
事務隔離級別
兩次轉賬
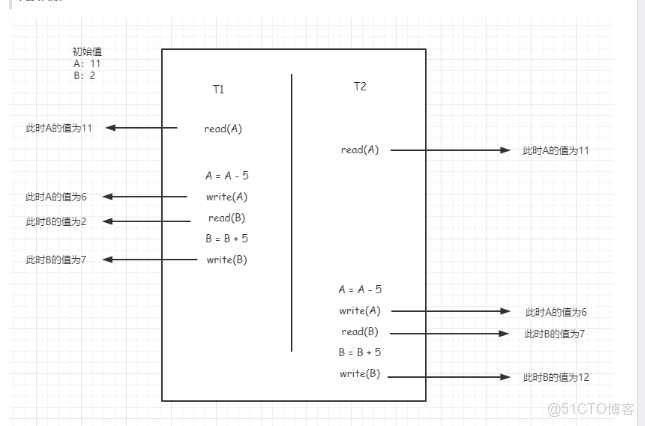
轉賬後:A:6 B:12 總和:18
違反了一致性
事務併發遇到的不一致性問題:
w=write c=commit a=abort w1=事務T1寫 x,y初始值為0
- 髒寫:一個事務修改了另一個未提交事務修改過的數據
w1[x=1]w2[x=2]w2[y=2]c2w1[y=1]c1 最終x=2,y=1破壞了一致性;
w1[x=2]w2[x=3]w2[y=3]c2a1 a1將會對x=2進行回滾到0,此時T2已經將x=3持久化。破壞了原子性和持久性。
- 髒讀:一個事務讀到了另一個未提交事務修改過的數據
- w1[x=1]r2[x=1]r2[y=0]c2w1[y=1]c1 T2得到了一個不一致的狀態
- w1[x=1]r2[x=1]a1 T2讀取了一個不存在的值x=1
- 不可重複讀:一個事務修改了另外一個未提交事務讀取的數據
r1[x=1]w2[x=2]c2r1[x=2]c1 兩次讀取不一致 - 幻讀:一個事務按照某個搜索條件讀取多次記錄時,在後讀取時讀到了之前沒有讀到的記錄 P:符合搜索條件P的記錄,[y in P]表示寫入一些符合P條件的記錄——多出來的記錄可以稱之為幻影記錄
r1[P]w2[y in P]c2r1[P]c1
解決一致性的兩種方式
- MVCC
- 鎖
SQL標準中的四種隔離級別
- READ UNCOMMITTED:讀未提交
- READ COMMITTED:讀已提交
- REPEATABLE READ:可重複讀
- SERIALIZABLE:可串行化
|
隔離級別
|
髒讀
|
不可重複讀
|
幻讀
|
|
READ UNCOMMITTED
|
可能
|
可能
|
可能
|
|
READ COMMITTED
|
不可能
|
可能
|
可能
|
|
REPEATABLE READ
|
不可能
|
不可能
|
可能
|
|
SERIALIZABLE
|
不可能
|
不可能
|
不可能
|
設置隔離級別
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level
MySQL的默認隔離級別是啥?為什麼?
https://dev.mysql.com/doc/refman/8.0/en/set-transaction.html
我們平時用的隔離級別是啥?
MVCC原理
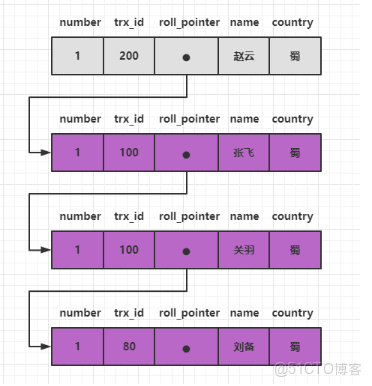
版本鏈
create table hero(
number int,
name varchar(100),
country varchar(100),
PRIMARY KEY(number)
) Engine=InnoDB CHARSET=utf-8;
insert into hero values(1,'劉備');|
number
|
name
|
country
|
|
1
|
劉備
|
蜀
|
InnoDB聚簇索引中兩個必要的隱藏列:
- trx_id:修改聚簇索引記錄的事務id
- roll_pointer: 對聚簇索引進行改動時,都會把舊的版本寫入到
undo日誌中。roll_pointer相當於一個指針,指向的就是修改前的信息
事務id分配時機
- 普通的select語句執行過程中不會分配事務id,
事務id默認是0; - 修改語句會分配一個事務id,且事務id是自增的。
undo log 的類型:
- insert 類型: 事務提交後就沒用了
- update類型: 事務提交後還需要供
MVCC使用
ReadView(一致性視圖)
READ UNCOMMITED:只需要讀取最新版本記錄即可;
READ COMMITED、REPEATABLE READ: 需要保證讀到的已經提交的事務修改的記錄
也就是版本鏈中的哪個版本的數據對當前事務是可見的
ReadView結構:
- m_ids:生成ReadView時,當前系統中活躍的讀寫事務的事務id列表
- min_trx_id:生成ReadView時,當前系統中活躍的讀寫事務中最小的事務id;也就是m_ids中的最小值
- max_trx_id:生成ReadView時系統應該分配給下一個事務的事務id
(不一定是m_ids中的最大值) - creator_trx_id:生成ReadView的事務的事務id
判斷規則
被訪問版本的trx_id等於creator_trx_id:可以訪問當前版本
被訪問版本的trx_id小於min_trx_id:可以訪問
被訪問版本的trx_id大於max_trx_id:不可以訪問
min_trx_id<被訪問版本的trx_id<max_trx_id:
- 被訪問版本的trx_id in (m_ids):不可訪問
- 可以訪問
READ COMMITED -------每次讀取數據前都生成一個ReadView
#transaction 100 #transaction 200
begin; begin;
update hero set name = '關羽' where number = 1; #更新其他一些別的表記錄
update hero set name = '張飛' where number = 1;#使用READ COMMITED隔離級別的事務
begin;
select * from hero where number = 1;#得到的值是多少?再來一次
#transaction 100 #transaction 200
begin; begin;
update hero set name = '關羽' where number = 1; #更新其他一些別的表記錄
update hero set name = '張飛' where number = 1;
------------------------------------------------------------------------------------------------------------
commit;
update hero set name = '趙雲' where number = 1;
update hero set name = '諸葛亮' where number = 1;#使用READ COMMITED隔離級別的事務
begin;
#事務100、200都未提交
select * from hero where number = 1;#得到的值是多少?
#事務100提交,200未提交
select * from hero where number = 1;#得到的值是多少?REPEATABLE READ -------只會在第一次讀取數據時生成一個ReadView
注:MySQL中的REPEATABLE READ可以很大程度上禁止幻讀
二級索引與MVCC
只有在聚簇索引中才會有trx_id和roll_pointer隱藏列。如果查詢語句使用二級索引查詢,如何判斷可見性呢?
begin
select name from hero where name = '劉備'- 二級索引頁面的PageHeader有一個PAGE_MAX_TRX_ID屬性,記錄着當前頁的最大事務id;當前生成ReadView中的
min_trx_id是否大於PAGE_MAX_TRX_ID,若是則可見,否則下一步進行判斷 - 通過回表,去比對版本鏈中的trx_id。判斷可見版本中的二級索引值是否與查詢時相同。
delete並不會立即刪除對應的記錄,而是執行一個delete mark操作,相當於打一個標記,主要就是為MVCC服務的
例如:在可重複讀級別中條件搜索
MVCC小結
所謂的mvcc就是在READ COMMITED、REPEATABLE READ這兩種隔離級別的事務執行普通的SELECT操作時,訪問記錄的版本鏈的過程。
可以對不同事務的讀 - 寫、寫 - 讀併發執行,從而提高系統性能。
關於Purge
把update undo日誌以及僅僅標記刪除的記錄徹底刪除,這個刪除操作就叫purge。
Rollback Segment Header中的兩個屬性:
- TRX_RSEG_HISTORY:History鏈表的基節點
- TRX_RSEG_HISTORY_SIZE:History鏈表佔用的頁面數量
怎麼判斷是undo日誌是否可以刪除呢?
- 在事務提交時,會為這個事務生成一個事務no,表示事務提交的順序,先提交的事務no小,提交的事務no大。
事務no將會填到undo日誌的TRX_UNDO_TRX_NO屬性上。因為History鏈表是按照事務提交的順序來排列undo日誌的。索引History鏈表中的undo日誌也是按照事務no來排序的
- 一個ReadView除了前面的屬性之外,還有一個事務no,生成ReadView時,會把比系統中最大的事務no還大1的值賦給這個屬性。
InnoDB會把當前系統中所有的ReadView按照創建時間連成一個鏈表。
判斷邏輯
將最早生成的ReadView取出來,然後從各個回滾段的History鏈表中取出事務no較小的各組undo日誌。如果一組undo日誌的事務no小於當前系統中最早生成的ReadView的事務no屬性,那麼就意味着undo日誌沒有用了。可以從鏈表中移除,釋放空間。