

全文鏈接:https://tecdat.cn/?p=44755
原文出處:拓端數據部落公眾號

關於分析師

在此對Yuan Rumeng對本文所作的貢獻表示誠摯感謝,她在安徽理工大學完成了應用統計學專業的碩士學位,專注數據分析與人工智能領域。擅長R語言、Python、深度學習、數據挖掘與數據降維。
Yuan Rumeng曾作為數據分析師,在多個涉及高維生物醫學數據的項目中,利用統計建模與機器學習方法,深入挖掘疾病風險因子並構建預測模型,為臨牀研究的假設生成與證據轉化提供了堅實的數據洞察支持。
項目文件目錄截圖:
專題:高維生物數據因果推斷與精準醫學應用
引言
在精準醫療時代,表觀遺傳數據已成為解析“環境-基因-疾病”複雜網絡的核心鑰匙。我們面臨着前所未有的數據挑戰:數十萬個DNA甲基化位點與有限的臨牀樣本並存,傳統的“一因一果”分析框架已然失效。如何從這海量的噪聲中,篩檢出真正介導疾病發生的關鍵分子路徑?
本文要講述的,正是這樣一個數據科學家如何運用統計智慧和計算工具,破解童年逆境如何“刻入”基因組並導致成年後心理創傷的故事。童年虐待是PTSD的已知風險因素,但其間精確的生物學橋樑一直是個黑箱。我們嘗試用數據建立這座橋樑——不是簡單關聯,而是嚴謹的因果推斷。
為此,我們設計了一套名為“OW-HDMA”的組合算法:用重疊加權(Overlap Weighting, OW) 平衡混雜,模擬隨機試驗的純淨環境;用高維中介分析(High-Dimensional Mediation Analysis, HDMA) 框架,結合迭代特徵篩選(Sure Independence Screening, SIS) 與去偏LASSO估計,對三十餘萬個候選位點進行“大海撈針”式的精準捕撈。這套方法不僅解決了超高維數據的計算難題,更提升了在觀察性研究中因果推斷的穩健性。
本文內容改編自過往客户諮詢項目的技術沉澱並且已通過實際業務校驗,該項目完整代碼與數據已分享至交流社羣。閲讀原文進羣,可與800+行業人士交流成長;還提供人工答疑,拆解核心原理、代碼邏輯與業務適配思路,幫大家既懂怎麼做,也懂為什麼這麼做;遇代碼運行問題,更能享24小時調試支持。
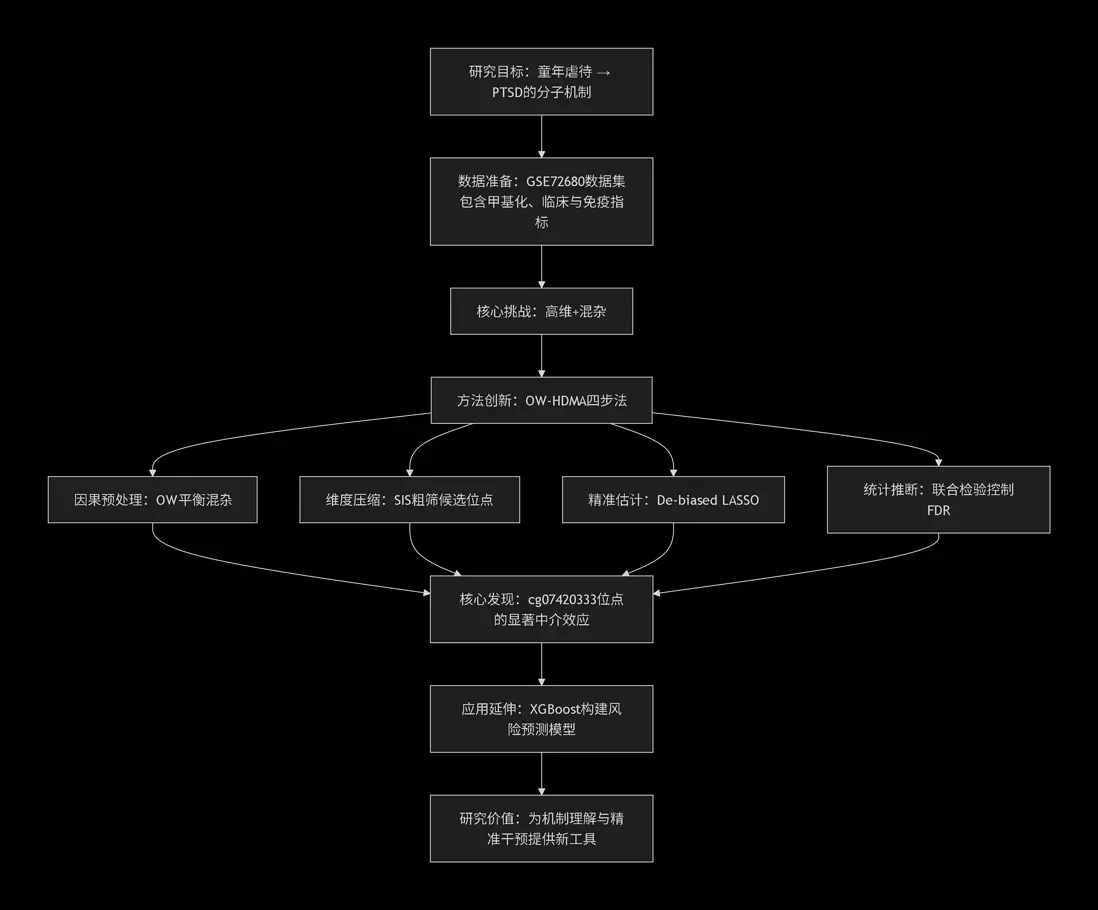
下方流程圖直觀地呈現了本次研究的“解題思路”:
研究背景:童年創傷的“生物烙印”
童年虐待是一個嚴峻的全球性公共衞生問題,其影響深遠,是多種精神障礙的強力風險因素。令人深思的是,早年遭受的創傷,其陰影可以跨越數十年,顯著增加個體成年後罹患創傷後應激障礙的風險。這背後隱藏着一個關鍵的生物學問題:早期的心理社會壓力,是如何在分子層面留下持久印記,並改變個體終身的健康軌跡的?
近年來的研究將目光投向了表觀遺傳學,特別是DNA甲基化。DNA甲基化如同基因這本“生命之書”上的鉛筆註釋,它不改變文字(基因序列)本身,卻能決定哪些段落(基因)被閲讀(表達)。童年虐待這類強烈的環境壓力,可能像一隻無形的手,在某些關鍵基因上擦除或添加了甲基化“註釋”,從而永久性地改變大腦應對壓力的方式,埋下PTSD的易感種子。
然而,驗證這一假説面臨巨大方法學鴻溝。全基因組甲基化掃描產生數十萬個數據點(CpG位點),樣本量往往只有幾百。這種“維度遠超樣本”的高維數據場景,使得傳統統計方法要麼力不從心,要麼結果極不可靠。更復雜的是,童年虐待並非隨機發生,受虐待羣體與未受虐待羣體在性別、年齡、社會經濟地位等多方面存在系統性差異(即混雜偏倚)。若不妥善處理這些混雜因素,任何發現的“關聯”都可能是誤導。
因此,本研究的目標清晰而富有挑戰:開發一套能同時處理“高維數據”和“觀察性研究混雜偏倚”的分析框架,從分子層面實證童年虐待通過DNA甲基化影響PTSD的因果路徑。
數據處理:從原始文件到分析變量
數據來源與清洗
本研究數據源自一項公開的創傷研究隊列(GEO:GSE72680),包含了童年虐待經歷、PTSD症狀評分(BDI和PSS)、年齡、性別、六類免疫細胞比例,以及約48萬個CpG位點的全基因組甲基化數據。
原始數據格式較為雜亂,不同變量分散在各列。我們的第一步是進行數據清洗與整合。核心思路是遍歷數據框的每一列,根據列名或內容特徵(如包含“cd8”、“cd4”等關鍵詞)提取對應的數值。
# 示例:清洗並提取CD8 T細胞數據# 初始化一個空列表,用於存放從每一列中找到的“cd8”相關值cd8結果列表 <- vector("list", ncol(原始數據框))for (第i列 in 1:ncol(原始數據框)) { # 使用正則表達式匹配,不區分大小寫查找包含“cd8”的單元格 匹配到的值 <- 原始數據框[[第i列]][grepl("cd8", 原始數據框[[第i列]], ignore.case = TRUE)] if (length(匹配到的值) > 0) { cd8結果列表[[第i列]] <- 匹配到的值 } else { cd8結果列表[[第i列]] <- NA # 如果沒找到,用NA填充 }}# 將列表名設置為原始列名,方便後續追蹤names(cd8結果列表) <- colnames(原始數據框)# ... 省略後續將列表轉換為數據框、以及處理CD4、BDI等其他8個變量的類似代碼 ...代碼解讀:這段R代碼通過循環和模式匹配(grepl),像用篩子一樣從原始數據的每一列中“篩”出我們需要的特定變量值,是數據整理中常見的“寬變長”思路。
我們將提取出的CD8、CD4、童年虐待(Abuse)、自然殺傷細胞(NK cells)、B細胞(Bcells)、單核細胞(Monocytes)、粒細胞(Granulocytes)、貝克抑鬱量表(BDI)、創傷後應激障礙症狀量表(PSS)共9個關鍵變量的數據,通過添加標識列(Marker)後進行行合併,最終得到一個整潔的、便於分析的數據集。
變量定義
清晰定義每個變量的角色是因果分析的基礎:
- 暴露變量(X):童年期是否遭受虐待(是=1,否=0)。
- 結果變量(Y):是否患有PTSD。我們綜合BDI和PSS量表評分,設定更嚴格的複合標準:
PSS≥14 且 BDI≥14判定為有症狀;PSS≤7 且 BDI≤7判定為無症狀。 - 中介變量(M):全部約48萬個CpG位點的甲基化M值(由原始的β值轉換而來,統計特性更優)。
- 協變量(C):年齡(Age)、性別(Sex)以及六種免疫細胞的比例,這些被視為潛在的混雜因素。
核心方法:OW-HDMA算法詳解
面對“超高維中介變量”和“非隨機暴露”兩大難題,我們創新性地將重疊加權整合進高維中介分析框架,形成四步走的穩健分析流程(OW-HDMA),其核心邏輯如圖2所示。
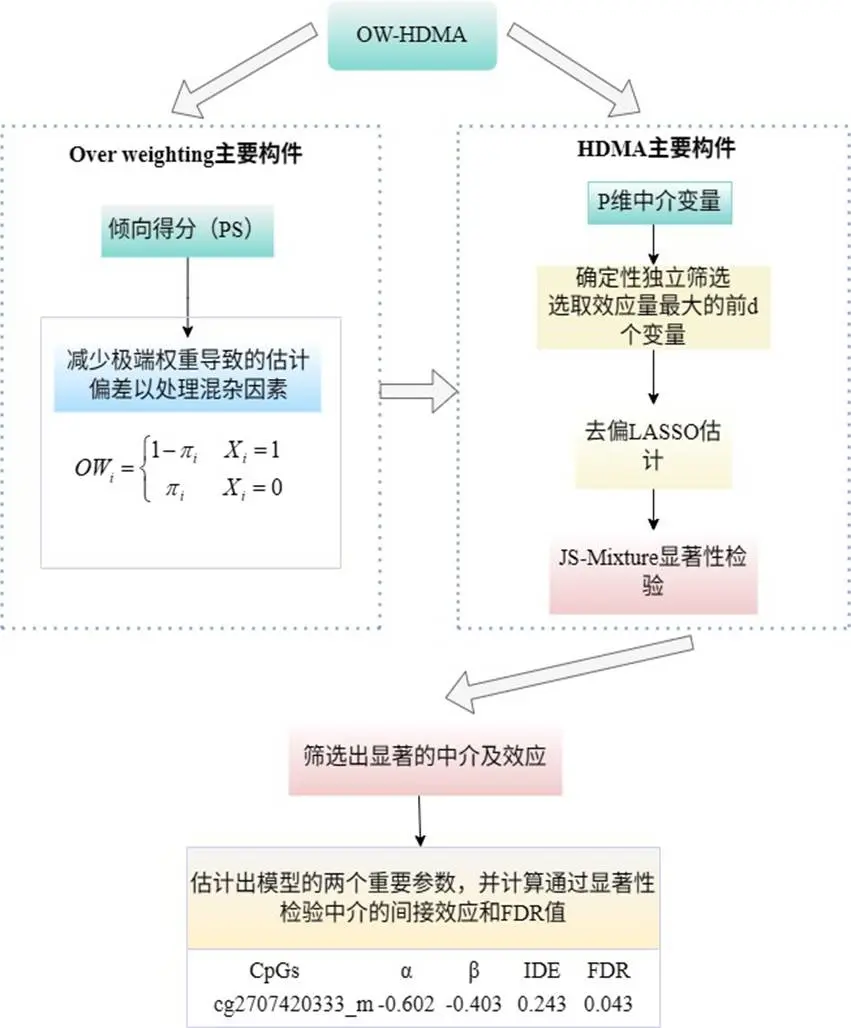
第一步:用重疊加權(OW)平衡混雜,模擬隨機試驗
在觀察性研究中,直接比較“暴露組”(受虐)和“對照組”(未受虐)會因基線特徵不平衡而產生偏倚。傳統方法是逆概率加權,但容易因傾向評分極端而產生巨大方差。我們採用更穩定的重疊加權。它的思想很巧妙:更關注那些傾向評分(即基於協變量預測出的受虐待概率)在0.5附近的個體。這些人在兩組中特徵高度相似,如同隨機試驗中“被隨機分到不同組”的個體,對他們的分析最能反映真實的暴露效應。
第二步:用迭代特徵篩選(SIS)實現降維
直接對48萬個位點建模是不可能的。我們採用SIS方法,依據每個甲基化位點與結局(PTSD)的邊際關聯強度,快速篩選出前 d = [2n/log(n)] 個最相關的候選位點,將維度從數十萬降至幾十(本研究篩出78個),為後續精細分析鋪路。
第三步:用去偏LASSO進行無偏係數估計
在篩選出的候選位點中,位點間仍可能存在共線性(相關性)。我們使用去偏LASSO來擬閤中介模型。它是LASSO的進階版,能在進行變量選擇、產生稀疏解的同時,對入選變量的係數進行糾偏,得到接近無偏的估計值及其標準誤。
第四步:聯合顯著性檢驗與錯誤發現率控制
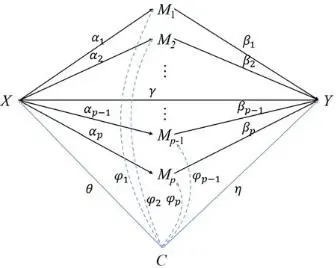
對於每個候選位點,其中介效應等於“暴露→甲基化”的路徑係數(α)與“甲基化→結局”的路徑係數(β)的乘積。我們檢驗複合零假設 H₀: α=0 或 β=0(即至少一條路徑不成立)。通過計算聯合P值,並採用能精準控制錯誤發現率(FDR) 的混合零分佈檢驗(JS-mixture),最終識別出那些通過嚴格統計檢驗的、真正發揮中介作用的甲基化位點。中介模型的因果路徑如圖3所示。
相關文章
Python梯度提升樹、XGBoost、LASSO迴歸、決策樹、SVM、隨機森林預測中國A股上市公司數據研發操縱融合CEO特質與公司特徵及SHAP可解釋性研究
原文鏈接:https://tecdat.cn/?p=44265
結果分析:從免疫特徵到分子中介
1. 研究人羣基線特徵
我們首先比較了PTSD患者組與健康對照組的基線特徵。如表1所示,兩組在年齡、性別上無顯著差異,但童年虐待經歷的比例存在極顯著差異(P < 0.001)。此外,部分免疫細胞的比例在組間也呈現出趨勢性差異。
表1:病例組與對照組基線特徵比較(部分)
| 變量 | 對照組 (N=77) | 病例組 (N=134) | P值 |
|---|---|---|---|
| 童年虐待 (是, %) | 17 (22.1%) | 89 (66.4%) | <0.001 |
| 年齡(歲,均值±標準差) | 42.6 ± 13.7 | 41.8 ± 11.5 | 0.658 |
| CD4+ T細胞比例 | 0.177 ± 0.064 | 0.188 ± 0.067 | 0.199 |
| 單核細胞比例 | 0.090 ± 0.026 | 0.090 ± 0.025 | 0.970 |
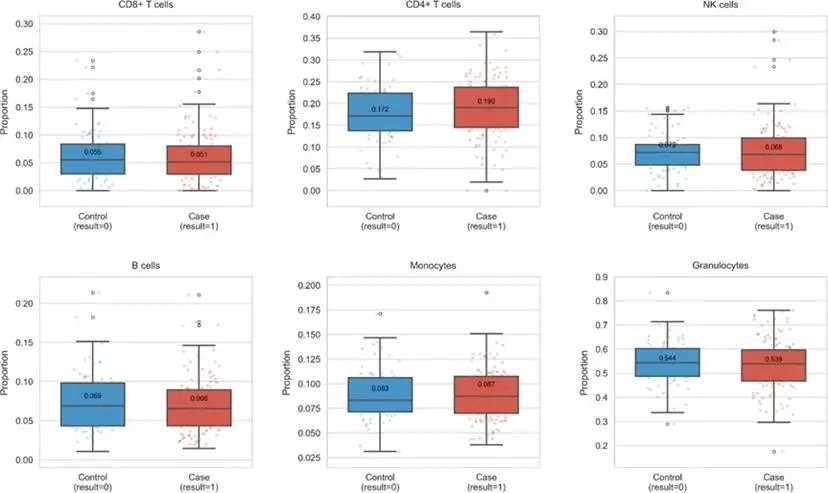
圖4更直觀地展示了兩組在六類免疫細胞比例分佈上的差異,提示免疫系統狀態可能與PTSD存在關聯。
2. 基於XGBoost的抑鬱與壓力狀態預測
為探索利用現有變量預測心理狀態的能力,我們構建了XGBoost模型,對根據BDI和PSS劃分的抑鬱/壓力等級進行分類。模型表現良好,準確率達到88%。
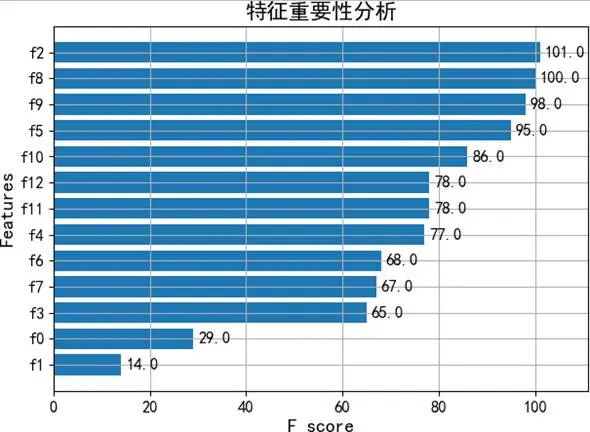
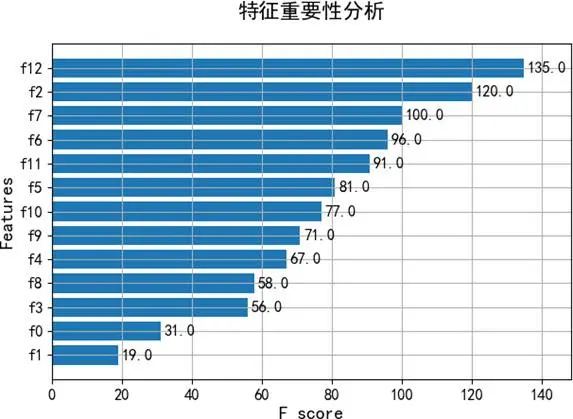
# 定義XGBoost多分類模型的關鍵參數模型參數 = { 'tree_method': 'gpu_hist', # 使用GPU加速,基於直方圖算法構建樹 'objective': 'multi:softmax', # 指定為多分類任務 'num_class': 4, # 目標類別數(針對BDI分為4類) 'max_depth': 6, # 控制樹的最大深度,防止過擬合 'learning_rate': 0.1, # 學習率,控制每棵樹的貢獻權重 'subsample': 0.8, # 每棵樹訓練時使用的樣本比例 'seed': 42 # 固定隨機種子,確保結果可重現}# ... 省略數據標準化、轉換為DMatrix格式、交叉驗證訓練及模型評估的詳細代碼 ...模型的特徵重要性分析(圖5、圖6)揭示了影響預測的關鍵因素,例如年齡和某些免疫細胞比例,這為理解影響心理狀態的生物基礎提供了線索。
3. OW-HDMA中介分析核心發現
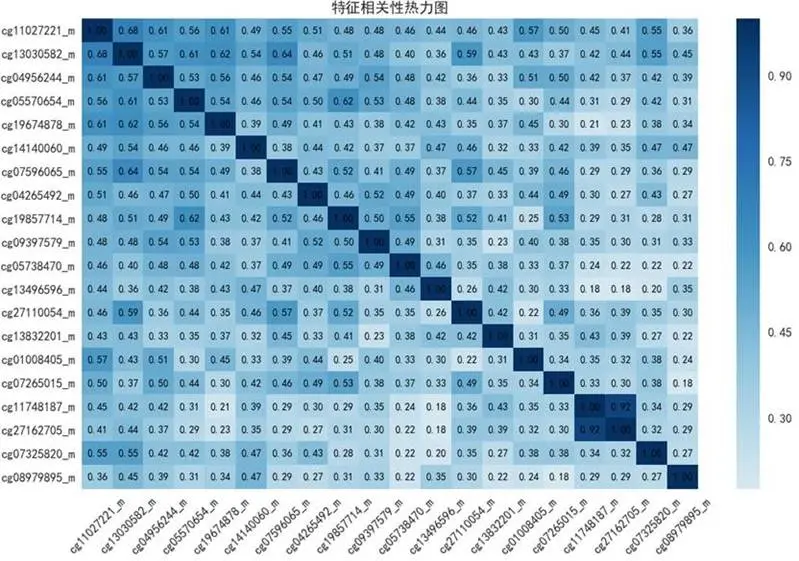
應用我們提出的OW-HDMA流程進行核心分析。SIS步驟從48萬位點中預篩選出78個候選位點。圖9展示了其中相關性最強的前20個位點的熱圖,證實了數據中存在複雜的共線性結構,這凸顯了使用去偏LASSO等高級方法進行估計的必要性。
最終,在嚴格控制FDR的條件下,只有一個CpG位點(cg07420333)被鑑定為具有顯著的中介效應。我們對比了OW和傳統IPW兩種加權方法的結果(表2)。兩者均成功識別出該位點,其中介效應估計值(α×β)分別為0.243和0.269。值得注意的是,基於OW方法估計的係數標準誤更小,這表明在本次數據分析中,OW方法可能提供了更穩定、更高效的估計。
表2:顯著中介甲基化位點檢測結果對比
| 方法 | CpG位點 | α (暴露->中介) | β (中介->結果) | 中介效應(IDE) | FDR校正P值 |
|---|---|---|---|---|---|
| OW-HDMA (本文方法) | cg07420333 | -0.602 (0.244) | -0.403 (0.189) | 0.243 | 0.044 |
| IPW-HDMA (傳統方法) | cg07420333 | -0.624 (0.244) | -0.431 (0.198) | 0.269 | 0.036 |
注:括號內為標準誤。係數α為負表示童年虐待可能降低該位點甲基化水平;係數β為負表示該位點甲基化水平降低與PTSD風險增加相關。
討論與展望
本研究成功地將重疊加權(OW)整合到高維中介分析(HDMA)框架中,為探索“童年虐待-DNA甲基化-PTSD”這一複雜因果路徑提供了穩健的分析工具。我們不僅初步驗證了表觀遺傳機制可能在此關聯中扮演中介角色,更重要的是展示了一套能同時攻克“高維”與“混雜”兩大方法論堡壘的完整流程。方法學對比顯示,OW在本次分析中表現出優於傳統IPW的估計穩定性。
發現的顯著中介位點cg07420333是一個重要的起點。它如同一枚精確的“分子座標”,為後續的生物學功能驗證(如其調控的基因、影響的下游通路)指明瞭方向。當然,統計顯著性不等同於生物或臨牀意義,這一發現需要在獨立樣本和實驗模型中得到進一步證實。
本研究的侷限也為未來指明瞭方向。當前模型基於線性假設,未考慮甲基化位點間可能存在的複雜交互作用;樣本量相對高維數據而言仍有提升空間。展望未來,隨着多組學數據的整合(如甲基化、轉錄組、蛋白質組),構建更精細、動態的“環境壓力-分子網絡-疾病表型”圖譜,將是揭示精神疾病複雜機制並最終實現精準預防與干預的關鍵。
