
本文價值提示: 很多轉型AI的大數據工程師,會調用 API,會寫 Prompt,但一旦遇到“為什麼這個任務跑得這麼慢?”或者“為什麼提取實體總是出錯?”時就懵了。 本文不講複雜的數學公式,而是用架構師的視角,帶你鑽進大模型的“黑盒”內部,看懂 Transformer 的三種形態,並附贈一份**2025年主流模型選型清單(含國產之光)**。
👋 大家好,我是你們的老朋友。
在上一期的《AI 計費的秘密:為什麼你的 Prompt 越寫越貴?》中,我們搞懂了模型是如何“吃”數據的。很多同學在後台留言:“數據吃進去了,然後在裏面到底發生了什麼?市面上模型幾百個,LLaMA、Qwen、BERT 到底該選誰?”
今天,我們就進入大模型基礎理論專題的第二站:核心引擎——Transformer 架構。
如果説 Python 工程化是你手中的“瑞士軍刀”,那麼 Transformer 架構原理就是你心中的“內功心法”。作為未來的 AI 架構師,你不需要推導反向傳播公式,但你必須知道:這台引擎的三個檔位(Encoder, Decoder, Encoder-Decoder)分別適合跑什麼路況,以及對應的代表車型是誰。
01 💡 靈魂機制:Attention(注意力)
—— 模型是如何“懂”你的?
在 Transformer 出現之前,老一代的 NLP 模型(如 RNN)像是一個記性不好的閲讀者,讀到句子末尾時,往往忘了開頭講什麼。
而 Transformer 的核心武器是 **Self-Attention(自注意力機制)**。
🌰 這是一個通俗的比喻:
想象你在讀這行字:“蘋果公司今天發佈了新手機,它真貴。”
當你讀到“貴”這個字時,你的大腦會自動把注意力聚焦在前面的“手機”和“蘋果”上,而不是“今天”或“發佈”。
這就是 Attention。它讓模型在生成或理解每一個 Token 時,都會 “回頭看一看” 上下文中的其他 Token,並計算出它們之間的關聯強度(權重)。
02 ⚔️ 華山論劍:三大家族與主流模型
—— 並不是所有模型都叫 GPT
Transformer 架構雖然統一了江湖,但根據對 Attention 的使用方式不同,分化出了三大流派。作為架構師,選對流派,成本能省 90%,效果能提升 50%。
1. 🧐 嚴謹的理解者:Encoder-only (BERT 家族)
- 核心特點:雙向注意力。它能同時看到“過去”和“未來”,擁有上帝視角。
- 比喻:完形填空高手。擅長做閲讀理解,但不擅長説話。
- 架構師必知代表模型 :
- 🌍 BERT (Google) :鼻祖級模型,工業界微調任務的基石。
- 🇨🇳 RoBERTa-wwm (哈工大訊飛) :針對中文優化的 BERT,中文理解任務的首選。
- 🇨🇳 BGE / M3 (BAAI 智源) :重點關注! 目前 RAG(檢索增強生成)架構中,用於將文本轉為向量(Embedding)的最強開源模型之一。
- 適用場景:文本分類(情感分析)、實體抽取(NER)、RAG 系統的向量檢索。
2. 🗣️ 奔放的創作者:Decoder-only (GPT 家族)
- 核心特點:單向注意力。只能看到“過去”,永遠看不見“未來”,走一步看一步。
- 比喻:即興演講大師。目前最火的大模型(LLM)基本都屬於這一派。
- 架構師必知代表模型:
- 🌍 GPT-4 / GPT-4o (OpenAI) :目前的戰力天花板,邏輯推理和多模態能力的標杆。
- 🌍 LLaMA 3 (Meta) :開源界的盟主,大多數私有化部署模型的基座。
- 🇨🇳 Qwen 通義千問 (Alibaba) :中文能力極強,生態完善,Qwen-72B/7B 是國產開源的佼佼者。
- 🇨🇳 DeepSeek 深度求索: 在代碼生成和數學推理上表現驚人,且 API 價格極具破壞力。
- 🇨🇳 ChatGLM (智譜 AI) :國內最早跑通消費級顯卡(int4 量化)的模型,微調生態非常成熟。
- 適用場景:文本生成、對話系統、創意寫作、代碼補全、邏輯推理。
3. 🔄 全能的翻譯官:Encoder-Decoder (Seq2Seq 家族)
- 核心特點:左手理解(Encoder),右手生成(Decoder)。
- 比喻:同聲傳譯員。
- 架構師必知代表模型:
- 🌍 T5 (Google) :Text-to-Text Transfer Transformer,萬金油模型。
- 🌍 BART (Facebook) :擅長文本摘要。
- 現狀:在通用大模型領域,Decoder-only 逐漸佔據了統治地位,但在機器翻譯和特定格式摘要任務中,T5 依然有一席之地。
03 🏗️ 架構師視角:選型與瓶頸
—— 別讓你的系統卡在“生成”上
作為從大數據轉型來的架構師,你可能習慣了 MapReduce 的並行處理思維。但在 LLM 時代,你必須面對一個新的物理約束。
🛑 核心瓶頸:推理延遲 (Inference Latency)
請記住這個公式:
Decoder 生成耗時 ≈ Token 數量 × 單個 Token 生成時間
GPT/Qwen 這類模型的生成是串行的。 它必須先生成第 1 個字,才能生成第 2 個字。如果一個字耗時 50ms,1000 個字就是 50 秒。這是物理硬傷,堆 GPU 也只能緩解,無法消除。
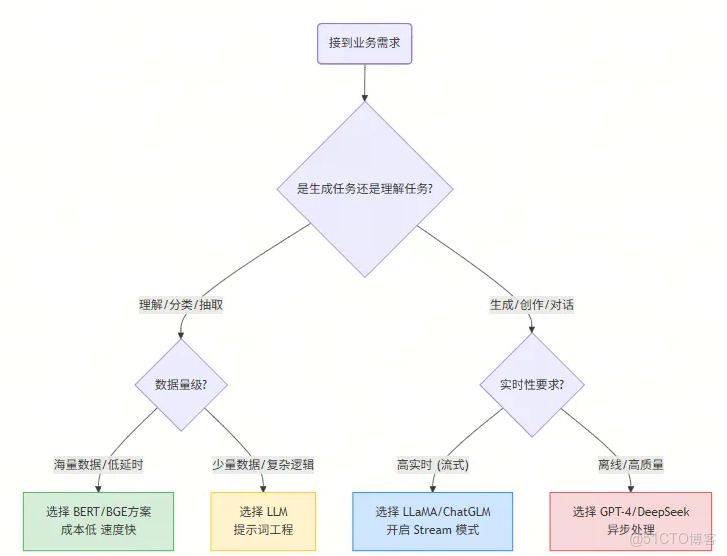
⚖️ 選型決策實戰
假設你現在要為公司設計一個 “電商評論分析系統” ,老闆有兩個需求:
- 需求 A:從 100 萬條評論中,找出所有抱怨“物流慢”的評論。
- 需求 B:針對用户的差評,自動寫一段安撫回覆。
❌ 錯誤的架構(全用 GPT-4):
- 用 GPT-4 掃描 100 萬條評論做分類。
- 後果:Token 費用爆炸,處理時間可能需要幾天。
✅ 正確的架構(組合拳):
- 針對需求 A(理解任務):使用 BGE 做向量檢索,或者微調一個 RoBERTa 小模型。
- 理由:BERT 類模型處理速度極快,可並行,成本幾乎為零。
- 針對需求 B(生成任務):調用 Qwen-Max 或 DeepSeek 接口。
- 理由:只有 Decoder 架構才能寫出有人情味的回覆。
👇 架構選型決策流程圖:
04 🛠️ 總結與下一步
今天我們拆解了大模型的“心臟”。作為架構師,你不需要去訓練一個 Transformer,但你必須深刻理解 Encoder(理解) 和 Decoder(生成) 的區別。
- Encoder (BERT/BGE) 是你手裏精準的手術刀,適合做分析、提取、搜索。
- Decoder (GPT/Qwen) 是你手裏萬能的畫筆,適合做創作、對話、交互。
未來的 AI 應用架構,往往是 “小模型(BERT/Embedding)做路由和檢索” + “大模型(GPT)做總結和生成” 的混合架構。這正是我們大數據工程師發揮架構整合能力的最佳戰場!
🧠 本文思維導圖總結
📢 下期預告
搞懂了“心臟”和“選型”,下一期我們將進入連接大數據與 AI 的最關鍵橋樑,也是 RAG(檢索增強生成)的基石——**Embedding(向量化)**。
👉 互動話題: 國產模型百花齊放,Qwen、DeepSeek、ChatGLM,你在實際業務中更看好哪一個?或者你踩過哪些坑?歡迎在評論區分享你的“實戰經驗”!
這是【大模型基礎理論】專題的第二篇。如果你錯過了第一篇《Python 高級工程化》,歡迎點擊歷史消息查看。讓我們一起,從大數據工程師蜕變為 AI 架構師!