這裏作為簡單的數據類,保存url和響應
record URLData (URL url, byte[] response) { }
public List<URLData> retrieveURLs(URL... urls) throws Exception {
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
var tasks = Arrays.stream(urls)
.map(url -> (Callable<URLData>)() -> getURL(url))
.toList();
return executor.invokeAll(tasks)
.stream()
.filter(Future::isDone)
.map(this::getFutureResult)
.toList();
}
}
獲取響應的邏輯在getURL中實現,使用同步的URLConnectionAPI來讀取數據。
URLData getURL(URL url) throws IOException {
try (InputStream in = url.openStream()) {
return new URLData(url, in.readAllBytes());
}
}
這裏我模擬了兩個HTTP接口,其中一個響應很慢,因此在運行後不會馬上完成。
// test1接口sleep 1s返回,test2接口則sleep 100s
example.retrieveURLs(new URL("http://localhost:7001/test1"), new URL("http://localhost:7001/test2"));
這樣就可以用jcmd命令進行線程轉儲。
$ jcmd `jps | grep VtExample | awk '{print $1}'` Thread.dump_to_file -format=json thread_dump.json
把結果中的普通線程堆棧去掉後,就得到了虛擬線程的堆棧:
{
"container": "java.util.concurrent.ThreadPerTaskExecutor@5d5a133a",
"parent": "<root>",
"owner": null,
"threads": [
{
"tid": "24",
"name": "",
"stack": [
"java.base\/jdk.internal.vm.Continuation.yield(Continuation.java:357)",
"java.base\/java.lang.VirtualThread.yieldContinuation(VirtualThread.java:370)",
"java.base\/java.lang.VirtualThread.park(VirtualThread.java:499)",
"java.base\/java.lang.System$2.parkVirtualThread(System.java:2596)",
"java.base\/jdk.internal.misc.VirtualThreads.park(VirtualThreads.java:54)",
"java.base\/java.util.concurrent.locks.LockSupport.park(LockSupport.java:369)",
"java.base\/sun.nio.ch.Poller.poll2(Poller.java:139)",
"java.base\/sun.nio.ch.Poller.poll(Poller.java:102)",
"java.base\/sun.nio.ch.Poller.poll(Poller.java:87)",
"java.base\/sun.nio.ch.NioSocketImpl.park(NioSocketImpl.java:175)",
"java.base\/sun.nio.ch.NioSocketImpl.park(NioSocketImpl.java:196)",
"java.base\/sun.nio.ch.NioSocketImpl.implRead(NioSocketImpl.java:304)",
"java.base\/sun.nio.ch.NioSocketImpl.read(NioSocketImpl.java:340)",
"java.base\/sun.nio.ch.NioSocketImpl$1.read(NioSocketImpl.java:789)",
"java.base\/java.net.Socket$SocketInputStream.read(Socket.java:1025)",
"java.base\/java.io.BufferedInputStream.fill(BufferedInputStream.java:255)",
"java.base\/java.io.BufferedInputStream.read1(BufferedInputStream.java:310)",
"java.base\/java.io.BufferedInputStream.implRead(BufferedInputStream.java:382)",
"java.base\/java.io.BufferedInputStream.read(BufferedInputStream.java:361)",
"java.base\/sun.net.www.http.HttpClient.parseHTTPHeader(HttpClient.java:827)",
"java.base\/sun.net.www.http.HttpClient.parseHTTP(HttpClient.java:759)",
"java.base\/sun.net.www.protocol.http.HttpURLConnection.getInputStream0(HttpURLConnection.java:1684)",
"java.base\/sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1585)",
"java.base\/java.net.URL.openStream(URL.java:1162)",
"com.rhino.vt.VtExample.getURL(VtExample.java:59)",
"com.rhino.vt.VtExample.lambda$retrieveURLs$0(VtExample.java:40)",
"java.base\/java.util.concurrent.ThreadPerTaskExecutor$ThreadBoundFuture.run(ThreadPerTaskExecutor.java:352)",
"java.base\/java.lang.VirtualThread.run(VirtualThread.java:287)",
"java.base\/java.lang.VirtualThread$VThreadContinuation.lambda$new$0(VirtualThread.java:174)",
"java.base\/jdk.internal.vm.Continuation.enter0(Continuation.java:327)",
"java.base\/jdk.internal.vm.Continuation.enter(Continuation.java:320)"
]
}
],
"threadCount": "1"
}
作為對比,把代碼中的executor改成Executors.newCachedThreadPool(),再dump出直接使用普通線程的堆棧:
{
"tid": "23",
"name": "pool-1-thread-2",
"stack": [
"java.base\/sun.nio.ch.SocketDispatcher.read0(Native Method)",
"java.base\/sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:47)",
"java.base\/sun.nio.ch.NioSocketImpl.tryRead(NioSocketImpl.java:251)",
"java.base\/sun.nio.ch.NioSocketImpl.implRead(NioSocketImpl.java:302)",
"java.base\/sun.nio.ch.NioSocketImpl.read(NioSocketImpl.java:340)",
"java.base\/sun.nio.ch.NioSocketImpl$1.read(NioSocketImpl.java:789)",
"java.base\/java.net.Socket$SocketInputStream.read(Socket.java:1025)",
"java.base\/java.io.BufferedInputStream.fill(BufferedInputStream.java:255)",
"java.base\/java.io.BufferedInputStream.read1(BufferedInputStream.java:310)",
"java.base\/java.io.BufferedInputStream.implRead(BufferedInputStream.java:382)",
"java.base\/java.io.BufferedInputStream.read(BufferedInputStream.java:361)",
"java.base\/sun.net.www.http.HttpClient.parseHTTPHeader(HttpClient.java:827)",
"java.base\/sun.net.www.http.HttpClient.parseHTTP(HttpClient.java:759)",
"java.base\/sun.net.www.protocol.http.HttpURLConnection.getInputStream0(HttpURLConnection.java:1684)",
"java.base\/sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1585)",
"java.base\/java.net.URL.openStream(URL.java:1162)",
"com.rhino.vt.VtExample.getURL(VtExample.java:59)",
"com.rhino.vt.VtExample.lambda$retrieveURLs$0(VtExample.java:40)",
"java.base\/java.util.concurrent.FutureTask.run(FutureTask.java:317)",
"java.base\/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)",
"java.base\/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)",
"java.base\/java.lang.Thread.run(Thread.java:1589)"
]
}
兩個堆棧對比一下會發現,除了中間執行的業務邏輯部分是一致的,有兩點不同:
- 普通線程的入口是Thread.run,而虛擬線程的入口是Continuation,這個類是虛擬線程的核心類,是VM內部對上面所説的continuation的抽象。Continuation有兩個關鍵方法:yield()和run()。
可以試着跑一下這段代碼看看輸出結果:
public void testContinuation() {
var scope = new ContinuationScope("test");
var continuation = new Continuation(scope, () -> {
System.out.println("C1");
Continuation.yield(scope);
System.out.println("C2");
Continuation.yield(scope);
System.out.println("C3");
Continuation.yield(scope);
});
System.out.println("start");
continuation.run();
System.out.println("came back");
continuation.run();
System.out.println("back again");
continuation.run();
System.out.println("back again again");
continuation.run();
}
// Output:
start
C1
came back
C2
back again
C3
back again again
PS:在Java19中還是預覽版,需要加上下面的參數:(Java21後已經是正式版了)
--add-opens java.base/jdk.internal.vm=ALL-UNNAMED
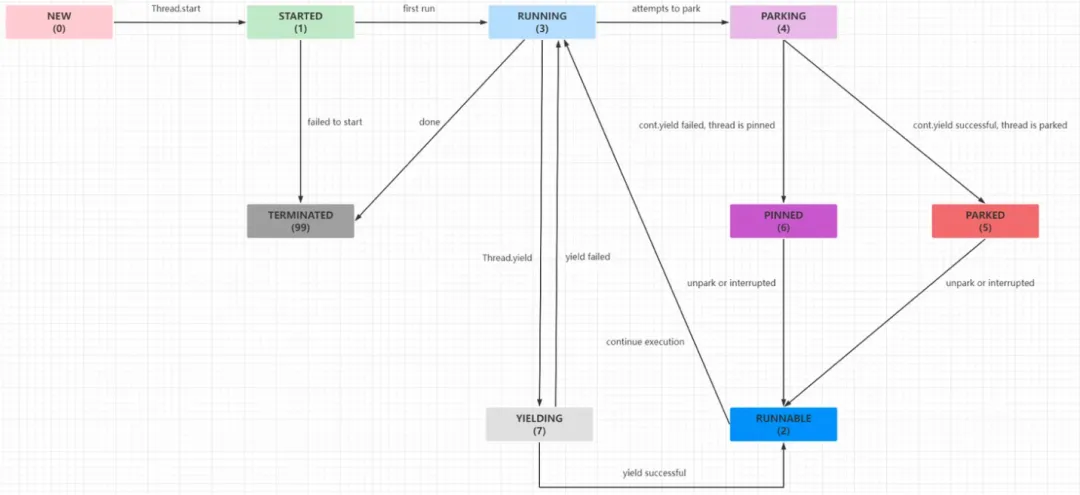
- 普通線程會阻塞在read本地方法調用上(底層應該就是read系統調用),而虛擬線程則會通過VirtualThread#park掛起,這也對應了上面説的,JDK中幾乎所有的阻塞點都已經過調整了。VirtualThread維護了一組state狀態,調用park後就會設置成PARKING,可以在註釋裏看到狀態之間的流轉邏輯。
在線程dump文件裏還能找到一個叫Read-Poller的線程(對應的還有一個寫操作的 Write-Poller線程):
{
"tid": "27",
"name": "Read-Poller",
"stack": [
"java.base\/sun.nio.ch.KQueue.poll(Native Method)",
"java.base\/sun.nio.ch.KQueuePoller.poll(KQueuePoller.java:66)",
"java.base\/sun.nio.ch.Poller.poll(Poller.java:363)",
"java.base\/sun.nio.ch.Poller.pollLoop(Poller.java:270)",
"java.base\/java.lang.Thread.run(Thread.java:1589)",
"java.base\/jdk.internal.misc.InnocuousThread.run(InnocuousThread.java:186)"
]
}
JDK底層做了什麼調整呢?從Read-Poller可以看出,其實就是把原來的阻塞調用改為了非阻塞的IO調用。流程如下:
- 在阻塞調用中,檢查是否虛擬線程,如果是的話,就註冊一個NIO handler,即將文件描述符註冊到Read-Poller的selector上。然後調用Continuation.yield()暫停自身。因為我本機是mac,所以線程堆棧裏顯示的NIO handler用的是KQueue,如果換成Linux,那就是我們熟悉的epoll了。
- Read-Poller底層維護了一組文件描述符 - 虛擬線程的映射,當一個文件描述符被註冊到Read-Poller上時,同樣也會將對應的虛擬線程加到這個映射裏。
- 當Socket可讀時,這個Read-Poller就會得到通知,隨即調用wakeup()方法,從映射裏找到文件描述符對應的虛擬線程,再將之前park()的虛擬線程unpark(),這樣就完成了虛擬線程的喚醒。
/**
* Unparks any thread that is polling the given file descriptor.
*/
private void wakeup(int fdVal) {
Thread t = map.remove(fdVal);
if (t != null) {
LockSupport.unpark(t);
}
}
虛擬線程的unpark()方法如下:
/**
* Re-enables this virtual thread for scheduling. If the virtual thread was
* {@link #park() parked} then it will be unblocked, otherwise its next call
* to {@code park} or {@linkplain #parkNanos(long) parkNanos} is guaranteed
* not to block.
* @throws RejectedExecutionException if the scheduler cannot accept a task
*/
@Override
@ChangesCurrentThread
void unpark() {
Thread currentThread = Thread.currentThread();
if (!getAndSetParkPermit(true) && currentThread != this) {
int s = state();
// CAS設置線程狀態
if (s == PARKED && compareAndSetState(PARKED, RUNNABLE)) {
if (currentThread instanceof VirtualThread vthread) {
Thread carrier = vthread.carrierThread;
carrier.setCurrentThread(carrier);
try {
// 提交給scheduler執行
submitRunContinuation();
} finally {
carrier.setCurrentThread(vthread);
}
} else {
submitRunContinuation();
}
} else if (s == PINNED) {
// unpark carrier thread when pinned.
synchronized (carrierThreadAccessLock()) {
Thread carrier = carrierThread;
if (carrier != null && state() == PINNED) {
U.unpark(carrier);
}
}
}
}
}
在unpark()中,會將虛擬線程的狀態重新設置為RUNNABLE,並且調用submitRunContinuation()方法將任務交給調度器執行,真正執行時,就會調用到Continuation.run()方法。另外,上面調用executor.invokeAll()方法提交任務時,底層同樣也是調用了VirtualThread.submitRunContinuation()方法,這裏的scheduler默認就是ForkJoinPool實例。
/**
* Submits the runContinuation task to the scheduler.
* @param {@code lazySubmit} to lazy submit
* @throws RejectedExecutionException
* @see ForkJoinPool#lazySubmit(ForkJoinTask)
*/
private void submitRunContinuation(boolean lazySubmit) {
try {
if (lazySubmit && scheduler instanceof ForkJoinPool pool) {
pool.lazySubmit(ForkJoinTask.adapt(runContinuation));
} else {
// 默認shceduler就是ForkJoinPool
scheduler.execute(runContinuation);
}
} catch (RejectedExecutionException ree) {
// 省略異常處理代碼
}
}
而在park()裏,虛擬線程讓出資源的關鍵方法是VirtualThread.yieldContinuation(),可以發現mount()和unmount()操作。
/**
* Unmounts this virtual thread, invokes Continuation.yield, and re-mounts the
* thread when continued. When enabled, JVMTI must be notified from this method.
* @return true if the yield was successful
*/
@ChangesCurrentThread
private boolean yieldContinuation() {
boolean notifyJvmti = notifyJvmtiEvents;
// unmount
if (notifyJvmti) notifyJvmtiUnmountBegin(false);
unmount();
try {
return Continuation.yield(VTHREAD_SCOPE);
} finally {
// re-mount
mount();
if (notifyJvmti) notifyJvmtiMountEnd(false);
}
}
mount()和unmount()會在Java堆和本地線程棧之間做棧幀的拷貝,這是Project Loom中為數不多的在JVM層面實現的本地方法,感興趣的可以去Loom的github庫裏搜一下continuationFreezeThaw.cpp。其餘的大部分代碼在JDK中實現, 參見java.base模塊下的jdk.internal.vm包。