

大家好,我是湯師爺,AI智能體架構師,致力於幫助100W人用智能體創富~
選題對內容創作至關重要,但面對海量信息,找到有價值的爆款選題並不容易。
對標賬號監控是內容創作者制定策略的有效工具。
通過跟蹤和分析行業內優秀創作者的內容,我們能獲得市場洞察和創作靈感,避免從零摸索。
這個方法尤其適合新手創作者,幫助他們快速瞭解哪類內容最受歡迎。
1. 為什麼要做對標賬號監控
1、幫助發現行業趨勢
通過觀察頭部創作者的內容變化,我們能及時把握行業熱點和用户興趣的轉變。
例如,當多個知名美妝博主同時開始測評某款新產品時,這很可能意味着該產品正成為市場熱點。
及時跟進這類話題,可以幫我們搭上流量紅利的順風車。
2、提供內容創作參考框架
通過分析成功賬號的視頻標題、封面設計、內容結構和互動策略,我們可以提取有效的內容模式。
這些模式不是用來簡單複製,而是幫助我們理解哪些元素能引起用户共鳴,從而優化自己的創作。
3、提升創作效率
在內容創作的海洋中,沒有明確方向很容易迷失和浪費資源。借鑑成功賬號的經驗,可以幫我們避開許多不必要的彎路,將有限的精力集中在已被驗證有效的內容策略上。
2. 智能體的搭建流程
智能體的搭建流程主要分為兩個步驟:梳理工作流和設置智能體。
1、梳理工作流
將對標賬號監控的場景流程轉化為可自動化運行的工作流節點。下面是具體步驟:
- 根據短視頻鏈接,獲取用户的基礎信息
- 根據用户ID,批量獲取視頻列表
- 篩選出對標賬號每天發佈的視頻
- 將數據添加到飛書表格中
2、設置智能體
- 設置人設與邏輯:配置對標賬號監控智能體的特徵、回覆風格和決策邏輯
- 綁定工作流:將工作流與智能體關聯,賦予其執行具體任務的能力
- 測試併發布:進行全面的功能測試,確認正常後將智能體正式發佈到生產環境
3. 抖音對標賬號監控工作流
登錄Coze官網,在“資源庫-工作流”裏新建一個空白工作流,取名“fetch_douyin_user_videos”。
工作流整體預覽。
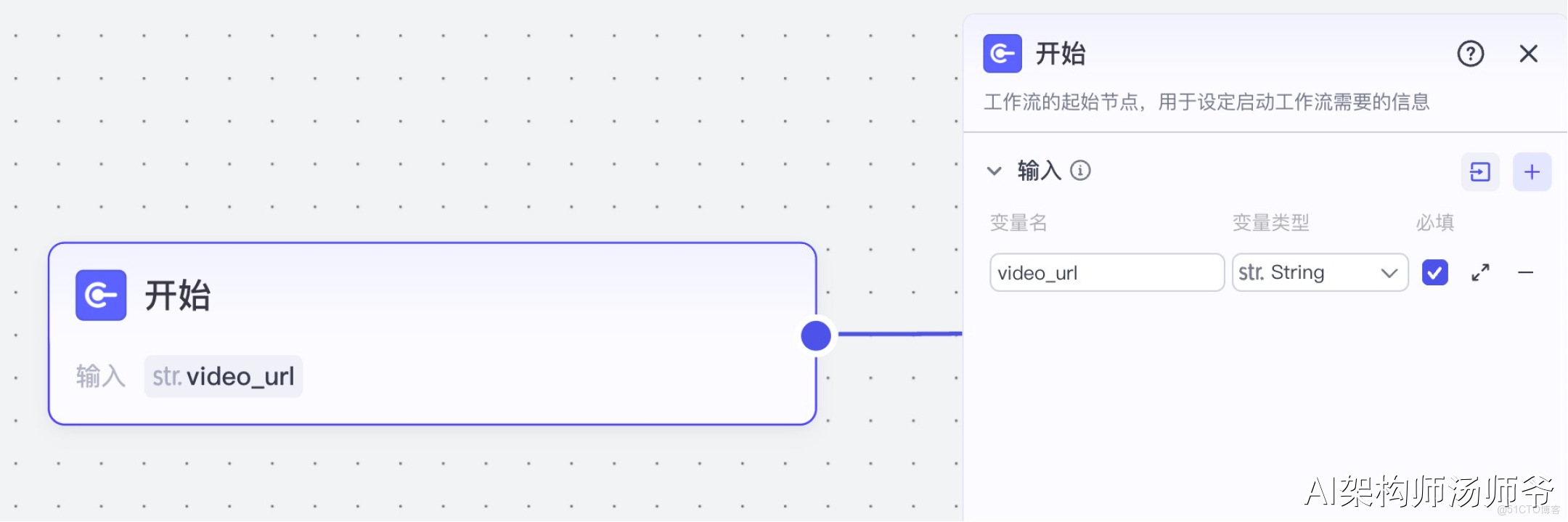
1、開始節點
這裏用於定義工作流啓動時所需的輸入參數。
- 輸入:
- video_url:抖音視頻分享鏈接
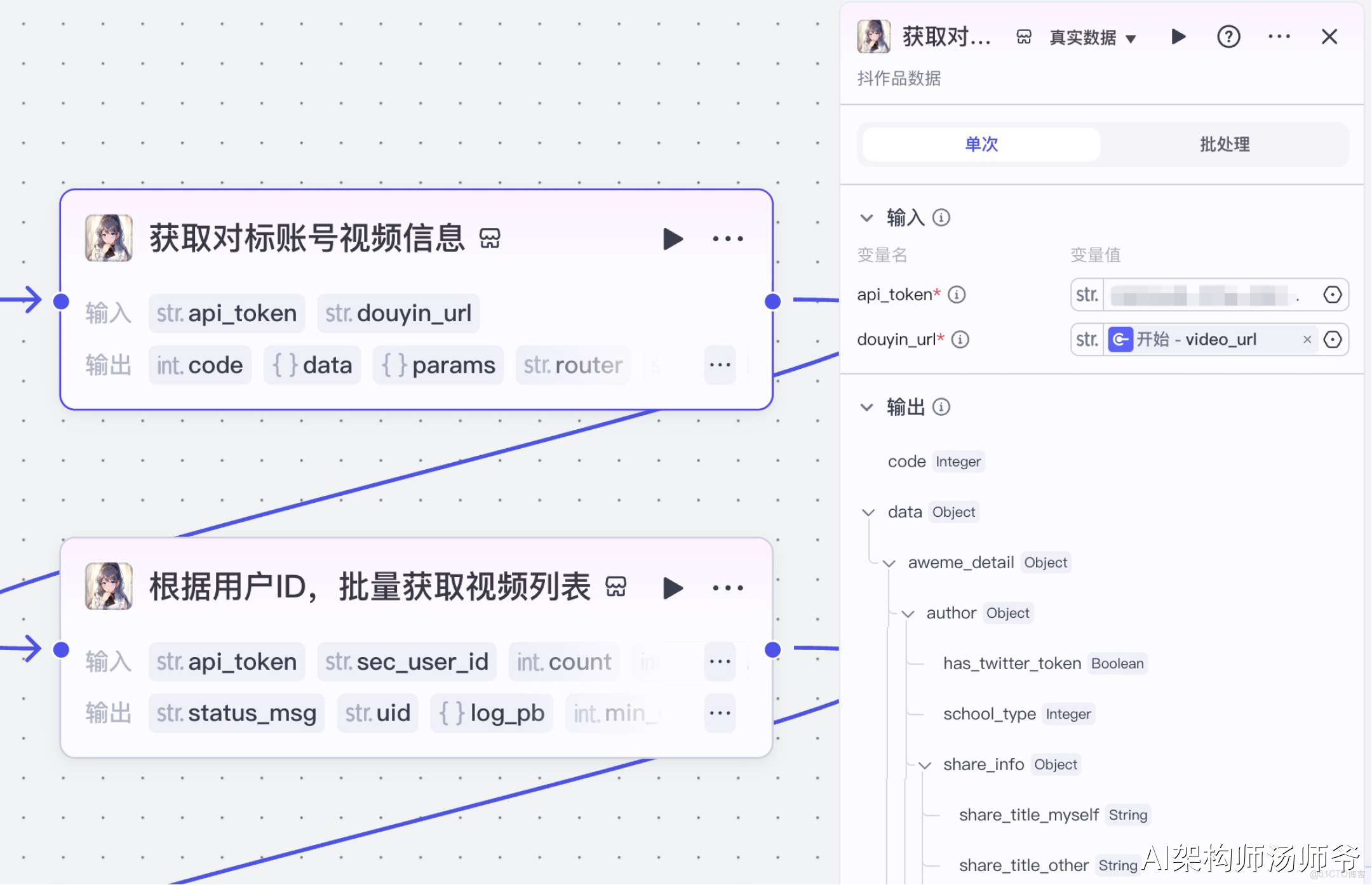
2、插件節點:獲取對標賬號視頻信息
我們將使用“視頻搜索”插件的douyin_data工具。通過這個功能,我們可以根據短視頻鏈接,獲取用户的ID信息。
- 輸入:
- douyin_url:開始節點的video_url
- api_token:API秘鑰
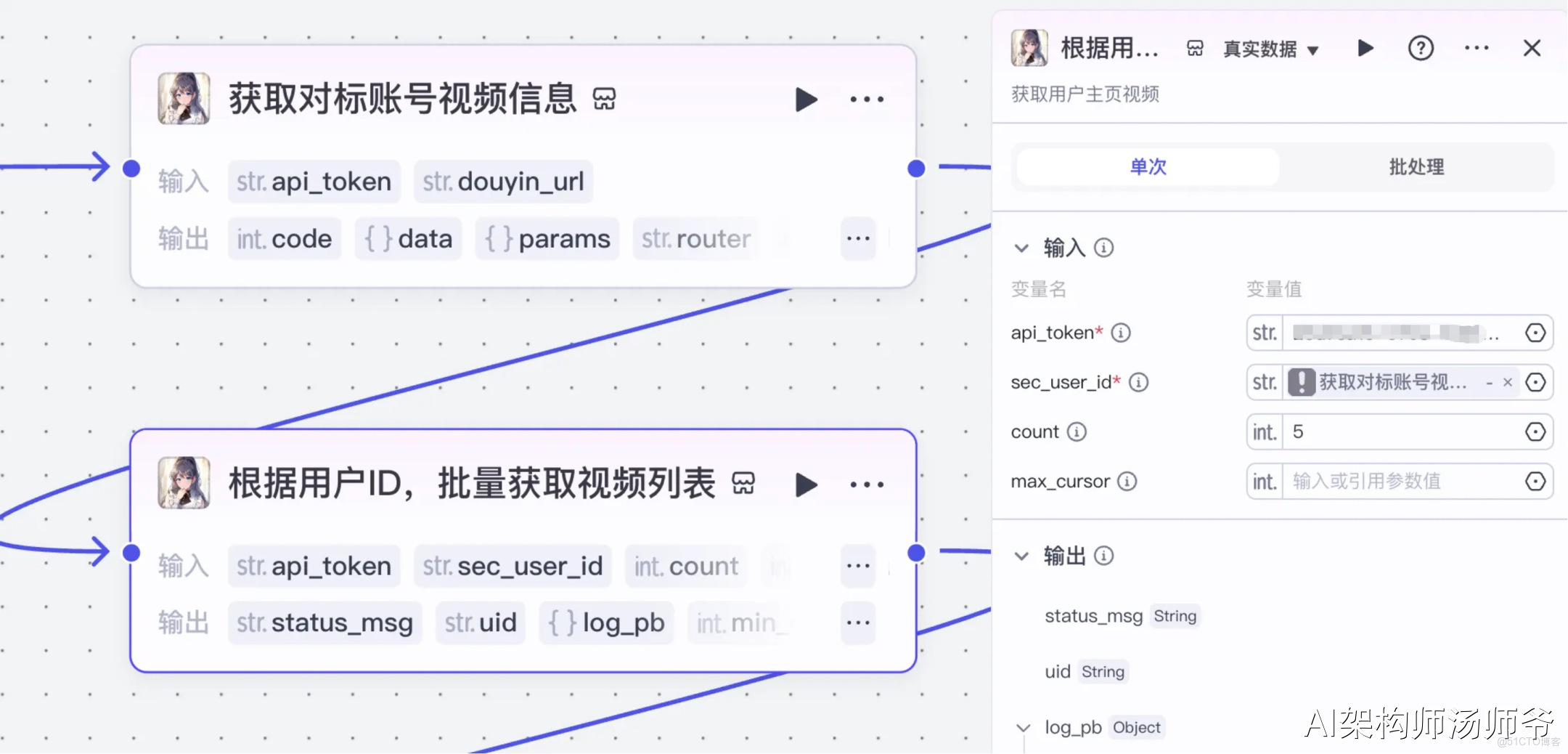
3、插件節點:根據用户ID,批量獲取視頻列表
我們繼續使用“視頻搜索”插件,使用其中的工具get_user_video_list。根據用户ID,批量獲取視頻列表。
- 輸入:
- api_token:API秘鑰
- sec_uid:在"獲取對標賬號視頻信息"節點的輸出變量中,選擇用户ID(sec_uid)
- count:設置需要獲取的短視頻數量,建議設為5個
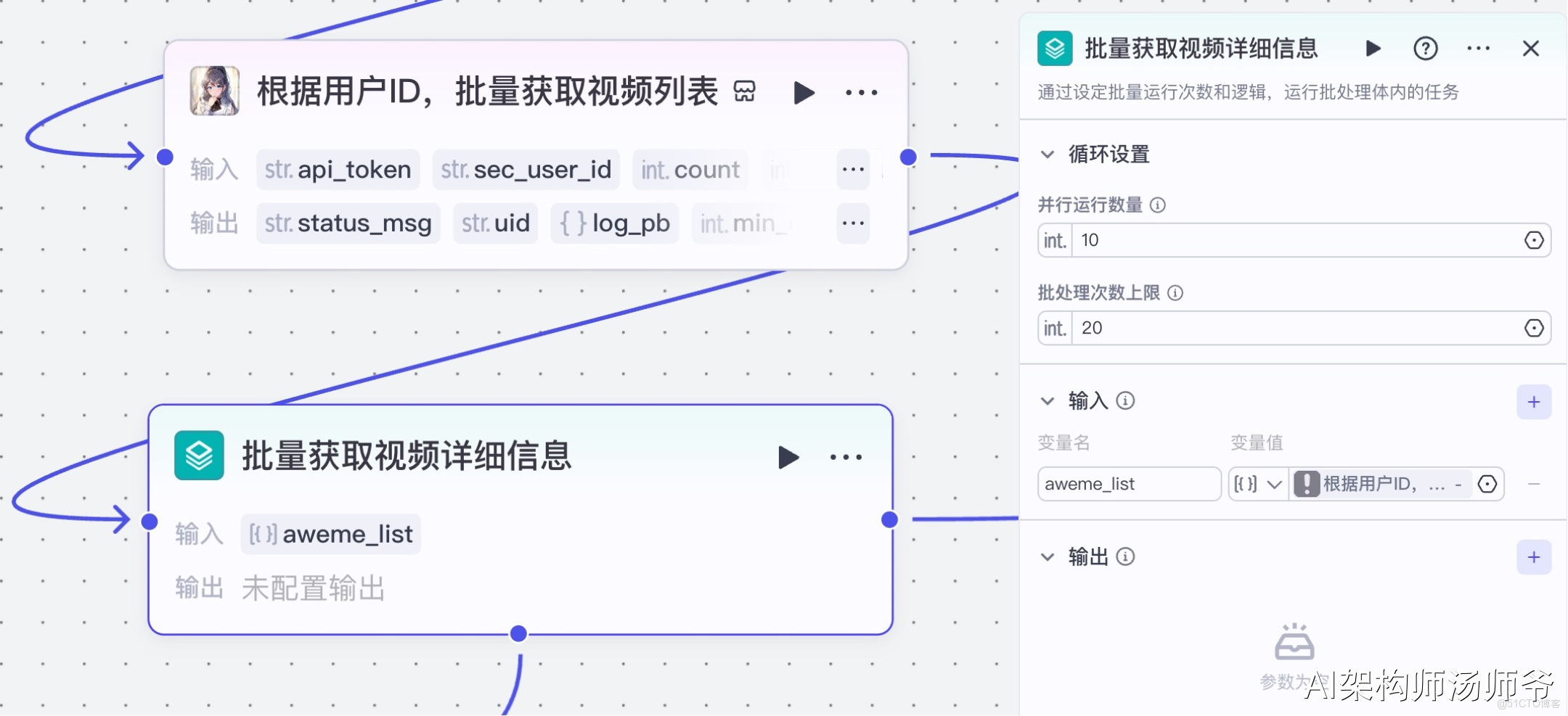
4、批處理節點:批量獲取視頻詳細信息
這一步將為我們從對標賬號的視頻列表中提取每個視頻的關鍵數據。通過批處理功能,我們可以同時處理多個視頻鏈接,大大提高數據採集效率。
- 輸入:
- aweme_list:從“根據用户ID,批量獲取視頻列表”節點的輸出中,選擇 aweme_list
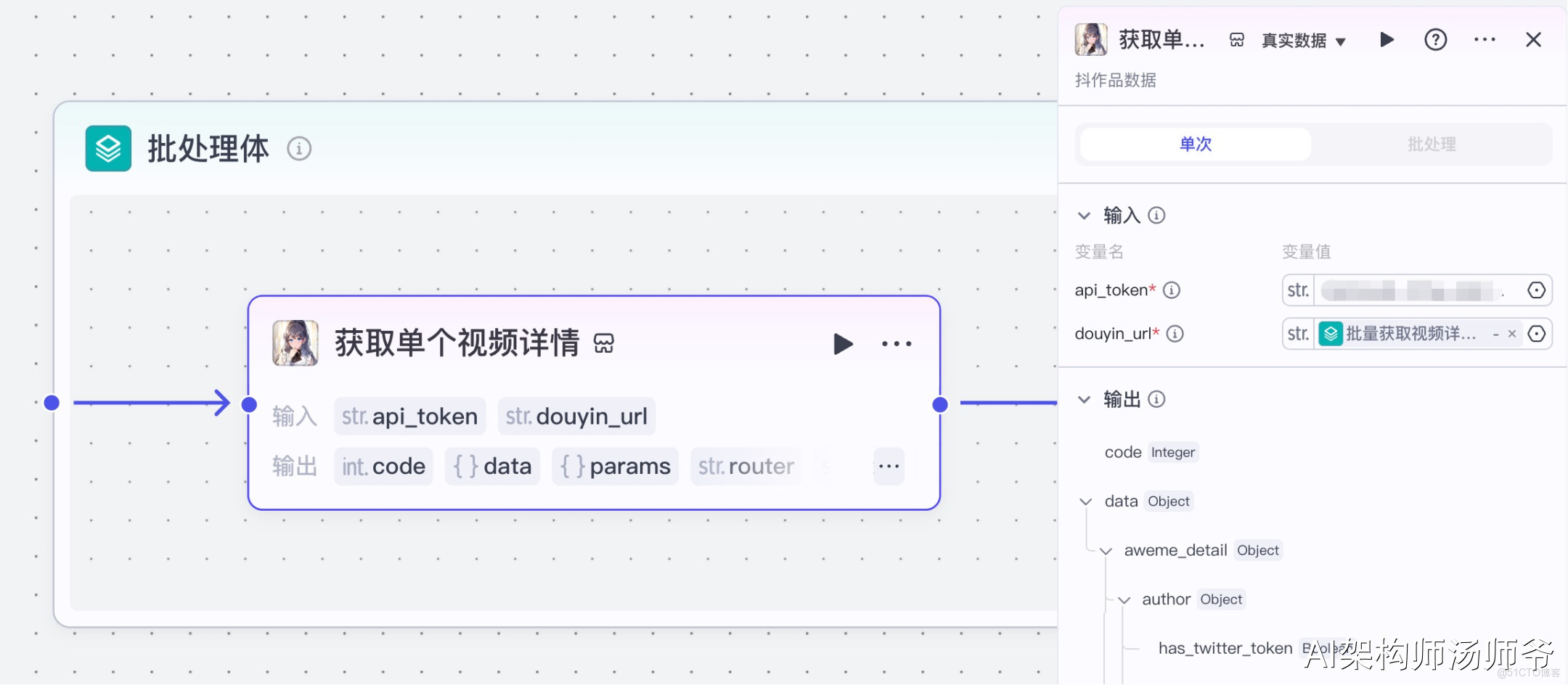
5、批處理體內插件節點:獲取單個視頻詳情
我們將使用“視頻搜索”插件的douyin_data工具。通過這個功能,我們可以根據抖音視頻鏈接,獲取視頻詳情信息。
- 輸入:
- api_token:API秘鑰
- douyin_url:從“批量獲取視頻詳細信息”節點的輸出中,選擇share_url
6、批處理體內代碼節點:將視頻詳情整合進視頻列表中
這一步將從抖音API獲取的詳細視頻信息與我們之前收集的視頻列表數據合併。通過這個過程,我們能確保掌握每個視頻的完整信息,包括互動數據(點贊、評論、收藏數)、創作者信息和內容詳情,為後續分析提供全面的數據基礎。
- 輸入:
- aweme_detail:從 “獲取單個視頻詳細信息”節點的輸出中,選擇aweme_detail
- aweme:從“批量獲取視頻詳細信息”節點的輸出中,選擇item
- 輸出:
- aweme_list:變量類型設置為 Array 對象數組,表示處理後的單條視頻
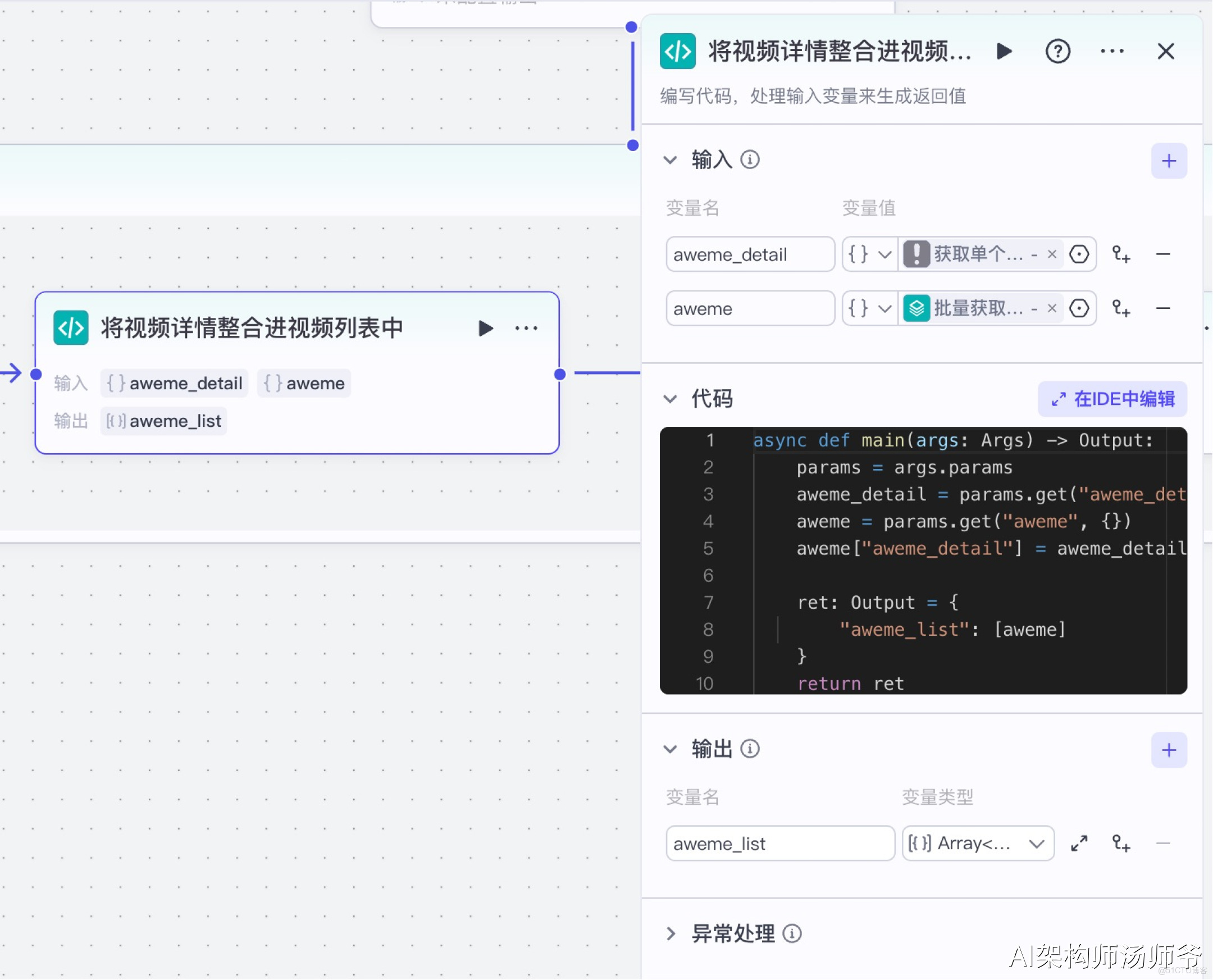
下面是處理數據的Python代碼,它會將視頻信息轉換成我們需要的格式。
async def main(args: Args) -> Output:
params = args.params
aweme_detail = params.get("aweme_detail", {})
aweme = params.get("aweme", {})
aweme["aweme_detail"] = aweme_detail
ret: Output = {
"aweme_list": [aweme]
}
return ret
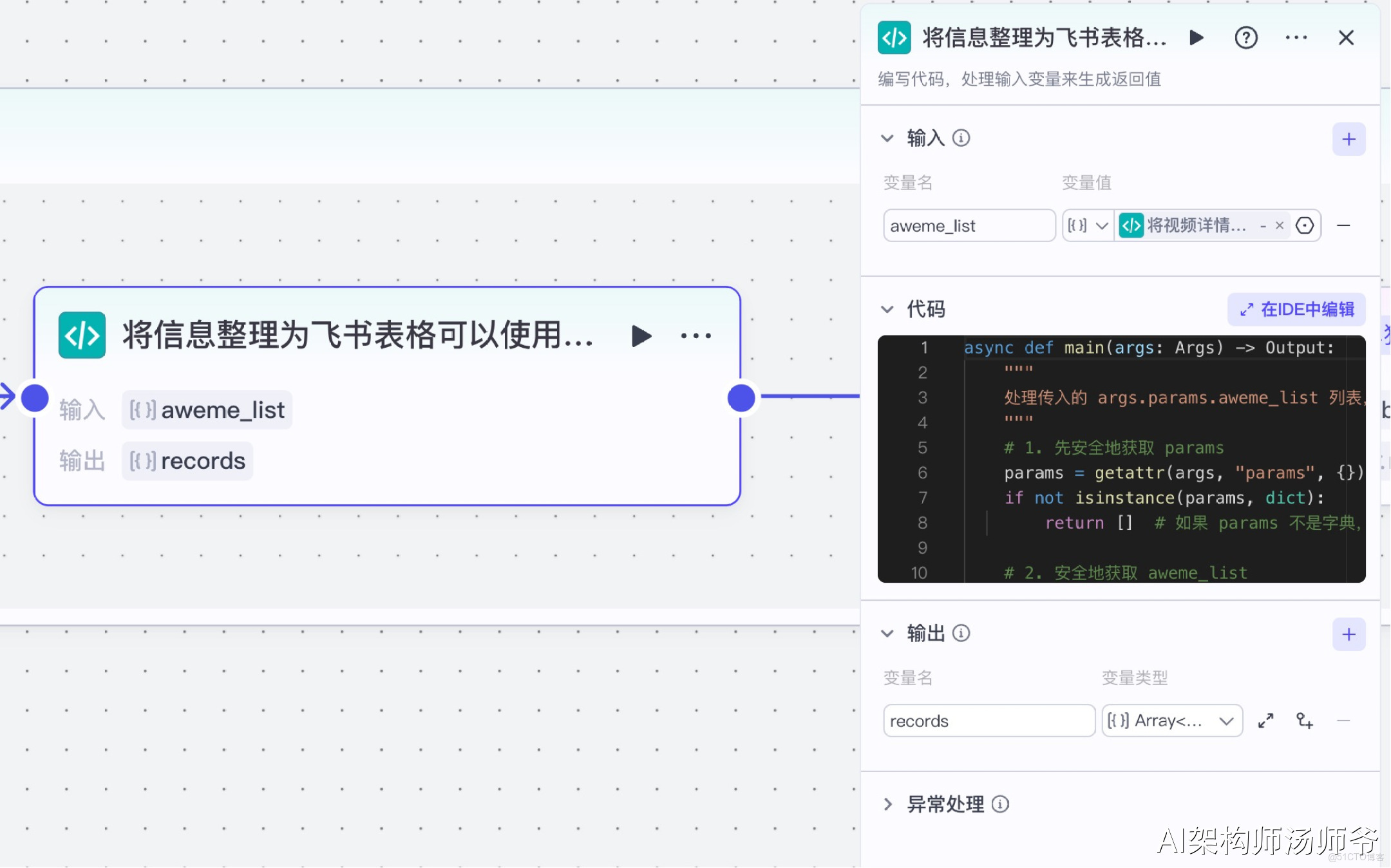
7、批處理體內代碼節點:將信息整理為飛書表格可以使用的數據
在這個環節中,我們會提取視頻的核心信息(如標題、點贊數、評論數等),並將它們轉換成飛書表格能夠直接識別和處理的格式。
- 輸入:
- aweme_list:從"將視頻詳情整合進視頻列表中"節點的輸出中,選擇aweme_list
- 輸出:
- records:處理後的表格數據,選擇Array類型
下面是Python代碼,用於處理數據轉換。這段代碼至關重要,它將抖音API返回的原始數據轉換為結構化的表格格式。
async def main(args: Args) -> Output:
params = args.params
aweme_list = params.get("aweme_list", [])
result = []
# 遍歷 aweme_list,依次處理
for aweme in aweme_list:
# 獲取 aweme_detail 並判空
aweme_detail = aweme.get("aweme_detail") or {}
title = aweme_detail.get("desc") or ""
link = aweme_detail.get("share_url") or ""
# 安全獲取 statistics
statistics = aweme_detail.get("statistics") or {}
# 提取各字段信息,並在取值時加默認值
video_id = statistics.get("aweme_id") or ""
digg_count = statistics.get("digg_count") or 0
comment_count = statistics.get("comment_count") or 0
collect_count = statistics.get("collect_count") or 0
share_count = statistics.get("share_count") or 0
# 獲取作者信息
author_info = aweme_detail.get("author") or {}
author_name = author_info.get("nickname") or ""
signature = author_info.get("signature") or ""
sec_uid = author_info.get("sec_uid") or ""
raw_create_time = aweme_detail.get("create_time", 0)
# 如果不是 int,就嘗試轉換,失敗則為 0
try:
create_time = int(raw_create_time)
except (TypeError, ValueError):
create_time = 0
# 創建時間以毫秒計,避免 None 或非法值導致報錯
create_time_ms = create_time * 1000
raw_duration = aweme_detail.get("duration", 0)
# 如果不是數字,嘗試轉換為 float,失敗則為 0
try:
duration = float(raw_duration)
except (TypeError, ValueError):
duration = 0.0
duration_sec = duration / 1000
# 組裝返回數據
item_dict = {
"fields": {
"視頻ID": video_id,
"標題": title.strip(),
"鏈接": {
"text": "查看視頻",
"link": link.strip(),
},
"點贊數": digg_count,
"評論數": comment_count,
"收藏數": collect_count,
"分享數": share_count,
"作者": author_name,
"用户簡介": signature,
"用户ID": sec_uid,
"發佈日期": create_time_ms, # 毫秒級時間戳
"時長": duration_sec # 秒
}
}
result.append(item_dict)
return result
8、批處理體內插件節點:將數據添加到多維表格
首先,我們需要創建一個多維表格,設置好表頭字段。

選擇“飛書表格”插件節點的add_records工具,將數據添加到多維表格。
- 輸入:
- app_token:提前創建一個多維表格,將多維表格的鏈接複製進去。
- records:從"將信息整理為飛書表格可以使用的數據"的輸出變量中,選擇records。
- table_id:多維表格數據表的唯一標識符
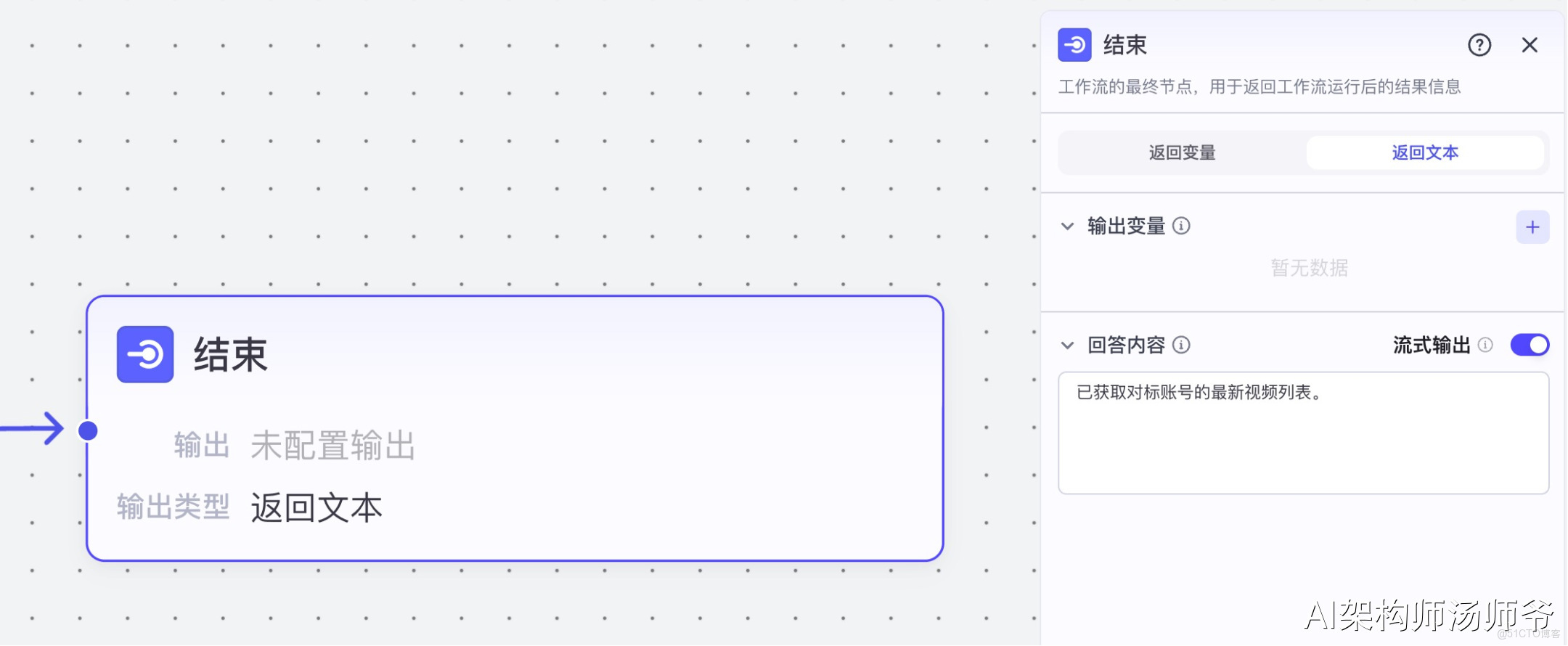
9、結束節點
選擇"返回文本",將回答內容設置為:已獲取對標賬號的最新視頻列表。
4.小紅書對標賬號監控工作流
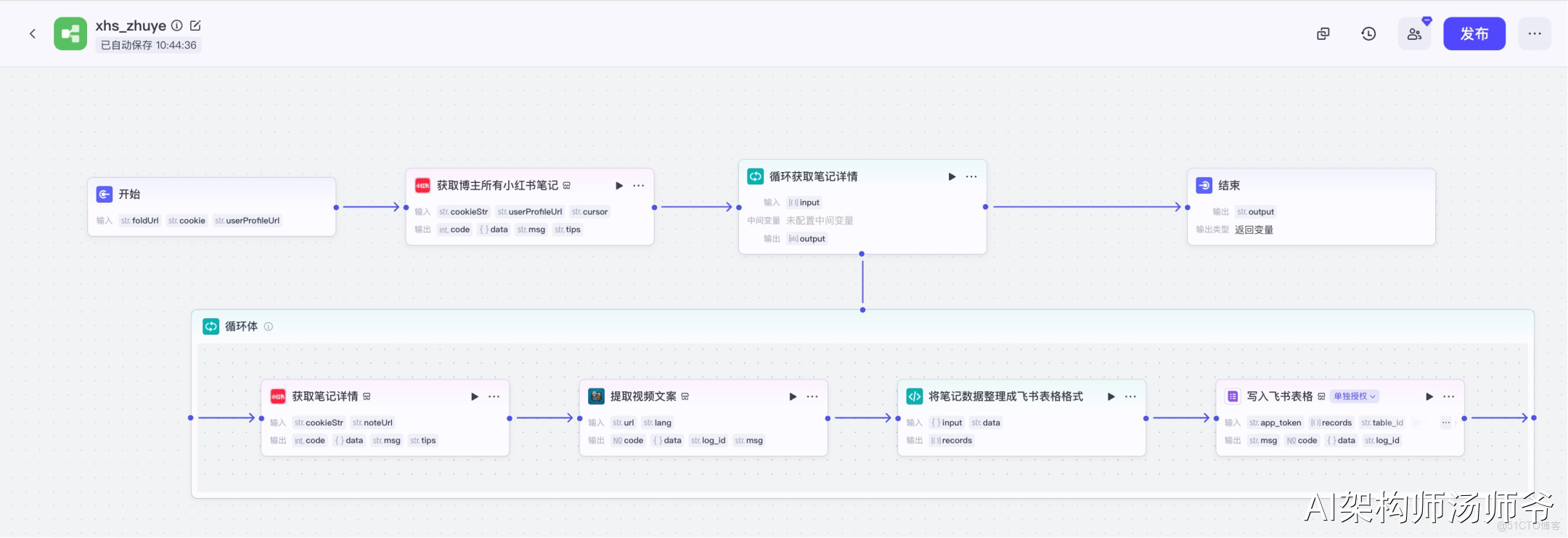
登錄Coze官網,在"資源庫-工作流"中新建一個空白工作流,命名為"xhs_zhuye"。
工作流整體預覽。
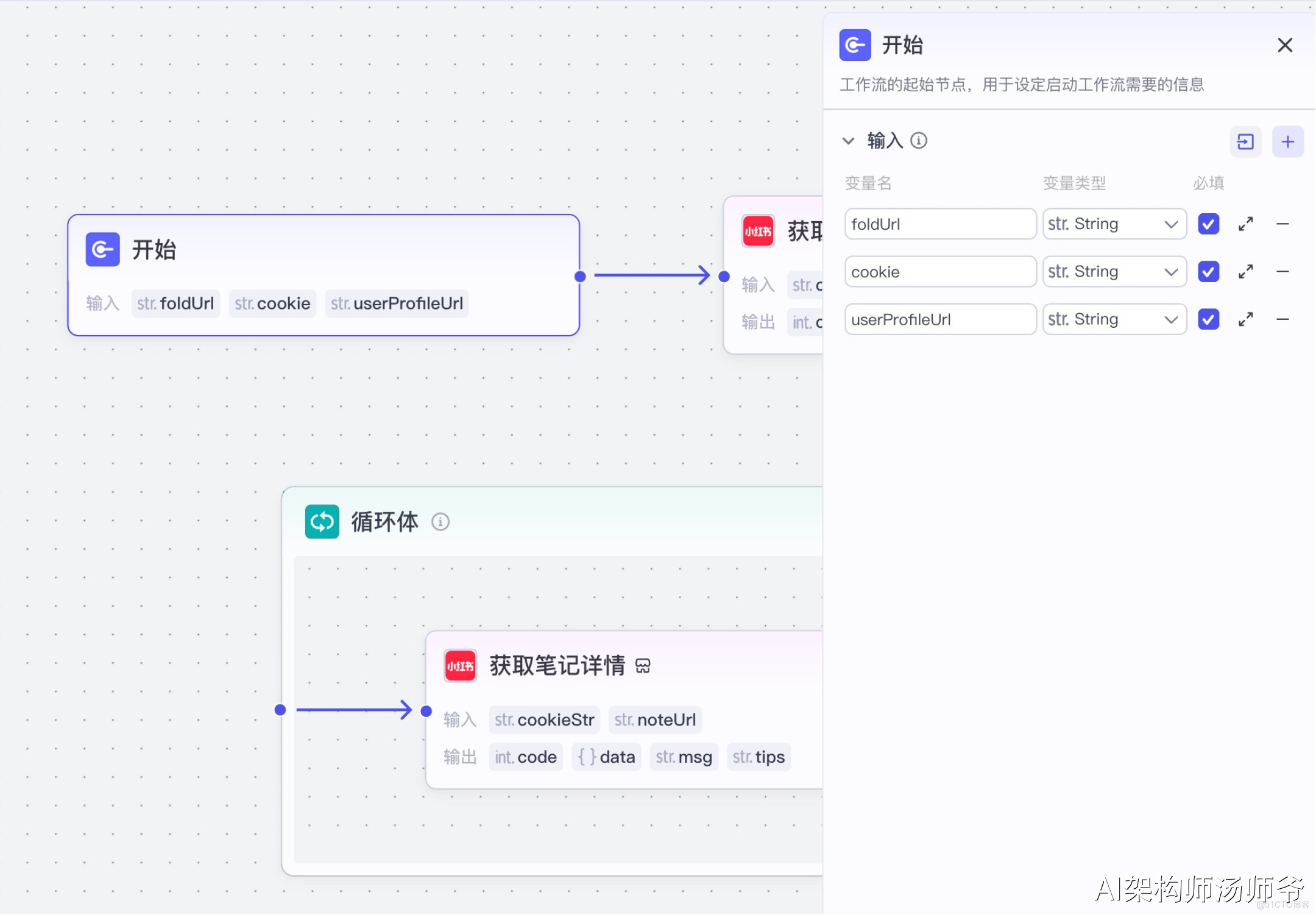
1、開始節點
此節點用於定義工作流啓動時所需的輸入參數。
- 輸入:
- foldUrl:飛書表格鏈接
- cookie:小紅書平台的cookie信息,這是訪問小紅書數據的身份憑證,獲取方法參考6節
- userProfileUrl:要監控的小紅書博主主頁完整URL地址
2、插件節點:獲取博主所有小紅書筆記
我們將使用"小紅書"插件的xhs_auther_notes工具。這個工具能幫我們一次性獲取博主所有發佈的筆記內容。
- 輸入:
- cookieStr:開始節點的 cookie
- userProfileUrl:開始節點的 userProfileUrl
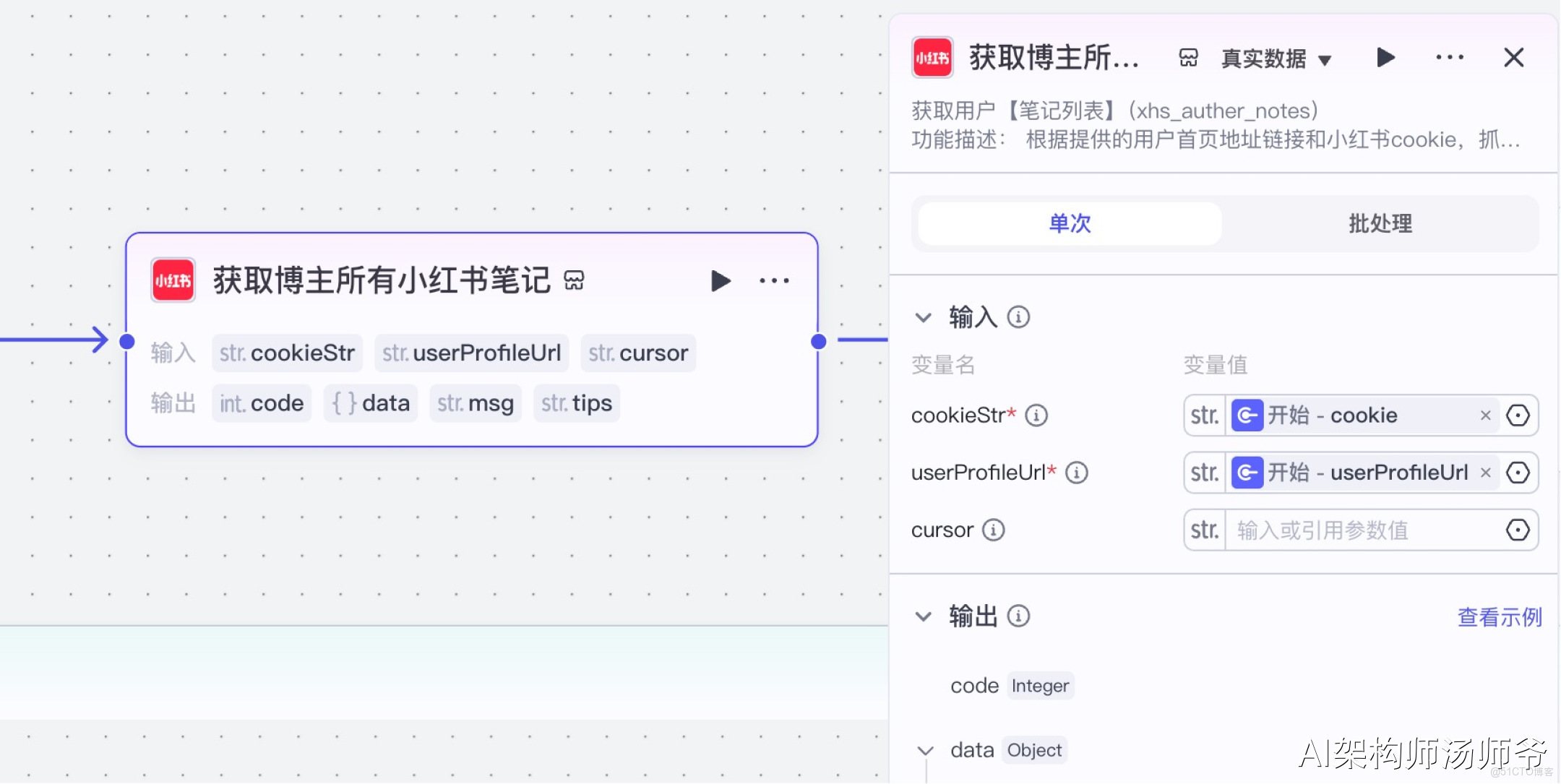
3、循環節點:循環獲取筆記詳情
循環獲取筆記詳情是工作流中的一個關鍵步驟,它會遍歷博主所有的筆記,逐一獲取詳細信息,收集每篇筆記的數據,包括標題、內容、互動數據等。
- 輸入
- input:從 “獲取博主所有小紅書筆記”節點 的輸出中,選擇 notes
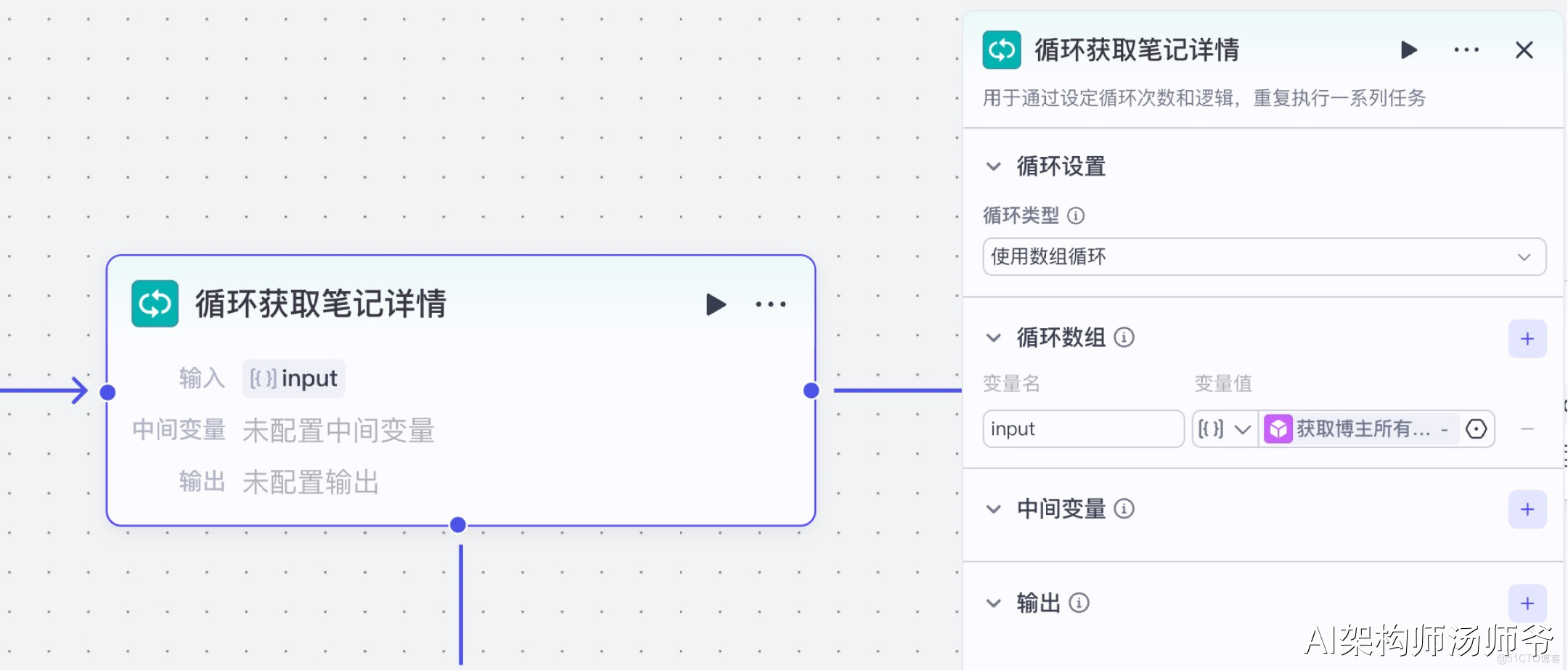
4、循環體內插件節點:獲取筆記詳情
我們將使用"小紅書"插件的xhs_note_detail工具。這個工具能夠幫助我們獲取每篇筆記的詳細信息,包括筆記內容、互動數據、圖片和視頻資源鏈接等。
- 輸入
- cookieStr:開始節點的 cookie
- noteUrl:從 “循環筆記詳情” 節點的輸出中,選擇 noteUrl
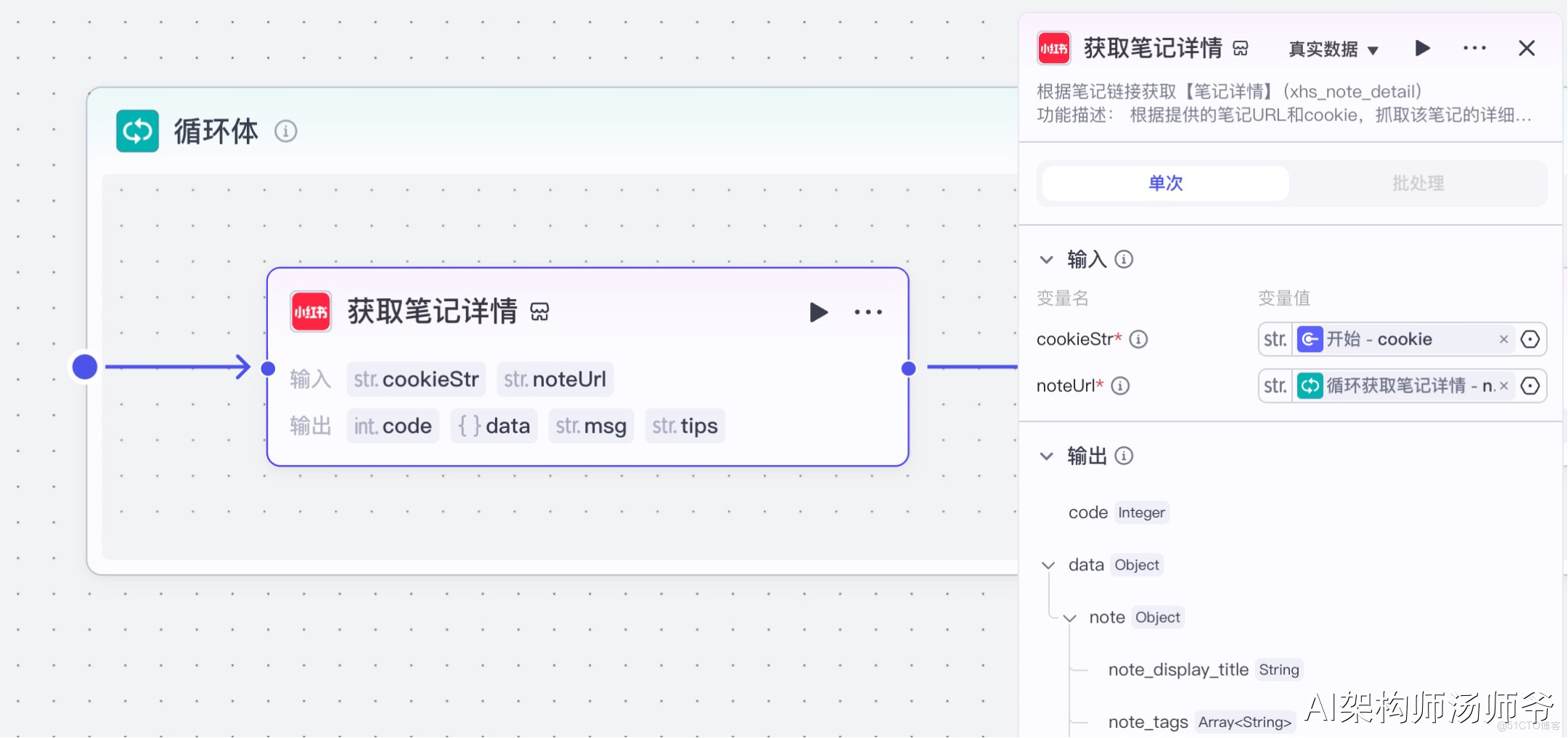
5、循環體內插件節點:提取視頻文案
我們將使用"字幕獲取"插件的generate_video_captions_sync工具。這個工具可以自動提取視頻中的語音內容並轉換為文字,非常適合批量處理視頻素材和內容分析。
- 輸入:
- url:從"獲取筆記詳情"節點的輸出中,選擇 video_h264_url,表示H264標準編碼格式視頻鏈接
- lang:視頻語言,如漢語、英語等,不填時默認為漢語
6、循環體內代碼節點:將筆記數據整理成飛書表格格式
這一步是將我們獲取到的原始數據轉換成標準化、結構化的格式,以便後續導入飛書表格。
- 輸入
- input:從“獲取筆記詳情”節點的輸出中,選擇note
- data:從“提取視頻文案”節點的 輸出中,選擇 content
- 輸出
- records:變量類型設置為 Array 對象數組,表示處理後的單條視頻
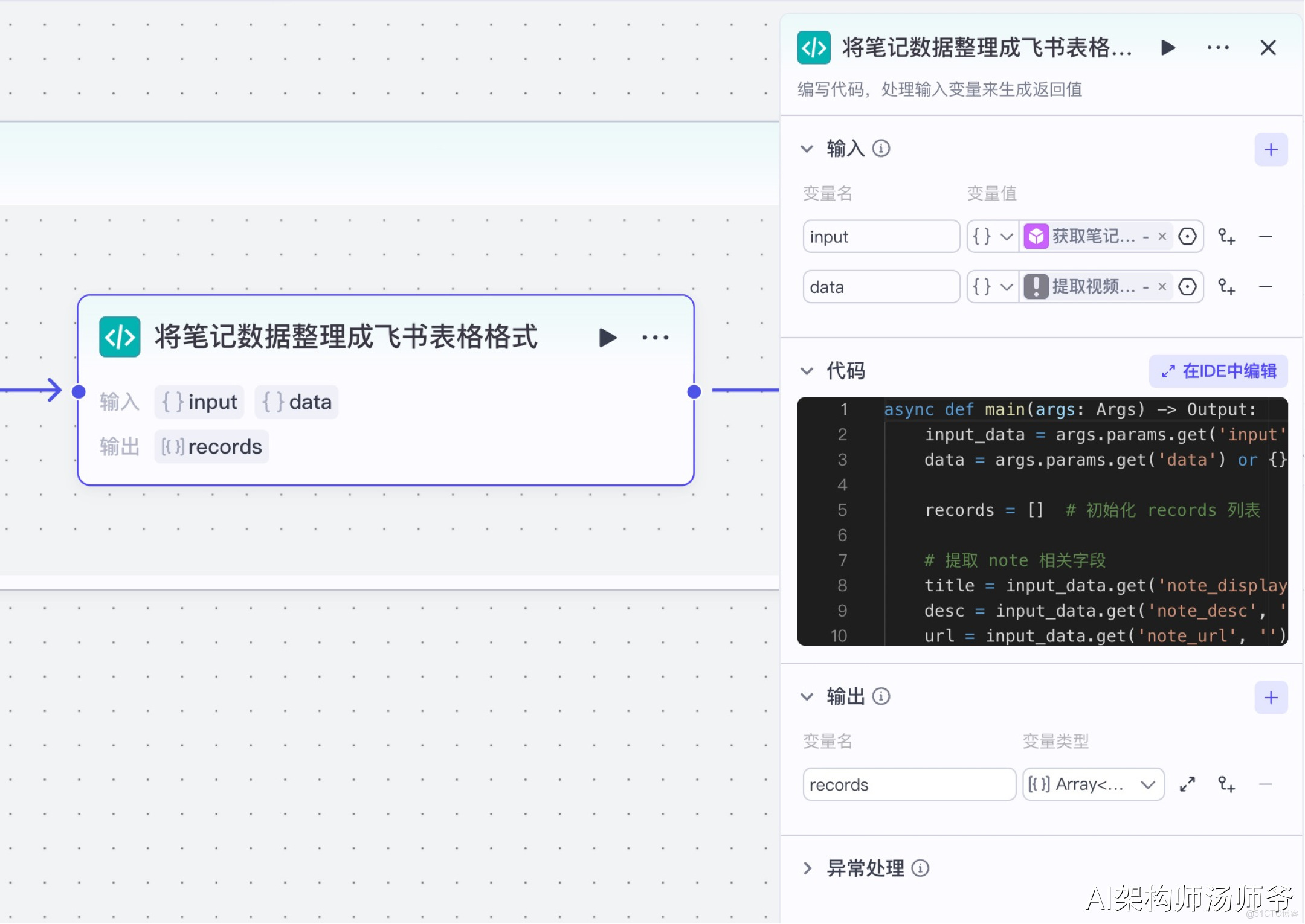
下面是處理數據的Python代碼:
async def main(args: Args) -> Output:
input_data = args.params.get('input') or {}
data = args.params.get('data') or {}
records = [] # 初始化 records 列表
# 提取 note 相關字段
title = input_data.get('note_display_title', '') # 標題
desc = input_data.get('note_desc', '') # 描述
url = input_data.get('note_url', '') # 鏈接
nickname = input_data.get('auther_nick_name', '') # 作者暱稱
likedCount = input_data.get('note_liked_count', '0') # 點贊數
videoUrl = input_data.get('video_h264_url', '') # 視頻地址
collectedCount = input_data.get('collected_count', '0') # 收藏數
imageList = input_data.get('note_image_list', []) # 圖片列表
# 構建記錄對象
record = {
"fields": {
"筆記鏈接": url,
"標題": title,
"內容": desc,
"作者": nickname,
"點贊數": likedCount,
"鏈接": {
"link": url,
"text": title
},
"收藏數": collectedCount,
"圖片地址": '\n'.join(imageList), # 將圖片列表拼接成字符串
"視頻地址": videoUrl,
"視頻文案": data.get("content", "")
}
}
records.append(record) # 將記錄對象添加到 records 列表中
# 構建輸出對象
ret: Output = {
"records": records
}
return ret
7、循環體內插件節點:寫入飛書表格
首先,我們需要創建一個多維表格,設置好表頭字段。

表頭字段包括視頻的所有關鍵信息:筆記鏈接、標題、內容、作者、點贊數、鏈接、收藏數、圖片地址、視頻地址、視頻文案。 最後,我們將處理好的數據添加到飛書多維表格中。選擇“飛書表格”插件節點的add_records工具,將數據添加到多維表格。
- 輸入:
- app_token:開始節點的 foldUrl,也就是飛書多維表格的鏈接
- records:從“將筆記整理成飛書表格格式”的輸出變量中,選擇records
- table_id:多維表格數據表的唯一標識符
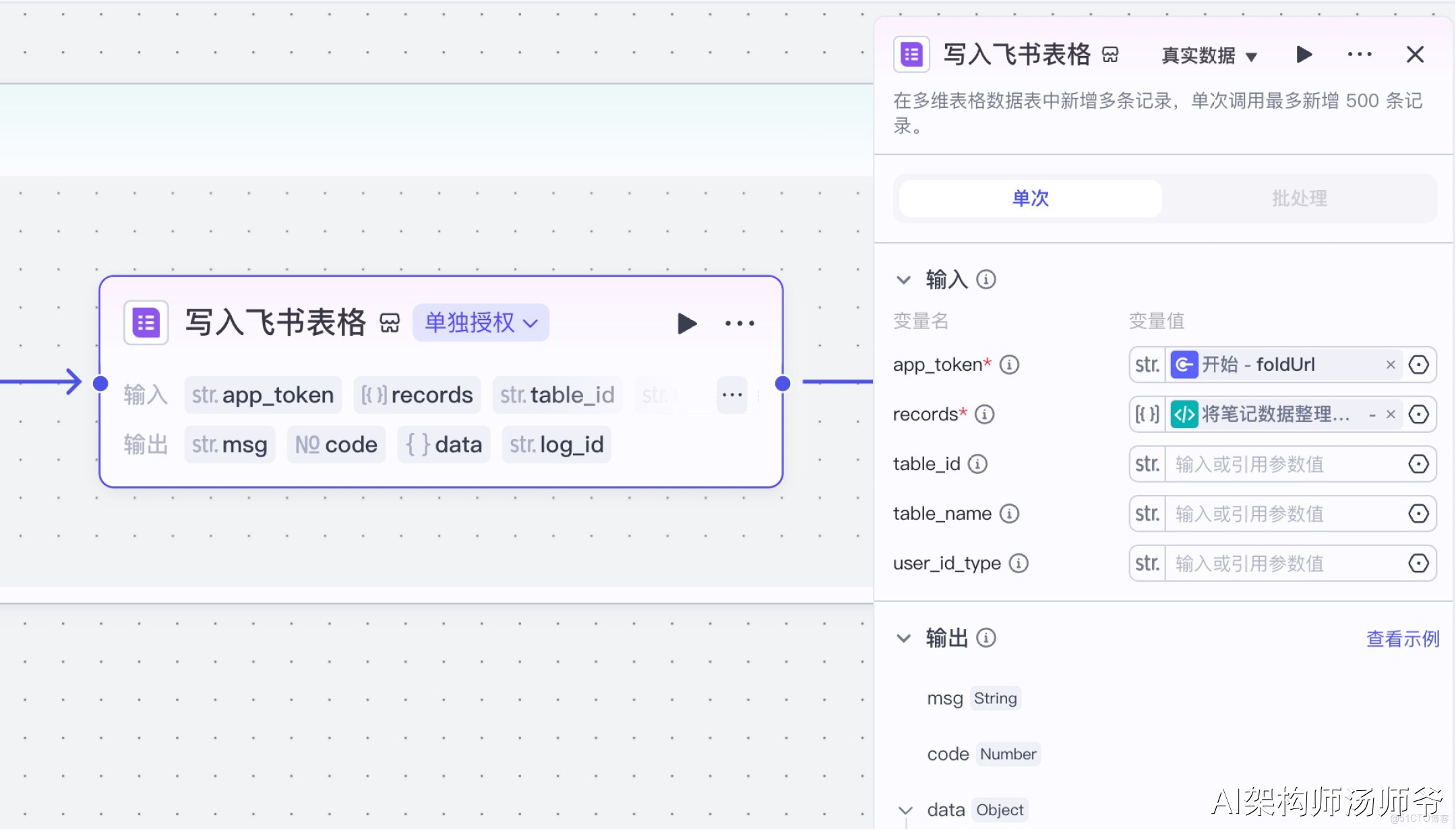
8、結束節點
選擇“返回變量”,輸出:output 開始節點的foldUrl,也就是飛書多維表格的鏈接
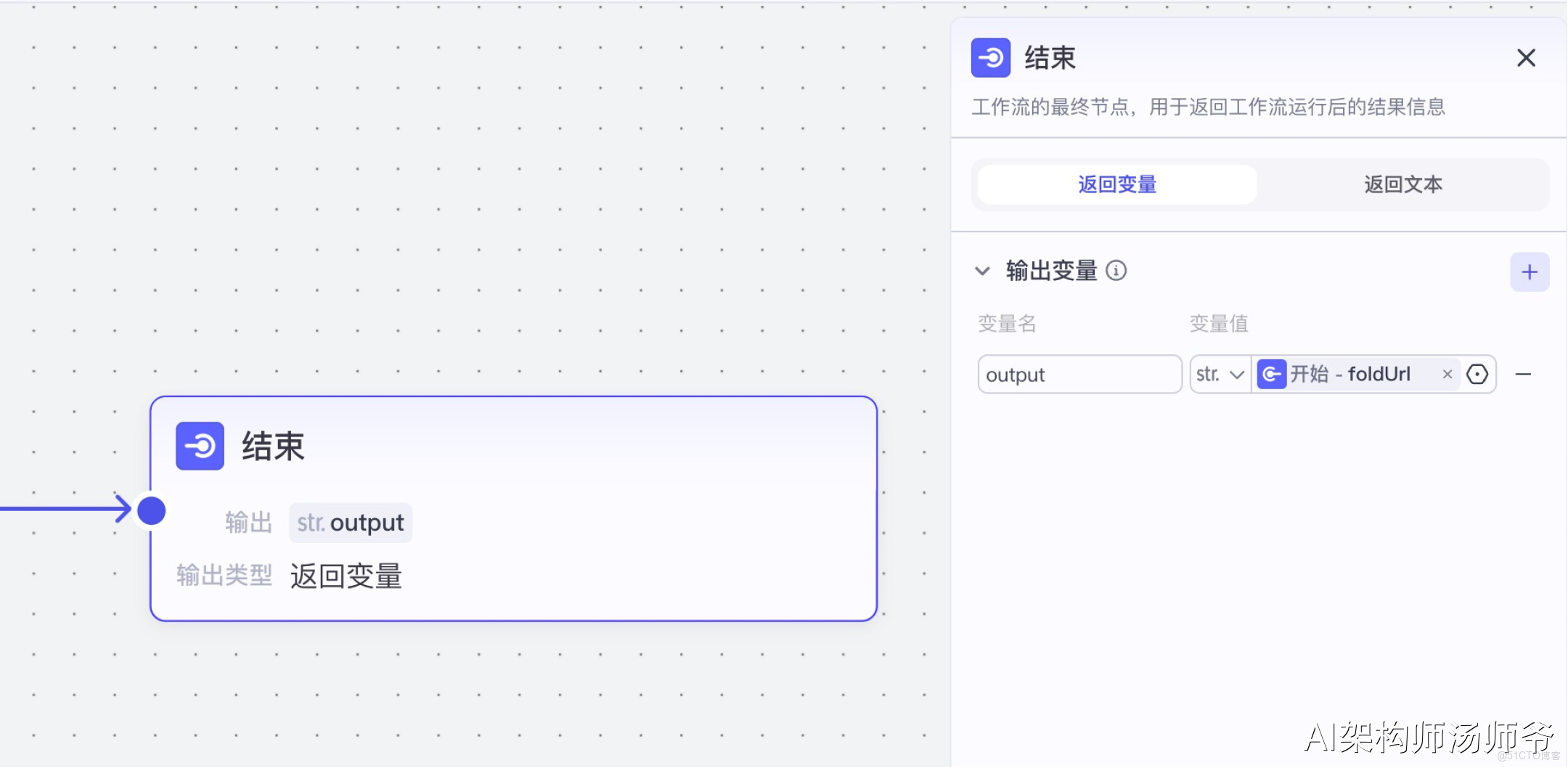
5. 小結
對標賬號監控智能體專注於競品分析,自動獲取優質賬號的內容數據。
我們介紹了抖音和小紅書平台的監控工作流搭建方法,包括獲取視頻列表、提取詳情、整理數據結構和存儲等步驟。
通過這一智能體,創作者可持續學習行業標杆,獲取創作靈感和參考。
本文已收錄於,我的技術博客 裏面有,AI 學習資料,Coze 工作流,n8n 工作流,算法 Leetcode 詳解,BAT 面試真題,架構設計,等乾貨分享。