
Linux
Linux可劃分為四部分: 1. Linux內核 2. GNU工具 3. 圖形化桌面環境 4. 應用軟件
Linux系統的核心是內核。內核控制着計算機系統上的所有硬件和軟件,在必要時分配硬件, 並根據需要執行軟件
內核主要負責以下四種功能:
- 系統內存管理
管理服務器上的可用物理內存,還可以創建和管理虛擬內存 - 軟件程序管理
運行中的程序叫進程,內核創建第一個進程(init進程)來啓動系統上所有其他進程
Linux操作系統的init系統採用了運行級,Linux操作系統有5個啓動運行級
運行級為1時,只啓動基本的系統進程以及一個控制枱終端進程,稱之為單用户模式。 單用户模式通常用來在系統有問題時進行緊急的文件系統維護。在這種模式下,僅有一個人(通常是系統管理員)能登錄到系統上操作數據
標準的啓動運行級是3,在這個運行級上大多數應用軟件,比如網絡支持程序都會啓動
另一個Linux中常見的運行級是5。在這個運行級上系統會啓動圖形化的X Window系統,允許用户通過圖形化桌面窗口登錄系統 - 硬件設備管理
任何Linux系統需要與之通信的設備都需要在內核代碼中加入其驅動程序代碼。驅動程序代碼相當於應用程序和硬件設備的中間人,允許內核與設備之間交換數據
在Linux內核中有兩種方法用於插入設備驅動代碼:
- 編譯進內核的設備驅動代碼
- 可插入內核的設備驅動模塊
Linux系統將硬件設備當成特殊的文件,設備文件有3種分類:
- 字符型設備文件
處理數據時每次只能處理一個字符的設備。大多數類型的調制解調器和終端都是作為字符型設備文件創建的 - 塊設備文件
處理數據時每次能處理大塊數據的設備, 比如硬盤 - 網絡設備文件
採用數據包發送和接收數據的設備,包括各種網卡和一個特殊的迴環設備。這個迴環設備允許Linux系統使用常見的網絡編程協議同自身通信
Linux為系統上的每個設備都創建一種稱為節點的特殊文件。與設備的所有通信都通過設備節點完成。每個節點都有唯一的數值對讓Linux內核標識它。數值對包括一個主設備號和一個次設備號,類似的設備被劃分到同樣的主設備號下,次設備號用於標識主設備組下的某個特 定設備
- 文件系統管理
Linux內核支持通過不同類型的文件系統從硬盤中讀寫數據。除了自有的諸多文件系統外,Linux還支持從其他操作系統採用的文件系統中讀寫數據。內核必須在編譯時就加入對所有可能用到的文件系統的支持
GNU工具
供Linux系統使用的這組核心工具被稱為coreutils(core utilities)軟件包, GNU coreutils軟件包由三部分構成:1.用以處理文件的工具2.用以操作文本的工具3.用以管理進程的工具
shell是一種特殊的交互式工具,它為用户提供了啓動程序、管理文件系統中的文件以及運行在Linux系統上的進程的途徑。shell的核心是命令行提示符:輸入文本命令,然後解釋命令並在內核中執行
可以將多個shell命令放入文件中作為程序執行。這些文件被稱作shell腳本。在命令行上執行的任何命令都可放進一個shell腳本中作為一組命令執行
Ctrl+Alt+[F1~F7]:切換到不同的虛擬控制枱,Ubuntu使用F7
#setterm -background color
/*更改終端背景顏色*/
#setterm -foreground
/*更改終端字體顏色*/
#setterm -store
/*恢復默認值*/文件和目錄命令
文件命令
man命令用來訪問存儲在Linux系統上的手冊頁面。在想要查找的工具的名稱前面輸入man命令,就可以找到那個工具相應的手冊條目
手冊分配了9個內容區域:
- 1:可執行程序或shell命令
- 2:系統調用
- 3:庫調用
- 4:特殊文件
- 5:文件格式與約定
- 6:遊戲
- 7:概覽、約定及雜項
- 8:超級用户和系統管理員命令
- 9:內核例程
Linux會在根驅動器上創建一些特別的目錄,稱為掛載點mount point。掛載點是虛擬目錄中用於分配額外存儲設備的目錄

#cd destination
切換到指定目錄,沒有指定則切換至用户主目錄
#pwd
查看當前目錄
-P:顯示確定的路徑,而不是鏈接路徑,注意是大寫- 絕對路徑
從根目錄 / 開始指定完整的路徑名 - 相對路徑
不從根目錄開始,而以某目錄名或特殊字符開始
.:當前目錄..:上一層目錄-:前一個工作目錄~:目前使用者身份所在的主文件夾
ls:顯示當前目錄下的文件和目錄
-a:全部的文件,連同隱藏文件一起列出
-A:全部的文件,連同隱藏文件,但不包括 . 與 .. 這兩個目錄
-d:僅列出目錄本身,而不是列出目錄內的文件數據
-f:直接列出結果,而不進行排序(ls默認會以文件名排序)
-F:根據文件、目錄等信息,給予附加數據結構
*:代表可可執行文件
/:代表目錄
=:代表socket文件
|:代表FIFO文件
-h:將文件大小以人類較易讀的方式(例如 GB, KB 等等)列出來
-i:列出inode號碼
-l:長數據串行出,包含文件的屬性與權限等等數據
-n:列出UID與GID而非使用者與羣組的名稱
-r:將排序結果反向輸出,例如:原本文件名由小到大,反向則為由大到小
-R:連同子目錄內容一起列出來,等於該目錄下的所有文件都會顯示出來
-S:以文件大小大小排序,而不是用文件名排序
-t:依時間排序,而不是用文件名
--color=never:不要依據文件特性給予顏色顯示
--color=always:顯示顏色
--color=auto:讓系統自行依據設置來判斷是否給予顏色
--full-time:以完整時間模式(包含年、月、日、時、分)輸出
--time={atime,ctime} :輸出 access 時間或改變權限屬性時間(ctime)而非內容變更時間ls支持過濾器,就是在命令行參數後添加該字符串,可以使用通配符:
- ?:一個字符
- *:任意個字符
- [abcd] || [a~b]:包括中括號內的字符
- !:排除字符
修改時間文件 || 創建文件
每個文件在linux下面都會記錄許多的時間參數,有三個主要的變動時間:
- modification time (mtime):當該文件的內容數據變更時,就會更新這個時間,內容數據指的是文件的內容,而不是文件的屬性或權限
- status time (ctime):當該文件的狀態(status)改變時,就會更新這個時間,權限與屬性被更改都會更新這個時間
- access time (atime):當該文件的內容被取時,就會更新這個讀取時間(access),也就是更新該文件的atime
默認的情況下,ls顯示出來的是該文件的mtime
touch命令可用於修改文件或者目錄的時間屬性,包括存取時間和更改時間。若文件不存在,系統會建立一個新的文件
#touch filename
/*可以使用以下參數來改變文件時間*/
-a:僅修改訪問時間access time
-c:僅修改文件的時間,若該文件不存在則不創建新文件
-d:後面可以為修改日期,也可以使用--date="日期或時間"
-m:僅修改mtime
-t:後面可以為修改日期,格式為[YYYYMMDDhhmm]複製文件
#cp source destination
-a:相當於-dr --preserve=all的意思
-d:若來源文件為鏈接文件的屬性(link file),則複製鏈接文件屬性而非文件本身
-f:為強制(force)的意思,若目標文件已經存在且無法打開,則移除後再嘗試一次
-i:若目標文件(destination)已經存在時,在覆蓋時會先詢問動作的進行
-l:進行硬鏈接(hard link)的鏈接文件創建,而非複製文件本身
-p:連同文件的屬性(權限、用户、時間)一起復制過去,而非使用默認屬性(備份常用)
-r[-R]:遞迴持續複製,用於目錄的複製行為
-s:複製成為軟鏈接文件(symbolic link)
-u:destination比source舊才更新destination,或destination不存在的情況下才複製
--preserve=all:除了-p的權限相關參數外,還加入SELinux的屬性, links,xattr等也複製了。如果來源文件有兩個以上,則最後一個目的文件一定是目錄
特殊符號可以用在相對文件路徑
#cp /etc/NetworkManager/NetworkManager.conf .
用.來表示當前工作目錄鏈接文件
鏈接文件是Linux文件系統的一個優勢。如需要在系統上維護同一文件的兩份或多份副本, 除了保存多份單獨的物理文件副本之外,還可以採用保存一份物理文件副本和多個虛擬副本的方 法。這種虛擬的副本就稱為鏈接
#ln 目標路徑 創建路徑
-s:不加任何參數就是hard link, -s就是symbolic link
-f:如果目標文件存在時,就將目標文件直接移除後再創建- 實體鏈接(硬鏈接)
硬鏈接會創建獨立的虛擬文件,其中包含了原始文件的信息及位置。但它們從根本上而言是同一個文件。引用硬鏈接文件等同於引用了源文件 - 符號鏈接(軟鏈接)
軟鏈接就是一個實實在在的文件,它指向存放在虛擬目錄結構中某個地方的另一個文件。 這兩個通過軟鏈接在一起的文件,彼此的內容並不相同
重命名文件
在Linux中重命名文件稱為moving,mv命令可以將文件和目錄移動到另一個位置或重新命名
mv ~/Downloads/mongodb-org-server_7.0.5_amd64.deb /usr/local/bin
#mv source destination
-f:force的意思,如果目標文件已經存在,不會詢問而直接覆蓋
-i:若目標文件已經存在時,就會詢問是否覆蓋
-u:若目標文件已經存在,且源文件比較新,才會更新
/*可以使用mv來更名*/
#mv test1 test2
/*也可以使用mv命令移動文件位置並修改文件名稱*/
#mv /home/christine/Pictures/fzll /home/christine/fall
使用另一個指令rename可以更改mv ~/Downloads/mongodb-org-server_7.0.5_amd64.deb /usr/local/bin
大量文件的文件名刪除文件
#rm filename
-f:force的意思,忽略不存在的文件,不會出現警告訊息
-i:互動模式,在刪除前會詢問使用者是否動作
-r:遞迴刪除,最常用在目錄的刪除,這是非常危險的選項目錄命令
創建目錄
#mkdir directoryname
/*默認情況下目錄需要一層一層的創建,不能一次性創建多層*/
-p:會將上級不存在的目錄一併自動創建
-v:顯示詳細信息
-m:運行用户指定創建新目錄的權限刪除目錄
#rmdir directoryname
/*只能刪除空目錄*/
-p:將上層空的目錄一併刪除
-v:顯示詳細信息查看文件
查看文件類型
#file filename查看文件內容
cat(concatenate):由第一行開始顯示文件內容
#cat filename
-A:相當於-vET的整合選項,可列出一些特殊字符而不是空白
-b:列出行號,空白行不標行號
-n:列出行號,空白行也會有行號
-E:將結尾的斷行字符$顯示出來
-T:將[tab]按鍵以^I顯示出來
-v:列出一些看不出來的特殊字符more:一頁一頁的顯示文件內容
#more filename
+:從指定行開始輸出
-:指定每屏顯示的行數
+n:顯示文件中的第n行之後的內容
-n:顯示文件中的前n行內容
/*最後一行會顯示出目前顯示的百分比,而且還可以在最後一行輸入一些有用的指令:*/
space:代表向下翻一頁
Enter :代表向下翻一行
/字符串:代表在這個顯示的內容當中,向下搜尋這個字符串
:f:立刻顯示出文件名以及目前顯示的行數
q:離開more
b或[ctrl]-b :代表往回翻頁,只對文件有用less與more類似,但是它可以往前翻頁
#less filename
/*less更加靈活,有更多的指令:*/
space:向下翻動一頁
pagedown:向下翻動一頁
pageup:向上翻動一頁
/字符串:向下搜尋字符串
?字符串:向上搜尋字符串
n:重複上一個搜尋
N:反向的重複上一個搜尋
g:跳到文件開頭
G:跳到文件末尾
q:離開lesshead:顯示文件前幾行
#head -n 100
/*顯示前100行*/
#home -n -100
/*最後100行不會顯示*/tail:顯示文件後幾行
#tail -n 20
/*顯示最後20行*/
#tail -n 20
/*顯示20行以後所有數據*/
-f:在查看文件內容時實時追蹤文件的變化,在文件更新時實時刷新輸出,按下[ctrl]-c才會結束tail的追蹤系統管理命令
進程命令
ps:顯示運行在系統上所有程序的信息
/*默認情況只顯示運行在當前控制枱下的屬於當前用户的進程*/
-A 顯示所有進程
-N 顯示與指定參數不符的所有進程
-a 顯示除控制進程(session leader)和無終端進程外的所有進程
-d 顯示除控制進程外的所有進程
-e 顯示所有進程
-C cmdlist 顯示包含在cmdlist列表中的進程
-G grplist 顯示組ID在grplist列表中的進程
-U userlist 顯示屬主的用户ID在userlist列表中的進程
-g grplist 顯示會話或組ID在grplist列表中的進程
-p pidlist 顯示PID在pidlist列表中的進程
-s sesslist 顯示會話ID在sesslist列表中的進程
-t ttylist 顯示終端ID在ttylist列表中的進程
-u userlist 顯示有效用户ID在userlist列表中的進程
-F 顯示更多額外輸出(相對-f參數而言)
-O format 顯示默認的輸出列以及format列表指定的特定列
-M 顯示進程的安全信息
-c 顯示進程的額外調度器信息
-f 顯示完整格式的輸出
-j 顯示任務信息
-l 顯示長列表
-o format 僅顯示由format指定的列
-y 不要顯示進程標記(process flag,表明進程狀態的標記)
-Z 顯示安全標籤(security context)①信息
-H 用層級格式來顯示進程(樹狀,用來顯示父進程)
-n namelist 定義了WCHAN列顯示的值
-w 採用寬輸出模式,不限寬度顯示
-L 顯示進程中的線程
-V 顯示ps命令的版本號
- UID:啓動這些進程的用户
- PID:進程的進程ID
- PPID:父進程的進程號(如果該進程是由另一個進程啓動的)
- C:進程生命週期中的CPU利用率
- STIME:進程啓動時的系統時間
- TTY:進程啓動時的終端設備
- TIME:運行進程需要的累計CPU時間
- CMD:啓動的程序名稱
- F:內核分配給進程的系統標記
- S:進程的狀態(O代表正在運行;S代表在休眠;R代表可運行,正等待運行;Z代表僵化,進程已結束但父進程沒有響應;T代表停止)
- PRI:進程的優先級(越大的數字代表越低的優先級)
- NI:謙讓度值用來參與決定優先級
- ADDR:進程的內存地址
- SZ:假如進程被換出,所需交換空間的大致大小
- WCHAN:進程休眠的內核函數的地址
top:實時檢測進程
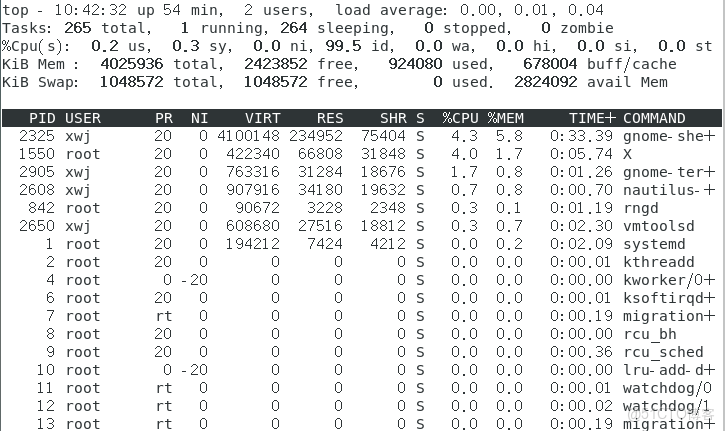
- 第1行顯示系統概況:當前時間、系統的運行時間、登錄的用户數、系統的平均負載
平均負載有3個值:最近1分鐘、最近5分鐘和最近15分鐘平均負載,值越大説明系統的負載越高 - 第2行顯示進程概要信息:top命令的輸出中將進程叫作任務task,有多少進程處在運行、休眠、停止或是僵化狀態
- 第3行顯示CPU概要信息:top根據進程的屬主(用户還是系統)和進程的狀態(運行、 空閒還是等待)將CPU利用率分成幾類輸出
- 第4行為物理內存,第5行為系統交換空間
- PID:進程ID
- USER:進程屬主的名字
- PR:進程的優先級
- NI:進程的謙讓度值
- VIRT:進程佔用的虛擬內存總量
- RES:進程佔用的物理內存總量
- SHR:進程和其他進程共享的內存總量
- S:進程的狀態(D代表可中斷的休眠狀態,R代表在運行狀態,S代表休眠狀態,T代表 跟蹤狀態或停止狀態,Z代表僵化狀態)
- %CPU:進程使用的CPU時間比例
- %MEM:進程使用的內存佔可用內存的比例
- TIME+:自進程啓動到目前為止的CPU時間總量
- COMMAND:進程所對應的命令行名稱,也就是啓動的程序名
結束進程
進程之間通過信號來通信。進程的信號就是預定義好的一個消息,進程能識別 它並決定忽略還是作出反應
Linux進程信號
1 HUP 掛起
2 INT 中斷
3 QUIT 結束運行
9 KILL 無條件終止
11 SEGV 段錯誤
15 TERM 儘可能終止
17 STOP 無條件停止運行,但不終止
18 TSTP 停止或暫停,但繼續在後台運行
19 CONT 在STOP或TSTP之後恢復執行要發送進程信號,必須是進程的屬主或登錄為root用户
kill命令可通過進程ID(PID)給進程發信號。默認情況下,kill命令會向命令行中列出的全部PID發送一個TERM信號。遺憾的是,只能用進程的PID而不能用命令名,所以kill命令有時並不好用
kill 進程號
-l:列出所有信號名稱
-s:指定發送信號,默認情況發送15信號
-p:只打印相關進程的進程號,而不發送任何信號killall命令非常強大,它支持通過進程名而不是PID來結束進程。killall命令也支持通配符,這在系統因負載過大而變得很慢時很有用
#killall http*
結束所有以http開頭的進程檢測磁盤命令
Linux文件系統將所有的磁盤都併入一個虛擬目錄下。在使用新的存儲媒 體之前,需要把它放到虛擬目錄下。這項工作稱為掛載
默認情況下,mount命令會輸出當前系統上掛載的設備列表
mount命令提供如下四部分信息:
- 媒體的設備文件名
- 媒體掛載到虛擬目錄的掛載點
- 文件系統類型
- 已掛載媒體的訪問狀態
要手動在虛擬目錄中掛載設備,需要以root用户身份登錄,或是以root用户身份運行sudo命令
#mount type device directory
-a 掛載/etc/fstab文件中指定的所有文件系統
-f 使mount命令模擬掛載設備,但並不真的掛載
-F 和-a參數一起使用時,會同時掛載所有文件系統
-v 詳細模式,將會説明掛載設備的每一步
-I 不啓用任何/sbin/mount.filesystem下的文件系統幫助文件
-l 給ext2、ext3或XFS文件系統自動添加文件系統標籤
-n 掛載設備,但不註冊到/etc/mtab已掛載設備文件中
-p num 進行加密掛載時,從文件描述符num中獲得密碼短語
-s 忽略該文件系統不支持的掛載選項
-r 將設備掛載為只讀的
-w 將設備掛載為可讀寫的(默認參數)
-L label 將設備按指定的label掛載
-U uuid 將設備按指定的uuid掛載
-O 和-a參數一起使用,限制命令只作用到特定的一組文件系統上
-o 給文件系統添加特定的選項:
ro:以只讀形式掛載。
rw:以讀寫形式掛載。
user:允許普通用户掛載文件系統。
check=none:掛載文件系統時不進行完整性校驗。
loop:掛載一個文件從Linux系統上移除一個可移動設備時,不能直接從系統上移除,而應該先卸載
Linux上不能直接彈出已掛載的CD。如果在從光驅中移除CD時遇到麻煩,通常是因為該CD還掛載在虛擬目錄裏。先卸載它,然後再去嘗試彈出
#umount [directory || device]
umount命令支持通過設備文件或者是掛載點來指定要卸載的設備。如果有任何程序正在使用設備上的文件,系統就不會允許你卸載它df:查看所有已掛載磁盤的使用情況
#df
-a:顯示所有文件系統,包括系統專用的文件系統
-h:以可讀的格式顯示磁盤使用情況,以MB、GB為單位顯示
-k:以kb為單位顯示磁盤使用情況
-m:以mb為單位顯示磁盤使用情況
-P:使用POSIX輸出格式
-T:顯示文件系統類型
-x:跳過不同文件系統上的目錄,不予統計
-l:計算所有硬鏈接的文件大小。
-i:顯示inode信息而非塊使用量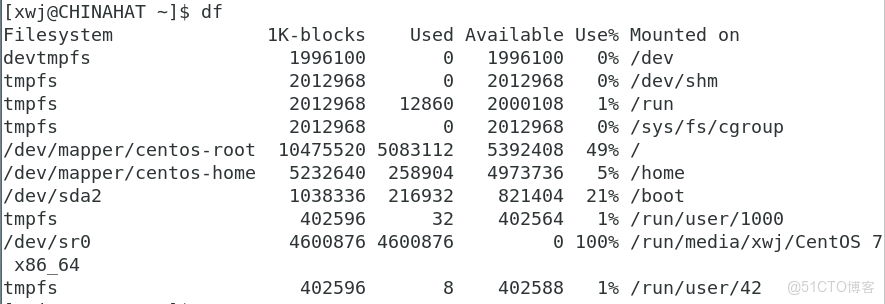
- Filesystem 設備的設備文件位置
- lk-blocks 能容納多少個1024字節大小的塊
- Used已用了多少個1024字節大小的塊
- Available還有多少個1024字節大小的塊可用
- Use%已用空間所佔的比例
- Mounted on設備掛載到了哪個掛載點上
du:查看某個特定目錄的磁盤使用情況
默認情況下,du命令會顯示當前目錄下所有的文件、目錄和子目錄的磁盤使用情況,它會以磁盤塊為單位來表明每個文件或目錄佔用了多大存儲空間
#du
-a:顯示目錄下所有文件和子目錄的大小,包括以.開頭的隱藏文件
-b:以字節為單位顯示磁盤使用空間
-c:額外顯示所有目錄或文件的總和
-h:以可讀的格式顯示磁盤使用空間,例如以K、M、G為單位
-s:只顯示目錄的總大小,不顯示其下子目錄和文件的大小
-x:以目錄樹中從根目錄開始的位置為標準,只顯示當前目錄下的文件和子目錄的大小
-l:統計硬鏈接所佔用的磁盤空間大小
-L:統計符號鏈接所指向的文件所佔用的磁盤空間大小輸出的列表是從目錄層級的最底部開始,然後按文件、子目錄、目錄逐級向上
處理數據命令
排序數據
sort命令用於對數據進行排序,默認按照字符順序進行升序排序
#sort filename
-b --ignore-leading-blanks 排序時忽略起始的空白
-C --check=quiet 不排序,數據無序不報告
-c --check 不排序,但檢查輸入數據是不是已排序,未排序將報告
-d --dictionary-order 僅考慮空白和字母,不考慮特殊字符
-f --ignore-case 默認情況大寫字母排前,這個參數會忽略大小寫
-g --general-number-sort 按通用數值來排序(跟-n不同,把值當浮點數來排序,支持科學計數法表示的值)
-i --ignore-nonprinting 在排序時忽略不可打印字符
-k --key=POS1 指定排序關鍵字,按照POS1字段來排序
-M --month-sort 按月份排序
-m --merge 將已排序數據文件合併
-n --numeric-sort 按字符串數值來排序(並不轉換為浮點數)
-o --output=file 將排序結果寫出到指定的文件中
-o output.txt input.txt:將input.txt文件中的內容排序後輸出到output.txt文件中
-R --random-sort 按隨機生成的散列表的鍵值排序
--random-source=FILE 指定-R參數用到的隨機字節的源文件
-r --reverse 反序排序(升序變降序)
-S --buffer-size=SIZE 指定使用的內存大小
-s --stable 禁用最後重排序比較
-T --temporary-directory=DIR 指定一個臨時文件目錄來存儲臨時工作文件
-t --field-separator=SEP 指定分隔符,-t":"將冒號作為分隔符
-z --zero-terminated 用NULL字符作為行尾,而不是用換行符搜索數據
grep命令會在輸入或指定的文件中查找包含匹配指定模式的字符的行
#grep characterstring
-v:反向搜索,查找不匹配該模式的行
-n:顯示對應的行號
-c:顯示一共有多少行匹配
-r:遞歸搜索指定目錄及子目錄中的文件
#grep -r "hello" /path/to/directory/
-e:指定多個匹配模式
#grep -e t -e f file1
/*可以使用正則表達式*/egrep命令是grep的一個衍生,支持POSIX擴展正則表達式。POSIX擴展正則表達式含有更多的可以用來指定匹配模式的字符
fgrep則是另外一個版本,支持將匹配模式指定為用換行符分隔的一列固定長度的字符串。這樣就可以把這列字符串放到一個文件中,然後在fgrep命令中用它在一個大型文件中搜索字符串
壓縮數據
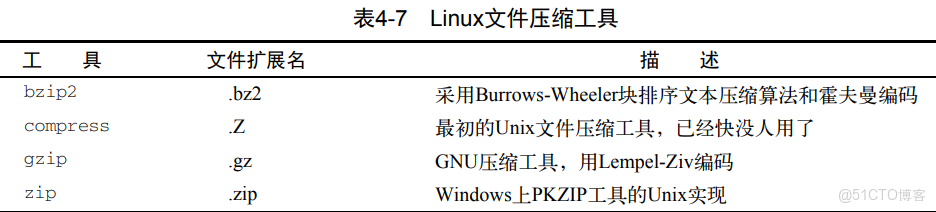
gzip:壓縮文件gzcat:查看壓縮文件內容gunzip:解壓文件
gzip命令會壓縮在命令行指定的文件,也可以在命令行指定多個文件名或使用通配符來一次性批量壓縮文件
歸檔數據
在Linux中,歸檔是將多個文件和目錄打包成一個單獨的歸檔文件(歸檔包)的過程。這個歸檔文件可以被存儲在硬盤上,或者通過網絡傳輸到其他系統或位置。歸檔文件通常用於備份、傳輸和存儲多個文件和目錄的集合,以便於在需要時進行恢復或訪問
#tar 歸檔文件名 object1 object2 ...
-A --concatenate 將一個tar歸檔文件追加到另一個tar歸檔文件
-c --create 創建一個新的tar歸檔文件
-C 切換到指定目錄
-d --diff --compare 檢查歸檔文件和文件系統的不同之處
--delete 從tar歸檔文件中刪除
-r --append 追加文件到tar歸檔文件末尾
-t --list 列出tar歸檔文件的內容
-u --update 將比tar歸檔文件中已有的同名文件新的文件追加到該tar歸檔文件中
-x --extract 從tar歸檔文件中提取文件
-f 輸出結果到文件或設備file
-j 將輸出重定向給bzip2命令來壓縮內容
-p 保留所有文件權限
-v 在處理文件時顯示文件
-z 將輸出重定向給gzip命令來壓縮內容
/*這些選項經常合併到一起使用,可以用下列命令來創建一個歸檔文件:*/
#tar -cvf test.tar test/ test2/
/*上面的命令創建了名為test.tar的歸檔文件,含有test和test2目錄內容,接着使用下列命令:*/
#tar -tf test.tar
/*列出tar文件test.tar的內容(但並不提取文件)。最後用命令:*/
#tar -xvf test.tar
/*從tar文件test.tar中提取內容,如果tar文件是從一個目錄結構創建的,那整個目錄結構都會在當前目錄下重新創建*/tar命令是給整個目錄結構創建歸檔文件的簡便方法,這是Linux中分發開源程序源碼文件所採用的普遍方法
shell
shell不單單是一種CLI(命令行界面,Command Line Interface for batch scripting),它是一個時刻都在運行的複雜交互式程序
系統啓動什麼shell程序取決於個人的用户ID配置。在/etc/passwd文件中的用户ID記錄中列出了默認的shell程序
/*可以在一行中指定要依次運行的一系列命令,這可以通過命令列表來實現,只需要在命令間加入分號即可*/
#pwd ; ls ; cd /etc ; pwd ; cd ; pwd ; ls
/*所有的命令依次執行,不過這不是進程列表。命令列表要想成為進程列表,這些命令必須包含在括號裏*/
#(pwd ; ls ; cd /etc ; pwd ; cd ; pwd ; ls)
括號的加入使命令列表變成了進程列表,生成了一個子shell來執行對應的命令,括號也可以嵌套來創建子shell的子shel進程列表是一種命令分組command grouping。另一種命令分組是將命令放入花括號中, 並在命令列表尾部加上分號,語法為{ command; }。使用花括號進行命令分組並不會創建出子shell
子shell可以利用bash命令來生成。當使用進程列表或coproc命令時也會產生子shell
可以使用一個環境變量命令來查看是否生成子shell
#echo $BASH_SUBSHELL
/*返回n便有幾個子shell*/執行命令時,是否在子shell中執行會有一些區別,主要涉及環境變量和命令執行上下文:
如果命令在子shell中執行,那麼該命令將不會影響當前shell的環境變量和執行上下文。這意味着在子shell中修改的環境變量和執行的操作不會影響父shell的環境。相反,如果命令在父shell中執行,那麼它將對當前shell的環境產生影響。
另外,子shell的執行速度可能比在父shell中執行慢一些,因為需要額外的上下文切換和創建子進程
子shell用法
一個高效的子shell用法就是使用後台模式
在後台模式中運行命令可以在處理命令的同時讓出CLI,以供它用
sleep命令接受一個參數,該參數是你希望進程等待(睡眠)的秒數。這個命令在腳本中常用於引入一段時間的暫停。sleep 10會將會話暫停10秒鐘,然後返回shell CLI提示符
/*要想將命令置入後台模式,在命令末尾加上字符&*/
#sleep 3000&
[1] 2396
當它被置入後台,在shell CLI提示符返回之前,會出現兩條信息:
1.後台作業(background job)號:1
2.後台作業的進程ID:2396
/*jobs命令可以顯示出當前運行在後台模式中的所有用户的進程(作業)*/
#jobs
[1]+ Running sleep 3000 &
作業號 當前狀態 對應命令
-l 額外顯示作業的進程ID
-n 僅顯示上次顯示後狀態發生更改的作業
-r:僅顯示運行狀態(running)的任務
-s:僅顯示停止狀態(stopped)的任務在CLI中運用子shell的創造性方法之一就是將進程列表置入後台模式。既可以在子shell中進行繁重的處理工作,同時也不會讓子shell的I/O受制於終端
協程
協程可以同時做兩件事:它在後台生成一個子shell,並在這個子shell中執行命令
/*創建子shell並將命令置入後台模式*/
#coproc sleep 10
[1] 2544
/*jobs命令能夠顯示出協程的處理狀態*/
#jobs
[1]+ Running coproc COPROC sleep 10 &
/*COPROC是coproc命令給進程起的名字。可以使用命令的擴展語法自己設置這個名字*/
#coproc My_Job { sleep 10; }
[1] 2570
# jobs
[1]+ Running coproc My_Job { sleep 10; } &
擴展語法寫起來有點麻煩
必須確保在第一個花括號和命令名之間有一個空格。還必須保證命令以分號結尾。另外,分號和閉花括號之間也得有一個空格shell的內建命令
- 外部命令
也稱文件系統命令,是存在於bash shell之外的程序,它們並不是shell 程序的一部分
當外部命令執行時,會創建出一個子進程。這種操作被稱為衍生
外部命令ps可以很方便顯示出它的父進程以及自己所對應的衍生子進程,作為外部命令,ps命令執行時會創建出一個子進程
當進程必須執行衍生操作時,它需要花費時間和精力來設置新子進程的環境。所以説外部命令多少還是有代價的
就算衍生出子進程或是創建了子shell,你仍然可以通過發送信號與其溝通
- 內建命令
不需要使用子進程來執行。它們已經和shell編譯成了一體,作為shell工具的組成部分存在,不需要藉助外部程序文件來運行
者不需要使用子進程來執行。它們已經和shell編譯成了一 體,作為shell工具的組成部分存在。不需要藉助外部程序文件來運行
因為既不需要通過衍生出子進程來執行,也不需要打開程序文件,內建命令的執行速度要更快,效率也更高
有些命令即有內建命令還有外部命令
對於有多種實現的命令,如果想要使用其外部命令實現,直接指明對應的文件就可以了。 例如要使用外部命令pwd,可以輸入/bin/pwd
history是一個內建命令,會跟蹤使用過的命令,通常歷史記錄中會保存最近的1000條命令,可以喚回並重用歷史列表中最近的命令,輸入!!,然後按回車鍵就能喚出剛剛使用過的那條命令來使用
命令歷史記錄被保存在隱藏文件.bash_history中,它位於用户的主目錄中。這裏要注意的是, bash命令的歷史記錄是先存放在內存中,當shell退出時才被寫入到歷史文件中
可以在退出shell會話之前強制將命令歷史記錄寫入.bash_history文件。要實現強制寫入,可以使用 history -a
如果打開了多個終端會話,仍可以使用history -a命令在打開的會話中向.bash_history文件中添加記錄,但是對於其他打開的終端會話,歷史記錄並不會自動更新。這是因為.bash_history文件只有在打開首個終端會話時才會被讀取。要想強制重新讀取.bash_history文件,更新終端會話的歷史記錄,可以使用history -n命令
可以喚回歷史列表中任意一條命令。只需輸入感嘆號和命令在歷史列表中的編號
alias是一個內建命令,命令別名允許你為常用的命令(及其參數)創建另一個名稱,減少輸入量
可以使用alias -p來查看當前當前可用的別名
創建別名:alias li='ls -li'
在定義好別名之後,你隨時都可以在shell中使用它,就算在shell腳本中也沒問題。 但命令別名屬於內部命令,一個別名僅在它所被定義的shell進程中才有效
echo命令
echo 是一個在許多命令行環境中常用的命令,用於在終端輸出文本或變量的值
-e:允許解釋轉義字符
-n:不在輸出後添加新行
-E:不使用-e選項,即不解釋轉義字符
-v:顯示選項後面的值環境變量
很多程序和腳本都通過環境變量來獲取系統 信息、存儲臨時數據和配置信息
bash shell用一個叫作環境變量environment variable的特性來存儲有關shell會話和工作環境的信息。這項特性允許你在內存中存儲數據,以便程序或shell中運行的腳本能夠輕鬆訪問到它們。這也是存儲持久數據的一種簡便方法
在bash shell中環境變量分為兩類
- 全局環境變量
全局環境變量對於shell會話和所有生成的子shell都是可見的,全局環境變量對那些所創建的子shell需要獲取父shell信息的程序來説非常有用
系統環境變量基本上都是使用全大寫字母,以區別於普通用户的環境變量
要查看全局變量,可以使用env或printenv命令,查看個別環境變量的值,使用printenv,也可以使用echo顯示變量的值。但在引用某個環境變量的時候,必須在變量前面加上一個美元符($) - 局部環境變量
局部變量則只對創建它們的shell可見,在Linux系統並沒有一個只顯示局部環境變量的命令
set命令會顯示出全局變量、局部變量以及用户定義變量。它還會按照字母順序對結果進行排序。env和printenv命令同set命令的區別在於前不會對變量排序,也不會輸出局部變量和用户定義變量
設置用户定義變量
一旦啓動了bash shell或者執行一個shell腳本,就能創建在這個shell進程內可見的局部變量。可以通過等號給環境變量賦值,值可以是數值或字符串
/*創建局部環境變量*/
#$my_variable
/*定義局部環境變量*/
#my_variable=Hello
/*使用局部環境變量*/
#echo $my_variable
Helloecho用於在終端或命令行界面上輸出文本或變量的值
如果要給變量賦一個含有空格的字符串值,必須用雙引號來界定字符串的首尾,沒有的話,bash shell會以為下一個詞是另一個要執行的命令
所有的環境變量名均使用大寫字母,涉及用户定義的局部變量時使用小寫字母,這能夠避免重新定義系統環境變量可能帶來的災難
變量名、等號和值之間沒有空格,這一點非常重要。如果在賦值表達式中加上了空格, bash shell就會把值當成一個單獨的命令
設置了局部環境變量後,就能在shell進程的任何地方使用它了。但如果生成了另外一個shell,它在子shell中就不可用
回到父shell時,子shell中設置的局部變量就不存在了
設置全局環境變量
創建全局環境變量的方法是先創建一個局部環境變量,然後再把它導出到全局環境中,使用export命令來完成,變量名前無需加$
#my_variable="I am Global now"
/*導出為全局環境變量*/
#export my_variable
/*創建子shell*/
#bash
/*在子shell中使用*/
#echo $my_variable
I am Global now
/*修改子shell中全局環境變量並不會影響到父shell中該變量的值,使用export也無法改變*/
#my_variable="NULL NOW"
#echo $my_variable
NULL NOW
#exit
/*父shell的環境變量並沒有改變*/
#echo $my_variable
I am Global now刪除環境變量
使用unset刪除已存在的環境變量,在unset命令中引用環境變量時,不使用$
#echo $my_variable
#I am Global now
/*刪除環境變量*/
#unset my_variable要使用變量加$,要操作變量不加,這條規則的一個例外就是使用printenv顯示某個變量的值
在子進程中刪除了一個全局環境變量, 這隻對子進程有效。該全局環境變量在父進程中依然可用
默認的shell環境變量
bash shell源自當初的Unix Bourne shell,因此也保留了Unix Bourne shell裏定義的那些環境變量,下列為bash shell支持的Bourne變量:
CDPATH 冒號分隔的目錄列表,作為cd命令的搜索路徑
HOME 當前用户的主目錄
IFS shell用來將文本字符串分割成字段的一系列字符
MAIL 當前用户收件箱的文件名(bash shell會檢查這個文件,看看有沒有新郵件)
MAILPATH 冒號分隔的當前用户收件箱的文件名列表(bash shell會檢查列表中的每個文件,看看有沒有新郵件)
OPTARG getopts命令處理的最後一個選項參數值
OPTIND getopts命令處理的最後一個選項參數的索引號
PATH shell查找命令的目錄列表,由冒號分隔
PS1 shell命令行界面的主提示符
PS2 shell命令行界面的次提示符bash shell環境變量
BASH 當前shell實例的全路徑名
BASH_ALIASES 含有當前已設置別名的關聯數組
BASH_ARGC 含有傳入子函數或shell腳本的參數總數的數組變量
BASH_ARCV 含有傳入子函數或shell腳本的參數的數組變量
BASH_CMDS 關聯數組,包含shell執行過的命令的所在位置
BASH_COMMAND shell正在執行的命令或馬上就執行的命令
BASH_ENV 設置了的話,每個bash腳本會在運行前先嚐試運行該變量定義的啓動文件
BASH_EXECUTION_STRING 使用bash -c選項傳遞過來的命令
BASH_LINENO 含有當前執行的shell函數的源代碼行號的數組變量
BASH_REMATCH 只讀數組,在使用正則表達式的比較運算符=~進行肯定匹配(positive match)時,包含了匹配到的模式和子模式
BASH_SOURCE 含有當前正在執行的shell函數所在源文件名的數組變量
BASH_SUBSHELL 當前子shell環境的嵌套級別(初始值是0)
BASH_VERSINFO 含有當前運行的bash shell的主版本號和次版本號的數組變量
BASH_VERSION 當前運行的bash shell的版本號
BASH_XTRACEFD 若設置成了有效的文件描述符(0、1、2),則'set -x'調試選項生成的跟蹤輸出可被重定向。通常用來將跟蹤輸出到一個文件中
BASHOPTS 當前啓用的bash shell選項的列表
BASHPID 當前bash進程的PID
COLUMNS 當前bash shell實例所用終端的寬度
COMP_CWORD COMP_WORDS變量的索引值,後者含有當前光標的位置
COMP_LINE 當前命令行
COMP_POINT 當前光標位置相對於當前命令起始的索引
COMP_KEY 用來調用shell函數補全功能的最後一個鍵
COMP_TYPE 一個整數值,表示所嘗試的補全類型,用以完成shell函數補全
COMP_WORDBREAKS Readline庫中用於單詞補全的詞分隔字符
COMP_WORDS 含有當前命令行所有單詞的數組變量
COMPREPLY
COPROC
含有由shell函數生成的可能填充代碼的數組變量
佔用未命名的協進程的I/O文件描述符的數組變量
DIRSTACK 含有目錄棧當前內容的數組變量
EMACS 設置為't'時,表明emacs shell緩衝區正在工作,而行編輯功能被禁止
ENV 如果設置了該環境變量,在bash shell腳本運行之前會先執行已定義的啓動文件(僅用於當bash shell以POSIX模式被調用時)
EUID 當前用户的有效用户ID(數字形式)
FCEDIT 供fc命令使用的默認編輯器
FIGNORE 在進行文件名補全時可以忽略後綴名列表,由冒號分隔
FUNCNAME 當前執行的shell函數的名稱
FUNCNEST 當設置成非零值時,表示所允許的最大函數嵌套級數(一旦超出,當前命令即被終止)
GLOBIGNORE 冒號分隔的模式列表,定義了在進行文件名擴展時可以忽略的一組文件名
GROUPS 含有當前用户屬組列表的數組變量
histchars 控制歷史記錄擴展,最多可有3個字符
HISTCMD 當前命令在歷史記錄中的編號
HISTCONTROL 控制哪些命令留在歷史記錄列表中
HISTFILE 保存shell歷史記錄列表的文件名(默認是.bash_history)
HISTFILESIZE 最多在歷史文件中存多少行
HISTTIMEFORMAT 如果設置了且非空,就用作格式化字符串,以顯示bash歷史中每條命令的時間戳
HISTIGNORE 由冒號分隔的模式列表,用來決定歷史文件中哪些命令會被忽略
HISTSIZE 最多在歷史文件中存多少條命令
HOSTFILE shell在補全主機名時讀取的文件名稱
HOSTNAME 當前主機的名稱
HOSTTYPE 當前運行bash shell的機器
IGNOREEOF shell在退出前必須收到連續的EOF字符的數量(如果這個值不存在,默認是1)
INPUTRC Readline初始化文件名(默認是.inputrc)
LANG shell的語言環境類別
LC_ALL 定義了一個語言環境類別,能夠覆蓋LANG變量
LC_COLLATE 設置對字符串排序時用的排序規則
LC_CTYPE 決定如何解釋出現在文件名擴展和模式匹配中的字符
LC_MESSAGES 在解釋前面帶有$的雙引號字符串時,該環境變量決定了所採用的語言環境設置
LC_NUMERIC 決定着格式化數字時採用的語言環境設置
LINENO 當前執行的腳本的行號
LINES 定義了終端上可見的行數
MACHTYPE 用“CPU公司系統”(CPU-company-system)格式定義的系統類型
MAPFILE 一個數組變量,當mapfile命令未指定數組變量作為參數時,它存儲了mapfile所讀
入的文本
MAILCHECK shell查看新郵件的頻率(以秒為單位,默認值是60)
OLDPWD shell之前的工作目錄
OPTERR 設置為1時,bash shell會顯示getopts命令產生的錯誤
OSTYPE 定義了shell所在的操作系統
PIPESTATUS 含有前台進程的退出狀態列表的數組變量
POSIXLY_CORRECT 設置了的話,bash會以POSIX模式啓動
PPID bash shell父進程的PID
PROMPT_COMMAND 設置後,在命令行主提示符顯示之前會執行這條命令
PROMPT_DIRTRIM 用來定義當啓用了\w或\W提示符字符串轉義時顯示的尾部目錄名的數量。被刪除的目錄名會用一組英文句點替換
PS3 select命令的提示符
PS4 如果使用了bash的-x選項,在命令行之前顯示的提示信息
PWD 當前工作目錄
RANDOM 返回一個0~32767的隨機數(對其的賦值可作為隨機數生成器的種子)
READLINE_LINE 當使用bind –x命令時,存儲Readline緩衝區的內容
READLINE_POINT 當使用bind –x命令時,表示Readline緩衝區內容插入點的當前位置
REPLY read命令的默認變量
SECONDS 自從shell啓動到現在的秒數(對其賦值將會重置計數器)
SHELL bash shell的全路徑名
SHELLOPTS 已啓用bash shell選項列表,列表項之間以冒號分隔
SHLVL shell的層級;每次啓動一個新bash shell,該值增加1
TIMEFORMAT 指定了shell的時間顯示格式
TMOUT select和read命令在沒輸入的情況下等待多久(以秒為單位)。默認值為0,表示
無限長
TMPDIR 目錄名,保存bash shell創建的臨時文件
UID 當前用户的真實用户ID(數字形式)PATH環境變量
當在shell命令行界面中輸入一個外部命令時,shell必須搜索系統來找到對應的程序。PATH環境變量定義了用於進行命令和程序查找的目錄

輸出中顯示了有8個可供shell用來查找命令和程序,PATH中的目錄使用冒號分隔。 如果命令或者程序的位置沒有包括在PATH變量中,不使用絕對路徑shell是無法找到的
PATH=$PATH:/home/christine/Scripts
/*將目錄添加到PATH環境變量,就可以在虛擬目錄結構中的任何位置執行程序*/對PATH變量的修改只能持續到退出或重啓系統
登入Linux系統啓動一個bash shell時,默認情況下bash會在幾個文件中查找命令。這些文件叫作啓動文件或環境文件,bash檢查的啓動文件取決於啓動bash shell的方式。啓動bash shell有3種方式:
- 登錄時作為默認登錄shell
- 作為非登錄shell的交互式shell
- 作為運行腳本的非交互shell
登錄式shell
當你登錄Linux系統時,bash shell會作為登錄shell啓動。登錄shell會從5個不同的啓動文件裏讀取命令:
- /etc/profile
/etc/profile文件是系統上bash shell默認的主啓動文件。系統上的每個用户登錄時都會執行這個啓動文件
剩下的啓動文件都起着同一個作用:提供一個用户專屬的啓動文件來定義該用户所用到的環境變量。大多數Linux發行版只用這四個啓動文件中的一到兩個
$HOME表示的是某個用户的主目錄,它和波浪號(~)的作用一樣 - $HOME/.bash_profile
- $HOME/.bashrc
- $HOME/.bash_login
- $HOME/.profile
交互式shell
如果bash shell不是登錄系統時啓動的(比如是在命令行提示符下敲入bash時啓動),那麼你啓動的shell叫作交互式shell
交互式shell不會像登錄shell一樣運行,但它依然提供了命令行提示符來輸入命令。 如果bash是作為交互式shell啓動的,它就不會訪問/etc/profile文件,只會檢查用户HOME目錄中的.bashrc文件
.bashrc文件有兩個作用:一是查看/etc目錄下通用的bashrc文件,二是為用户提供一個定製自己的命令別名和私有腳本函數的地方
非交互式shell
系統執行shell腳本時用的就是這種shell,不同的地方在於它沒有命令行提示符
bash shell提供了BASH_ENV環境變量。當shell啓動一個非交互式shell進 程時,它會檢查這個環境變量來查看要執行的啓動文件。如果有指定的文件,shell會執行該文件裏的命令,這通常包括shell腳本變量設置
環境變量持久化
如果升級了所用的發行版, 這個文件也會跟着更新,那你所有定製過的變量設置可就都沒有了,最好在/etc/profile.d目錄中創建一個以.sh結尾的文件,把所有新的或修改過的全局環境變量設置放在這個文件中。
在大多數發行版中,存儲個人用户永久性bash shell變量的地方是HOME/.bashrc文件。這一點適用於所有類型的shell進程。但如果設置了BASH_ENV變量,那麼除非它指向的是HOME/.bashrc,否則你應該將非交互式shell的用户變量放在別的地方
可以把自己的alias設置放在 $HOME/.bashrc啓動文件中,使其效果永久化
數組變量
數組是能夠存儲多個值的變量。這些值可以單獨引用,也可以作為整個數組來引用
環境變量數組的索引值都是從0開始,如果只寫echo $mytest[2],bash會嘗試將其解釋為一個變量名,而不是一個數組元素
/*要給某個環境變量設置多個值,可以把值放在括號裏,值與值之間用空格分隔*/
#mytest=(one two three four five)
/*要引用一個單獨的數組元素,就必須用代表它在數組中位置的數值索引值,索引值要用方括號括起來*/
#echo ${mytest[2]}
#three
/*要顯示整個數組變量,可用星號作為通配符放在索引值的位置*/
#echo ${mytest[*]}
#one two three four five
/*也可以改變某個索引值位置的值*/
#mytest[2]=3
#one two 3 four five
/*unset 數組名是刪除整個數組,也可以刪除其中某個值*/
#unset mytest[2]
#echo ${mytest[*]}
#one two four five數組變量有時會讓事情很麻煩,所以在shell腳本編程時並不常用。對其他shell而言,數組變量的可移植性並不好,如果需要在不同的shell環境下從事大量的腳本編寫工作,這會帶來很多不便
Linux文件權限
用户對系統中各種對象的訪問權限取決於他們登錄系統時用的賬户。 用户權限是通過創建用户時分配的用户ID(User ID)來跟蹤的,每個用户都有唯一的UID
Linux系統的/etc/passwd文件包含了一些與用户有關的信息
#more -1 /etc/passwd
root:x:0:0:root:/root:/bin/bash
登錄用户名:用户密碼:UID:GID:用户的文本描述:用户HONE目錄的位置:用户的默認shellLinux系統的用户密碼在/etc/shadow文件中,只有root用户才能訪問,它為系統上的每個用户賬户都保存了一條記錄
添加新用户
#useradd username
-c 添加備註
-d 後面指定用户登錄時的主目錄
-D 查看默認值,不在命令行中指定具體的值,useradd命令就會使用默認值
-s 後面指定用户的登錄shell
-G 後面指定用户的附加組,可以指定多個值,使用逗號隔開
-e YYYY-MM-DD格式指定一個賬户過期的日期
-k 必須和-m一起使用,將/etc/skel目錄的內容複製到用户的HOME目錄
-m 自動創建用户的主目錄 默認情況不會自動創建
-M 不創建用户主目錄
-n 創建一個與用户登錄名同名的新組
-f 設置密碼過期的天數,設置為0則是禁用密碼過期警告
-u 手動設置UID
-g 手動設置GID
-r 創建系統賬户
-p 為用户賬户指定默認密碼
# useradd -D
GROUP=100 羣組
HOME=/home HOME目錄
INACTIVE=-1 密碼過期後不會被禁用
EXPIRE= 未設置過期日期
SHELL=/bin/bash 默認shell
SKEL=/etc/skel 該目錄下的內容複製到用户的HOME目錄下
CREATE_MAIL_SPOOL=yes 為該用户在mail目錄下創建一個用於接收郵件的文件useradd命令使用系統的默認值以及命令行參數來設置用户賬户,系統默認值在/etc/default/useradd文件中
刪除用户
默認情況下,userdel命令只刪除/etc/passwd文件中的用户信息,而不會刪除系統中屬於該賬户的任何文件
-r 刪除用户的主目錄及其所有文件
-f 強制刪除用户,即使該用户已登錄
-n 默認情況下userdel命令會刪除用户主目錄,如果要保留用户主目錄,可以使用-n選項指定新的用户名,並將-r選項設置為false修改用户
usermod:修改用户賬户的字段,還可以指定主要組以及附加組的所屬關係
-l newname oldname 修改登錄名
-d newdirectory 修改主目錄
-s newshell 修改shell
-g 修改用户所屬主要組
-G 修改用户所屬附加組
-L 鎖定用户,無法登錄
-U 解鎖用户
-p 修改用户密碼passwd:修改用户密碼,-e可強制用户下次登錄時修改密碼。可以先給用户設置一個簡單的密碼,之後再強制在下次登錄時改成他們能記住的更復雜的密碼
chpasswd:從一個文件中讀取用户和密碼的組合,文件中的每一行包含一個用户名和對應的密碼,文件格式應該為“username:password”chsh:快速修改默認的用户登錄shell,使用時必須用shell的全路徑名作為參數
chfn:更改finger命令顯示的信息。這些信息存儲在/etc/passwd文件中,並由finger程序顯示
-f 設置姓名
-h 設置電話號碼
-o 設置辦公室地址
-p 設置辦公室電話號碼如果未指定任何參數,chfn命令將進入問答式界面,提示每個字段,用户可以在提示符下輸入新信息,也可以按返回使字段保持不變。輸入關鍵字None使字段為空
chage:管理用户賬號有效期
chage命令的日期值可以用下面兩種方式中的任意一種:
- YYYY-MM-DD格式的日期
- 從1970年1月1日起到該日期天數的數值
-d 設置上次修改密碼到現在的天數
-E 設置密碼過期的日期
-I 設置密碼過期到鎖定賬户的天數
-m 設置修改密碼之間最少要多少天
-W 設置密碼過期前多久開始出現提醒信息過期的賬户跟鎖定的賬户很相似:賬户仍然存在, 但用户無法用它登錄
羣組
組權限允許多個用户對系統中的對象(比如文件、目錄或設備等)共享一組共用的權限,每個組都有唯一的GID,和UID類似,組名也是唯一的
/etc/group文件包含系統上用到的每個組的信息
#more -1 /etc/group
root:x:0:
組名:組密碼:GID:屬於該組的用户列表創建新組
#groupadd groupname
-g 指定GID
-r 創建系統組,系統組GID小於500更改了已登錄系統賬户所屬的用户組,該用户必須登出系統後再登錄,組關係的更改才能生效
修改組
#groupmod groupname
-g 設置新GID
-o 允許使用重複GID
-n 設置新組名文件權限
#ls -l
drwxr-xr-x. 2 xwj xwj 6 Jan 21 13:04 Desktop第1個字符代表:
d是目錄-是文件l是鏈接文件link fileb是可供儲存的接口設備,例如硬盤,U盤[塊設備]c是串行接口設備,例如鍵盤、鼠標[字符型設備]n是網絡設備
接下來的字符以3個為一組,均為rwx的組合,無權限使用-代替:
rread:可讀取此一文件的實際內容,如讀取文本文件的文字內容等wwrite:可以編輯、新增或者是修改該文件的內容(但不含刪除該文件)xexecute:該文件具有可以被系統執行的權限
從左到右的3組權限分別為User、Group、Others的權限
2表示有多少文件名硬鏈接到此文件,每個文件至少有一個硬鏈接,通常這個硬鏈接就是文件名本身- 第1個
xwj表示這個文件或目錄的擁有者賬號 - 第2個
xwj表示這個文件的所屬羣組 193為文件的大小,單位為bytes4月 1 2020為文件最近修改日期
內容分別為月 日 時間,如果這個文件被修改的時間距離現在太久,那麼時間部分僅顯示年份
如果想要顯示完整的時間格式,ls -l --full-time就能夠顯示出完整的時間格式.bash_profile為文件名
目錄與文件的權限意義並不相同,這是因為目錄與文件所記錄的數據內容不相同
文件是存放實際數據的所在,目錄主要的內容在記錄文件名
針對目錄時:
rread contents in directory:表示具有讀取目錄結構清單的權限,所以當你具有讀取一個目錄的權限時,表示你可以查詢該目錄下的文件名數據。就可以利用ls這個指令將該目錄的內容列表顯示出來wmodify contents of directory:它表示你具有異動該目錄結構清單的權限,也就是下面這些權限:
- 創建新的文件與目錄
- 刪除已經存在的文件與目錄(不論該文件的權限為何)
- 將已存在的文件或目錄進行更名
- 搬移該目錄內的文件、目錄位置。總之,目錄的w權限就與該目錄下面的文件名異動有關
xaccess directory:目錄不可以被執行,目錄的x代表的是使用者能否進入該目錄成為工作目錄的用途,所謂的工作目錄work directory就是你目前所在的目錄,當你登陸Linux時,你所在的主文件夾就是你當下的工作目錄
文件是一堆文件數據夾,目錄是一堆抽屜,可以將數據夾分類放置到不同的抽屜去,因此抽屜最大的目的是拿出/放入數據夾
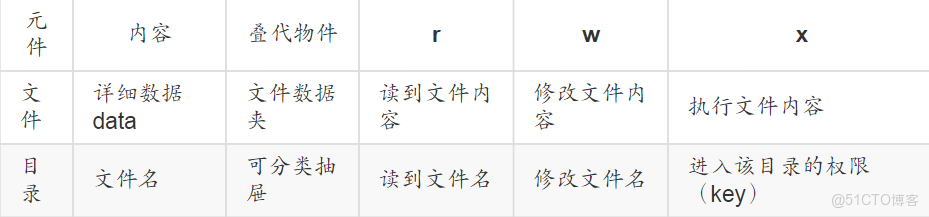
僅擁有r權限,沒有x權限是無法執行文件或進入目錄的
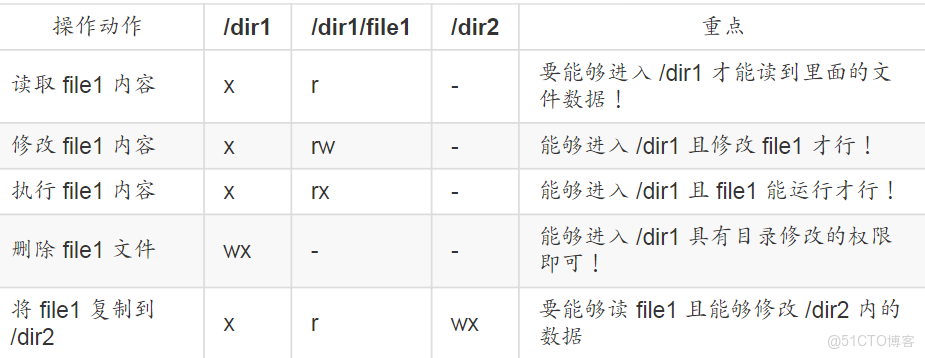
有x就可以執行了,r是可選的,如果沒有r,按Tab無法自動補齊文件名
改變文件屬性與權限
touch命令用分配給我的用户賬户的默認權限創建了這個文件,umask命令可以顯示和設置這個默認權限
#umask
0022第1位代表粘着位,是一項特別的安全特性,後面3位是文件或目錄對應的8進制值
權限 二進制 八進制 描述
--- 000 0 沒有任何權限
--x 001 1 只有執行權限
-w- 010 2 只有寫入權限
-wx 011 3 有寫入和執行權限
r-- 100 4 只有讀取權限
r-x 101 5 有讀取和執行權限
rw- 110 6 有讀取和寫入權限
rwx 111 7 有全部權限umask的值是掩碼,數字是需要減掉的值,022==755
更改權限直接在umask後輸入數字即可
改變權限
chmod命令用於改變文件和目錄的安全性設置
-r 遞歸改變指定目錄及其下所有文件和子目錄的權限
-v 顯示詳細信息- 數字類型改變文件權限
r:4,w:2,x:1
chmod 777 .bashrc符號類型改變文件權限
u:user,g:group,o:others,a:all
chmod u=rwx,go=rx .bashrc
也可以使用+來加上某個權限
a+r
也可以使用-來 減去某個權限
a-r改變所屬關係
chown :改變文件擁有者
change owner,在/etc/passwd這個文件中有紀錄的使用者名稱才能改變
可用登錄名或UID來指定文件的新屬主
#chown 賬號名 文件或目錄
/*可以以只更改擁有者,也可以同時修改擁有者和羣組*/
#chown 帳號名:羣組名 文件或目錄
-r 遞歸更改目錄及其以下所有文件和子目錄的所有者和羣組
-h 改變該文件的所有符號鏈接文件的所屬關係chgrp :改變文件所屬羣組
change group,被改變的羣組名稱必須要在/etc/group文件內存在,否則就會顯示錯誤
#chgrp 羣組名 文件或目錄
-r 不多説
-v 顯示指令執行過程
-h 只對符號鏈接的文件作修改,而不更改其他任何相關文件文件系統操作
創建分區
fdisk用於來幫助管理安裝在系統上的任何存儲設備上的分區
創建新磁盤分區最麻煩的事情就是找出安裝在Linux系統中的物理磁盤,老式的IDE驅動器,Linux使用的是/dev/hdx。其中x表示一個字母,具體是什麼要根據驅動器的檢測順 序(第一個驅動器是a,第二個驅動器是b,以此類推)
對於較新的SATA驅動器和SCSI驅動器,Linux使用/dev/sdx。其中的x具體是什麼也要根據驅動器的檢測順序(同上,第一個驅動器是a,第二個驅動器是b,以此類推)。在格式化分區之前,最好再檢查 一下是否正確指定了驅動器
#fdisk
-l 列出當前系統中的所有磁盤設備以及分區表
-u 以扇區為單位顯示分區大小
/*交互命令*/
l 顯示可用的分區類型
m 顯示命令選項
n 創建分區
d 刪除分區
p 顯示當前分區表
w 退出,保存更改
q 退出,不保存更改創建文件系統
在將數據存儲到分區之前,你必須用某種文件系統對其進行格式化,這樣Linux才能使用它。 每種文件系統類型都用自己的命令行程序來格式化分區
創建文件系統的命令行程序
mkefs 創建一個ext文件系統
mke2fs 創建一個ext2文件系統
mkfs.ext3 創建一個ext3文件系統
mkfs.ext4 創建一個ext4文件系統
mkreiserfs 創建一個ReiserFS文件系統
jfs_mkfs 創建一個JFS文件系統
mkfs.xfs 創建一個XFS文件系統
mkfs.zfs 創建一個ZFS文件系統
mkfs.btrfs 創建一個Btrfs文件系統並非所有文件系統工具都已經默認安裝了,想知道某個文件系統工具是否可用,可以使用type命令
文件系統掛載與卸載
為分區創建了文件系統之後,下一步是將它掛載到虛擬目錄下的某個掛載點,這樣就可以將數據存儲在新文件系統中
- 單一文件系統不應該被重複掛載在不同的掛載點(目錄)中
- 單一目錄不應該重複掛載多個文件系統
- 要作為掛載點的目錄,理論上應該都是空目錄
#mount -t 文件系統類型 -o 選項 設備文件 掛載點
-o:後面可以接一些掛載時額外加上的參數,比方説帳號、密碼、讀寫權限等:
async, sync:此文件系統是否使用同步寫入(sync)或非同步(async)的內存機制,默認為async
atime,noatime: 是否修訂文件的讀取時間(atime),為了性能某些時刻可使用noatime
ro, rw:掛載文件系統成為只讀(ro)或可讀寫(rw)
auto, noauto:是否允許此filesystem被以mount -a自動掛載(auto)
dev, nodev:是否允許此filesystem上可創建設備文件,dev為可允許
suid, nosuid:是否允許此filesystem含有suid/sgid的文件格式 exec, noexec:是否允許此filesystem上擁有可執行binary文件 user, nouser:是否允許此filesystem讓任何使用者執行mount,一般來説,mount僅有root可以進行,但下達user參數,則可讓一般user也能夠對此partition進行mount
defaults:默認值為:rw, suid, dev, exec, auto, nouser, and async
remount:重新掛載,在系統出錯或重新更新參數時很有用
/*卸載已掛載的文件系統*/
#umount 掛載點
-f 忽略任何錯誤,強制將文件系統從掛載點卸載
-l 將文件系統設置為只讀模式,然後卸載
-r 顯示詳細信息文件系統的檢查與修復
fsck命令能夠檢查和修復大部分類型的Linux文件系統
#fsck filesystem
-a 自動修復文件系統
-A 依照/etc/fstab配置文件的內容,檢查文件內所列的全部文件系統
-P 當搭配"-A"參數使用時,則會同時檢查所有的文件系統
-r 互動模式,在執行修復時詢問問題,讓用户得以確認並決定處理方式
-R 當搭配"-A"參數使用時,則會略過/目錄的文件系統不予檢查
-s 依序執行檢查作業,而非同時執行
-t 文件系統類型 指定要檢查的文件系統類型
-V 顯示指令執行過程可以在命令行上列出多個要檢查的文件系統。文件系統可以通過設備名、在虛擬目錄中的掛載點以及分配給文件系統的唯一UUID值來引用
只能在未掛載的文件系統上運行fsck命令。對大多數文件系統來説,你只需卸載文件系統來進行檢查,檢查完成之後重新掛載就好了。但因為根文件系統含有所有核心的Linux 命令和日誌文件,所以你無法在處於運行狀態的系統上卸載它
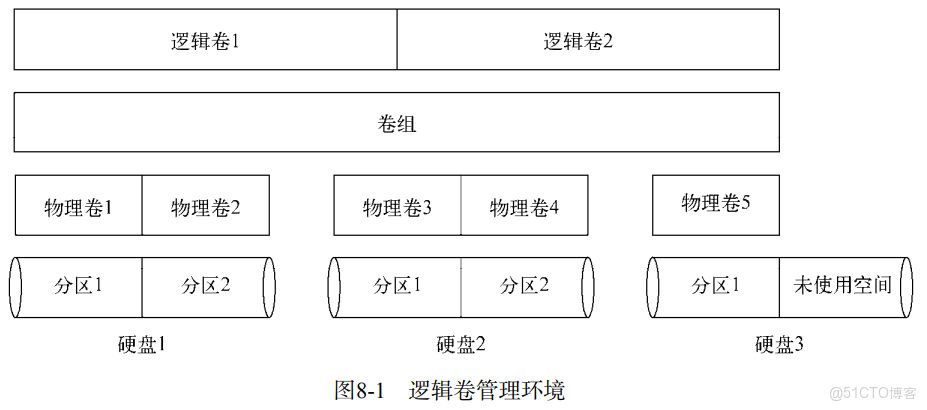
邏輯卷管理
Linux邏輯卷管理器(logical volume manager,LVM)軟件包可以讓你在無需重建整個文件系統的情況下,輕鬆地管理磁盤空間
邏輯卷管理的核心在於如何處理安裝在系統上的硬盤分區。在邏輯卷管理裏,硬盤稱作物理卷(physical volume,PV)。每個物理卷都會映射到硬盤上特定的物理分區
多個物理卷集中在一起可以形成一個卷組(volume group,VG)。邏輯卷管理系統將卷組視為一個物理硬盤,但卷組可能是由分佈在多個物理硬盤上的多個物理分區組成的。卷組提供了一個創建邏輯分區的平台,而這些邏輯分區則包含了文件系統
邏輯卷(logical volume,LV)為Linux提供了創建文件系統的分區環境,作用類似於到目前為止Linux中的物理硬盤分區。Linux系統將邏輯卷視為物理分區
可以使用任意一種標準Linux文件系統來格式化邏輯卷,然後再將它加入Linux虛擬目錄中的 某個掛載點
如果你給系統添加了一塊硬盤,邏輯卷管理系統允許你將它添加到已有卷組,為某個已有的卷組創建更多空間,或是創建一個可用來掛載的新邏輯卷
快照
在邏輯卷在線的狀態下將其複製到另一個設備
LVM2允許創建在線邏輯卷的可讀寫快照。有了可讀寫的快照,就可以刪除原先的邏輯卷, 然後將快照作為替代掛載上。這個功能對快速故障轉移或涉及修改數據的程序試驗(如果失敗, 需要恢復修改過的數據)非常有用
條帶化
可跨多個物理硬盤創建邏輯卷。當Linux LVM將文件寫入邏輯卷時,文件中的數據塊會被分散到多個硬盤上。每個後繼數據塊會被寫到下一個硬盤上
條帶化有助於提高硬盤的性能,因為Linux可以將一個文件的多個數據塊同時寫入多個硬盤, 而無需等待單個硬盤移動讀寫磁頭到多個不同位置。這個改進同樣適用於讀取順序訪問的文件, 因為LVM可同時從多個硬盤讀取數據
LVM條帶化會增加文件因硬盤故障而丟失的概率,單個硬盤故障可能會造成多個邏輯卷無法訪問
鏡像
鏡像是一個實時更新的邏輯卷的完整副本。當創建鏡像邏輯卷時,LVM會將原始邏輯卷同步到鏡像副本中。根據原始邏輯卷的大小,這可能需要一些時間才能完成。 一旦原始同步完成,LVM會為文件系統的每次寫操作執行兩次寫:一次寫入到主邏輯卷,一次寫入到鏡像副本,會降低系統的寫入性能
使用Linux LVM
定義物理卷
將硬盤上的物理分區轉換成Linux LVM使用的物理卷區段
在fdisk命令中創建基本Linux分區後,使用t命令將分區類型改為8e,分區類型8e表示這個分區將會被用作Linux LVM系統的一部分,而不是一個直接的文件系統
/*將磁盤分區轉換為物理卷*/
#pvcreate /dev/sdb1
/*顯示已創建的物理卷列表*/
#pvdisplay創建卷組
從物理卷中創建一個或多個卷組,究竟要為系統創建多少卷組並沒有既定的規則, 可以將所有的可用物理卷加到一個卷組,也可以結合不同的物理卷創建多個卷組
#vgcreate 卷組名 物理卷名
-l 卷組上允許創建的最大邏輯卷數
-p 卷組中允許添加的最大物理卷數
-v 顯示執行過程
/*顯示卷組詳細信息*/
#vgdisplay 卷組名創建邏輯卷
創建一個或多個卷組後,就可以創建邏輯卷,Linux系統使用邏輯捲來模擬物理分區,並在其中保存文件系統
Linux系統會像處理物理分 區一樣處理邏輯卷,允許你定義邏輯卷中的文件系統,然後將文件系統掛載到虛擬目錄上
#lvcreate
-c --chunksize 指定快照邏輯卷的單位大小
-C --contiguous 設置或重置連續分配策略
-i --stripes 指定條帶數
-I --stripesize 指定每個條帶的大小
-l --extents 指定分配給新邏輯卷的邏輯區段數,或者要用的邏輯區段的百分比
-L --size 指定分配給新邏輯卷的硬盤大小
--minor 指定設備的次設備號
-m --mirrors 創建邏輯卷鏡像
-M --persistent 讓次設備號一直有效
-n --name 指定新邏輯卷的名稱
-p --permission 為邏輯卷設置讀/寫權限
-r --readahead 設置預讀扇區數
-R --regionsize 指定將鏡像分成多大的區
-s snapshot 創建快照邏輯卷
/*顯示邏輯卷詳細信息*/
#lvdisplay創建文件系統
使用相應的命令行程序來創建所需要的文件系統
然後使用mount命令將這個卷掛載到虛擬目錄中
修改LVM
#vgchange 激活和禁用卷組
#vgremove 刪除卷組
#vgextend 將物理卷加到卷組中
#vgreduce 從卷組中刪除物理卷
#lvextend 增加邏輯卷的大小
#lvreduce 減小邏輯卷的大小安裝軟件程序
centos是基於Red Hat的系統,使用
#yum options command package
-h 幫助
-y 安裝過程選擇時全部為yes
常用命令包括:
安裝install
更新update 升級upgrapde 更新會保留舊版本的package,升級不會
檢查check 刪除remove
查看某個特定軟件包的詳細信息 yum list package
列出系統上已安裝的包yum list installed使用yum安裝和卸載軟件的前提是軟件包必須是rpm格式,可以使用yum clean all清除所有,yum clean headers清除緩存目錄下的headers,這些headers是用於描述軟件包信息的元數據,yum clean packages清除下載的rpm包
yum是在安裝發行版的時候設置的軟件倉庫,yum repolist可以查看現在正從哪些倉庫中獲取軟件
如果倉庫中沒有需要的軟件,可以編輯配置文件。yum的倉庫定義文件位於 /etc/yum.repos.d。需要添加正確的URL,並獲得必要的加密密鑰
使用編輯器
vim編輯器
Unix系統最初的編輯器
/*為vim設置別名*/
#alias vi=vim
#alias vi
alias vi='vim'which命令用於在PATH環境變量中指定的目錄中查找可執行文件,並返回該文件的絕對路徑。它的作用是快速定位到可執行文件的實際位置,避免因環境變量設置的錯誤導致無法找到正確的執行文件
/*查找vim的絕對路徑*/
# which vi
alias vi='vim'
/usr/bin/vim
/*查看*/
#ls -l /usr/bin/vim
-rwxr-xr-x. 1 root root 2337208 Dec 16 2020 /usr/bin/vim
文件權限組 硬鏈接數量 所有者 所屬組 文件大小[單位byte] 文件的最後修改日期 文件的絕對路徑如果vim程序被設置了鏈接,它可能會被鏈接到一個功能較弱的編輯器。所以最好 還是檢查一下鏈接文件
#vim [filename]
如在啓動vim時未指定文件名,或者這個文件不存在,vim會開闢一段新的緩衝區域來編輯vim編輯器有兩種操作模式:普通模式和插入模式,當你剛打開要編輯的文件或新建一個文件時,vim編輯器會進入普通模式。在普通模式中,vim編輯器會將按鍵解釋成命令,i進入插入模式,ESC進入普通模式
移動命令
- h:左移 l:右移
- j:下移 k:上移
- PageUp或Ctrl+B:上翻一屏
- PageDown或Ctrl+F:下翻一屏
- gg:第一行
- G:最後一行
- number G:第n行
在普通模式下有個特別的功能叫命令行模式。命令行模式提供了一個交互式命令行,可以輸入額外的命令來控制vim的行為。,在普通模式下按下冒號鍵,進入命令行模式,光標會移動到消息行,然後出現冒號,等待輸入命令
- q:如果未修改緩衝區數據,退出
- q!:取消所有對緩衝區數據的修改,退出
- w filename:將文件保存到另一個文件中
- wq:將緩衝區數據保存到文件中並退出
編輯命令
- x:刪除當前所在字符
- dw:刪除所在單詞
- dd:刪除所在行
- d$:刪除當前所在位置到行尾的內容
- j:刪除行尾換行符
- u:撤銷前一編輯命令
- a:在當前光標後追加數據
- A:在當前光標所在行行尾追加數據
- r char 用char替換當前光標所在位置的單個字符
- R text 用text覆蓋當前光標所在位置的數據,直到按下ESC鍵
查找和替換命令
- /text:查找文本
- s/old/new/g:一行命令替換所有old
- :n,ms/old/new/g:替換行號n和m之間所有old
- :%s/old/new/g:替換整個文件中的所有old

nano編輯器
- CTRL+C:顯示光標在文本編輯緩衝區中的位置
- CTRL+G:顯示nano的主幫助窗口
- CTRL+K:剪切文本行,並將其保存在剪切緩衝區
- CTRL+U:將剪切緩衝區中的內容放入當前行
- CTRL+O:將當前文本編輯緩衝區的內容寫入文件
- CTRL+R:將文件讀入當前文本編輯緩衝區
- CTRL+T:啓動可用的拼寫檢查器
- CTRL+Y:翻動到文本編輯緩衝區中的上一頁內容
- CTRL+V:翻動到文本編輯緩衝區中的下一頁內容
- CTRL+W:在文本編輯緩衝區中搜索單詞或短語
- CTRL+X:關閉當前文本編輯緩衝區,退出nano
構建shell基本腳本
shell腳本的關鍵在於輸入多個命令並處理每個命令的結果,甚至需要將一個命令的結果傳給另一個命令
#date;who
顯示時間日期;顯示當前是誰登錄命令之間使用分號隔開,可以將這些命令組合成一個簡單的文本文件,這樣就不需要在命令行中手動輸入。在需要運行這些命令時,只用運行這個文本文件
使用文本編輯器來創建shell腳本文件
#用作註釋行,shell並不會處理shell腳本中的註釋行
shell腳本文件的第一行是個例外,#後面的驚歎號會告訴shell用哪個shell來運行腳本
#gvim test
/*圖形化vim*/
#!/bin/bash
echo This script displays the date and who's logged on
date在編寫好腳本文件後,需要編寫PATH來讓shell查找到
- 將shell腳本文件所處的目錄添加到PATH環境變量中
#PATH=$PATH:/所在目錄
#bash test
This script displays the date and whos logged on
Wed Jan 31 15:22:00 CST 2024
xwj :0 2024-01-21 13:04 (:0)
root tty2 2024-01-28 13:01
xwj pts/1 2024-01-31 14:10 (:0)- 在提示符中用絕對或相對文件路徑來引用shell腳本文件
#./test
bash: ./test: Permission denied
/*拒絕權限*/最後要注意文件的權限組
在腳本中添加自己的文本消息,可以在echo命令後面加上了一個字符串,該命令就能顯示出這個文本字符串
#echo This is a test
This is a test默認情況下,不需要使用引號將要顯示的文本字符串劃定出來
echo命令可用單引號或雙引號來劃定文本字符串。如果在字符串中用到了它們,需要在文本中使用其中一種引號,而用另外一種來將字符串劃定起來
#echo Let's see if this'll work
Lets see if thisll work
/*引號無法正常顯示*/
#echo "This is a test to see if you're paying attention"
This is a test to see if you're paying attention
#echo 'Rich says "scripting is easy".'
Rich says "scripting is easy"如果想把文本字符串和命令輸出顯示在同一行中,使用echo -n
如果在字符串的兩側使用引號,保證要顯示的字符串尾部有一個空格
使用變量
變量允許臨時性地將信息存儲在shell腳本中, 以便和腳本中的其他命令一起使用
可以在script內使用環境變量,使用$來引用
用户變量可以是任何由字母、數字或下劃線組成的文本字符串,長度不超過20個,用户變量區分大小寫,使用等號將值賦給用户變量。在變量、等號和值之間不能出現空格
shell腳本會自動決定變量值的數據類型。在腳本的整個生命週期裏,shell腳本中定義的變量會一直保持着它們的值,在shell腳本結束時會被刪除,也使用$來引用
day=1
echo $day after
/*輸出*/
1 after
/*可以使用變量給變量賦值*/
da=$day
沒有$,shell會將變量名解釋為普通的文本字符串命令替換
有兩種方法可以將命令輸出賦給變量:
- 反引號字符 `
test=`date`- $()格式
test=$(date)shell會運行命令替換符號中的命令,並將其輸出賦給變量test,使用$test等價於使用date命令
命令替換會創建一個子shell來運行對應的命令。子shell是由運行該腳本的shell所創建出來的一個獨立的子shell。正因此,由該子shell所執行命令是無法使用腳本中所創建的變量的。 在命令行提示符下使用路徑./運行命令的話,也會創建出子shell;要是運行命令的時候不加入路徑,就不會創建子shell。如果你使用的是內建的shell命令,並不會涉及子shell。 在命令行提示符下運行腳本時一定要留心
重定向輸入和輸出
輸出重定向
bash shell使用>來實現
#command>outputfile
/*example*/
#date>test
#cat test
Wed Jan 31 15:33:56 CST 2024如果不想覆蓋文件原有內容,使用>>來追加數據
輸入重定向
將文件內容重定向到命令,使用 < 來實現
#wc<test
1 6 29
wc命令可以對數據進行計數,默認情況分別輸出行數、次數、字節數<<是內聯輸入重定向,這種方法無需使用文件進行重定向,只需要在命令行指定用於輸入重定向的數據即可
要在輸入輸入數據的開始和結尾指定一個一致的文本標記,以此來結束輸入,任何字符串都可以作為文本標記
#wc<<EOF
> 1234
> 1234
> 1234
> EOF
3 3 15管道
將一個命令的輸出作為另一個命令的輸入可以使用重定向來實現,但很笨拙
/*rpm通過過Red Hat包管理系統對系統上安裝的軟件包進行管理,-qa將生成已安裝包的列表,結果輸出重定向到rpm.list,然後輸入重定向到sort,按字母順序進行排序*/
#rpm -qa>rpm.list
#sort<rpm.list
#more rpm.list
/*管道連接*/
#rpm -qa|sort|more|管道符號放在兩個命令之間,將一個命令的輸出重定向到另一個命令中,Linux實際上會同時運行這兩個命令,在第一個命令產生輸出的同時,輸出會被立即送給第二個命令。數據傳輸不會用到任何中間文件或緩衝區
數學運算
expr命令允許在命令行上處理數學表達式,但是特別笨拙
- 一些expr的命令操作符在shell中另有含義,比如
*,對於這些容易錯誤解釋的字符,需要使用轉義字符
#expr 5 \* 2
10- 要將一個數學算式的結果賦給一個變量,需要使用命令替換來獲取expr命令的輸出
result=$(expr 6 / 2)bash shell為了保持跟Bourne shell的兼容而包含了expr命令,但它同樣也提供了一種更簡單的方法來執行數學表達式
result=$[1+5]
使用美元符和方括號來將數學表達式圍起來,使用方括號就不用擔心shell會誤解符號不過bash shell數學運算符只支持整數運算,z shell可以支持浮點數算術運算
內建的bash計算器實際上是一種編程語言,它允許在命令行中輸入浮點表達式,然後解釋並計算該表達式,最後返回結果
bash計算器能夠識別:
- 數字(整數和浮點數)
- 變量(簡單變量和數組)
- 註釋(以#或C語言中的/* */開始的行)
- 表達式
- 編程語句(例如if-then語句)
- 函數
可以在shell提示符下通過bc命令訪問bash計算器,使用quit離開
浮點運算是由內建變量scale控制的,設置它來控制保留的小數位數
scale=4
3.44/5
.6880-q命令行選項可以不顯示bash計算器冗長的歡迎信息
bc支持變量,變量一旦被定義,就可以在bash計算器會話中使用該變量了。print語句允許打印變量和數字
#bc -q
var1=10-2
print var1
8在shell腳本中使用
/*編寫shell腳本*/
#!/bin/bash
var1=$(echo "scale=4; 3.44 / 5" | bc)
echo The answer is $var1
/*output*/
#./test
The answer is .6880如果是大量的運算,除了使用文件重定向來處理,也可以用更簡便的內聯輸入重定向
#!/bin/bash
var1=10.46
var2=43.67
var3=33.2
var4=71
var5=$(bc<<EOF
scale=4
a1=($var1*$var2)
b1=($var3*$var4)
a1+b1
EOF
)
echo The final answer for this megs is $var5
/*使用腳本,這個報錯應該就是警告性錯誤,反正腳本能運行,解決不了一點*/
#./test
./test: line 20: warning: here-document at line 14 delimited by end-of-file (wanted `EOF')
./test: line 18: warning: here-document at line 13 delimited by end-of-file (wanted `EOF')
(standard_in) 5: illegal character: O
(standard_in) 5: syntax error
The final answer for this megs is 2813.9882退出腳本
shell中運行的每個命令都使用退出狀態碼告訴shell它已經運行完畢。退出狀態碼是一個0~255的整數值,在命令結束運行時由命令傳給shell。可以捕獲這個值並在腳本中使用
Linux提供一個專門的變量$?來保存上個已執行命令的退出狀態碼
Linux退出狀態碼
0 命令成功結束
1 一般性未知錯誤
2 不適合的shell命令
126 命令不可執行
127 沒找到命令
128 無效的退出參數
128+x 與Linux信號x相關的嚴重錯誤
130 通過Ctrl+C終止的命令
255 正常範圍之外的退出狀態碼默認情況下,shell腳本會以腳本中的最後一個命令的退出狀態碼退出
exit命令允許在腳本結束時指定一個退出狀態碼,也可以使用變量
使用結構化命令
有一類命令會根據條件使腳本跳過某些命令。這樣的命令通常稱為結構化命令
if-then
if command
then
commands
#和代碼塊一樣,不是隻能一條語句
fi
#和cpp一樣,分號為結束,因此可以這樣寫
if command; then
command1; command2; fi會運行if後面的那個命令,如果該命令的退出狀態碼是0 ,then部分命令就被執行;如果該命令的退出狀態碼是其他值,then部分命令不執行。fi為if-then語句的結束
if-then-else
if command
then
commands
else
commands
fi
#變種if-elsegrep命令在/etc/passwd文件中查找某個用户名當前是否在系統上使用。如果有用户使用了那個登錄名,腳本會顯示文本信息並列出該用户HOME目錄的bash文件,否則顯示該用户在本系統上不存在
#!/bin/bash
user=xwj
if grep $user /etc/passwd
then
echo good very good
ls -a /home/$user/.b*
else
echo The user $user does not exist on this system
fiif怎麼可能沒有嵌套
!/bin/bash
tuser=NoSuchUser
if grep $tuser /etc/passwd
then #如果登錄名存在
echo "The user $user exists on this system."
else #如果登錄名不存在
echo "The user $user does not exist on this system."
if ls -d /home/$user/ #如果登錄名不存在,但是用户目錄存在
then
echo "However, $user has a directory."
fi
fielif其實就是變種if-else
if command
then
commands
elif command
# 如果elif後命令退出狀態碼為0.執行then部分,否則退出
then
commands
fi
#使用elif可以簡寫上面的嵌套,其實就只把else和if簡寫為elif
if grep $user /etc/passwd
then #如果登錄名存在
echo "The user $user exists on this system."
elif ls -d /home/$user #如果登錄名不存在,檢查目錄是否存在
then
echo "The user $user does not exist on this system."
echo "However, $user has a directory."
fi可以繼續將多個elif語句串起來,形成一個大的if-then-elif嵌套組合
if command
then
command
elif command
then
command
elif command
then
command
fitest命令
如果test命令中列出的條件成立, test命令就會退出並返回退出狀態碼0;如果條件不成立,test命令就會退出並返回非零的退出狀態碼
if test condition
#如果沒有condition,以非零狀態碼退出,執行else語句塊
then
commands
else
commands
fi
#可以使用test命令確定變量中是否有內容
if test $variable
#bash shell提供了另一種條件測試方法,無需聲明test命令
if [ condition ]
then
commands
fi
#方括號定義測試條件,注意括號內必須有空格test命令可以判斷三類條件:
- 數值比較
- 字符串比較
- 文件比較
數值比較
n1 -eq n2 #檢查n1是否與n2相等
n1 -ge n2 #檢查n1是否大於或等於n2
n1 -gt n2 #檢查n1是否大於n2
n1 -le n2 #檢查n1是否小於或等於n2
n1 -lt n2 #檢查n1是否小於n2
n1 -ne n2 #檢查n1是否不等於n2可以用在數字和變量上,是為真,否為假,注意bash shell只能處理整數,所以浮點數不能比較
字符串比較
str1 = str2 #檢查str1是否和str2相同
str1 != str2 #檢查str1是否和str2不同
str1 < str2 #檢查str1是否比str2小
str1 > str2 #檢查str1是否比str2大
-n str1 #檢查str1的長度是否非0
-z str1 #檢查str1的長度是否為0在比較字符串的相等性時,比較測試會將所有的標點和大小寫情況都考慮在內
大於號和小於號必須轉義,否則shell會把它們當作重定向符號,把字符串值當作文件名
if [$value1\>$value2]在比較測試中,大寫字母被認為是小於小寫字母的。但sort命令恰好相反。同樣的字符串放進文件中並用sort命令排序時,小寫字母會先出現。這是由各個命令使用的排序技術不同造成的。 比較測試中使用的是標準的ASCII順序,根據每個字符的ASCII數值來決定排序結果。sort命令使用的是系統的本地化語言設置中定義的排序順序。對於英語,本地化設置指定了在排序順序中小寫字母出現在大寫字母前
比較中,大寫小於小寫
sort中,大寫大於小寫
空的和未初始化的變量會對shell腳本測試造成災難性的影響。如果不是很確定一個變量的內容,最好在將其用於數值或字符串比較之前先通過-n或-z來測試一下變量是否含有值
文件比較
-d file #檢查file是否存在並是一個目錄
-e file #檢查file是否存在
-f file #檢查file是否存在並是一個文件
-r file #檢查file是否存在並可讀
-s file #檢查file是否存在並非空
-w file #檢查file是否存在並可寫
-x file #檢查file是否存在並可執行
-O file #檢查file是否存在並屬當前用户所有
-G file #檢查file是否存在並且默認組與當前用户相同
file1 -nt file2 #檢查file1是否比file2新
file1 -ot file2 #檢查file1是否比file2舊
#比較日期時應先確定文件是否存在用於比較文件路徑是相對你運行該腳本的目錄而言的。如果要檢查的文件已經移走,就會出現問題。是為真,否為假
可以使用&&或||來組合條件
- [ condition1 ] && [ condition2 ]
- [ condition1 ] || [ condition2 ]
if-then高級特性
test命令只能在比較中使用簡單的算術操作。雙括號命令提供了更多的數學符號
val++ #後增
val-- #後減
++val #先增
--val #先減
! #邏輯求反
~ #位求反
** #冪運算
<< #左位移
>> #右位移
& #位布爾和
| #位布爾或
&& #邏輯和
|| #邏輯或可以在if語句中用雙括號命令,也可以在腳本中的普通命令裏使用來賦值
((expression))
#expression可以是任意的數學賦值或比較表達式
if (( $val1 ** 2 > 90 ))
then
(( val2 = $val1 ** 2 ))
echo "The square of $val1 is $val2"
fi不需要將雙括號中表達式裏的大於號轉義,這是雙括號命令提供的另一個高級特性
雙方括號命令提供了針對字符串比較的高級特性,支持模式匹配
在模式匹配中,可以定義一個正則表達式來匹配字符串值
雙方括號在bash shell中工作良好。不過要小心,不是所有的shell都支持雙方括號
case命令
case variable in
pattern1 | pattern2) commands1;;
pattern3) commands2;;
*) default commands;;
esaccase命令會將指定的變量與不同模式進行比較。如果變量和模式是匹配的,那麼shell會執行為該模式指定的命令- 可以通過豎線操作符在一行中分隔出多個模式模式
- 星號會捕獲所有與已知模式不匹配的值
#!/bin/bash
case $USER in
rich | barbara)
echo "Welcome, $USER"
echo "Please enjoy your visit";;
testing)
echo "Special testing account";;
jessica)
echo "Do not forget to log off when you're done";;
*)
echo "Sorry, you are not allowed here";;
esaccase命令提供了一個更清晰的方法來為變量每個可能的值指定不同的選項
更多結構化命令
for命令
for var in list
do
commands
done在list參數中需要提供迭代中要用到的一系列值。可以通過幾種不同的方法指定列表中的值
在每次迭代中,變量var會包含列表中的當前值。第一次迭代會使用列表中的第一個值,第 二次迭代使用第二個值,以此類推,直到列表中的所有值都過一遍
讀取列表中的值
for test in Alabama Alaska Arizona Arkansas California Colorado
do
echo The next state is $test
done在最後一次迭代後,$test變量的值會在shell腳本的剩餘部分一直保持有效。它會一直保持最後一次迭代的值,除非修改了它
如果值中帶有單引號,有兩種辦法解決:
- 使用轉義字符(反斜線)來將單引號轉義
- 使用雙引號來定義用到單引號的值
for test in I don\'t know if "this'll" work
do
echo word:$test
donefor循環假定每個值都是用空格分割的。 如果有包含空格的數據值需要使用雙引號圈起來,在某個值兩邊使用雙引號時,shell並不會將雙引號當成值的一部分
從變量讀取列表
#!/bin/bash
list="Alabama Alaska Arizona Arkansas Colorado"
list=$list" Connecticut"#向list變量的列表添加了一個值
for state in $list
do
echo "Have you ever visited $state?"
done
#輸出結果
Have you ever visited Alabama?
Have you ever visited Alaska?
Have you ever visited Arizona?
Have you ever visited Arkansas?
Have you ever visited Colorado?
Have you ever visited Connecticut?從命令讀取值
可以用命令替換來執行任何能產生輸出的命令,然後在for命令中使用該命令的輸出
file="states"
for state in $(cat $file) #從文件讀取
#文件名中沒有加入路徑。這要求文件和腳本位於同一個目錄中。如果不是需要使用全路徑名
do
echo "Visit beautiful $state"
done更改字段分隔符
環境變量IFS定義bash shell用作字段分隔符的一系列字符
默認情況下,bash shell會將下列字符當作字段分隔符:
- 空格
- 製表符
- 換行符
在處理含有空格的數據時,可以在shell腳本中臨時更改IFS環境變量的值來限制被bash shell當作字段分隔符的字符
IFS=$'\n':;"
#將換行符、冒號、分號和雙引號作為字段分隔符用通配符讀取目錄
可以用for命令來自動遍歷目錄中的文件。進行此操作時,必須在文件名或路徑名中使用通配符。它會強制shell使用文件擴展匹配。文件擴展匹配是生成匹配指定通配符的文件名或路徑名的過程
for file in /home/rich/test/*
do
if [ -d "$file" ]#如果是目錄
then
echo "$file is a directory"
elif [ -f "$file" ]#如果是文件
then
echo "$file is a file"
fi
done在Linux中,目錄名和文件名中包含空格是合法的。要適應這種情況,應該將$file變量用雙引號圈起來。如果不這麼做,遇到含有空格的目錄名或文件名時就會有錯誤產生
可以在數據列表中放入任何東西。即使文件或目錄不存在,for語句也會嘗試處理列表中的內容,所以最好先確定文件或目錄是否存在
C語言風格的for命令
bash shell也支持一種for循環,它看起來跟C語言風格的for循環類似,但有一些細微的不同
for (( variable assignment ; condition ; iteration process ))有些部分並沒有遵循bash shell標準的for命令:
- 變量賦值可以有空格
- 條件中的變量不以美元符開頭
- 迭代過程的算式未用expr命令格式
for (( i=1; i <= 10; i++ ))
do
echo "The next number is $i"
doneC語言風格的for命令也允許為迭代使用多個變量。循環會單獨處理每個變量,可以為每個變量定義不同的迭代過程,但只能在for循環中定義一種條件
for ((a=1,b=10;a<=10;a++,b--))
do
echo "$a-$b"
donewhile命令
while test command
do
other commands
donewhile命令的關鍵在於所指定的test command的退出狀態碼必須隨着循環中運行的命令而改變。如果退出狀態碼不發生變化, while循環就將一直不停地進行下去
var1=10
while [ $var1 -gt 0 ]
do
echo $var1
var1=$[ $var1 - 1 ]
donewhile命令允許在while語句行定義多個測試命令。只有最後一個測試命令的退出狀態碼會被用來決定什麼時候結束循環
var1=10
while echo $var1#顯示值
[ $var1 -ge 0 ]#判斷值
do
echo "This is inside the loop"
var1=$[ $var1 - 1 ]
done在含有多個命令的while語句中,在每次迭代中所有的測試命令都會被執行,包括測試命令失敗的最後一次迭代,注意每個測試命令都出現在單獨的一行上
until命令
until命令要求指定一個通常返回非零退出狀態碼的測試命令。只測試命令的退出狀態碼不為0,bash shell才會執行循環中列出的命令。 一旦測試命令返回退出狀態碼0,循環就結束
until test commands
do
other commands
done可以在until命令語句中放入多個測試命令。只有最後一個命令的退出狀態碼決定了bash shell是否執行已定義的other commands
var1=100
until echo $var1
[ $var1 -eq 0 ]
do
echo Inside the loop: $var1
var1=$[ $var1 - 25 ]
done嵌套循環
循環語句可以在循環內使用任意類型的命令,包括其他循環命令,這種循環叫作嵌套循環nested loop
注意在使用嵌套循環時是在迭代中使用迭代,與命令運行的次數是乘積關係。不注意這點的話,有可能會在腳本中造成問題
while [ $var1 -ge 0 ]
do
echo "Outer loop: $var1"
for (( var2 = 1; $var2 < 3; var2++ ))
do
var3=$[ $var1 * $var2 ]
echo " Inner loop: $var1 * $var2 = $var3"
done
var1=$[ $var1 - 1 ]
done循環處理文件數據
需要結合使用嵌套循環和修改IFS環境變量兩種方法
IFS.OLD=$IFS
IFS=$'\n'
for entry in $(cat /etc/passwd)
do
echo "Values in $entry –"
IFS=:
for value in $entry
do
echo " $value"
done
done使用了兩個不同的IFS值來解析數據。第一個IFS值解析出/etc/passwd文件中的單獨的行。內部for循環接着將IFS的值修改為冒號,允許從/etc/passwd的行中解析出單獨的值,輸出如下:
Values in rich:x:501:501:Rich Blum:/home/rich:/bin/bash -
rich
x
501
501
Rich Blum
/home/rich
/bin/bash
Values in katie:x:502:502:Katie Blum:/home/katie:/bin/bash -
katie
x
506
509
Katie Blum
/home/katie
/bin/bash控制循環
break命令
可以用break命令來退出任意類型的循環
#跳出單個循環
for var1 in 1 2 3 4 5 6 7 8 9 10
do
if [ $var1 -eq 5 ]
then
break
fi
echo "Iteration number: $var1"
done
#在處理多個循環時,終止所在的最內層的循環
for (( a = 1; a < 4; a++ ))
do
echo "Outer loop: $a"
for (( b = 1; b < 100; b++ ))
do
if [ $b -eq 5 ]
then
break
fi
echo " Inner loop: $b"
done
done
#跳出外部循環
#break命令接受單個命令行參數值:break n; n指定要跳出的循環層級
for (( a = 1; a < 4; a++ ))
do
echo "Outer loop: $a"
for (( b = 1; b < 100; b++ ))
do
if [ $b -gt 4 ]
then
break 2
fi
echo " Inner loop: $b"
done
donecontinue命令
continue命令可以提前中止某次循環中的命令,但並不會完全終止整個循環
for (( var1 = 1; var1 < 15; var1++ ))
do
if [ $var1 -gt 5 ] && [ $var1 -lt 10 ]
then
continue
fi
echo "Iteration number: $var1"
done
#錯誤示例
var1=0
while echo "while iteration: $var1"
[ $var1 -lt 15 ]
do
if [ $var1 -gt 5 ] && [ $var1 -lt 10 ]
then
continue
#當shell執行continue命令時,它跳過了while循環中餘下的命令,因此無法遞增,剩下的變量值不會改變
fi
echo " Inside iteration number: $var1"
var1=$[ $var1 + 1 ]
done
#continue命令也允許通過命令行參數指定要繼續執行哪一級循環 continue n
#n定義了要繼續的循環層級
for (( a = 1; a <= 5; a++ ))
do
echo "Iteration $a:"
for (( b = 1; b < 3; b++ ))
do
if [ $a -gt 2 ] && [ $a -lt 4 ]
then
continue 2
fi
var3=$[ $a * $b ]
echo " The result of $a * $b is $var3"
done
done處理循環的輸出
在shell腳本中,可以對循環的輸出使用管道或進行重定向。可以通過在done命令之後添加一個處理命令來實現
for file in /home/rich/*
do
if [ -d "$file" ]
then
echo "$file is a directory"
elif
echo "$file is a file"
fi
done > output.txt
#將循環的結果管接給另一個命令
for state in "North Dakota" Connecticut Illinois Alabama Tennessee
do
echo "$state is the next place to go"
done | sort
echo "This completes our travels"查找可執行文件
當從命令行中運行一個程序的時候,Linux系統會搜索一系列目錄來查找對應的文件。這些目錄被定義在環境變量PATH中
#首先創建一個for循環,對環境變量PATH中的目錄進行迭代
#設置IFS
IFS=:
for folder in $PATH
do
echo "$folder:"
#使用另一個for循環來迭代特定目錄中的所有文件
for file in $folder/*
do
#最後檢查各個文件是否具有可執行權限
if [ -x $file ]
then
echo " $file"
fi
done
done創建多個用户賬户
不用為每個需要創建的新用户賬户手動輸入useradd命令,而是可以將需要添加的新用户賬户放在一個文本文件中,然後創建一個簡單的腳本進行處理
文本文件的格式如下: userid,user name 第一個條目是為新用户賬户所選用的用户ID。第二個條目是用户的全名。兩個值之間使用逗號分隔,這樣就形成了一種名為逗號分隔值的文件格式
#將IFS分隔符設置成逗號,然後使用read命令讀取文件中的各行
#read命令會自動讀取.csv文本文件的下一行內容,所以不需要專門再寫一個循環來處理。當read命令返回FALSE也就是讀取完整個文件時,while命令就會退出
input="users.csv"
while IFS=',' read -r userid name
do
echo "adding $userid"
useradd -c "$name" -m $userid
done < "$input"
#$input變量指向數據文件處理用户輸入
向shell腳本傳遞數據的最基本方法是使用命令行參數。命令行參數允許在運行腳本時向命令行添加數據
讀取參數
bash shell會將一些稱為位置參數的特殊變量分配給輸入到命令行中的所有參數。這也包括shell所執行的腳本名稱
位置參數變量是標準的數字:$0是程序名,$1是第一個參數,$2是第二個參數,依次類推,直到第九個參數$9
factorial=1
for (( number = 1; number <= $1 ; number++ ))
do
factorial=$[ $factorial * $number ]
done
echo The factorial of $1 is $factorial
#輸出
The factorial of 5 is 120
#如果需要輸入更多的命令行參數,則每個參數都必須用空格分開
#也可以在命令行上用文本字符串,如果字符串含空格,需要用引號,單雙均可
# ./test "Rich Blum"
#將文本字符串作為參數傳遞時,引號並非數據的一部分。它們只是表明數據的起止位置如果腳本需要的命令行參數不止9個,在第9個變量之後,在變量數字周圍加上花括號,比如${10}
讀取腳本名
可以用$0參數獲取shell在命令行啓動的腳本名
當傳給$0變量的實際字符串不僅僅是腳本名,而是完整的腳本路徑時, 變量$0就會使用整個路徑
#basename命令會返回不包含路徑的腳本名
name=$(basename $0)
echo
echo The script name is: $name
#bash /home/Christine/test5b.sh
#輸出
The script name is: test5b.sh可以用這種方法來編寫基於腳本名執行不同功能的腳本
name=$(basename $0)
if [ $name = "addem" ]
then
total=$[ $1 + $2 ]
elif [ $name = "multem" ]
then
total=$[ $1 * $2 ]
fi
echo
echo The calculated value is $total
#./addem 2 5
The calculated value is 7
#./multem 2 5
The calculated value is 10從腳本中創建了兩個不同的文件名,在兩種情況下都會先獲得腳本的基本名稱,然後根據值執行相應的功能
測試參數
當腳本認為參數變量中會有數據而實際上並沒有時,腳本很有可能會產生錯誤消息。這種寫腳本的方法並不可取。在使用參數前一定要檢查其中是否存在數據
所有編程語言都大同小異,思想是幾乎一致的,只是實現方法和細節有所不同
if [ -n "$1" ]#檢查參數長度是否非零
then
echo Hello $1, glad to meet you.
else
echo "Sorry, you did not identify yourself. "
fi特殊參數變量
參數統計
$#含有腳本運行時攜帶的命令行參數的個數,可以在腳本中任何地方使用這個特殊變量,和普通變量一樣
if [ $# -ne 2 ]
then
echo#輸出空行
echo Usage: test a b
echo
else
total=$[ $1 + $2 ]
echo
echo The total is $total
echo
fiif-then語句用-ne測試命令行參數數量。如果參數數量不對,會顯示一條錯誤消息告知腳本的正確用法
可以使用${!#}來獲取最後一個命令行參數變量,當命令行上沒有任何參數時,,$#的值為0,但${!#}變量會返回命令行用到的腳本名
params=$#
echo
echo The last parameter is $params
echo The last parameter is ${!#}
#bash test
The last parameter is 0
The last parameter is test抓取所有的數據
$*變量會將命令行上提供的所有參數當作一個單詞保存,這個單詞包含了命令行中出現的每一個參數值,將這些參數視為一個整體$@變量會將命令行上提供的所有參數當作同一字符串中的多個獨立的單詞,能夠遍歷所有的參數值,得到每個參數
count=1
for param in "$*"
do
echo "\$* Parameter #$count = $param"
count=$[ $count + 1 ]
done
echo
count=1
for param in "$@"
do
echo "\$@ Parameter #$count = $param"
count=$[ $count + 1 ]
done
#輸出
$* Parameter #1 = rich barbara katie jessica
$@ Parameter #1 = rich
$@ Parameter #2 = barbara
$@ Parameter #3 = katie
$@ Parameter #4 = jessica$*變量會將所有參數當成單個參數,而$@變量會單獨處理每個參數
移動變量
使用shift命令時,默認情況下它會將每個參數變量向左移動一個位置。所以變量$3的值會移到$2中,變量$2的值會移到$1中,而變量$1的值則會被刪除(變量$0的值,也就是程序名不會改變)
這是遍歷命令行參數的另一個好方法,尤其是在不知道到底有多少參數時。可以只操作第一個參數,移動參數,然後繼續操作第一個參數
count=1
while [ -n "$1" ]#當第一個參數的長度為零時循環結束
do
echo "Parameter #$count = $1"
count=$[ $count + 1 ]
shift#將所有參數左移一位
done
#輸出
Parameter #1 = rich
Parameter #2 = barbara
Parameter #3 = katie
Parameter #4 = jessica
#可以一次性移動多個位置,只需給shift命令提供一個參數,指明要移動的位置數
shift 2
#移動2位通過使用shift命令的參數,就可以輕鬆地跳過不需要的參數
處理選項
查找選項
選項是跟在單破折線後面的單個字母,它能改變命令的行為
while [ -n "$1" ]#輸入長度是否非零
do
case "$1" in #case語句會檢查參數是不是有效選項
-a) echo "Found the -a option" ;;
-b) echo "Found the -b option" ;;
-c) echo "Found the -c option" ;;
*) echo "$1 is not an option" ;;
esac
shift #位置移動,檢查下一個參數
done分離參數和選項
如果想在shell腳本中同時使用選項和參數,Linux的方法是使用特殊字符雙破折線--來表明選項列表結束,在雙破折號之後,剩下的命令行參數就會當作選項
while [ -n "$1" ]
do
case "$1" in
-a) echo "Found the -a option" ;;
-b) echo "Found the -b option";;
-c) echo "Found the -c option" ;;
--) shift #遇到雙破折線,移出參數變量,結束檢查選項的循環
break ;;
*) echo "$1 is not an option";;
esac
shift #無論匹配哪個選項,都左移一位,以此循環繼續處理下一個參數
done
count=1
for param in $@
do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
done處理帶值的選項
有些選項會帶上一個額外的參數值,當命令行選項要求額外的參數時,腳本必須能檢測到並正確處理,下面是如何處理的例子:
while [ -n "$1" ]
do
case "$1" in
-a) echo "Found the -a option";;
-b) param="$2"
echo "Found the -b option, with parameter value $param"
shift ;;
#b選項需要一個額外的參數值,由於要處理的參數是$1,額外的參數值就應該位於$2
#因為所有的參數在處理完之後都會被移出,只要將參數值從$2變量中提取出來就可以
#因為這個選項佔用了兩個參數位,所以需要移動兩個位置
-c) echo "Found the -c option";;
--) shift
break ;;
*) echo "$1 is not an option";;
esac
shift
done
count=1
for param in "$@"
do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
donegetopt命令
getopt命令可以接受一系列任意形式的命令行選項和參數,並自動將它們轉換成適當的格式
#列出要在腳本中用到的每個命令行選項字母
#然後在每個需要參數值的選項字母后加一個冒號
getopt ab:cd -a -b test1 -cd test2 test3
定義了四個有效選項字母:a、b、c和d,b選項需要一個參數值
當getopt命令運行時,它會檢查提供的參數列表(-a -b test1 -cd
test2 test3),並基於提供的optstring進行解析
它會自動將-cd選項分成兩個單獨的選項,並插入雙破折線來分隔行中的額外參數可以在腳本中使用getopt來格式化腳本所攜帶的任何命令行選項或參數,方法是用getopt命令生成的格式化後的版本來替換已有的命令行選項和參數。用set命令能夠做到
set命令能夠處理shell中的各種變量。 set命令的選項之一是雙破折線--,它會將命令行參數替換成set命令的命令行值
set -- $(getopt -q ab:cd "$@")
#-q選項讓getopt在遇到錯誤時安靜地退出,而不是顯示錯誤信息。ab:cd 是有效的選項,其中a和b是需要參數的選項,而c和d是不需要參數的選項。"$@"表示所有的命令行參數
echo
while [ -n "$1" ]
do
case "$1" in
-a) echo "Found the -a option" ;;
-b) param="$2"
echo "Found the -b option, with parameter value $param"
shift ;;
-c) echo "Found the -c option" ;;
--) shift
break ;;
*) echo "$1 is not an option";;
esac
shift
done
count=1
for param in "$@"
do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
done
#./test -a -b test1 -cd test2 test3 test4
#輸出
Found the -a option
Found the -b option, with parameter value 'test1'
Found the -c option
Parameter #1: 'test2'
Parameter #2: 'test3'
Parameter #3: 'test4'getopt命令並不擅長處理帶空格和引號的參數值。它會將空格當作參數分隔符,而不是根據雙引號將二者當作一個參數
選項標準化
有些字母選項在Linux裏已經擁有了某種程度的標準含義。如果能在shell腳本中支持這些選項,腳本看起來能更友好
常用的Linux命令選項
-a 顯示所有對象
-c 生成一個計數
-d 指定一個目錄
-e 擴展一個對象
-f 指定讀入數據的文件
-h 顯示命令的幫助信息
-i 忽略文本大小寫
-l 產生輸出的長格式版本
-n 使用非交互模式(批處理)
-o 將所有輸出重定向到的指定的輸出文件
-q 以安靜模式運行
-r 遞歸地處理目錄和文件
-s 以安靜模式運行
-v 生成詳細輸出
-x 排除某個對象
-y 對所有問題回答yes獲得用户輸入
read命令從標準輸入或另一個文件描述符中接受輸入,收到輸入後,read命令會將數據放進一個變量
#read [選項] [變量名]
-p:後面跟提示信息,即在輸入前打印提示信息
-t:後面跟一個秒數,表示等待用户輸入的時間
-n:後面跟一個字符數,表示只接受指定數量的字符
-s:隱藏輸入內容,適用於機密信息的輸入
#read命令包含了-p選項,允許直接在read命令行指定提示符echo -n "Enter your name: "
read name
echo "Hello $name, welcome to my program. "
#測試
Enter your name: Rich Blum
Hello Rich Blum, welcome to my program.
#read命令會將提示符後輸入的所有數據分配給單個變量,可以指定多個變量。輸入的每個數據值都會分配給變量列表中的下一個變量。如果變量數量不夠,剩下的數據就全部分配給最後一個變量
read -p "Enter your name: " first last
echo "Checking data for $last, $first…"
#測試
Enter your name: Rich Blum
Checking data for Blum, Rich...
#如果在read命令行中不指定變量,read命令會將它收到的任何數據都放進特殊環境變量REPLY中
read -p "Enter your name: "
echo Hello $REPLY, welcome to my program.
#測試
Enter your name: Christine
Hello Christine, welcome to my program.REPLY環境變量會保存輸入的所有數據,可以在shell腳本中像其他變量一樣使用
超時
使用read -t來指定命令等待輸入秒數,當計時器過期後,read命令會返回一個非零退出狀態碼
從文件中讀取
可以用read命令來讀取Linux系統上文件裏保存的數據。每次調用read命令,它都會從文件中讀取一行文本。當文件中再沒有內容時,read命令會退出並返回非零退出狀態碼
將文件中的數據傳給read命令最常見的方法是對文件使用cat命令,將結果通過管道直接傳給含有read命令的while命令
count=1
cat test | while read line
do
echo "Line $count: $line"
count=$[ $count + 1]
done
echo "Finished processing the file"呈現數據
Linux系統將每個對象當作文件處理。這包括輸入和輸出進程。Linux用文件描述符來標識每個文件對象,文件描述符是一個非負整數,可以唯一標識會話中打開的文件。每個進程一次最多可以有九個文件描述符,bash shell保留了前三個 件描述符0、1和2
0 STDIN 標準輸入
1 STDOUT 標準輸出
2 STDERR 標準錯誤STDIN文件描述符代表shell的標準輸入。對終端界面來説,標準輸入是鍵盤- 在使用輸入重定向符號時,Linux會用重定向指定的文件來替換標準輸入文件描述符。 它會讀取文件並提取數據
cat < testfile
#從文件讀取然後輸出
#可以從命令行讀取,使用內聯輸入重定向<<STDOUT文件描述符代表shell的標準輸出。在終端界面上,標準輸出就是終端顯示器
ls -l > test2
#將輸出重定向到文件
#也可以將數據追加到某個文件。這可以用>>符號來完成- shell對於錯誤消息的處理是跟普通輸出分開的,不可以使用普通輸出來顯示
shell通過特殊的STDERR文件描述符來處理錯誤消息。STDERR文件描述符代表shell的標準錯誤輸出。shell或shell中運行的程序和腳本出錯時生成的錯誤消息都會發送到這個位置
默認情況下,STDERR文件描述符和STDOUT文件描述符指向同樣的地方(儘管分配給它們的文件描述符值不同),也就是説默認情況下,錯誤消息也會輸出到顯示器輸出中
重定向錯誤
ls -al badfile > test
#依舊輸出在顯示器
ls -al badfile 2> test
#STDERR文件描述符為2。可以選擇只重定向錯誤消息,將該文件描述符值放在重定向符號前,不能有空格
#現在運行該命令,錯誤信息不會顯示在屏幕上
ls -al test badtest test2 2> "error log"
#查看3個目錄或文件,但只會輸出存在的
#不存在的錯誤消息重定向到error log文件
同時重定向數據和錯誤
ls -al test1 test2 test3 2> "error log" 1> data
使用&>符時,命令生成的所有輸出都會發送到同一位置,包括數據和錯誤
ls -al test1 test2 &> test
#不過相較於標準輸出,bashshell自動賦予了錯誤消息更高的優先級,錯誤信息優先顯示腳本中重定向輸出和輸入
可以在腳本中用STDOUT和STDERR文件描述符以在多個位置生成輸出,只要簡單地重定向相應的文件描述符就行
臨時重定向
#在重定向到文件描述符時,必須在文件描述符數字之前加一個&
echo "This is an error" >&2
echo "This is normal output"
如果像平常一樣運行這個腳本,沒有區別
#./test
This is an error
This is normal output
#默認情況下,Linux會將STDERR導向STDOUT
但是如果在運行腳本時重定向了STDERR,腳本中所有導向STDERR的文本都會被重定向
#./test 2> log
This is normal output
#cat log
This is an error永久重定向
如果腳本中有大量數據需要重定向,那重定向每個echo語句就會很煩瑣
可以用exec命令告訴shell在腳本執行期間重定向某個特定文件描述符
exec命令會啓動一個新shell並將文件描述符重定向到文件
exec 2>testerror #錯誤信息重定向
echo "This is the start of the script" #正常信息仍默認顯示屏幕
echo "now redirecting all output to another location"
exec 1>testout #正常信息重定向
#在testout內
echo "This output should go to the testout file"
#在testerror內
echo "but this should go to the testerror file" >&2重定向輸入
exec 0< testfile
count=1
while read line
#每次循環時,它從當前文件描述符取一行數據,並將其賦值給變量line
do
echo "Line #$count: $line"
count=$[ $count + 1 ]
done創建自己的重定向
在腳本中重定向輸入和輸出時,並不侷限於這3個默認的文件描述符。在shell中最多可以有9個打開的文件描述符,其他6個從3~8的文件描述符均可用作輸入或輸出重定向,可以將這些文件描述符中的任意一個分配給文件,然後在腳本中使用它們
創建輸出文件描述符
可以用exec命令來給輸出分配文件描述符。和標準的文件描述符一樣,一旦將另一個文件描述符分配給一個文件,這個重定向就會一直有效,直到重新分配
exec 3>>testout #追加數據到文件
echo "This should display on the monitor"
echo "and this should be stored in the file" >&3 #在testout內
echo "Then this should be back on the monitor重定向文件描述符
exec 3>&1 #文件描述符3重定向到文件描述符1也就是STDOUT
exec 1>test14out #STDOUT重定向到文件
#但是文件描述符3仍然指向STDOUT原來的位置,也就是顯示器
#此時將輸出數據發送給文件描述符3,它仍然會出現在顯示器上,儘管STDOUT已經被重定向
echo "This should store in the output file"
echo "along with this line."
exec 1>&3 #將STDOUT重定向到文件描述符3的當前位置,也就是顯示器
echo "Now things should be back to normal"創建輸入文件描述符
用和重定向輸出文件描述符同樣的辦法重定向輸入文件描述符
exec 6<&0#保存STDIN位置
exec 0<testfile#重定向到文件
count=1
while read line
do
echo "Line #$count:$line"
count=$[$count+1]
done
exec 0<&6#讀取所有行之後重定向到STDIN
read -p "Are you done now?" answer
case $answer in
y|Y) echo "Goodbye!";;
n|N) echo "Sorry.this is the end.";;
*) echo "please input y or n";;
esac創建讀寫文件描述符
可以打開單個文件描述符來作為輸入和輸出。可以用同一個文件描述符對同一個文件進行讀寫。 不過用這種方法時要特別小心。由於是對同一個文件進行數據讀寫,shell會維護一個內部指針,指明在文件中的當前位置。任何讀或寫都會從文件指針上次的位置開始
exec 3<> testfile#重定向讀寫
read line <&3 #讀取第一行
echo "Read: $line"
echo "This is a test line" >>&3當腳本向文件中寫入數據時,它會從文件指針所處的位置開始。read命令讀取了第一行數據,所以它使得文件指針指向了第二行數據的第一個字符。在echo語句將數據輸出到文件時, 它會將數據放在文件指針的當前位置,覆蓋了該位置的已有數據
關閉文件描述符
如果創建了新的輸入或輸出文件描述符,shell會在腳本退出時自動關閉它們。有些情況下,需要在腳本結束前手動關閉文件描述符
#要關閉文件描述符,將它重定向到特殊符號&-
exec 3> testfile
echo "This is a test line of data" >&3
exec 3>&-
echo "This won't work" >&3 #error
#一旦關閉了文件描述符,就不能在腳本中向它寫入任何數據,否則shell會生成錯誤消息
exec 3> testfile
echo '"This will be bad"'
#如果隨後在腳本中打開了同一個輸出文件,shell會用一個新文件來替換已有文件。這意味着如果輸出數據,它就會覆蓋已有文件
#cat testfile
"This will be bad"列出打開的文件描述符
lsof命令會列出整個Linux系統打開的所有文件描述符。這是個有爭議的功能,因為它會向非系統管理員用户提供Linux系統的信息。鑑於此,許多Linux系統隱藏了該命令,這樣用户就不會一不小心就發現
在很多Linux系統中,lsof命令位於/usr/sbin目錄。要想以普通用户賬户來運行它,必須通過全路徑名來引用
具體使用可必應
阻止命令輸出
這將腳本作為後台進程運行時很常見
可以將STDERR重定向到一個叫作null文件的特殊文件。null文件跟它的名字很像,文件裏什麼都沒有,shell輸出到null文件的任何數據都不會保存
在Linux系統上null文件的標準位置是/dev/nul,重定向到該位置的任何數據都會被丟掉,不會顯示
ls -al > /dev/null這是避免出現錯誤消息,也無需保存它們的一個常用方法
也可以在輸入重定向中將/dev/null作為輸入文件,通常用它來快速清除現有文件中的數據,而不用先刪除文件再重新創建
cat /dev/null > testfile文件testfile仍然存在系統上,但現在它是空文件。這是清除日誌文件的一個常用方法,因為日誌文件必須時刻準備等待應用程序操作
創建臨時文件
Linux專門使用/tmp目錄來存放不需要永久保留的文件,大多數Linux發行版配置了系統在啓動時自動刪除/tmp目錄的所有文件
系統上的任何用户賬户都有權限在讀寫/tmp目錄中的文件
mktemp命令可以在/tmp目錄中創建一個唯一的臨時文件。shell會創建這個文件,但不用默認的umask值
它會將文件的讀和寫權限分配給文件的屬主,並將你設成文件的屬主。一旦創建了文件,你就在腳本中有了完整的讀寫權限, 除root外其他人沒法訪問它
創建本地臨時文件
默認情況下,mktemp會在本地目錄中創建一個文件。要用mktemp命令在本地目錄中創建一 個臨時文件,只要指定一個文件名模板即可,模板可以包含任意文本文件名,在文件名末尾加上6個X就行
mktemp testing.XXXXXX
ls -al testing*mktemp命令會用6個字符碼替換這6個X,從而保證文件名在目錄中是唯一的
mktemp命令的輸出是它所創建的文件的名字。在腳本中使用mktemp命令時,可能要將文件名保存到變量中,這樣就能在後面的腳本中引用
#命令替換,執行括號中的命令,並將命令的輸出賦值給變量tempfile
tempfile=$(mktemp test19.XXXXXX)
#重定向3到指定文件
exec 3>$tempfile
#輸入信息
echo "This is the first line" >&3
#重定向到&-就是關閉它
exec 3>&-
#刪除指定文件,-f表示不用提示強制刪除,將2標準錯誤重定向到null
rm -f $tempfile 2> /dev/null在/tmp目錄創建臨時文件
-t選項會強制mktemp命令來在系統的臨時目錄來創建該文件。在用這個特性時,mktemp命令會返回用來創建臨時文件的全路徑,而不是隻有文件名
由於mktemp命令返回了全路徑名,因此可以在Linux系統上的任何目錄下引用該臨時文件,不管臨時目錄在哪裏
tempfile=$(mktemp -t tmp.XXXXXX)
echo "This is a test file." > $tempfile
#>>是追加
echo "This is the second line of the test." >> $tempfile
echo "The temp file is located at: $tempfile"
rm -f $tempfile創建臨時目錄
-d選項告訴mktemp命令來創建一個臨時目錄而不是臨時文件
tempdir=$(mktemp -d dir.XXXXXX)
cd $tempdir
tempfile1=$(mktemp temp.XXXXXX)
tempfile2=$(mktemp temp.XXXXXX)
exec 7> $tempfile1
exec 8> $tempfile2在當前目錄創建了一個目錄,然後用cd命令進入該目錄,並創建了兩個臨時文件,之後這兩個臨時文件被分配給文件描述符
記錄消息
將輸出同時發送到顯示器和日誌文件,不需要輸出重定向兩次,只要用特殊的tee命令即可
tee命令相當於管道的一個T型接頭,它將STDIN過來的數據同時發往兩處。一處是STDOUT,另一處是tee命令行所指定的文件名
tee filename
#tee會重定向來自STDIN的數據,可以用它配合管道命令來重定向命令輸出
date | tee testfile輸出出現在了STDOUT中,同時也寫入了指定的文件中,默認情況下,tee命令會在每次使用時覆蓋輸出文件內容。如果想將數據追加到文件中,必須用-a選項
echo "This is the start of the test" | tee $tempfile
echo "This is the second line of the test" | tee -a $tempfile
echo "This is the end of the test" | tee -a $tempfile讀取.csv格式的數據文件,輸出INSERT語句來將數據插入數據庫
#!/bin/bash
#定義變量並賦值
outfile='members.sql'
#設置內部字段分隔符IFS為逗號,read語句使用IFS字符解析讀入的文本
IFS=','
#while循環,使用read從輸入中讀取一行,將該行的前6個字段分別賦值給這些變量
while read lname fname address city state zip
do
#將cat命令的輸出追加到members.sql,<<EOF是here document的開始,單獨的EOF是結束,這部分內容將用作cat命令的輸入
cat >> $outfile << EOF
INSERT INTO members (lname,fname,address,city,state,zip) VALUES
('$lname', '$fname', '$address', '$city', '$state', '$zip');
#here document結構的結束,需要定義多行輸入或輸出時,command<<EOF ... EOF
EOF
#while循環的結束,$(1)是一個特殊的shell變量,代表腳本的第一個參數。這意味着當你運行這個腳本並傳遞一個文件名作為參數時,該腳本會從這個文件中讀取數據
done < ${1}shell腳本使用命令行參數指定待讀取的.csv文件。.csv格式用於從電子表格中導出數據,所以可以把數據庫數據放入電子表格中,把電子表格保存成.csv格式,讀取文件,然後創建INSERT語句將數據插入MySQL數據庫
控制腳本
Linux利用信號與運行在系統中的進程進行通信,可以通過對腳本進行編程,使其在收到特定信號時執行某些命令,從而控制shell腳本的操作
1 SIGHUP 掛起進程
2 SIGINT 終止進程
3 SIGQUIT 停止進程
9 SIGKILL 無條件終止進程
15 SIGTERM 儘可能終止進程
17 SIGSTOP 無條件停止進程,但不是終止進程
18 SIGTSTP 停止或暫停進程,但不終止進程
19 SIGCONT 繼續運行停止的進程默認情況bash shell會忽略收到的任何SIGQUIT(3)和SIGTERM(5)信號,正因為這樣, 交互式shell才不會被意外終止。但bash shell會處理收到的SIGHUP(1)和SIGINT(2)信號
如果收到SIGHUP信號,比如離開一個交互式shell,它就會退出,但在退出之前會將SIGHUP信號傳給所有由該shell所啓動的進程,包括正在運行時的shell腳本
通過SIGINT信號可以中斷shell,Linux內核會停止為shell分配CPU處理時間,這種情況發生時,shell會將SIGINT信號傳給所有由它啓動的進程
由於shell會將這些信號傳給shell腳本程序來處理。而shell腳本的默認行為是忽略這些信號。它們可能會不利於腳本的運行。要避免這種情況,需要在腳本中加入識別信號的代碼,並執行命令來處理信號
生成信號
- 終止程序:
Ctrl+C組合鍵會生成SIGINT信號,並將其發送給當前在shell中運行的所有進程 - 停止程序:
Ctrl+Z組合鍵會生成一個SIGTSTP信號,停止shell中運行的任何進程。stopping進程和terminating進程不同:停止進程會讓程序繼續保留在內存中,並能從上次停止的位置繼續運行
sleep 100
^Z
#shell會通知進程已經被停止
#方括號中的數字是shell分配的作業號,shell中運行的每個進程稱為作業,併為每個作業分配唯一的作業號
[1]+ Stopped sleep 100
#如果shell會話中有一個已停止的作業,在退出shell時,bash會提醒你
exit
There are stopped jobs.
#ps查看已停止的作業,停止作業的狀態是T,説明命令要麼被跟蹤,要麼被停止
ps -i
#在有已停止作業存在的情況下,如果想退出shell,重複輸入一次exit命令即可
#也可以利用已停止作業的PID來使用Kill命令終止
kill -9 2466捕獲信號
也可以不忽略信號,在信號出現時捕獲它們並執行其他命令
trap命令允許指定shell腳本要監看並從shell中攔截的Linux信號。如果腳本收到了trap命令中列出的信號,該信號不再由shell處理,而是交由本地處理
trap command signals在trap命令行上列出想要shell執行的命令,以及一組用空格分開的待捕獲的信號,可以用數值或信號名來指定信號
#當捕獲到SINGINT信號不會終止腳本的執行,而是執行命令
trap "echo ' Sorry! I have trapped Ctrl-C'" SIGINT
count=1
#count是否小於等於10
while [ $count -le 10 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done捕獲腳本退出
也可以在shell腳本退出時進行捕獲,只需在trap命令後加上EXIT命令
#正常或非正常退出腳本都能夠捕獲EXIT,因此都會執行命令
trap "echo Goodbye" EXIT修改或移除捕獲
在腳本中的不同位置進行不同的捕獲處理,只需重新使用帶有新選項的trap命令
trap "echo ' Sorry... Ctrl-C is trapped.'" SIGINT
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#重新定義trap
trap "echo ' I modified the trap!'" SIGINT
count=1
while [ $count -le 5 ]
do
echo "Second Loop #$count"
sleep 1
count=$[ $count + 1 ]
done也可以刪除已設置好的捕獲。只需在trap命令與希望恢復默認行為的信號列表之間加上兩個破折號
trap "echo ' Sorry... Ctrl-C is trapped.'" SIGINT
#
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#移除為SIGINT設置的捕獲
trap -- SIGINT
echo "I just removed the trap"也可以在trap命令後使用單破折號來恢復信號的默認行為。單破折號和雙破折號都可以正常發揮作用
移除信號捕獲後腳本按照默認行為來處理SIGINT信號,在捕獲移除之前的信號按之前trap命令中的設置進行處理
以後台模式運行腳本
只需在執行命令後加&
./script &
[1] 3231
#會顯示作業號和進程ID將命令作為系統中的一個獨立的後台進程運行,當後台進程結束時,它會在終端上顯示出一條消息表明作業號、作業狀態、啓動作業的命令
[1] Done ./script當後台進程運行時,它仍然會使用終端顯示器來顯示STDOUT和STDERR消息,在顯示輸出的同時仍然可以運行命令,但會造成腳本輸入輸出和命令輸出的混亂,最好還是將後台運行腳本的STDOUT和STDERR重定向
運行多個後台作業
可以在命令行提示符下同時啓動多個後台作業,每次啓動新作業時,Linux系統都會為其分配一個新的作業號和PID
在終端會話中使用後台進程時一定要小心,如果終端會話退出,那麼後台進程也會隨之退出
在非控制枱下運行腳本
nohup命令運行了另外一個命令來阻斷所有發送給該進程的SIGHUP信號,這會在退出終端會話時阻止進程退出
nohup ./test &
[1] 3856如果關閉該會話,腳本會忽略終端會話發過來的SIGHUP信號,其餘都與普通後台進程一樣
nohup命令會解除終端與進程的關聯,進程也就不再同STDOUT和STDERR聯繫在一起。 為了保存該命令產生的輸出,nohup命令會自動將STDOUT和STDERR的消息重定向到一個名為nohup.out的文件中運行位於同一個目錄中的多個命令時一定要當心,因為所有的輸出都會被髮送到同一個
nohup.out文件中
nohup.out文件包含了通常會發送到終端顯示器上的所有輸出。在進程完成運行後就可以查看nohup.out文件中的輸出結果
作業控制
可以用kill命令終止該進程。要重啓停止的進程需要向其發送一個SIGCONT信號
啓動、停止、終止以及恢復作業的這些功能統稱為作業控制,通過作業控制來完全控制shell環境中所有進程的運行方式
查看作業
jobs命令允許查看shell當前正在處理的作業
echo "Script Process ID: $$"可以在腳本內用$$變量來顯示Linux系統分配給該腳本的PID
jobs可以使用一些不同的命令行參數
-l 列出進程的PID以及作業號
-n 只列出上次shell發出的通知後改變了狀態的作業
-p 只列出作業的PID
-r 只列出運行中的作業
-s 只列出已停止的作業jobs命令輸出的加號和減號表示:
- 帶加號的作業會被當做默認作業,使用作業控制命令時如果未指定如何作業號,該作業就成為作業控制命令的操作對象
- 當前的默認作業完成處理後,帶減號的作業成為下一個默認作業。任何時候都只有一個帶加號的作業和一個帶減號的作業
重啓停止的作業
可以將已停止的作業作為後台進程或前台進程重啓。作為前台進程會接管當前工作的終端
以後台模式重啓一個作業,用bg命令加作業號
bg
#不帶參數自然重啓帶加號的默認作業,當作業被轉入後台模式時,並不會列出其PID以前台模式重啓作業,用fg命令加作業號
fg
#由於作業是以前台模式運行的,直到該作業完成後,命令行界面的提示符才會出現調整謙讓度
多任務系統中,內核負責將CPU時間分配給系統上運行的每個進程,調度優先級是內核分配給進程的CPU時間。在Linux系統中,由shell啓動的所有進程的調度優先級默認都是相同的
調度優先級是整數值,從-20(最高優先級)~+19(最低優先級),默認情況下bash shell以優先級0來啓動所有進程
nice命令允許降低命令啓動時的調度優先級,只有root用户能任意調整
nice -n 10 script
#以10低優先級啓動,-n選項不是必須的,指定優先級即可可以使用top命令或ps -eo查看命令的調度優先級
renice命令允許降低已運行命令的優先級,只有root用户能任意調整
定時運行作業
at命令允許指定Linux系統何時運行腳本,at命令會將作業提交到隊列中,指定shell何時運行該作業。at的守護進程atd會以後台模式運行,檢查作業隊列來運行作業。大多數Linux發行版會在啓動時運行此守護進程
atd守護進程會檢查系統上的一個特殊目錄,通常位於/var/spool/at來獲取用at命令提交的作業。默認情況下atd守護進程會每60秒檢查一下這個目錄
有作業時atd守護進程會檢查作業設置運行的時間,如果時間跟當前時間匹配,atd守護進程就會運行此作業
at [-f filename] time默認情況下at命令會將STDIN的輸入放到隊列中,可以用-f參數來指定用於讀取命令或腳本文件的文件名
time參數指定了Linux系統何時運行該作業。如果指定的時間已經錯過,at命令會在第二天的此時間運行指定的作業
at命令能識別多種不同的時間格式:
- 標準的小時和分鐘格式:10:15
- AM/PM指示符:10:15 PM
- 特定可命名時間:now、noon、midnight或者teatime(4 PM)
除了指定運行作業的時間,也可以通過不同的日期格式指定特定的日期
- 標準日期格式:MMDDYY、MM/DD/YY或DD.MM.YY
- 文本日期:Jul 4或Dec 25,加不加年份均可
- 也可指定時間增量,格式是
now + count time-units
now表示當前時間time-units可以是以下之一:minutes、hours、days、weeks- now + 10 minutes(也可簡寫為10m)
- mow + 1week 5:30pm
- now + 2h
使用at命令時,該作業會被提交到作業隊列,作業隊列會保存通過at命令提交的待處理的作業。針對不同優先級,存在26種不同的作業隊列,作業隊列通常用小寫字母a~z 和大寫字母A~Z來指代
作業隊列的字母排序越高,作業運行的優先級就越低,如果想以更高優先級運行作業,可以用-q參數指定不同的隊列字母
獲取作業的輸出
當作業在Linux系統上運行時,顯示器並不會關聯到該作業,Linux系統會將提交該作業的用户的電子郵件地址作為STDOUT和STDERR,任何發到STDOUT或STDERR的輸出都會通過郵件系統發送給該用户
at -f script now + 10m使用e-mail作為at命令的輸出極其不便。at命令利用sendmail應用程序來發送郵件。如果系統中沒有安裝sendmail,那就無法獲得任何輸出,因此在使用at命令時,最好在腳本中對STDOUT和STDERR進行重定向
#echo命令的輸出重定向到文件
echo "This script ran at $(date +%B%d,%T)" > test.out
#追加一個空行
echo >> test.out
sleep 5
echo "This is the script's end..." >> test.out列出等待的作業
atq命令可以查看系統中有哪些作業在等待
作業列表中顯示了作業號、系統運行該作業的日期和時間、其所在的作業隊列
刪除作業
用atrm命令來刪除等待中的作業,指定刪除作業號即可
安排需要定期執行的腳本
如果需要腳本在每天的同一時間運行或是每週一次、每月一次等,無需多次使用at提交作業,可以使用cron程序來安排要定期執行的作業,cron程序會在後台運行並檢查cron表來獲知已安排執行的作業
cron時間表採用一種特別的格式來指定作業何時運行
min hour day month week command可以使用通配符*來指定條目在任意時候,數值0週日~數值6週六,也可使用取值範圍n1-n2,使用,來枚舉
#在每個月的每天的10:15執行命令
15 10 * * * command
#每週一的16:15執行命令
15 16 * * 1 command
#每個月的第一天的12:00執行命令
00 12 1 * * command如何設置每個月的最後一天執行命令,因為每月的月份不同,常用的方法是加一條使用date命令的if-then語句來檢查明天的日期是不是01:
00 12 * * * if [`date +%d -d tomorrow` = 01 ] ; then ; command命令列表必須指定要運行的命令或腳本的全路徑名,可以像在普通的命令行中那樣,添加任何想要的命令行參數和重定向符號
15 10 * * * /home/rich/test > testoutcron程序會用提交作業的用户賬户運行該腳本。因此必須有訪問該命令和命令中指定的輸出文件的權限
構建cron時間表
每個系統用户包括root用户都可以用自己的cron時間表來運行安排好的任務,Linux提供 了crontab命令來處理cron時間表
crontab -l
#列出已有的cron時間表默認情況下用户的cron時間表文件並不存在。要為cron時間表添加條目,可以用-e選項
瀏覽cron目錄
如果創建的腳本對精確的執行時間要求不高,用預配置的cron腳本目錄會更方便。有4個基本目錄:hourly、daily、monthly、weekly
如果腳本需要每天運行一次,只要將腳本複製到daily目錄,cron就會每天執行它
anacron程序
cron它假定Linux系統是7×24小時運行的。除非將Linux當成服務器環境來運行,否則此假設未必成立
如果某個作業在cron時間表中安排運行的時間已到,但這時候Linux系統處於關機狀態,那麼這個作業就不會被運行。當系統開機時,cron程序不會再去運行那些錯過的作業
而如果anacron知道某個作業錯過了執行時間,它會盡快運行該作業。這意味着如果Linux系統關機了幾天,當它再次開機時,原定在關機期間運行的作業會自動運行
這個功能常用於進行常規日誌維護的腳本。如果系統在腳本應該運行的時間剛好關機, 日誌文件就不會被整理,可能會變很大。通過anacron,至少可以保證系統每次啓動時整理日誌文件
anacron程序只會處理位於cron目錄的程序,比如/etc/cron.monthly,它用時間戳來決定作業是否在正確的計劃間隔內運行了,每個cron目錄都有個時間戳文件,該文件位於/var/spool/anacron
anacron程序使用自己的時間表(通常位於/etc/anacrontab)來檢查作業目錄
anacron時間表的基本格式和cron時間表略有不同:
period delay identifier commandperiod條目定義作業多久運行一次,以天為單位delay條目會指定系統啓動後anacron程序需要等待多少分鐘再開始運行錯過的腳本identifier條目是一種特別的非空字符串,如cron-weekly,它用於唯一標識日誌消息和錯誤郵件中的作業command條目包含run-parts程序和一個cron腳本目錄名,run-parts程序負責運行目錄中傳給它的任何腳本
anacron不會運行位於/etc/cron.hourly的腳本。這是因為anacron程序不會處理執行時間 需求小於一天的腳本
使用新shell啓動腳本
當用户登入bash shell時需要運行的啓動文件,基本上依照下列順序所找到的第一個文件會被運行,其餘的文件會被忽略:
- $HOME/.bash_profile
- $HOME/.bash_login
- $HOME/.profile
將需要在登錄時運行的腳本放在上面第一個文件中,這樣每次啓動shell時都會運行該腳本
創建函數