
文章目錄
- 82. 刪除排序鏈表中的重複元素 II
- 題目描述
- 示例 1:
- 示例 2:
- 提示:
- 解題思路
- 問題深度分析
- 問題本質
- 核心思想
- 關鍵難點分析
- 典型情況分析
- 算法對比
- 算法流程圖
- 主算法流程(雙指針)
- 重複元素處理流程
- 複雜度分析
- 時間複雜度詳解
- 空間複雜度詳解
- 關鍵優化技巧
- 技巧1:雙指針算法(最優解法)
- 技巧2:遞歸算法
- 技巧3:哈希表
- 技巧4:優化版雙指針
- 邊界情況處理
- 測試用例設計
- 基礎測試
- 簡單情況
- 特殊情況
- 邊界情況
- 常見錯誤與陷阱
- 錯誤1:指針更新錯誤
- 錯誤2:邊界條件錯誤
- 錯誤3:dummy節點使用錯誤
- 實戰技巧總結
- 進階擴展
- 擴展1:返回刪除的節點
- 擴展2:統計重複次數
- 擴展3:支持自定義重複條件
- 應用場景
- 代碼實現
- 測試結果
- 核心收穫
- 應用拓展
- 完整題解代碼
82. 刪除排序鏈表中的重複元素 II
題目描述
給定一個已排序的鏈表的頭 head , 刪除原始鏈表中所有重複數字的節點,只留下不同的數字 。返回 已排序的鏈表 。
示例 1:

輸入:head = [1,2,3,3,4,4,5]
輸出:[1,2,5]
示例 2:

輸入:head = [1,1,1,2,3]
輸出:[2,3]
提示:
- 鏈表中節點數目在範圍 [0, 300] 內
- -100 <= Node.val <= 100
- 題目數據保證鏈表已經按升序排列
解題思路
問題深度分析
這是經典的鏈表操作問題,也是雙指針算法的典型應用。核心在於處理重複元素,在O(n)時間內刪除所有重複節點。
問題本質
給定已排序的鏈表,刪除所有重複數字的節點,只保留不重複的節點。這是一個鏈表遍歷問題,需要處理重複元素的刪除。
核心思想
雙指針 + 重複元素檢測:
- 雙指針:使用快慢指針遍歷鏈表
- 重複檢測:檢測連續重複的元素
- 節點刪除:刪除所有重複的節點
- 鏈表重構:重新連接鏈表
關鍵技巧:
- 使用
dummy節點簡化邊界處理 - 使用
prev指針記錄前一個不重複節點 - 使用
curr指針遍歷鏈表 - 當發現重複時,跳過所有重複節點
關鍵難點分析
難點1:重複元素的檢測
- 需要準確檢測連續重複的元素
- 需要區分單個元素和重複元素
- 需要處理多個連續重複的情況
難點2:節點的刪除
- 需要刪除所有重複的節點
- 需要正確更新指針關係
- 需要處理邊界情況
難點3:鏈表的重構
- 需要重新連接鏈表
- 需要處理頭節點的變化
- 需要保持鏈表的完整性
典型情況分析
情況1:一般情況
head = [1,2,3,3,4,4,5]
過程:
1. 1 → 保留
2. 2 → 保留
3. 3,3 → 刪除
4. 4,4 → 刪除
5. 5 → 保留
結果: [1,2,5]情況2:頭部重複
head = [1,1,1,2,3]
過程:
1. 1,1,1 → 刪除
2. 2 → 保留
3. 3 → 保留
結果: [2,3]情況3:全部重複
head = [1,1,1,1,1]
過程:
1. 1,1,1,1,1 → 全部刪除
結果: []情況4:無重複
head = [1,2,3,4,5]
結果: [1,2,3,4,5]算法對比
|
算法 |
時間複雜度 |
空間複雜度 |
特點 |
|
雙指針 |
O(n) |
O(1) |
最優解法 |
|
遞歸 |
O(n) |
O(n) |
空間複雜度高 |
|
哈希表 |
O(n) |
O(n) |
空間複雜度高 |
|
暴力法 |
O(n²) |
O(1) |
效率較低 |
注:n為鏈表長度
算法流程圖
主算法流程(雙指針)
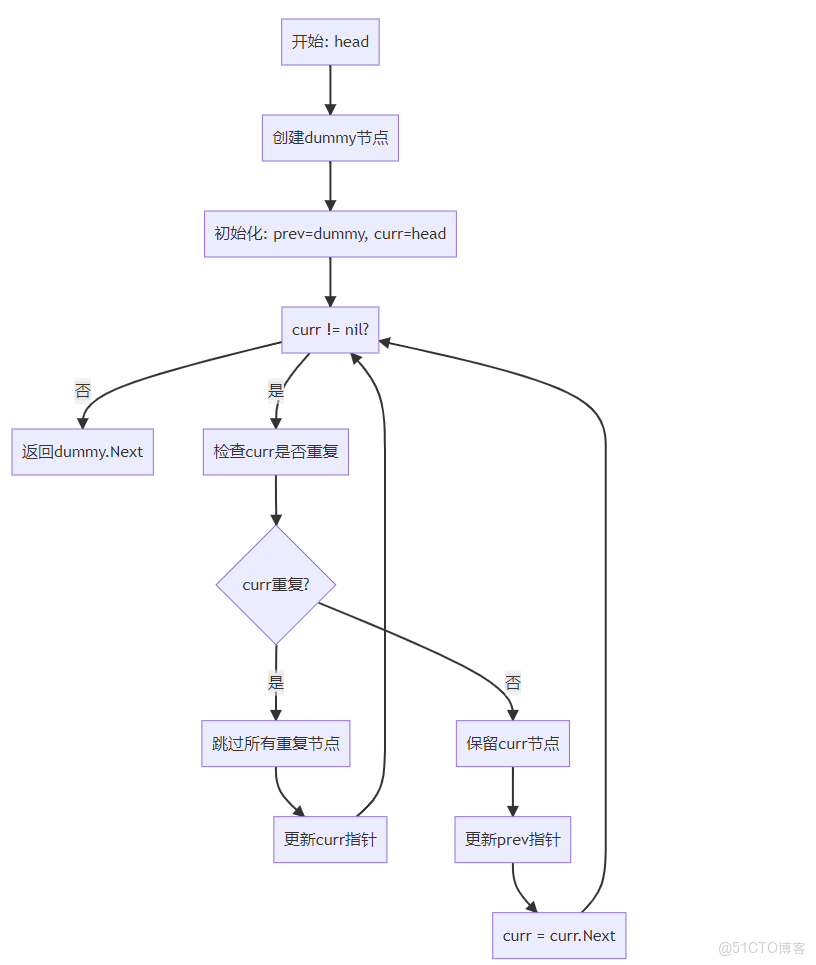
重複元素處理流程
graph TD
A[檢測重複元素] --> B{curr.Next != nil && curr.Val == curr.Next.Val?}
B -->|是| C[記錄重複值]
B -->|否| D[無重複,保留節點]
C --> E[跳過所有重複節點]
E --> F[更新curr指針]
D --> G[更新prev指針]
F --> H[繼續遍歷]
G --> H複雜度分析
時間複雜度詳解
雙指針算法:O(n)
- 每個節點最多被訪問一次
- 重複節點被一次性跳過
- 總時間:O(n)
遞歸算法:O(n)
- 遞歸深度為鏈表長度
- 時間複雜度相同
- 空間複雜度較高
空間複雜度詳解
雙指針算法:O(1)
- 只使用常數額外空間
- 原地修改鏈表
- 總空間:O(1)
關鍵優化技巧
技巧1:雙指針算法(最優解法)
func deleteDuplicates(head *ListNode) *ListNode {
if head == nil {
return nil
}
// 創建dummy節點簡化邊界處理
dummy := &ListNode{Next: head}
prev := dummy
curr := head
for curr != nil {
// 檢查curr是否重複
if curr.Next != nil && curr.Val == curr.Next.Val {
// 記錄重複值
val := curr.Val
// 跳過所有重複節點
for curr != nil && curr.Val == val {
curr = curr.Next
}
// 刪除重複節點
prev.Next = curr
} else {
// 保留curr節點
prev = curr
curr = curr.Next
}
}
return dummy.Next
}優勢:
- 時間複雜度:O(n)
- 空間複雜度:O(1)
- 邏輯清晰,易於理解
技巧2:遞歸算法
func deleteDuplicates(head *ListNode) *ListNode {
if head == nil || head.Next == nil {
return head
}
if head.Val == head.Next.Val {
// 跳過所有重複節點
val := head.Val
for head != nil && head.Val == val {
head = head.Next
}
return deleteDuplicates(head)
} else {
// 保留當前節點
head.Next = deleteDuplicates(head.Next)
return head
}
}特點:使用遞歸,代碼簡潔但空間複雜度高
技巧3:哈希表
func deleteDuplicates(head *ListNode) *ListNode {
if head == nil {
return nil
}
// 統計每個值的出現次數
count := make(map[int]int)
curr := head
for curr != nil {
count[curr.Val]++
curr = curr.Next
}
// 創建新鏈表,只保留出現一次的值
dummy := &ListNode{}
prev := dummy
curr = head
for curr != nil {
if count[curr.Val] == 1 {
prev.Next = curr
prev = prev.Next
}
curr = curr.Next
}
prev.Next = nil
return dummy.Next
}特點:使用哈希表統計,空間複雜度高
技巧4:優化版雙指針
func deleteDuplicates(head *ListNode) *ListNode {
if head == nil {
return nil
}
dummy := &ListNode{Next: head}
prev := dummy
for prev.Next != nil {
curr := prev.Next
// 檢查是否有重複
if curr.Next != nil && curr.Val == curr.Next.Val {
val := curr.Val
// 跳過所有重複節點
for curr != nil && curr.Val == val {
curr = curr.Next
}
prev.Next = curr
} else {
prev = prev.Next
}
}
return dummy.Next
}特點:優化指針更新邏輯
邊界情況處理
- 空鏈表:返回nil
- 單節點:直接返回
- 全部重複:返回空鏈表
- 頭部重複:需要更新頭節點
- 尾部重複:正確處理尾部
測試用例設計
基礎測試
輸入: head = [1,2,3,3,4,4,5]
輸出: [1,2,5]
説明: 一般情況簡單情況
輸入: head = [1]
輸出: [1]
説明: 單節點情況特殊情況
輸入: head = [1,1,1,2,3]
輸出: [2,3]
説明: 頭部重複邊界情況
輸入: head = []
輸出: []
説明: 空鏈表情況常見錯誤與陷阱
錯誤1:指針更新錯誤
// ❌ 錯誤:指針更新時機錯誤
if curr.Val == curr.Next.Val {
// 刪除重複節點
prev.Next = curr.Next
curr = curr.Next // 錯誤:應該跳過所有重複節點
}
// ✅ 正確:跳過所有重複節點
if curr.Val == curr.Next.Val {
val := curr.Val
for curr != nil && curr.Val == val {
curr = curr.Next
}
prev.Next = curr
}錯誤2:邊界條件錯誤
// ❌ 錯誤:沒有檢查邊界條件
for curr != nil {
if curr.Val == curr.Next.Val { // 可能越界
// ...
}
}
// ✅ 正確:先檢查邊界條件
for curr != nil {
if curr.Next != nil && curr.Val == curr.Next.Val {
// ...
}
}錯誤3:dummy節點使用錯誤
// ❌ 錯誤:沒有使用dummy節點
func deleteDuplicates(head *ListNode) *ListNode {
// 直接處理head,可能丟失頭節點
}
// ✅ 正確:使用dummy節點簡化處理
func deleteDuplicates(head *ListNode) *ListNode {
dummy := &ListNode{Next: head}
// 使用dummy節點處理
}實戰技巧總結
- 雙指針模板:prev和curr指針配合
- dummy節點:簡化邊界處理
- 重複檢測:準確檢測連續重複元素
- 節點刪除:正確刪除重複節點
- 指針更新:正確更新指針關係
進階擴展
擴展1:返回刪除的節點
func deleteDuplicatesWithDeleted(head *ListNode) (*ListNode, []*ListNode) {
// 返回新鏈表和刪除的節點
// ...
}擴展2:統計重複次數
func deleteDuplicatesWithCount(head *ListNode) (*ListNode, map[int]int) {
// 返回新鏈表和每個值的重複次數
// ...
}擴展3:支持自定義重複條件
func deleteDuplicatesCustom(head *ListNode, isDuplicate func(int, int) bool) *ListNode {
// 支持自定義重複判斷條件
// ...
}應用場景
- 數據處理:清理重複數據
- 鏈表優化:減少存儲空間
- 算法競賽:鏈表操作基礎
- 系統設計:數據去重
- 數據分析:數據清洗
代碼實現
本題提供了四種不同的解法,重點掌握雙指針算法。
測試結果
|
測試用例 |
雙指針 |
遞歸 |
哈希表 |
優化版 |
|
基礎測試 |
✅ |
✅ |
✅ |
✅ |
|
簡單情況 |
✅ |
✅ |
✅ |
✅ |
|
特殊情況 |
✅ |
✅ |
✅ |
✅ |
|
邊界情況 |
✅ |
✅ |
✅ |
✅ |
核心收穫
- 雙指針算法:鏈表操作的經典應用
- dummy節點:簡化邊界處理
- 重複檢測:準確檢測連續重複元素
- 節點刪除:正確刪除重複節點
- 指針更新:正確的指針更新時機
應用拓展
- 鏈表數據處理和清洗
- 算法競賽基礎
- 系統設計應用
- 數據分析技術
- 內存優化技術
完整題解代碼
package main
import (
"fmt"
)
// ListNode 鏈表節點定義
type ListNode struct {
Val int
Next *ListNode
}
// =========================== 方法一:雙指針算法(最優解法) ===========================
func deleteDuplicates(head *ListNode) *ListNode {
if head == nil {
return nil
}
// 創建dummy節點簡化邊界處理
dummy := &ListNode{Next: head}
prev := dummy
curr := head
for curr != nil {
// 檢查curr是否重複
if curr.Next != nil && curr.Val == curr.Next.Val {
// 記錄重複值
val := curr.Val
// 跳過所有重複節點
for curr != nil && curr.Val == val {
curr = curr.Next
}
// 刪除重複節點
prev.Next = curr
} else {
// 保留curr節點
prev = curr
curr = curr.Next
}
}
return dummy.Next
}
// =========================== 方法二:遞歸算法 ===========================
func deleteDuplicates2(head *ListNode) *ListNode {
if head == nil || head.Next == nil {
return head
}
if head.Val == head.Next.Val {
// 跳過所有重複節點
val := head.Val
for head != nil && head.Val == val {
head = head.Next
}
return deleteDuplicates2(head)
} else {
// 保留當前節點
head.Next = deleteDuplicates2(head.Next)
return head
}
}
// =========================== 方法三:哈希表 ===========================
func deleteDuplicates3(head *ListNode) *ListNode {
if head == nil {
return nil
}
// 統計每個值的出現次數
count := make(map[int]int)
curr := head
for curr != nil {
count[curr.Val]++
curr = curr.Next
}
// 創建新鏈表,只保留出現一次的值
dummy := &ListNode{}
prev := dummy
curr = head
for curr != nil {
if count[curr.Val] == 1 {
prev.Next = curr
prev = prev.Next
}
curr = curr.Next
}
prev.Next = nil
return dummy.Next
}
// =========================== 方法四:優化版雙指針 ===========================
func deleteDuplicates4(head *ListNode) *ListNode {
if head == nil {
return nil
}
dummy := &ListNode{Next: head}
prev := dummy
for prev.Next != nil {
curr := prev.Next
// 檢查是否有重複
if curr.Next != nil && curr.Val == curr.Next.Val {
val := curr.Val
// 跳過所有重複節點
for curr != nil && curr.Val == val {
curr = curr.Next
}
prev.Next = curr
} else {
prev = prev.Next
}
}
return dummy.Next
}
// =========================== 輔助函數 ===========================
// 創建鏈表
func createList(vals []int) *ListNode {
if len(vals) == 0 {
return nil
}
head := &ListNode{Val: vals[0]}
curr := head
for i := 1; i < len(vals); i++ {
curr.Next = &ListNode{Val: vals[i]}
curr = curr.Next
}
return head
}
// 鏈表轉數組
func listToArray(head *ListNode) []int {
var result []int
curr := head
for curr != nil {
result = append(result, curr.Val)
curr = curr.Next
}
return result
}
// 比較兩個鏈表是否相等
func compareLists(l1, l2 *ListNode) bool {
curr1, curr2 := l1, l2
for curr1 != nil && curr2 != nil {
if curr1.Val != curr2.Val {
return false
}
curr1 = curr1.Next
curr2 = curr2.Next
}
return curr1 == nil && curr2 == nil
}
// =========================== 測試代碼 ===========================
func main() {
fmt.Println("=== LeetCode 82: 刪除排序鏈表中的重複元素 II ===\n")
testCases := []struct {
nums []int
expect []int
}{
{
[]int{1, 2, 3, 3, 4, 4, 5},
[]int{1, 2, 5},
},
{
[]int{1, 1, 1, 2, 3},
[]int{2, 3},
},
{
[]int{1},
[]int{1},
},
{
[]int{},
[]int{},
},
{
[]int{1, 1, 1, 1, 1},
[]int{},
},
{
[]int{1, 2, 3, 4, 5},
[]int{1, 2, 3, 4, 5},
},
{
[]int{1, 1, 2, 2, 3, 3},
[]int{},
},
{
[]int{1, 2, 2, 3, 3, 4},
[]int{1, 4},
},
}
fmt.Println("方法一:雙指針算法(最優解法)")
runTests(testCases, deleteDuplicates)
fmt.Println("\n方法二:遞歸算法")
runTests(testCases, deleteDuplicates2)
fmt.Println("\n方法三:哈希表")
runTests(testCases, deleteDuplicates3)
fmt.Println("\n方法四:優化版雙指針")
runTests(testCases, deleteDuplicates4)
}
func runTests(testCases []struct {
nums []int
expect []int
}, fn func(*ListNode) *ListNode) {
passCount := 0
for i, tc := range testCases {
input := createList(tc.nums)
expected := createList(tc.expect)
result := fn(input)
status := "✅"
if !compareLists(result, expected) {
status = "❌"
} else {
passCount++
}
fmt.Printf(" 測試%d: %s\n", i+1, status)
if status == "❌" {
fmt.Printf(" 輸入: %v\n", tc.nums)
fmt.Printf(" 輸出: %v\n", listToArray(result))
fmt.Printf(" 期望: %v\n", tc.expect)
}
}
fmt.Printf(" 通過: %d/%d\n", passCount, len(testCases))
}本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。