
💎 本文價值提示
閲讀時長:約 8 分鐘 核心收穫:
- 打破壁壘:從大數據視角解構 Milvus 架構,你會發現這全是你的“老熟人”。
- 實戰選型:深度對比 Milvus 與 Elasticsearch 8.0+,掌握企業級落地的決策邏輯。
- 架構思維:理解從“玩具級 Demo”到“生產級集羣”的質變關鍵。
適用人羣:正在從大數據/後端轉型 AI Infra、RAG 架構師的技術人員。
👋 前言:歡迎回到“舒適區”
大家好!在上一期的 《Python 高級工程化》 和 《大模型基礎理論》 專題中,我們已經打好了地基。而在本專題的第一篇,我們通過 Chroma 跑通了 RAG 的最小閉環(MVP)。
很多同學在後台留言:“*跑個 Demo 很簡單,但數據量一上億,查詢就崩,內存就爆,這咋整?*”
恭喜你,問到了點子上。
如果説跑 Demo 是 AI 算法工程師的“遊樂場”,那麼大規模、高併發、分佈式的向量檢索,就是我們大數據工程師的 **“核心戰場”**。
今天,我們將進入RAG 架構與數據工程——向量數據庫專項計劃的第二階段。我們將暫時放下 Python 腳本,拿起我們最擅長的武器——分佈式架構,去解剖兩個生產級的重量級選手:Milvus 和 Elasticsearch。
你會驚訝地發現:原來向量數據庫的底層,竟然長得和 Kafka、HDFS 這麼像! 😲
🏗️ 一、Milvus:披着 AI 外衣的大數據組件
如果你第一次看 Milvus 的架構圖,可能會被那一堆 Coord、Node、Proxy 搞暈。但作為大數據老兵,請允許我為你戴上一副 **“大數據透視鏡”**。
Milvus 是典型的雲原生(Cloud-Native)架構,它的核心設計哲學是存儲與計算分離,以及控制平面與數據平面分離。
1.1 架構映射:找找“老朋友”
讓我們用 Hadoop/Kafka 的概念來翻譯 Milvus 的組件:
- Proxy (代理層) ➡️ Gateway / Router
- 它是集羣的門户,負責接收請求、聚合結果。就像 Nginx 或數據庫中間件,它不存數據,只管路由。
- Coord (協調服務) ➡️ Master / NameNode / Zookeeper Controller
RootCoord、DataCoord、QueryCoord。它們是大腦,負責分配任務、管理元數據。這不就是 HDFS 的 NameNode 嗎?
- Worker Node (執行節點) ➡️ DataNode / RegionServer
DataNode(負責寫)、QueryNode(負責查)、IndexNode(負責建索引)。它們是幹苦力的,且無狀態(Stateless),隨時可以擴縮容。
- Log Broker (消息骨幹) ➡️ Kafka / Pulsar
- 這是 Milvus 最精妙的設計! 它用消息隊列(默認 Pulsar)來做 WAL(預寫日誌)。一切操作皆消息,保證了數據的最終一致性。
1.2 核心數據流:WAL 與 刷盤
為什麼説 Milvus 適合大數據工程師?因為它解決“數據丟失”和“高併發寫入”的思路,和我們做數倉 ETL 是一模一樣的。
請看下面的數據寫入流程圖:
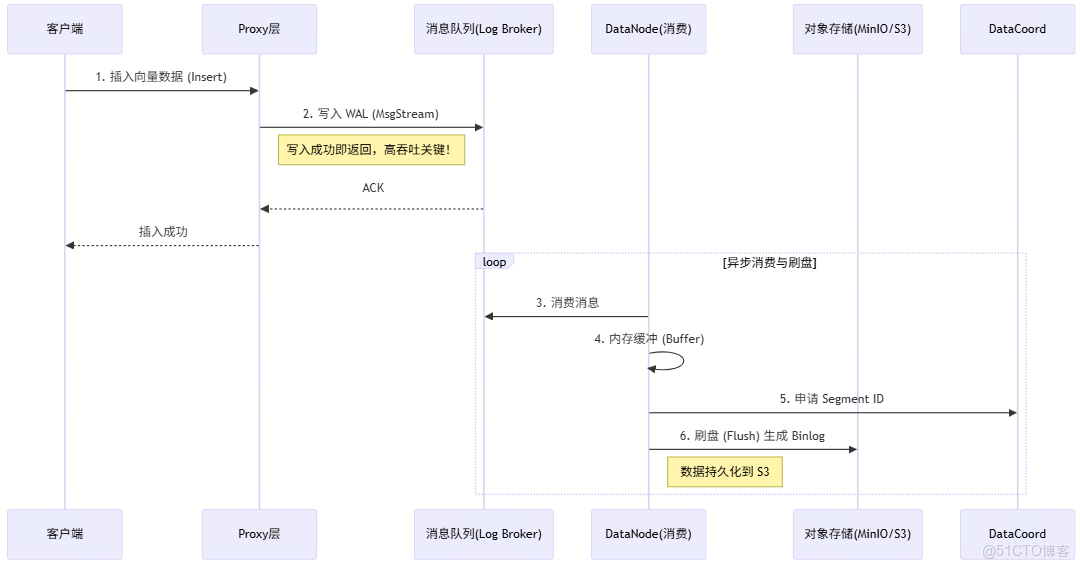
🧐 架構師視角的解讀:
- 寫操作是異步的:客户端只要把數據塞進消息隊列(Log Broker)就算成功。這保證了極高的寫入吞吐量(Write Throughput)。
- 流批一體:數據先在內存(Growing Segment),達到閾值後刷寫到對象存儲(Sealed Segment)。這不就是我們熟悉的 LSM-Tree 或者 Hudi/Iceberg 的邏輯嗎?
- 存算分離:數據最終存在 S3/MinIO 上,計算節點(QueryNode)如果掛了,起個新的拉取數據即可,不丟數據。
1.3 部署實戰:Kubernetes 是標配
在生產環境,你不會用 docker-compose 跑 Milvus,你會用 K8s。 作為大數據工程師,你對 Helm Charts、Pod 資源限制、PVC 掛載早已爛熟於心。
- 挑戰:AI 工程師可能不懂為什麼 Etcd 掛了整個集羣就癱瘓了。
- 你的價值:你可以通過配置 K8s 的
Affinity(親和性),讓計算密集型的IndexNode跑在 GPU 機器上,讓 IO 密集型的DataNode跑在高帶寬機器上。這就是工程化落地的價值!
🔍 二、Elasticsearch (8.0+):老樹發新芽
如果説 Milvus 是為了向量而生的“特種部隊”,那麼 Elasticsearch 就是企業裏的“瑞士軍刀”。
很多公司的數據本來就在 ES 裏(日誌、商品信息、用户畫像)。如果為了做 RAG,非要引入一套複雜的 Milvus,運維成本(Etcd+Pulsar+MinIO+Milvus)會直接勸退老闆。
這時候,Elasticsearch 8.0+ 的 Vector Search 就是你的救命稻草。
2.1 核心特性:dense_vector
在 ES 8.x 中,向量檢索不再是插件,而是原生的一等公民。
PUT /my-rag-index
{
"mappings": {
"properties": {
"content": { "type": "text" }, // 傳統倒排索引
"embedding": {
"type": "dense_vector", // 向量字段
"dims": 1536, // OpenAI 模型維度
"index": true,
"similarity": "cosine" // 餘弦相似度
}
}
}
}
2.2 倒排索引 vs 向量索引:資源消耗戰
作為架構師,你需要清楚 ES 做向量檢索的代價。
| 特性 | 倒排索引 (Inverted Index) | 向量索引 (HNSW in ES) |
|---|---|---|
| 原理 | 關鍵詞 -> 文檔 ID | 圖導航 (Graph Navigation) |
| 內存消耗 | 低 (主要存 Term Dictionary) | 極高 (圖結構常駐堆外內存) |
| 查詢速度 | 極快 (O(1) ~ O(logN)) | 快,但受限於內存帶寬 |
| 準確率 | 100% 精確匹配 | 近似匹配 (Approximate) |
⚠️ 避坑指南: ES 的 HNSW 索引非常吃內存(Off-heap memory)。如果你在只有 16G 內存的節點上存 1000 萬條 1536 維的向量,ES 可能會頻繁 GC 甚至 OOM。 大數據工程師的直覺:這時候你需要做索引分片(Sharding)規劃,或者通過Force Merge減少 Segment 數量,這都是我們的拿手好戲。
⚔️ 三、巔峯對決:Milvus vs Elasticsearch
在做架構選型報告時,老闆問你:“為什麼選 A 不選 B?” 你可以直接甩出這張對比圖:
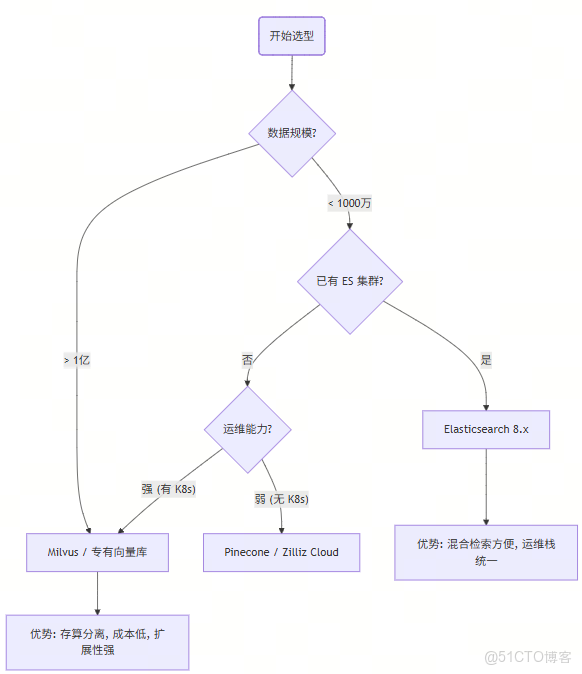
- 選 Milvus:當你數據量極大(億級),或者需要極致的向量檢索性能,且團隊有 K8s 運維能力。
- 選 Elasticsearch:當你數據量中等(千萬級),且強依賴“關鍵詞+向量”的混合檢索(Hybrid Search),或者不想引入新組件。
🧠 四、總結與思維導圖
從大數據工程師轉型 AI 架構師,不要丟掉你的“舊錘子”,因為 AI 的世界裏到處都是“釘子”。
Milvus 的架構設計證明了:AI 系統本質上還是分佈式數據系統。你對一致性哈希、WAL、LSM-Tree、Sharding 的理解,就是你駕馭 RAG 架構的內功心法。
在下一階段,我們將深入 索引算法(HNSW, IVF, DiskANN) 的底層。那是純算法與數據結構的暴力美學,敬請期待!
🗺️ 本文核心知識點思維導圖
💬 互動話題
你的公司目前的數據基礎設施是怎樣的?
- A. 全套 Hadoop/Spark/Kafka,準備上 Milvus。
- B. 只有 MySQL/ES,想直接用 ES 做向量搜索。
- C. 還在用 Python 本地跑 Chroma/Faiss,經常內存溢出。
歡迎在評論區回覆 A、B 或 C,或者分享你在搭建向量庫時遇到的“坑”,我會挑選典型問題在下一期文章中解答!
👉 下一篇預告: 我們將硬核拆解 HNSW 和 IVF 算法,教你如何通過調整參數,在“速度”與“精度”之間跳出完美的探戈。
喜歡這篇文章嗎?記得點贊、在看、轉發,帶你的大數據兄弟們一起轉型 AI 架構師!