
下面分別從這四個方面來帶大家學習數據分析:
第一,做數據分析要精通Python嗎?
第二,數據分析流程是什麼?學什麼?
第三,如何培養數據分析思維?
第四,數據分析書籍推薦
一、數據分析要精通Python嗎?
做數據分析不必精通Python,但至少要掌握Python基礎內容。第一步是要了解一些Python的編程基礎,知道Python的數據結構,什麼是向量、列表、數組、字典等等;瞭解Python的各種函數及模塊。

二、數據分析流程是什麼?學什麼?
一個完整的數據分析項目,大概可以分為這五個流程:數據獲取——數據存儲——數據清洗——數據分析——可視化分析,具體每部分都要掌握什麼,下面給大家説清楚。
數據獲取
數據獲取是數據分析的第一步,關於一些內部數據大家可以找公司內部的人去要,其他外部數據如市場調研、競品分析這些報告,大家可以在這些網站獲取:
數據存儲
企業常用的存儲數據的數據庫有哪些?不同數據庫的存儲區別又有哪些?下面跟我一起來了解常見數據庫:
Access數據庫:是一個關係型數據庫管理系統;本地桌面型數據庫,存儲的數據量較少,是小型的數據庫;查詢語句為SQL。
MYSQL數據庫:是一個關係型數據庫管理系統;是開源的,總體擁有成本低;支持多種操作系統;
SQL Server 數據庫:是一個關係型數據庫管理系統;是非開源的;中型的數據庫;
Oracle數據庫:是一個關係型數據庫管理系統;不是開源的;支持多種操作系統;
Hive 數據庫:是非關係型數據庫管理系統;數據規模大;主要進行離線的大數據分析;查詢語句為HQL;
以上就是幾種常見的數據庫及介紹,方便大家在做數據分析的時候提取數據。
數據清洗
數據清洗是利用相關技術將“髒”數據轉換為滿足質量要求的數據。下面通過一張圖描述數據清洗的原理。
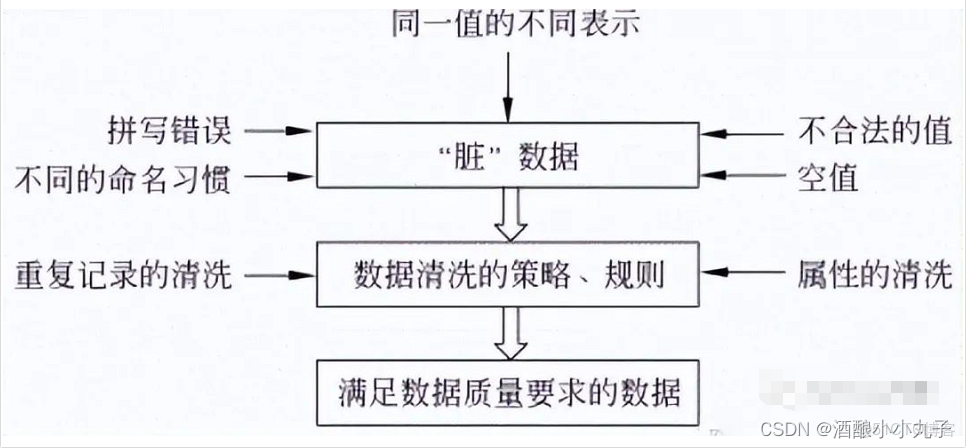
從圖中可以看出,同一值的不同表示、拼寫錯誤、不同的命名習慣、不合法的值以及空值都會導致“髒”數據出現,通過定義好的數據清洗策略和清洗規則(即數理統計技術、數據挖掘技術等清洗策略)對“髒”數據進行清洗,得到滿足數據質量要求的數據。
需要注意的是,數據清洗的目的是解決“髒”數據問題,即不是將“髒”數據洗掉,而是將“髒”數據洗乾淨。乾淨的數據指的是滿足質量要求的數據。
數據分析與可視化分析
Python中常會用到一些專門的庫,如NumPy、SciPy、Pandas和Matplotlib。數據處理常用到NumPy、SciPy和Pandas,數據分析常用到Pandas和Scikit-Learn,數據可視化常用到Matplotlib,而對大規模數據進行分佈式挖掘時則可以使用Pyspark來調用Spark集羣的資源。
NumPy官方文檔:https://numpy.org/
SciPy官方文檔:https://scipy.org/
Pandas官方文檔:pandas documentation
Matplotlib官方文檔:Matplotlib - Visualization with Python
Scikit-learn官方文檔:scikit-learn: machine learning in Python
Keras官方文檔:the Python deep learning API
三、如何培養數據分析思維?
數據分析屬於分析思維的一個子類,有專門的數據方法論,只有養成正確的分析思維才能做好數據分析。什麼是好的分析思維,網上有張圖是這樣的:
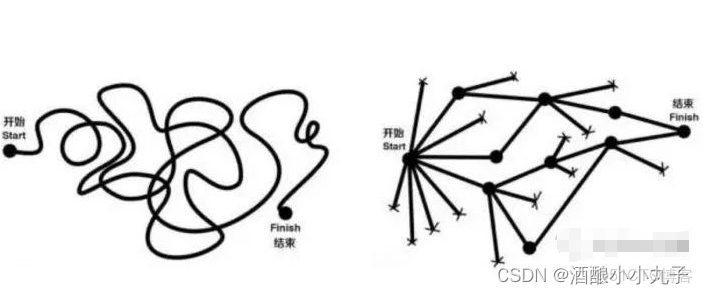
第一個分析思維是依賴經驗和直覺的線性思維,第二個分析思維則注重邏輯推導,屬於結構化的思維。這兩種思維也往往會導致不同的結果。
除了Excel、Tableau、SQL、Python 等工具技能的學習,另一個關鍵點則是數據分析思維的培養。大家在做數據分析之前需要構建分析框架、理清思路、學會運用常見的分析方法等結合具體業務進行分析。
這需要我們去做案例+看書來不斷積累經驗,形成自己的數據分析思維。








