

作者:稚柳
前言
當企業想用大模型和內部非公開信息打造智能問答系統時,RAG(Retrieval-Augmented Generation,檢索增強生成)已成為必備技術。然而,在實際落地中,構建 RAG 應用的數據準備過程繁瑣複雜且充滿挑戰,讓很多企業和開發者望而卻步。本文將介紹構建 RAG 的最佳實踐:通過阿里雲事件總線 EventBridge 提供的多源 RAG 處理方案,基於事件驅動架構為企業 AI 應用打造高效、可靠、自動化的數據管道,輕鬆解決 RAG 數據處理難題。
為什麼 RAG 是治癒模型幻覺的“良方”?
大語言模型(LLM)就像一個博覽羣書、記憶力超羣的“學霸”,儘管文采斐然、對答如流,但偶爾也會犯一些令人啼笑皆非的錯誤,比如憑空編造事實或提供過時信息,這就是我們常説的“模型幻覺”。
這背後的原因很簡單:這位“學霸”的知識完全來自於“畢業前”學過的海量教材(即訓練數據),儘管覆蓋了維基百科、新聞、書籍等通用知識和各領域的專業知識,但存在兩個天然侷限:
- 知識領域侷限: 它對企業內部、垂直領域等私域知識知之甚少。比如,它不瞭解你公司內部的規章制度,也無法接觸電商平台的用户數據等非公開信息。
- 知識時效侷限: 它的知識更新停留在訓練數據截止的那個時間點,無法獲取實時信息,比如股票行情、時事新聞等不斷更新的動態數據。
為了治好大語言模型“一本正經胡説八道”的毛病,我們必須讓它從“閉卷考試”升級為“開卷考試”,RAG(Retrieval-Augmented Generation,檢索增強生成)技術應運而生。
RAG 的核心理念,可以通俗地理解為“先查找資料,再生成答案”。當收到一個問題時,它不會讓大模型直接憑記憶回答問題,而是分兩步走:
- 檢索(Retrieval): 從一個可隨時更新的外部知識庫(如企業內部文檔、產品手冊等)中,快速檢索出與問題最相關的信息片段。
- 生成(Generation): 將檢索到的信息片段連同用户問題一起作為上下文提供給大模型,引導它基於這些可靠的“證據”生成準確、有理有據且可追溯來源的回答。

(來自阿里雲大模型平台服務百鍊 - 知識庫功能 文檔示例)
通過這種方式,不僅能有效減少模型幻覺,大幅提升生成答案的準確性與時效性,還讓模型在無需耗費巨資和時間進行重新訓練的情況下,就能輕鬆擴展知識邊界。憑藉這些顯著優勢,RAG 已成為企業構建可靠、智能 AI 應用的首選方案。
RAG 落地挑戰:數據處理的“三重困境”
儘管 RAG 的原理聽起來簡單明瞭,但在實際落地時,無數企業和開發者卻深陷數據處理的泥潭。
AI 時代的數據處理,與過去以結構化數據為主的傳統數據處理模式截然不同。我們面對的是由海量、異構、多模態數據構成的洪流,數據處理的複雜度和挑戰呈指數級增長。企業對實時性要求也不斷提高,任何數據延遲都可能影響模型效果。
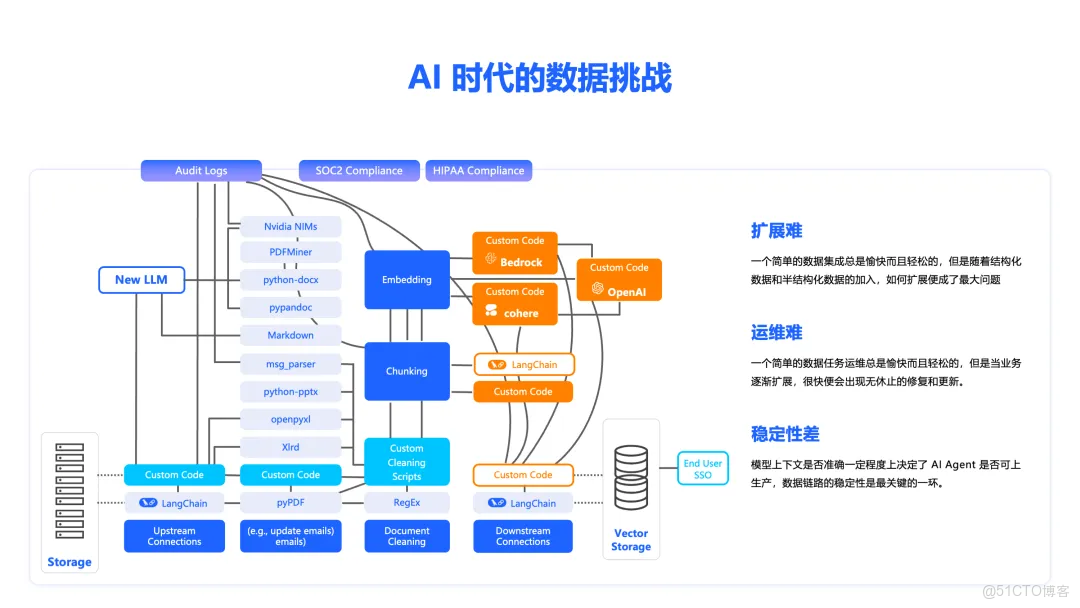
企業和開發者在落地 RAG 時,普遍會陷入數據處理的“三重困境”:
1. 擴展之困——異構化數據源的“接入鴻溝”
現代企業的數據通常散落在 ERP、CRM、OA、IoT 設備、社交媒體等數十個系統中,涵蓋結構化數據(如數據庫、表格)、非結構化數據(如 PDF、網頁、圖片、音視頻)和半結構化數據(如 JSON、XML)。若採用傳統點對點連接的數據集成方式,每接入一個新數據源,都需要複雜的定製化開發,擴展性極差,響應速度慢,嚴重拖慢 AI 應用的迭代速度。
2. 運維之難——脆弱數據管道的“運維噩夢”
RAG 的數據處理鏈路漫長且複雜,涉及數據採集、清洗、切塊、向量化、入庫、檢索等多個環節。整條鏈路如同一個脆弱的“黑箱”,任何一個環節的微小故障都可能導致全鏈路癱瘓。在實際運維過程中,數據源接口變更、數據質量問題、系統負載突增等突發狀況層出不窮,數據管道的問題排查、修復和系統更新,都極其耗時耗力,讓運維團隊疲於奔命。
3. 穩定之痛——數據管道的“可靠性危機”
數據管道的穩定性是 AI 應用落地的基石。數據丟失、重複、延遲、質量下降以及系統故障等數據處理鏈路中的任何問題,都可能直接導致模型推理結果的偏差甚至錯誤,進而影響業務決策和用户體驗。傳統數據處理架構的緊耦合設計,導致任何一個組件故障都可能影響整個系統運行,並且缺乏有效的監控和告警機制,往往在造成嚴重影響後才發現問題。
因此,我們迫切需要一種全新的數據處理範式,來構建一個靈活、可擴展、實時、智能的數據處理管道。
破局之道:事件架構驅動重塑 AI 數據管道
事件驅動架構(Event-Driven Architecture,EDA)為應對 AI 數據處理的複雜性挑戰,提供了堅實的技術基礎。在事件驅動架構中,“事件(Event)”是核心概念,它本質上是一次狀態變化的數字化表達。在 AI 數據處理場景中,數據的產生、變更、處理、存儲等各個環節都可以被抽象為事件。 例如,當新的訓練數據上傳到系統時,產生數據接收事件;當數據經過清洗和轉換後,產生數據處理完成事件;當向量化處理完成後,產生向量生成事件;當數據成功存儲到向量數據庫後,產生數據入庫事件。

這種“事件化”的處理方式,使整個 AI 數據處理流程變得標準化、清晰、可控且可追溯,帶來三大優勢:
1. 鬆耦合
數據處理流程被分解為獨立的事件和處理單元。數據工程、算法、平台等團隊可以獨立開發、部署和迭代各自負責的組件,無需關心對方的內部實現。一個組件的變更不會影響其他部分,系統容錯能力和迭代效率更高。
2. 可擴展性與穩定性
每個組件都可以根據實際負載獨立擴展,當某個組件成為瓶頸時,只需增加該組件的實例數量,而無需對整個系統進行擴容。同時,通過引入智能監控和自動恢復機制,系統能夠及時發現和處理各種異常情況,保證數據鏈路穩定運行。
3. 端到端實時性
在智能客服、實時推薦等場景中,毫秒級的響應至關重要。事件驅動架構可以確保事件一旦發生,便能被立即捕獲並觸發後續處理。這使得 RAG 的知識庫能夠近乎實時地吸收新信息,讓大模型始終掌握着最新“情報”。
綜上所述,採用事件驅動架構的系統在敏捷性、可擴展性和可靠性方面實現了質的飛躍,這正是 AI 應用規模化落地的基石。
EventBridge 多源 RAG 處理方案:為 AI 場景提供高效數據管道
阿里雲事件總線 EventBridge 基於事件驅動架構,將 AI 能力深度融入數據處理全鏈路,為企業和開發者提供專為 AI 應用設計的、端到端的、智能化的數據處理中間件。

EventBridge 通過一系列 ETL for AI Data 的全新能力,提供多源 RAG 處理方案:將 RAG 數據準備的全流程(從多源異構數據提取、清洗、切塊、向量化再到入庫)徹底實現自動化。
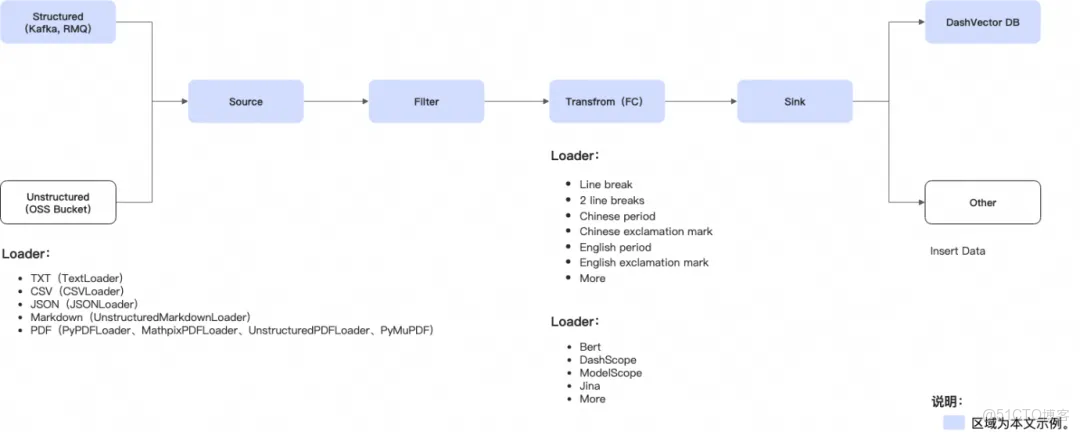
開發者現在可以通過 EventBridge 簡單的“白屏化”配置,輕鬆實現:
1. 無縫對接多源數據
輕鬆接入主流的對象存儲(OSS)、消息隊列(如 Kafka、RocketMQ、MQTT)、日誌服務(如 SLS)、數據庫服務(如 MySQL)等多種數據源,覆蓋結構化數據(如數據庫、表格)、非結構化數據(如 PDF、網頁、圖片、音視頻)和半結構化數據(如 JSON、XML)。
2. 智能化的數據處理
自動完成文檔解析(Loader)、文本切分(Chunking)和向量化(Embedding)的完整數據轉換流程,內置多種核心技術,支持多種非結構化數據(如 TEXT、JSON、XML、YAML、CSV)的智能解析和處理,提供完整的 Loader 技術體系,包括多種分塊策略、單文檔加載、批量數據加載,確保大規模數據的可靠處理;對結構化數據採用流式處理架構,能夠實時處理高吞吐量的數據流,可實現複雜的流式數據轉換和聚合操作。
3. 一鍵式向量入庫
提供統一的向量數據庫接入接口,支持將處理好的向量數據直接加載到主流向量數據庫(如 DashVector、Milvus)中,也兼容傳統數據庫的向量擴展插件。只需簡單的圖形界面配置(拖拽方式配置數據源、處理邏輯、目標數據庫等),系統會自動生成複雜的向量數據處理和入庫流程。提供豐富的預置模板,可基於模板快速搭建數據處理流程。提供完善的監控儀表板和告警機制,可實時查看數據處理的狀態、性能指標、錯誤信息等,及時發現和解決問題。
場景實踐:從 0 到 1 構建基於事件驅動架構的實時 RAG 應用
接下來,我們將通過一個完整的實戰場景,帶你從零開始,利用阿里雲事件總線 EventBridge、對象存儲 OSS、函數計算 FC、向量檢索服務 DashVector 和大模型服務平台百鍊,快速構建一個實時的 RAG 應用。
方案概覽
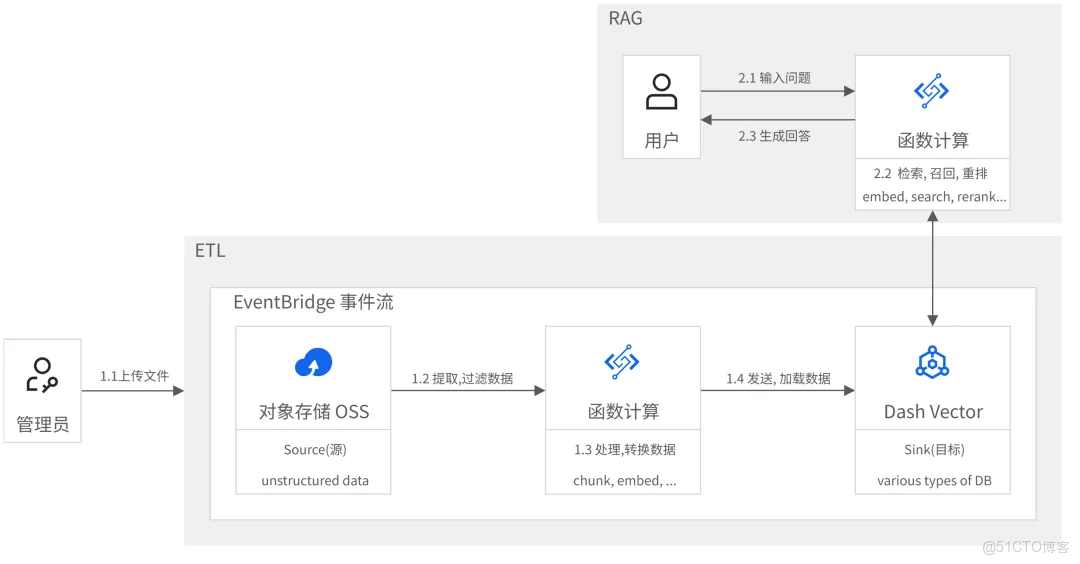
- 首先,通過 EventBridge 構建一個高效的 ETL 數據管道:能夠自動從數據源(對象存儲 OSS)中實時提取數據,通過函數計算 FC 靈活定義數據轉換的邏輯,進行清洗、切塊和向量化,並將處理結果持續加載到目標(向量檢索服務 DashVector),形成一個動態更新的知識庫。
- 然後,通過函數計算(FC)的 Web 函數構建一個簡單的 RAG 應用,調用大模型服務平台百鍊進行推理,以 DashVector 中的向量數據作為知識庫。
- 最後,我們通過輸入與知識庫相關的用户問題,測試 RAG 應用的回答效果。
方案架構
方案提供的默認設置完成部署後,在阿里雲上搭建的系統如下圖所示。實際部署時您可以根據資源規劃修改部分設置,但最終形成的運行環境與下圖相似。
實施步驟
- 構建自動化數據管道:
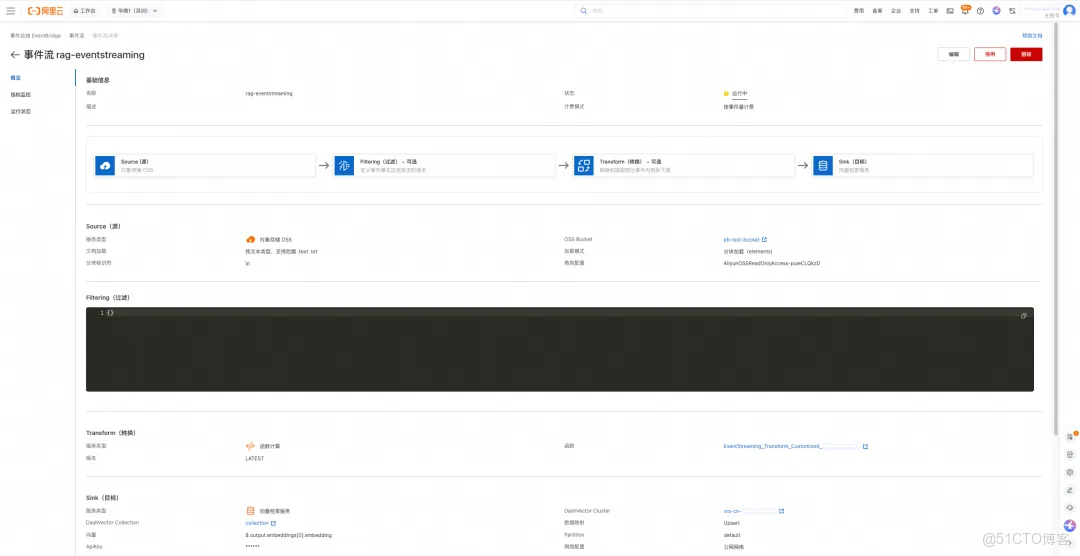
- 創建事件流: 在事件總線 EventBridge 控制枱創建並配置一個事件流,作為數據處理管道的核心。
- 配置數據源與目標: 創建並配置對象存儲 OSS Bucket 作為數據源(Source),創建並配置向量檢索服務 DashVector 作為數據投遞的目標(Sink)。
- 配置數據轉換邏輯(Transform): 選擇“內容向量化”的函數模板創建一個函數,並在函數代碼中填寫獲取的百鍊 API-KEY,這個函數將負責對數據進行切塊和向量化。
- 構建 RAG 應用:
- 創建 Web 函數:創建一個 Web 函數(注意和之前創建的用於處理數據流的事件函數區分)。
- 編寫應用代碼:這個函數將作為 RAG 應用的後端,負責接收用户查詢,從 DashVector 檢索知識,並調用百鍊大模型生成回答。需要在函數代碼中配置百鍊和向量檢索服務 DashVector 的相關訪問憑證(如 API-KEY、Endpoint 等)。
- 部署應用:部署代碼成功後,RAG 應用即構建完成並可供訪問。
效果驗證
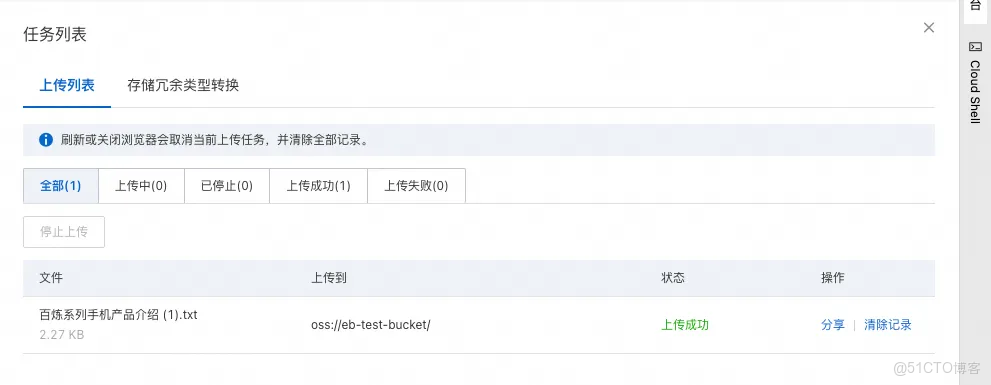
1. 更新知識庫: 將包含私有數據的文件(例如,一份名為百鍊系列手機產品介紹.txt 的文檔,包含了虛擬手機廠商的商品數據)上傳到 OSS Bucket 中。
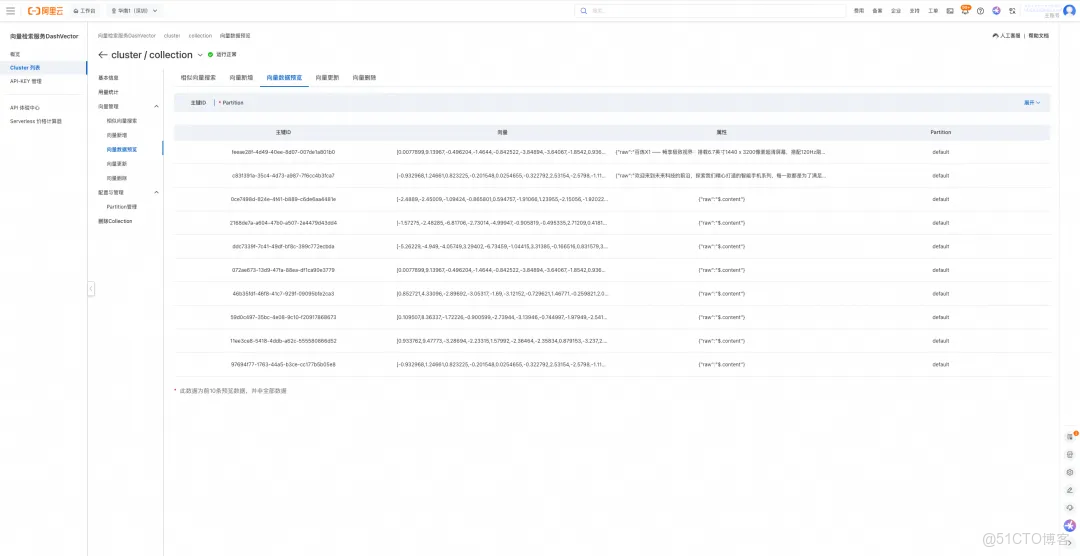
2. 查看向量生成: 文件上傳成功後,EventBridge 會自動捕獲這一事件並觸發數據處理流程。稍等片刻,即可在 DashVector 控制枱查看已生成的向量。
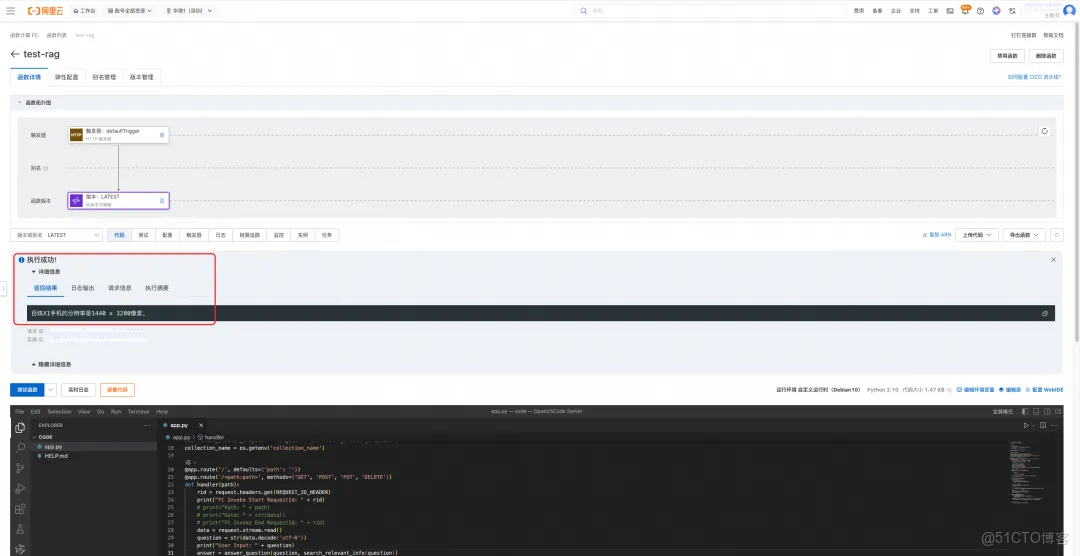
3. 測試問答效果: 通過創建的 RAG 應用發起訪問,輸入一個與你上傳文檔相關的問題,例如:“百鍊 X1 手機的分辨率是多少?”。
4. 獲取精準回答: RAG 應用會自動檢索知識庫,並將相關信息連同問題一起發送給百鍊大模型。很快就會收到一個基於私有數據生成的精準回答。在函數的執行日誌中,還可以看到向量檢索召回的具體原文片段,從而驗證整個 RAG 鏈路的有效性。
目前,該解決方案已在阿里雲官網上線,歡迎點擊閲讀原文即可部署體驗~
邀請您釘釘搜索羣號:44552972,加入 EventBridge 用户交流羣,探索更多產品功能,與我們共同定義和構建 AI 數據處理的未來!