
💡 本文價值提示: 歡迎回到我們的 “大數據工程師轉型 AI 架構師” 系列專題! 在搞定了 Python 高級工程化 和 大模型基礎理論 之後,今天我們正式開啓第三個重磅專題——RAG 架構與數據工程之向量數據庫。
對於大數據老兵來説,數據庫是我們的“後花園”。但 AI 時代的數據庫(Vector DB)徹底顛覆了我們熟悉的 SQL 邏輯。本文將帶你從底層思維上完成從“精確匹配”到“語義模糊匹配”的跨越,並用最輕量級的代碼跑通你的第一個 RAG 閉環。這不僅是技術的升級,更是架構認知的重構。
01 引言:當 SQL 遇到“靈魂拷問” 🤯
作為一名在大數據領域摸爬滾打多年的工程師,你一定對這樣的 SQL 語句爛熟於心:
SELECT * FROM products WHERE category = 'electronics' AND price < 5000;
這是一種精確匹配(Exact Match)。數據庫像一個一絲不苟的圖書管理員,你給它一個 ISBN 號,它給你一本書。如果 ISBN 錯了一位,它就冷冰冰地告訴你:0 rows returned。
但在 AI 的世界裏,用户的問題往往是模糊的、充滿“靈魂”的。比如用户問:
“有沒有那種適合打遊戲、散熱好,而且不太貴的手機?”
如果你試圖用 SQL 的 LIKE 語句去匹配“散熱好”、“不太貴”,那你大概率會瘋掉。因為數據庫裏存的是“驍龍8 Gen 2”、“VC液冷”、“4999元”,根本沒有“不太貴”這個字段。
這時候,向量數據庫(Vector Database) 就登場了。它不再比較“字面是否一樣”,而是比較“意思是否相近”。
今天,我們就來揭開這個 AI 時代“新基建”的神秘面紗,完成從大數據工程師到 AI 數據架構師的第一步蜕變。
02 核心思維轉變:從 KV 到 Embedding 🧠
要理解向量數據庫,首先要理解它的原子單位——**Embedding(嵌入)**。
什麼是 Embedding?
想象一下,我們把世界上所有的詞語都扔進一個巨大的、多維的座標系裏。
- “蘋果” 和 “香蕉” 都是水果,它們在座標系裏的距離應該很近。
- “蘋果” 和 “iPhone” 雖然字一樣,但在語義空間裏,一個在“食物區”,一個在“電子產品區”,距離應該很遠。
Embedding 就是把文本變成一串數字(向量),這串數字代表了它在這個高維空間裏的座標。
🧪 大數據視角映射: 以前做用户畫像(User Profile)時,我們會給用户打標籤:
[男, 25-30歲, 喜歡運動]。這其實就是一種低維的、稀疏的向量。 而現在的 Embedding(如 OpenAI 的text-embedding-3-small),是一個 1536 維 的稠密向量。它捕捉的特徵比我們手動打的標籤要豐富億萬倍。
核心差異對比表
| 特性 | 傳統數據庫 (MySQL/HBase) | 向量數據庫 (Milvus/Chroma) |
|---|---|---|
| 查詢邏輯 | 精確匹配 (=, LIKE) |
相似度匹配 (Approximate Nearest Neighbor) |
| 核心操作 | CRUD | Insert & Search (TopK) |
| 數據形態 | 結構化 (Row/Column) | 非結構化 (Vector + Metadata) |
| 結果 | 確定性結果 | 概率性結果 (Score) |
03 距離度量:向量世界的“尺子” 📏
既然數據變成了空間裏的點,那怎麼判斷兩個點“像不像”呢?我們需要一把尺子。在大數據聚類算法(如 K-Means)中,你可能已經見過它們:
1. 歐氏距離 (L2 - Euclidean Distance)
- 原理:兩點之間直線最短。
- 直覺:空間距離越近,越相似。
- 場景:對向量的大小和方向都敏感的場景。
2. 餘弦相似度 (Cosine Similarity) 🌟 (最常用)
- 原理:看兩個向量的夾角。
- 直覺:不管你跑得遠不遠(向量模長),只要我們方向一致,就是“同道中人”。
- 場景:文本語義檢索。因為文本長短不一可能導致模長不同,但核心語義(方向)是一致的。
3. 內積 (IP - Inner Product)
- 原理:向量對應位相乘再求和。
- 場景:通常用於歸一化(Normalized)後的向量,此時 IP 等價於 Cosine,但計算更快。
04 極速上手:你的第一個 RAG 閉環 (MVP) 🛠️
光説不練假把式。作為工程師,我們直接上代碼。 我們將使用 Chroma —— 向量數據庫界的 SQLite。它輕量、無需安裝服務器,直接作為 Python 庫運行,非常適合 MVP(最小可行性產品)驗證。
場景設定
我們要存入三句話,然後問一個問題,看它能不能找到最相關的那句。
1. 環境準備
pip install chromadb
2. 代碼實戰 (Python)
import chromadb
# 1. 初始化一個本地的向量數據庫客户端(內存模式,重啓數據丟失,適合測試)
client = chromadb.Client()
# 2. 創建一個集合 (Collection),類似於 SQL 中的 Table
# 這裏我們使用默認的 Embedding 模型 (all-MiniLM-L6-v2),它會自動下載
collection = client.create_collection(name="my_knowledge_base")
# 3. 準備數據 (Documents) 和 元數據 (Metadata)
documents = [
"Hadoop 是一個分佈式系統基礎架構,主要解決海量數據的存儲和分析計算問題。",
"Spark 是一種基於內存的快速、通用、可擴展的大數據分析計算引擎。",
"向量數據庫是專門用於存儲和查詢高維向量數據的數據庫,是 LLM 的記憶體。"
]
metadatas = [{"type": "bigdata"}, {"type": "bigdata"}, {"type": "ai"}]
ids = ["doc1", "doc2", "doc3"]
# 4. 寫入數據 (Upsert)
# Chroma 會自動調用內置模型,將 text 轉為 vector,然後存儲
print("🔄 正在將文本轉化為向量並存入 Chroma...")
collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)
# 5. 語義查詢 (Retrieve)
query_text = "怎麼讓大模型擁有記憶?"
print(f"🔍 用户提問: {query_text}")
results = collection.query(
query_texts=[query_text],
n_results=1 # TopK = 1
)
# 6. 輸出結果
print("\n✅ 檢索結果:")
print(f"匹配文檔: {results['documents'][0][0]}")
print(f"距離/相似度: {results['distances'][0][0]}")
運行結果解析
當你運行這段代碼,雖然你的問題裏沒有“向量數據庫”這五個字,但系統會精準地返回 doc3。 這就是 語義匹配 的魅力!它聽懂了“大模型記憶”和“向量數據庫”之間的潛在聯繫。
05 架構師視角:RAG 的標準數據流水線 🏗️
跑通了 Demo 只是第一步。作為未來的 AI 架構師,你需要關注的是整個數據流的流轉。 一個標準的 RAG (Retrieval-Augmented Generation) 數據工程鏈路如下:
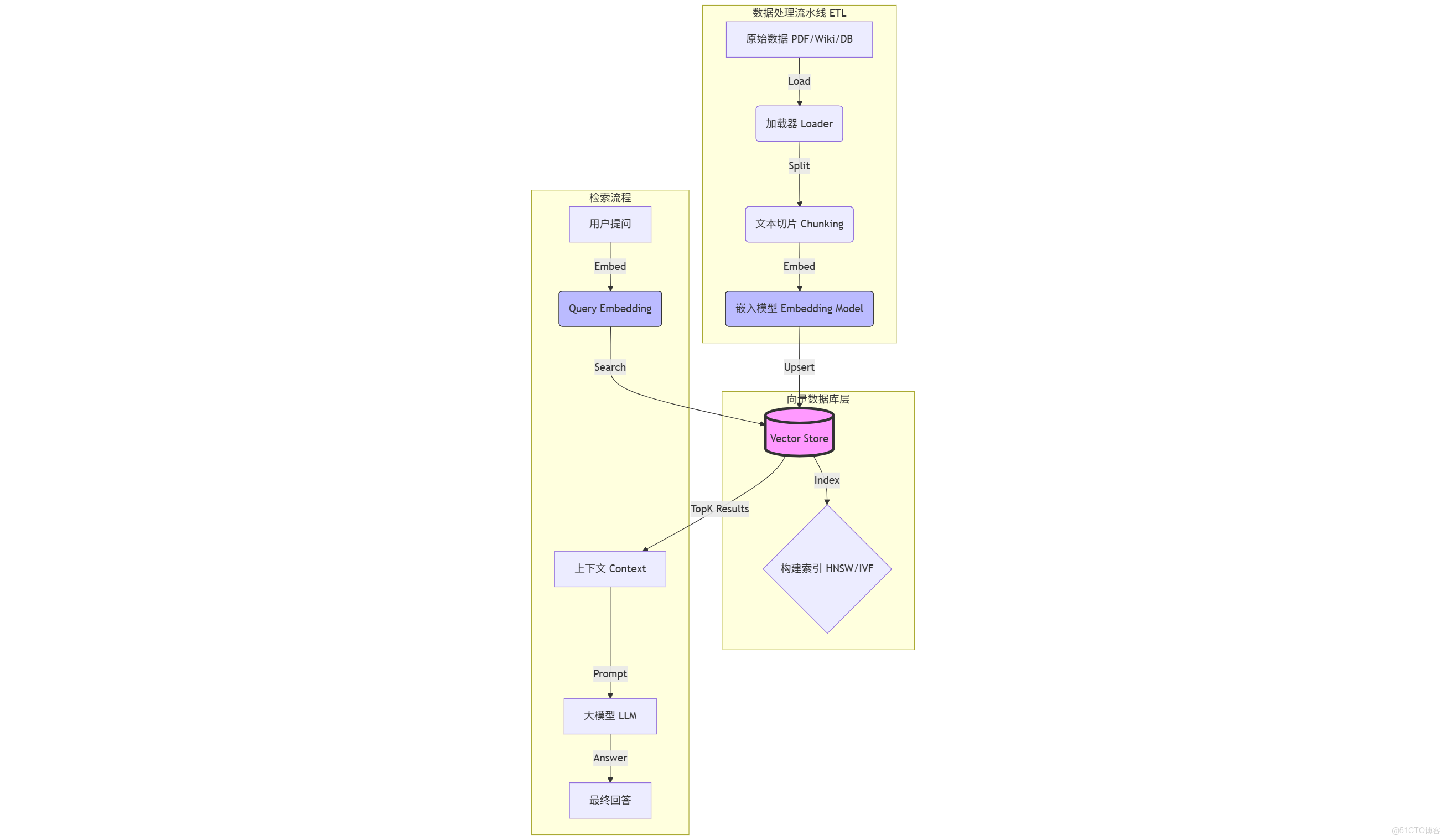
關鍵環節解析:
- Load (加載):從 HDFS、S3 或本地讀取非結構化數據。
- Split (切片):這是最考驗功力的地方。切太長,語義雜糅;切太短,語義破碎。通常使用
RecursiveCharacterTextSplitter。 - Embed (向量化):調用 OpenAI 或 HuggingFace 的模型,將 Chunk 變成 Vector。這是最耗時且產生費用的環節。
- Store (存儲):將 Vector + Metadata + Original Text 存入向量庫。
- Retrieve (檢索):計算 Query Vector 與 Library Vectors 的距離,返回 TopK。
06 總結與預告 📝
今天我們完成了從大數據工程師到 AI 工程師的第一次“腦機接口”升級。我們不再糾結於 WHERE id=1,而是開始思考數據在多維空間中的位置。
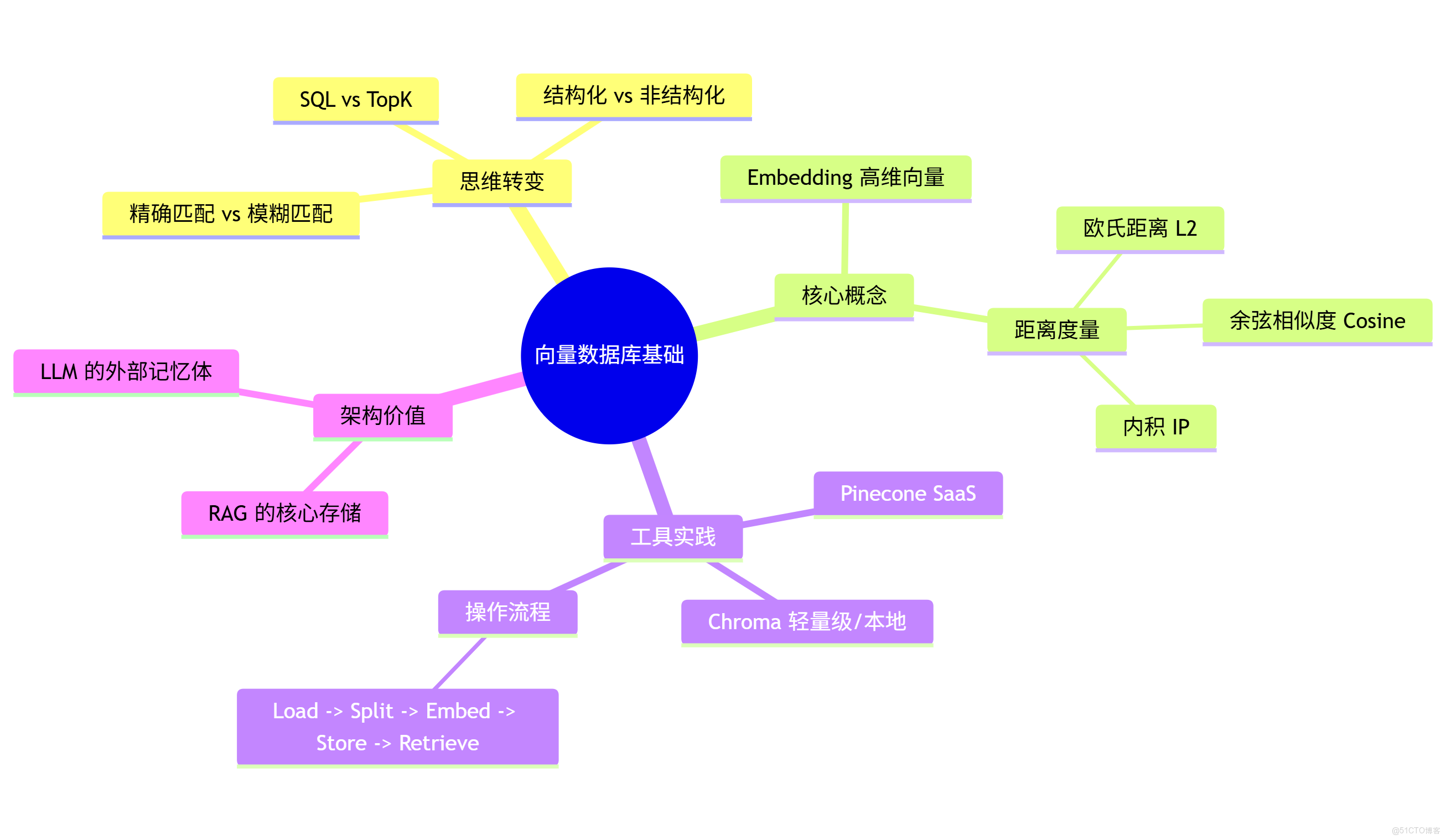
核心知識點回顧:
- Embedding 是數據的靈魂座標。
- Cosine Similarity 是尋找同類的指南針。
- Chroma 是我們手中的瑞士軍刀。
- RAG Pipeline 是我們將非結構化數據轉化為 AI 知識的標準工廠。
為了讓你更直觀地複習,我為你準備了本篇的思維導圖:
📢 下期預告:核心戰場——分佈式向量數據庫
用 Chroma 跑 Demo 很爽,但如果數據量到了 10 億級 怎麼辦?內存爆了怎麼辦?寫入太慢怎麼辦? 這正是我們大數據工程師的主場!
下一期,我們將深入 Phase 2,硬核拆解 Milvus 的分佈式架構。你會發現,它簡直就是向量版的 Kafka + HDFS!我們將探討 Proxy、DataCoord、QueryNode 等組件是如何協同工作的。
💬 互動話題: 你在運行上面的 Python 代碼時,有沒有遇到 OpenAI API 連接的問題?或者你覺得“文本切片”應該按什麼規則切才最合理?歡迎在評論區留言,我們一起探討!
(別忘了關注,不錯過下一篇硬核乾貨!)