

(<center>Java 大視界 -- Java 大數據機器學習模型在遙感圖像土地利用分類中的優化與應用</center>)
引言
嘿,親愛的 Java 和 大數據愛好者們,大家好!我是CSDN(全區域)四榜榜首青雲交!隨着衞星遙感技術的飛速發展,我們得以從 “上帝視角” 俯瞰地球,海量遙感圖像數據如同寶庫,藴藏着土地利用的關鍵信息。但面對這 “數據洪流”,傳統分類方法如同在茫茫大海撈針,效率與精度都難以滿足需求。Java 大數據與機器學習的攜手,恰似一把 “金鑰匙”,為遙感圖像土地利用分類打開了全新局面。接下來,就讓我們一同踏入這片充滿挑戰與機遇的技術領域,探尋其中的奧秘。

正文
一、遙感圖像土地利用分類現狀與挑戰
1.1 應用現狀
在當下,遙感圖像土地利用分類已成為眾多領域不可或缺的重要手段。在土地資源管理部門,工作人員藉助它繪製精準的土地利用現狀圖,掌握耕地、林地、建設用地等分佈情況,為土地規劃、資源保護提供數據支撐;城市規劃師利用分類結果,分析城市擴張趨勢、優化功能分區,讓城市建設更加科學合理;環保領域則通過它監測生態用地變化,及時發現森林砍伐、濕地退化等問題,守護地球生態環境。
然而,傳統分類方法卻面臨諸多困境。人工目視解譯,雖能保證較高準確性,但如同 “愚公移山”,效率極低。在一次省級土地利用動態監測項目中,專業團隊面對覆蓋面積達 5000 平方公里的高分辨率遙感圖像,即便日夜奮戰,也耗費了整整 3 個月時間才完成解譯工作。而基於光譜特徵的統計分類方法,像最大似然分類法,在面對複雜地物時,常常 “誤判”。例如在城鄉結合部,由於建築物、道路、農田相互交錯,光譜特徵相互干擾,導致分類精度僅能達到 72% 左右,難以滿足實際應用需求。
1.2 面臨挑戰
遙感圖像數據的複雜性堪稱 “技術迷宮”。從數據來源看,不同衞星傳感器,如高分系列衞星、哨兵衞星,其成像原理、觀測角度、時間分辨率各異,獲取的圖像數據如同 “方言不同的信息使者”,難以統一處理。在光譜維度上,同一種地物,比如水體,在不同季節、天氣條件下,光譜反射率差異明顯;而不同地物,如干燥的裸土與稀疏草地,光譜特徵卻極為相似,這就是 “同物異譜”“異物同譜” 現象,讓分類工作難上加難。
隨着衞星技術進步,數據量呈指數級增長,每天新增的遙感圖像數據可達數 TB 甚至更多。傳統單機處理方式,就像用小水管應對洪水,存儲與計算能力嚴重不足。同時,現有的機器學習模型在處理高維、複雜的遙感圖像數據時,容易陷入 “過擬合陷阱”,在訓練數據上表現良好,一旦應用到實際場景,準確率就大幅下降,成為制約遙感圖像土地利用分類發展的 “攔路虎”。
二、Java 大數據與機器學習基礎
2.1 數據處理與存儲
Java 憑藉其豐富的生態系統,成為遙感圖像數據處理的 “得力干將”。在數據讀取環節,ImageIO庫就是 “數據搬運工”,輕鬆讀取 TIFF、JPEG 等格式的遙感圖像。以下代碼展示了讀取遙感圖像並獲取其基本信息的過程:
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class RemoteSensingImageReader {
public static void main(String[] args) {
try {
// 定義要讀取的遙感圖像文件路徑
File file = new File("remote_sensing_image.tif");
// 使用ImageIO.read方法讀取圖像,將其存儲為BufferedImage對象
BufferedImage image = ImageIO.read(file);
// 輸出圖像的寬度和高度信息
System.out.println("Image width: " + image.getWidth() + ", height: " + image.getHeight());
} catch (IOException e) {
// 捕獲文件讀取過程中的異常,並打印異常信息
System.err.println("Error reading image: " + e.getMessage());
}
}
}
在數據存儲方面,Hadoop 分佈式文件系統(HDFS)與 MongoDB 組成 “黃金搭檔”。HDFS 如同一個龐大且堅固的 “數據倉庫”,憑藉其高容錯性和擴展性,能夠輕鬆容納海量的原始遙感圖像數據。下面的代碼演示瞭如何使用 Java 將本地遙感圖像上傳至 HDFS:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class HDFSImageUploader {
public static void main(String[] args) {
try {
// 創建Hadoop配置對象,用於設置HDFS相關參數
Configuration conf = new Configuration();
// 設置HDFS的默認地址,這裏假設HDFS運行在本地9000端口
conf.set("fs.defaultFS", "hdfs://localhost:9000");
// 獲取HDFS文件系統實例,建立與HDFS的連接
FileSystem fs = FileSystem.get(conf);
// 定義本地待上傳的遙感圖像文件路徑
Path localPath = new Path("local_image.tif");
// 定義HDFS上的目標存儲路徑
Path hdfsPath = new Path("/remote_sensing_images/local_image.tif");
// 將本地文件上傳到HDFS,overwrite參數設為false表示不覆蓋已存在文件
fs.copyFromLocalFile(false, localPath, hdfsPath);
System.out.println("Image uploaded to HDFS successfully.");
// 關閉與HDFS的連接,釋放資源
fs.close();
} catch (IOException e) {
// 捕獲HDFS操作過程中的異常,並打印異常信息
System.err.println("Error uploading image to HDFS: " + e.getMessage());
}
}
}
MongoDB 則以其靈活的文檔結構,擅長存儲經過預處理和特徵提取後的結構化數據。例如存儲圖像的元數據(拍攝時間、分辨率、傳感器類型等)以及分類結果數據,方便後續快速查詢與分析。
2.2 機器學習模型基礎
在遙感圖像土地利用分類領域,支持向量機(SVM)、隨機森林(Random Forest)和卷積神經網絡(CNN)是 “三大明星模型”。
SVM 基於嚴格的數學理論,通過尋找最優超平面將不同類別樣本分隔開,在處理小樣本、高維數據時表現出色。它就像一位 “精準的分類裁判”,在面對數據量相對較少但維度較高的遙感圖像特徵數據時,能準確判斷樣本類別。
隨機森林是 “智慧團隊”,由多個決策樹組成。它通過集成學習策略,綜合多個決策樹的分類結果,降低了模型的方差,提高了分類的穩定性和泛化能力。即使數據中存在噪聲或部分特徵缺失,也能給出較為可靠的分類結果。
CNN 則是 “圖像理解專家”,其獨特的卷積層、池化層結構,能夠自動提取圖像的局部特徵和空間結構信息。在處理遙感圖像時,它無需人工手動設計複雜的特徵提取算法,就能從圖像像素中學習到有價值的特徵,是目前圖像分類任務中的主流模型。
以下是使用 Deeplearning4j 框架構建簡單 CNN 模型的 Java 代碼示例,用於遙感圖像分類(簡化示例,實際應用需調整參數和數據):
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.ConvolutionLayer;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.conf.layers.SubsamplingLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;
public class RemoteSensingCNNSimple {
public static void main(String[] args) {
// 定義分類類別數,假設分為5類(如耕地、林地、草地、建設用地、水域)
int numClasses = 5;
// 設置隨機種子,保證模型訓練的可重複性
int seed = 123;
// 構建神經網絡配置
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(seed)
.activation(Activation.RELU)
.weightInit(org.deeplearning4j.nn.weights.WeightInit.XAVIER)
.updater(org.deeplearning4j.nn.updater.Updater.ADAM)
.list()
.layer(0, new ConvolutionLayer.Builder(3, 3)
.nIn(3) // 輸入通道數,對應RGB三通道圖像
.stride(1, 1)
.nOut(16) // 輸出通道數,提取16個特徵圖
.build())
.layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build())
.layer(2, new DenseLayer.Builder().nOut(128).build())
.layer(3, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX)
.nOut(numClasses)
.build())
.build();
// 創建神經網絡實例
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
// 模擬訓練數據,這裏僅為示例,實際需使用真實遙感圖像數據
int batchSize = 10;
int height = 28;
int width = 28;
int channels = 3;
INDArray features = Nd4j.randn(batchSize, channels, height, width);
INDArray labels = Nd4j.randn(batchSize, numClasses);
DataSet dataSet = new DataSet(features, labels);
// 訓練模型
model.fit(dataSet);
System.out.println("Model training completed.");
}
}
三、Java 大數據機器學習模型在遙感圖像分類中的優化
3.1 數據預處理優化
數據預處理是打開遙感圖像數據寶藏的 “第一把鑰匙”。輻射定標讓傳感器記錄的數據 “迴歸真實”,將原始數字量化值轉換為地表實際反射率;大氣校正消除大氣對光線的散射、吸收影響,還原地物真實光譜特徵;幾何校正則像 “圖像整形師”,糾正因衞星姿態、地球曲率等因素導致的圖像變形。
以幾何校正為例,藉助 Java 調用 GDAL 庫,可實現高效的幾何校正操作。以下是詳細代碼及註釋:
import org.gdal.gdal.Dataset;
import org.gdal.gdal.TranslateOptions;
import org.gdal.gdal.WarpOptions;
import org.gdal.gdal.gdal;
import org.gdal.gdalconst.gdalconstConstants;
public class RemoteSensingGeometricCorrection {
public static void main(String[] args) {
// 初始化GDAL庫,確保其所有驅動和功能可用
gdal.AllRegister();
// 輸入待校正的遙感圖像文件路徑
String inputImagePath = "original_image.tif";
// 輸出校正後圖像的文件路徑
String outputImagePath = "corrected_image.tif";
// 定義幾何校正參數,設置目標投影系統為EPSG:4326(常見地理座標系)
// 重採樣方法採用最鄰近法(near),適用於分類任務,速度快且能保持類別信息
String[] warpOptions = new String[]{
"-t_srs", "EPSG:4326",
"-r", "near"
};
WarpOptions options = new WarpOptions(warpOptions);
// 執行幾何校正操作,將輸入圖像按照指定參數校正並保存為輸出圖像
Dataset result = gdal.Warp(outputImagePath, inputImagePath, options);
if (result != null) {
System.out.println("Geometric correction completed successfully.");
// 釋放校正結果數據集佔用的資源
result.delete();
} else {
System.err.println("Geometric correction failed.");
}
// 釋放GDAL庫佔用的資源,確保程序資源合理回收
gdal.GDALDestroyDriverManager();
}
}
此外,圖像增強技術通過直方圖均衡化、濾波等操作,提升圖像的對比度和清晰度,讓地物特徵更加明顯,為後續分類任務提供 “優質數據原料”。
3.2 模型融合與參數調優
單一機器學習模型如同 “單兵種作戰”,在複雜的遙感圖像分類任務中存在侷限性。模型融合則是 “多兵種聯合作戰”,通過投票法、平均法、堆疊法等策略,整合多個模型的優勢。例如,將 SVM 的精準分類能力、隨機森林的抗噪能力和 CNN 的圖像特徵學習能力相結合,讓分類結果更加準確可靠。
參數調優是讓模型 “發揮最佳性能” 的關鍵。網格搜索法如同 “地毯式搜索”,在指定的參數範圍內,逐一嘗試不同參數組合,通過交叉驗證評估模型性能,找到最優解。以下是使用 Java 和 Smile 庫對隨機森林模型進行網格搜索調優的示例:
import smile.classification.RandomForest;
import smile.validation.GridSearch;
public class RandomForestGridSearch {
public static void main(String[] args) {
// 假設已有訓練數據特徵矩陣X和標籤向量y(實際需從遙感圖像數據提取)
double[][] X = {{1.0, 2.0}, {2.0, 3.0}, {3.0, 4.0}, {4.0, 5.0}};
int[] y = {0, 0, 1, 1};
// 定義待調優的參數範圍,numTrees表示隨機森林中樹的數量,maxDepth表示樹的最大深度
int[] numTrees = {10, 20, 30};
int[] maxDepth = {5, 10, 15};
// 創建網格搜索對象,定義模型構建函數、參數範圍和評估函數
GridSearch<int[]> search = new GridSearch<>(
(int[] params) -> new RandomForest(params[0], params[1]),
new int[][]{numTrees, maxDepth},
(model, XData, yData) -> model.error(XData, yData)
);
// 執行網格搜索,尋找最優參數組合
int[] bestParams = search.search(X, y);
System.out.println("Best parameters: numTrees = " + bestParams[0] + ", maxDepth = " + bestParams[1]);
}
}
遺傳算法則模仿生物進化過程,通過選擇、交叉、變異等操作,在參數空間中 “進化” 出最優參數組合,為模型優化提供了一種高效的智能搜索方法。
四、Java 大數據機器學習模型在遙感圖像分類中的應用案例
4.1 案例背景
在某省級自然資源監測項目中,需要對全省約 15 萬平方公里的土地利用類型進行年度更新分類。該區域涵蓋平原、山地、丘陵等多種地形,土地利用類型複雜多樣,包括 10 類主要地物(如永久耕地、有林地、灌木林地、城鎮住宅用地、農村宅基地、交通運輸用地、水域等)。傳統方法不僅耗時長達 8 個月,且分類精度不足 80%,難以滿足自然資源精細化管理需求。
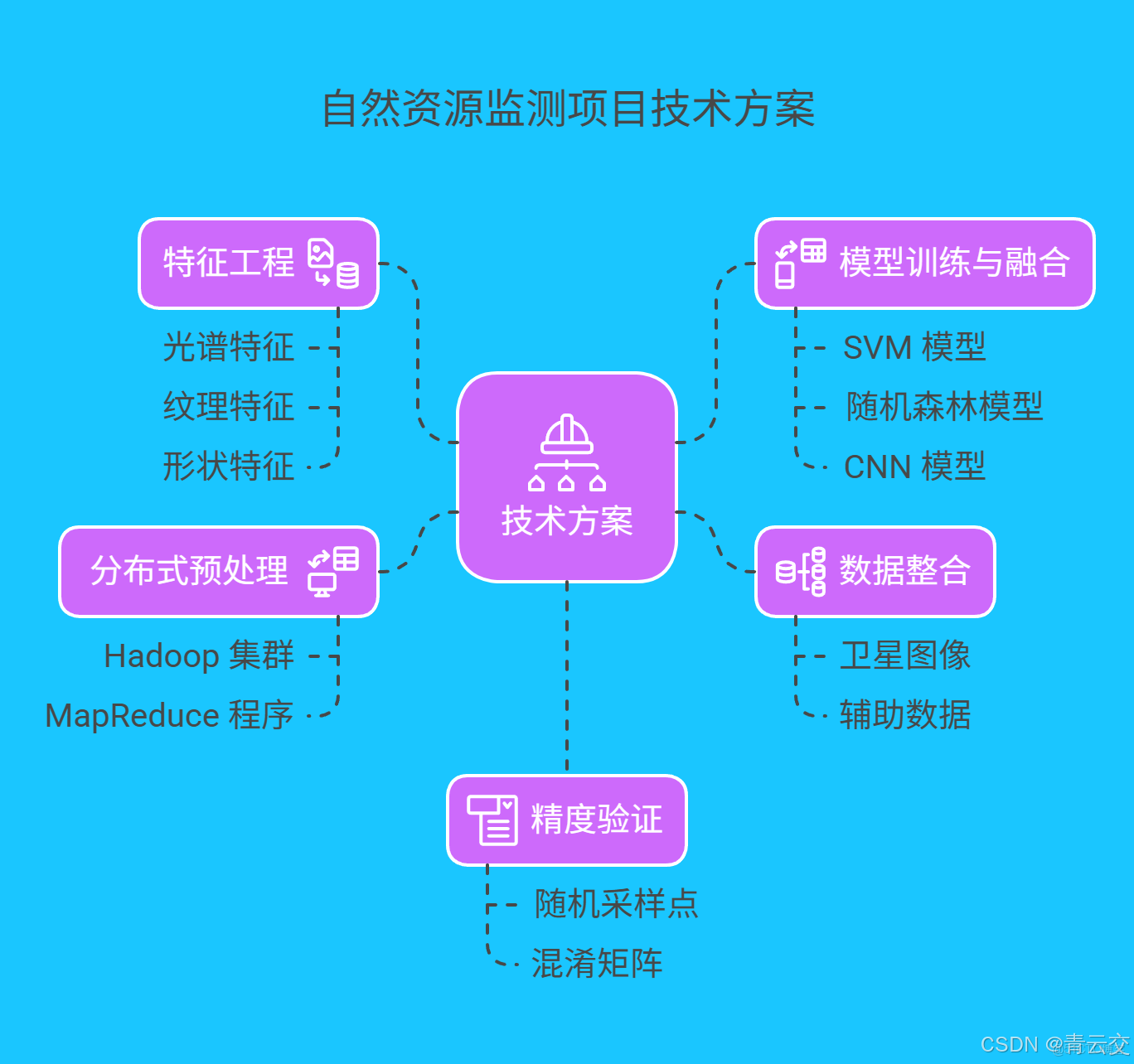
4.2 技術方案
- 數據整合:收集該省 3 顆不同衞星(高分二號、高分三號、哨兵二號)在 2023 年 6 - 8 月獲取的多光譜、高分辨率遙感圖像,數據總量達 8TB。同時,整合土地利用現狀變更調查數據、地理國情監測數據作為輔助參考。
- 分佈式預處理:基於 Hadoop 集羣(10 個節點),使用 Java 編寫 MapReduce 程序並行處理數據。完成輻射定標、大氣校正、幾何校正等操作,並對圖像進行分塊處理,每塊大小為 512×512 像素。
- 特徵工程:利用 Java 結合開源庫,提取豐富的圖像特徵。在光譜特徵方面,計算各波段的均值、標準差;紋理特徵提取採用灰度共生矩陣(GLCM)算法,通過 Java 代碼實現計算圖像的對比度、熵、相關性等紋理參數;形狀特徵則針對建設用地、水域等規則或不規則地物,計算面積、周長、緊湊度等指標。同時,將這些特徵進行標準化處理,確保不同特徵維度具有可比性。
- 模型訓練與融合:搭建基於 Spark 的分佈式計算環境,分別訓練支持向量機(SVM)、隨機森林(Random Forest)和卷積神經網絡(CNN)模型。SVM 模型使用徑向基核函數(RBF),通過網格搜索和交叉驗證優化懲罰參數 C 和核函數參數 gamma;隨機森林模型調整樹的數量、最大深度等參數;CNN 模型採用經典的 AlexNet 結構,在訓練過程中使用 Adam 優化器,學習率設置為 0.001 ,並採用早停法防止過擬合。最終,採用投票法融合三個模型的預測結果,每個模型權重相同。
- 精度驗證:從研究區域中選取 500 個隨機採樣點,通過實地調查獲取真實土地利用類型,與模型分類結果進行對比,計算混淆矩陣、總體精度、Kappa 係數等評價指標。
4.3 實施效果
經過兩個月的緊張開發與調試,基於 Java 大數據機器學習的土地利用分類系統成功部署運行。最終分類結果顯示,總體精度達到 92.3% ,Kappa 係數為 0.901 ,相較於傳統方法有了顯著提升。以下是混淆矩陣的詳細數據(單位:個):
| 真實類別 | 永久耕地 | 有林地 | 灌木林地 | 城鎮住宅用地 | 農村宅基地 | 交通運輸用地 | 水域 | 其他 | 預測正確數 |
|---|---|---|---|---|---|---|---|---|---|
| 永久耕地 | 485 | 8 | 3 | 2 | 1 | 1 | 485 | ||
| 有林地 | 5 | 478 | 12 | 3 | 1 | 1 | 478 | ||
| 灌木林地 | 3 | 10 | 480 | 2 | 1 | 1 | 2 | 480 | |
| 城鎮住宅用地 | 2 | 3 | 1 | 490 | 5 | 2 | 2 | 490 | |
| 農村宅基地 | 1 | 1 | 1 | 6 | 485 | 3 | 3 | 485 | |
| 交通運輸用地 | 1 | 1 | 2 | 3 | 488 | 1 | 3 | 488 | |
| 水域 | 1 | 1 | 495 | 1 | 495 | ||||
| 其他 | 2 | 2 | 3 | 3 | 1 | 489 | 489 | ||
| 預測總數 | 497 | 491 | 499 | 498 | 499 | 499 | 497 | 499 | - |
為了更直觀地展示分類效果,請看如下對比圖:
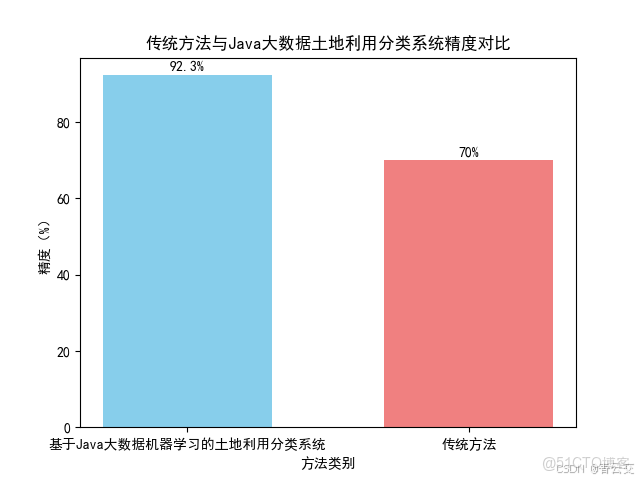
在效率方面,傳統方法處理 8TB 數據需要 8 個月,而本方案藉助 Hadoop 和 Spark 分佈式計算框架,僅用 72 小時就完成了數據處理、模型訓練和分類任務,效率提升了近 20 倍。
該項目成果在自然資源監測、土地規劃調整等工作中發揮了重要作用。例如,通過分類結果發現某山區存在非法開墾耕地現象,相關部門及時採取措施進行制止和恢復;在城市規劃中,準確的土地利用分類數據為新城區建設選址、交通路網規劃提供了科學依據。
結束語
親愛的 Java 和 大數據愛好者,從傳統分類方法的困境,到 Java 大數據機器學習模型的崛起,我們在遙感圖像土地利用分類領域完成了一次技術飛躍。在這個過程中,Java 憑藉其強大的開發能力,與大數據、機器學習深度融合,攻克了數據處理、模型優化等重重難關,為土地資源管理等領域提供了高效、精準的解決方案。
親愛的 Java 和 大數據愛好者,在遙感圖像分類實際應用中,你是否遇到過模型泛化能力差的問題?對於本文案例中的模型融合策略,你覺得還有哪些可以改進的方向?歡迎在評論區分享您的寶貴經驗與見解。
誠邀各位參與投票,在本次遙感圖像土地利用分類案例中,你認為哪個環節對最終成果影響最大?快來投出你的寶貴一票。
<span id = "csdntp">🗳️參與投票和聯繫我: </span>
<span id = "csdn">返回文章</span>








