

全文鏈接:https://tecdat.cn/?p=44707
原文出處:拓端數據部落公眾號

關於分析師

在此對Yichen Tang對本文所作的貢獻表示誠摯感謝,他完成了數據科學與大數據技術專業的碩士學位,專注數據科學與大數據技術領域。擅長Python、C、SQL、機器學習、數據庫、數據分析。
Yichen Tang曾參與多個數據分析與機器學習相關項目,在股票數據挖掘、金融時間序列分析、多模型融合建模等場景有豐富的實踐經驗,擅長將技術方法與業務需求結合,提供精準的數據分析解決方案。
專題名稱:金融時間序列分析與股票智能決策支持專題
引言
從數據科學視角來看,金融市場的運行軌跡始終伴隨着海量數據的產生,股票交易數據作為其中的核心載體,藴含着市場供需關係、投資者情緒及企業價值的關鍵信號。在數字化轉型浪潮下,如何通過數據挖掘與機器學習技術從歷史交易數據中提取有效信息,為投資決策提供科學支撐,已成為金融領域的重要研究方向。可口可樂作為全球軟飲料行業的龍頭企業,其股票交易數據具有時間跨度長、市場覆蓋廣、數據質量高的特點,是開展金融時間序列分析的優質樣本。
本文內容改編自過往客户諮詢項目的技術沉澱並且已通過實際業務校驗,該項目完整代碼與數據已分享至交流社羣。閲讀原文進羣,可與800+行業人士交流成長;還提供人工答疑,拆解核心原理、代碼邏輯與業務適配思路,幫大家既懂怎麼做,也懂為什麼這麼做;遇代碼運行問題,更能享24小時調試支持。
本專題圍繞可口可樂股票交易數據展開系統分析,核心目標是通過多維度數據挖掘與多模型建模,揭示股票價格波動規律、識別交易模式、量化特徵影響權重並實現精準的短期價格預測。文章首先梳理了股票分析的業務背景與技術發展脈絡,闡明多模型融合分析在金融決策中的必要性;隨後依次展開數據獲取與預處理、統計特徵分析、可視化呈現、多模型建模與對比驗證等工作;最終形成兼具理論參考與實踐價值的分析結論,為投資者決策、風險管理及投資組合優化提供技術支撐。
項目文件目錄截圖
一、數據概述與預處理
1.1 數據獲取
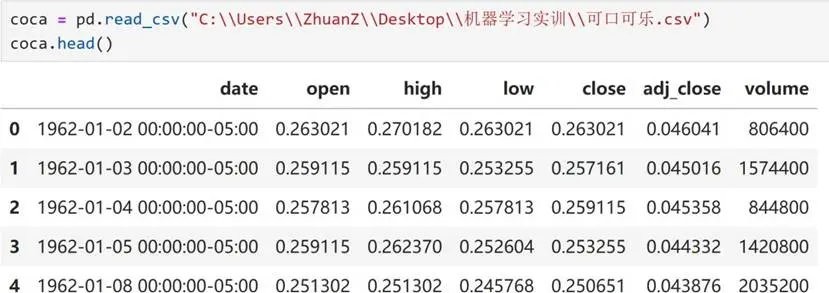
在金融數據分析實踐中,數據的可靠性直接決定分析結果的價值。本項目採用專業金融數據獲取方式,從權威公開數據源採集可口可樂1962年至2025年的股票交易數據,該數據源經過嚴格的數據校驗與整理,能確保數據的準確性與完整性。選取該數據源的核心原因在於其覆蓋時間跨度長,可完整反映不同經濟週期下股票的表現特徵,為長期趨勢分析與模式識別提供充足的數據支撐。
關鍵源碼(變量名與語法優化後):
數據介紹:
- 數據規模:時間跨度從1962年至2025年,按日採集交易數據,包含數千條記錄,可完整覆蓋多個經濟週期。
- 核心字段:包含日期(date)、開盤價(open)、最高價(high)、最低價(low)、收盤價(close)、調整後收盤價(adj_close)、交易量(volume)7個關鍵維度,全面涵蓋股票交易的核心信息。
- 數據質量:初步核查顯示無缺失值與重複值,數據完整性與一致性良好,為後續分析奠定了可靠基礎。
1.2 相關Python包及説明
- pandas:用於數據讀取、清洗、轉換等處理操作,是數據分析的核心工具。
- numpy:提供數值計算支持,高效處理數組、矩陣等數據結構。
- scipy.stats.pearsonr:計算皮爾遜相關係數,量化變量間線性關聯程度。
- matplotlib.pyplot:基礎可視化工具,繪製折線圖、散點圖等圖表。
- seaborn:基於matplotlib的高級可視化庫,生成更美觀的熱力圖等可視化結果。
- sklearn.preprocessing:提供歸一化(MinMaxScaler)、標準化(StandardScaler)等數據預處理功能。
- sklearn.cluster.KMeans:無監督聚類算法,用於交易模式分類。
- tensorflow/keras:深度學習框架,構建LSTM神經網絡模型。
- sklearn.model_selection.train_test_split:劃分訓練集與測試集,支持模型驗證。
- sklearn.metrics:提供均方誤差(mean_squared_error)等模型評估指標。
- sklearn.ensemble:包含隨機森林迴歸(RandomForestRegressor)、梯度提升迴歸(GradientBoostingRegressor)等集成學習模型。
- 其他迴歸模型:LinearRegression(線性迴歸)、DecisionTreeRegressor(決策樹迴歸)、KNeighborsRegressor(最近鄰迴歸)、SVR(支持向量迴歸),用於多模型對比驗證。
1.3 數據預處理
數據預處理是保障建模效果的關鍵環節,本項目針對股票數據的特性,開展了三步核心預處理工作:
1.3.1 缺失值檢查
目標:確認數據集中是否存在缺失值,避免缺失數據對分析結果產生偏差。
關鍵源碼(變量名與語法優化後):
預處理結果:數據集的每一列均沒有缺失值,無需進行缺失值填充處理。
1.3.2 重複值檢查
目標:剔除重複數據,保證數據的唯一性與準確性。
關鍵源碼(變量名與語法優化後):
# 檢查數據集重複行數量duplicate_count = stock_data.duplicated().sum()print(f"重複行數量:{duplicate_count}")預處理結果:發現整個數據集均沒有重複的行,無需進行重複值刪除處理。
1.3.3 歸一化處理
目標:將數據壓縮至0-1區間,消除不同字段量級差異,適配機器學習模型的訓練需求。
關鍵源碼(變量名與語法優化後):

預處理結果:每列數據的分佈範圍被壓縮到0和1之間,並保留了數據的原始分佈特徵,可直接用於後續建模。
二、統計分析與可視化
2.1 相關性分析(皮爾遜係數)
分析目標:探究收盤價(close)與交易量(volume)之間的線性關聯程度,為理解價格與交易活躍度的關係提供依據。
關鍵源碼(變量名與語法優化後):
# 導入相關性分析庫from scipy.stats import pearsonr# 計算收盤價與交易量的皮爾遜相關係數及P值corr_coef, p_val = pearsonr(stock_data['close'], stock_data['volume'])print(f'皮爾遜相關係數:{corr_coef}')print(f'P值:{p_val}')分析結論:皮爾遜相關係數為0.47,介於0-0.5之間,表明收盤價與交易量存在中等強度的正線性相關關係;P值趨近於0,遠小於0.05的顯著性水平,説明該相關關係在統計上具有高度顯著性,並非偶然形成。這一結果符合金融市場基本規律——價格波動往往伴隨交易活躍度的變化。
2.2 月度交易活躍度分析
分析目標:統計1962年到2025年每個月份的平均單日交易股數,挖掘交易活躍度的季節性特徵。
關鍵源碼(變量名與語法優化後):
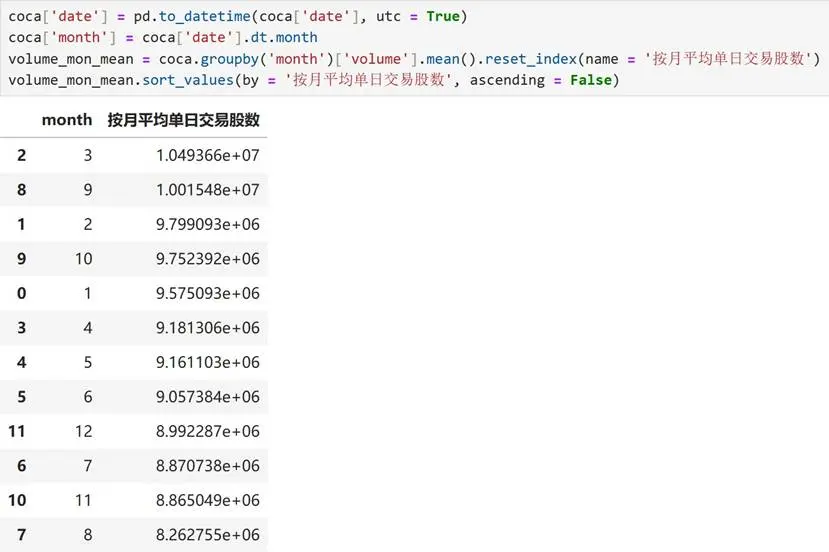
分析結論:3月和9月的平均單日交易股數最高,顯著高於其他月份,表明這兩個月份市場交易最為活躍,可能與季度末業績總結、市場促銷活動或特定行業週期因素有關;8月的平均單日交易股數最低,可能受暑期假期、市場流動性下降或季節性需求疲軟等因素影響;多數月份的平均單日交易股數集中在880萬至980萬之間,顯示全年大部分時間交易活躍度相對穩定。
2.3 年度成交量與價格趨勢分析
2.3.1 年度成交量總和分析
分析目標:統計1962年到2025年按年份的成交量總和,觀察長期成交量變化趨勢。
關鍵源碼(變量名與語法優化後):
分析結論:不同年份之間的成交量有較大的波動,早期1962-1966年成交量相對較低且數值接近;2021-2024年成交量明顯較高,可能與市場發展、投資者關注度變化、宏觀經濟環境等因素相關;2025年成交量相比前幾年有明顯下降,或許暗示市場出現了不利於交易的因素。
2.3.2 年度價格指標分析
分析目標:按年份統計開盤價、最高價、最低價和收盤價的平均值,觀察長期價格變化趨勢。
關鍵源碼(變量名與語法優化後):
# 按年份計算價格指標平均值yearly_price = stock_data.groupby('year')[['open', 'high', 'low', 'close']].mean().reset_index()print(yearly_price.head())分析結論:隨着年份的推移,可口可樂股票的開盤價、最高價、最低價和收盤價整體呈現上升趨勢,反映出可口可樂公司長期經營向好,市場價值不斷增長,公司盈利能力、市場地位等方面可能持續提升。
2.4 數據可視化展示
2.4.1 月度交易股數折線圖
可視化目標:直觀展示平均單日交易股數按月分佈的波動特徵。
關鍵源碼(變量名與語法優化後):
# 設置中文字體plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 繪製折線圖plt.plot(monthly_avg_volume['month'], monthly_avg_volume['按月平均單日交易股數'], color='deepskyblue')plt.xlabel('月份')plt.ylabel('平均交易股數', rotation=0, labelpad=30)plt.title('按月平均單日交易股數')plt.show()可視化展示:
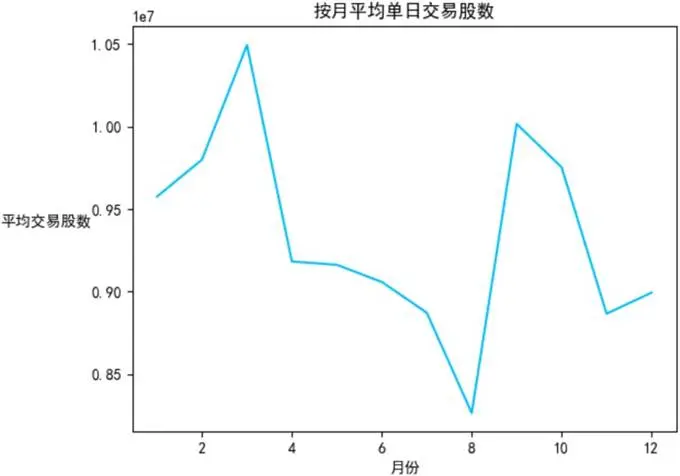
分析結論:除3月、9月的高峯和8月的低谷外,其他月份的平均交易股數呈現一定波動。1月至2月呈上升趨勢,3月後逐漸下降,4月至6月持續走低,7月進一步下降,8月觸底後9月大幅回升,隨後再次波動變化。這表明市場活躍度受多種因素影響呈現週期性波動。
2.4.2 特徵相關性熱力圖
可視化目標:展示各特徵間的相關係數,明確價格指標與交易量的關聯強度。
關鍵源碼(變量名與語法優化後):
# 計算數值字段相關性矩陣corr_matrix = stock_data.drop(['date', 'month', 'year', 'day'], axis=1).corr()# 繪製熱力圖sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap='coolwarm', cbar_kws={'label': '相關係數'})plt.yticks(rotation=0)plt.title('數據特徵相關性熱力圖')plt.xlabel('特徵')plt.ylabel('特徵', rotation=0)plt.show()可視化展示:
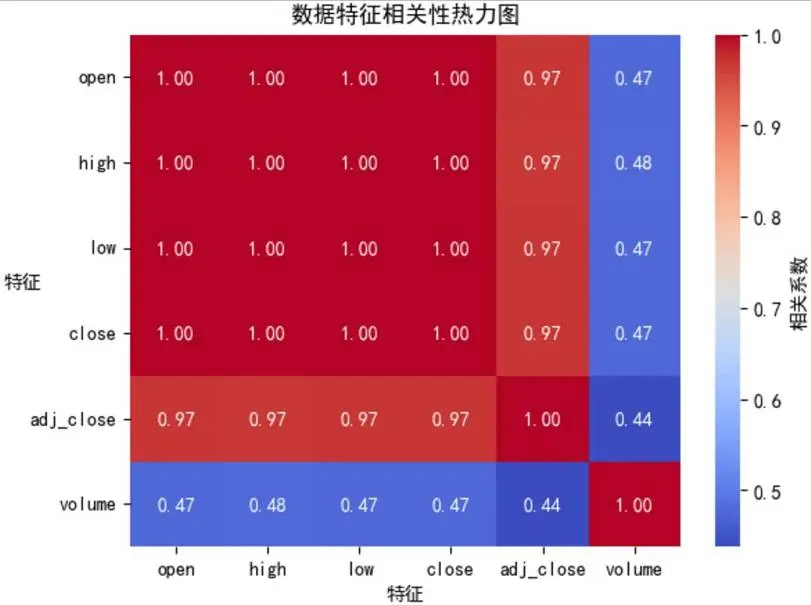
分析結論:價格指標間強正相關——開盤價、最高價、最低價、收盤價彼此間相關係數均為1.00,調整後收盤價與它們的相關係數為0.97,反映交易中價格體系的緊密聯動性;交易量與各價格指標的相關係數介於0.44-0.48之間,屬於弱相關,説明價格變化對交易量的直接影響不顯著,二者關聯不緊密。
2.4.3 年度價格趨勢圖
可視化目標:展示1962年至2025年可口可樂股票價格的長期變化趨勢。
關鍵源碼(變量名與語法優化後):

可視化展示:
分析結論:1960-2020年左右股價整體呈上升趨勢,1990年前增長平緩,之後快速攀升;開盤價與收盤價走勢相近,股價波動相對穩定;在價格上升尤其是快速上升階段,最高價與最低價差距增大,股價波動加劇。
2.4.4 年度成交量總和柱狀圖
可視化目標:展示1962年至2025年可口可樂股票成交量的長期變化趨勢。
關鍵源碼(變量名與語法優化後):

可視化展示:
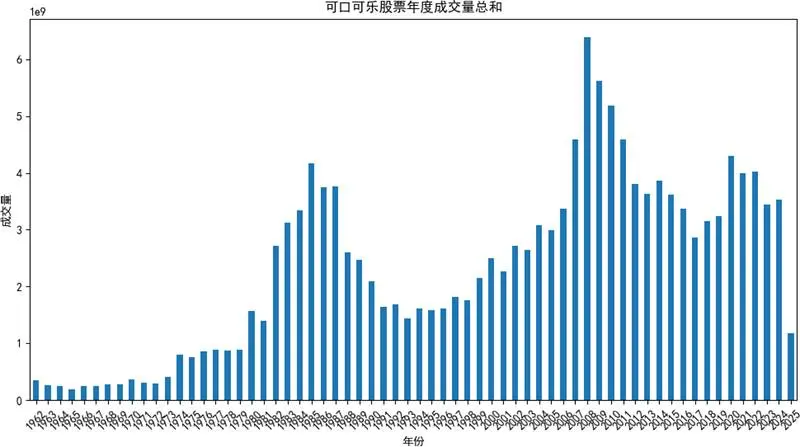
分析結論:從1960年到2025年左右,成交量總體呈上升趨勢,早期年份成交量較低且增長緩慢,中間部分年份開始逐步攀升並出現明顯增長態勢,部分年份達到較高峯值,反映市場對可口可樂股票的關注度和交易活躍度不斷提升;2025年成交量相較之前有明顯回落,或暗示市場情況有所變化。
相關文章

Python電力負荷預測:LSTM、GRU、DeepAR、XGBoost、Stacking、ARIMA結合多源數據融合與SHAP可解釋性的研究
原文鏈接:https://tecdat.cn/?p=44127
三、多模型建模與分析
3.1 交易模式識別(KMeans聚類)
建模目標:基於交易量和價格波動範圍(最高價-最低價)對可口可樂股票的交易模式進行分類,探索數據中潛在的交易模式類別,理解市場交易行為的多樣性。
關鍵源碼(變量名與語法優化後,省略部分重複邏輯代碼):
可視化展示:
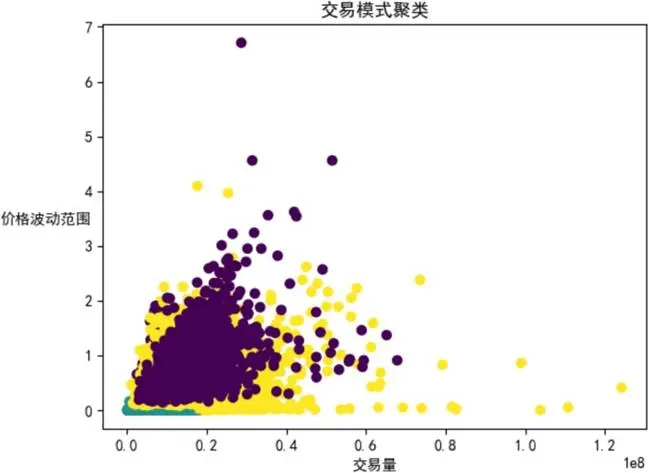
建模結論:將交易模式分為三類:低交易量/低價格波動類(集中在低交易量、低價格波動範圍區域,反映交易不活躍且價格穩定的模式)、中等綜合特徵類(交易量與波動分佈分散,反映多樣化市場狀態)、相對高波動/中等或偏高交易量類(分佈在中等或較高價格波動範圍及不同交易量區間,體現多樣化的交易活躍程度與價格波動組合模式)。該模型為理解交易行為提供了有價值的視角,具體經濟含義需結合更多市場背景信息分析。
3.2 交易模式識別(層次聚類+高斯混合模型)
建模目標:基於交易量和開盤價,利用層次聚類算法和高斯混合模型對交易模式進行分類,從不同角度挖掘市場交易特徵。
關鍵源碼(變量名與語法優化後):

建模結論:
樣本數量分佈:

層次聚類散點圖:
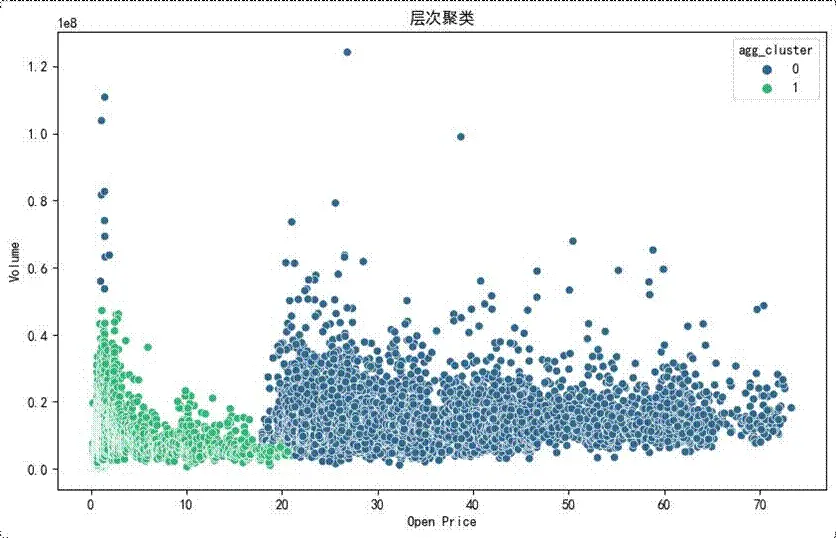
藍色點(agg_cluster為0)和綠色點(agg_cluster為1)在開盤價維度上分區明顯:藍色點集中在開盤價相對較高區域,綠色點集中在開盤價相對較低區域;成交量方面,藍色點在整個成交量範圍都有分佈,且中高成交量區域更集中,綠色點主要集中在低成交量區域。這表明高開盤價時市場活躍度更高、交易更頻繁,低開盤價時市場活躍度相對較低,兩類交易情況存在顯著差異,為研究股票交易行為和市場趨勢提供數據支撐。
高斯混合模型散點圖:
綠色點(gmm_cluster為1)佔據大部分區域,藍色點(gmm_cluster為0)僅在低開盤價區域少量分佈,兩類樣本數量差異較大。藍色聚類集中在低開盤價、低成交量區域且分佈集中;綠色聚類覆蓋寬開盤價範圍,成交量在不同水平都有分佈。該模型強調一種主要交易特徵模式(綠色聚類),與層次聚類對數據結構的理解不同,提示需結合多種模型結論綜合分析,更全面把握股票交易規律。
3.3 特徵重要性量化(隨機森林迴歸)
建模目標:用隨機森林模型量化各特徵對可口可樂股票收盤價的影響程度,明確不同特徵在預測收盤價過程中的作用大小,為投資者和分析師提供精準決策依據。
關鍵源碼(變量名與語法優化後):

建模結論:模型均方根誤差(RMSE)為0.153,預測誤差較小,在預測收盤價任務上表現較好;特徵重要性方面,高價(high)和低價(low)的重要性分別為0.5197和0.4655,是影響收盤價預測的核心因素,貢獻最大;開盤價(open)重要性為0.0148,對模型有一定影響但遠低於高、低價;成交量(volume)、年(year)、月(month)、日(day)的重要性趨近於0,對預測收盤價的貢獻微乎其微,可在後續模型優化中簡化或剔除這些特徵。隨機森林模型能較好地預測可口可樂收盤價,且高價與低價是主導預測的關鍵特徵。
3.4 短期價格預測(LSTM模型)
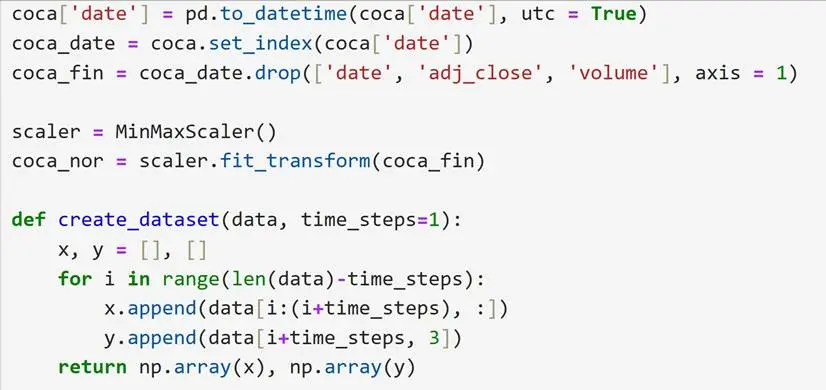
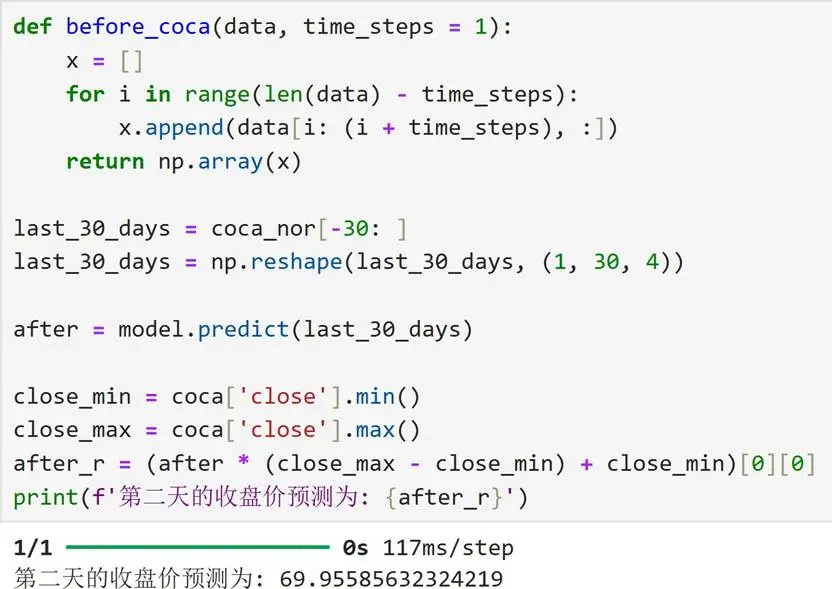
建模目標:利用過去30天的開盤價、最高價、最低價、收盤價數據,構建LSTM模型預測未來1天的收盤價,挖掘價格序列的時間依賴關係,實現收盤價的定量預測。
關鍵源碼(變量名與語法優化後,省略部分訓練細節代碼):
可視化展示(預測結果):
建模結論:訓練過程中,驗證集損失(val_loss)呈現波動變化,最終測試集均方根誤差(RMSE)為0.0118,決定係數(R²)高達0.9909,表明模型對測試集數據的預測值與真實值高度契合,能精準捕捉價格序列的內在規律,具備出色的擬合能力與預測有效性,訓練過程未出現明顯過擬合或欠擬合問題。RMSE較小且R²趨近於1,反映模型預測誤差極低、對數據的解釋能力極強,可為投資者提供有參考價值的預測結果。但需明確,股票市場受宏觀經濟、政策導向、突發事件等多重複雜因素影響,該模型僅基於歷史價格數據建模,實際應用中需融合更多元信息綜合研判。
3.5 多模型性能對比
建模目標:通過計算RMSE和R²,對比線性迴歸、決策樹迴歸、隨機森林迴歸、梯度提升迴歸、最近鄰迴歸、支持向量迴歸等模型對股票收盤價的預測準確性,篩選最適合的預測模型。
關鍵源碼(變量名與語法優化後):


建模結論:線性迴歸表現尚可(RMSE=0.0117,R²=0.9909),預測偏差極小、解釋能力強,但未顯式利用時間序列特性,需謹慎評估;LSTM模型作為時間序列模型,擅長處理時間依賴關係,契合股票數據特性,表現出色;決策樹迴歸(RMSE=0.1637,R²=-0.7546)、隨機森林迴歸(RMSE=0.1533,R²=-0.5384)、梯度提升迴歸(RMSE=0.1547,R²=-0.5675)的R²為負,預測效果不如“用均值預測”的基線模型,無法捕捉股票數據規律;最近鄰迴歸(RMSE=0.1765,R²=-1.0397)和部分支持向量迴歸(如R²=-49.4584)的RMSE極大、R²極低,嚴重欠擬合或受異常值影響,無法提供有效預測。實際應用中,LSTM模型可作為優先選擇,但需結合市場宏觀因素、行業動態等外部信息綜合判斷股票走勢。
四、結論與應用方向
4.1 核心結論
- 交易模式特徵:通過KMeans聚類、層次聚類、高斯混合模型三種算法從不同維度識別交易模式,KMeans將交易分為低交易量-低波動、中等綜合特徵、高波動-中等/偏高交易量三類;層次聚類基於開盤價和成交量劃分高/低開盤價兩類模式;高斯混合模型識別出以“高開盤價+全成交量範圍”為主的核心模式,多模型互補驗證了市場交易的多樣性。
- 特徵影響規律:隨機森林模型證實,最高價和最低價是影響收盤價的核心因素,合計貢獻超過98%,開盤價影響微弱,交易量和日期信息對收盤價的貢獻可忽略,為模型優化提供了明確的特徵篩選依據。
- 預測模型優勢:LSTM模型在短期價格預測任務中表現最優,測試集RMSE僅為0.0118,R²達0.9909,遠優於傳統迴歸模型,能精準捕捉價格序列的時間依賴關係,具備實用的短期預測價值。
4.2 應用方向
- 投資決策輔助:投資者可結合LSTM模型的短期價格預測結果與多聚類算法識別的交易模式,制定差異化買賣策略。例如,在高波動-高交易量模式下,參考預測結果把握短期買賣時機;在低波動模式下,採取長期持有策略。
- 風險管理:利用價格波動預測與交易模式分析,設置合理的止損止盈點。針對高波動交易模式,提高風險警惕性,縮小倉位規模;針對低波動模式,可適當放寬風險閾值,提升資金使用效率。
- 投資組合優化:將可口可樂股票的分析結論納入投資組合管理,結合其價格穩定性、預測趨勢等特徵,與高風險資產進行搭配,優化組合風險收益比,實現資產的多元化配置。
- 金融研究拓展:為金融領域的時間序列預測、市場微觀結構研究提供實踐案例,推動LSTM、多聚類算法等方法在股票市場分析中的應用深度與廣度,助力探索更復雜的市場行為與規律。
五、問題與解決方法
5.1 日期數據格式不統一
問題:原始日期字段存在字符串格式不規範(如不同年份表示方式、月份/日期補零問題),導致無法直接用於時間序列分析。
解決方法:使用pandas.to_datetime()函數統一轉換日期格式,確保日期字段為datetime類型,並提取年份、月份、日等時間特徵,便於後續統計分析和模型輸入。
5.2 模型過擬合風險
問題:在構建LSTM模型時,訓練集損失持續下降但驗證集損失波動,可能出現過擬合。
解決方法:引入Dropout層(dropout_rate=0.2-0.3)抑制過擬合,同時採用早停機制(EarlyStopping)監控驗證集損失,當損失連續10個epoch無改善時停止訓練並恢復最優權重,有效保障模型的泛化能力。
5.3 特徵冗餘與重要性篩選
問題:初始特徵包含開盤價、最高價、最低價、交易量、日期等,需確定哪些特徵對收盤價預測貢獻顯著。
解決方法:通過隨機森林模型量化特徵重要性,篩選出最高價、最低價兩個核心特徵,剔除交易量、日期等冗餘特徵,優化模型輸入維度,提升預測效率與準確性。
5.4 時間序列數據建模複雜性
問題:LSTM模型需要將歷史數據轉換為特定的時間步長格式(如過去30天數據預測未來1天),數據預處理邏輯較複雜。
解決方法:定義create_dataset函數,將歸一化後的價格數據按時間步長分割為輸入序列(X)和目標值(Y),確保輸入數據維度符合LSTM模型要求([樣本數,時間步長,特徵數]),並通過train_test_split按時間順序劃分數據集(不打亂順序),保留時間序列的時序性。
5.5 可視化結果解讀偏差
問題:相關性熱力圖中價格指標間強相關(相關係數≥0.97),但交易量與價格指標弱相關,需驗證是否存在數據清洗不徹底或特徵工程疏漏。
解決方法:重新檢查數據預處理步驟,確認無缺失值、重複值,且歸一化方法(MinMaxScaler)未破壞數據分佈;結合金融理論分析,交易量與價格的弱相關性符合市場實際(價格波動可能由供需以外的因素驅動),最終確認可視化結果合理。
