
💎 本文價值提示
你將獲得什麼?
- 從零構建:不再是寫腳本,而是構建一個可擴展的微服務架構。
- 企業級思維:掌握限流、熔斷、流式傳輸等生產環境必備技能。
- 代碼即資產:一套可直接複用的 LLM Gateway 核心代碼骨架。
- 轉型視角:看懂大數據高吞吐思維如何映射到 AI 高併發架構。
👋 大家好,我是你們的老朋友,那個正在從大數據轉型 AI 架構的“老司機”。
在前三篇文章中,我們已經完成了 Python 的“脱胎換骨”:
- 第一篇:我們用 Type Hints 和 Pydantic 戒掉了“弱類型”的隨意,像寫 Java 一樣嚴謹;
- 第二篇:我們用 Asyncio 征服了高併發 I/O,不再讓 CPU 傻等;
- 第三篇:我們用 Generator 和 Decorator 搞定了流式輸出和 AOP 切面編程。
今天,是時候把這些散落的珍珠串成項鍊了!我們將進入 Phase 4:工程化落地與架構設計。
我們要一起做一個 Capstone Project(畢業設計) —— **企業級 LLM Gateway(大模型網關)**。
🏗️ 為什麼要造一個 LLM Gateway?
在企業裏,直接讓業務代碼調用 OpenAI 或 DeepSeek 的 API 是非常危險的。這就好比讓公司的每輛車都自己去海關報關,效率低且無法管控。
我們需要一個 “海關總署” (Gateway) :
- 統一計費:誰用了多少 Token,得算清楚。
- 流量控制:防止某個業務線把 API Rate Limit 刷爆。
- 協議轉換:前端要 SSE 流式,後端要統一接口。
- 安全審計:敏感詞過濾,防止數據泄露。
技術棧選型:
- 框架:
FastAPI(Python 界的最強黑馬,性能直逼 Go)。 - 校驗:
Pydantic V2(數據契約的守護神)。 - 併發:
Asyncio(高併發的核心引擎)。
🧩 架構藍圖:數據是如何流動的?
在我們開始寫代碼之前,先像設計 Flink 拓撲圖一樣,畫出我們的架構流向。
🛠️ 第一步:立規矩 —— 定義數據契約 (Pydantic)
做大數據出身的我們,最怕數據格式亂七八糟。在 AI 架構中,Prompt 就是 SQL,Schema 就是 Table Schema。
我們需要定義“輸入”和“輸出”的嚴格標準。
from pydantic import BaseModel, Field, field_validator
from typing import List, Optional, Literal
# 1. 定義消息體
class Message(BaseModel):
role: Literal["system", "user", "assistant"]
content: str
# 2. 定義請求契約 (Request Contract)
class ChatCompletionRequest(BaseModel):
model: str = Field(..., description="模型名稱,如 gpt-4, deepseek-chat")
messages: List[Message]
temperature: float = Field(0.7, ge=0.0, le=2.0)
stream: bool = False
# 💡 亮點:自定義校驗,防止惡意注入過長文本
@field_validator('messages')
def validate_message_length(cls, v):
total_len = sum(len(m.content) for m in v)
if total_len > 10000:
raise ValueError("Prompt 內容過長,請精簡後重試")
return v
# 3. 定義響應契約 (Response Contract)
# 這裏我們模擬 OpenAI 的標準返回格式
class ChatCompletionResponse(BaseModel):
id: str
object: str = "chat.completion"
created: int
choices: List[dict]
👨💻 架構師旁白: 這不僅僅是代碼,這是協議。有了它,前端開發和後端開發就有了“法律依據”,不再需要口頭對齊字段。
🚀 第二步:高併發引擎 —— 異步請求 (Asyncio)
LLM 的響應通常很慢(幾秒到幾十秒)。如果用傳統的同步代碼(像 JDBC 那樣),一個請求卡住,整個服務就掛了。
我們要用 Asyncio + httpx,實現非阻塞調用。這就像 Node.js 的事件循環,或者 Netty 的 IO 線程。
import httpx
import os
from fastapi import HTTPException
# 模擬從環境變量獲取 Key
LLM_API_KEY = os.getenv("LLM_API_KEY")
LLM_BASE_URL = "https://api.deepseek.com/v1"
async def call_llm_api(request: ChatCompletionRequest):
"""
異步調用上游大模型接口
"""
headers = {
"Authorization": f"Bearer {LLM_API_KEY}",
"Content-Type": "application/json"
}
# 💡 亮點:使用異步上下文管理器,自動釋放連接
async with httpx.AsyncClient(timeout=60.0) as client:
try:
response = await client.post(
f"{LLM_BASE_URL}/chat/completions",
json=request.model_dump(), # Pydantic V2 序列化
headers=headers
)
response.raise_for_status()
return response.json()
except httpx.HTTPStatusError as e:
# 記錄日誌...
raise HTTPException(status_code=e.response.status_code, detail="上游服務報錯")
🌊 第三步:極致體驗 —— 流式透傳 (Generator)
用户不想盯着空白屏幕等 10 秒。他們想要 ChatGPT 那種“打字機”效果。 這就需要用到 Python 的 Generator (生成器) ,配合 FastAPI 的 StreamingResponse。
這在大數據領域,就是 Spark Streaming 或 Flink DataStream —— 數據來一條,處理一條,發走一條。
import json
from typing import AsyncGenerator
async def stream_llm_api(request: ChatCompletionRequest) -> AsyncGenerator[str, None]:
"""
流式生成器:像水管一樣接通上游和下游
"""
headers = {
"Authorization": f"Bearer {LLM_API_KEY}",
"Content-Type": "application/json"
}
async with httpx.AsyncClient() as client:
# 開啓流式請求
async with client.stream(
"POST",
f"{LLM_BASE_URL}/chat/completions",
json=request.model_dump(),
headers=headers
) as response:
# 💡 亮點:逐行讀取上游數據,並實時 yield 給前端
async for line in response.aiter_lines():
if line:
# 這裏可以做數據清洗、計費統計等中間處理
yield f"{line}\n\n" # 符合 SSE 格式
🛡️ 第四步:穩定性保障 —— 熔斷器 (Decorator)
如果上游 DeepSeek 掛了,或者網絡抖動,我們不能讓請求堆積把自己的網關壓垮。我們需要一個 熔斷器 (Circuit Breaker) 。
利用 Python 的 Decorator (裝飾器) ,我們可以優雅地實現 AOP(面向切面編程)。
import time
from functools import wraps
# 簡單的熔斷器狀態
CIRCUIT_OPEN = False
ERROR_COUNT = 0
LAST_ERROR_TIME = 0
def circuit_breaker(threshold=5, recovery_time=60):
"""
裝飾器:當錯誤次數超過 threshold 時,暫停服務 recovery_time 秒
"""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
global CIRCUIT_OPEN, ERROR_COUNT, LAST_ERROR_TIME
# 1. 檢查是否熔斷
if CIRCUIT_OPEN:
if time.time() - LAST_ERROR_TIME > recovery_time:
# 嘗試恢復
CIRCUIT_OPEN = False
ERROR_COUNT = 0
else:
raise HTTPException(status_code=503, detail="服務熔斷中,請稍後重試")
# 2. 嘗試執行
try:
return await func(*args, **kwargs)
except Exception as e:
ERROR_COUNT += 1
LAST_ERROR_TIME = time.time()
if ERROR_COUNT >= threshold:
CIRCUIT_OPEN = True
print("⚠️ 觸發熔斷保護!")
raise e
return wrapper
return decorator
🏰 第五步:集大成 —— FastAPI 入口
最後,我們將所有組件組裝到 main.py 中。
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI(title="Enterprise LLM Gateway")
@app.post("/v1/chat/completions")
@circuit_breaker() # 掛載熔斷器
async def chat_completions(request: ChatCompletionRequest):
"""
網關核心接口
"""
# 1. 打印日誌 (實際項目中應使用 logging 模塊)
print(f"收到請求: {request.model} - {len(request.messages)} msgs")
# 2. 判斷是否流式
if request.stream:
# 返回流式響應 (SSE)
return StreamingResponse(
stream_llm_api(request),
media_type="text/event-stream"
)
else:
# 返回普通 JSON
return await call_llm_api(request)
# 啓動命令: uvicorn main:app --reload
📝 總結與回顧
恭喜你!你已經從一個寫 ETL 腳本的大數據工程師,成功蜕變為能手寫 高併發微服務 的 AI 架構師。
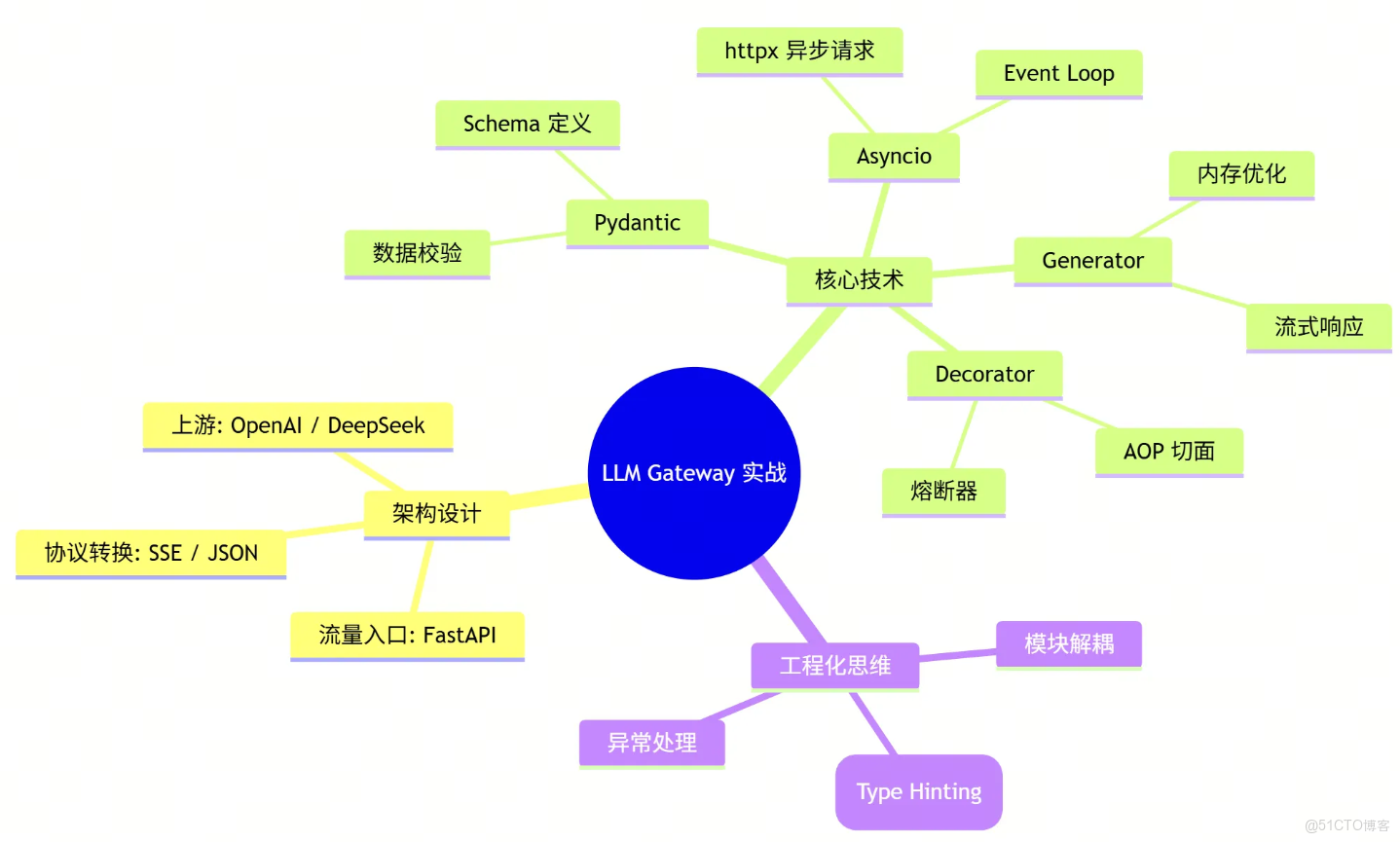
讓我們回顧一下這個 LLM Gateway 涉及的核心能力:
- Pydantic: 你的“數據安檢員”,確保進來的數據都是合規的。
- Asyncio: 你的“交通指揮官”,讓單線程也能處理成千上萬的併發請求。
- Generator: 你的“流水線”,實現數據的實時流轉,降低內存壓力。
- Decorator: 你的“保鏢”,在不侵入業務邏輯的情況下,提供熔斷和重試保護。
🧠 本文思維導圖
🗣️ 互動話題
你在轉型 AI 開發的過程中,遇到的最大“坑”是什麼?
- A. 習慣了 Java 的強類型,受不了 Python 的動態類型?
- B. 搞不懂
async/await,代碼經常卡死? - C. 流式輸出 (Streaming) 總是斷斷續續?
- D. 依賴管理太亂,
pip和conda打架?
👇 在評論區告訴我你的答案,或者輸入關鍵詞【網關源碼】,獲取本文完整的項目代碼包!