
摘要:在如 Snowflake、ElasticSearch、ClickHouse.... 等傳統系統中,對於 JSON 的處理往往面臨靈活性及性能無法兼得的困境,而 Apache Doris 的 VARIANT 類型,通過動態子列、稀疏列存儲、延遲物化和路徑索引等能力,實現了靈活結構 + 列存性能的平衡。本文將對該能力的實現一一講解,全面展示其優勢。
在大數據時代,JSON 已成為數據交換的事實標準。從日誌、埋點到 IoT 設備數據,從用户畫像到實時監控,JSON 憑藉其靈活、可擴展、無需預定義 Schema 的特性,完美契合了快速迭代的現代業務需求。然而,JSON 的動態靈活性與傳統數據庫的靜態處理模型存在根本矛盾,這直接導致了查詢性能低下、Schema 管理複雜以及在超寬表場景下的擴展性危機。
因此,對於 JSON 數據的處理,用户常常陷入兩難抉擇:
- 犧牲 性能 換取 靈活性(用 JSON 存儲,承擔高昂查詢開銷)
- 犧牲 靈活性 換取 性能(提前建立 Schema,喪失動態響應業務變化能力)
那麼,是否存在兩全之策,能讓性能與靈活性兼得?答案是肯定的。 Doris VARIANT通過底層的存算創新,將半結構化數據的靈活性與結構化數據的分析性能完美結合,全面超越了 Snowflake、ClickHouse 等傳統方案。
具體而言,Doris Variant 充分發揮列存與索引優勢,避免頻繁解析和全量掃描導致 CPU 與 I/O 過高引發性能問題。此外,它能從容應對字段動態變化及類型不一致場景,簡化 Schema 維護難度,消除了靈活性與性能間衝突。同時,Doris 優化了超寬表中鍵值繁多、稀疏分佈帶來的存儲與索引複雜性,解決超寬表場景下擴展性問題。

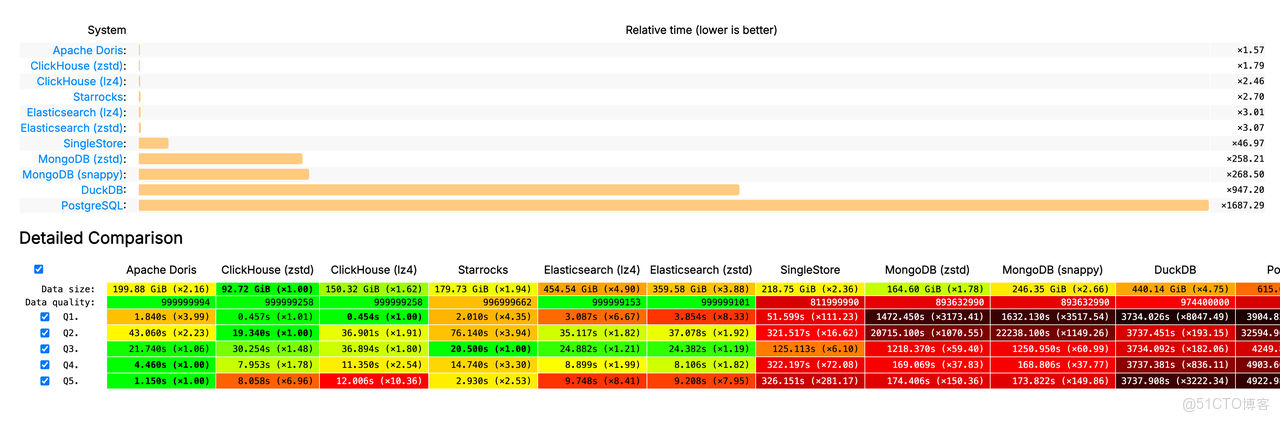
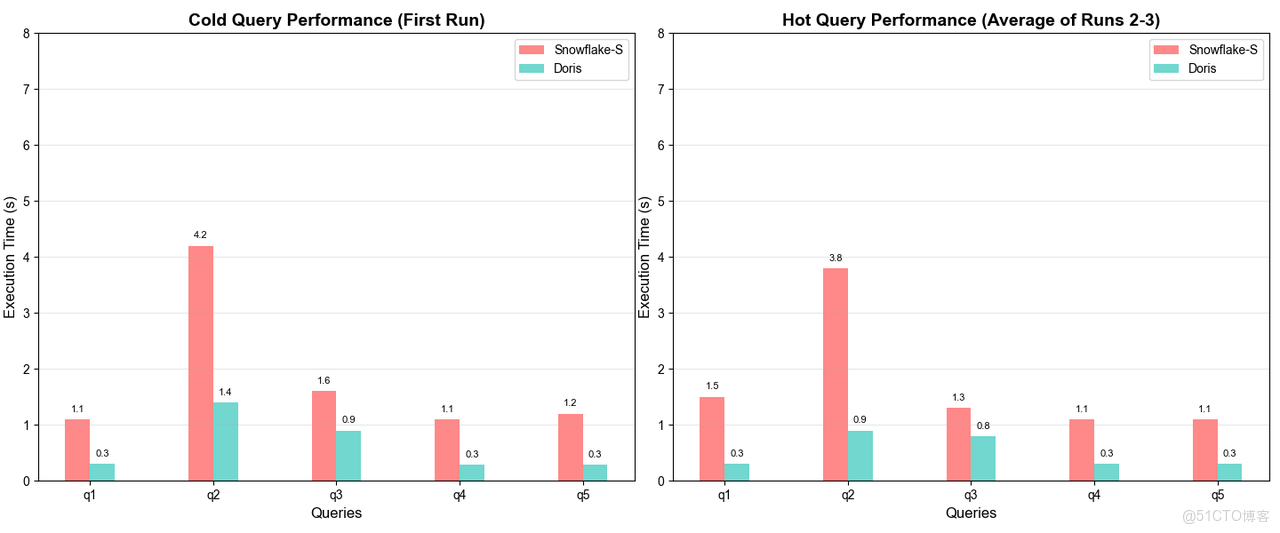
Doris VARIANT 的卓越性能也在業界公開的 JSONBench 半結構化數據測試中得到了充分驗證:冷查詢性能排名第一、熱查詢性能位居第二,全面領先 ClickHouse、Elasticsearch 等一眾知名產品。 其查詢速度約是 MongoDB 的 164 倍、PostgreSQL 的 1074 倍。此外,對 Doris、 Snowflake 進一步對比, 不管是在冷查詢還是熱查詢中,Doris 相較 Snowflake 有約 2-5 倍的性能優勢。具體可見下圖:
- 登頂 JSONBench 榜單
- Doris vs. Snowflake
Doris Variant 能夠具備上述優勢,主要得益於以下設計巧思及技術創新。
一、如何讓 JSON 獲得列存性能?
實現半結構化數據高性能分析的前提是,使其能夠像處理結構化數據一樣,為其構建高效的列式存儲結構,這是後續高性能分析的基礎。因此,在 Doris 中,通過動態子列、壓縮算法、列裁剪等設計,將半結構數據規範化,從而獲獲得列存的高性能。
1.1 動態子列
在如 Snowflake 這樣的系統中,JSON 數據的底層存儲對用户而言是一個黑盒,難以進行查詢優化、無法保證性能。而在 Doris 中,當 JSON 對象寫入 VARIANT 列時,系統會執行以下操作:
- 子列與類型推斷:解析 JSON 的層級結構,提取出所有的 Key Path(如
user.id,event.properties.timestamp),並自動推斷每個子列的值類型(如BIGINT,DOUBLE,STRING等)。 - 動態列化(Subcolumnization): 對於頻繁出現的子列,將其物化為獨立的內部子列。例如,嵌套在 JSON 中的
user.id字段在物理存儲上會擁有獨立的BIGINT列式存儲結構。 - 透明訪問 :該過程對用户完全透明。無需預先定義 Schema,數據寫入時自動完成列式轉換。用户仍可使用
v['user']['id']查詢 ,但查詢引擎可以直接訪問到已物化的user.id子列,充分利用列存和向量化執行的性能優勢。 - 稀疏列 :對於出現頻率極低或結構複雜的稀疏子列,不為其創建獨立子列以避免列爆炸。相反,這些數據會被高效組織在一個類 JSONB 的二進制“稀疏”列中,保留完整數據而不為罕見字段額外建列。
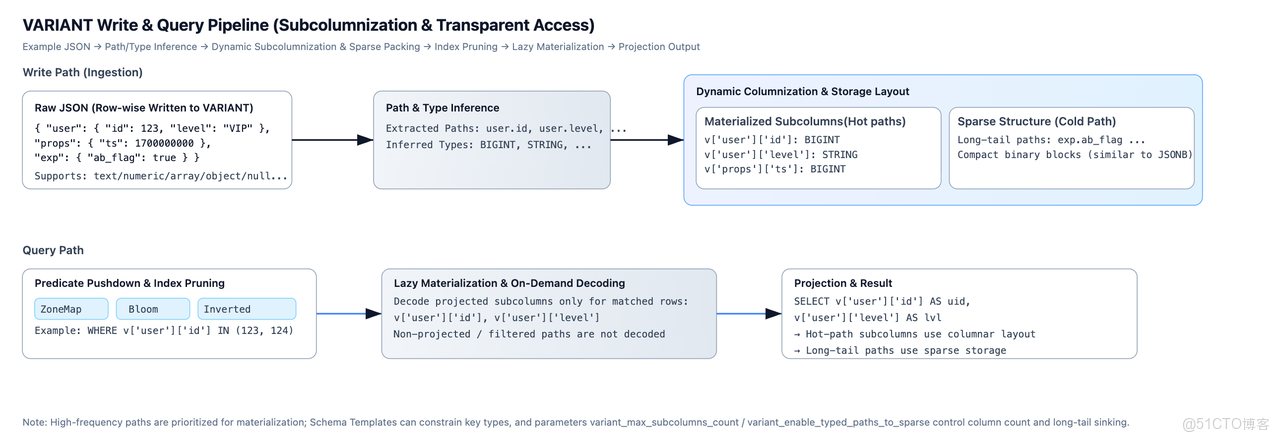
通過這一機制,Doris 在數據寫入階段就完成了從半結構化到準結構化的轉換,為高性能分析奠定了基礎。
1.2 列式存儲
在動態子列的基礎上,Doris 進一步運用成熟的列式存儲技術,實現存儲與 I/O 效率的倍增。
- 壓縮: Doris 會根據子列的數據分佈自動挑選壓縮算法,例如枚舉型字段使用字典編碼、連續數值用 RLE,從而實現更緊湊的存儲並降低讀取成本。
- 子列級 I/O (列裁剪):查詢只讀取實際需要的字段,消除了過去整塊 JSON 拉入再解析的方式。通過 Path 級別列裁剪和延遲物化機制,僅加載必需的 JSON 子列數據,有效減少了數據讀取的放大問題。

通過以上策略,Doris 解決傳統系統中 JSON 查詢的慢和重問題,成功地將 JSON 數據的靈活性與列式存儲的高性能相結合,實現了半結構化數據的高效分析。 這種方法不僅提高了查詢性能,還簡化了 Schema 管理,為用户帶來顯著的使用優勢。
1.3 千列級存儲的性能躍升
然後,當數據模型從寬進一步演化為超寬時,新的挑戰也隨之而來。因此 Doris Variant 持續優化,使其能夠從容面對元數據膨脹與合併(Compaction)開銷巨大的問題。
1.3.1 元數據存儲優化
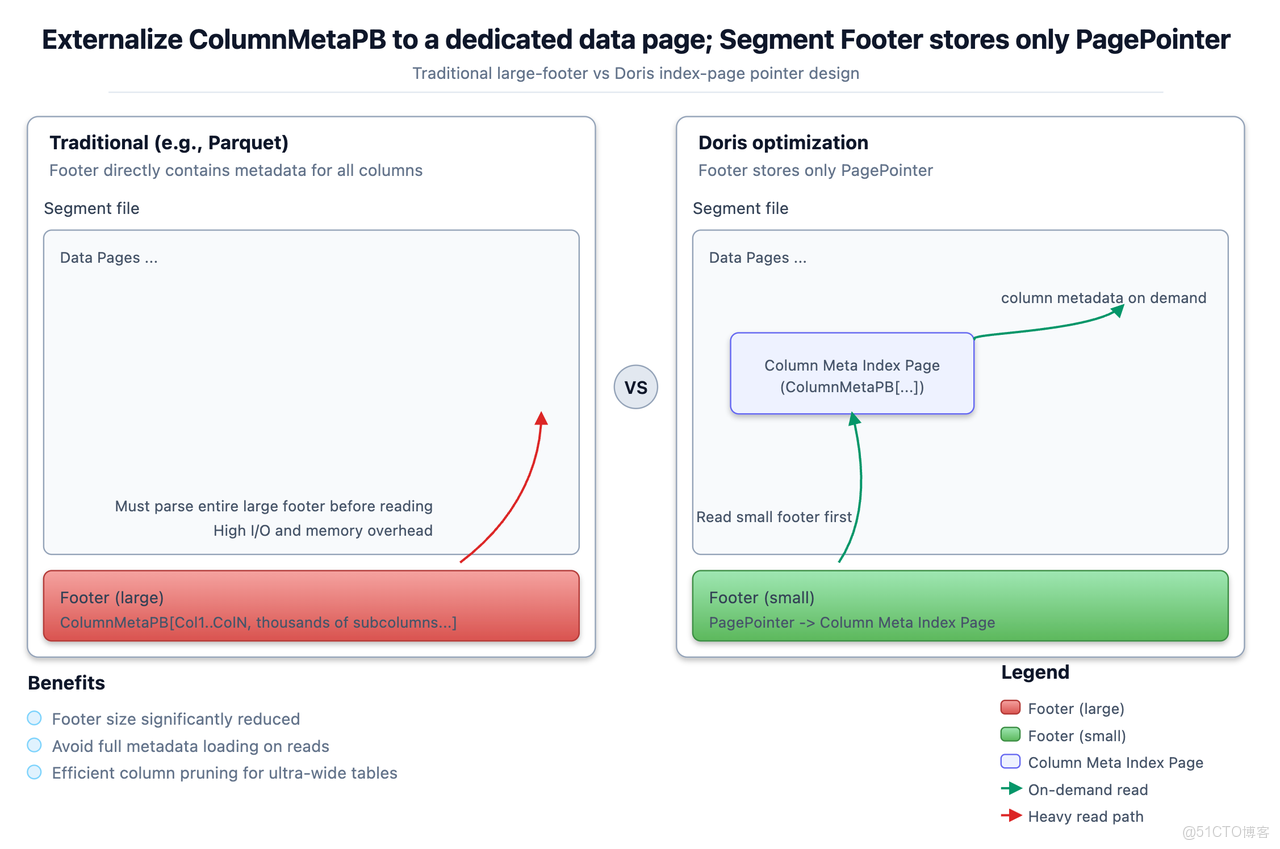
在日誌分析、用户畫像等超寬表場景中,單表常涉及上千個列(列存)。即便查詢僅需訪問其中幾列,也需將包含所有列元數據的龐大 Footer 完整加載至內存並解析,內存和反序列化成本急劇膨脹,導致嚴重的 I/O 與內存開銷。
為此,Doris 在 Segment 文件格式層進行了關鍵優化:將列元數據從 Footer 中剝離,獨立存儲於專用的數據頁(可理解為元數據索引頁)中,Footer 僅保留指向該頁的輕量指針。讀取時先加載精簡 Footer,再按需定位並加載所需列元數據。這種 Externalize Meta 的設計,從根本上避免了寬表場景下的元數據膨脹問題,使列裁剪始終保持高效。
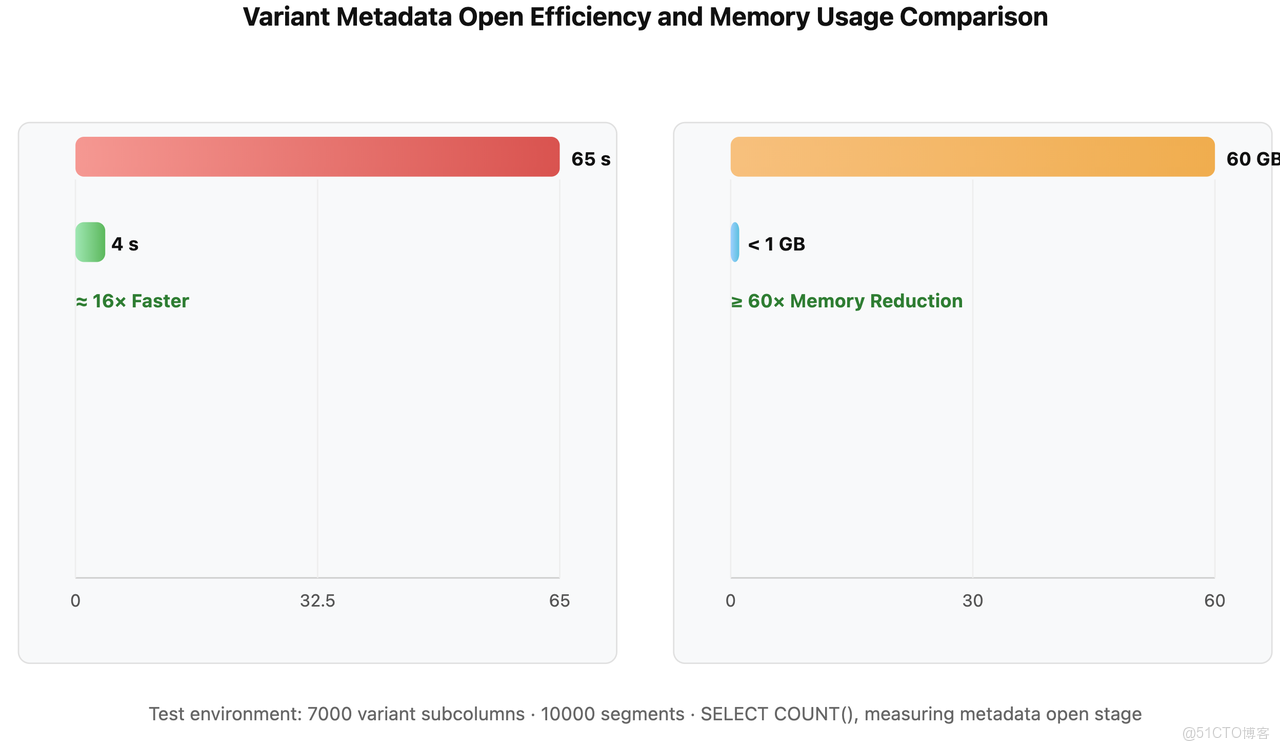
以下是關於 VARIANT 元數據打開效率的測試對比(環境設置包含 10,000 個 Segment,每個 Segment 擁有 7,000 個 JSON Path,且均已物化為子列):
- 優化前:需要解析巨大 Footer(包含所有列的 ColumnMeta),導致大量無效的 I/O 操作、反序列化和內存膨脹,I/O 成為性能瓶頸。
- 優化後:首先讀取小型 Footer(僅包含 PagePointer),然後按需加載被訪問列的元數據,避免全量解析。打開速度從 65s 縮減至 4s,效率提升約 16 倍;內存從 60GB 縮減至小於 1GB。
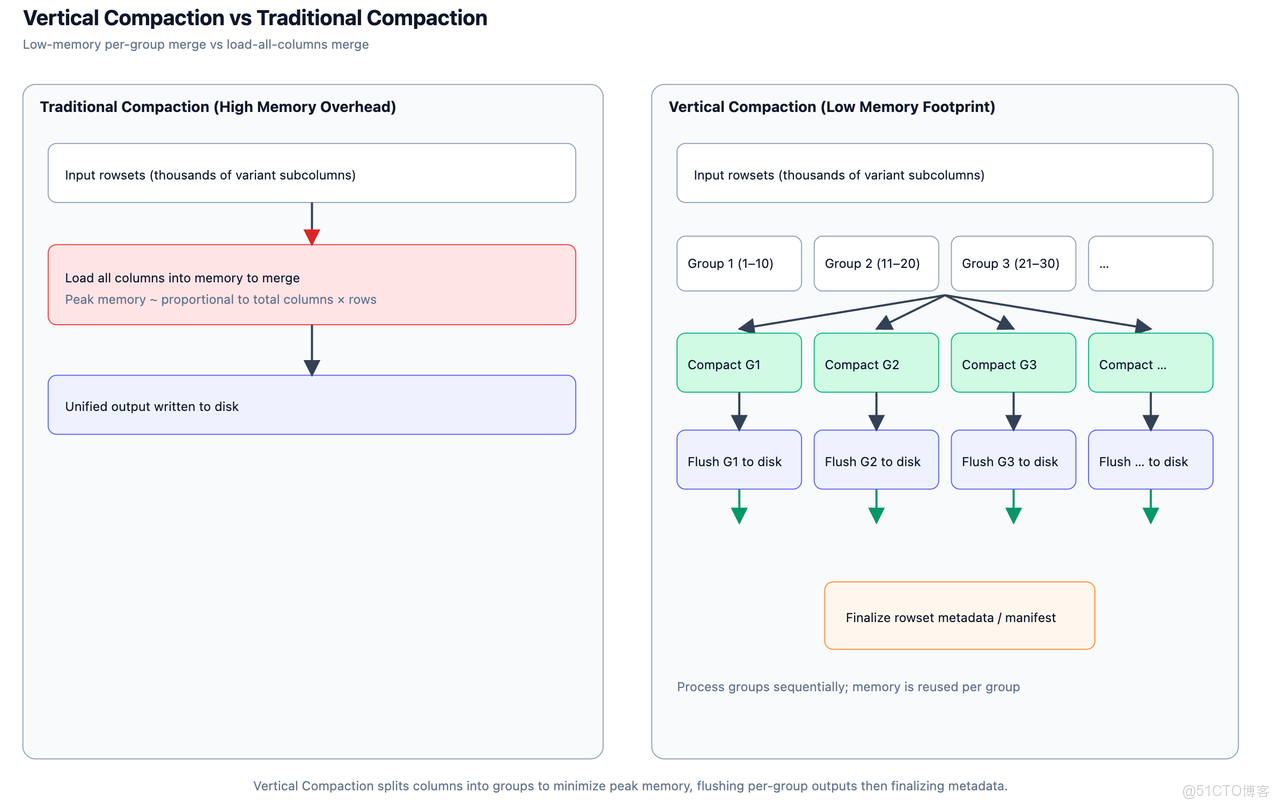
1.3.2 Vertical Compaction
在超寬表場景中,數據合併(Compaction)一直是最棘手的環節。隨着表中列數達到上千甚至上萬,傳統合並策略會暴露出兩個主要問題:首先,每次合併都需掃描並重寫所有列,即使絕大多數字段並未更新;其次,列元數據和 Segment 文件體積龐大,導致合併的 I/O 成本和內存消耗大幅增加。
為此,Doris Variant 引入子列級 Vertical Compaction,將單次 Compaction 拆分為按列分組的多輪合併。每輪僅加載部分列組(如 10 列),逐步完成全量合併。此舉帶來兩大核心改進:
- 內存峯值顯著降低:每輪只需持有部分列的中間數據,避免了全列併發合併帶來的內存瞬時激增;
- I/O 訪問更加可控:更細粒度的列組處理,可以更好與磁盤調度、後台刷寫並行化配合。
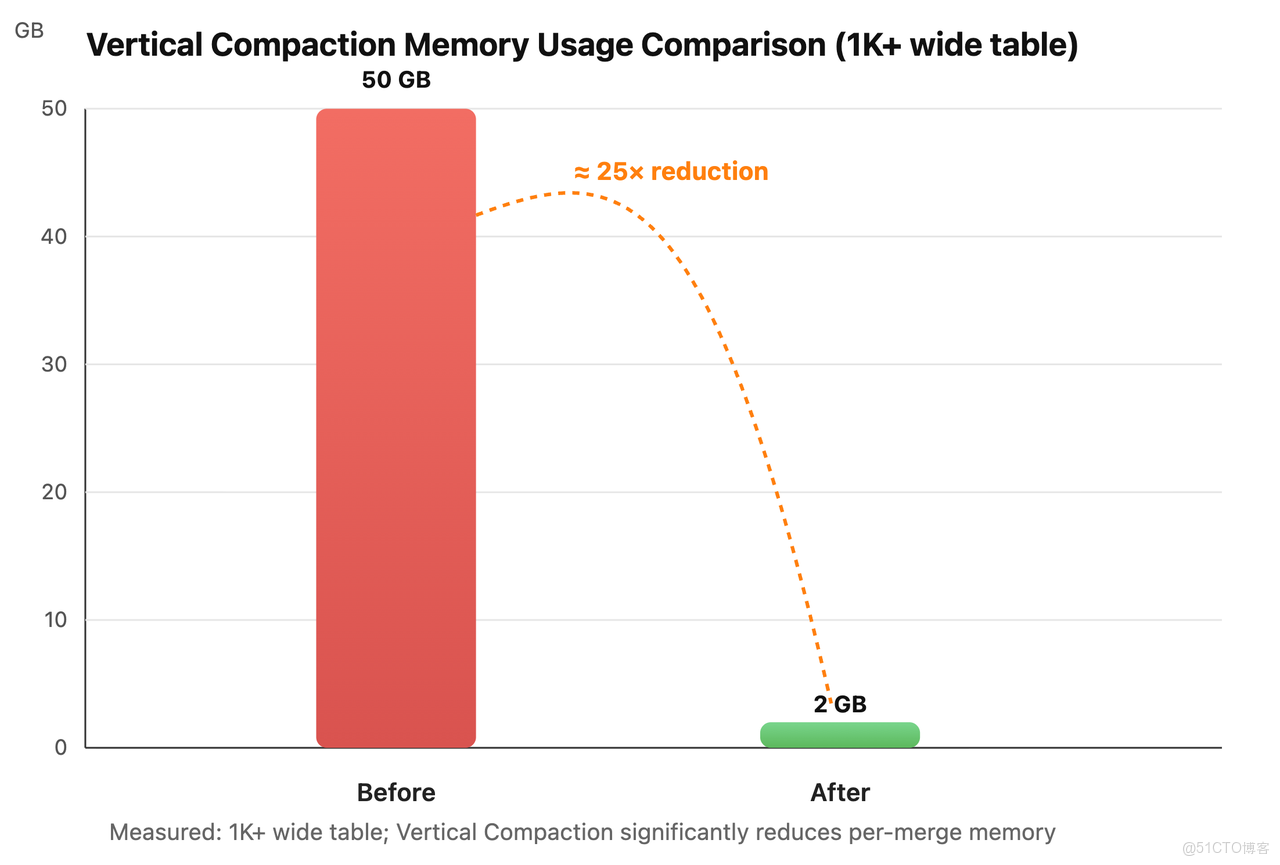
實測結果顯示,在表結構中列數超過 1,000 時,開啓 Vertical Compaction 後,單次合併的內存佔用從約 50 GB 降至 2 GB 左右,降低近 25 倍;同時,整體吞吐量幾乎未受影響。更重要的是,Vertical Compaction 使 VARIANT 不再只是能存 JSON,還能在動態 Schema 的超寬表模型中實現長期穩定的運行——這是大多數列式引擎的薄弱環節。
二、 兼備結構化查詢與全文檢索
動態子列解決了 JSON 在大規模掃描與聚合場景下的性能瓶頸,而 Doris 進一步為其構建了高度可定製的索引機制,使其在點查詢與文本檢索場景下也具備極速響應的能力。設計借鑑了 Elasticsearch dynamic mapping 的思想,可提供開箱即用的高性能索引能力。
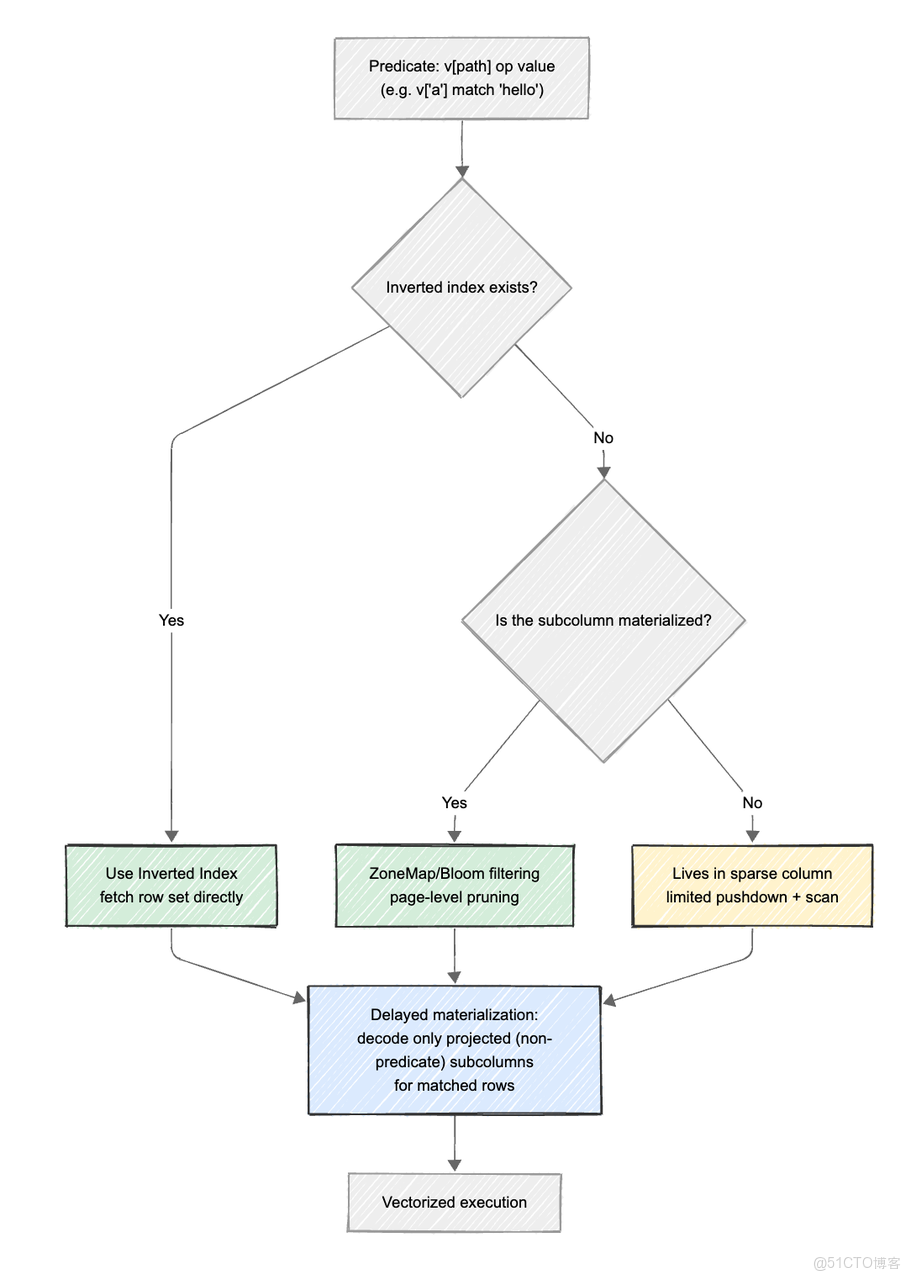
Doris Variant 的索引體系,目標是在 結構化過濾 與 全文檢索 之間取得平衡。它既能像列存一樣高效命中結構化字段,又能像搜索引擎一樣支持關鍵詞匹配與短語檢索。為實現這一目標,Doris 在存儲層集成倒排索引,並與 ZoneMap、BloomFilter、延遲物化 等原生索引協同工作,實現從文件級到行級的多層剪枝與快速定位。下面從幾個關鍵機制來看它的實現方式:
2.1 倒排索引的無縫集成
- 原理:
VARIANT允許用户為任意子列創建倒排索引。例如,CREATE INDEX idx ON tbl(v) USING INVERTED PROPERTIES("parser" = "english")。Doris 在數據寫入時,自動提取v子列的值,並分詞(如果需要)或按原始值建立一個從“詞(Term)”到“行號(RowID)”的映射表。 - 查詢: 當查詢條件為
WHERE v['message'] MATCH_ANY 'error'或v['level'] = 'FATAL'時,查詢引擎不需掃描全表數據。可直接利用倒排索引,快速定位包含關鍵詞error或FATAL的所有行,查詢複雜度從 O(N) 降至 O(logN) 甚至 O(1)。
2.2 內置索引的協同
由於高頻子列已被物化為內部子列,它們自然享受到 Doris 的其他索引類型的加成:
- ZoneMap 索引: 默認開啓,記錄每個數據塊(Page)內子列最大/最小值。對於
WHERE v['properties']['price'] > 1000這樣的範圍查詢,可快速跳過不滿足條件的數據塊,甚至跳過文件。 - BloomFilter 索引: 對於高基數的子列(如
user_id),可創建布隆過濾器索引,快速判斷某個值是否存在,過濾掉大量無關讀取請求。 - 延遲物化配合索引: 先用 ZoneMap/BBloomFilter 倒排在文件/頁/行級完成剪枝與定位,再對查詢命中的行按需解碼非謂詞投影的子列,避免對未投影或被過濾掉的子列做無謂解碼,可有效降低 CPU 與 I/O 成本。
2.3 Schema Template 與 Path 級索引
Schema Template 和 Path 級索引 是實現精確索引下推的關鍵機制。前者定義「哪些 JSON 子列需被單獨識別與優化」,後者定義「這些子列如何被索引與命中」。
通過 Schema Template,可以為關鍵子列預聲明類型及索引屬性,讓系統在讀寫階段就能識別這些高價值路徑。 Path 級索引則在此基礎上綁定倒排、Bloom 或 ZoneMap 等多層索引策略,實現結構感知的查詢優化。
典型配置:
CREATE TABLE IF NOT EXISTS tbl (
k BIGINT,
v VARIANT<'content' : STRING>,
INDEX idx_tokenized(v) USING INVERTED PROPERTIES(
"parser" = "english",
"field_pattern" = "content",
"support_phrase" = "true"
),
INDEX idx_keyword(v) USING INVERTED PROPERTIES(
"field_pattern" = "content"
)
);
-- tokenized for MATCH; keyword for exact equality
SELECT * FROM tbl WHERE v['content'] MATCH 'Doris';
SELECT * FROM tbl WHERE v['content'] = 'Doris';
tokenized 用於
MATCH搜索;keyword 用於精確匹配。
通配符示例:
INDEX idx_logs(v) USING INVERTED PROPERTIES(
"field_pattern" = "logs.*"
);
更多使用方式請參考:Variant 文檔
三、典型場景實戰指南
3.1 日誌分析場景
基於 Elasticsearch 或 ClickHouse 的日誌分析平台是較為常見的方案,但其問題也比較明顯:寫入成本高、字段變化難以管理以及查詢吞吐不穩定等。
而如果使用 Doris ,Variant 類型可直接寫入原始 JSON 日誌,不再需要複雜的 ETL 或 Schema Flatten,無需複雜的預處理和 Schema 定義,即可對任意日誌字段進行高性能的過濾和全文檢索。
示例建表:
CREATE TABLE access_log (
dt DATE,
log JSON
)
DUPLICATE KEY(dt)
DISTRIBUTED BY HASH(dt)
PROPERTIES ("replication_num" = "1");
CREATE INDEX idx_log ON access_log(log) USING INVERTED;
日誌通過 Stream Load 實時寫入:
curl -u user:password \
-T access.json \
-H "format: json" \
http://fe_host:8030/api/db/access_log/_stream_load
隨後就可以像操作結構化數據一樣執行查詢:
SELECT
log['status'] AS status,COUNT(*) AS cnt
FROM access_log
WHERE log['region'] = 'US'
GROUP BY status;
在這個場景中,Doris 會自動將 key 列化存儲,例如 region 和 status,從而實現亞秒級聚合性能。同時日誌結構若有新增字段(例如 latency 或 trace_id),系統會自動創建列存並寫入索引,無需手動 ALTER TABLE 或重新導入。
實測表明,在同等硬件條件下,Doris 的日誌聚合查詢性能相比 Elasticsearch 快 2–3 倍,寫入延遲降低 80% 以上,減少約 70–80% 存儲空間。
3.2 動態用户畫像
在用户畫像系統中,每個用户通常擁有成百上千個標籤,如地域、興趣、偏好、活躍度和渠道來源等。這些標籤往往需要頻繁新增或變更。傳統的列式建模方案意味着需要不斷修改表結構或維護上百個寬表,這種做法效率極低。而 Doris 的 VARIANT 只需一個 Profile 列即可容納所有標籤信息。
示例建表:
CREATE TABLE user_profile (
user_id BIGINT,
profile VARIANT
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id);
寫入時直接插入 JSON 結構:
INSERT INTO user_profile VALUES
(1001, '{"region": "US", "age": 28, "interest": ["movie","sports"]}'),
(1002, '{"region": "CA", "vip": true, "device": "ios"}');
查詢時無需展開,也能高效聚合:
SELECT
CAST(profile['region'] AS String) AS region,COUNT(*) AS cnt
FROM user_profile
WHERE profile['vip'] = true
GROUP BY region;
在後台,Doris 會自動識別出現的 key (如 region 、vip ),並將其物化為獨立列(支持成千上萬的獨立列)。極其低頻字段仍保留在兜底 Sparse 列中。 因此即便標籤數量增長到上千個,查詢性能依然接近普通結構化表。
實際用户測試中,擁有 7000 個動態標籤的用户畫像表,查詢 Top10 標籤分佈的平均響應時間保持在 1 秒以內。
3.3 客户使用反饋
度小滿實現從 Greenplum 到 Apache Doris 的平滑遷移,構建了超大規模數據分析平台。藉助內置的 Variant 類型,實現了對 2–3 萬 JSON Key 的高效查詢與存儲(PB 級別)。系統整體性能提升 20–30 倍,JSON 查詢速度提升 10 倍,存儲佔用為傳統 JSON 類型的 1/10。在高併發實時查詢與複雜分析任務下,成功支撐 金融級指標分析與實時數據服務,讓度小滿的數據平台實現從 離線分析 → 實時洞察的跨越。
——度小滿
某大型互聯網公司將原有 HBase + Elasticsearch + Snowflake 三套系統遷移至 Doris 這一套系統中來,實現了搜索與分析統一。Doris Variant 列式數據類型支持高維、動態 JSON 的高效存儲與查詢,讓數十億對象的非結構化屬性也能以列式方式處理。並基於子列索引與裁剪機制,查詢延遲從秒級降至百毫秒級,併發寫入與複雜 Join 性能也顯著提升。系統整體成本降低,架構得到簡化,穩定性與一致性全面增強。
——某大型互聯網公司
在原系統中(Elasticsearch),Dynamic Mapping 導致字段衝突頻發、資源佔用高、聚合性能受限。觀測雲攜手飛輪科技,基於 Doris 引入 Variant 數據類型與倒排索引,並通過 S3 對象存儲 構建彈性冷熱分離架構,大幅提升日誌與行為數據的查詢效率。升級後,機器成本降低 70%,整體查詢性能提升 2 倍,簡單查詢提速超 4 倍,以不到 1/3 的成本獲得數倍性能提升,顯著增強了可觀測性平台的可擴展性與經濟性。
——觀測雲
某全球領先的新能源與智能製造企業將原有 Hive/Kudu + Impala/Presto 體系遷移到 Apache Doris,構建了面向車聯網與裝備全生命週期的實時分析平台。依託 Doris 內置的 Variant 類型,高效處理 PB 級規模的 JSON 半結構化數據,實現秒級實時攝取和毫秒級查詢性能。 在核心業務如實時看板、全鏈路追蹤、設備運行與健康分析等場景中,複雜 JSON 查詢提速 3–10 倍、高併發查詢能力顯著提升、且存儲佔用僅為傳統方案的 1/3。藉助統一的 Doris 引擎,實現從離線批處理到實時洞察的跨越,大幅降低整體架構複雜度與運維成本。
——某全球領先的新能源與智能製造企業
面對上百萬輛車日均數十 TB 信號數據的挑戰,零跑採用 Variant 動態列存 與 S3 對象存儲 構建統一數據底座,支持了智能座艙、遠程診斷和用户行為分析等多場景。結合物化視圖與彈性計算,實現毫秒級查詢與自動伸縮、存儲成本下降 60% 的顯著成效。團隊正進一步驗證 Serverless 形態,希望利用 S3 的高彈性與 Doris 的高性能,實現“按需使用、零運維伸縮”的數據雲腦。
—— 零跑汽車
四、結束語
Apache Doris 的 VARIANT 類型,讓半結構化數據能在列式引擎中被自然地處理。它通過動態子列、稀疏列存儲、延遲物化和路徑索引,將 JSON 解析、列裁剪與索引下推整合為統一體系,實現了靈活結構 與 列存性能的平衡。
未來,Apache Doris 將進一步增強 Variant 自動 Schema 推導能力,支持更豐富的類型、更強大的子列索引系統,並優化稀疏列的數據查詢。