

文章和代碼已經歸檔至【Github倉庫:https://github.com/timerring/dive-into-AI 】或者公眾號【AIShareLab】回覆 R語言 也可獲取。
用 R 基本包
在實際的數據分析中,分析者往往需要花費大量的精力在數據的準備上,將數據轉換為分析所需要的形式。遺憾的是,大多數統計學教材很少涉及這一重要問題。整理數據是統計學的任務之一。我們開始關注 R 中最常用的數據格式——數據框的基本操作。我們將首先使用基本包處理數據框。
先加載 epiDisplay 包裏的一個小型數據集 Familydata。
library(epiDisplay)
data("Familydata")1.查看數據框裏的內容
如果數據框較小,比如本例(只有 6 個變量,11 條記錄),只需輸入數據框名即可查看其全部內容,這等價於調用函數 print( ) 顯示對象的內容。
# 輸入數據框名即可查看其全部內容,這等價於調用函數 print( ) 顯示對象的內容。
Familydata
# 用函數 `head( )` 只顯示其前幾行
head(Familydata)
# 用函數 `tail( )` 顯示其最後幾行
tail(Familydata)
# 可以加參數指定到底幾行
tail(Familydata,7) # 顯示尾7行
# 列出所有變量名(列名)
names(Familydata)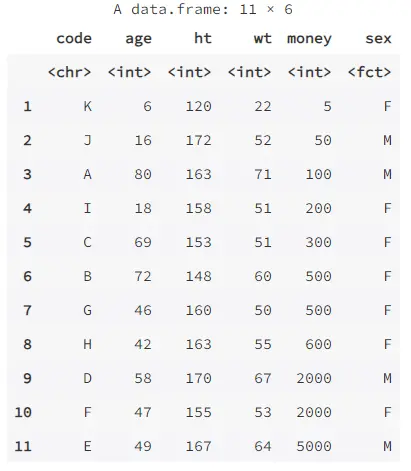
另一個可以用來方便地探索數據框結構的函數是 str( )。
str(Familydata)
# ==============顯示結果=============
# 首先給出了對象的類型(這裏是數據框“data.frame”)、觀測數和變量的個數;
'data.frame': 11 obs. of 6 variables:
# 接着給出了數據框中每個變量的變量名和類型,以及變量的前幾個取值
$ code : chr "K" "J" "A" "I" ...
$ age : int 6 16 80 18 69 72 46 42 58 47 ...
$ ht : int 120 172 163 158 153 148 160 163 170 155 ...
$ wt : int 22 52 71 51 51 60 50 55 67 53 ...
$ money: int 5 50 100 200 300 500 500 600 2000 2000 ...
# 對於因子型變量還給出了因子的水平;
$ sex : Factor w/ 2 levels "F","M": 1 2 2 1 1 1 1 1 2 1 ...
# 最後給出了數據框的一些屬性:
# 數據標籤(“datalabel”)
- attr(*, "datalabel")= chr "Anthropometric and financial data of a hypothetical family"
- # 數據建立時間(“time.stamp”)
- attr(*, "time.stamp")= chr "23 Nov 2006 17:15"
- attr(*, "formats")= chr [1:6] "%9s" "%8.0g" "%8.0g" "%8.0g" ...
- attr(*, "types")= int [1:6] 128 98 105 98 105 108
# 變量標籤(“var.labels”)
- attr(*, "val.labels")= chr [1:6] "" "" "" "" ...
- attr(*, "var.labels")= chr [1:6] "" "Age(yr)" "Ht(cm.)" "Wt(kg.)" ...
# 版本號(“version”)
- attr(*, "version")= int 7
- attr(*, "label.table")=List of 6
..$ sex1: Named num [1:2] 1 2
.. ..- attr(*, "names")= chr [1:2] "F" "M"
..$ : NULL
..$ : NULL
..$ : NULL
..$ : NULL
..$ : NULL這些屬性可以增強用户對數據集的理解。要想顯示數據框屬性的全部信息,可以使用 attributes( ) 函數,該函數的輸出是一個列表。
attributes(Familydata)
# ================== 輸出 ======================
$names
'code''age''ht''wt''money''sex'
$row.names
1234567891011
$class
'data.frame'
$datalabel
'Anthropometric and financial data of a hypothetical family'
$time.stamp
'23 Nov 2006 17:15'
$formats
'%9s''%8.0g''%8.0g''%8.0g''%8.0g''%8.0g'
$types
1289810598105108
$val.labels
'''''''''''sex1'
$var.labels
'''Age(yr)''Ht(cm.)''Wt(kg.)''Pocket money(B.)'''
$version
7
$label.table
$sex1
F1M2
[[2]]
NULL
[[3]]
NULL
[[4]]
NULL
[[5]]
NULL
[[6]]
NULL也可以修改和自定義這些屬性。例如,從上面的輸出可以看到,第一個變量和最後一個變量沒有定義標籤。現在為這兩個變量添加標籤:
attr(Familydata, "var.labels")[1] <- "Identification number"
attr(Familydata, "var.labels")[6] <- "Gender"
attributes(Familydata)$var.labels
# 'Identification number''Age(yr)''Ht(cm.)''Wt(kg.)''Pocket money(B.)''Gender'給變量添加標籤能幫助我們更好地理解變量的含義。此外,後面用到的 epiDisplay 包裏有些函數的輸出還能直接使用這些變量標籤。
2.選取數據框的子集
與矩陣類似,我們可以用索引下標的方式選取數據框的子集。
# 選擇數據框 Familydata 的第 3 列
Familydata[, 3]
# 也可以使用$變量名的方式
Familydata$ht
# 要提取一個以上的變量,可以使用變量的索引號或名字。例如,只顯示變量ht、wt 和 sex 的前 3 條記錄,可以輸入:
Familydata[1:3, c(3, 4, 6)]
# 等價於
Familydata[1:3, c("ht", "wt", "sex")]下標中的索引還可以是一個條件語句。例如,要選擇性別為女性的數據,可以輸入:
Familydata[Familydata$sex == "F", ] # 注意逗號跟雙等號另一種選擇數據框的子集的方法是使用 subset( ) 函數。
subset(Familydata, sex == "F")
# 若只選擇女性中的變量 ht 和 wt
subset(Familydata, sex == "F", select = c(ht, wt))注意,該命令只是選擇一個子集來顯示,不會對原來的數據框產生任何影響。如果還要進一步使用該子集,需要把它存為一個新的對象。
在機器學習領域,經常需要從數據集裏隨機抽取一部分樣本。例如,我們想把一個大的數據集隨機分成兩份,其中一份用於構建預測模型,另一份用於驗證模型的預測精度。函數 sample( ) 可用於隨機抽樣,下面的命令從數據框 Familydata 裏隨機抽取一個大小為 3 的樣本:
sample.rows <- sample(1:nrow(Familydata), size = 3, replace = FALSE)
sample.rows
# 5 4 1函數 sample( ) 中的第一個參數是一個由要從中抽樣的元素組成的向量,在這裏是從 1 到數據框中的總觀測數;第二個參數 size 是要抽取的元素的數量;第三個參數 replace 用於設定是否放回抽樣,默認為 FALSE(不放回抽樣)。
函數 sample( ) 的返回值可用於選擇數據框中的行。由於隨機種子數的不同,每次運行得到的結果很可能不一樣。
3.將數據框按照某個變量的值排序:order( )
有時我們想將數據框按照某個變量的值的大小進行排序顯示,這可以藉助函數 order( ) 實現。例如,將數據框 Familydata 以變量 age 的值從小到大顯示,可以使用下面的命令:
# ,前表示條件 ,後表示顯示的列
Familydata[order(Familydata$age), ] # 默認升序
# 降序寫法
Familydata[order(Familydata$age, decreasing = TRUE), ]
# 等價於age取反結果
Familydata[order(-Familydata$age), ]4.查找和刪除重複數據:duplicated( )
原始數據集裏經常會有重複的行。如果不是重複測量的數據,數據集的每一行應該是某一個對象的觀測,而且數據集裏通常有一個用於識別個體的變量(比如 id)。
數據集 Familydata 中的變量 code 就是個體識別號,下面檢查該變量有無重複值:
duplicated(Familydata$code)
# FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
# 函數 duplicated( ) 的返回值是邏輯值 TRUE 或 FALSE,這裏全為 FASLE,表明變量 code 沒有重複值。如果數據框的行數較多,逐一查看這些邏輯值會很麻煩。此時,可以將函數 any( ) 作用於函數 duplicated( ) 的輸出結果:
any(duplicated(Familydata$code))
# FALSE或者使用函數 table( ),還能得到重複值的個數:
table(duplicated(Familydata$code))
# FALSE
# 11刪除重複行
為了闡明怎樣刪除重複的行,下面建立一個數據框 Familydata1,將原數據框 Familydata 的第 2 行添加在其第 12 行:
Familydata1 <- Familydata
Familydata1[12, ] <- Familydata[2, ]
Familydata1使用函數 which( ) 可以找出變量 code 的重複值所在的行:
which(duplicated(Familydata1$code))然後,刪除重複的行:
# 將不重複的新建對象即可
unique.code.data <- Familydata1[!duplicated(Familydata1$code), ]
unique.code.dataidentical 查看對象是否完全一樣
# 用identical查看兩個對象是否完全一樣
identical(unique.code.data, Familydata)
# TRUE5.在數據框中添加和刪除變量
在處理數據框時,我們經常需要創建新的變量並把它添加到現有的數據框中。例如,建立一個新的變量 log10money,其值等於變量 money 以 10 為底的對數。最直接地,可以輸入:
Familydata$log10money <- log10(Familydata$money)
# 或者可以使用 `transform( )` 函數:
Familydata <- transform(Familydata, log10money = log10(money))
names(Familydata)
# 'code''age''ht''wt''money''sex''log10money'與添加變量相反,如果想從數據框中刪除一個變量,只需在方括號內下標號的前面添加一個減號。例如:
Familydata[, -7]請注意,該命令只顯示所需的子集,對數據框本身不會產生影響。
但是賦一個空值(NULL)給數據框中的變量等同於刪除該變量,並且是會永久刪除數據框中的變量:
Familydata$log10money <- NULL
colnames(Familydata)6.把數據框添加到搜索路徑
在前面查看和使用數據框中的變量時,我們需要在變量名前面加上數據框名和符號 $。這種方式有時候會顯得比較煩瑣,尤其是數據框和變量的名字都很長的時候。此時,函數 attach( ) 或者函數 with( ) 可以用來簡化代碼。
函數 attach( ) 可以將數據框添加到搜索路徑中。輸入以下命令:
attach(Familydata)然後用函數 search( ) 查看搜索路徑中的所有對象:
search()
#'.GlobalEnv''Familydata''package:epiDisplay''package:nnet''package:MASS''package:survival''package:foreign''package:repr''jupyter:irkernel''package:stats''package:graphics''package:grDevices''package:utils''package:datasets''package:methods''Autoloads''package:base'現在搜索路徑中的第二個位置存放了數據框 Familydata。由於數據框已經在搜索路徑中了,而變量 age 又在該數據框裏,所以現在可以直接使用變量 age 了。
summary(age)
# Min. 1st Qu. Median Mean 3rd Qu. Max.
# 6.00 30.00 47.00 45.73 63.50 80.00 把一個數據框放入搜索路徑類似於使用函數 library( ) 加載一個包。調入搜索路徑的數據框和加載的包都會被自動讀入 R,並一直存放在內存中直至它們被移出(detach( ))。
使用函數
attach( )雖然會在輸入代碼時帶來一些便利,但同時也會帶來一些問題。例如,重複加載數據框可能會最終導致系統資源過度負荷。另外,如果全局環境中或多個數據框中有相同的變量名,容易使用户產生混淆。因此,有些 R 的使用者儘量避免使用函數 attach( ),而使用函數with( )。以
datasets包裏的數據集infert為例:
with(infert, summary(age))
# Min. 1st Qu. Median Mean 3rd Qu. Max.
# 21.00 28.00 31.00 31.50 35.25 44.00 函數 with( ) 的侷限性在於,對於多次使用數據框,我們必須重複使用函數 with( )。此外,賦值僅在此函數內部生效,例如:
with(infert, {
m <- mean(age)}
)
m
# ERROR:object 'm' not found選擇哪一種數據處理方式取決於分析者的偏好。例如《R 語言醫學數據分析實戰》推薦的做法是:
- 在開啓一個新的分析項目時,首先使用命令
rm(list = ls( )) 從 R 工作環境中清除所有對象; - 在分析過程中用函數
detach( )將不再需要使用的數據框從搜索路徑中移出; - 不要定義與已經存在於搜索路徑中的數據框同名的新對象;