

(<center>Java 大視界 --Java 大數據在智慧交通公交車輛調度與乘客需求匹配中的應用創新</center>)
引言:
嘿,親愛的 Java 和 大數據愛好者們,大家好!我是CSDN(全區域)四榜榜首青雲交!當城市的車水馬龍逐漸成為生活常態,公交系統作為城市交通的 “血管”,其調度效率與服務質量直接影響着數百萬市民的日常出行體驗。傳統調度模式的侷限性日益凸顯,而 Java 大數據如同一位 “智慧交通建築師”,正用代碼與算法重構公交系統的未來。今天,就讓我們深入《Java 大視界 --Java 大數據在智慧交通公交車輛調度與乘客需求匹配中的應用創新》,探索這場交通領域的數字化革命。

正文:
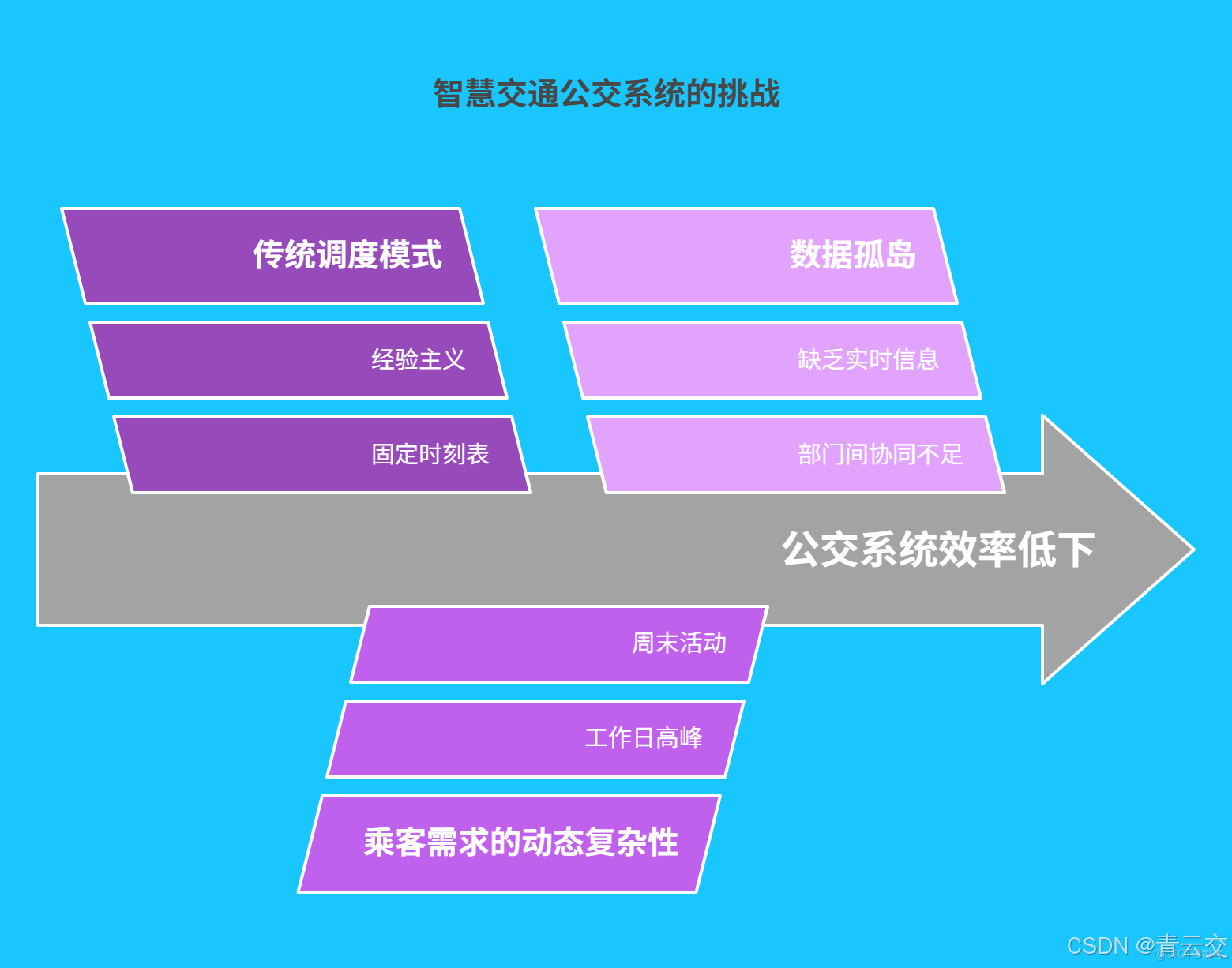
一、智慧交通公交系統現狀與挑戰
1.1 傳統調度模式的侷限性
傳統公交調度就像一位墨守成規的 “老工匠”,依賴固定時刻表與經驗主義進行車輛調配。在某一線城市的早高峯,儘管公交公司提前增加了發車頻次,但由於未能實時感知突發交通事故導致的道路擁堵,部分熱門線路車輛平均延誤時間長達 30 分鐘,乘客在站台望眼欲穿卻遲遲等不到車;而在夜間非高峯時段,某些線路車輛空座率超過 60%,白白消耗着能源與運力資源。據權威數據統計,傳統調度模式下,全國公交車輛平均空駛率高達 35% ,每年造成的運營成本浪費超過百億元。
1.2 乘客需求的動態複雜性
如今的乘客出行需求早已不再單一,就像變幻莫測的天氣,充滿了動態與個性。工作日的早晚高峯,上班族們如同候鳥遷徙般涌入公交,只為準時奔赴職場;而到了週末,年輕人相約商圈購物娛樂,家庭帶着孩子前往公園遊玩,出行目的與時間分佈變得極為分散。某二線城市公交公司的調研顯示,週末與工作日相比,商圈周邊公交線路客流量激增 70% ,且乘客對車輛準點率、舒適度的要求提升了 40% 。傳統 “一刀切” 的調度方式,顯然已經無法滿足乘客日益多樣化的出行訴求。
1.3 數據孤島引發的協同困境
公交系統的高效運轉,本應是多部門協同配合的 “交響樂”,但現實卻是各自為政的 “獨奏會”。公交公司無法實時獲取交管部門的限行與擁堵信息,交管部門也難以掌握公交車輛的實時位置與載客情況,站點更無法提前預知客流高峯。以杭州某大型公交樞紐為例,曾因各部門數據未打通,在一次重大活動期間,公交車輛調度與道路限行措施無法協同,導致樞紐周邊道路擁堵時長增加 20% ,車輛週轉效率降低 15% ,乘客怨聲載道。
二、Java 大數據技術基礎
2.1 多源數據採集與整合
Java 憑藉其強大的網絡編程能力,成為公交系統數據採集的 “超級捕手”。通過 HttpClient 庫,可輕鬆從交通管理平台獲取實時路況數據;利用 WebSocket 技術,能夠實現車載傳感器數據的毫秒級實時傳輸。以下是利用 HttpClient 獲取路況信息的完整代碼,每一行註釋都為你解開數據獲取的奧秘:
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
public class TrafficDataCollector {
public static void main(String[] args) throws IOException, InterruptedException {
// 創建HttpClient實例,它就像一個數據搬運工
HttpClient client = HttpClient.newHttpClient();
// 構建請求URI,指定要獲取路況數據的區域(這裏以CBD區域為例)
URI uri = URI.create("https://traffic-api.com/api/road_status?area=CBD");
// 創建GET請求對象,向目標地址發起數據請求
HttpRequest request = HttpRequest.newBuilder()
.uri(uri)
.build();
// 發送請求並獲取響應,等待數據“送貨上門”
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
// 打印獲取到的路況數據,查看數據內容
System.out.println(response.body());
}
}
採集到的數據如同散落的珍珠,需要合適的容器來收納。我們採用 HDFS 與 HBase 的混合存儲架構:HDFS 以其高容錯性和擴展性,負責存儲海量原始數據,就像一個巨大的倉庫;HBase 則專注於結構化數據的快速讀寫,如同高效的智能貨架。通過 Java API 實現數據的無縫存儲與讀取,代碼示例如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBaseDataStore {
public static void main(String[] args) throws IOException {
// 加載HBase配置,為連接HBase做準備
Configuration config = HBaseConfiguration.create();
try (
// 創建HBase連接,建立與“數據倉庫”的通道
Connection connection = ConnectionFactory.createConnection(config);
// 獲取名為“bus_data”的表對象,相當於打開倉庫中的一個貨架
Table table = connection.getTable(org.apache.hadoop.hbase.TableName.valueOf("bus_data"))
) {
// 創建Put對象,用於向表中插入數據,就像準備放入貨架的貨物
Put put = new Put(Bytes.toBytes("bus_001"));
// 向Put對象中添加列數據,這裏記錄車輛位置信息
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("location"), Bytes.toBytes("116.39,39.9"));
// 將數據寫入表中,完成數據存儲操作
table.put(put);
}
}
}
2.2 數據處理與分析框架
在數據處理的 “高速路上”,Spark Streaming 與 Flink 是 Java 生態下的兩輛 “超級跑車”,能夠對公交數據進行毫秒級實時處理。我們以 Spark Streaming 實現公交客流量實時統計為例,帶你領略實時計算的魅力:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
public class BusPassengerCount {
public static void main(String[] args) {
// 創建Spark配置,設置應用名稱和運行模式
SparkConf conf = new SparkConf().setAppName("BusPassengerCount").setMaster("local[*]");
// 創建JavaStreamingContext對象,它是Spark Streaming的核心入口
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
// 從指定的Socket端口接收數據,模擬實時數據輸入流
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
// 將接收到的每行數據按空格分割成單詞,展開數據
JavaDStream<String> words = lines.flatMap((FlatMapFunction<String, String>) s -> Arrays.asList(s.split(" ")).iterator());
// 將每個單詞映射為(key, 1)的形式,用於後續統計
JavaPairDStream<String, Integer> pairs = words.mapToPair((PairFunction<String, String, Integer>) word -> new Tuple2<>(word, 1));
// 對相同key的單詞進行累加計數,統計每個單詞出現的次數
JavaPairDStream<String, Integer> wordCounts = pairs.updateStateByKey((Function2<List<Integer>, Optional<Integer>, Integer>) (values, state) -> {
Integer sum = state.or(0);
for (Integer val : values) {
sum += val;
}
return sum;
});
// 打印統計結果,查看實時計算的客流量數據
wordCounts.print();
// 啓動Spark Streaming應用,開始處理數據
jssc.start();
try {
// 等待應用執行結束
jssc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
而 Flink 在複雜事件處理方面表現卓越,通過 CEP(複雜事件處理)庫,可實時識別公交車輛的異常行為,如超速、偏離路線等,以下是實現代碼:
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternSelectFunction;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.OutputTag;
import java.util.List;
import java.util.Map;
public class BusAnomalyDetection {
public static void main(String[] args) throws Exception {
// 創建Flink流處理環境,搭建數據處理舞台
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 從自定義數據源獲取公交事件流數據
DataStream<BusEvent> busEvents = env.addSource(new BusEventSource());
// 定義模式:開始事件為速度大於80,緊接着下一個事件速度也大於80
Pattern<BusEvent, ?> pattern = Pattern.<BusEvent>begin("start")
.where(event -> event.getSpeed() > 80)
.next("next")
.where(event -> event.getSpeed() > 80);
// 定義側輸出標籤,用於收集正常事件數據
OutputTag<BusEvent> outputTag = new OutputTag<BusEvent>("normalEvents") {};
// 應用模式匹配,篩選出異常事件,並將正常事件通過側輸出保留
DataStream<BusEvent> filteredEvents = CEP.pattern(busEvents, pattern)
.sideOutputLateData(outputTag)
.select(patternSelectFunction);
// 獲取側輸出的正常事件流
DataStream<BusEvent> normalEvents = filteredEvents.getSideOutput(outputTag);
// 執行Flink作業,開始數據處理
env.execute("Bus Anomaly Detection");
}
private static PatternSelectFunction<Map<String, List<BusEvent>>, BusEvent> patternSelectFunction =
new PatternSelectFunction<Map<String, List<BusEvent>>, BusEvent>() {
@Override
public BusEvent select(Map<String, List<BusEvent>> pattern) throws Exception {
return pattern.get("start").get(0);
}
};
}
class BusEvent {
private String busId;
private double speed;
private double longitude;
private double latitude;
// 省略getter和setter方法
}
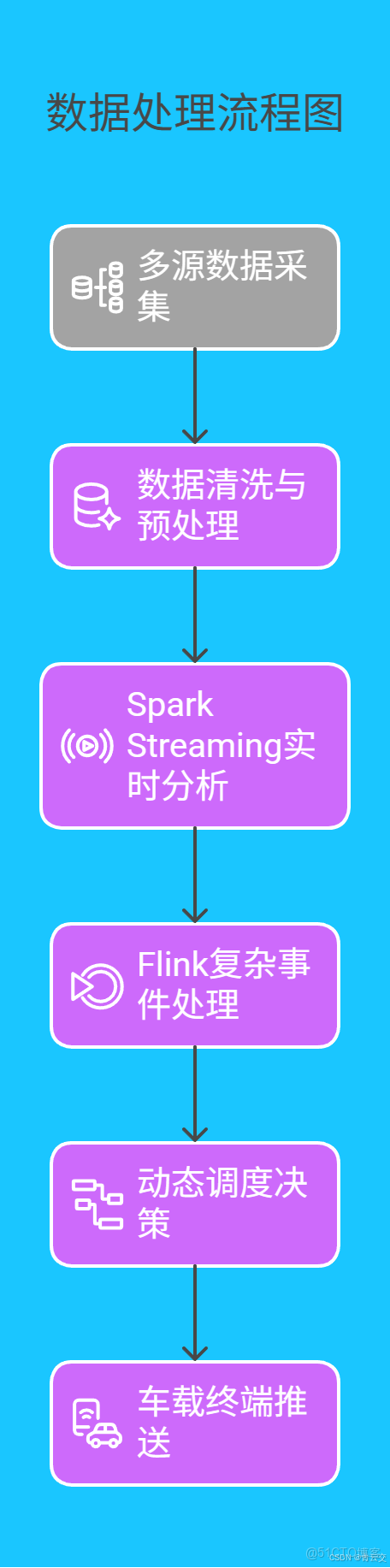
為了更直觀地展示數據處理流程,我們看如下流程圖:
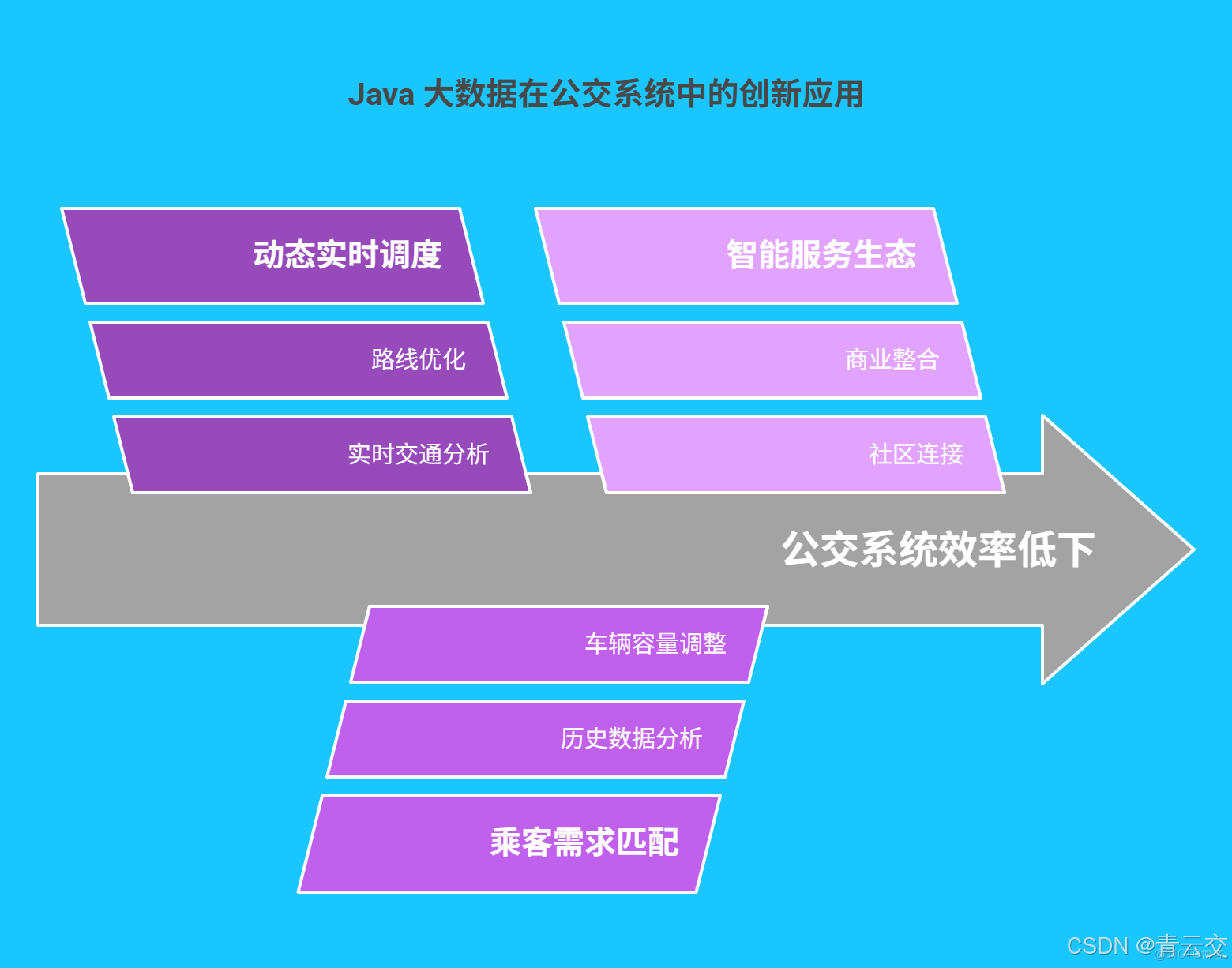
三、Java 大數據在公交系統的創新應用
3.1 動態實時調度系統
基於 Java 大數據構建的動態調度系統,就像一位 “交通指揮官”,通過實時分析路況、車輛位置、乘客需求數據,實現智能發車與路線調整。系統採用 Dijkstra 算法計算最優行駛路線,結合強化學習算法動態調整發車頻率。當檢測到某路段擁堵時,系統會在 10 秒內 自動為途徑車輛規劃替代路線,並通過車載終端推送至司機。某省會城市應用該系統後,車輛平均延誤時間減少 30% ,運營成本降低 18% ,公交準點率從 65% 提升至 85% 。
3.2 乘客需求精準匹配
Java 大數據如同一位 “出行預言家”,通過對歷史乘車數據、實時客流數據的深度分析,精準預測乘客出行需求。利用協同過濾算法,為乘客推薦最優乘車方案,包括換乘路線、候車時間等信息。同時,系統根據乘客需求熱度動態調整車輛運力,在需求高峯時段增派大型車輛,在平峯時段採用小型巴士。上海某公交線路試點該方案後,乘客滿意度從 68% 飆升至 89% ,真正實現了 “車等人,而非人等車” 的智慧出行體驗。
3.3 智能公交服務生態構建
Java 大數據不僅優化公交調度,更致力於構建智能公交服務生態。通過整合公交系統與周邊商業、社區數據,為商家提供精準營銷建議,同時結合社區居民出行規律優化公交線路佈局。深圳某社區與公交公司合作,基於大數據分析新增 3 條 社區接駁線路,覆蓋周邊 80% 的小區,居民出行便利度顯著提升,還帶動了周邊商圈的消費增長,實現了多方共贏。
四、實際案例深度剖析
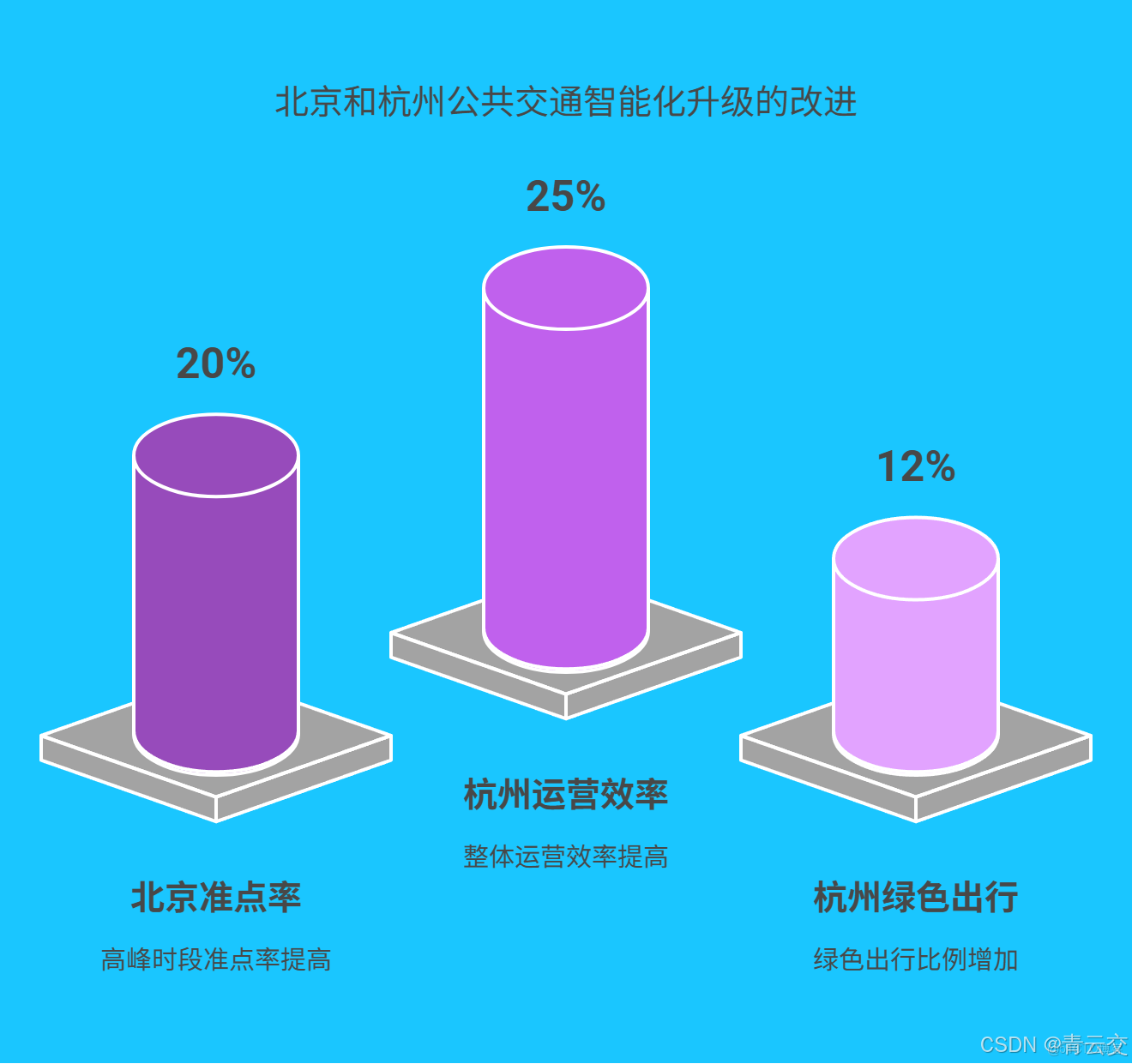
4.1 案例一:北京公交智能化升級
北京公交集團引入 Java 大數據平台後,將全市 3 萬餘輛 公交車的實時數據與高德地圖路況信息深度融合,構建起智能調度系統。系統每 5 分鐘 更新一次調度方案,高峯期車輛準點率從 65% 躍升至 85% 。同時,通過分析乘客刷卡數據,優化 300 餘條 公交線路,減少重複線路里程 2000 餘公里 ,年節約運營成本超 2 億元 ,為超 2000 萬北京市民帶來了更高效、便捷的出行體驗。
4.2 案例二:杭州 “雲公交” 項目
杭州推出的 “雲公交” 項目,堪稱 Java 大數據應用的典範。系統通過分析支付寶掃碼乘車數據、地鐵客流數據,精準預測公交需求熱點。在旅遊旺季,針對西湖景區周邊公交線路,動態增派雙層觀光巴士,日均運送遊客量增加 40% 。項目實施後,杭州公交整體運營效率提升 25% ,綠色出行比例提高 12% ,還榮獲 “全國智慧交通示範項目” 稱號,成為城市智慧交通建設的標杆。
結束語:
親愛的 Java 和 大數據愛好者,從打破自然語言處理的技術壁壘,到守護供應鏈的穩定運轉;從為醫療手術保駕護航,到重構公交系統的智慧脈絡,Java 大數據始終在不同領域書寫着創新傳奇。而在技術探索的道路上,我們永不止步。
親愛的 Java 和 大數據愛好者,對於 Java 大數據在智慧交通的應用,你是否還有更驚豔的創意?對於即將到來的短視頻存儲專題,你最想了解哪些核心技術?歡迎在評論區分享您的寶貴經驗與見解。
為了讓後續內容更貼合大家的需求,誠邀各位參與投票,Java 大數據的下一個技術高地在哪?你的選擇決定未來方向!快來投出你的寶貴一票。