
String作為Java中最常用的引用類型,相對來説基本上都比較熟悉,無論在平時的編碼過程中還是在筆試面試中,String都很受到青睞,然而,在使用String過程中,又有較多需要注意的細節之處。
String的連接
如果新字符串長度大於value數組長度則進行擴容
AI寫代碼
@Test
public void contact () {
//1連接方式
String s1 = "a";
String s2 = "a";
String s3 = "a" + s2;
String s4 = "a" + "a";
String s5 = s1 + s2;
//表達式只有常量時,編譯期完成計算
//表達式有變量時,運行期才計算,所以地址不一樣
System.out.println(s3 == s4); //f
System.out.println(s3 == s5); //f
System.out.println(s4 == "aa"); //t
}
String類型的intern
AI寫代碼
public void intern () {
//2:string的intern使用
//s1是基本類型,比較值。s2是string實例,比較實例地址
//字符串類型用equals方法比較時只會比較值
String s1 = "a";
String s2 = new String("a");
//調用intern時,如果s2中的字符不在常量池,則加入常量池並返回常量的引用
String s3 = s2.intern();
System.out.println(s1 == s2);
System.out.println(s1 == s3);
}
String類型的equals
AI寫代碼
//字符串的equals方法
// public boolean equals(Object anObject) {
// if (this == anObject) {
// return true;
// }
// if (anObject instanceof String) {
// String anotherString = (String)anObject;
// int n = value.length;
// if (n == anotherString.value.length) {
// char v1[] = value;
// char v2[] = anotherString.value;
// int i = 0;
// while (n-- != 0) {
// if (v1[i] != v2[i])
// return false;
// i++;
// }
// return true;
// }
// }
// return false;
// }
StringBuffer和Stringbuilder
底層是繼承父類的可變字符數組value
AI寫代碼
/**
* The value is used for character storage.
*/
char[] value;
初始化容量為16
/**
* Constructs a string builder with no characters in it and an
* initial capacity of 16 characters.
*/
public StringBuilder() {
super(16);
}
這兩個類的append方法都是來自父類AbstractStringBuilder的方法
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
@Override
public StringBuilder append(String str) {
super.append(str);
return this;
}
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
append
AI寫代碼
Stringbuffer在大部分涉及字符串修改的操作上加了synchronized關鍵字來保證線程安全,效率較低。
String類型在使用 + 運算符例如
String a = "a"
a = a + a;時,實際上先把a封裝成stringbuilder,調用append方法後再用tostring返回,所以當大量使用字符串加法時,會大量地生成stringbuilder實例,這是十分浪費的,這種時候應該用stringbuilder來代替string。
擴容
AI寫代碼
#注意在append方法中調用到了一個函數
ensureCapacityInternal(count + len);
該方法是計算append之後的空間是否足夠,不足的話需要進行擴容
public void ensureCapacity(int minimumCapacity) {
if (minimumCapacity > 0)
ensureCapacityInternal(minimumCapacity);
}
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
擴容後的長度一般為原來的兩倍 + 2;
假如擴容後的長度超過了jvm支持的最大數組長度MAX_ARRAY_SIZE。
考慮兩種情況
如果新的字符串長度超過int最大值,則拋出異常,否則直接使用數組最大長度作為新數組的長度。
private int hugeCapacity(int minCapacity) {
if (Integer.MAX_VALUE - minCapacity < 0) { // overflow
throw new OutOfMemoryError();
}
return (minCapacity > MAX_ARRAY_SIZE)
? minCapacity : MAX_ARRAY_SIZE;
}
刪除
AI寫代碼
這兩個類型的刪除操作:
都是調用父類的delete方法進行刪除
public AbstractStringBuilder delete(int start, int end) {
if (start < 0)
throw new StringIndexOutOfBoundsException(start);
if (end > count)
end = count;
if (start > end)
throw new StringIndexOutOfBoundsException();
int len = end - start;
if (len > 0) {
System.arraycopy(value, start+len, value, start, count-end);
count -= len;
}
return this;
}
事實上是將剩餘的字符重新拷貝到字符數組value。
這裏用到了system.arraycopy來拷貝數組,速度是比較快的
system.arraycopy方法
AI寫代碼
轉自知乎:
在主流高性能的JVM上(HotSpot VM系、IBM J9 VM系、JRockit系等等),可以認為System.arraycopy()在拷貝數組時是可靠高效的——如果發現不夠高效的情況,請報告performance bug,肯定很快就會得到改進。
java.lang.System.arraycopy()方法在Java代碼裏聲明為一個native方法。所以最naïve的實現方式就是通過JNI調用JVM裏的native代碼來實現。
String的不可變性
關於String的不可變性,這裏轉一個不錯的回答
什麼是不可變?
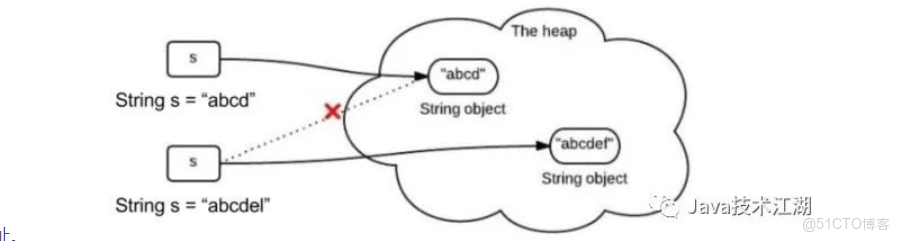
String不可變很簡單,如下圖,給一個已有字符串"abcd"第二次賦值成"abcedl",不是在原內存地址上修改數據,而是重新指向一個新對象,新地址。
String為什麼不可變?
翻開JDK源碼,java.lang.String類起手前三行,是這樣寫的:
AI寫代碼
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** String本質是個char數組. 而且用final關鍵字修飾.*/
private final char value[]; ... ...
}
首先String類是用final關鍵字修飾,這説明String不可繼承。再看下面,String類的主力成員字段value是個char[]數組,而且是用final修飾的。
final修飾的字段創建以後就不可改變。 有的人以為故事就這樣完了,其實沒有。因為雖然value是不可變,也只是value這個引用地址不可變。擋不住Array數組是可變的事實。
Array的數據結構看下圖。
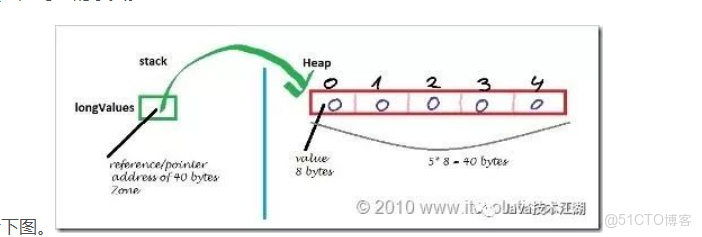
也就是説Array變量只是stack上的一個引用,數組的本體結構在heap堆。
String類裏的value用final修飾,只是説stack裏的這個叫value的引用地址不可變。沒有説堆裏array本身數據不可變。看下面這個例子,
AI寫代碼
final int[] value={1,2,3} ;
int[] another={4,5,6};
value=another; //編譯器報錯,final不可變 value用final修飾,編譯器不允許我把value指向堆區另一個地址。
但如果我直接對數組元素動手,分分鐘搞定。
final int[] value={1,2,3};
value[2]=100; //這時候數組裏已經是{1,2,100} 所以String是不可變,關鍵是因為SUN公司的工程師。
在後面所有String的方法裏很小心的沒有去動Array裏的元素,沒有暴露內部成員字段。
private final char value[]這一句裏,private的私有訪問權限的作用都比final大。而且設計師還很小心地把整個String設成final禁止繼承,避免被其他人繼承後破壞。所以String是不可變的關鍵都在底層的實現,而不是一個final。考驗的是工程師構造數據類型,封裝數據的功力。
不可變有什麼好處?
這個最簡單地原因,就是為了安全。看下面這個場景(有評論反應例子不夠清楚,現在完整地寫出來),一個函數appendStr( )在不可變的String參數後面加上一段“bbb”後返回。appendSb( )負責在可變的StringBuilder後面加“bbb”。
總結以下String的不可變性。
1 首先final修飾的類只保證不能被繼承,並且該類的對象在堆內存中的地址不會被改變。
2 但是持有String對象的引用本身是可以改變的,比如他可以指向其他的對象。
3 final修飾的char數組保證了char數組的引用不可變。但是可以通過char[0] = 'a'來修改值。不過String內部並不提供方法來完成這一操作,所以String的不可變也是基於代碼封裝和訪問控制的。
舉個例子
AI寫代碼
final class Fi {
int a;
final int b = 0;
Integer s;
}
final char[]a = {'a'};
final int[]b = {1};
@Test
public void final修飾類() {
//引用沒有被final修飾,所以是可變的。
//final只修飾了Fi類型,即Fi實例化的對象在堆中內存地址是不可變的。
//雖然內存地址不可變,但是可以對內部的數據做改變。
Fi f = new Fi();
f.a = 1;
System.out.println(f);
f.a = 2;
System.out.println(f);
//改變實例中的值並不改變內存地址。
Fi ff = f;
//讓引用指向新的Fi對象,原來的f對象由新的引用ff持有。
//引用的指向改變也不會改變原來對象的地址
f = new Fi();
System.out.println(f);
System.out.println(ff);
}這裏的對f.a的修改可以理解為char[0] = 'a'這樣的操作。只改變數據值,不改變內存值。
要理解String裏的intern方法,就要注意基本數據類型的拆箱裝箱,以及對常量池的理解。
常量池和自動拆箱裝箱
AI寫代碼
自動拆箱和裝箱的原理其實與常量池有關。
3.1存在棧中:
public void(int a)
{
int i = 1;
int j = 1;
}方法中的i 存在虛擬機棧的局部變量表裏,i是一個引用,j也是一個引用,它們都指向局部變量表裏的整型值 1.
int a是傳值引用,所以a也會存在局部變量表。
3.2存在堆裏:
class A{
int i = 1;
A a = new A();
}
i是類的成員變量。類實例化的對象存在堆中,所以成員變量也存在堆中,引用a存的是對象的地址,引用i存的是值,這個值1也會存在堆中。可以理解為引用i指向了這個值1。也可以理解為i就是1.
3.3包裝類對象怎麼存
其實我們説的常量池也可以叫對象池。
比如String a= new String("a").intern()時會先在常量池找是否有“a"對象如果有的話直接返回“a"對象在常量池的地址,即讓引用a指向常量”a"對象的內存地址。
public native String intern();
Integer也是同理。
下圖是Integer類型在常量池中查找同值對象的方法。
AI寫代碼
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
所以基本數據類型的包裝類型可以在常量池查找對應值的對象,找不到就會自動在常量池創建該值的對象。
而String類型可以通過intern來完成這個操作。
JDK1.7後,常量池被放入到堆空間中,這導致intern()函數的功能不同,具體怎麼個不同法,且看看下面代碼,這個例子是網上流傳較廣的一個例子,分析圖也是直接粘貼過來的,這裏我會用自己的理解去解釋這個例子:
AI寫代碼
[java] view plain copy
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
輸出結果為:
[java] view plain copy
JDK1.6以及以下:false false
JDK1.7以及以上:false true
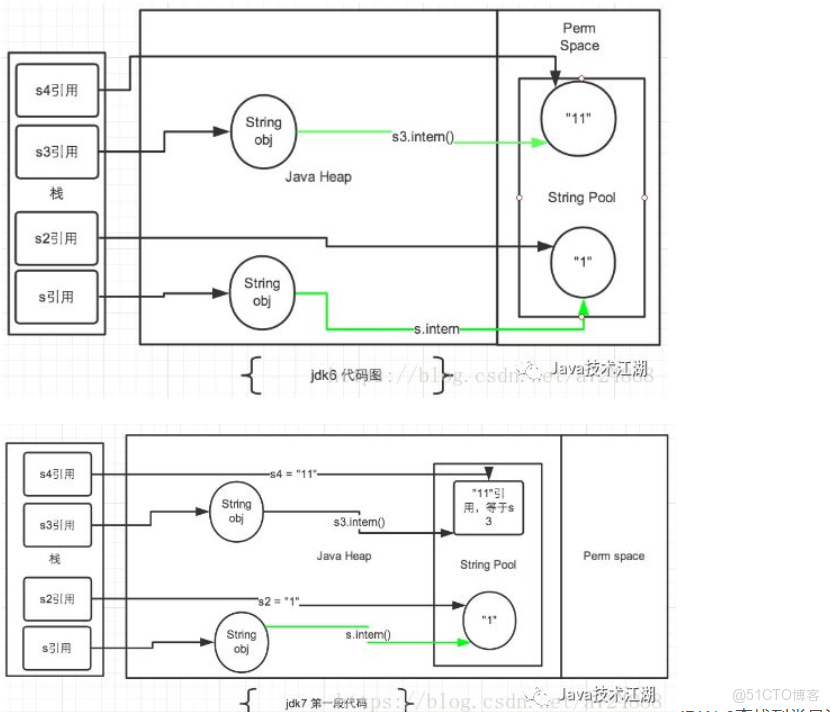
JDK1.6查找到常量池存在相同值的對象時會直接返回該對象的地址。
JDK 1.7後,intern方法還是會先去查詢常量池中是否有已經存在,如果存在,則返回常量池中的引用,這一點與之前沒有區別,區別在於,如果在常量池找不到對應的字符串,則不會再將字符串拷貝到常量池,而只是在常量池中生成一個對原字符串的引用。
那麼其他字符串在常量池找值時就會返回另一個堆中對象的地址。